NLP论文阅读记录 - 2022 | WOS 04.基于 XAI 的强化学习方法,用于社交物联网内容的文本摘要
文章目录
- 前言
- 0、论文摘要
- 一、Introduction
-
- 1.1目标问题
- 1.2相关的尝试
- 1.3本文贡献
- 二.相关工作
- 三.本文方法
-
- 3.1 总结为两阶段学习
-
- 3.1.1 基础系统
- 3.2 重构文本摘要
- 四 实验效果
-
- 4.1数据集
- 4.2 对比模型
- 4.3实施细节
- 4.4评估指标
- 4.5 实验结果
-
- 4.6 细粒度分析
- 五 总结
- 思考
前言

XAI-Based Reinforcement Learning Approach for Text Summarization of Social IoT-Based Content(2204)
0、论文摘要
自动文本摘要技术的目的是压缩给定的文本,同时在摘要中正确地描绘原始文本中的主要信息。另一方面,目前的生成文本摘要方法在构建摘要句子时重构原始语言并引入新单词,这很容易导致不连贯和可读性差。 )这项研究提出了一种基于 XAI(可解释人工智能)的强化学习,使用强化学习对基于社交物联网的内容进行文本摘要。此
外,基于标记数据来提高摘要句子连贯性的标准监督训练具有巨大的数据成本,这限制了实际应用。为了做到这一点,提出了一种基于真实情况的文本摘要(生成)模型(XAI-RL)以增强连贯性。
一方面,根据原文的编码结果,生成句子提取标识符,描述原文重要信息的筛选过程。在确定两种类型摘要文章的整体效益后,自判断方法梯度帮助模型学习关键句子选择并解码所选关键短语,从而产生句子连贯性高、内容质量好的摘要文本。
实验表明,即使没有预先注释的摘要事实,该模型的摘要内容索引总体上优于文本摘要方式;信息冗余、词汇原创性和抽象复杂性也优于当前方法。
一、Introduction
1.1目标问题
随着互联网的快速发展,网络中蕴藏着海量的基础、形式多样的数据内容。从中快速定位关键信息是高效信息检索的首要问题。对于文本数据来说,自动文摘技术可以从给定的语料库中提取出核心内容,并用相对概括的文本来描述原文的主要内容,有利于降低文本数据的存储成本,是提高文本数据质量的必要手段。文本数据检索的效率。对于进一步实现信息集成具有重要的现实意义和应用价值。
现有的自动文本摘要方法可以直接从原始文本中选择基本句子或段落,并通过句子提取生成摘要文本[1]。生成文本摘要方法已成为文本摘要领域的研究热点[2]。一般来说,生成文本摘要方法首先对给定的原始文本进行编码,获得可以从词和句子层面覆盖原始文本信息的向量(嵌入)表示。最后对上述特征码进行解码,即根据解码结果,从给定的语言(词典)中选择相应的词汇,形成摘要文本。最后,将原文以文本形式重新表达。可以看出,与提取方法相比,生成文本摘要的实现更为复杂。尽管如此,它产生的摘要文本词汇表达更加灵活和丰富,浓缩原文关键信息的效果也更加理想[3]。
但面临的问题是,生成式文本摘要方法需要经过原文编码、编码解析、特征解码等过程,组织词汇量更丰富的句子来传达原文,因此很容易导致生成的摘要句子的连贯性。此外,当前的生成式文本摘要方法涉及人工注释摘要以进行监督训练[3],导致现有的生成式文本摘要方法经常面临问题。由于宝贵资源的稀缺,仅依靠预先句子连贯性较强的“摘要真值”,并根据监督训练的方法来提高模型生成的摘要的句子连贯性,在实际中可能存在很大阻力。应用[4]。因此,本文在生成文本摘要模型的基础上,寻求一种无需干预即可提高摘要生成模型句子连贯性的有效机制。
具体来说,一方面,在摘要文本生成阶段,编码器(模块A)首先对给定的源文档(source document)进行编码,得到原始文本的嵌入表示;在此基础上,进一步使用连贯性测量模块(模块B)e Transformer-XL [5]编码器对原文的嵌入表示进行编码,解析上下文相关的内容特征,并设置一个“关键句分类层” ”位于连贯性测量模块的顶部,生成句子提取标识符,过滤掉(或成为关键)句子编码结果,描述通过连贯性测量模块从原文中提取关键句子的过程;最后,解码器(模块C)基于一致性测量模块输出的关键句编码。并生成“提取”的关键句子的解码结果,即原始词汇分布。
另一方面,在句子连贯性增强阶段,模型XAI-RL首先获得前一级解码器(模块C)输出的原始词汇分布,并通过“按概率选择”和“按概率选择”生成两种类型的摘要文本。 Softmax-greedy”,两种类型的摘要由编码器(模块 A)重新编码;之后,由一致性测量模块(模块B)解析两类摘要的重编码结果,由一致性测量模块(模块B)解析两类摘要的重编码结果。 )e语义片段(segment)[5]的循环自注意力权重作为摘要句的连贯性效益;将生成的摘要文本的ROUGE[6]得分和“伪摘要真值”作为摘要句子的内容收益,从而通过连贯性测量模块将上述两项收益相加,计算出两种类型摘要文本各自的总体优势;这里,“伪摘要的真实值”是通过ROUGE评分从原文中提取的最优句子集。其次,构建两类摘要的“交叉熵损失”,采用XAI-Based强化学习中的“自我批评策略梯度”[7],并利用两类摘要的“总体回报差异”奖励或奖励模型参数梯度。 Penalty是迫使“Softmax-贪婪选择”生成的摘要的整体恢复接近“概率选择”生成的摘要的整体恢复,并通过“概率探索”提高“Softmax-贪婪选择”的总体基线水平,”,然后在句子连贯性和句子内容方面提高 XAI-RL 生成的摘要文本的模型值。最终在没有抽象真值介入的情况下,生成句子连贯性高、内容质量好的抽象文本。
1.2相关的尝试
1.3本文贡献
总之,我们的贡献如下:
综上所述,本文提出了一种面向连贯性增强的无真值文本摘要模型(XAI-RL),该模型结合“提取和生成”,根据从原文中提取的关键句子集生成摘要内容。同时,通过对最初生成的摘要文本进行重新编码、连贯性和内容收益计算,基于解码器的实际词汇分布,得到“通过概率选择”与“通过Softmax-贪婪选择”进行比较。 “获得优势”通过最大化这种“利润优势”来指导模型梯度更新,以生成具有更高句子连贯性的摘要文本。实验结果表明,即使在仅给定原文的限制下,XAI-RL模型的ROUGE[6]和METEOR[8]评分指标总体上仍然优于现有的文本摘要方法。摘要文本在句子连贯性、内容重要性、信息冗余、词汇新颖性和摘要困惑度方面也优于现有方法。
二.相关工作
目前,基于“编码-解码”思想的序列到序列(Seq2Seq)结构是处理生成文本摘要任务的主要方法[3]。传统Seq2Seq结构中的编码器和解码器通常使用循环神经网络(RNN)[9]、长短期记忆(LSTM)[10]和双向长短期记忆(Bi-LSTM) [11],为了生成句子质量更好的摘要文本,许多学者对上述摘要和基于循环神经网络及其变体的生成模型进行了相关改进。
作者[12]提出了一种分层编码器,可以从单词和片段两个级别捕获输入文本的语篇结构,并将语篇结构特征注入解码器以协助解码器生成摘要文本。高 ROUGE 分数是在开发学术论文摘要的任务上取得了成就。作者[13]在解码器端引入了解码器内注意力机制,即在解码第t位时观察解码结果的前t-1位,注意力权重防止解码器生成重复内容,这有效减少摘要文本句子内容的冗余;同时,本文结合Teacher Forcing算法[14]和自判断策略梯度[7]构建了混合XAIBased强化学习目标,使得模型在处理原始文本时有效避免暴露偏差,并生成摘要文本,评价准确度高。作者[15]首先将输入的原始文本分为多个片段,并基于Bi-LSTM,模型构建多个代理;之后,每个智能体解析分配的元素,并根据多智能体通信机制在智能体之间传输该部分的解析结果,最终形成原文的“全局观察”,定义为“全局观察” ”根据“编码-解码”的思想生成摘要文本。
尽管上述模型在摘要生成的准确性方面取得了提高,但循环神经网络及其变体都是基于时间步的序列结构,这严重阻碍了模型的并行训练[16-18],导致推理能力下降。过程受到内存的限制,导致摘要生成模型的编码和解码速度降低,并增加训练开销[19-23]。另一方面,上述工作优化模型以最大化ROUGE指数或最大似然,而不考虑摘要句子的连贯性或流畅性[24-26]并依赖于预先注释的摘要文本的ground-truth值。在有监督训练的情况下,模型训练所涉及的数据成本很高。 )因此,需要进一步改进基于循环神经网络及其变体的摘要生成模型[27-29]。
关于摘要句子连贯性的工作还包括:作者通过对原始文本进行编码、解码和重新编码来优化模型,构建摘要相似性损失和文本重建损失。一个好的语言模型会计算生成的摘要文本的负对数似然来衡量句子的连贯性;作者使用BERTSCORE指标构建分布式语义增益,并将支付与自判断策略梯度相结合来评估模型优化。人类评估结果表明,这种好处可以使模型摘要更加连贯;作者在预训练解码器后,通过在句子级别应用优势演员评论家 (A2C) 来优化提取器,以确保模型解释正确的关键句子以生成连贯且流畅的摘要 [30, 31]。
上述模型优化了摘要的连贯性,以最大限度地减少生成的摘要文本的复杂性。但值得注意的是,现有作品在评估摘要句子的连贯性时均采用人工评估方法。 )摘要生成模型中缺乏自动测量句子连贯性的机制或过程[32-34]。综上所述,当前的生成文本摘要方法应满足或解决以下问题:第一,能够根据给定的原文生成连贯且可读性强的摘要文本;对生成的摘要句子进行自动一致性测量的处理机制;第三,应尽量减少模型训练过程中摘要真实数据的标签依赖性,以降低模型训练成本[35-37]。
三.本文方法
3.1 总结为两阶段学习
3.1.1 基础系统
3.2 重构文本摘要
四 实验效果
)这一章对本文提出的用于增强连贯性的依赖于事实的文本摘要模型(XAI-RL)进行了一系列实验分析,并讨论了该模型在摘要生成过程和摘要生成质量方面的有效性。 )论文使用Python 3.7和Tensorflow-1.15来实现模型,实验运行环境为GPU,NVIDIA GeForceGTX 1080Ti,11 GB。
4.1数据集
首先,本文使用两个典型的自动文本摘要数据集 CNN/Daily Mail 和 XSum 进行实验[41, 42]。 )它们都使用新闻报道作为文本数据,并包含相应的“黄金标准”摘要事实文档。本文将原始数据集分为训练集、验证集和测试集。 )训练集用于模型训练,验证集用于模型参数选择,测试集用于模型评估。特别是,“黄金标准”摘要确实不参与模型XAI-RL训练过程,仅用于摘要生成质量评估。如表1所示,CNN/Daily Mail中原文和摘要文本的平均长度大于XSum; XSum 是人类编写的作为概念真值的句子。与 CNN/DailyMail 相比,XSum 中的 groundtruth 的新颖性更高,并且包含更多原文中未出现的单词。
其次,在模型设置方面,设词向量维度为E,隐藏层单元数量为H,自注意力头数量为A,前馈层维度大小为F,XAI-RL模型采用ALBERTlarge[30](E = 128,H = 1.024,A = 16,F = 4.096)作为编码器,相干性度量模块由L = 3层Transformer-XL编码器组成(E = 1.024,H = 2.048,A = 32,F = 4.096),解码器由 R = 6 Transformer-XL 解码器组成(E = 1.024,H = 2.048,A = 32,F = 4.096)。在摘要文本生成阶段,使用宽度为4的束搜索算法进行词汇选择。 )生成摘要的最大长度由原始文档和摘要文档在数据集中的平均压缩比(文档长度的比率)决定,并且丢弃的词数较低。在第3句中,相干性度量模块和解码器采用Adam优化器[19],学习率分别为1E-3和0.05。 )e 两者的学习率都随着迭代次数的增加而降低。 )e个batch样本数(batch_size,即输入文本集D的大小)为16。在句子连贯性增强阶段,β1 = 0.3和β2 = 0.2取自式(6)所示的文本内容收益,式(6)的总收入中c = 0.7。当使用 CNN/Daily Mail 数据集训练模型时,输入文本集 D 在一次迭代中取前 M=8 个最优记录,用于一致性增强阶段的“体验回放”;当用XSum训练时,D在一次迭代中,取前M=4个最优记录。

4.2 对比模型
)en,在比较方法方面,本文提出的摘要生成模型XAI-RL与现有的提取式和生成式自动摘要方法进行了比较。其中,对于提取方法,使用了MMS_Text、SummaRuNNer和HSSAS;对于生成方法,Pointer-Generator + Coverage、Bottom-up、DCA(深度通信代理)、BERTSUMEXTABS 和 PEGASUS。
4.3实施细节
4.4评估指标
最后,对于评价指标,本文采用ROUGE-N[6](包括ROUGE-1和ROUGE-2,式(12))、ROUGE-L(式(13))和METEOR[8](式(14) ))。 )e指标评估生成文本的内容质量,同时配合人工评估,从句子连贯性、内容冗余度、内容重要性等方面评估相关模型生成的摘要文本。这里,在ROUGE-N中,n表示n-gram(n-gram)的长度,{RS}表示参考摘要,Countmatch(grain)表示生成的摘要中与参考摘要中相同的n-gram数量,Count(grain) 是参考摘要中 n 元语法的总数。 ROUGE-L中,X为生成摘要,Y为参考摘要,LCS(X,Y)表示生成摘要与参考摘要之间的最长公共子序列的长度,m为展开摘要长度,n为参考摘要长度; METEOR中,m为生成摘要中与参考摘要匹配的元组数量,r为连接摘要长度,c为展开摘要长度,α、c、β为平衡参数,dh为生成概念和参考摘要公共子序列的数量。
4.5 实验结果
为了探索XAI-RL模型中不同模块对实验结果的影响,本文实现了如表2所示的六种烧蚀组合。具体来说,组合1使用模块A(AL-BERT编码器)和模块B(相干性度量模块,仅Transformer-XL编码器)进行编码,而没有可替换的顶层进行编码,然后使用模块C(解码器)进行编码和解码以产生摘要。组合2在组合1的基础上向模块B添加了一个sigmoid分类层,其目的是对文本编码表示进行关键句子选择,然后生成摘要。组合3与组合2结构相同,但预训练了模块B;特别地,上述三种组合都是使用训练集“金标准”作为ground Truth的监督训练。最后,组合4采用组合3的结构。除了预训练模块B之外,仅通过最大化相干增益来进行相干增强。在强化过程中,将提取的伪摘要作为替代真值;组合5与组合4类似,只是通过最大化内容收益来增强连贯性;组合6是图1中完整的XAI-RL模型,仍然使用提取的伪摘要作为替代真值。


CNN/Daily Mail 和 XSum 验证集评估了上述六种烧蚀组合。 )e实验结果如表3和表4以及图3和图4所示。
首先,组合2的评估结果优于组合1,这表明在模块B提取关键句子后,解码器可以解码关键内容并生成更高质量的摘要。其次,组合3优于组合2,说明预训练可以使模块B的参数配置更加合理,进而更加合理地选择关键句子。 )en,组合4和组合5的评价结果优于组合3,表明本文构建的收益和句子连贯性增强方法能够有效提高摘要内容的质量。特别是组合4的ROUGE-L和METEOR指标优于组合3,体现了本文通过连贯性测量和强化对句子连贯性的提升。最后,所有机制6的组合具有最佳评估结果,反映了所提出的模型XAI-RL的每个模块在摘要生成中的有效性。
综上所述,对于XAI-RL模型,首先通过比较组合二和组合三可以发现,通过伪摘要对连贯性测量模块进行预训练后,可以更好地从组合二和组合三中识别出有意义的句子和上下文语义信息。文本编码表示,为解码器提供语义基准和辅助输入,生成能够准确概括原文主要思想的摘要内容;其次,通过比较组合三和组合四,可以发现self.
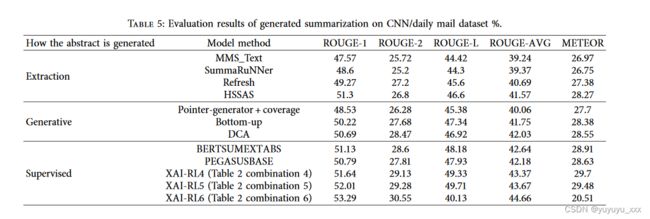
4.6 细粒度分析
4.3. XAI-RL 模型与现有文本摘要模型的比较。在本节中,XAI-RL模型的准确性与测试集上现有的提取和生成方法进行比较,以评估其摘要生成质量。首先,XAI-RL模型的评估结果(3次平均值)以及在CNN/Daily Mail数据集上的比较方法如表5所示(ROUGEAVG是ROUGE-1、ROUGE-2和ROUGE-的平均值)L)。一方面,如图5所示,XAI-RL模型的评估结果普遍优于现有的提取方法。 )模型在ROUGE-1和ROUGE-2指标上优于其他基于提取的基线模型,表明其能够有效获取原始受试者信息。
五 总结
利用自动文本摘要技术浓缩文本核心内容是降低文本数据存储成本、提高信息检索效率的必要手段。为了快速生成高质量且可读的文本摘要,同时避免模型训练的真实依赖,本文提出的基于 XAI-RL 的连贯性增强文本摘要模型(XAI-RL)利用注意力机制的 Transformer-XL 来构建一致性测量模块,并使用提取的伪摘要对其进行预训练,可以有效地识别和去除重要的文本信息。此外,它可以在重编码过程中自动衡量生成摘要的连贯性,并产生文本连贯性效益,可以将其引入到模型的连贯性增强过程中,从而可以促进模型生成更接近原始主题,更具可读性的摘要内容。实验表明,在多组实验中,结合相干性度量和相干性增强的XAI-RL模型的评估精度优于其他现有方法。 )本文未来的工作将进一步提高自注意力权重在相干性测量上的有效性。通过构建各种测量方法,从多个角度考虑语义连接、语法规则性和共指消歧等连贯性因素,以提高下一代模型的句子连贯性。
同时,其在ROUGE-L和METEOR指标上的得分高于其他基于提取的基线模型,这表明该模型在释义获取的重要句子时能够保证生成句子的连贯性。对比提取方法(MMS_Text、SummaRuNNer、Refresh、HSSAS)的核心思想可以概括为三类:一是将文本转化为图结构(如MMS_Text),通过对节点(句子)进行评分来提取本质形成摘要文本的句子;二是通过编码器挖掘读者的潜在特征,按照概率矩阵或句子排列的顺序提取摘要句子(例如SummaRuNNer和HSSAS)。第三是使用基于XAI的强化学习来构建质量增益,并在更新句子选择策略以最大化利润后,从原始文档中提取摘要文本(例如Refresh)。然而,对于本文提出的XAIRL模型来说,其核心思想是“先提取,后生成”。 )模型的连贯性测量模块可以在预训练后识别并提取原文中的关键句子,从而提示解码器关注实际内容。另外,在解码和生成时,XAI-RL模型向解码器输出包含上下文语义的辅助信息H,进一步丰富了模型内部的文本特征信息,最终使得模型XAI-RL生成的摘要文本的质量强化学习优于“单一”提取模型。另一方面,如图6(b)所示,XAI-RL模型与现有的生成方法(Pointer-Generator + Coverage [11]、Bottom-up、DCA [15]、BERTSUMEXTABS [19]和PEGASUS)并且总体上也取得了更好的精度。 )e模型在ROUGE-1和ROUGE-2指标上优于其他生成基线模型,表明它可以正确地解释原始文本消息。同时,其在 ROUGE-L 和 METEOR 指标上的得分均高于其他生成基线模型,这表明该模型更能够生成连贯且流畅的摘要内容。其性能提升可以归因于:首先,在开发摘要方面,如图2所示,模型XAI-RL基于预训练组件(如AL-BERT编码器和预训练相干性测量模块),并且进一步使用文本编码结果。 )e语义段是划分单元,由L�3layer Transformer-XL组件通过基于语义段的循环自注意力机制进行额外编码,以增加特征解析的强度。其次,在图4所示的连贯性增强过程中,模型XAI-RL对生成的摘要文本进行重新编码,以计算连贯性增益;同时,使用提取的伪摘要创建摘要,通过最大化两者来计算内容增益。 )收入的加权总和增强了模型摘要文本生成过程。此外,它从内容和句子连贯性水平提高了模型文本生成质量。
其次,XAI-RL模型和对比方法在XSum数据集上的评估结果(3次平均值)如表6所示,相应的直方图如图6所示。总体而言,模型仍然达到了最优结果。特别是,XSum 数据集仅用于测试生成方法,因为它具有与“黄金标准”摘要相对应的高度新颖性。表6和图6的结果进一步说明了模型XAIRL所遵循的“先提取,后生成”的设计原则,基于语义分段的循环自注意力权重,以及基于内容效益和连贯效益的强化过程可以有效提高摘要生成质量。
