FastSpeech2——TTS论文阅读
笔记地址:https://flowus.cn/share/1683b50b-1469-4d57-bef0-7631d39ac8f0
【FlowUs 息流】FastSpeech2
论文地址:lFastSpeech 2: Fast and High-Quality End-to-End Text to Speech https://arxiv.org/abs/2006.04558
https://arxiv.org/abs/2006.04558
Abstract:
tacotron→fastspeech,引入knowledge distillation,缓解TTS中one-to-many problem。问题:teacher-student distillation pipeline 1)复杂速度慢 2)不够准确 3)学生模型是从教师模型输出的结果来学习,而不是直接学习mel图谱,导致信息缺失
fastspeech2的解决方案:1)直接从gt进行训练 2)引入更多条件输入:pitch, enerngy, accurate, duration。具体为:extract duration, pitch and energy from speech waveform and directly take them as conditional inputs in training and use predicted values in inference
1.Introduction:
fastspeech2改进之处:
1.直接使用gt来训练fastspeech2模型
2.为了缓解one-to-many problem,引入更多的声音condition;训练时,先从目标语音波形中提取pitch, energy, extrate duration,然后作为condition输入
3.音高energy难以预测且重要,采用方法we convert the pitch contour into pitch spectrogram using continuous wavelet transform and predict the pitch in the frequency domain, which can improve the accuracy of predicted pitch.
4.Fastspeech2s,不采用mel图谱,而是直接从text中生成语音波形
贡献:
- FastSpeech 2 achieves a 3x training speed-up over FastSpeech by simplifying the training pipeline.
- FastSpeech 2 alleviates the one-to-many mapping problem in TTS and achieves better voice quality.
- FastSpeech 2s further simplifies the inference pipeline for speech synthesis while maintaining high voice quality, by directly generating speech waveform from text.
2.FastSpeech2 and 2s
2.1Motivation
解决自回归模型中one-to-many problem,fastspeech中teacher-student复杂,损失,不准确问题
2.2Model Overview
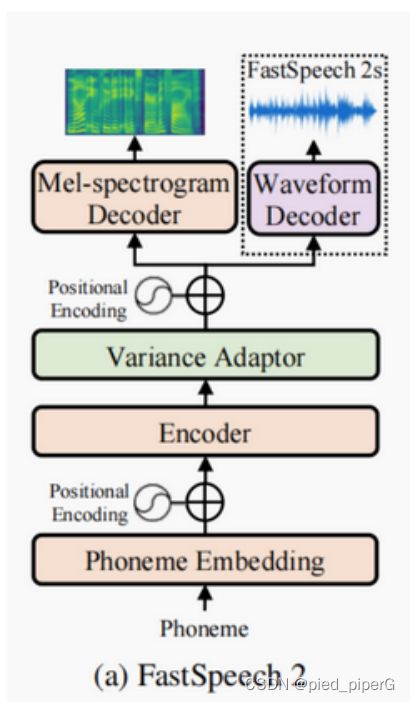
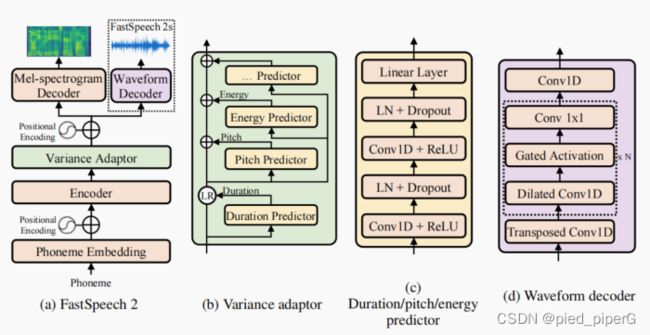
结构:
编码器(Encoder):编码器的作用是将输入的音素嵌入序列转换为隐藏的音素序列。音素嵌入是将文本中的每个音素转换为一个高维向量,这些向量包含了音素的丰富信息。
变异调节器(Variance Adaptor):变异调节器的功能是在隐藏序列中添加不同的变化信息,包括音长(duration)、音高(pitch)和能量(energy)。这些信息对于模拟自然语音的细微变化非常重要,有助于缓解文本到语音转换中的一对多映射问题。
Mel频谱解码器(Mel-spectrogram Decoder):这个部分将经过变异调节器调整后的隐藏序列并行转换成Mel频谱序列。Mel频谱是一种表示音频信号的方式,常用于语音处理领域。
训练:
- 去除了教师-学生蒸馏流程:FastSpeech 2不再依赖从教师模型蒸馏得到的Mel频谱,而是直接使用真实的Mel频谱作为模型训练的目标,这样做可以避免在蒸馏过程中产生的信息损失,并提高语音质量的上限。
- 变异调节器的改进:变异调节器不仅包括音长预测器,还新增了音高和能量预测器。音长预测器使用通过强制对齐得到的音素时长作为训练目标,这比从自回归教师模型的注意力图中提取的音素时长更为准确。新增的音高和能量预测器提供了更多的变化信息,这对于解决文本到语音转换的一对多映射问题非常重要。
- 进一步简化训练流程:为了推进模型向完全端到端系统的发展,FastSpeech 2提出了一个变种FastSpeech 2s,它可以直接从文本生成波形,无需Mel频谱生成(声学模型)和波形生成(声码器)的级联过程。
2.3VARIANCE ADAPTOR
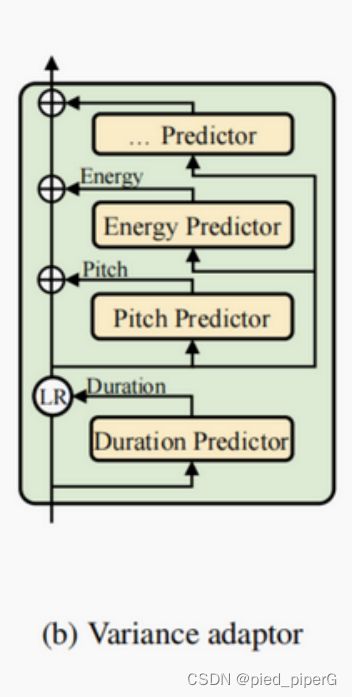
目标:The variance adaptor aims to add variance information to the phoneme hidden sequence, which can provide enough information to predict variant speech for the one-to-many mapping problem in TTS. 添加信息预测,以解决one-to-many problem
添加的信息:
音素时长(Phoneme Duration):它表示语音声音持续的时间长短。音素时长能够指示每个音素对应多少个Mel帧,并且为了便于预测,这个时长会被转换为对数域。
音高(Pitch):音高是传达情感的关键特征,它极大地影响语音的韵律(prosody)。在FastSpeech 2中,为了更好地预测音高轮廓中的变化,使用连续小波变换(CWT)将连续的音高序列分解成音高频谱,然后将这个频谱作为音高预测器的训练目标。
能量(Energy):能量指示了Mel频谱的帧级幅度,直接影响语音的音量和韵律。能量通过计算每个短时傅立叶变换(STFT)帧的振幅的L2范数得到。然后,与音高类似,能量被量化为256个可能的值,并编码成能量嵌入向量,添加到扩展的隐藏序列中。
对于每个信息,设置了相应的predictor:
- 时长预测器:采用两层一维卷积网络,通过ReLU激活函数,后面跟着层正则化和dropout层,以及一个额外的线性层将隐藏状态投影到输出序列。它优化的是均方误差(MSE)损失,以录音中提取的真实时长作为训练目标。
- 音高预测器:预测音高频谱,并在推理时使用逆连续小波变换(iCWT)将其转换回音高轮廓。音高预测器的架构和优化细节在附录D中有详细描述。
- 能量预测器:预测能量的原始值而不是量化值,并且也使用MSE损失进行优化。
使用:
在训练过程中,这些真实的变异信息(时长、音高和能量)被直接输入到隐藏序列中,用于预测目标语音。在推理时,利用预测器预测出的目标值来合成目标语音。通过这样的设计,FastSpeech 2可以更准确地处理音素的持续时间,音高和能量的变化,生成更自然的语音输出。
2.4FastSpeech2s
跳过mel频谱阶段,实现实现了从文本直接生成波形的完全端到端的文本到语音合成的过程
Challenges:
信息差异:波形相比Mel频谱包含了更多的变化信息(例如,相位),这导致输入和输出之间的信息差距比文本到频谱生成时要大。
训练难度:由于波形样本极长,加上GPU内存的限制,很难对整个文本序列对应的音频剪辑进行训练。因此,只能在对应部分文本序列的短音频剪辑上进行训练,这使得模型难以捕捉不同部分文本序列中音素之间的关系,从而影响文本特征的提取。
Method:
对抗训练:由于使用变异预测器难以预测相位信息,FastSpeech 2s引入了对抗训练使波形解码器能够隐式地自行恢复相位信息。
借助Mel频谱解码器:利用FastSpeech 2中训练有素的Mel频谱解码器帮助文本特征提取,尽管在推理阶段不使用Mel频谱解码器。
2.5Discussion
discuss how FastSpeech 2 and 2s differentiate from previous and concurrent works.
非自回归并行生成:与自回归方法如Deep Voice系列和其他一些方法相比,FastSpeech 2和2s使用基于自注意力机制的前馈网络,能够并行生成Mel频谱或波形,提高了合成速度。
更多变化信息输入:FastSpeech 2和2s不仅预测时长,还提供额外的音高和能量信息作为输入,有助于减少输入文本和输出语音之间的信息差距,这在其他一些非自回归声学模型中不常见。
细粒度音高预测:相对于同期的一些工作在音素级别预测音高,FastSpeech 2和2s在帧级别上进行更细粒度的音高预测,使得语音的韵律更加自然。
连续小波变换:为了改善合成语音的韵律,FastSpeech 2和2s引入连续小波变换来建模音高的变化,这是以前的系统没有的功能。
完全非自回归架构:FastSpeech 2s采用完全非自回归的架构,这使得在推理时更加快速,而ClariNet等其他文本到波形模型则是联合训练自回归声学模型和非自回归声码器。
直接文本到波形的转换:与EATS等同时期工作相比,FastSpeech 2s不仅预测时长,还额外提供其他变化信息,以缓解TTS中的一对多映射问题。
与传统声码器的区别:之前的非自回归声码器需要将文本转换为语言或声学特征,FastSpeech 2s则直接从音素序列生成波形,省去了这一转换步骤,这使得FastSpeech 2s成为第一个完全并行的从文本到波形的系统。
3.Experiments and Results
3.1 Experimental Setup
数据集:数使用LJSpeech数据集,包含了约24小时、13,100个英语音频剪辑及其对应的文本转录据集被分为三个部分,12,228个样本用于训练,349个样本(文档标题为LJ003)用于验证,以及523个样本(文档标题为LJ001和LJ002)用于测试。据集被分为三个部分,12,228个样本用于训练,349个样本(文档标题为LJ003)用于验证,以及523个样本(文档标题为LJ001和LJ002)用于测试。
主观评价样本选择:在测试集中随机选择100个样本进行主观评价。
文本到音素转换:为了缓解错发音问题,使用开源的字母转音素工具将文本序列转换为音素序列。
Mel频谱转换:按照Shen等人(2018年)的方法,将原始波形转换为Mel频谱,并设置帧大小和跳跃大小分别为1024和256,这是针对22050的采样率设置的。
模型配置:FastSpeech 2的编码器和Mel频谱解码器都包含4个前馈Transformer(FFT)块。解码器中的输出线性层将隐藏状态转换为80维的Mel频谱,模型使用平均绝对误差(MAE)进行优化。
3.2Results

3.2.1Model Performance
音频质量分析
评估方法:采用平均意见分数(MOS)进行感知质量评估。
评价人群:20名母语为英语的测试者参与,确保评价结果的准确性。
测试条件控制:保持不同系统间文本内容一致,确保评价专注于音频质量。
比较基准:与包括原始录音(GT)、GT Mel + PWG、Tacotron 2、Transformer TTS和FastSpeech等系统进行比较。
结果展示:FastSpeech 2在音质上超过了自回归模型,FastSpeech 2s音质相当于自回归模型。
FastSpeech 2的优势:提供更多变化信息(如音高、能量等),直接使用真实语音作为训练目标,避免教师-学生蒸馏带来的信息损失。
训练和推理速度提升分析
训练时间降低:FastSpeech 2移除了教师-学生蒸馏过程,训练时间相比FastSpeech减少了3.12倍。
训练时间计算标准:仅包括声学模型的训练时间,未包括声码器训练时间。
推理速度提升:FastSpeech 2和2s在波形合成上的推理速度比Transformer TTS模型分别快了47.8倍和51.8倍。
FastSpeech 2s的速度优势:实现了完全端到端的生成,因此比FastSpeech 2有更快的推理速度。
总体来说,FastSpeech 2和FastSpeech 2s在音质和推理速度方面均显示出优异的性能,FastSpeech 2在音质上有明显提升,而FastSpeech 2s则在速度上有显著优势。
3.2.2Analyses on Variance Information
分析Fastspeech2和2s在处理variance information上的表现

Pitch:
统计量计算:计算了音高的标准差(σ)、偏度(γ)和峰度(K),以及与原始语音音高的动态时间规整(DTW)平均距离。
比较结果:FastSpeech 2和FastSpeech 2s生成的音频在统计量(σ、γ和K)方面更接近原始语音,DTW距离也小于其他方法,说明它们在音高轮廓的自然度方面优于FastSpeech。
Energy:
误差计算:计算了合成语音与真实语音之间逐帧能量的平均绝对误差(MAE)。
比较结果:FastSpeech 2和FastSpeech 2s在能量方面的MAE小于FastSpeech,说明它们生成的语音在能量上更接近真实语音。
More Accurate Duration for Model Training:
准确性比较:通过手动对齐教师模型生成的音频与对应文本,获取真实的音素级时长,并计算使用FastSpeech教师模型和MFA(Montreal Forced Alignment)提取的时长之间的绝对边界差异的平均值。
比较结果:MFA提取的时长比FastSpeech教师模型的更准确。
语音质量测试:将FastSpeech中使用的时长(来自教师模型)替换为MFA提取的时长,并进行CMOS(比较平均意见分数)测试,比较两种时长设置下训练的FastSpeech模型的语音质量。
测试结果:使用MFA提取的更准确的时长信息,提高了FastSpeech的语音质量,验证了更准确时长信息的有效性。
3.2.3Ablity Study
消融研究,旨在研究pitch和energy等variance information对模型性能的影响
音高和能量输入的重要性
能量的影响:
- 移除能量导致FastSpeech 2和FastSpeech 2s的语音质量下降(分别为-0.040和-0.160 CMOS),这表明能量是一个有效的信息维度,尤其对FastSpeech 2s更为重要。
音高的影响:
- 移除音高导致FastSpeech 2和FastSpeech 2s的语音质量显著下降(分别为-0.245和-1.130 CMOS),这表明音高信息对于提升语音质量至关重要。
同时移除音高和能量:
- 当同时移除音高和能量时,语音质量进一步下降(FastSpeech 2为-0.370,FastSpeech 2s为-1.355 CMOS),证明音高和能量的结合对于提升FastSpeech 2和FastSpeech 2s的性能是非常有效的。
在频域预测音高的有效性
连续小波变换(CWT):
- 研究使用CWT在频域预测音高的有效性,通过对FastSpeech 2和FastSpeech 2s直接拟合音高轮廓进行了CMOS评估,发现CMOS分别下降了0.185和0.201。
- 通过计算音高的统计量和与真实音高的平均DTW距离,发现使用CWT可以更好地建模音高,改善合成语音的韵律,从而获得更好的CMOS评分。
Mel频谱解码器在FastSpeech 2s中的有效性
文本特征提取:
- 为了验证Mel频谱解码器在FastSpeech 2s中对文本特征提取的有效性,移除了Mel频谱解码器进行了CMOS评估。
- 结果表明移除Mel频谱解码器导致了0.285的CMOS下降,这表明Mel频谱解码器对于高质量波形生成是必不可少的。
4.Conclusion
FastSpeech 2的创新和贡献
简化训练流程:FastSpeech 2直接使用真实的Mel频谱进行模型训练,简化了训练流程,并且与FastSpeech相比避免了信息损失。
提高时长准确性:改进了音素时长的预测准确性,帮助模型更好地处理一对多映射问题。
引入更多变化信息:增加了包括音高和能量在内的变化信息,使得模型能够生成更自然、更富有表现力的语音。
改进音高预测:通过引入连续小波变换(CWT),提高了音高预测的准确性。
FastSpeech 2s的创新和贡献
非自回归文本到波形模型:FastSpeech 2s基于FastSpeech 2进一步发展,实现了非自回归的文本到波形直接生成,享有完全端到端推理的好处,达到了更快的推理速度。
实验结果
模型性能:实验结果表明,FastSpeech 2和FastSpeech 2s在语音质量方面优于FastSpeech,FastSpeech 2甚至能在声音质量上超过自回归模型,同时保持了FastSpeech的快速、稳健和可控的语音合成优势。
未来展望
完全端到端的TTS:虽然FastSpeech 2的质量得益于外部的高性能对齐工具和音高提取工具,未来的工作将寻求更简单的解决方案来实现完全端到端的TTS,不依赖于外部对齐模型和工具。
考虑更多变化信息:未来将考虑引入更多的变化信息,以进一步提升声音质量。
更轻量级的模型:探索更轻量级的模型以加速推理,满足快速、高质量、端到端训练的最终目标。