深入Kafka broker
一、协议设计
- 颗粒度, PRODUCE和FETCH中支持topic,partion等层级的颗粒度;
- 测试友好, 基于session_id和epoch确定一条拉取链路的fetch session;
- 全量增量结合, FetchRequest中的全量拉取和增量拉取;
- 基本结构: header+body。 常见header: api_key, api_version, corelation_id, client_id。与网络协议类似, Kafka本身的协议也是分层读取, header中保留必要的分类和标识信息, body中为具体的消息内容。
request format

response format

二、延时操作
与定时操作的比较
- 都有超时时间, 但延迟操作如果超时时间内没有完成, 则需要强制执行;
- 定时操作通常必须在固定时间段之后执行, 延时操作可以在固定时间点之前执行;
- 为了能够提前完成操作, 延时操作支持提前执行(外部触发);
Kafka使用场景
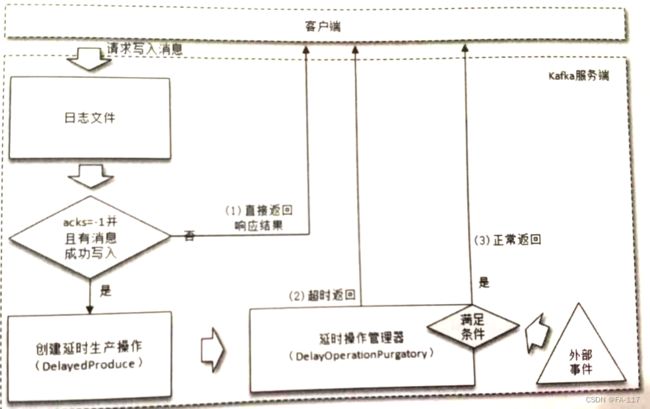
- 延时生产: leader节点完成消息写入之后, 等待所有follower节点同步完成, 然后响应客户端;
- 延时拉取: follower向leader节点拉取数据, 但此时并没有新消息写入, Kafka并不是立即返回, 而是基于延时操作来处理。一来减少空拉取消耗资源, 二来如果在超时时间窗口内有新消息进入, 则可以立刻拉取到, 保证时效性;
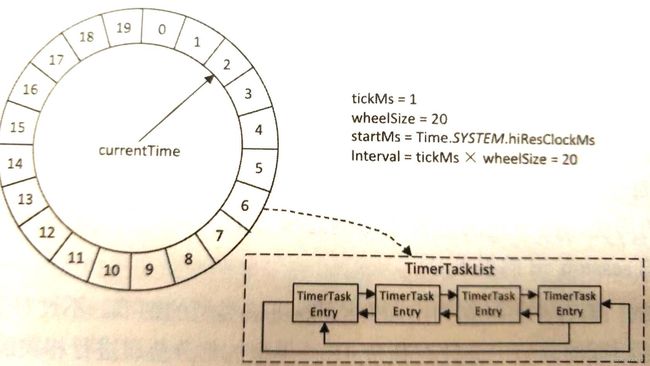
时间轮结构
TimeWheel是一个存储延时任务的环形队列, 底层采用数组实现。数组中的每个元素存放一个定时任务列表(TimerTaskList)。列表本身为环形双向链表, 每个元素为任务项(TimerTaskEntry), 内部封装了定时任务TimerTask。
时间轮(数组)上的每个位置表示相同的时间间隔tickMs, 间隔数量由wheelSize确定, 因此一周代表的时间为tickMs*wheelSize。时间轮还有个表盘指针, currentTime是tickMs的整数倍, 将时间轮划分为到期部分和未到期部分。
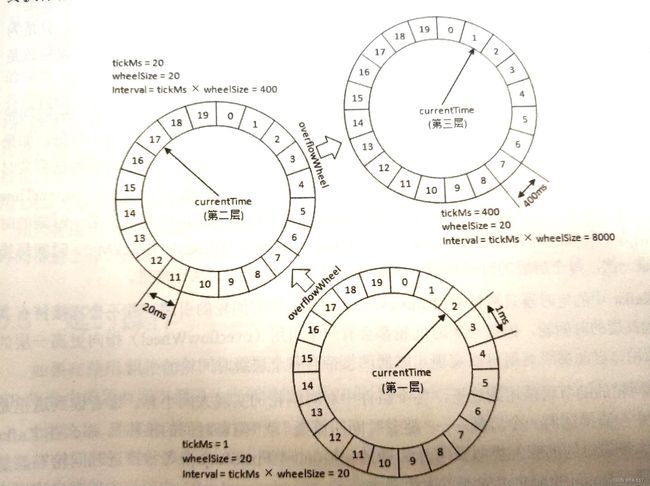
时间轮可以级联。Kafka中基于层级时间轮, 类似钟表的时、分、秒。秒级延迟的任务在秒级轮, 分级任务在分级轮, 时级任务在时级轮。一个时级任务会从一开始在时级轮, 到分级轮, 最后到秒级轮。
在时间推进上, Kafka基于JDK中的DelayQueue。DelayQueue中的元素为, 时间轮上的TimerTaskList。DelayQueue会按照工期时间排序, 最先过期的任务放在最前面。超时任务处理线程, 从DelayQueue中获取过期的TimerTaskList, 然后执行时间轮推进或者执行任务中的超时处理。既降低超时任务添加和删除的复杂度, 又能够做到精准推进(按照超时时间超越推进, 而不是按固定时间步进)。
单轮示意
层级轮示意
延时操作示意
三、组控制器
Kafka有多个broker, 某个broker会被选举为controller, 负责管理所有分区和副本状态。具体包括如下三个方面:
- 当分区leader副本变化时, 由其进行leader副本选举;
- 当分区ISR集合变化时, 由其通知所有的broker更新元数据;
- 当更新Topic分区数量时, 尤其负责分区重分配;
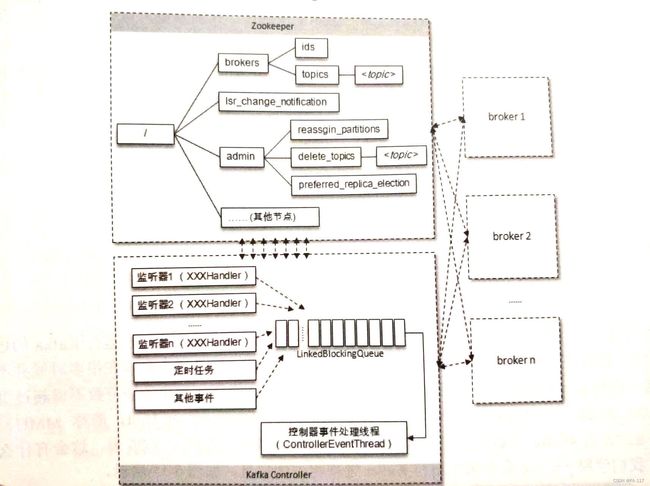
Controller选举和异常恢复
- 基于zookeeper的临时节点/controller, 如果某个broker创建成功, 则该broker成功成为controller。其他失败节点进入状态同步阶段, 设置activieBrokerId。
- 如果该节点异常, 则会进入新一轮的竞争;
- 此外还有一个永久节点/controller_epoch, 记录本轮controller选举的纪元, 用于辅助选举;
Controller职责与zk节点
- topic变化, /brokers/topics, /admin/delete_topics
- partition变化, /admin/ressign_partitions, /isr_change_notification, /admin/prefered-replica-election
- broker变化, /brokers/ids
- 启动分区状态机和副本状态机;
- 更新集群元数据信息;
- 维护分区优先副本选举的均衡;
Controller内部的事件处理模型
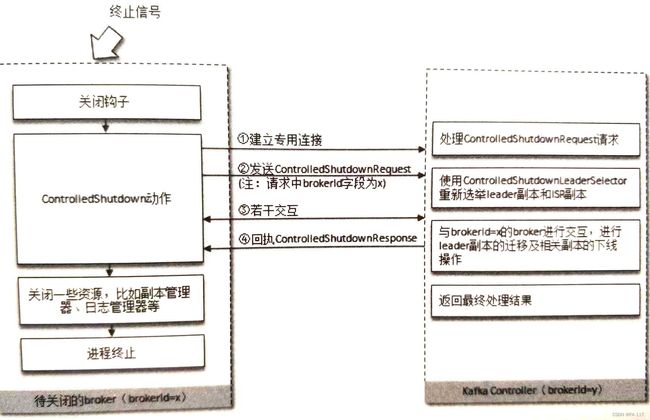
优雅关闭broker
Kafka本身显然是一个有状态依赖的服务, 因此每个组成服务的broker本身会维护一堆的状态。关闭某个运行中的broker节点对集群状态是有影响的。因此集群要能处理两种关闭, 失控关闭和受控关闭。失控关闭比如broker节点被kill -9 或者节点突然掉电, 这种应对方案只能通过关闭前已持久化的信息进行恢复。受控关闭则是在消除对集群本身的影响之后再关闭。
受控关闭示意如下:
分区leader选举
由controller从AR中找到第一个ISR副本作为leader副本。当然, 此处还需要考虑leader副本所在的节点不是一个正在关闭的节点。
小结
本文深入Kafka broker节点内部, 探讨Kafka协议设计,延迟操作和组控制器的设计与实现, 结合之前的存储结构,建立起Kakfa broker的整体结构框架。