EPE-NAS: Efficient Performance Estimation Without Training for Neural Architecture Search(论文精读)
文章目录
- 《EPE-NAS: 高效性能评估无需训练的神经网络结构搜索》
-
- 摘要
- 1 前言
- 2 相关工作
- 3 提出方法(待完善)
- 4 实验
-
- A. `NAS-Bench-201`
- B. 结果和讨论
- 5 总结
《EPE-NAS: 高效性能评估无需训练的神经网络结构搜索》
Paper:https://arxiv.org/abs/2102.08099
代码: www.github.com/VascoLopes/EPENAS
摘要
神经网络结构搜索Neural Architecture Search (NAS) 在计算机视觉领域中模型结构设计方面展现出卓越的效果。NAS通过自动架构设计和工程减轻了人工定义网络的需求。然而,NAS方法往往很慢,因为它们需要大量的GPU计算。这种瓶颈主要是由于模型评估策略,它需要重新训练生成的模型架构,来评估其性能。
本文提出EPE-NAS,一种高效的性能估计策略,缓解了评估网络的耗时问题,通过对未训练的网络进行评分,并创建该评分与模型训练表现的关联性。我们通过查看类内和类间相关性进行未训练的网络进行评估。
我们表明EPE-NAS可以产生鲁棒的关联性并且将其 纳入一个简单的随机变量抽样策略,我们就能够使用单一的GPU在几秒钟内搜索有竞争力的网络,而不需要任何训练。
此外,EPE-NAS与搜索方法无关,而仅仅侧重于对未训练模型的评估,使得它很容易集成到几乎任何NAS方法中。
1 前言
在过去的几年里,深度学习算法已经有广泛的研究,并有效地应用于各种任务以,尤其是与计算机视觉相关的任务。
计算机视觉的巨大成功任务的出现主要归功于卷积神经的出现网络(CNNs),具有鲁棒的特征提取能力以及 不同问题之间的迁移性。不同的CNNs架构已经逐渐被提出,并且逐渐表明CNNs可以通过修改来改进架构本身,添加额外的组件,例如残差连接,以此来减少了参数的数量大小或推理时间。然而, 设计高效的架构是非常耗时的。这需要专业知识和试错。神经网络可以有许多设计选择,例如层组合和序列,每层的参数、架构和训练过程中的优化规则。因此,一种自动进行神经架构的设计的方式是一个自然的选择。
神经架构搜索(NAS)是一种自动的架构工程和设计,目的是为了针对特定问题自动设计出高性能模型结构。NAS解决计算机视觉问题的方法已经成功应用于各种任务,如图像分类、语义分割、目标检测等。
最初,NAS方法都是使用相似的流程设计架构。一个控制器, 使用特定的搜索策略,是最常见的强化学习或进化策略, 在可能的搜索空间中采样一个搜索空间定义架构A,包含可能的操作(例如卷积、池化)和模型结构类型。对生成的模型结构进行评估结果作为奖励给控制器进行更新它的参数。这个过程重复了数千次,控制器随着时间的推移借此学习采样更好的模型结构。这个过程的可视化可参见下图

图1:通用神经架构搜索流程。一个控制器从可能的搜索空间中生成模型结构,然后进行评估,以及它的性能被用作更新控制器的奖励。我们的方法作用于性能估计块,得到未训练的的评估结果。
=======doing
虽然NAS方法已经显示出很好的效果,大多数方法的计算成本都非常高,在某些情况下需要几个月的GPU计算时间。这主要采用的性能估计策略相关,对生成的模型结构 要么是 定期训练从零开始直至收敛 要不就是 部分训练。最近的方法,试图通过共享参数使训练过程更加顺畅,对已经训练好的网络应用突变,或通过使用one-shot NAS,其中控制器生成模型结构和相应的权重。然而,已经出现了一些NAS方法过度拟合搜索空间,由于引入了设计偏差,不允许探索。
为了缓解上述问题,在本文中提出EPE-NAS,一种性能估计策略
在初始化阶段对生成的网络进行评分,无需任何训练。
那么如何对未训练的模型进行评分呢?本文提出 通过 评估 在输入的影响下 模型梯度的变化行为,去除 训练 中生成更新参数的步骤。
该方法速度极快,可在几秒内分析上千个网络。我们证明了该方法由于其快速的推理,可从未训练模型状态中得到训练模型精度,因此可以指导搜索空间的搜索网络训练。
本文所提出的方法可以很容易地集成到几乎任何NAS系统中,通过完全替代性能估计策略,或者通过创建多重评估来补充策略。
将该方法融入采用随机搜索策略可来证明这一点,最终在数秒内实现有竞争力的搜索结果。
本文的主要贡献可以概括为如下:
-
本文提出一种新的性能估计策略,能够评估未训练的模型 训练后的性能,这样可以很容易地集成到几乎任何NAS的方法。
-
我们分析了所提出方法的影响,在结合随机搜索的情况下,可以实现几秒钟就的得到具有竞争力的模型结构。
-
将所提出的方法与不同的NAS进行比较方法,以及在NAS-Bench-201中的替代性能。
-
所提出的方法在无需训练模型的情况下进行搜索,可快速分析模型结构,让表现不好的的候选模型结构被淘汰,具体是通过分析score与训练时的模型性能的关系来实现这一点。
2 相关工作
通常,NAS方法 使用 “样本-评估-更新” 方案 来自动设计最优CNNs 结构,其中控制器生成模型结构,并使用生成的模型性能进行更新。问题是评估生成的模型结构是非常昂贵的。
Zoph和Le最初将NAS作为强化学习问题,控制器经过长时间的训练采样更高效的架构。问题是方法需要超过60年的GPU计算才能将所有生成的模型结构训练收敛。
在后续工作中,作者通过在具有13个操作的搜索空间中执行基于 cell 搜索来解决这个问题。通过重点设计两种类型cells :正常cell (执行卷积操作)和 简化 cell(简化输入尺寸),作者可以将GPU计算量减少到2000天。此外,他们发现在CIFAR-10中基于 cell 的搜索架构 可以通过堆叠更多的cell 数据迁移到ImageNet数据集上。该方法训练了超过20000个模型结构并进行评估和评估。
与最初的强化学习的方法类似,另外有人提出了MetaQNN,一种基于强化学习和Q-leraning 的方法, 学习agent 被训练成顺序采样CNN层。
使用类似的强化学习方法,BlockQNN专注于对所使用的操作块进行采样形成完整的网络。然而,BlockQNN仍然需要96 GPU天的计算。
ENAS使用控制器,使用策略梯度进行训练,以发现由在大规模计算节点图中寻找最优子图。通过构建一个规模可观的计算图,其中每个子图表示一个网络,ENAS强制所有生成模型结构共享其参数。这样,高效搜索使用GPU计算在不到一个天内即可实现。
DARTS,是一种基于的梯度方法,通过由于搜索空间是连续的,因此对模型结构使用梯度下降进行了优化。提出了一种双层梯度优化,联合学习模型结构以及模型权重,需要数天GPU的计算。这篇文章为其他许多one-shot方法提供了基础。
另外有研究通过引入诱导正则化机制提高DARTS生成的体系结构性能。
同样使用可微的方法,GDAS是一种进行搜索的方法过程可微,以便子图从表示搜索空间的有向无环图中被采样,它可以进行端到端的训练,以采样高效的网络。GDAS的控制器基于 训练采样模型结构 的验证损失进行优化。
SETN同样使用可微的方法,它允许对网络进行选择性采样,会训练评估器预测每个模型结构的损失较低的概率。
**REA,**与强化学习或基于梯度的方法不同,重点介绍了进化锦标赛选择算法,具有年龄属性,对较新的模型结构更友好。
为缓解性能估计策略的瓶颈,一些替代方法也被提出用部分训练,或者学习一个HyperNet,并基于该超网络结构生成权重。此外BOBH,重点是超参数优化,其中包括架构设计,通过贝叶斯优化和bandit-based方法。然而,设计CIFAR-10的最优网络仍然需要33 天GPU计算量。
我们的工作不同于前面提到的,而是更接近NAS-WOT,因为我们的重点是评估生成的网络,不需要任何训练,也不需要性能估计策略,也不为生成网络。因此,在有效的时间内创建一个score可关联未训练的模型 和其训练后的模型性能。
3 提出方法(待完善)
本文提出EPE-NAS,一种新的性能估计策略,其目标是无需任何训练评估性能生成网络,并不为生成网络也无需关注性能估计。
为此,我们对未训练的网络进行评分,指标为训练时的准确性。
论文基于NASWOT的思想,关于论文NASWOT,请参考以下博客,写的超赞!!!
论文精读:Neural Architecture Search without Training
NASWOT 指出不同的网络 可以通过评估 局部线性算子的在不同数据点的行为来比较。
每层的ReLU 乘 线性特征得到 局部线性算子。我们可以定义一个线性特性
然后,线性特征如下所示:

为了评估网络对于数据点在不同情况下的行为,我们为不同的数据点计算雅可比矩阵
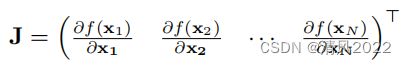
雅可比矩阵 J 包含关于的网络输出相对于输入的几个数据点的信息。
然后,我们可以计算哪些点属于相同的类相互关联,这正是我们的目标,看看未训练网络是否能够建模复杂的问题功能。
显然,一个灵活的网络应该满足不仅 可区分每个数据点的局部线性算子,而且对于相似的数据点在有监督的方法中 也有相似的结果 ,表示数据点的归属于同一个类别。
最理想的情况是不同数据之间 是低相关性的,同一类别的数据点则更接近,这意味着网络很容易在训练过程中学习区分两个数据点。

每个独立的相关矩阵可以分析,未训练网络对每个类的表现如何,表示局部线性算子感知类别之间的差异的能力。
允许在不同的个体关系矩阵之间进行比较,因为它们可能具有不同的大小 由于每个类别的数据点,它们是单独的评估:
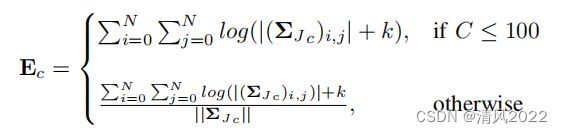

其中E是包含所有相关矩阵的向量分数。中的类的数量批处理时,最终得分是单个相关矩阵得分的和或归一化的成对差异。
归一化可以缓解类间差异评估具有大量类别的数据集中的网络和噪音。
4 实验
在三个数据集上评估了EPE-NAS的有效性:
CIFAR-10
CIFAR-100
来自NAS-Bench-201的ImageNet16-120,
使用的批处理大小为256。
提出的方法为一个不需要任何训练的性能估计策略。
我们还通过将EPE-NAS与 随机搜索策略相结合来评估,其中一个候选网络是从搜索空间中随机产生的,并使用提出的性能估计方法打分,而不是训练网络。这个评估是针对不同的样本大小进行的N个网络。
所有实验都是在台式计算机上进行,具有一个1080Ti GPU和32GB ram。
在以下几节中,我们对NAS-Bench-201进行评测,并分别详细介绍了实验,给出了实验结果讨论。
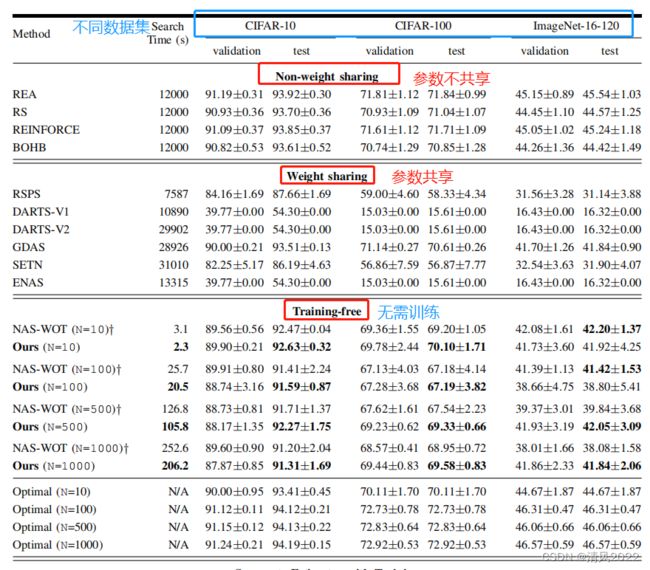
表格1:
在NAS-Bench-201 benchmark上的不同搜索方法实验结果;
不同数据集: CIFAR-10, CIFAR-100 and ImageNet-16-120;
不同方法:不共享参数, 共享参数,无需训练方法,SVM作为评估代理;
搜索时间为使用一个 1080Ti GPU上的时间,当需要训练时,包含训练时间;
A. NAS-Bench-201
相比之下,NAS方法相比其他方法往往很难复现,包括在实际搜索空间进行性能评估。搜索空间增大结导致 可能的网络数量增加,使用需要训练的性能估计策略使得全面评估NAS方法的性能变得非常困难,最终结果是使用整个搜索空间的子集进行评估(搜索空间中的数千个网络最终可以是无限的)。因此平滑的将共同训练程序迁移和设置变得至关重要。
最近,NAS benchmarks被提出,其中目标是有一个可控的设置,其中提供了在搜索空间下网络的训练和最终性能的相关信息,允许快速搜索不同NAS方法的原型设计 ,以及使用相同的训练程序和hyper参数与其他NAS方法进行比较。
在本文中,我们使用NAS-Bench-201来评估所提出的方法。
NAS-Bench-201提供在三个不同数据集上的训练网络信息:
– CIFAR-10
– CIFAR-100
– ImageNet16-120
包括 在其约束下的 固定分割,同时提供几种NAS方法的结果,可以直接比较。
在这个基准测试中,目标是设计基于单元的架构,其中每个单元由6条边和4个节点。所有节点组成。所有的节点都从上述所有节点接收一条输入边。
边表示可能性操作,从5个操作中选择:
(1)Zeroize,将信息归零,
(2)跳过连接,
(3)1×1卷积,
(4)3×3卷积,
(5)3×3average pooling layer
可能的操作和边的数量意味着有 56 = 15625个可能的单元。
最后的网络由固定的 骨架组成,其中一个单元网络中的一个复制块,意味着有多少单元就有多少网络,因为唯一的变化要复制的单元。
B. 结果和讨论
首先,我们评估了所提方法的有效性。
通过从NAS-Bench-201每个数据集中随机抽样1000个网络,并对它们进行评分,看看它们之间的相关性分数和网络在训练时的表现。
图3

如图3所示,
第一张图表示CIFAR-10
第二张图表示CIFAR-100
第三个到张图表示imagenet16-120
在左边,可以看到由EPE-NAS给出的分数和网络训练后的准确性 的强关联。
这验证了所提出的方法,未训练网络的score越高,表明其性能就越好,反之则表面性能越差。
由此,也可以通过定义阈值来看出这一点,
例如在CIFAR-10中2 × 104,我们可以高效地淘汰不合格的候选网络,这在基于进化算法中是最重要的,在进化算法中可以使用这种方法用于从生成的网络池中选择最佳网络,服务于产生下一个进化的迭代。
另外,也可直接评估哪种网络配置更好,这些信息也可用于指导大搜索空间的搜索。
这一点很重要,是因为大搜索空间搜索网络,可能是无界的,是极其困难 且容易收敛到局部最小值,主要原因是由于缺乏初始采样的最佳网络。
然后,通过将EPE-NAS与随机搜索策略相结合,我们可以与其他NAS方法相比,验证 简单搜索策略与所提出的性能估计相结合 的有效性。
为了进行这个实验,随机产生一个网络,在不训练的情况下我们通过对网络进行评分来评估其性能。
这个设置不需要训练,我们可以执行不同的样本大小(N,其中N表示评估模型的数量)。
表一显示了EPE-NAS的结果并与几种方法进行了比较。
第一块中显示执行搜索而不共享权重的方法;
第二块中显示权重共享方法;
第三块中,是本文结果为所提出的方法,并直接与NAS-WOT进行对比,同时也展示本文方法和NAS-WOT时的最优网络;
在最后一个块中,我们展示了一个基于在支持向量机(SVM)上基线的方法。
SVM方法如下:
SVM是由100个网络的性能信息训练的代理网络。
SVM的输入是通过计算单个相关系数生成的矩阵,然后计算这个矩阵特征值。
训练100个网络的需要4.16 的GPU计算。在完成SVM训练时,不需要进一步训练任何网络,因为可以基于未训练网络,使用SVM相关矩阵推断性能。
从这个表中,可以看出本文的方法所需的搜索时间减少了几个数量级,相比非权重共享 和 权重共享会减少了大量的搜索时间开销。
我们的方法在所有数据集上都取得了比 权重共享更好的结果,除了GDAS在CIFAR-10和CIFAR-100上的结果。然而,我们的方法速度快了12500倍以上。
非权重共享方法优于我们的方法(随机搜索与所提出的性能估计相结合策略),但我们的方法仍然与它们相媲美,能够在所有数据集中取得有竞争力的结果。
作为与NAS-WOT的直接比较,
如表1所示实验结果表明,所提方法的性能优于NAS-WOT
无论是在推理方面,本文方法在所有环境中都更快
在准确性方面,能够选择高性能CIFAR-10和CIFAR-100中的网络样本大小分别为10和100,以及CIFAR-10和CIFAR-100和ImageNet-16-120,更高的样本大小(500和1000)。
重要的是要注意NAS-WOT随着样本大小增加,它越来越受到噪声的影响,选择的网络精度与最优之间的差距增加,与小样本相比降低了性能。
我们的方法正好相反。随着随着样本量的增加,我们的方法有能力在不损失精度的情况下选择具有较高的性能的网络。这也非常重要,因为优化网络是不可能的存在于小样本中。如果更多关注ImageNet-16-120,由于图像的原因,这个数据集有更多的噪声尺寸(16 × 16)和高类别数,我们的方法与 无权值共享方法 和NAS-WOT相比,可以选择获得优秀测试精度的网络。
从表1的第二列可以看出,我们的方法的执行时间是一个很大的优势,事实也是如此,能够在206秒内评估1000个网络。
从图2中可以进一步看到相比NAS-WOT 在执行时间方面的收益,随着batch size越来越大,得到两种方法在得分方面的表现。
图2
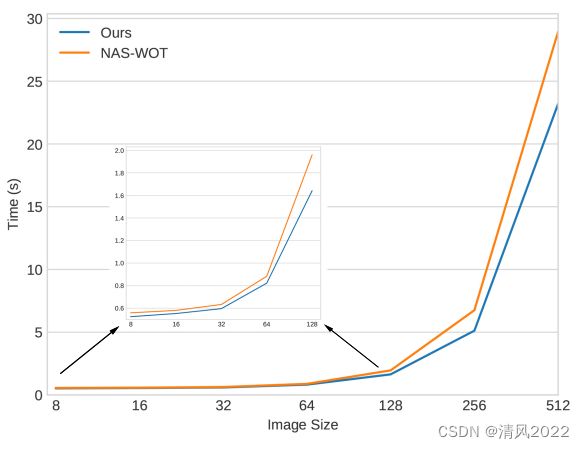
这个评估表明所提出的方法始终优于NAS-WOT,它能够在5秒内评价大小为256∗256∗3英寸的图像,这意味着所提出的方法也可以作为当前NAS方法的改进,当前的NAS由于CIFAR-10图像尺寸较小,只搜索基于该数据的网络,然后将最佳网络迁移到ImageNet设置。因此,NAS方法由于时间复杂度,无法使用更大的数据集进行搜索,这一点可以使用用EPE-NAS做到,即直接在更大的数据集中搜索网络。
所提出的方法在时间上能够超过NAS-WOT的原因是,时间和直接创建相关矩阵的时间相关,对数据点和特征的数量高度依赖。通过评估个体的相关矩阵,每个类别一个,为了更快的计算我们减小了每个相关矩阵的大小。
如表1,考虑到我们的方法评估1000个网络所需的平均时间,EPE-NAS还允许对搜索空间进行彻底的探索,所提出的方法能够评估超过100万个架构,仅需要2天的GPU计算天数。
因此, 该方法可以用来评估搜索空间的行为,给出关于如何开始和继续搜索方法的信息,当考虑较大的,可能无界的搜索空间,其shape信息是有限的。
该方法的一个重要性质是它可以很容易地合并到几乎任何NAS方法中,要么作为评估网络的唯一方法,要么作为互补方法进行混合训练,更新控制器参数的奖励(图1)是一个互补评估的组合(例如,EPE-NAS分数结合网络在移动端的的推理/延迟。此外,EPE-NAS相比 搜索方法,由于它侧重于评估网络,是对依赖的搜索方法的完美补充关于生成网络或指导搜索的信息,可以在几秒内分析数千个网络。
5 总结
本文提出EPE-NAS,一种性能估计策略,以较高的分数对未训练的网络进行评分与训练表现的相关性。对于其输入通过利用关于网络输出梯度的信息,可以准确地推断 生成的网络是否足够好,可以在不到一秒钟的时间评估数千个网络。
此外,在这项工作中,我们已经表明使用简单随机搜索与所提出的估计相结合策略,它可以在几秒内采样高性能的网络,这可以超过许多当前的NAS方法。
我们的建议也有助于允许NAS方法通过提供一种高效的方法来搜索较大的搜索空间
提取生成网络的信息需要任何训练和大型数据库作为我们的方法即使在图像尺寸很大的情况下,仍然非常快。此外,所提出的方法与搜索无关的策略,允许它集成到几乎任何NAS中方法。