【分布式】搭建springboot + mybatis-plus + druid + sharding-jdbc实现分库分表
【分布式】sharding-jdbc实现分库分表
目录
- 【分布式】sharding-jdbc实现分库分表
-
- 1. 简介
- 2. 数据库准备
-
- 2.1 创建数据库test
- 2.2 创建数据库订单表order
- 3. 搭建springboot+mybatis-plus+sharding-jdbc+druid工程
-
- 3.1 引入maven依赖
- 3.2 实体类
- 3.3 mapper层(mybatis-plus)
- 3.4 启动类
- 4. sharding-jdbc配置单库分表
-
- 4.1 application.yml详细配置单库分表
- 4.2 测试单库分表结果
- 5. sharding-jdbc配置分库分表操作
-
- 5.1 application.yml详细配置分库分表
- 5.2 测试分库分表结果
1. 简介
sharding-jdbc 是轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。
它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。更多详细可以参考官网:sharding-jdbc官网
本文记录 搭建 spring boot + mybatis-plus + druid + sharding-jdbc 实现水平分库分表操作
对mybatis-plus有所需要的,可以看往期文章:SpringBoot集成Mybatis-Plus框架
2. 数据库准备
数据库准备:创建数据库 和 表,为后面的做准备
实现单库分表:一个数据库 db1 + 两个相同结构的表1 表2
实现分库分表:两个数据库 db1 db2 + 每个数据库分别创建两个相同结构的表1 表2
2.1 创建数据库test
创建两个数据库 test、test2
-- 数据库 test
CREATE DATABASE IF NOT EXISTS test DEFAULT CHARACTER SET utf8 ;
-- 数据库 test2
CREATE DATABASE IF NOT EXISTS test2 DEFAULT CHARACTER SET utf8 ;
2.2 创建数据库订单表order
创建两个订单表,数据结构保持一致 t_order_1、t_order_2,两个数据库都需要创建,为后面的分库分表做准备
-- 指定使用数据库
USE test; -- USE test2
-- 创建数据库订单表 order1
DROP TABLE IF EXISTS `t_order_1`;
CREATE TABLE `t_order_1` (
`order_id` bigint(20) NOT NULL COMMENT '主键',
`order_name` varchar(50) DEFAULT NULL COMMENT '订单名称',
`order_type` varchar(50) DEFAULT NULL COMMENT '订单类型',
`order_desc` varchar(200) DEFAULT NULL COMMENT '订单详情',
`create_user_id` int(10) DEFAULT NULL COMMENT '创建人',
`create_user_name` varchar(50) DEFAULT NULL COMMENT '创建人姓名',
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '创建时间',
PRIMARY KEY (`order_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- 创建数据库订单表 order2
DROP TABLE IF EXISTS `t_order_2`;
CREATE TABLE `t_order_2` (
`order_id` bigint(20) NOT NULL COMMENT '主键',
`order_name` varchar(50) DEFAULT NULL COMMENT '订单名称',
`order_type` varchar(50) DEFAULT NULL COMMENT '订单类型',
`order_desc` varchar(200) DEFAULT NULL COMMENT '订单详情',
`create_user_id` int(10) DEFAULT NULL COMMENT '创建人',
`create_user_name` varchar(50) DEFAULT NULL COMMENT '创建人姓名',
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '创建时间',
PRIMARY KEY (`order_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
3. 搭建springboot+mybatis-plus+sharding-jdbc+druid工程
3.1 引入maven依赖
springboot+mybatis-plus+sharding-jdbc+druid
<properties>
<sharding-jdbc-version>4.1.1sharding-jdbc-version>
properties>
<parent>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-parentartifactId>
<version>2.2.4.RELEASEversion>
parent>
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-aopartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-testartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-actuatorartifactId>
dependency>
<dependency>
<groupId>com.baomidougroupId>
<artifactId>mybatis-plus-boot-starterartifactId>
<version>3.3.2version>
dependency>
<dependency>
<groupId>org.apache.shardingspheregroupId>
<artifactId>sharding-jdbc-spring-boot-starterartifactId>
<version>${sharding-jdbc-version}version>
dependency>
<dependency>
<groupId>org.apache.shardingspheregroupId>
<artifactId>sharding-jdbc-spring-namespaceartifactId>
<version>${sharding-jdbc-version}version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>druid-spring-boot-starterartifactId>
<version>1.2.8version>
dependency>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>fastjsonartifactId>
<version>1.2.73version>
dependency>
<dependency>
<groupId>com.github.javafakergroupId>
<artifactId>javafakerartifactId>
<version>1.0.2version>
dependency>
dependencies>
3.2 实体类
@TableName(value = “t_order”) 配置数据库表逻辑表名(t_order),而不是物理表名(t_order_1 | t_order_2)
/**
* @description
* 订单表 模型
* @author TianwYam
* @date 2021年10月9日下午9:07:10
*/
@Data
@Builder
@TableName(value = "t_order")
public class Order {
// 订单ID
@TableId("order_id")
private Long orderId ;
// 订单名称
private String orderName ;
// 订单类型
private String orderType ;
// 订单详情描述
private String orderDesc ;
// 创建人
private int createUserId ;
// 创建人姓名
private String createUserName;
// 创建时间
// JSON输出格式
@JSONField(format = "yyyy年MM月dd日 HH:mm:ss")
private Date createTime ;
}
3.3 mapper层(mybatis-plus)
mapper层继承 BaseMapper 就可以对表 t_order 进行CRUD操作,而不需要编写XML文件
@Repository
public interface IOrderMapper extends BaseMapper<Order>{
}
3.4 启动类
@SpringBootApplication
@MapperScan("com.tianya.springboot.shardingjdbc.mapper")
public class LearnShardingJdbcApplication {
public static void main(String[] args) {
SpringApplication.run(LearnShardingJdbcApplication.class, args);
}
}
4. sharding-jdbc配置单库分表
配置 单库分表,我们采用数据库 test 及 表 t_order_1、t_order_2 来实现
分表规则:
- 当 订单表order_id是奇数,就存放在 t_order_2 表中
- 当 订单表order_id是偶数,就存放在 t_order_1 表中
表达式:数据表序号 = ${order_id % 2 + 1}
4.1 application.yml详细配置单库分表
# 单库分表 配置
spring:
shardingsphere:
datasource:
# 配置数据库名称 相当于给数据源取别名(可以配置多个库,以逗号隔开)
names: db1
# 配置具体数据库连接信息
db1:
type: com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.cj.jdbc.Driver
# 配置 数据库 test
url: jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=utf-8&useSSL=true&serverTimezone=UTC
username: root
password: mysql
# 分片策略
sharding:
# 配置不同表的 分片策略
tables:
# 配置 具体的 逻辑表的 分片策略
t_order:
# t_order 订单表的 主键规则
keyGenerator:
# 主键列
column: order_id
# 主键生成规则 (SNOWFLAKE 雪花算法 生成分布式唯一ID)
type: SNOWFLAKE
# 配置 t_order 订单表的 具体数据库物理表的映射关系 表达式
actualDataNodes: db1.t_order_$->{1..2}
# 表策略
tableStrategy:
inline:
# 分片列
sharding-column: order_id
# 分片规则 表达式(映射到具体的物理表 )
algorithm-expression: t_order_$->{order_id % 2 + 1}
# 配置是否打印SQL
props:
sql.show: true
# 解决一个bean映射到多张表问题
main:
allow-bean-definition-overriding: true
实际数据库物理表的映射关系:
表达式:db1.t_order_$ ->{1…2},$ 是个变量,取值来源于后面的{},1…2表示在1和2之间选择
分片规则 表达式:
表达式:t_order_$ ->{order_id % 2 + 1},分片表具体的表名 t_order__ 取决于 {order_id % 2 + 1}
4.2 测试单库分表结果
编写测试用例
/**
* @description
* 测试类
* @author TianwYam
* @date 2021年10月9日下午9:10:08
*/
@SpringBootTest
public class OrderMapperTest {
@Autowired
private IOrderMapper orderMapper ;
/**
* @description
* 随机插入
* @author TianwYam
* @date 2021年10月10日下午3:59:37
*/
@Test
public void insertOrder() {
Faker faker = new Faker(Locale.SIMPLIFIED_CHINESE);
long currentTimeMillis = System.currentTimeMillis();
Random random = new Random();
for (int i = 1; i <= 10; i++) {
int nextInt = random.nextInt(500000000);
Order order = Order.builder()
.orderName("订单应用类型:" + faker.app().name())
.orderType("网购订单")
.orderDesc("买了款应用:" + faker.app().name() + " 的VIP会员")
.createUserName(faker.name().fullName())
.createUserId(i)
.createTime(new Date(currentTimeMillis + nextInt))
.build();
orderMapper.insert(order);
}
}
}
随机插入 10条订单信息表数据,sharding-jdbc会根据设置的主键生成规则(雪花算法) 生成主键 order_id,然后sharding-jdbc会根据主键 order_id 分片规则(奇数偶数)判断映射到具体数据库表中,执行插入操作
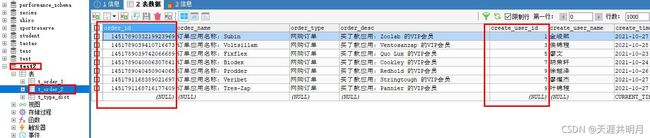
t_order_1 插入数据情况:(订单ID为偶数)

t_order_2 插入数据情况:(订单ID全部为奇数)

可以看出 t_order_1 里面存放的是 order_id 为偶数的订单信息,t_order_2 里面存放的是 order_id 为奇数的订单信息,是按照我们配置的分片规则进行分表操作的
5. sharding-jdbc配置分库分表操作
分库,我们采用数据库 test 、test2 (多个数据库都行)
分表,我们使用 表 t_order_1、t_order_2 来实现(每个数据库内又采用分表策略)
分库规则:
当用户主键 create_user_id为奇数,就存放在库 test2(db2) 里面
当用户主键 create_user_id为偶数,就存放在库 test(db1) 里面
分表规则:
当 订单表order_id是奇数,就存放在 t_order_2 表中
当 订单表order_id是偶数,就存放在 t_order_1 表中
表达式:
数据库序号 = ${create_user_id % 2 + 1}
数据表序号 = ${order_id % 2 + 1}
5.1 application.yml详细配置分库分表
# 分库分表 配置
spring:
shardingsphere:
datasource:
# 配置数据库名称
names: db1,db2
# 配置具体数据库连接信息
db1:
type: com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=utf-8&useSSL=true&serverTimezone=UTC
username: root
password: mysql
db2:
type: com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/test2?useUnicode=true&characterEncoding=utf-8&useSSL=true&serverTimezone=UTC
username: root
password: mysql
sharding:
tables:
# 配置多个逻辑表
t_order:
# 配置 主键 列、及类型
keyGenerator:
column: order_id
type: SNOWFLAKE
# 配置 数据库 表规则
actualDataNodes: db$->{1..2}.t_order_$->{1..2}
# 分库策略(具体某张表的)
databaseStrategy:
inline:
shardingColumn: create_user_id
algorithmExpression: db$->{create_user_id % 2 + 1}
# 分表策略
tableStrategy:
inline:
sharding-column: order_id
algorithm-expression: t_order_$->{order_id % 2 + 1}
# 默认的 分库策略(针对所有表)
#defaultDatabaseStrategy:
# inline:
# shardingColumn: create_user_id
# algorithmExpression: db$->{create_user_id % 2 + 1}
# 配置默认数据源
defaultDataSourceName: db1
# 配置 是否打印SQL
props:
sql.show: true
# 解决一个bean映射到多张表问题
main:
allow-bean-definition-overriding: true
5.2 测试分库分表结果
执行测试插入的用例
/**
* @description
* 随机插入
* @author TianwYam
* @date 2021年10月10日下午3:59:37
*/
@Test
public void insertOrder() {
Faker faker = new Faker(Locale.SIMPLIFIED_CHINESE);
long currentTimeMillis = System.currentTimeMillis();
Random random = new Random();
for (int i = 1; i <= 10; i++) {
int nextInt = random.nextInt(500000000);
Order order = Order.builder()
.orderName("订单应用名称:" + faker.app().name())
.orderType("网购订单")
.orderDesc("买了款应用:" + faker.app().name() + " 的VIP会员")
.createUserName(faker.name().fullName())
.createUserId(i)
.createTime(new Date(currentTimeMillis + nextInt))
.build();
orderMapper.insert(order);
}
}
随机插入 10条订单信息表数据,sharding-jdbc先会根据分库规则(创建人 create_user_id 奇数偶数)确定具体数据库,然后根据设置的分表规则的表主键生成规则(雪花算法) 生成主键 order_id,然后sharding-jdbc会根据主键 order_id 分片规则(奇数偶数)判断映射到具体数据表中,执行插入操作
数据库db1(test):创建用户ID都是偶数
t_order_1 插入数据情况:(订单ID都是偶数,创建用户ID都是偶数)

t_order_2 插入数据情况:(订单ID都是奇数,创建用户ID都是偶数)

数据库db2(test2):创建用户ID都是奇数
t_order_1 插入数据情况:(订单ID都是偶数,创建用户ID都是奇数)

t_order_2 插入数据情况:(订单ID都是奇数,创建用户ID都是奇数)