Parallel Computing 并行计算相关学习
参考资料
https://hpc.llnl.gov/documentation/tutorials
https://hpc.llnl.gov/documentation/tutorials/introduction-parallel-computing-tutorial
https://hpc-tutorials.llnl.gov/openmp/
https://www.openmp.org/
Parallel Computing 并行计算
并行计算的基本概念、用途、概念和术语、并行存储体系结构和编程模型等主题。
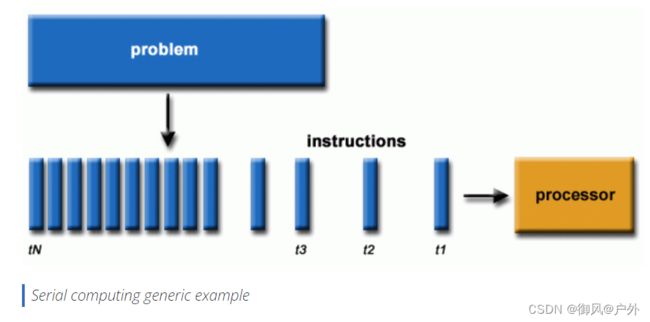
Serial Computing 串行计算:
Parallel computing 并行计算:
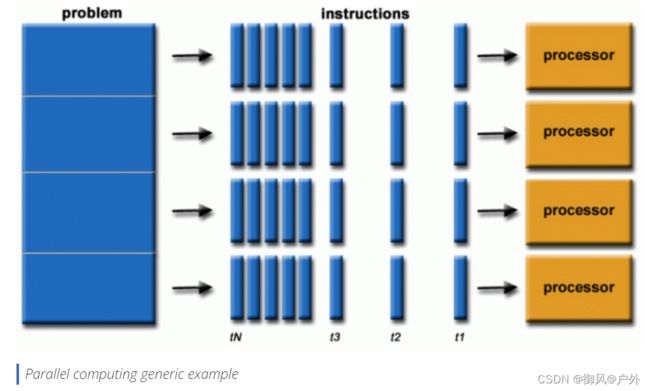
问题可被分解为可并行的离散工作片段。
有多个计算资源:单台机器的多核,多台计算机。
Parallel Computers 并行计算机
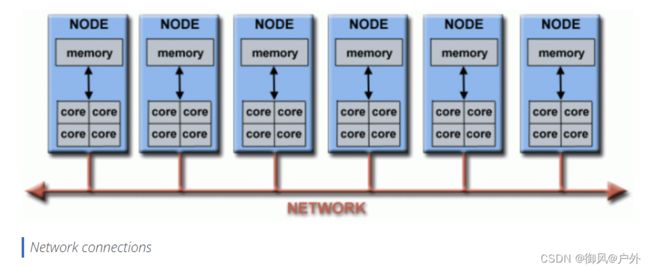
下面的示意图展示了一个典型的LLNL并行计算机集群:
每个计算节点本身就是一个多处理器的并行计算机
多个计算节点通过Infiniband网络连接在一起
还有用于其他目的的专用节点,同样是多处理器的

更好地利用底层并行硬件
现代计算机,甚至是笔记本电脑,都采用多核心的并行体系结构。
并行软件专门设计用于支持多核心、多线程等并行硬件。
在大多数情况下,串行程序在现代计算机上运行会“浪费”潜在的计算能力。
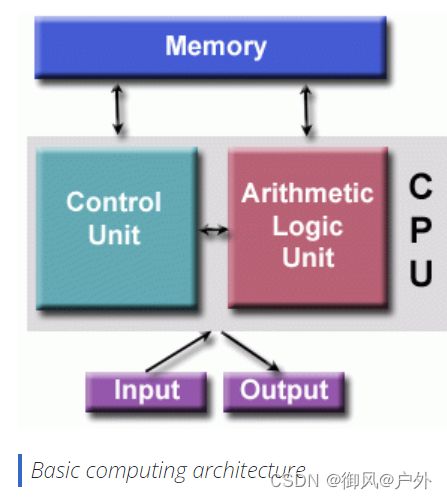
冯·诺依曼体系结构以匈牙利数学家约翰·冯·诺伊曼(John von Neumann)的名字命名
“存储程序计算机” - 程序指令和数据都存储在电子内存中。
并行计算机仍然遵循这一基本设计。
弗林经典分类法Flynn’s Classical Taxonomy
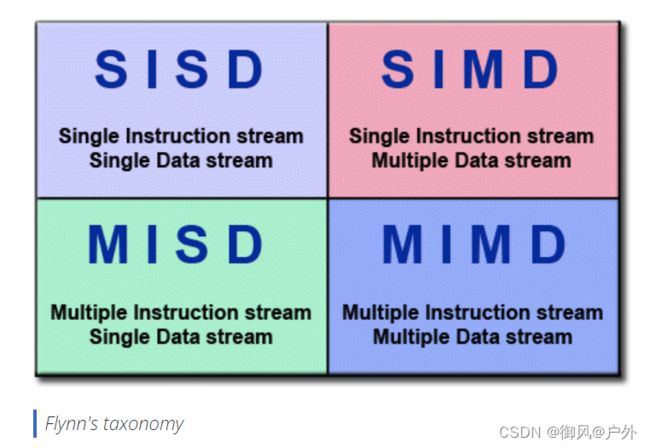
单指令流单数据流(SISD)
串行(非并行)计算机
单一指令:在任何时钟周期内 CPU 只执行一个指令流
单一数据:在任何时钟周期内只使用一个数据流作为输入
确定性执行Deterministic execution

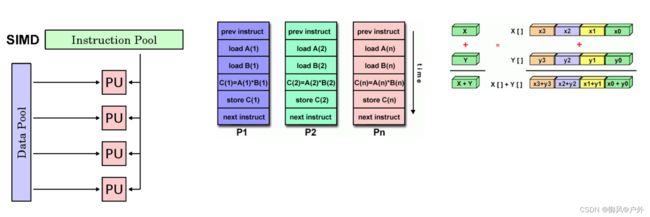
单指令流多数据流(SIMD)
一种并行计算机类型
单一指令:所有处理单元在任何给定时钟周期内执行相同的指令
多数据:每个处理单元可以操作不同的数据元素
最适用于具有高度规律性的专业问题,如图形/图像处理。
同步(锁步)和确定性执行
两种变体:处理器阵列和矢量流水线
示例:
处理器阵列:Thinking Machines CM-2,MasPar MP-1 和 MP-2,ILLIAC IV
矢量流水线:IBM 9000,Cray X-MP,Y-MP 和 C90,Fujitsu VP,NEC SX-2,Hitachi S820,ETA10
大多数现代计算机,特别是那些配备图形处理器单元(GPU)的计算机使用 SIMD 指令和执行单元。
多指令流单数据流(MISD)
一种并行计算机类型
多指令:每个处理单元通过独立的指令流独立地操作数据。
单一数据:单个数据流被馈送到多个处理单元。
这一类并行计算机几乎没有实际的例子(如果有的话)。
一些可行的用途可能包括:
多个频率滤波器对单一信号流的操作
多个密码算法尝试破解单一的编码消息。

多指令流多数据流(MIMD)
一种并行计算机类型
多指令:每个处理器可以执行不同的指令流
多数据:每个处理器可以使用不同的数据流
执行可以是同步的或异步的,确定性的或非确定性的
目前,最常见的并行计算机类型 - 大多数现代超级计算机属于这一类。
例子:大多数现代超级计算机,网络化的并行计算机集群和“网格”,多处理器SMP计算机,多核PC。
注意:许多MIMD架构还包括SIMD执行子组件。

并行计算的一般术语
与其他领域一样,并行计算有其自己的术语。以下列出了与并行计算相关的一些常用术语。这些术语中的大多数将在后面进行更详细的讨论。
-
CPU
当代CPU由一个或多个核心组成 - 具有自己的指令流的独立执行单元。具有CPU的核心可以组织成一个或多个插槽 - 每个插槽具有自己独立的内存。当CPU由两个或更多插槽组成时,通常硬件基础设施支持在插槽之间共享内存。 -
节点 Node
一个独立的“盒中计算机”。通常由多个CPU/处理器/核心、内存、网络接口等组成。节点通过网络连接在一起,构成一个超级计算机。 -
任务 Task
计算工作的逻辑上离散的部分。任务通常是一个程序或类似程序的一组指令,由处理器执行。并行程序由在多个处理器上运行的多个任务组成。 -
流水线处理Pipelining
将任务分解为由不同处理单元执行的步骤,输入通过这些步骤流动,类似于流水线装配线;这是一种并行计算的类型。 -
共享内存 Shared Memory
描述所有处理器都可以直接访问共同物理内存的计算机体系结构。在编程意义上,它描述了一个模型,其中并行任务都有对内存相同“图像”的看法,可以直接寻址和访问相同的逻辑内存位置,而不考虑物理内存实际存在的位置。 -
对称多处理器(SMP)Symmetric Multi-Processor
多处理器共享内存的硬件体系结构,多个处理器共享单一地址空间,并平等访问所有资源 - 内存、磁盘等。 -
分布式内存 Distributed Memory
在硬件上,指的是基于网络的内存访问,物理内存不是共享的。作为一种编程模型,任务只能逻辑上“看到”本地机器内存,并且必须使用通信来访问在其他机器上执行其他任务的内存。 -
通信 Communications
并行任务通常需要交换数据。有几种方法可以实现这一点,例如通过共享内存总线或通过网络。 -
同步 Synchronization
并行任务的实时协调,通常与通信相关。
同步通常涉及至少一个任务的等待,因此可能导致并行应用的挂钟执行时间增加。
-
计算颗粒度Computational Granularity
在并行计算中,颗粒度是计算与通信的比率的定量或定性度量。
粗颗粒度:在通信事件之间执行相对较大数量的计算工作
细颗粒度:在通信事件之间执行相对较小数量的计算工作 -
观察到的加速比Observed Speedup
已经并行化的代码的观察到的加速比,定义为:串行执行的挂钟时间 ---------------------- 并行执行的挂钟时间
是衡量并行程序性能的最简单和最广泛使用的指标之一。
-
并行开销 Parallel Overhead
唯一与并行任务相关的执行时间,而不是用于执行有用工作的时间。并行开销可能包括以下因素:
任务启动时间
同步
数据通信
由并行语言、库、操作系统等引起的软件开销
任务终止时间 -
大规模并行 Massively Parallel
指的是构成给定并行系统的硬件 - 具有许多处理单元。 “许多”的含义不断增加,但目前,最大的并行计算机由数十万到数百万个处理单元组成。 -
尴尬地(理想地)并行 Embarrassingly (IDEALY) Parallel
同时解决许多相似但独立的任务;任务之间几乎不需要协调。 -
可伸缩性 Scalability
指的是并行系统(硬件和/或软件)在添加更多资源时能够呈现与并行加速成比例的能力。影响可伸缩性的因素包括:
硬件 - 特别是内存-CPU带宽和网络通信性质
应用算法
与并行开销相关的因素
您特定应用程序的特性
潜在的并行编程收益、限制和成本
阿姆达尔定律 Amdahl’s Law:潜在的程序加速取决于可并行化的代码部分(P)的比例。



其中 P = 可并行部分占比,N = 处理器数量,S = 串行部分占比。
数据量增大时,往往增加了可并行部分P的占比。
API的标准化,如MPI、OpenMP和POSIX线程
MPI(Message Passing Interface)、OpenMP和POSIX线程都是与并行计算相关的编程接口,用于实现并行化的程序设计。
-
MPI(Message Passing Interface):
- 定义: MPI是一种消息传递编程模型,用于在分布式内存系统中进行并行编程。它定义了一组库函数,允许多个进程之间相互通信和协作,通常在集群或超级计算机上使用。
- 工作原理: MPI允许进程通过发送和接收消息来进行通信,它提供了点对点通信和集体通信的功能,使得多个进程能够协同解决问题。
- 应用: 主要用于在不同计算节点上的并行任务之间进行通信,适用于大规模、高性能的并行计算。
-
OpenMP(Open Multi-Processing):
- 定义: OpenMP是一套用于共享内存系统的编程接口,旨在简化并行程序的编写。它通过在程序中插入编译器指导性语句(pragma)来实现并行化。
- 工作原理: OpenMP使用指导性语句来标识哪些部分的代码可以并行执行。通过在循环、函数等区域添加pragma,编译器可以生成并行化的代码。
- 应用: 适用于共享内存系统,如多核处理器和共享内存计算机。它使得简单的并行任务可以更容易地实现,提高了编写并行程序的便利性。
-
POSIX线程(Pthreads):
- 定义: POSIX线程是一种标准的多线程编程接口,用于在同一进程内实现多线程并行。POSIX是IEEE为操作系统提供标准的工作组,而Pthreads是该标准中与线程相关的部分。
- 工作原理: Pthreads提供了创建、同步、互斥等多线程操作的函数。它允许程序员创建多个执行线程,这些线程可以并行执行,共享进程的资源。
- 应用: 适用于多线程编程,可以在单一进程内的多个线程之间共享数据和资源。常用于需要更细粒度的并行性的应用程序。
这些接口可以根据应用程序的需求选择合适的并行编程模型。MPI主要用于分布式内存系统的通信,OpenMP适用于共享内存系统的简单并行化,而POSIX线程则用于在单一进程内实现多线程并行。
共享内存
总体特征:
共享内存并行计算机有很大的变化,但通常都具有所有处理器都能访问所有内存作为全局地址空间的能力。
多个处理器可以独立运行,但共享相同的内存资源。
由一个处理器引起的内存位置的更改对所有其他处理器都是可见的。
从历史上看,共享内存机器被分为UMA和NUMA两类,基于内存访问时间。
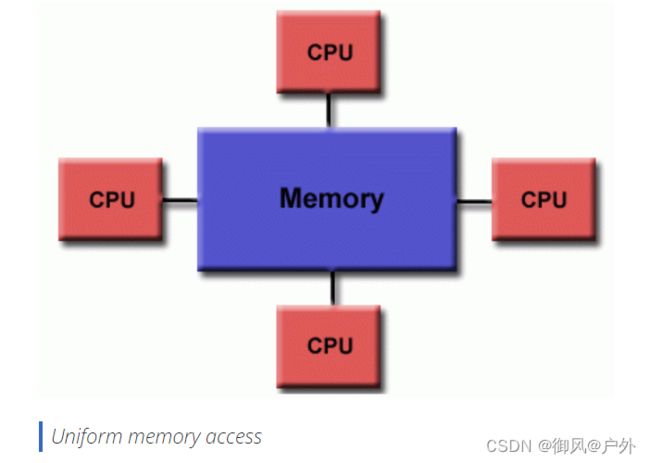
统一内存访问(UMA)Uniform Memory Access
今天最常见的是对称多处理器(SMP)机器
相同的处理器
对内存的访问和访问时间相同
有时称为CC-UMA - 缓存一致的UMA。缓存一致意味着如果一个处理器更新共享内存中的位置,所有其他处理器都会知道更新。缓存一致性是在硬件层面完成的。
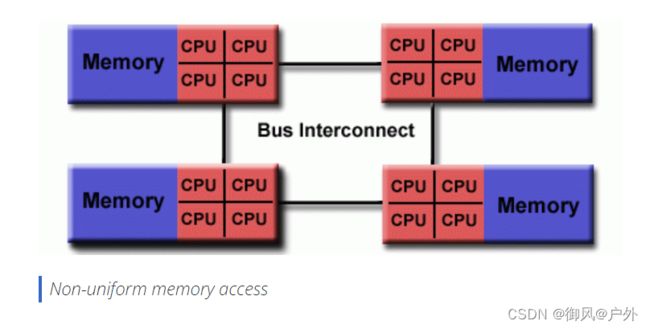
非统一内存访问(NUMA)Non-Uniform Memory Access
通常由两个或多个SMP物理连接而成
一个SMP可以直接访问另一个SMP的内存
并非所有处理器对所有内存的访问时间都相同
跨链路的内存访问速度较慢
如果保持缓存一致性,也可以称为CC-NUMA - 缓存一致的NUMA
分布式内存
总体特征
与共享内存系统一样,分布式内存系统差异很大,但共享一个共同的特点。分布式内存系统需要一个通信网络来连接处理器间的内存。
处理器有自己的本地内存。一个处理器的内存地址不能映射到另一个处理器,因此在所有处理器之间没有全局地址空间的概念。
由于每个处理器都有自己的本地内存,它可以独立运行。它对本地内存的更改对其他处理器的内存没有影响。因此,缓存一致性的概念不适用。
当一个处理器需要访问另一个处理器的数据时,通常由程序员明确定义数据如何以及何时进行通信。任务之间的同步也是程序员的责任。
用于数据传输的网络“结构”各异,尽管可以简单到以太网。
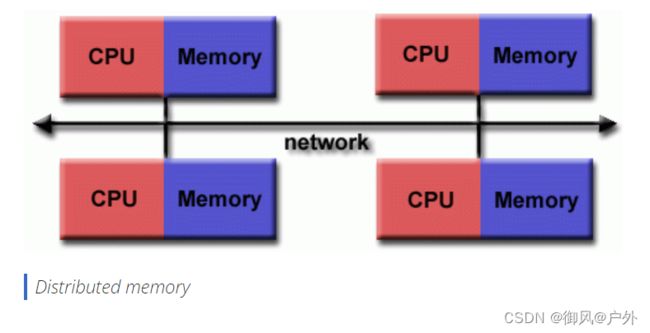
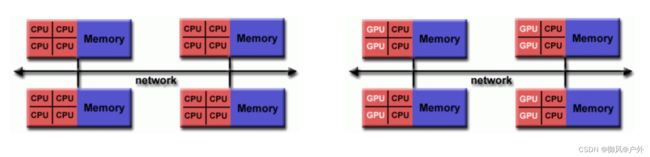
混合分布式-共享内存Hybrid Distributed-Shared Memory
并行编程模型Parallel Programming Models
- 目前有几种常见的并行编程模型:
- 共享内存(无线程)
- 线程
- 分布式内存 / 消息传递
- 数据并行
- 混合
- 单程序多数据(SPMD)
- 多程序多数据(MPMD)
- 并行编程模型存在于硬件和内存架构之上的抽象层。
- 尽管这可能并不明显,但这些模型并不特定于特定类型的机器或内存架构。实际上,任何这些模型都可以(理论上)在任何底层硬件上实现。
POSIX线程
- 由IEEE POSIX 1003.1c标准(1995年)规定。仅限C语言。
- 是Unix/Linux操作系统的一部分。
- 基于库
- 通常称为Pthreads。
- 非常显式的并行性;需要程序员对细节进行大量关注。
POSIX Threads tutorial: hpc.llnl.gov/sites/default/files/2019.08.21.TAU_.pdf
OpenMP
- 行业标准,由一组主要的计算机硬件和软件供应商、组织和个人共同定义和支持。
- 基于编译器指令
- 可移植 / 多平台,包括Unix和Windows平台
- 在C/C++和Fortran实现中可用
- 可以非常简单易用 - 提供“渐进式并行性”。可以从串行代码开始。
- 其他线程实现也很常见,但这里不讨论:
- Microsoft线程
- Java、Python线程
- 用于GPU的CUDA线程
OpenMP tutorial: hpc-tutorials.llnl.gov/openmp/
分布式内存 / 消息传递模型Distributed Memory / Message Passing Model
MPI规范 http://www.mpi-forum.org/docs/
Message Passing Interface (MPI) 是消息传递的“事实上的”行业标准。
MPI tutorial: hpc-tutorials.llnl.gov/mpi/

数据并行模型Data Parallel Model
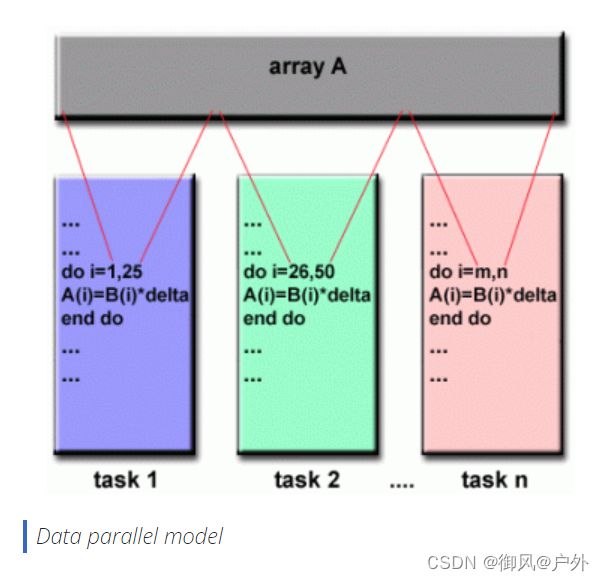
- 也可能被称为Partitioned Global Address Space分区全局地址空间(PGAS)模型。
- 数据并行模型展示了以下特征:
- 地址空间被视为全局
- 大多数并行工作集中在对数据集执行操作上。数据集通常组织成一个共同的结构,如数组或立方体。
- 一组任务共同在相同的数据结构上工作,但是每个任务在相同数据结构的不同分区上工作。
- 任务在其工作分区上执行相同的操作,例如“对每个数组元素加4”。
- 在共享内存架构中,所有任务都可以通过全局内存访问数据结构。
- 在分布式内存架构中,全局数据结构可以在逻辑上和/或物理上分布在任务之间。
实现:
- 目前,有几种并行编程实现处于不同开发阶段,基于数据并行/PGAS模型。
- Coarray Fortran:Fortran 95的一小组扩展,用于SPMD并行编程。依赖于编译器。更多信息:https://en.wikipedia.org/wiki/Coarray_Fortran
- Unified Parallel C(UPC):C编程语言的扩展,用于SPMD并行编程。依赖于编译器。更多信息:https://upc.lbl.gov/
- 全局数组:在分布式数组数据结构的上下文中提供共享内存风格的编程环境。具有C和Fortran77绑定的公有领域库。更多信息:https://en.wikipedia.org/wiki/Global_Arrays
- X10:由IBM在Thomas J. Watson研究中心开发的基于PGAS的并行编程语言。更多信息:http://x10-lang.org/
- Chapel:由Cray领导的开源并行编程语言项目。更多信息:http://chapel.cray.com/
混合模型

-
将消息传递模型(MPI)与线程模型(OpenMP)结合使用。
线程使用本地的、节点上的数据执行计算密集型内核
不同节点上的进程之间的通信通过MPI在网络上进行
这种混合模型非常适用于目前最流行的硬件环境,即集群化的多/多核机器。 -
使用MPI与CPU-GPU(图形处理单元)编程。
MPI任务在CPU上使用本地内存运行,并通过网络与彼此通信。
计算密集型内核被卸载到节点上的GPU上。
节点本地内存和GPU之间的数据交换使用CUDA(或类似的东西)。 -
其他混合模型也很常见:
- MPI与Pthreads
- MPI与非GPU加速器
SPMD和MPMD
单程序多数据(SPMD)
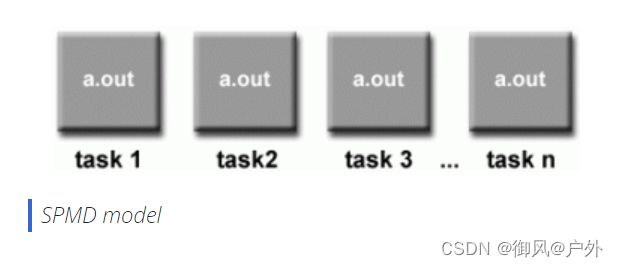
多程序多数据(MPMD)

自动并行化与手动并行化
用于自动并行化串行程序的最常见类型的工具是:并行编译器、预处理器。
完全自动
- 编译器分析源代码并识别并行性的机会。
- 该分析包括识别并行性的抑制因素,以及并行性是否实际上会提高性能的成本权衡。
- 循环(do、for)是自动并行化最频繁的目标。
程序员指导 - 使用“编译器指令”或可能是编译器标志,程序员明确告诉编译器如何并行化代码。
- 可能还可以与某些程度的自动并行化结合使用。
- 最常见的编译器生成的并行化是使用节点上的共享内存和线程(如OpenMP)完成的。
- 如果您从现有的串行代码开始并且有时间或预算限制,那么自动并行化可能是一个答案。然而,自动并行化有几个重要的警告:
- 可能会产生错误的结果
- 性能实际上可能会下降
- 比手动并行化灵活性差得多
- 仅限于代码的子集(主要是循环)
- 如果编译器分析表明存在抑制因素或代码太复杂,实际上可能不会并行化代码
- 本节的其余部分适用于手动开发并行代码的方法。
理解问题和程序Understand the Problem and the Program
Programs = algorithms + data + (hardware)
调试Debugging
- 调试器:
- 线程 - pthreads 和 OpenMP
- MPI
- GPU / 加速器
- 混合
- Livermore Computing 用户可以访问安装在 LC 集群上的几个并行调试工具:
- RogueWave Software 的 TotalView
- Allinea 的 DDT
- 英特尔的 Inspector
- 堆栈跟踪分析工具(STAT)Stack Trace Analysis Tool- 在 LLNL 本地开发
- 所有这些工具都有与之相关的学习曲线。
- 有关详细信息和入门信息,请参见:
- LC 的网页:hpc.llnl.gov/software/development-environment-software
- TotalView 教程:hpc.llnl.gov/documentation/tutorials/totalview-tutorial
性能分析与调优Performance Analysis and Tuning
- Livermore Computing LC 系统上安装的工具:
- LC 的网页,网址为 https://hpc.llnl.gov/software/development-environment-software
- TAU:http://www.cs.uoregon.edu/research/tau/docs.php
- HPCToolkit:http://hpctoolkit.org/documentation.html
- Open|Speedshop:https://www.openspeedshop.org/
- Vampir / Vampirtrace:http://vampir.eu/
- Valgrind:http://valgrind.org/
- PAPI:http://icl.cs.utk.edu/papi/
- mpiP:http://mpip.sourceforge.net/
- memP:http://memp.sourceforge.net/