【Python】内置 方法、语法 合集
| Python YYDS |
本篇博客记录python各大内置方法以及常见语法,查漏补缺用,环境始终基于python3。
——持续更新ing
各大内置方法合集
- 一、面向数据类型
- id(a)
- a.copy()
- ord(ch)
- chr(d)
- hex(d)
- int(ch)
- list(str)
- str.join(l)
- str.split(ch) & str.partition(ch)
- 二、面向列表
- 列表常用语法
- 切片
- l.index(v)
- l.reverse()
- l.remove(v) & l.insert(i, v) & l.count(v) & l.pop(i) & l.append(v) & l1.extend(l2) & l.clear:
- l.sort() & sorted(l)
- (1)sorted(l,key=lambda x:x[key_str])
- (2)sorted(l,key=lambda x:x[i])
- min(l) & max(l)
- set(l)
- enumerate(l)
- 三、面向字符和字符串
- str.isupper() & str.islower() & str.isnumeric() & str.isalpha()
- str.rjust(width,chr_fill) & str.ljust(width,chr_fill)
- str.encode(way) & str.decode(way)
- ——b'xxxx'与'xxxx'的区别:
- ——b'xxxx'与'xxxx'的相互转化:
- str1.strip(str2)
- str.format(d)
- str.replace(str_old,str_new,times)
- str.title()
- str.lower()
- str.upper()
- 四、面向文件读写
- open(path,m) & file.close()
- 关于文件路径
- file.read(n)
- 五、面向字典
- 1.添加键值对
- 2.删除键值对
- 3.遍历字典
- 4.创建字典
- 5.清空字典
- 6.字典转列表
- 7.字典排序
- 8.dict.get(key, default=None)
- 六、import
- 1. A.py和B.py在同一文件夹下
- 2. A.py和B.py在不同文件夹下
- 七、lambda
- 八、其他函数
- [1] map(function,list/str/tuple)
- [2] isinstance(variable,type)
- [3] assert
- [4] round()
- 九、运算符
- 十、`if __name__ == '__main__':`
针对本博客形参命名的相关说明:
- a:任意类型的变量
- ch:字符变量
- d:数据变量
- str & str_开头的:字符串变量
- v:列表某个元素的值
- i & j:列表某个元素的下标
- k:步长
- l:列表变量
- way:代表编码方式的字符串
- file:文件对象
- path:文件路径
- m:读写模式
- dict:字典变量
- key_str:键字串
一、面向数据类型
id(a)
python所有的对象包含的三个基本要素,分别是:
id(身份标识)、type(数据类型)和value(值)。
获取变量的id(下面的id值仅供参考,这个id相当于地址,所以在不同电脑,不同程序中运行结果可能不一样),我们用is运算符本质上是比较id值,在本篇博客的运算符模块下会详述。
>>>a=4
>>>id(a)
2583558121840
a.copy()
在python中,数据有两种类型:mutable(可变) 和 immutable (不可变)。对于inmutable object,函数参数传递是值,对于mutable object,函数参数传递是指针。
list ,dict是mutable的;int , string , float ,tuple是inmutable的。
而.copy方法的一个很大用处就是,如果我们传入函数的形参是一个mutable型变量,那么我们需要先用.copy方法拷贝一份,之后的操作在备份上进行,这样便不会破坏原始数据。
.copy并不相当于给一个新的变量赋值,因为单纯把一个初始化的变量赋值给另一个变量时,对该两个变量的修改对另一个变量都有效,本质上这两个变量的id都是一样的(也就是说指针都指向一个内存单元),只不过两个不同的名字,如果不理解可以看下面的案例:
>>> a=[1,2,3,4,5]
>>> b=a
>>> b[0]=9
>>> b
[9, 2, 3, 4, 5]
>>> a
[9, 2, 3, 4, 5]
>>>#------------------------对比一下-----------------------
>>> a=[1,2,3,4,5]
>>> b=a.copy()
>>> b[0]=9
>>> b
[9, 2, 3, 4, 5]
>>> a
[1, 2, 3, 4, 5]
ord(ch)
将字符ch转为Unicode编码并返回,仅支持一个字符
>>> ord('我')
25105
>>> ord('A')
65
>>> ord('AB')
Traceback (most recent call last):
File "" , line 1, in <module>
TypeError: ord() expected a character, but string of length 2 found
chr(d)
将ASCII码值d转为对应的字母并返回,参数必须是整数。
>>> chr(65)
'A'
hex(d)
转化成对应16进制字符串
>>>hex(12) #将参数转化成16进制并以字符串形式表示
'0xc'
int(ch)
转化成对应十进制数据
>>>int('12')#字符串形式的十进制数直接转化成int型
12
>>>int('0x12',16)#字符串形式的16进制数需要额外指定base为16
18
list(str)
返回一个列表,参数多为字符串,list(a)等价于[i for i in a]
>>>a = 'abcd efg'
>>>b = list(a) #字符串列表化
>>>c=[i for i in a]
>>>d=list(('a', 'b', 'c', 'd', ' ', 'e', 'f', 'g'))
>>> print(b)
['a', 'b', 'c', 'd', ' ', 'e', 'f', 'g']
>>> print(c)
['a', 'b', 'c', 'd', ' ', 'e', 'f', 'g']
>>> print(d)
['a', 'b', 'c', 'd', ' ', 'e', 'f', 'g']
str.join(l)
把列表l的元素拼接成字符串放到str字符串的末尾
>>>a=['a','b','c']
>>>b = ''.join(a) #列表字符串化
>>>> print(b)
abc
str.split(ch) & str.partition(ch)
以ch字符或者字符串为界限划分字符串str,转化成列表(不连同ch在内)
>>> a='abc abc'
>>> b=a.split(' ')
>>> print(b)
['abc', 'abc']
>>> c=a.split('a')
>>> print(c)
['', 'bc ', 'bc']
以ch字符或者字符串为界限划分字符串str,转化成三元元组(连同ch在内),第一个是ch左边的字串,第二个是ch本身,第三个是ch右边的字串
>>> a=a='abc abc abc'
>>> b=a.partition(' ')
>>>print(b)
('abc', ' ', 'abc abc')
二、面向列表
列表常用语法
1. v in l:
返回true:如果列表l中有元素v
返回false:如果没有元素v
2. v not in l:
返回true:如果列表l中没有元素v
返回false:如果有元素v
3. l1 + l2:
将列表l1和列表l2连接起来。
4. l * n or n * l:
将列表s重复n次
5. a,b,c=l
用列表给变量赋值
>>> l=[1,2,3]
>>> a,b,c=l
>>> a
1
>>> b
2
>>> c
3
6. l.sort(*, key = None, reverse = False):
对s中的元素进行排序,用比较符号'<',如果元素是不可比较的会发生错误。reverse为True时,用比较符号'>'。
7. l.index(v[, i[, j]):
返回l列表中第一个v的下标位置(或者下标为i和j之间,第一个v出现的位置的下标)
8. l[0],l[1]=l[1],l[0]
交换两个元素的位置
9. l.insert
切片
-
l[i:j]:
截取下标从i到j的那部分,包括i不包括j -
del l[i:j]:
删除列表l中i到j之间的元素。类似于l[i:j] = [] -
l[i:j:k]:
截取下标从i到j的那部分,但是每一步跨越k个。 -
l1[i:j] = l2:
用l2替换列表l1中从i到j之间的元素。
>>> a=[1,2,3,4,5,6]
>>> b=[7,8,9,0]
>>> a[1:1]=b
>>> print(a)
[1, 7, 8, 9, 0, 2, 3, 4, 5, 6]
- l1[i:j:k] = l2:
用l2中的元素代替列表l1中从i开始,步长尾k,直到j之间的元素。
l.index(v)
获取列表l中元素v的下标,索引返回第一个符合的下标值。
>>> a=['a','b','c','a']
>>> b=a.index('a')
>>> print(b)
0
l.reverse()
用于把列表l中元素倒置,它不返回任何值,不传入任何参数
>>> a=[1,2,3,4,5,6]
>>> a.reverse()
>>> print(a)
[6, 5, 4, 3, 2, 1]
l.remove(v) & l.insert(i, v) & l.count(v) & l.pop(i) & l.append(v) & l1.extend(l2) & l.clear:
- l.remove(v):删除列表
l中的第一个v元素 - l.insert(i, v):在下标为
i的元素前面插入值v,即l[i:i] = [v] - l.count(v):返回列表
l中元素v的数目 - l.pop(i):返回第
i个位置的元素,并将该元素从l中删除 - l.append(v):向列表
l的尾部追加元v,类似于l[len(l) : len(l)] = [v] - l1.extend(l2):相当于
l1+=l2 - l.clear:清空
l的所有元素,类似于del l[:]
>>> a=[1,2,3,2,4,5]
>>> a.count(2)
2
>>> a.remove(2)
>>> print(a)
[1, 3, 2, 4, 5]
>>> a.insert(1,11)
>>> print(a)
[1, 11, 3, 2, 4, 5]
>> a.pop(1)
11
>>print(a)
[1, 3, 2, 4, 5]
>>>b=[6,7,8]
>>>a.extend(b)
>>>print(a)
[1, 3, 2, 4, 5, 6, 7, 8]
>>>a.clear()
>>>print(a)
[]
l.sort() & sorted(l)
两个都是给列表排序,但有所不同,仔细观察下面的几个代码片。
- l.sort():对
l这个列表进行修改
>>> a=[1,3,2,5,4,6,8,7]
>>> b=a[:] #a和b两个变量指向不同列表,对b修改不影响a(分片传入)
>>> b.sort()
>>> print(a)
[1, 3, 2, 5, 4, 6, 8, 7]
>>> print(b)
[1, 2, 3, 4, 5, 6, 7, 8]
>>> a=[1,3,2,5,4,6,8,7]
>>> b=a #a和b两个变量指向同一个列表,对b修改即为对a修改
>>> b.sort()
>>> print(a)
[1, 2, 3, 4, 5, 6, 7, 8]
>>> print(b)
[1, 2, 3, 4, 5, 6, 7, 8]
sorted(l):对l修改后返回新的列表,原传入的列表参数值不变
>>> a=[1,3,2,5,4,6,8,7]
>>> b=sorted(a)
>>> print(b)
[1, 2, 3, 4, 5, 6, 7, 8]
>>> print(a)
[1, 3, 2, 5, 4, 6, 8, 7]#a的值是不变的
(1)sorted(l,key=lambda x:x[key_str])
这个是对列表元素为字典(key-value:键值对)时的排序,需要指定按哪个key排序
>>> list_1=[{'name':'a','age':20},{'name':'b','age':30},{'name':'c','age':25}]
>>> sorted(list_1,key=lambda x:x['age']) #直接指定键是什么
[{'name': 'a', 'age': 20}, {'name': 'c', 'age': 25}, {'name': 'b', 'age': 30}]
(2)sorted(l,key=lambda x:x[i])
这个是对列表元素为元组时的排序,需要指定第几个元素参与排序。
>>> listA=[('q',2),('c',3),('y',1)]
>>> sorted(listA,key=lambda x:x[-1])#指定每个元组元素的第二个(最后一个)元素参与排序
[('y', 1), ('q', 2), ('c', 3)]
min(l) & max(l)
返回列表l中最小值和最大值
>>> a=[1,2,3,4,5,6]
>>> min(a)
1
>>> max(a)
6
set(l)
取出列表l中唯一的元素并组成一个新的集合并返回
>>> list=['a','a','b','c']
>>> set(list)
{'c', 'b', 'a'}
enumerate(l)
用于获取列表元素及对应的索引值,但返回的并不是一个字典之类,而是一个对象
list=['E','m','0','s','_','E','r','1','t']
for index,column in enumerate(list):
print(index,column)
#输出:
0 E
1 m
2 0
3 s
4 _
5 E
6 r
7 1
8 t
三、面向字符和字符串
字符串同样也是满足切片的。
str.isupper() & str.islower() & str.isnumeric() & str.isalpha()
判断字符串str的大小写
>>>str='abcd'
>>>str.isupper() #检测字符串中所有的字母是否都为大写。如果字符串中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True,否则返回False
False
>>>str.islower() #检测字符串中所有的字母是否都为小写。如果字符串中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True,否则返回 False
True
>>> str.isalpha() #判断是否全是字母
True
>>> str.isnumeric() #判断是否全是数字
False
>>> str='a1bd'
>>> str.isalpha()
False
>>> str.isnumeric()
False
str.rjust(width,chr_fill) & str.ljust(width,chr_fill)
将str长度扩充至width,如果用rjust就右对齐,如果用ljust就左对齐,然后空下来的部分用chr_fill字符串变量填补,得到一个新的字符串并返回,而不对原始str做出改变。
注意:
- 如果没有给
chr_fill传入值就默认填入空格; chr_fill参数必须是字符或长度为1的字符串,否则会报错- 当字符串本身的长度大于或等于参数
width的值时,rjust()方法返回原字符串。
>>> str1="m0s_Er1"
>>> str2=str1.rjust(len(str1)+1,"E")
>>> str2
'Em0s_Er1'
>>> str3=str2.ljust(len(str2)+1,"t")
>>> str3
'Em0s_Er1t'
>>> str1
'm0s_Er1'
>>>str1='bc'
>>>str1.ljust(50,'d')
'bcdddddddddddddddddddddddddddddddddddddddddddddddd'
>>>str1.rjust(50,'a')
'aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaabc'
str.encode(way) & str.decode(way)
返回用way的方式编码/解码str后的值。
——b’xxxx’与’xxxx’的区别:
有的时候我们发现一些字符串在经过一些函数处理后输出来的值是
b'xxxx'格式的,这是由于编码不同,b'xxxx'代表字符是以字节为单位的形式输出的,'xxxx'则是代表字符串以unicode编码的方式输出,有的时候如果要在网络上传输,或保存在磁盘上就需要把str变成以字节为单位的bytes。——b’xxxx’与’xxxx’的相互转化:
>>> 'Em0s_Er1t'.encode('ascii') b'Em0s_Er1t' >> b'Em0s_Er1t'.decode() #无参数时默认以unicode的方式编码 'Em0s_Er1t' >> b'Em0s_Er1t'.decode('utf-8') 'Em0s_Er1t'
str1.strip(str2)
对于str1的头尾,将包含在字符串str2中的连续字符删除。
>>> str1='123321452136782231'
>>> str2='123'
>>> str1=str1.strip(str2)
>>> print(str1)
45213678
其实就相当于下面的代码。
str1='123321452136782231'
str2='123'
for i in (l:=list(str1)):
if l[0] in str2:
del l[0]
if l[-1] in str2:
del l[-1]
str1=''.join(l)
print(str1) #45213678
str.format(d)
格式控制字符串
>>> "Em0s_Erit is {} {}".format('a','student')
'Em0s_Erit is a student'
>>> "Em0s_Erit is a {0}".format('student')
'Em0s_Erit is a student'
>>> "Em0s_Erit is {0}-year-old".format(19)
'Em0s_Erit is 19-year-old'
>>> "Em0s_Erit is a {0}-year-old {1}".format(19,'student')
'Em0s_Erit is a 19-year-old student'
>>> "Em0s_Erit is a {age}-year-old {job}".format(age=19,job='student')
'Em0s_Erit is a 19-year-old student'
#用一对大括号实现大括号转义
>>> "{{Em0s_Er1t}}{}".format("Em0s_Er1t")
'{Em0s_Er1t}Em0s_Er1t'
可以用于保留小数点位数
#返回一个字符型
>>>f = 1.216
>>>format(f, ".2f"))
'1.22'
这里再给出一些输出格式。
| 数字 | 格式 | 输出 | 描述 |
|---|---|---|---|
| 3.1415926 | {:.2f} | 3.14 | 保留小数点后两位 |
| 3.1415926 | {:+.2f} | 3.14 | 带符号保留小数点后两位 |
| -1 | {:+.2f} | -1 | 带符号保留小数点后两位 |
| 2.71828 | {:.0f} | 3 | 不带小数 |
| 1000000 | {:,} | 1,000,000 | 以逗号分隔的数字格式 |
| 0.25 | {:.2%} | 25.00% | 百分比格式 |
| 1000000000 | {:.2e} | 1.00E+09 | 指数记法 |
| 25 | {0:b} | 11001 | 转换成二进制 |
| 25 | {0:d} | 25 | 转换成十进制 |
| 25 | {0:o} | 31 | 转换成八进制 |
| 25 | {0:x} | 19 | 转换成十六进制 |
| 数字 | 格式 | 输出 | 描述 |
|---|---|---|---|
| 5 | {:0>2} | 05 | 数字补零 (填充左边, 宽度为2) |
| 5 | {:x<4} | 5xxx | 数字补x (填充右边, 宽度为4) |
| 10 | {:x^4} | x10x | 数字补x (填充右边, 宽度为4) |
| 13 | {:10} | 13 | 右对齐 (默认, 宽度为10) |
| 13 | {:<10} | 13 | 左对齐 (宽度为10) |
| 13 | {:^10} | 13 | 中间对齐 (宽度为10) |
str.replace(str_old,str_new,times)
将str_old用str_new替代,最多替代times次,但并不对目标字符串本身做出改变
>>> str="Emos_Er1t"
>>> str.replace('o','0')
'Em0s_Er1t'
>>> str
'Emos_Er1t'
str.title()
将str以除字母外的字符为分隔,分割成几个单词,将这几个单词的首字母变成大写,其他字母变成小写
#'em0s_er1t'.title()就是把eM、s、er、t的首字母变成大写,其余的变成小写
>>> 'eM0s_er1t'.title()
'Em0S_Er1T'
str.lower()
将str所有字母转小写。
>>> 'EM0S_ER1T'.lower()
'em0s_er1t'
str.upper()
将str所有字母转大写。
>>> 'em0s_er1t'.upper()
'EM0S_ER1T'
四、面向文件读写
open(path,m) & file.close()
- open(path,m)
关于文件路径
- 相对路径:若要打开的文件在当前文件的同级文件夹中或者在其子文件夹中可以采用相对路径。
.表示py文件当前所处的文件夹的绝对路径,..表示py文件当前所处的文件夹上一级文件夹的绝对路径
例如:a_file文件夹下的xxx.py想打开的是b_file下的文件,xxx.py和b_file都在文件目录之下,两者是同级目录,因此操作就是在当前目录向下搜索,因此就可以用下面8种打开方式任选其一即可#关于with open……后面会细述 #字符串前面加个`r`可以使字符串不转义 with open(r"b_file\a.txt","r") as file: with open(r".\b_file\a.txtx", "r") as file: #用/可以避免转义 with open("b_file/a.txt","r") as file: with open("./b_file/a.txtx", "r") as file: #双斜杠转义 with open("b_file\\a.txt","r") as file: with open(".\\b_file\\a.txtx", "r") as file:而下面这样打开是错误的,因为python会把
\译为与后面的字符a搭配成为转义字符\awith open("b_file\a.txt","r") as file: with open(".\b_file\a.txtx", "r") as file:
- 绝对路径:绝对路径只需要要打开的文件路径全名即可
以m的方式打开path路径的文件,返回这个文件的文件对象,m可取如下值:
| 模式(m) | 说明 | 指针初始位置 | 如果文件不存在 |
|---|---|---|---|
| r | 以只读的方式打开文件 | 文件开头 | 报错 |
| w | 打开一个文件写入内容。注意:这种模式是从头写入,会覆盖之前已有的内容 | 文件开头 | 创建 |
| a | 与w一样是写入文件。不同之处在于它不是从头写入,而是在已有文件后面接着写 | 文件结尾 | 创建 |
| rb | 和r基本相同,不同之处在于以二进制的格式打开文件 | 文件开头 | 报错 |
| wb | 和w基本相同,不同之处在于以二进制的格式打开文件 | 文件开头 | 创建 |
| ab | 和a基本相同,不同之处在于以二进制的格式打开文件 | 文件结尾 | 创建 |
| r+、w+、a+、rb+、wb+,ab+ | 以可读可写的方式打开 | r,w:开头。a:结尾 | r:报错。w,a:创建 |
path的斜杠最好用‘/’,不要用‘\’,因为后者很容易被误识成转义符,有时候会报错
- file.close()
关闭文件(虽然python会在一个文件不用后自动关闭文件,但不能保证)
- with open(path,m) as file:
为了防止打开文件产生错误而导致不能关闭文件,可以试试这种方法,这样就不用额外进行关闭文件的操作。
file.read(n)
以byte为单位(输出是以b'xxx'的形式,后面不再赘述)读取长度为n的字符串。
五、面向字典
字典是无序集。
1.添加键值对
>>> dict={1:'Em0s',2:'_'}
>>> dict[3]='Er1t'
>>> dict
{1: 'Em0s', 2: '_', 3: 'Er1t'}
2.删除键值对
>>> dict={1:'Em0s',2:'_',3:'Er1t'}
>>> del dict[2]
>>> dict
{1: 'Em0s', 3: 'Er1t'}
3.遍历字典
- 遍历所有键值对。
for key,value in dict.items(): - 遍历所有键。
for key in dict.keys(): #或者for key in dict: - 遍历所有值。
for key in dict.values():
4.创建字典
创建一个字典除了用赋值语句,也可以用dict函数
>>> dict(name="Em0s_Er1t")
{'name': 'Em0s_Er1t'}
5.清空字典
>>> dict={1:"a",2:"b",3:"c"}
>>> dict.clear()
>>>dict
{}
6.字典转列表
>>> dict={1:"a",2:"b",3:"c"}
>>> list(dict)
[1, 2, 3]
>>> list(dict.values())
['a', 'b', 'c']
>>> list(dict.keys())
[1, 2, 3]
>>> list(dict.items())
[(1, 'a'), (2, 'b'), (3, 'c')]
7.字典排序
原理是创建一个新的字典。
- 按值升序排
dict = {'c':20,'a':12,'b':5} sorted_dict = {key: value for key, value in sorted(dict.items(), key=lambda item: item[1])} print(sorted_dict) #输出:{'b': 5, 'a': 12, 'c': 20} - 按值降序排
dict = {'c':20,'a':12,'b':5} sorted_dict = {key: value for key, value in sorted(dict.items(), key=lambda item: item[1],reverse=True)} print(sorted_dict) #输出:{'c': 20, 'a': 12, 'b': 5}
8.dict.get(key, default=None)
返回指定键的值,如果键不在字典中返回 default 设置的默认值。
>>>dict={1:'Em0s',2:'_',3:'Er1t'}
>>>dict.get(1)
'Em0s'
>>>dict.get(4,'none')
'none'
六、import
A.py如何调用B.py内的add方法
- B.py
def add(x,y): print('和为:%d'%(x+y)) class B: def __init__(self,xx,yy): self.x=xx self.y=yy def sub(self): print("x和y的差为:%d"%(self.x-self.y))
1. A.py和B.py在同一文件夹下
调用函数时A.py为
import B
B.add(1,2)
或者
from B import add
add(1,2)
调用类时A.py为
from B import B
b=B(2,3)
b.sub()
2. A.py和B.py在不同文件夹下
若B.py的路径是E:\Python\B.py
A.py为
import sys
sys.path.append(r'E:\Python')
'''python import模块时,是在sys.path里按顺序查找的。
sys.path是一个列表,里面以字符串的形式存储了许多路径。
使用B.py文件中的函数需要先将他的文件路径放到sys.path中'''
import B
b=B.B(2,3)
b.sub()
七、lambda
原型:
lambda arguments : expression
- lambda函数可接受任意数量的参数
- lambda函数是一种小的匿名函数。
使用lambda函数可以帮助我们用一个函数定义生成两个函数,如下:
def myfunc(n):
return lambda a : a * n
fun1 = myfunc(2)
fun2 = myfunc(3)
print(fun1(11))
#输出:22
print(fun2(11))
#输出:33
八、其他函数
[1] map(function,list/str/tuple)
对列表或者字符串或者元组中的每个元素使用function函数
#把字符串的各个字符转ASCII编码
>>> list(map(ord,"Em0s_Er1t"))
[69, 109, 48, 115, 95, 69, 114, 49, 116]
#把[1,2,3]里的元素转字符串
>>> list(map(str,[1,2,3]))
['1','2','3']
#自定义函数同样支持
def square(variable):
return variable*variable
print(list(map(square,range(10))))
#输出:[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
[2] isinstance(variable,type)
检查variable变量是否是给定类型
>>> variable="Em0s_Er1t"
>>> isinstance(variable,str)
True
[3] assert
在程序中插入一个断点,如果跟在后面的相当于bool值False,就会抛出一个AssertionError异常。
例如下面的代码运行之后,由于list肯定不是str型,所以就不会接着向下运行,而是抛出一个AssertionError异常。
list=[1,2,3]
assert isinstance(list,str)
print("==========")
输出结果如下:
Traceback (most recent call last):
File "XXXX", line 2, in <module>
assert isinstance(list,str)
AssertionError
[4] round()
保留小数点位数。
>>> f=1.2169
>>> round(f,3)
1.217
九、运算符
Python提供了很多有用的运算符,除去一些常用的,下面的是参考了一个博主的《python中的各种符号》整理一些相对冷门与需要进行区分的运算符罗列如下。
| 运算符 | 描述 |
| := | 海象运算符,可以构建赋值表达式并写在语句中,一个很大的用处就是简化你的代码,比如[y for x in names if (y := f(x))] |
| is&== | python所有的对象包含的三个基本要素,分别是:id(身份标识)、type(数据类型)和value(值)。
|
| 集合运算 >>>a = set([1,2,3]) >>>b = set([2,3,4,5,6]) |
|
| <> | 不等于,比较两个对象是否不相等 (a <> b) 。这个运算符类似 != 。 |
| & | 求交集,如print(a&b) #{2, 3} |
| | | 求并集,如print(a|b) #{1, 2, 3, 4, 5, 6} |
| - | 求差集,与交集取差,如print(a-b) #{1} |
| ^ | 求交集的补集,如print(a^b) #{1, 4, 5, 6} |
| -> | python函数定义的函数名后面,为函数添加元数据,描述函数的返回类型,从而方便开发人员使用 |
十、if __name__ == '__main__':
我们知道,对于一个py文件,要么作为脚本文件直接运行,要么就被其他直接运行的py文件作为模块导入,而if __name__ == ‘main’:的作用就是被它包裹的语句只有在当前脚本文件被直接运行才执行。
其实每个python模块都包含内置的变量 __name__,当该模块被直接执行的时候,__name__就被赋值等于 “__main__”,__name__ == 'main'结果为真;而不直接执行的模块,变量 __name__始终指当前执行模块的名称。
下面举个栗子:
test.py文件如下
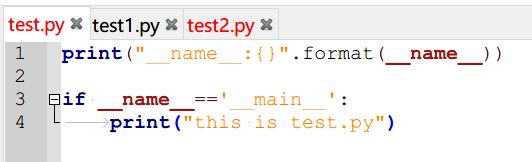
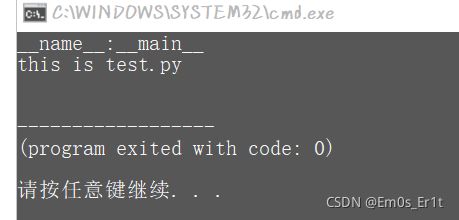
直接运行test.py的结果如下:
test1.py文件如下,两个都处于同一目录下,test1.py导入test模块。

直接运行test1.py的结果如下,因为print("__name__:{}".format(__name__))语句打印出的结果是所在文件的__name__值,由于test.py被test1.py作为模块导入,所以运行结果的第一行打印出的是test.py的__name__值,第二行是当前文件的__name__值。
