风控算法大赛解决方案分享
拍拍贷“魔镜风控系统”从平均400个数据维度评估用户当前的信用状态,给每个借款人打出当前状态的信用分,在此基础上再结合新发标的信息,打出对于每个标的6个月内逾期率的预测,为投资人供关键的决策依据。本次竞赛目标是根据用户历史行为数据来预测用户在未来6个月内是否会逾期还款的概率。

01
项目总体思路
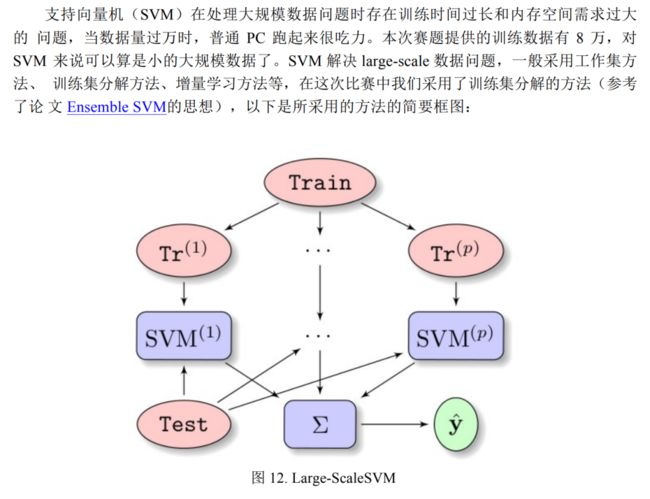
本文将为您介绍我们在数据处理过程中所采用的方法,从数据清洗到特征工程再到特征选择,最终进行模型设计与分析。在数据清洗阶段,我们采用多维度处理缺失值、剔除离群点以及处理字符和空格等方法。随后,我们进行特征工程,包括构建地理位置信息特征、成交时间特征、类别特征编码、组合特征构建以及提取UpdateInfo和LogInfo表的特征。接着,我们使用xgboost进行特征选择,该过程会对特征进行排序以确定其重要性。考虑到数据存在类别不平衡现象,我们采用代价敏感学习和过采样两种方法进行处理,其中重点介绍过采样方法的应用。最后,我们选择了逻辑回归模型、数据挖掘比赛中的强力选手xgboost以及大规模svm方法进行模型设计与分析,并取得了令人满意的结果。此外,我们还探索了模型融合的方法。
1. 数据清洗
在征信领域,用户信息的完善程度对其信用评级有重要影响。一位信息完善程度为100%的用户相比信息完善程度只有50%的用户,更容易通过审核并获得借款。为了更好地处理这一问题,我们进行了多维度的缺失值分析和处理。我们首先按照属性统计了每列缺失值的数量,并进一步计算了各列的缺失比率。下图(图 1)展示了含有缺失值的属性及其相应的缺失比率。
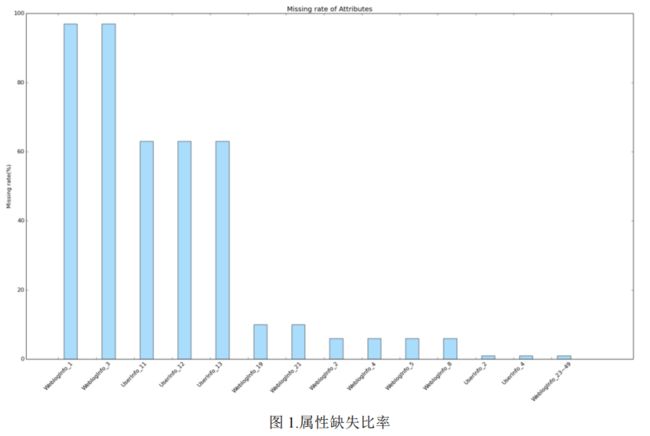
根据分析结果,发现WeblogInfo_1和WeblogInfo_3的缺失值比率高达97%,这两列属性基本上没有携带有用的信息,因此我们可以直接剔除它们。而UserInfo_11、UserInfo_12和UserInfo_13的缺失值比率为63%,这三列属性是类别型的,我们可以将缺失值用-1填充,将其视为另一种类别。至于其他缺失值比率较小的数值型属性,我们可以使用中值进行填充。
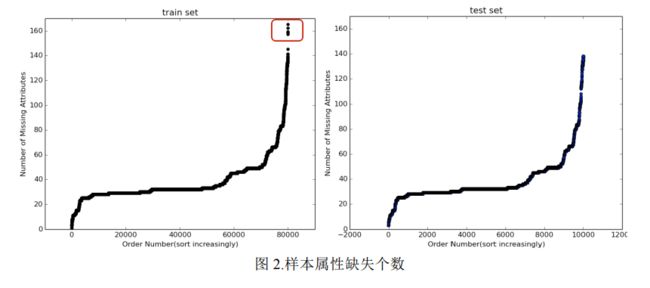
接下来,我们按照每个样本的属性缺失值个数进行统计,并将其从小到大排序。以序号为横坐标,缺失值个数为纵坐标,绘制了下图(图2)中的散点图。
2. 剔除常变量
根据对原始数据的分析,我们发现有190个数值型特征。为了筛选出变化较小的特征,我们计算了每个数值型特征的标准差。通过这一计算,我们确定了标准差接近于0的15个特征。下表(表1)列出了这15个特征,我们将它们剔除,以提高数据的准确性和模型的效果。

3. 离群点剔除
在我们的研究中,我们定义离群点为在样本空间中与其他样本点的一般行为或特征不一致的数据点。考虑到离群点可能具有多维度的异常特征,我们采用了多种方法来识别并剔除这些离群点。
首先,我们通过分析样本属性的缺失值个数,剔除了一小部分离群点,这在第3.1节中有详细说明。
其次,我们还使用了一种简单而有效的方法,即在原始数据上训练了一个xgboost模型。通过这个模型,我们得到了特征的重要性排序。我们选取了最重要的前20个特征,并统计了每个样本在这20个特征上的缺失值个数。如果某个样本在这20个特征上的缺失值个数大于10,我们将其标记为离群点。
通过上述方法,我们可以较为准确地识别
02
特征工程
1. 地理位置处理
在处理地理位置信息(类别型变量)时,最常用的方法是独热编码(one-hot encoding)。然而,这种方法会导致高维度的稀疏特征,可能会影响模型的学习效果。为了解决这个问题,我们在独热编码的基础上,进行了特征选择。下面是具体的方法介绍。
在赛题数据中,提供了用户的地理位置信息,包括7个字段:UserInfo_2、UserInfo_4、UserInfo_7、UserInfo_8、UserInfo_19、UserInfo_20。其中,UserInfo_7和UserInfo_19是省份信息,其他字段是城市信息。我们对每个省份和城市进行了违约率的统计分析。
以UserInfo_7为例,我们通过统计不同省份的违约率,得到了下图的结果。该图展示了不同省份的违约率信息。通过这样的分析,我们可以发现不同省份之间的违约率差异。
在特征选择阶段,我们可以将这些统计信息作为特征之一,以帮助模型更好地理解地理位置信息与违约率之间的关系。具体的方法可以参考下图。

2. 地理位置的独热编码
为了解决类别型特征取值个数太多导致独热编码后得到高维稀疏特征的问题,除了使用特征选择方法外,我们还采用了合并变量的方法。根据城市等级,我们将类别变量进行合并。例如,一线城市(北京、上海、广州、深圳)合并为1,二线城市合并为2,三线城市合并为3。
另外,我们引入了经纬度特征。除了处理类别型变量,我们还收集了各个城市的经纬度信息。通过用经纬度替换城市名称,我们将类别型变量转化为数值型变量。以北京市为例,我们用经纬度(39.92,116.46)代替,得到北纬和东经两个数值型特征。加入经纬度后,在线下交叉验证中,我们观察到了千分位的性能提升。
此外,我们对城市特征进行了向量化处理。我们计算了城市特征中每个城市的计数,并取对数,然后将其离散化到6-10个区间内。以UserInfo_2特征中的325个城市为例,我们将其离散为一个6维向量。例如,向量“100000”表示该城市位于第一个区间。通过这个向量化的表示,我们观察到了线下交叉验证中千分位的性能提升。
这些处理方法的具体效果可以参考下图。

3. 成交时间特征
根据训练集中的日期,我们统计了每天借贷的成交量,并将正负样本分别进行了统计。下图显示了曲线图,横坐标表示日期(从2013年11月1日至2014年11月9日),纵坐标表示每天的借贷量。
在图中,蓝色曲线代表违约样本每天的数量(为了突出对比,数量乘以了2),而绿色曲线表示不违约样本每天的数量。
通过这个曲线图,我们可以观察到正负样本在不同日期的借贷量变化。这个图像可以帮助我们分析样本的时间分布特征,并在模型训练中有助于理解日期与违约风险之间的关系。

4.组合特征
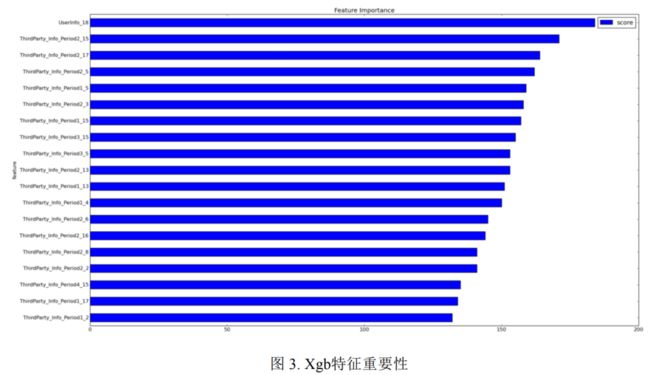
在训练Xgboost模型完成后,我们可以输出特征的重要性,通过观察发现第三方数据特征"ThirdParty_Info_Period_XX"的feature score较大,即具有较高的判别性。为了充分利用这些特征,我们采取了一种组合特征的方法。
具体而言,我们将特征两两相除,得到了7000多个新的组合特征。然后,我们使用Xgboost单独对这7000多个特征进行训练,并得到了这些特征的重要性排序。我们选择其中排名靠前的500个特征,并将其添加到原始特征体系中。通过这个步骤,我们观察到线下交叉验证的AUC值从0.777提高到了0.7833。
此外,我们还尝试了乘法特征的组合,即取对数后的log(x*y)。我们刷选出了其中的270多个维度,并将其加入到原始特征体系中。这一步使得单模型的交叉验证AUC进一步提升至约0.785左右。
通过这些特征组合的操作,我们能够进一步优化模型的性能,提高模型在交叉验证中的AUC值。
03
特征选择
在特征工程的过程中,我们构建了许多不同类型的特征,涵盖了位置信息、组合特征、成交时间特征、排序特征、类别稀疏特征、updateinfo和loginfo相关的特征等。所有这些特征加起来接近1500维。然而,这么多维的特征可能会导致维数灾难,并增加过拟合的风险。因此,我们需要进行特征降维处理。
常见的降维方法包括主成分分析(PCA)和t-SNE等,但在以往的经验中,这些方法在数据挖掘比赛中的效果通常不理想,而且计算复杂度比较高。除了采用降维算法外,我们还可以通过特征选择来降低特征维度。特征选择的方法有很多种,包括最大信息系数(MIC)、皮尔逊相关系数(衡量变量间的线性相关性)、正则化方法(L1、L2)和基于模型的特征排序方法。
在这里,我们选择了基于学习模型的特征排序方法,即使用Xgboost来进行特征选择。在Xgboost模型训练完成后,我们可以输出特征的重要性。根据这些重要性,我们可以保留Top N个特征,从而实现特征选择的目的。这种方法的好处是,模型训练和特征选择可以同时进行,因此非常高效。
通过这样的特征选择方法,我们可以在保留重要特征的前提下,降低特征维度,减少维数灾难和过拟合的问题。
1.类别不平衡的处理
在解决类别不平衡问题时,我们采用了两种方法:一是在训练模型时设置类别权重,即代价敏感学习;二是采用过采样方法。在本节中,我们将重点介绍我们所采用的过采样方法。
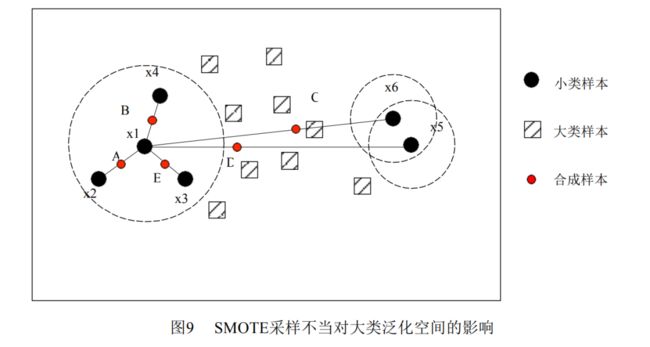
我们选择了SMOTE算法作为过采样方法,因为它在合成小类样本时简便快捷,不容易造成过拟合。然而,尽管SMOTE采样后扩大了小类的泛化空间,但同时也会缩小大类的泛化空间,从而降低了对未知大类样本的预测准确率,也就是存在一定的盲目性。
为了更好地理解SMOTE采样不当造成新样本影响大类泛化空间的原因,我们可以通过一个例子从邻域粗糙集的角度来进行分析。在这个例子中,我们可以观察到,当合成小类样本时,SMOTE算法会通过插值在小类样本的邻域中生成新样本。然而,由于插值是基于少数类样本的,这些新样本可能会覆盖大类样本的一部分决策区域,从而影响大类样本的泛化能力。
因此,在采用SMOTE过采样方法时,我们需要注意合成新样本的策略,以避免对大类样本的泛化空间造成不利影响。
2. 更多详情图片