4.贪心算法 含例题
文章目录
- 贪心算法
-
- 一、一个基本的贪心算法问题:区间调度问题
- 二、区间调度的推广:多个资源下的贪心算法
- 三、最小延迟调度——交换论证
- 四、最优超高速缓存问题
- 五、图最短路径问题
- 六、最小生成树问题
- 七、实现kruskal
- 八、聚类 cluster
- 九、霍夫曼树 Huffman
- 十、交换论证
- 十一、例题
-
- 1.贪心算法有效性证明
- 2.依旧是贪心算法的证明——来看看交换论证
- 3.一个比割性质和圈性质更强的性质
- 4.多重价值贪心问题
- 5.一个特殊的区间调度问题(当时间线是重复循环的)
贪心算法
一、一个基本的贪心算法问题:区间调度问题
假设有很多需要需要被处理,要选择性的处理其中的需求,一旦选择了某个需求,则其他与其冲突的需求将会被拒绝。那么怎么选取这些个需求,使得能够完成更多的需求?
先说这个问题的解法,这个问题的解法是基于贪心算法:尽早的接受最早结束的需求。
这个解法看上去是相当简单且自然的,事实上贪心算法也正是如此,但难点是如何证明这个算法的有效性。
PROOF:
首先我们假设存在一个最优解:O,我们要证明由贪心算法的到的解A是最优解,即|O|=|A|
我们继续假设在A中有m个需求,i1,i2,i3……im,在O中有n个需求,j1,j2,j3……jn,让这些需求按时间排列(注意这些需求是相容的)我们要证明的是m=n。
让f(i1)表示i1这个需求的结束时间,由我们的贪心算法可以的到,f(i1)≤f(j1),接下来我们要证明对于每个需求r,都有f(ir)≤f(jr)。这个证明可以由归纳法完成,(我们省去归纳法的其他步骤,直接从n-1开始):我们知道f(jr-1)≤s(jr),将其与假设f(ir-1)≤f(jr-1)结合得到f(ir-1)≤f(jr),然后贪心算法就至少可以选择到O中的第r个需求,满足f(ir)≤f(jr)。
现在我们的到了这一点:
对于每个需求r,都有f(ir)≤f(jr)
我们接下来就可以用反证法证明贪心算法是最优的了。
假设贪心算法不是最优的,即n>m,但是我们有f(im)≤f(jm),此时的贪心算法仍然可以选择m+1的需求,这与贪心算法当不能再选择时才停止矛盾。
时间复杂度:
对这些需求按照结束时间排序需要用到O(nlogn)的时间,然后按照这个次序去选择满足相容的需求需要O(n)的时间,总共的时间复杂度时O(nlogn)
二、区间调度的推广:多个资源下的贪心算法
在第一节中描述的问题中只有一个资源被调度,现在考虑多个资源下的贪心问题。
举个例子,你现在有多间教室而不是只有一间可以供你调配,你要合理的安排课程,使得使用最少的资源(教室)把这些课程全部安排妥当。
这个算法的最优性其实比上一个算法好证明的多,我们知道如果有多节课在同一个时间上,例如星期二的上午有5节课需要安排,那么我们至少就需要5间教室,我们将时间线上任意一点的最大区间树称为深度。那么我们只需要寻找一个算法,能够用深度个数的教室安排这些课程就可以了。
算法的具体过程:我们只需要按照开始时间对这些需求区间进行排序,将每个深度作为一个“标签”按照顺序分配给这些需求区间,如果在分配过程中,某个与该区间重叠的区间已经被分配了某个标签,那么就不再考虑这个标签。
三、最小延迟调度——交换论证
现在我们将考虑一个更加灵活的问题,每个任务不再是固定一个开始或者结束的时间,而是有一个截止日期(ddl),并且它要求花费一个连续的时间t,它可以被安排在ddl前的任何时期。如果某个任务被延迟了,我们把延迟 l 定义为l=f-ddl。我们的目标是使得最大的延迟L=maxl达到最小。
这个问题的解法也相当的简单:尽早的完成ddl更早的任务
难点在于如何证明这一点。
我们继续假设存在一个最优的(没有空闲时间的)的最小延迟调度O。证明的策略是逐步修改O保证其最优性,知道O=A(A是贪心算法的结果)
-
我们先假设O≠A,若O存在一个逆序:一对任务i和j,j被直接安排在i的后面,并且dj
也许有人会问,若j不是紧挨在i的后面呢?那么也一定存在另一对连续的或者说紧挨着的逆序对
-
我们交换这个连续的逆序对并不会对其他的任务产生影响,因此交换这个逆序对不会产生更多的逆序对,只会让整个流程的逆序对-1
-
重点:这个被交换的调度的最大延迟是否不会大于O?
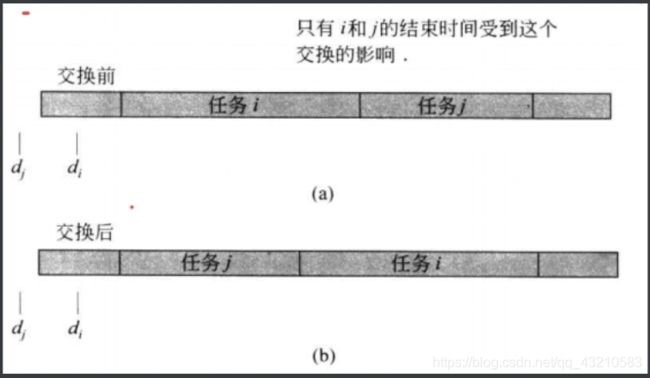
请观察这幅图,很清楚的知道在交换两个任务后,任务j的结束时间变成了任务i的结束时间,任务j变得结束的更早,因此任务j的延迟并不会增加,麻烦的是任务i的延迟是否会增加呢?
在这个交换后调度中,任务i的延迟是l’i=f’(i)-di=f(j)-di,但是在交换前,j的延迟是lj=f(j)-dj,因为我们假设过dj
四、最优超高速缓存问题
这个问题涉及到计算机的内存管理机制,具体内容是在计算机的高性能存储器内,只能存储一部分内容,而这些内容需要从硬盘中获取,那么当新的内容被加入到高性能内存中时,就会有一部分暂时用不到的内容被回收到硬盘中去。如何安排这种回收策略,使得计算机在高性能存储器中获得资源时达到最小的缺失次数?
在20世纪60年代,Les Belady证明了一个听上去非常简单的算法:
每次都回收在最远的将来被需要的那个资源
具体证明暂略,后续补上
五、图最短路径问题
在前文的介绍下,其实我们已经见识到了,运用BFS可以很好的解决无向图的最小距离问题,但是当问题到了有向图的时候,我们就需要寻求新的方法了。这里介绍一个大名鼎鼎的dijkstra的方法:
Dijkstra(G,L)
设S是已经被探查的节点的组合
对每个属于S的u,我们存储一个距离d(u)
初始化S=V且d(s)=0,其他所有点的d(x)=+inf
while S≠ø
从S中删除一个d(x)最小的点v
对于v的出边连接的所有点,更新最短的路径
(tip:dijkstra无法处理负权边)
如果我们能证明dijkstra每次探查到的点都是从s到这个点的最短距离,那么我们可以立即证明这个算法的正确性。
证明略(归纳法)
假设S是已探查的最小路径的集合,规模为n,那么对于每次删除的点x,我们认为是集合外的点,既然我们要到达这个点,就一定要从某个地方出集合,但是由于d(x)是目前最短的路径,因此从任何其他地方出集合,都会产生更远的路径。
时间复杂度:迭代n次,每次去检查连接S的所有节点将可能需要O(m)的时间,因此复杂度是O(mn)
但是我们可以使用优先队列:
我们对n个点都要使用一次delete操作,复杂度是nlogn,我们总共要遍历m条边(因为在这条边被遍历后入点就会被删树,所以每条边只会被遍历一次),遍历每条边的时候我们都会使用一次decrease-key(logn),复杂度是mlogn。所以总的时间复杂度是(m+n)logn,近似认为是O(mlogn)
六、最小生成树问题
问题:对于某个无向有权(边是非负的)连通的图,能不能找到一个最小的边的集合,使得这个图仍然是连通的?
为什么是树:对于一个无向图,假如这个最小生成树中有环,我们删除环的其中一条边,这个图仍然是连通的,所以不存在环
对于这个算法的探究,人们想出了许多不同的贪心法:
-
Kruskal算法
按照费用递增的顺序不断的插入来自E中的边来建立一颗生成树,但是如果某条边e产生了一个圈,我们就放弃这条边。
-
Prim
先构建一个跟节点s,每次都往跟节点不断的插入费用尽可能小的边来扩张这棵树
-
逆向删除算法
即逆向运行kruskal,按照顺序每次删除当前费用最多的边(只要不影响连通性)
对于贪心算法,我们每次证明其正确性的时候,都是在证明一件事,即每次贪心的时候(在这里是加入新的边的时候)是不是都是安全的?或者说是一定正确的?我们用一个观点陈述这件事:
假设所有边的费用是不等的,设边e是一条从已经存在的生成树到剩余边的最小费用边,那么每棵最小生成树都包含边e
为了证明这一点,我们使用交换论证的方法,我们要证明某个不包含e的生成树T不具有最小费用,或者说把T中的某条边e’交换为e之后能够获得更小的费用。
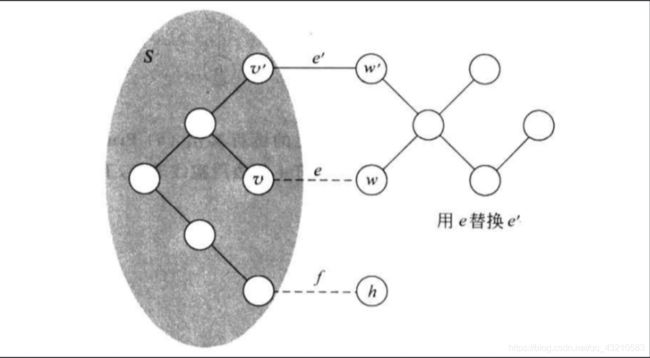
如图所示,在这种情况下,由于原来的T也是生成树,所以S和V-S的部分是连通的,所以我们在删除e’获得e之后,这个树仍然是连通的。并且由于上图中六边形是唯一的圈,在删除e’之后,这个树就不再存在圈了。
至此我们证明这个观点,这个证明的关键点在于证明交换边之后的树仍然是一颗生成树。这个证明的性质我们一般称它为割性质。
接下来我们思考在什么情况下我们能确认某条边一定不属于最小生成树呢?同样我们称这个性质为圈性质。
假设所有边的费用不同,令C是G中的一个圈,那么C中最贵的边一定不属于最小生成树。
这个证明同样可以用交换论证证明,具体证明略。
我们证明的割性质一般用于证明prim和kruskal的算法最优性,圈性质一般用于证明逆删除算法的最优性。
排除边费用相同的假设: 但这个时候我们注意到我们所有的假设都是建立在所有边费用相同的基础上的,其实我们只需要给每条边一个不一样的,非常小的干扰数c,使得每条边都不一样,这个干扰是如此的小以至于不会对边与边的比较产生影响,所以我们的到的树仍然是和原来结果一样的树。
时间复杂度分析:我们暂时先分析Prim算法,不难发现Prim算法的实现和djkstra基本一致,因此复杂度也是mlogn
七、实现kruskal
我们为什么要单独拿出一点来讲kruskal的实现?是为了介绍一种新的数据结构:Union-Find。
这个数据结构将要能够实现三个操作
- MakeUnionFind(S)将返回集合S上的一个Union-Find数据结构,其中所有的元素都在分离的集合中。(O(n))
- Find(u)将要找到包含u的集合的名字 O(logn)实际上我们讨论的某些实现只需要O(1)的时间
- Union(A,B)将合并A,B集合 O(logn)
这里考虑两种实现方式:
数组法:
即把这些个元素存到数组list中去。对于某个元素s,list[s]表示这个元素所属的集合。
优点是我们可以用O(1)的时间去获取某个元素所属的集合,即Find操作。
缺点是当我们做Union操作时,我们要更改数组里很多的值,最坏复杂度达到了O(n)。为了解决这个问题,我们采用一个优化:每次都让少的集合向多的集合合并。这个优化实际上并不会降低一次Union的复杂度,但是我们观察整体的最坏复杂度,整体的最坏复杂度在每次合并集合的大小都一样的时候达到,(举个例子:假设有n(n=8)个元素需要合并,如下图)
那么总共要合并log28=3次,每次合并的花费都是n/2=4,所以总的复杂度是O(nlogn),而且我们总共执行了n/2次Union操作,平均的Union操作的时间复杂度是O(logn),这已经足够好了。
指针法:
也许有些人对Union的时间复杂度仍然不满意,我们可以采用指针法,但是缺点是会给Find操作带来更多的时间。
我们让一个集合里的所有元素都指向其中的某一个元素(领头元素),以这个元素的名字作为集合名(这个元素指向自己或者null),这样我们在合并集合的时候,只需要改变领头元素的指向即可。带来的缺点是执行find操作时,需要经历多层指针,我们在这里同样采用优化策略,使得每次都让小集合向大集合合并,这样每次find至多经历logn层指针(如上图)。
指针法可以进一步优化:
问题出在与我们每次调用底层的每个元素执行find操作都要经历多层指针,我们可以记录这个find的结果,改变底层的指针,使其直接指向最终的答案。
现在让我们用这个Union-find的数据结构实现kruskal算法:仍然假设有m条边,n个节点。
我们首先要对这些边的费用进行排序,这需要花费mlogm的时间,由于m≤n2,所以这个运行时间也是mlogn。
由于我们要考虑m条边,所以我们最多要执行2m次find操作,n-1次union操作,若采用指针法,需要的复杂度是2m(logn)+n-1=O(mlogn)[采用数组法得到的也是相同的答案]
八、聚类 cluster
我们把一个集合内的许多元素无监督的聚成多个不同的类成为聚类。我们定义不同类的任意元素对的最小距离为类间隔。我们定义k聚类是把集合分为k类,现在的问题是我们怎么找出最大间隔的聚类?
过程与kruskal的算法基本完全相同,我们每次都按照递增的顺序添加边,唯一的区别是我们在产生k的连通分量后停止。
简略的正确性证明:
可以很清楚的看到通过这个算法获得的聚类C的最大距离d正好就是最小生成树中第k-1贵的边。
我们通过证明另一个聚类C’的最小间隔不会大于d来证明这个算法的最优性。
由于C是通过krusakl算法添加的边,所以聚类结果中的任意一条边(u,v)都会≤d
那么对于C’中的某个间隔d’,他要么与C中的某个间隔相同,要么是C中的某条边,如果是C中的某条边的话,那么他一定≤d
九、霍夫曼树 Huffman
最优前缀码

这个函数表示的是前缀码的平均位数,其中fx表示的是某个字符出现的频率,|c(x)|表示的是该字符对应的前缀码的长度。
所谓最优前缀码就是使得ABL(c)达到最小的前缀码。
二叉树和前缀码
我们可以很自然的观察到可以由一个二叉树构成一个前缀码。那么一个最优前缀码呢?
与最优前缀码对于的二叉树是满的
我们再次使用交换论证的方法证明:
假设T是某个最优前缀码的二叉树,且T不是满的,那么T存在一个节点u只有一个子节点v,此时我们可以简单的用v替换u,得到的新树有着更短的前缀码,因此T不是最优的——矛盾。
huffman的算法关键在于证明这个最优前缀码对应的二叉树一定存在两个频率最低的字符在树中是两个叶子结点,且互为兄弟。
算法最优性证明
我们采用归纳法证明这一点。我们的归纳证明从n-1开始。
现在考虑规模为n的二叉树,假设树T是最优前缀码对应的二叉树,算法有着最低频率的两个字符x和y。
现在我们删除x和y,将其父节点对应某个字符w,那么这颗新的二叉树T’就是规模为n-1的二叉树。
继续我们的归纳法,假设n-1规模的二叉树是最优的,即T’有最优性,我们来证明T也有最优性。
假设T没有最优性,那么存在某个树Z有最优性,即ABL(Z) 那么有ABL(Z)-fw 时间复杂度 使用优先队列的huffman算法可以达到O(nlogn)的复杂度 我们多次提到这个论证方法。 Exchange Argument的主要的思想也就是 先假设 存在一个最优的算法和我们的贪心算法最接近,然后通过交换两个算法里的一个步骤(或元素),得到一个新的最优的算法,同时这个算法比前一个最优算法更接近于我们的贪心算法,从而得到矛盾,原命题成立。 下面来看一个更为formal的解释: 步骤: Step0: 给出贪心算法A的描述 Step1: 假设A不是最优的算法,那么存在一个算法O是和A最相似(假设O和A的前k个步骤都相同,第k+1个开始不同,通常这个临界的元素最重要)的最优算法 Step2: [Key] 修改算法O(用Exchange Argument,交换A和O中的一个元素),得到新的算法O’ Step3: 证明O’ 是feasible的,也就是O’是对的 Step4: 证明O’至少和O一样,即O’也是最优的 Step5: 得到矛盾,因为O’ 比O 更和A 相似。 证毕。 当然上面的步骤还有一个变种,如下: Step0: 给出贪心算法A的描述 Step1: 假设O是一个最优算法(随便选,arbitrary) Step2: 找出O和A中的一个不同。(当然这里面的不同可以是一个元素在O不再A,或者是一个pair的顺序在A的和在O的不一样。这个要根据具体题目) Step3:Exchange这个不同的东西,然后argue现在得到的算法O’ 不必O差。 Step4: Argue 这样的不同一共有Polynomial个,然后我exchange Polynomial次就可以消除所有的不同,同时保证了算法的质量不比O差。这也就是说A 是as good as 一个O的。因为O是arbitrary选的,所以A是optimal的。 证毕 假设anditty有一段路程要走,在这段路程中有一些露营点,假设每天anditty最多可以行走的距离为d,且每两个露营点之间的距离最多为d。anditty想出了一种策略:每天尽可能走的多一点,但是显然他们不能在晚上行走,每次出发前都要估计一下能否在天黑之前到达下一个宿营点,如果可以才出发。anditty想知道这种策略能否使得整个旅程尽可能少的露营? 证明: 这个算法看上去是很自然的正确的,每天多走一点当然可以更少的露营,但是有没有可能存在另一种策略,能够虽然暂时落后贪心算法,但是能够后来居上领先它? 我们假设存在这样一个最优的算法O,他经历了更少的露营点:O1,O2……Om,而我们的贪心算法A经历了更多的露营点A1,A2……Ak,(k>m)。 现在我们要证明这一点,对于每个i=1,2……m,有Ai≥Oi,如果这一点被证明,那么一定有Am距离终点距离大于d,不然就不必在Am+1的位置停下,如果Am离终点距离大于d,那么Om离终点的距离也大于d,这样的话O得到的集合就不是一个合法的集合,从而反证A才是最优解。 好,现在只要证明了对于每个i=1,2……m,有Ai≥Oi,那么我们可以立即宣称我们的结果。 证明这一点,我们使用归纳法。对于i=1的结果由贪心算法的定义就可以看出。 接下来如果有An-1≥On-1,又因为On-On-1≤d,有On-On-1≥On-An-1,即d≥On-An-1,那么此人在An-1休息之后的一天内至少可以走到On的位置,所以有An≥On,完成证明。 假设你有公司需要购买n张许可证,每张许可证的初始价格相同,假设为100元,但是他们的价格增常率r不同。我们假设许可证随购买的时间t这样变化,价格=100 · rt。(一个单位时间内只能购买一张许可证)那么怎么购买许可证能到达到最低的价格? 很自然的想到当然是按照r递减的顺序购买啦!这道题主要考察的是交换论证的运用: 边e(v,w)不属于G的一颗mst 当且仅当 v和w可以被一条由全比e便宜的边组成的路径连接 only if部分:如果v和w可以被一条由全比e便宜的边组成的路径连接,那么由圈性质,e是其中最贵的边,所以将不属于mst if部分:观察其逆否命题,如果v和w不能由一条全比e便宜的边组成的路径连接,那么我们假设从v开始用比e便宜的边形成一颗生成树,那么e将会成为从T到其他部分最便宜的边,由割性质,e将属于mst。 假设有n个任务,每个任务都存在一个重要程度w,和花费时间t,现在要以流水线的形式处理这些任务,假设用c代表这些任务的结束时间,那么怎么安排这些任务能使得所有任务的w·c之和最小? 一个贪心解是用w/t越大的任务越先开始。 证明略(交换论证,逆序……) TIp:至今为止我们学会了两种证明方式,一种是通过交换论证(找逆序),还有一种是通过证明贪心算法的每一步都领先于其他算法(归纳法)。 现在考虑一个具有每日循环工作模式的机器,即这个机器每天都在做重复的内容,现在你有n个工作要安排给他,那么如何安排能使得完成的任务数量最多? 这题的难点在于,如果任务都是在0-24点按顺序完成的话,这就是一个简单的区间调度问题,但如果有些问题是从第一天晚上9点到次日的凌晨3点呢?(即使是这样,机器每天也都在做重复的内容) 解决方案是这样的,对于每一个区间我们都算一次包含这个区间的解,假设对于某个区间x,我们先剔除与这个区间重复的其他区间,然后以这个区间上的某个点切断时间线,这样我们就可以用前文提到的区间调度问题求解了。我们对每个区间都这样做,选出最大的一个包含解即可。十、交换论证
十一、例题
1.贪心算法有效性证明
2.依旧是贪心算法的证明——来看看交换论证
3.一个比割性质和圈性质更强的性质
4.多重价值贪心问题
5.一个特殊的区间调度问题(当时间线是重复循环的)