语义分割miou指标计算详解
文章目录
-
- 1. 语义分割的评价指标
- 2. 混淆矩阵计算
-
- 2.1 np.bincount的使用
- 2.2 混淆矩阵计算
- 3. 语义分割指标计算
-
- 3.1 IOU计算
-
- 方式1(推荐)
- 方式2
- 3.2 Precision 计算
- 3.3 总体的Accuracy计算
- 3.4 Recall 计算
- 3.5 MIOU计算
- 参考
MIoU全称为Mean Intersection over Union,平均交并比。可作为语义分割系统性能的评价指标。
- P:Prediction预测值
- G:Ground Truth真实值

其中IOU: 交并比就是该类的真实标签和预测值的交和并的比值

单类的交并比可以理解为下图:
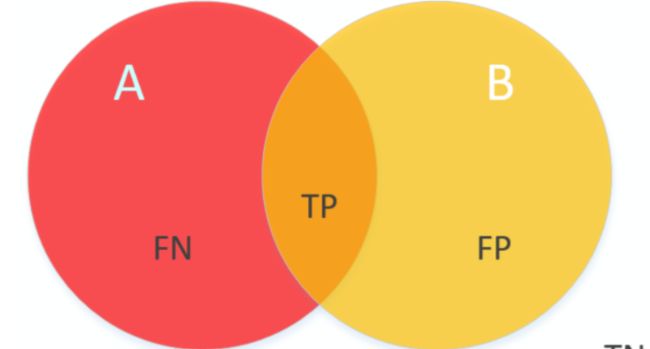
1. 语义分割的评价指标
True Positive (
TP): 把正样本成功预测为正。
True Negative (TN):把负样本成功预测为负。
False Positive (FP):把负样本错误地预测为正。
False Negative (FN):把正样本错误的预测为负。
-
(1) Accuracy准确率,指的是“预测正确的样本数÷样本数总数”。计算公式为:
A c c u r a c y = T P + T N T P + T N + F P + F N Accuracy = \frac{TP+TN}{TP+TN+FP+FN} Accuracy=TP+TN+FP+FNTP+TN -
(2) Precision精确率或者精度,指的是预测为Positive的样本,占所有预测样本的比率
P r e c i s i o n = T P T P + F P Precision= \frac{TP}{TP+FP} Precision=TP+FPTP -
(3)Recall召回率,指的是预测为Positive的样本,占所有Positive样本的比率
P r e c i s i o n = T P P Precision= \frac{TP}{P} Precision=PTP -
(4) F1 score: 综合考虑了precision和recall两方面的因素,做到了对于两者的调和,即:既要“求精”也要“求全”,做到不偏科。
F 1 s c o r e = 2 ∗ p r e c i s i o n ∗ r e c a l l p r e c i s i o n + r e c a l l F1 score= \frac{2*precision*recall}{precision+recall} F1score=precision+recall2∗precision∗recall
- (5)
MIOU作为为语义分割最重要标准度量。其计算两个集合的交集和并集之比,在语义分割的问题中,这两个集合为真实值和预测值。在每个类上计算IoU,之后平均。计算公式如下
M I O U = 1 k + 1 ∑ i = 0 k T P F N + F P + T P MIOU =\frac{1}{k+1}\sum_{i=0}^{k}\frac{TP}{FN+FP+TP} MIOU=k+11i=0∑kFN+FP+TPTP
等价于:
M I O U = 1 k + 1 ∑ i = 0 k p i i ∑ j = 0 k p i j + ∑ j = 0 k p j i − p i i MIOU=\frac{1}{k+1}\sum_{i=0}^{k}\frac{p_{ii}}{\sum_{j=0}^k p_{ij} + \sum_{j=0}^k p_{ji} -p_{ii}} MIOU=k+11i=0∑k∑j=0kpij+∑j=0kpji−piipii
其中: p i i p_{ii} pii 真实为类别i,预测也为i的像素个数,也就是正确预测的像素个数TP; p i j p_{ij} pij表示真实为类别i,但预测为类别j的像素个数,也就是FN; p j i p_{ji} pji表示真实为类别j,但预测为类别i的像素个数, 也就是FP
注意: 对于多分类,TN为0 ,即没有所谓的负样本
2. 混淆矩阵计算
- 计算
MIoU,我们需要借助混淆矩阵来进行计算。 混淆矩阵就是统计分类模型的分类结果,即:统计归对类,归错类的样本的个数,然后把结果放在一个表里展示出来,这个表就是混淆矩阵- 其
每一列代表预测值(pred),每一行代表的是实际的类别(gt)

对角都对TP,横看真实,竖看预测: 每一行之和,为该行对应类(如Cat)的总数;每一列之和为该列对应类别的预测的总数。
2.1 np.bincount的使用
在计算混淆矩阵时,可以利用np.bincount函数方便我们计算。
numpy.bincount(x, weights=None, minlength=None)
- 该方法返回每个索引值在x中出现的次数
- 给一个向量
x,x中最大的元素记为j,返回一个向量1行j+1列的向量y,y[i]代表i在x中出现的次数
#x中最大的数为7,那么它的索引值为0->7
x = np.array([0, 1, 1, 3, 2, 1, 7])
#索引0出现了1次,索引1出现了3次......索引5出现了0次......
np.bincount(x)
#因此,输出结果为:array([1, 3, 1, 1, 0, 0, 0, 1])
minlength也是一个常用的参数,表示输出的数组长度至少为minlength,如果x中最大的元素加1大于数组长度,那么数组的长度以x中最大元素加1为准(例如,如果数组中最大元素为3,minlength=5,那么数组的长度为5;如果数组中最大元素为7,minlength=5,那么数组的最大长度为7+1=8,这里之所以加1是因为元素0也占了一个索引)。举个例子说明:
# a中最大的数为3,因此数组长度为4,那么它的索引值为0->3
a = np.array([2, 2, 1, 3 ])
# 本来数组的长度为4,但指定了minlength为7,因此现在数组长度为7(多的补0),所以现在它的索引值为0->6
np.bincount(x, minlength=7)
# 输出结果为:array([0, 1, 2, 1, 0, 0, 0])
# a中最大的数为4,因此bin的数量为5,那么它的索引值为0->4
x = np.array([4, 2, 3, 1, 2])
# 数组的长度原本为5,但指定了minlength为1,因为5 > 1,所以这个参数不起作用,索引值还是0->4
np.bincount(x, minlength=1)
# 输出结果为:array([0, 1, 2, 1,1])
2.2 混淆矩阵计算
# 设标签宽W,长H
def fast_hist(a, b, n):
#--------------------------------------------------------------------------------#
# a是转化成一维数组的标签,形状(H×W,);b是转化成一维数组的预测结果,形状(H×W,)
#--------------------------------------------------------------------------------#
k = (a >= 0) & (a < n)
#--------------------------------------------------------------------------------#
# np.bincount计算了从0到n**2-1这n**2个数中每个数出现的次数,返回值形状(n, n)
# 返回中,写对角线上的为分类正确的像素点
#--------------------------------------------------------------------------------#
return np.bincount(n * a[k].astype(int) + b[k], minlength=n ** 2).reshape(n, n)
- 产生
n×n的混淆矩阵统计表参数a:即:真实的标签gt, 需要reshape为一行输入参数b:即预测的标签pred,它是经过argmax输出的预测8位标签图,每个像素表示为类别索引(reshape为一行输入),参数n:类别数cls_num
- 首先过滤
gt中,类别超过n的索引,确保gt的分类都包含在n个类别中
k = (a >= 0) & (a < n)
- 如果要去掉背景,不将背景计算在混淆矩阵,则可以写为:
k = (a > 0) & (a < n) #去掉了背景,假设0是背景
- 然后利用
np.bincount生成元素个数为n*n的数组,并且reshape为 n × n n \times n n×n的混淆矩阵,这样确保混淆矩阵行和列都为类别class的个数n n*n数组中,每个元素的值,表示为0~n*n的索引值在x中出现的次数,这样就获得了最终混淆矩阵。这里的x表示为n * a[k] + b[k],为啥这么定义呢?,
举例如下:将图片的gt标签a和pred输出图片b,都转换为一行; a和b中每个元素代表类别索引

- 前面
8, 9, 4, 7, 6都预测正确, 对于预测正确的像素来说,n * a + b就是对角线的值; 假设n=10,有10类。n * a + b就是88, 99, 44, 77, 66 - 紧接着6预测成了5, 因此n * a + b就是65
- 88, 99, 44, 77, 66就是对角线上的值(
如下图红框,65就是预测错误,并且能真实反映把6预测成了5(如下图蓝框)

3. 语义分割指标计算

3.1 IOU计算
方式1(推荐)
计算每个类别的IOU计算:
I O U = T P F N + F P + T P IOU =\frac{TP}{FN+FP+TP} IOU=FN+FP+TPTP
def per_class_iu(hist):
return np.diag(hist) / np.maximum((hist.sum(1) + hist.sum(0) - np.diag(hist)), 1)
输入hist表示 2维的混淆矩阵,大小为n*n(n为类别数)- 混淆矩阵
对角线元素值,表示每个类别预测正确的数TP:
np.diag(hist)
- 其中:混淆矩阵所对应
行中,每一行为对应类别(如类1)的统计值中,对角线位置为正常预测为该类别的统计值(TP),其他位置则是错误的将该类别预测为其他的类别FN: 因此每个类别的FP统计值为:
FN =hist.sum(1) -TP = hist.sum(1) - np.diag(hist)
- 同理,预测为该类别所对应的
列中,对角线为正确预测,其他位置则是将其他类别错误的预测为该列所对应的类别,也就是FP
FP =hist.sum(0) -TP = hist.sum(0) - np.diag(hist)
因此分母FN_FP+TP=np.maximum(hist.sum(1) + hist.sum(0) - np.diag(hist),1), 这里加上np.maximum确保了分母不为0
方式2
def IOU(pred,target,n_classes = args.num_class ):
ious = []
# ignore IOU for background class
for cls in range(1,n_classes):
pred_inds = pred == cls
target_inds = target == cls
# target_sum = target_inds.sum()
intersection = (pred_inds[target_inds]).sum()
union = pred_inds.sum() + target_inds.sum() - intersection
if union == 0:
ious.append(float('nan')) # If there is no ground truth,do not include in evaluation
else:
ious.append(float(intersection)/float(max(union,1)))
return ious
参考:https://github.com/dilligencer-zrj/code_zoo/blob/master/compute_mIOU
3.2 Precision 计算
每个类别的Precision 计算如下:
P r e c i s i o n = T P T P + F P Precision= \frac{TP}{TP+FP} Precision=TP+FPTP
def per_class_Precision(hist):
return np.diag(hist) / np.maximum(hist.sum(0), 1)
- 其中
np.diag(hist)为TP值,hist.sum(0)表示为TP+FP,np.maximum确保确保分母不为0
3.3 总体的Accuracy计算
总体的Accuracy计算如下:
A c c u r a c y = T P + T N T P + T N + F P + F N Accuracy = \frac{TP+TN}{TP+TN+FP+FN} Accuracy=TP+TN+FP+FNTP+TN
由于是多类别,没有负样本,因此TN为0。
def per_Accuracy(hist):
return np.sum(np.diag(hist)) / np.maximum(np.sum(hist), 1)
3.4 Recall 计算
recall指的是预测为Positive的样本,占所有Positive样本的比率
P r e c i s i o n = T P P Precision= \frac{TP}{P} Precision=PTP
def per_class_PA_Recall(hist):
return np.diag(hist) / np.maximum(hist.sum(1), 1)
- 每一行统计值为该类别样本的真实数量P, 因此
P = hist.sum(1)
3.5 MIOU计算
def compute_mIoU(gt_dir, pred_dir, png_name_list, num_classes, name_classes=None):
print('Num classes', num_classes)
#-----------------------------------------#
# 创建一个全是0的矩阵,是一个混淆矩阵
#-----------------------------------------#
hist = np.zeros((num_classes, num_classes))
#------------------------------------------------#
# 获得验证集标签路径列表,方便直接读取
# 获得验证集图像分割结果路径列表,方便直接读取
#------------------------------------------------#
gt_imgs = [join(gt_dir, x + ".png") for x in png_name_list]
pred_imgs = [join(pred_dir, x + ".png") for x in png_name_list]
#------------------------------------------------#
# 读取每一个(图片-标签)对
#------------------------------------------------#
for ind in range(len(gt_imgs)):
#------------------------------------------------#
# 读取一张图像分割结果,转化成numpy数组
#------------------------------------------------#
pred = np.array(Image.open(pred_imgs[ind]))
#------------------------------------------------#
# 读取一张对应的标签,转化成numpy数组
#------------------------------------------------#
label = np.array(Image.open(gt_imgs[ind]))
# 如果图像分割结果与标签的大小不一样,这张图片就不计算
if len(label.flatten()) != len(pred.flatten()):
print(
'Skipping: len(gt) = {:d}, len(pred) = {:d}, {:s}, {:s}'.format(
len(label.flatten()), len(pred.flatten()), gt_imgs[ind],
pred_imgs[ind]))
continue
#------------------------------------------------#
# 对一张图片计算21×21的hist矩阵,并累加
#------------------------------------------------#
hist += fast_hist(label.flatten(), pred.flatten(), num_classes)
# 每计算10张就输出一下目前已计算的图片中所有类别平均的mIoU值
if name_classes is not None and ind > 0 and ind % 10 == 0:
print('{:d} / {:d}: mIou-{:0.2f}%; mPA-{:0.2f}%; Accuracy-{:0.2f}%'.format(
ind,
len(gt_imgs),
100 * np.nanmean(per_class_iu(hist)),
100 * np.nanmean(per_class_PA_Recall(hist)),
100 * per_Accuracy(hist)
)
)
#------------------------------------------------#
# 计算所有验证集图片的逐类别mIoU值
#------------------------------------------------#
IoUs = per_class_iu(hist)
PA_Recall = per_class_PA_Recall(hist)
Precision = per_class_Precision(hist)
#------------------------------------------------#
# 逐类别输出一下mIoU值
#------------------------------------------------#
if name_classes is not None:
for ind_class in range(num_classes):
print('===>' + name_classes[ind_class] + ':\tIou-' + str(round(IoUs[ind_class] * 100, 2)) \
+ '; Recall (equal to the PA)-' + str(round(PA_Recall[ind_class] * 100, 2))+ '; Precision-' + str(round(Precision[ind_class] * 100, 2)))
#-----------------------------------------------------------------#
# 在所有验证集图像上求所有类别平均的mIoU值,计算时忽略NaN值
#-----------------------------------------------------------------#
print('===> mIoU: ' + str(round(np.nanmean(IoUs) * 100, 2)) + '; mPA: ' + str(round(np.nanmean(PA_Recall) * 100, 2)) + '; Accuracy: ' + str(round(per_Accuracy(hist) * 100, 2)))
return np.array(hist, np.int), IoUs, PA_Recall, Precision
- 首先创建一个维度为
(num_classes, num_classes)的空混淆矩阵hist - 遍历
pred_imgs和gt_imgs, 将遍历得到的每一张pred和label展平(flatten)到一维,输入到fast_hist计算单张图片预测的混淆矩阵,将每次的计算结果加到总的混淆矩阵hist中
for ind in range(len(gt_imgs)):
#------------------------------------------------#
# 读取一张图像分割结果,转化成numpy数组
#------------------------------------------------#
pred = np.array(Image.open(pred_imgs[ind]))
#------------------------------------------------#
# 读取一张对应的标签,转化成numpy数组
#------------------------------------------------#
label = np.array(Image.open(gt_imgs[ind]))
# 如果图像分割结果与标签的大小不一样,这张图片就不计算
if len(label.flatten()) != len(pred.flatten()):
print(
'Skipping: len(gt) = {:d}, len(pred) = {:d}, {:s}, {:s}'.format(
len(label.flatten()), len(pred.flatten()), gt_imgs[ind],
pred_imgs[ind]))
continue
#------------------------------------------------#
# 对一张图片计算21×21的hist矩阵,并累加
#------------------------------------------------#
hist += fast_hist(label.flatten(), pred.flatten(), num_classes)
- 每
计算10张就输出一下目前已计算的图片中所有类别平均的mIoU值
# 每计算10张就输出一下目前已计算的图片中所有类别平均的mIoU值
if name_classes is not None and ind > 0 and ind % 10 == 0:
print('{:d} / {:d}: mIou-{:0.2f}%; mPA-{:0.2f}%; Accuracy-{:0.2f}%'.format(
ind,
len(gt_imgs),
100 * np.nanmean(per_class_iu(hist)),
100 * np.nanmean(per_class_PA_Recall(hist)),
100 * per_Accuracy(hist)
)
)
- 遍历完成后,得到所有类别的Iou值
IoUs以及PA_Recall和Precision,并逐类别输出一下mIoU值
if name_classes is not None:
for ind_class in range(num_classes):
print('===>' + name_classes[ind_class] + ':\tIou-' + str(round(IoUs[ind_class] * 100, 2)) \
+ '; Recall (equal to the PA)-' + str(round(PA_Recall[ind_class] * 100, 2))+ '; Precision-' + str(round(Precision[ind_class] * 100, 2)))
- 最后在所有验证集图像上求所有类别平均的mIoU值
print('===> mIoU: ' + str(round(np.nanmean(IoUs) * 100, 2)) + '; mPA: ' + str(round(np.nanmean(PA_Recall) * 100, 2)) + '; Accuracy: ' + str(round(per_Accuracy(hist) * 100, 2)))
参考
- https://github.com/bubbliiiing/deeplabv3-plus-pytorch/blob/main/utils/utils_metrics.py
- https://github.com/dilligencer-zrj/code_zoo/blob/master/compute_mIOU
- https://www.jianshu.com/p/42939bf83b8a