LangChain 69 向量数据库Pinecone入门
LangChain系列文章
- LangChain 50 深入理解LangChain 表达式语言十三 自定义pipeline函数 LangChain Expression Language (LCEL)
- LangChain 51 深入理解LangChain 表达式语言十四 自动修复配置RunnableConfig LangChain Expression Language (LCEL)
- LangChain 52 深入理解LangChain 表达式语言十五 Bind runtime args绑定运行时参数 LangChain Expression Language (LCEL)
- LangChain 53 深入理解LangChain 表达式语言十六 Dynamically route动态路由 LangChain Expression Language (LCEL)
- LangChain 54 深入理解LangChain 表达式语言十七 Chains Route动态路由 LangChain Expression Language (LCEL)
- LangChain 55 深入理解LangChain 表达式语言十八 function Route自定义动态路由 LangChain Expression Language (LCEL)
- LangChain 56 深入理解LangChain 表达式语言十九 config运行时选择大模型LLM LangChain Expression Language (LCEL)
- LangChain 57 深入理解LangChain 表达式语言二十 LLM Fallbacks速率限制备份大模型 LangChain Expression Language (LCEL)
- LangChain 58 深入理解LangChain 表达式语言21 Memory消息历史 LangChain Expression Language (LCEL)
- LangChain 59 深入理解LangChain 表达式语言22 multiple chains多个链交互 LangChain Expression Language (LCEL)
- LangChain 60 深入理解LangChain 表达式语言23 multiple chains链透传参数 LangChain Expression Language (LCEL)
- LangChain 61 深入理解LangChain 表达式语言24 multiple chains链透传参数 LangChain Expression Language (LCEL)
- LangChain 62 深入理解LangChain 表达式语言25 agents代理 LangChain Expression Language (LCEL)
- LangChain 63 深入理解LangChain 表达式语言26 生成代码code并执行 LangChain Expression Language (LCEL)
- LangChain 64 深入理解LangChain 表达式语言27 添加审查 Moderation LangChain Expression Language (LCEL)
- LangChain 65 深入理解LangChain 表达式语言28 余弦相似度Router Moderation LangChain Expression Language (LCEL)
- LangChain 66 深入理解LangChain 表达式语言29 管理prompt提示窗口大小 LangChain Expression Language (LCEL)
- LangChain 67 深入理解LangChain 表达式语言30 调用tools搜索引擎 LangChain Expression Language (LCEL)
- LangChain 68 LLM Deployment大语言模型部署方案

这份指南解释了如何在几分钟内设置一个Pinecone向量数据库。
在您开始之前
- 如果您还没有注册,请先免费注册一个Pinecone账户。
笔者注册的Pinecone账户
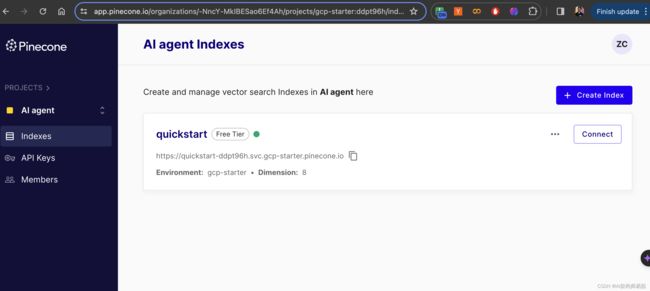
在免费的入门计划中,您可以获得一个项目和一个索引,这些资源足够您测试Pinecone以及运行小型应用程序。尽管入门计划不支持所有Pinecone功能,但当您准备好时,升级是很简单的。
- 如果您更愿意在浏览器中开始,请使用 “Hello, Pinecone!” colab notebook.
1. 安装Pinecone客户端
Pinecone提供了一个简单的REST API,用于与您的向量数据库进行交互。您可以直接使用这个API,也可以使用官方的Pinecone客户端之一:
pip install pinecone-client
当前,Pinecone支持Python客户端和Node.js客户端。有关社区支持的客户端和其他客户端资源,请参阅 Libraries。
2. 获取您的API密钥
您需要一个API密钥和环境名称来对您的Pinecone项目进行API调用。要获取您的密钥和环境,请按照以下步骤操作:
- 打开Pinecone控制台。
- 前往API密钥。
- 复制您的API密钥和环境。
3. 3. 初始化您的连接
使用您的API密钥和环境,初始化您对Pinecone的客户端连接:
import pinecone
pinecone.init(api_key="YOUR_API_KEY", environment="YOUR_ENVIRONMENT")
备注:
使用API时,每个HTTP请求都必须包含一个指定您的API密钥的Api-Key头,而且您的环境必须在URL中指定。在所有后续的curl示例中,您都会看到这一点。
4. 创建索引
在Pinecone中,你可以在索引中存储向量嵌入。在每个索引中,向量具有相同的维度和用于测量相似度的距离度量。
创建一个名为“quickstart”的索引,该索引使用欧几里得距离度量对8维向量进行最近邻搜索:
pinecone.create_index("quickstart", dimension=8, metric="euclidean")
pinecone.describe_index("quickstart")
5. 插入向量
现在您已经创建了索引,接下来将样本向量插入到两个不同的命名空间中。
命名空间允许您在单个索引中划分向量。尽管这是可选的,但它是加速查询的最佳实践,查询可以通过命名空间进行过滤,同时也符合多租户要求。
- 创建一个针对“quickstart”索引的客户端实例:
index = pinecone.Index("quickstart")
- 使用upsert操作将8个8维向量写入2个不同的命名空间:
index.upsert(
vectors=[
{"id": "vec1", "values": [0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1]},
{"id": "vec2", "values": [0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0.2]},
{"id": "vec3", "values": [0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3]},
{"id": "vec4", "values": [0.4, 0.4, 0.4, 0.4, 0.4, 0.4, 0.4, 0.4]}
],
namespace="ns1"
)
index.upsert(
vectors=[
{"id": "vec5", "values": [0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5]},
{"id": "vec6", "values": [0.6, 0.6, 0.6, 0.6, 0.6, 0.6, 0.6, 0.6]},
{"id": "vec7", "values": [0.7, 0.7, 0.7, 0.7, 0.7, 0.7, 0.7, 0.7]},
{"id": "vec8", "values": [0.8, 0.8, 0.8, 0.8, 0.8, 0.8, 0.8, 0.8]}
],
namespace="ns2"
)
注释:
当插入较大量的数据时,应将数据分批次进行,每批不超过100个向量,通过多次插入请求完成。
6. 检查索引
Pinecone数据库最终是一致的,因此在您的向量对查询可见之前可能会有延迟。使用 describe_index_stats 操作来检查当前向量计数是否与您插入的向量数量相匹配:
index.describe_index_stats()
# Returns:
# {'dimension': 8,
# 'index_fullness': 8e-05,
# 'namespaces': {'ns1': {'vector_count': 4}, 'ns2': {'vector_count': 4}},
# 'total_vector_count': 8}
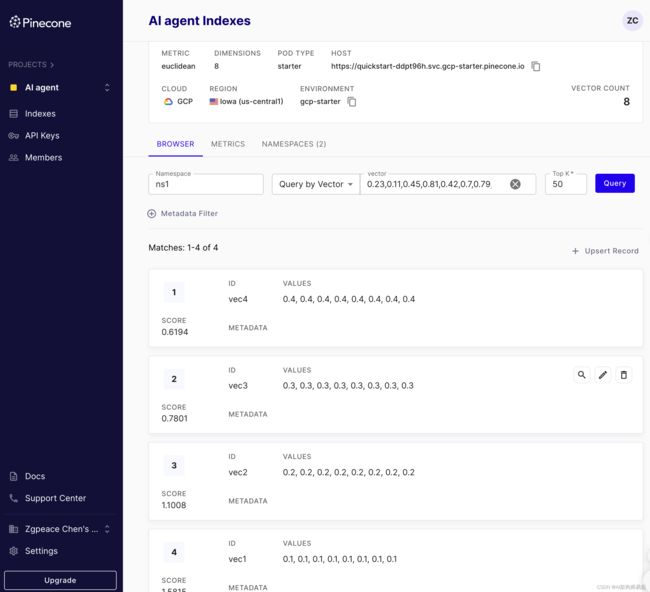
7. 运行相似性搜索
使用您为索引指定的欧几里得距离度量,查询索引中的每个命名空间,以找到与一个示例8维向量最相似的3个向量:
index.query(
namespace="ns1",
vector=[0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3],
top_k=3,
include_values=True
)
index.query(
namespace="ns2",
vector=[0.7, 0.7, 0.7, 0.7, 0.7, 0.7, 0.7, 0.7],
top_k=3,
include_values=True
)
# Returns:
# {'matches': [{'id': 'vec3',
# 'score': 0.0,
# 'values': [0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3]},
# {'id': 'vec4',
# 'score': 0.0799999237,
# 'values': [0.4, 0.4, 0.4, 0.4, 0.4, 0.4, 0.4, 0.4]},
# {'id': 'vec2',
# 'score': 0.0800000429,
# 'values': [0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0.2]}],
# 'namespace': 'ns1'}
# {'matches': [{'id': 'vec7',
# 'score': 0.0,
# 'values': [0.7, 0.7, 0.7, 0.7, 0.7, 0.7, 0.7, 0.7]},
# {'id': 'vec6',
# 'score': 0.0799999237,
# 'values': [0.6, 0.6, 0.6, 0.6, 0.6, 0.6, 0.6, 0.6]},
# {'id': 'vec8',
# 'score': 0.0799999237,
# 'values': [0.8, 0.8, 0.8, 0.8, 0.8, 0.8, 0.8, 0.8]}],
# 'namespace': 'ns2'}
这是一个简单的例子。随着您对松果的要求增加,您会发现它在巨大的规模上返回低延迟、准确的结果,拥有高达数十亿向量的索引。
8. 清理
入门计划仅允许一个索引,因此一旦你完成了“quickstart”索引,使用 delete_index 操作来删除它:
pinecone.delete_index("quickstart")
代码
https://github.com/zgpeace/pets-name-langchain/tree/develop
参考
https://docs.pinecone.io/docs/quickstart