数据结构和算法
# 数据结构与算法绪论
世界上没有最好的算法,只有最合适的算法


逻辑结构
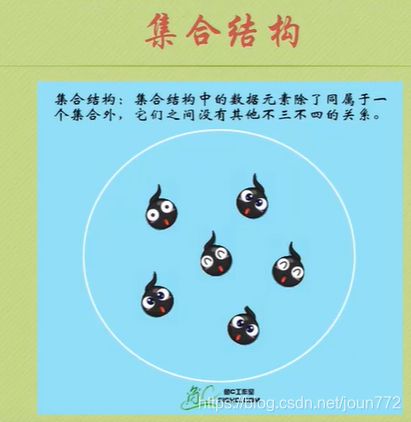
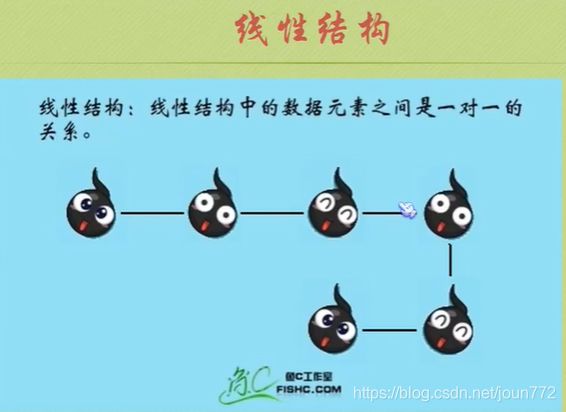
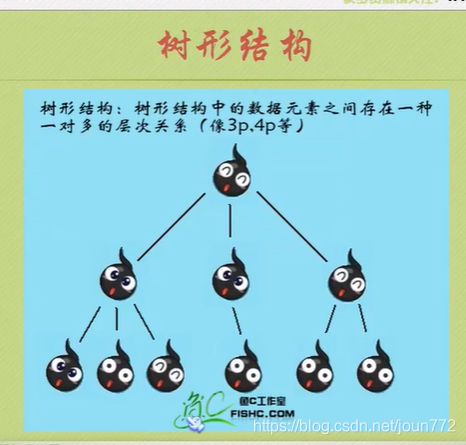
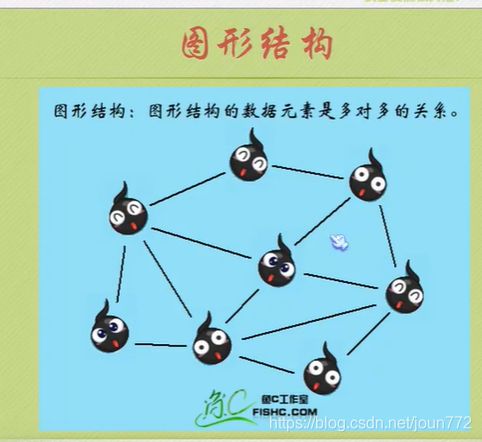
物理结构





谈谈算法









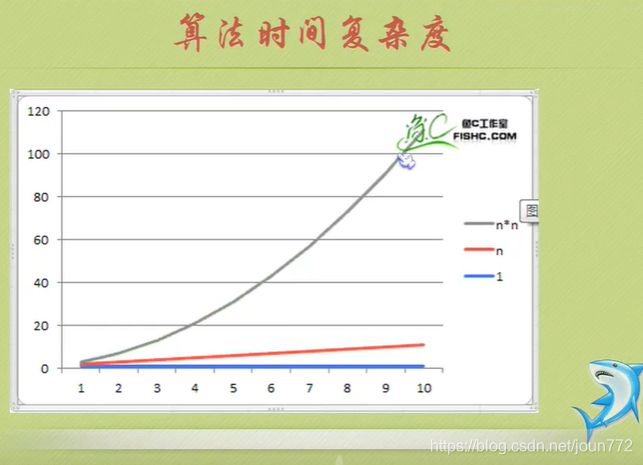
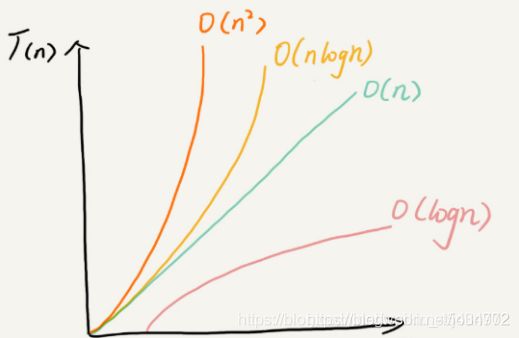
算法时间复杂度




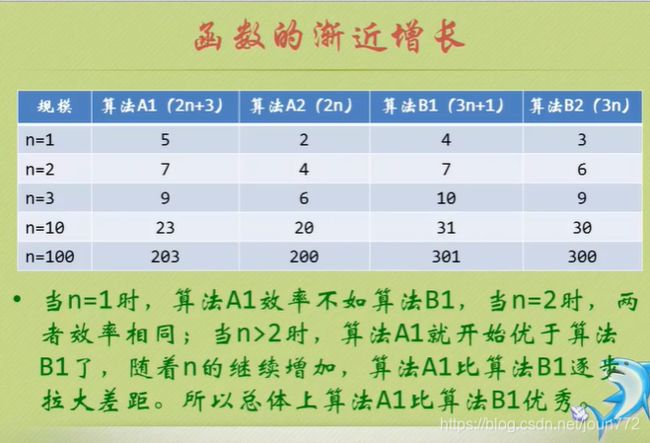
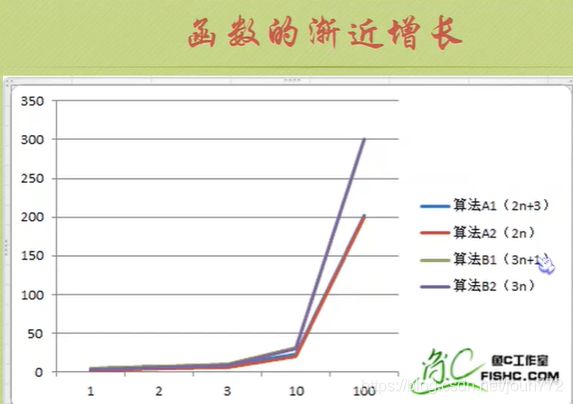

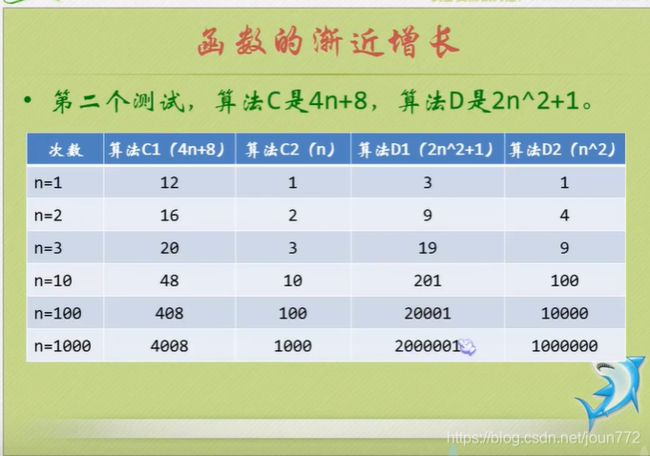
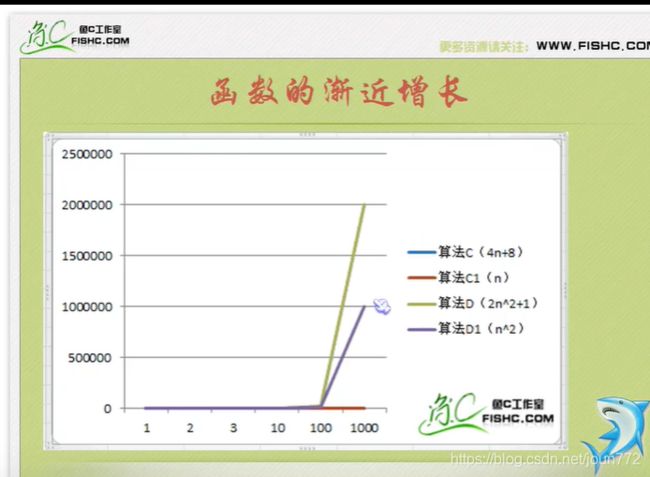

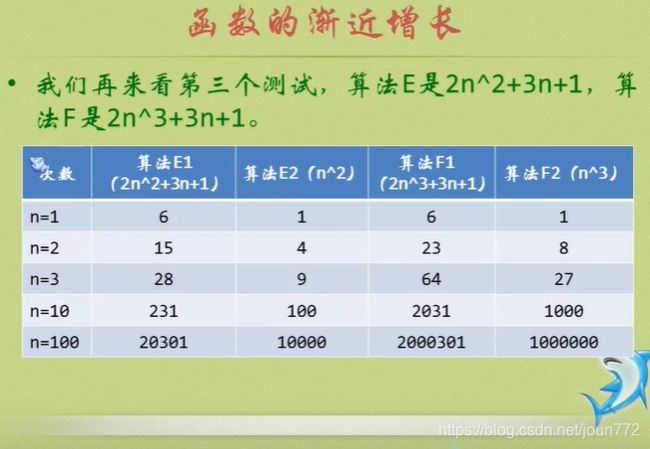
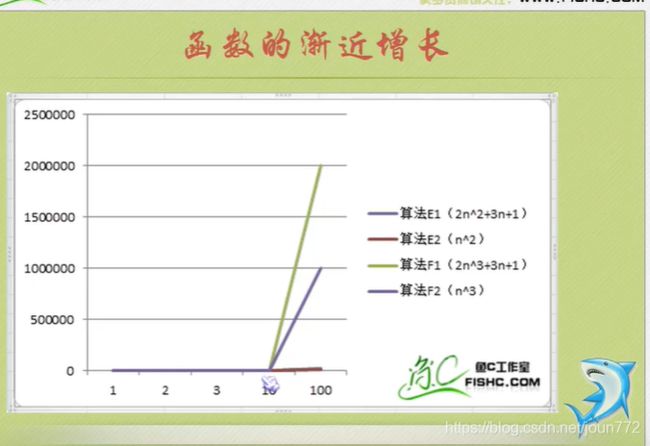

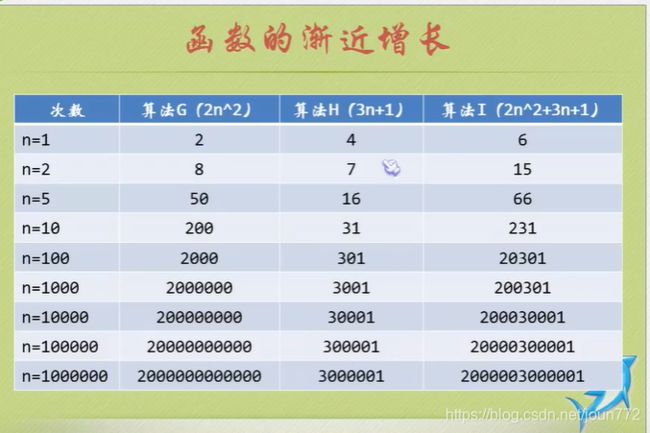
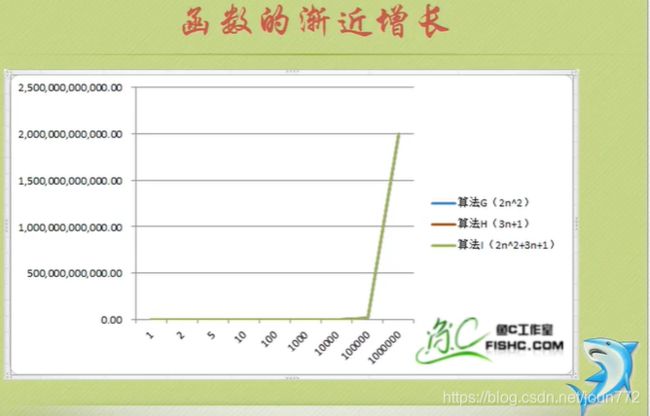
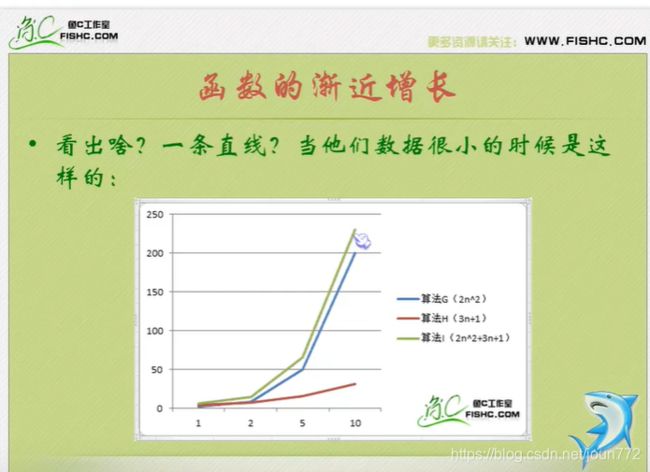

就是告诉你要注重看最高阶次,然后常数和阶次的常数乘积忽略掉,注意数据要足够多。

执行次数就是时间















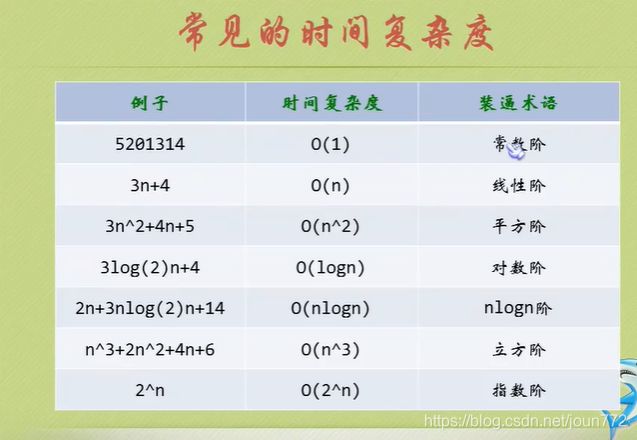
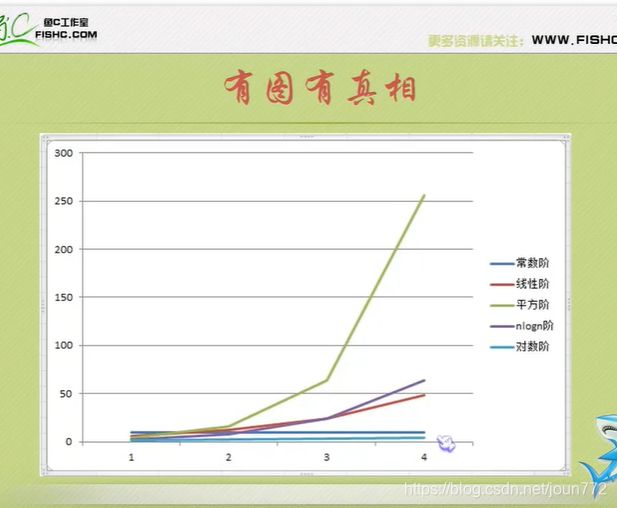



算法空间复杂度



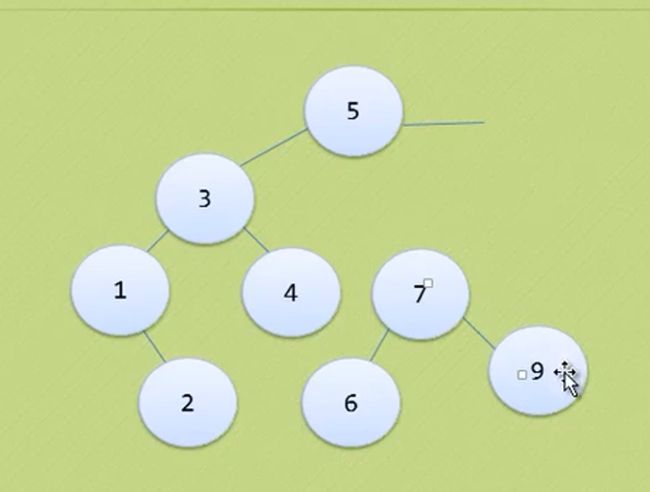
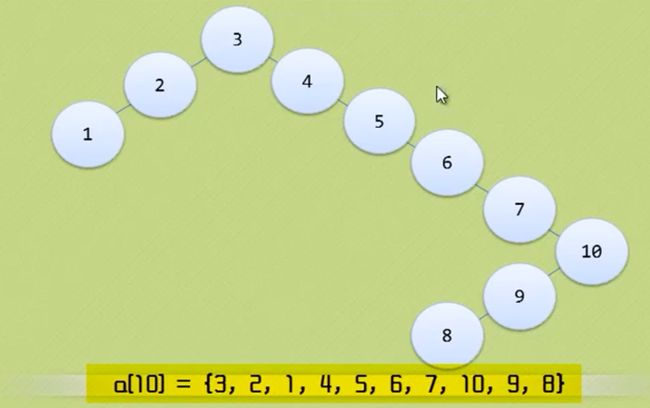
线性表





抽象数据类型










void unionL(List* La, List* Lb)//此伪代码是来依次将Lb中与La不同的数据插入到La的后面
{
int La_len, Lb_len, i;
ElemType e;
La_len = ListLength(*La);
Lb_len = ListLength(*Lb);
for (int i=1;i<=Lb_len;i++)//这里写成一因为只是数据结构算法重点是过算法流程,而不是让编译器看懂
{
GetElem(Lb, i, &e);
if (!Locate(*La,e))
{
ListInsert(La, ++La_len, e);
}
}
}
线性表的顺序存储结构



地址计算方法


这里应该是O(1),而不是0(1)。
获得元素操作


typedef int Status;
Status GetElem(Sqlist L,int i,ElemType *e)
{
if (L.length == 0 || i<i || i>L.length)//线性表从1开始
{
return ERROR;
}
*e = L.data[i - 1];
return OK;
}
插入操作



Status ListInsert(Sqlist *L, int i, ElemType e)
{
int k;
if (L->length == MAXSIZE)//顺序表已经满了
{
return ERROR;
}
if (i<1 || i>L->length + 1)//i不在范围内
{
return ERROR;
}
if (i <= L->length)
{
for (k = L.length - 1; k >= i - 1; k--)
{
L->data[k + 1] = L->data[k];//元素后移
}
}
L->data[i - 1] = e;
L->length++;
return OK;
}
删除操作

//删除
//输出L的第i个元素,并用e来返回删除的值。
Status ListDelete(Sqlist* L, int i, ElemType e)
{
if (L - length == 0)
{
return ERROR;
}
if (i<1 || i>L->length )//i不在范围内
{
return ERROR;
}
e = L->data[i - 1];
if (i <= L->length)
{
for (k = i; k < L->length; k++)
{
L->data[k - 1] = L - data[k];
}
}
L->length--;
return e;
}

线性表顺序存储结构的优缺点


线性表的链式储存结构




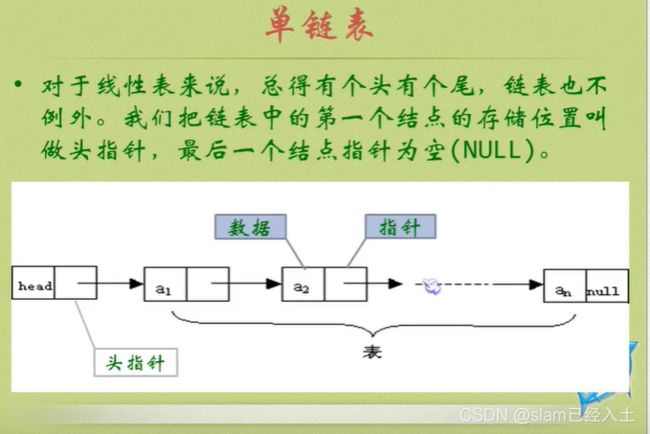



可以看到空指针指向头节点。
头节点后面的节点才是真正存放数据的。



单链表读取

//获取
Satus GetElem(LinkList *L, int i, ElemType* e)
{
int j;
LinkList p;
p = L->next;//p指向第一个节点
j = 1;
while (p && j < i)//跳出循环的时候,正常情况下应该是i==j
{
p = p->next;
++j;
}
if (p! || j > i)//如果p指向空或者你想要查找的根本不存在
{
return ERROR;
}
*e = p->data;
return OK;
}

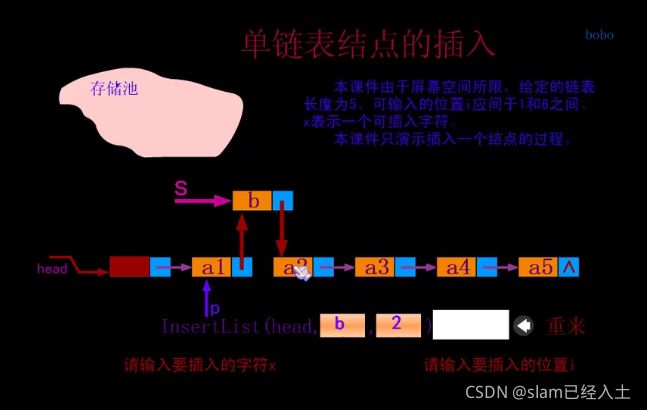
单链表插入

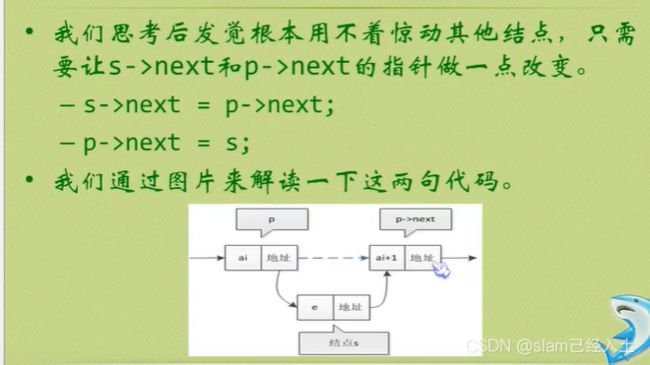


//单链表插入
//在L中第i个位置之后插入新的元素e,L的长度加1
Status ListInsert(LinkList* L, int i, ElemType* e)
{
int j;
LinkList* p;
LinkList* s;
p = L->next;//p指向第一个节点
j = 1;
while (p && j < i)//跳出循环的时候,正常情况下应该是i==j
{
p = p->next;
++j;
}
if (p!|| j > i)//如果p指向空或者你想要查找的根本不存在
{
return ERROR;
}
s = (LinkList)malloc(sizeof(Node));//分配一个内存空间给新的节点S
s->data = *e;
//下面两句千万不能写反,前面ptt有讲这个后果。
s->next = p->next;
p->next = s;
return OK;
}
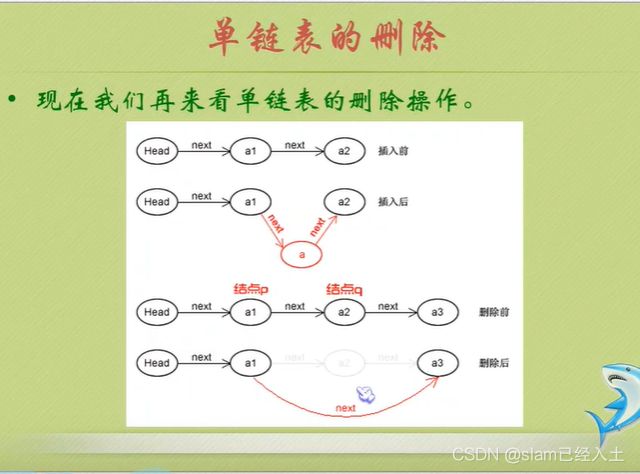


//单链表删除
//删除第i个Node 并把里面的data返回
Status ListDelete(LinkList* L, int i, ElemType* e)
{
int j;
LinkList* p;
LinkList* q;
p = L->next;//p指向第一个节点
j = 1;
while (p && j < i-1)//跳出循环的时候、
{
p = p->next;
++j;
}
if (p!|| j > i)//如果p指向空或者你想要查找的根本不存在
{
return ERROR;
}
q = p->next;//q指向第i个节点
p -> next = q -> next;
*e = q->data;
delete q;
return OK;
}
效率PK


可以看到单链表在插入删除多个数据的时候优势明显大于顺序存储结构。
单链表的整表创建


头插法建立单链表


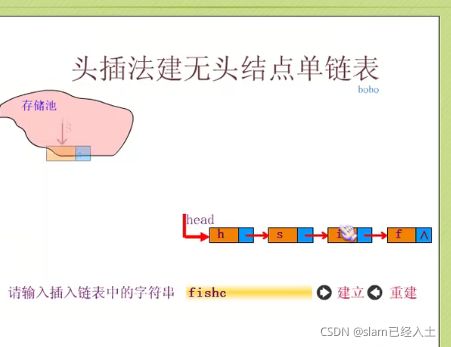
在这里插入代码片
//单链表头插
void CreateListHead(LinkList* L, int n)
{
LinkList p;
int i;
srand(time(0));//初始化随机数种子
*L = (LinkList)malloc(sizeof(Node));
(*L)->next = NULL;
for (int i = 0; i < n; i++)
{
p = (LinkList)malloc(sizeof(Node));//生成新节点
p->data = rand() % 100 + 1;
p->next = (*L)->next;
(*L)->next = p;
}
}
//这里面为什么 *L 另一个则是p ,说明L是二级指针,函数传进来的是*L,我们直接认为*L是指向链表的指针就行了
//这个代码是头插,但是表头*L还是在最前面。
代码流程图
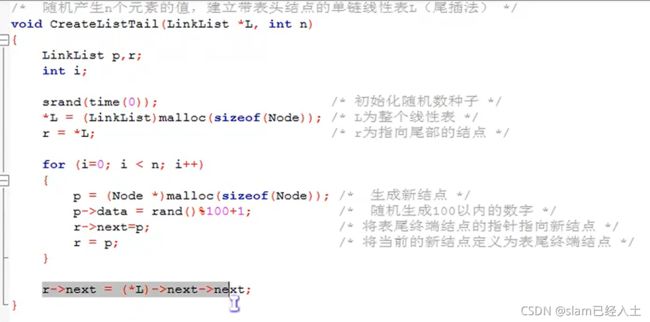
尾插法建立单链表



//单链表尾插
void CreateListTail(LinkList* L, int n)
{
LinkList p,r;
int i;
srand(time(0));//初始化随机数种子
*L = (LinkList)malloc(sizeof(Node));
r = *L;
for (int i = 0; i < n; i++)
{
p = (Node *)malloc(sizeof(Node));//生成新节点
p->data = rand() % 100 + 1;
r->next = p;
r = p;
}
r->next = NULL;
}
代码流程
单链表的整表删除

//单链表整表删除
Status ClearList(LinkList* L)
{
LinkList p, q;
p = (*L)->next;//p指向第一个节点
while (p)
{
q = p->next;
free(p);
p = q;
}
(*L)->next = NULL;
return OK;
}

单链表结构和顺序存储结构的优缺点


对于查找来说,顺序存储结构有下标,一下就找到了。单链表要一个一个找,因为下一个节点的地址要从上一个节点的next来找寻。
插入删除就很明显了,因为顺序存储结构要对其他元素移位,而单链表只需移动指针指向。



回顾


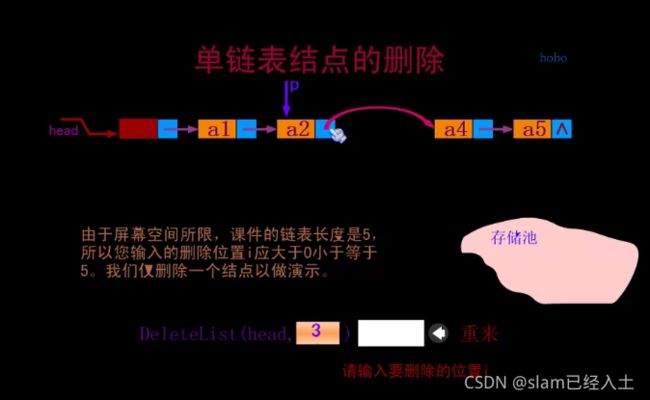
静态链表







游标指向下一个下标
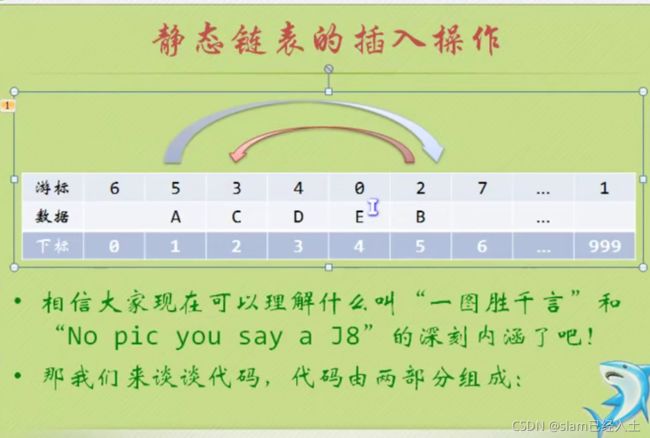

就是第一个space的游标指向空闲space的下标。
也就是最开始第一个space里面的游标是5,也就是下标为5的space是空闲,之后再让第一个space的游标变成6.
最后一个非空闲space用的游标用0表示


静态链表的插入操作
首先获得空闲元素的下标

//在静态链表L中的第i个元素之前插入新的元素e
//这里面代码理解难一点,结合下面的图比较好理解
Status ListInsert(StaticLinkList L.int i,ElemType e)
{
int j, k, l;
k = MAX_SIZE - 1;//最后一个元素,最后一个元素的游标是第1个元素的的下标
if (i<1 || i>ListLength(L)+1)//i超出正常范围
{
return ERROR;
}
j = Mlloc_SLL(L);//获得空闲元素的下标
if(j)
{
L[j].data = e;
for (l=1;l<=i-1;l++)
{
k = L[k].cur;
}
L[j].cur = L[k].cur;
L[k].cur = j;
return OK;
}
return ERROR;
}
代码流程
以 i=2 为例




静态链表的删除操作



//删除L中的第i个元素
Status ListDelete(StaticLinkList L.int i)
{
int j, k;
if (i<1 || i>ListLength(L) + 1)//i超出正常范围
{
return ERROR;
}
k = MAXSIZE - 1;
for (j = 1; j <= i - 1; j++)
{
k = L[k].cur;//k1 =1.k2=5
}
j = L[k].cur;//j=2
L[k].cur = L[j].cur;//L[5].cur=3
Free_SLL(L.j);//这里是把备用空闲元素连接起来
return OK;
}
//将下标为k的空闲节点会受到备用链表
void Free_SLL(StaticLinkList space,int k)
{
space[k].cur = space[0].cur;
space[0].cur = k;
}
//返回L中元素个数
int ListLength(StaticLinkList L)
{
int j = 0;
int i = L[MAXSIZE - 1].cur;
while (i)
{
i = L[i].cur;
j++
}
rturn j;
}
代码流程





静态链表的优缺点
单链表小结 腾讯面试题

//腾讯面试题,找到中间节点
Status GetMidNode(LinkList L.ElemType* e)
{
LinkList search, mid;
search = mid = L;
while (search->next!=NULL)
{
if (search->next->next != NULL)
{
search = search->next->next;
mid = mid->next;
}
else
{
search = search->next;
}
}
*e = mid->data;
return OK;
}

循环链表




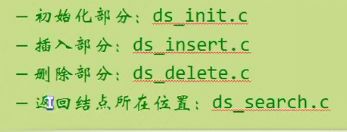
//循环链表
#include约瑟夫问题


#include 循环链表的特点



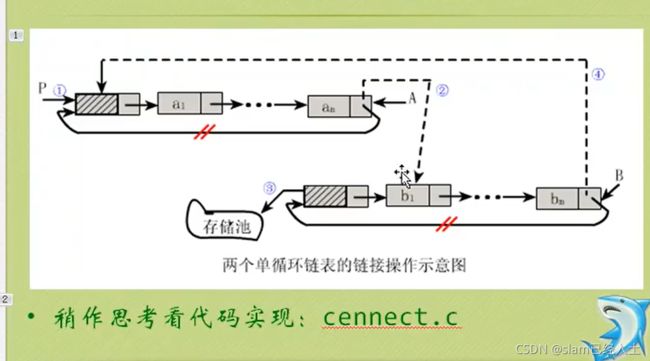

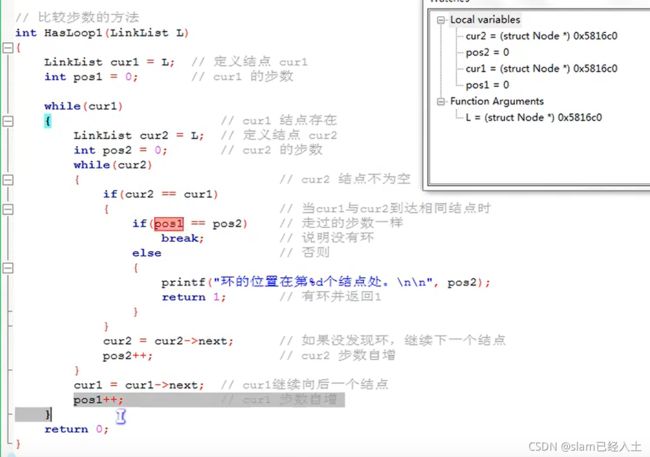
判断链表是否有环
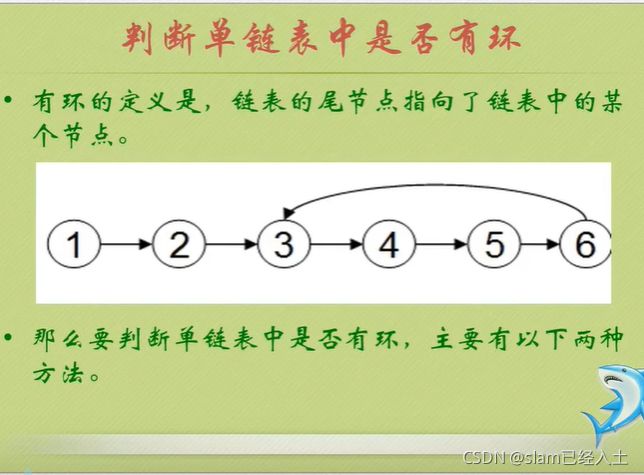


两种方法的代码实现


整体代码—还未完成
#include魔术师发牌
![]()




代码如下:
#include 拉丁方阵问题–作业

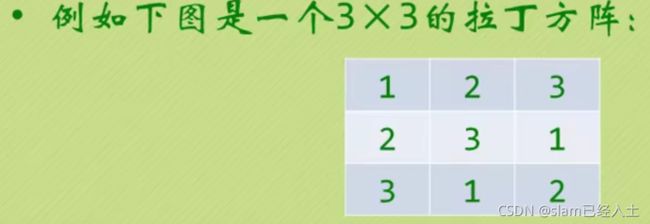

其实就是按照环的顺序打印出来.
代码如下。我把发牌和拉丁方阵放在一个文件里实现的。
#include data<<" ";
p=p->next;
}*/
int count=0;
for(int k=0;k<n;k++)
{
for(int l=0;l<n;l++)
{
cout<<p->data;
p=p->next;
}
p=head;
count++;
for(int m=0;m<count;m++)
{
p=p->next;
}
cout<<endl;
}
}
/**
* 拉丁矩阵问题test
* @return
*/
void LatinMatrix_Problem()
{
LinkList p;
int n;
cout<<"请输入拉丁方阵的维数:"<<endl;
cin>>n;
p=CreatLinkList(n);
LatinMatrix(p,n);
cout<<endl;
//DestoryList(&p);
}
int main() {
int choice=1;
while(choice)
{
cout<<"选择发牌问题请输入1"<<endl;
cout<<"选择拉丁矩阵问题请输入2"<<endl;
cout<<"退出请输入0"<<endl;
cin>>choice;
switch (choice) {
case 1 :
Magician_Problem();
break;
case 2 :
LatinMatrix_Problem();
break;
case 0 :
exit(0);
break;
}
}
return 0;
}
双向链表


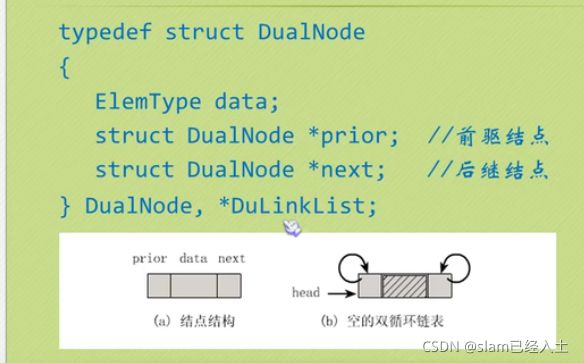
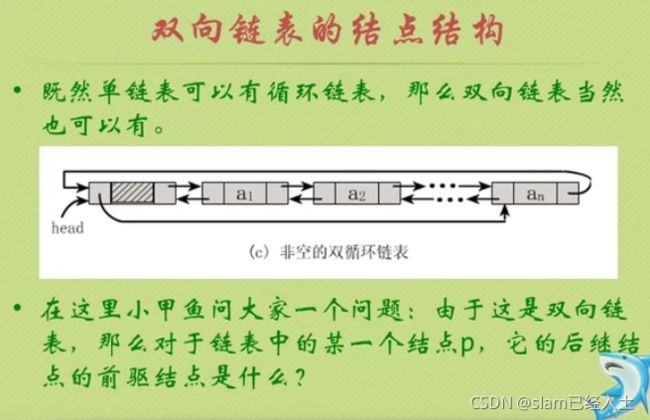
双向链表的插入


双向链表的删除
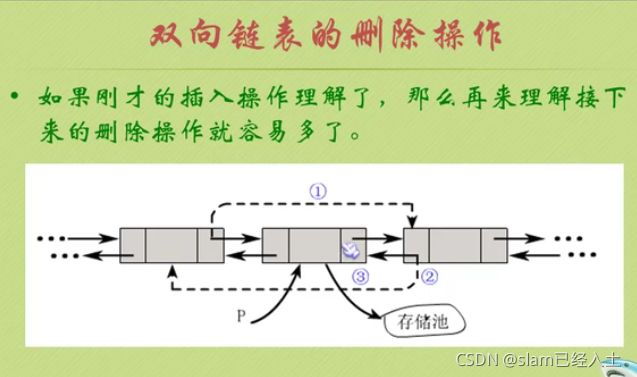


双线循环链表实践


#include Vingenre加密–作业

代码如下,我把Vigenere和字母表排序的问题放在一起了。
#include
//直接把密文和密匙放在容器里
for(int i=0;i<26;i++)
{
//int m=(p->data)-'A';//明文对应的序号
int n=i+mmWem_[i].mishi;//得到密匙对应字母序号
for(int j=0;j<n;j++)//找到密文对应的节点
{
p=p->next;
}
mmWem_[i].miwen=p->data;
p=L->next;//p重新指向字母A
}
for(auto a:mmWem_)
{
cout<<"密文:"<<a.miwen<<" "<<"密匙:"<<a.mishi;
cout<<endl;
}
char c;
cout<<"按0退出!!!"<<endl;
cout<<"输入明文:"<<endl;
while(1)
{
cin>>c;
if(c=='0')
{
break;
}
else
{
int m=c-'A';//明文对应的序号
for(int i=0;i<m;i++)//找到明文的位置
{
p=p->next;
}
cout<<"明文"<<p->data<<" "<<"密文:"<<mmWem_[m].miwen<<" "<<"密匙:"<<mmWem_[m].mishi;
p=L->next;
}
cout<<endl;
cout<<endl;
cout<<"按0退出!!!"<<endl;
cout<<"输入明文:"<<endl;
}
}
int main() {
int choice=1;
while(choice)
{
cout<<endl;
cout<<"选择字母表输出问题请输入1"<<endl;
cout<<"选择Vingenre加密问题请输入2"<<endl;
cout<<"退出请输入0"<<endl;
cin>>choice;
switch (choice) {
case 1 :
alpha_cout();
break;
case 2 :
Vingenre();
break;
case 0 :
exit(0);
break;
}
}
return 0;
}
栈和队列

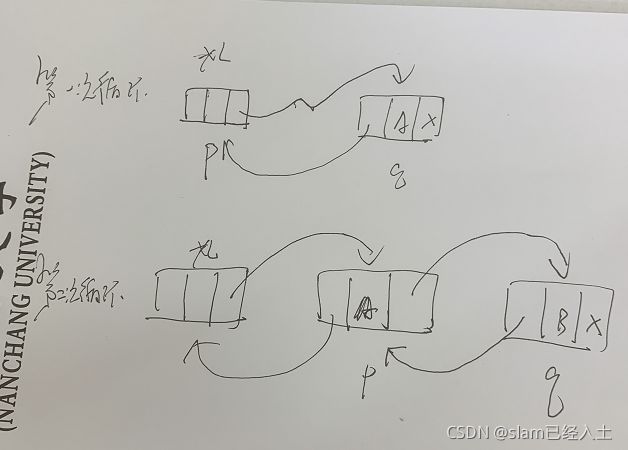
栈的定义
按三次push
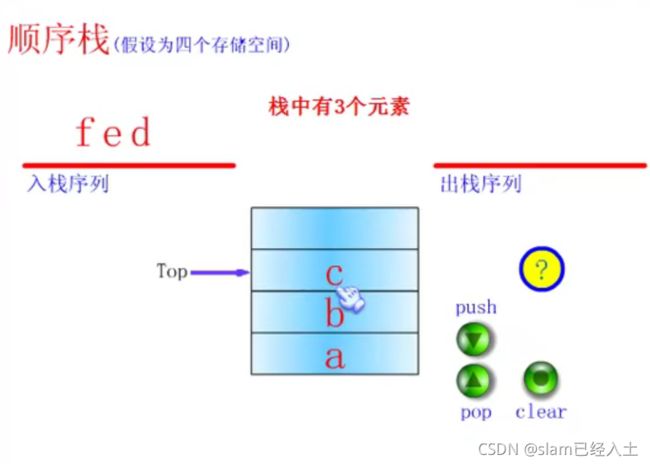
按一下pop
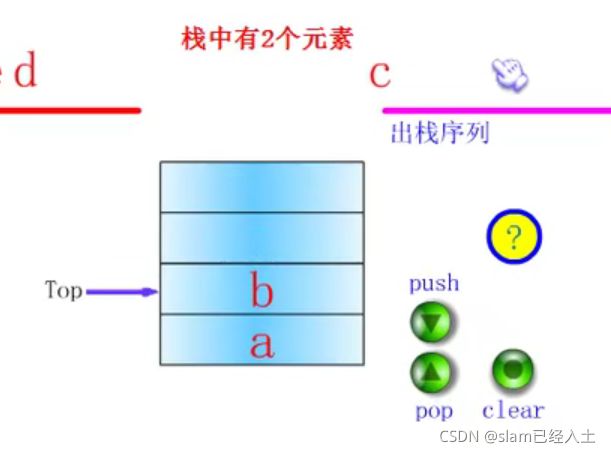

栈的顺序存储结构




入栈操作


出栈操作

栈顶的位置是没数据的,是准备存放数据的。




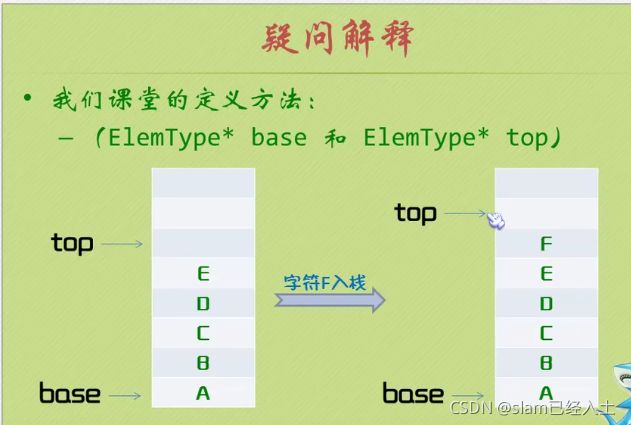


清空栈

销毁栈



实例



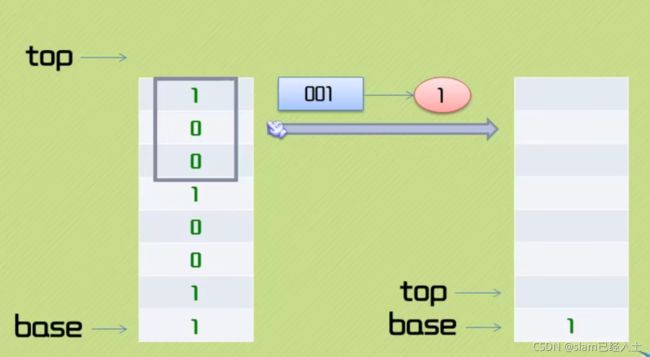

代码如下:
#include 栈的链式存储结构

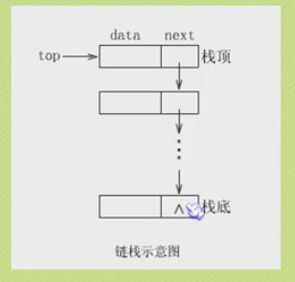

链式栈的入栈

链式栈的出栈

实践



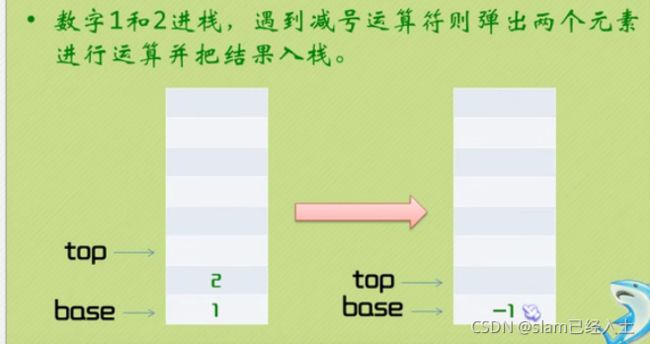

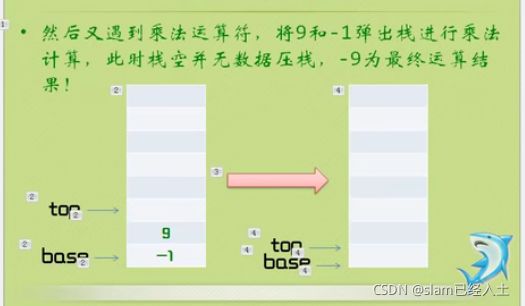
逆波兰计算器

目前这个代码在自己的电脑运行存在问题,这个和小甲鱼的代码是一样实现的,但是不知道哪里出错了。
找到问题了,是输入语句的问题,不能用cin,因为cin自动忽略了空格,我操了!
参考博客
#include 下面是正确代码:
#include 中缀表达式变为后缀表达式


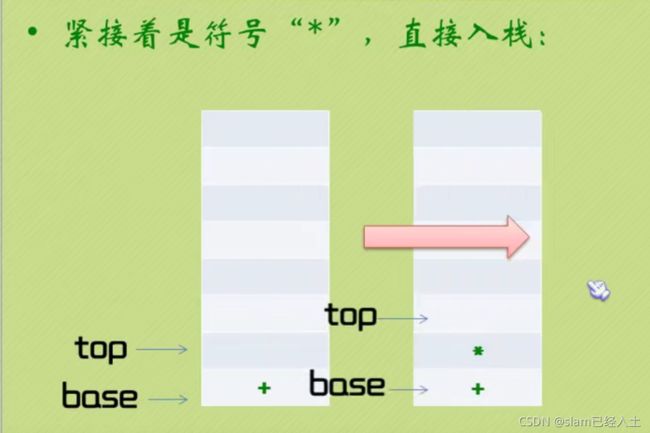
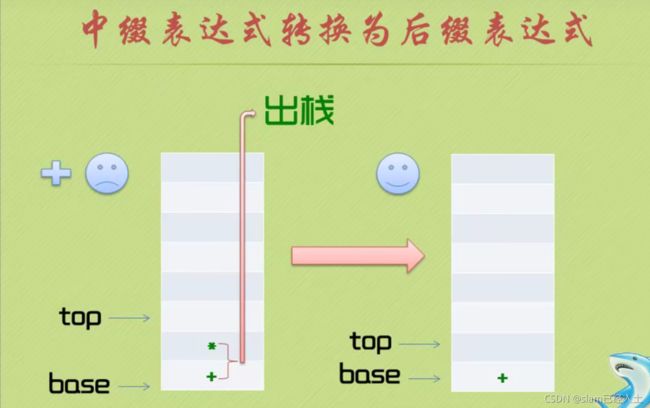
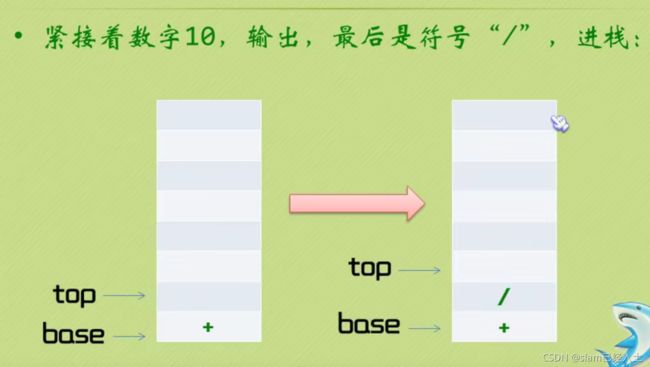
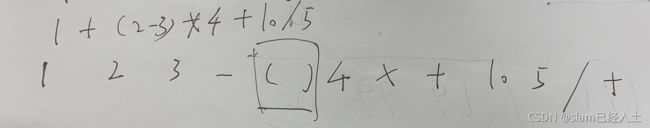

中缀表达式转为后缀表达式+逆波兰计算器完整代码如下:
#include 队列queue

创建一个队列
入队列操作


出队列操作
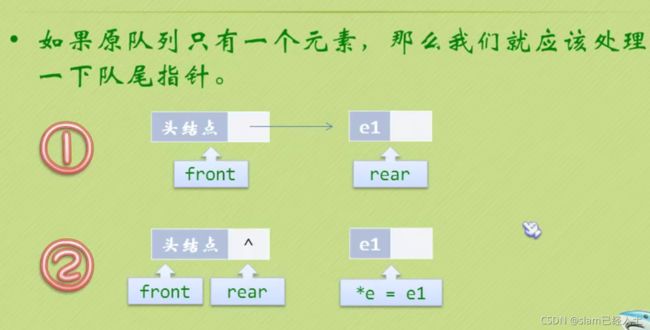

销毁一个队列
#include 队列的顺序存储
循环队列
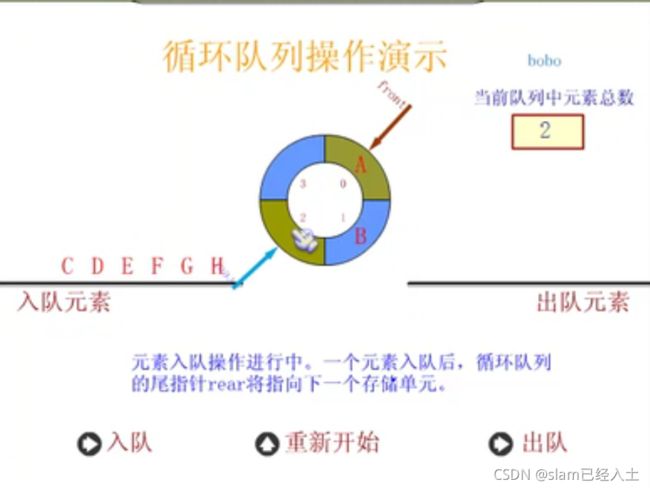
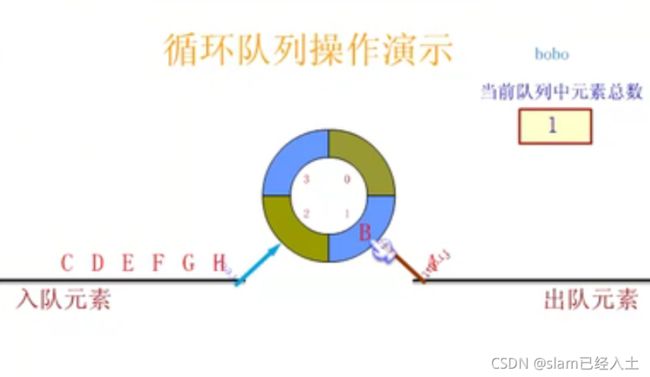
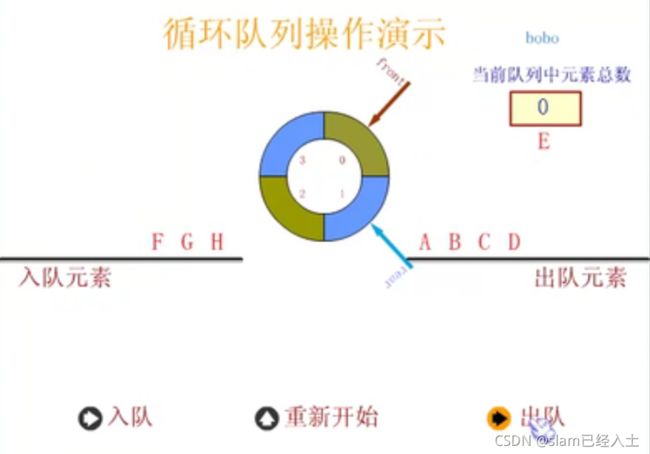
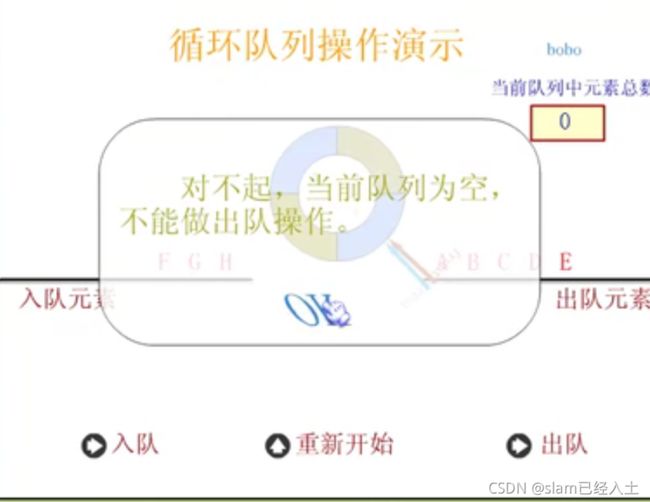
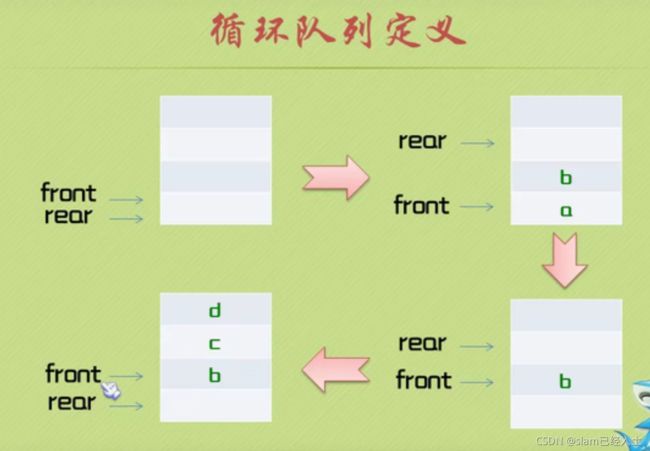
定义循环队列
初始化循环队列

入队列操作



#include 递归和分治


斐波那契数列的递归实现
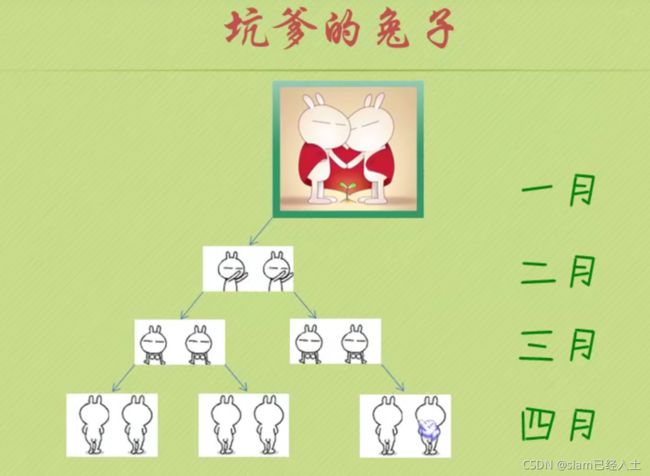



#include 递归定义



实例


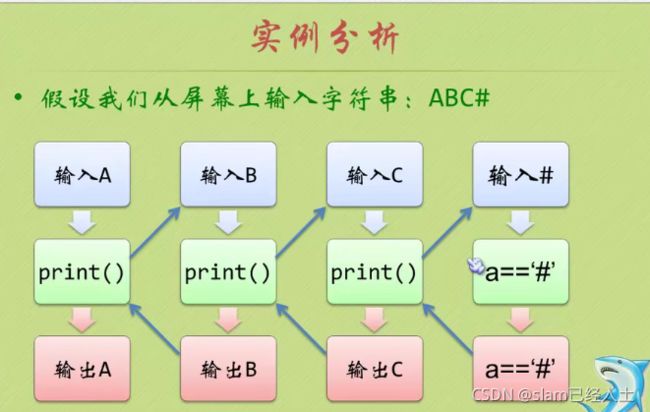
void DiGui_StrInverse()
{
char c;
scanf("%c",&c);
if('#'!=c) DiGui_StrInverse();
if('#'!=c) cout<<c;
}
分治思想

折半查找法的递归实现



#include
//DiGui_StrInverse();
//二分查找递归
int str[11] = {1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89};
int n, addr;
printf("请输入待查找的关键字: ");
scanf("%d", &n);
addr= binary_Search_DiGui(str,0,10,n);
if( -1 != addr )
{
printf("查找成功,可喜可贺,可口可乐! 关键字 %d 所在的位置是: %d\n", n, addr);
}
else
{
printf("查找失败!\n");
}
return 0;
}
汉诺塔






#include //以三层汉诺塔为例,递归的流程如下:
3 x y z
{
2 x z y
{
1 x y z x-->z
x-->y
1 z x y z-->y
}
x-->z
2 y x z
{
1 y z x y-->x
y-->z
1 x y z x-->z
}
}
//最终的结果是:
x-->z
x-->y
z-->y
x-->z
y-->x
y-->z
x-->z
无论多少层数,本质上它都可以递归到1的时候,然后返回到2,再一次返回到n-1。
八皇后问题

#include 下面是完整的递归分治代码:
#include 字符串


字符串的存储结构
BF算法
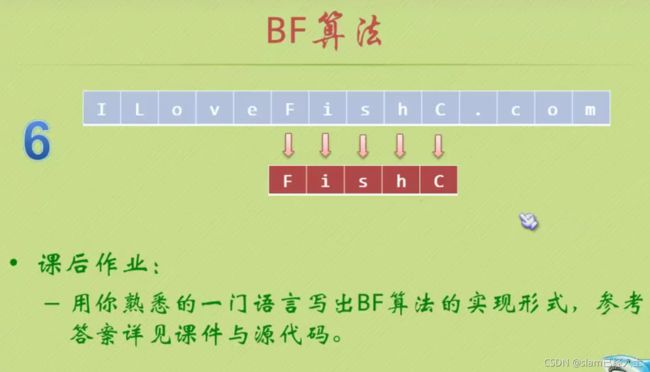
#include <<endl;
}
return 0;
}
KMP算法
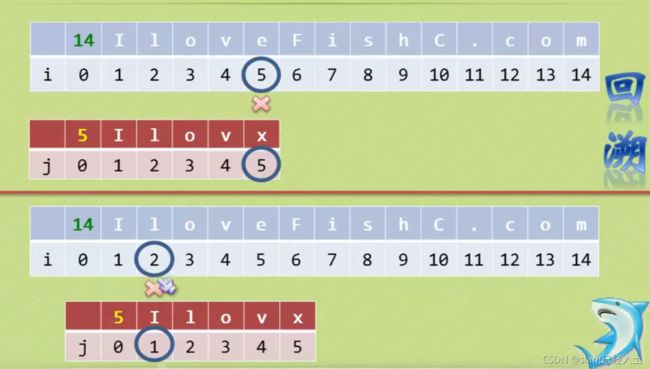



不需要回溯 i
在判断到不等的时候,模式串前面没有一样的字符,,回溯从1开始

模式串里有两个相等的字符,回溯从2开始
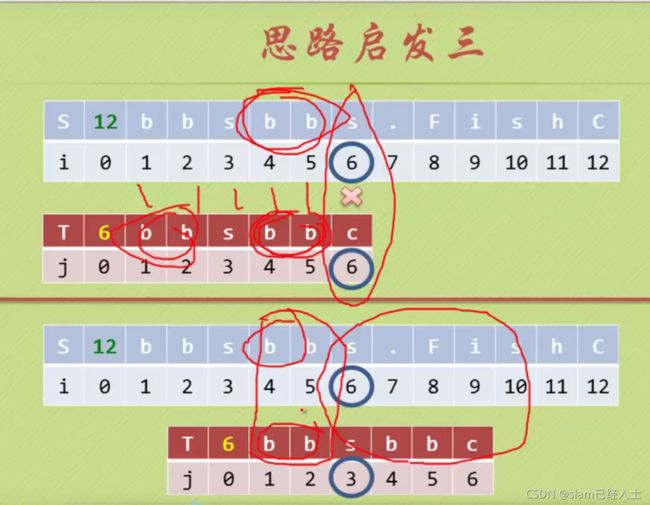
模式串里有一对相等的字符,回溯从2开始
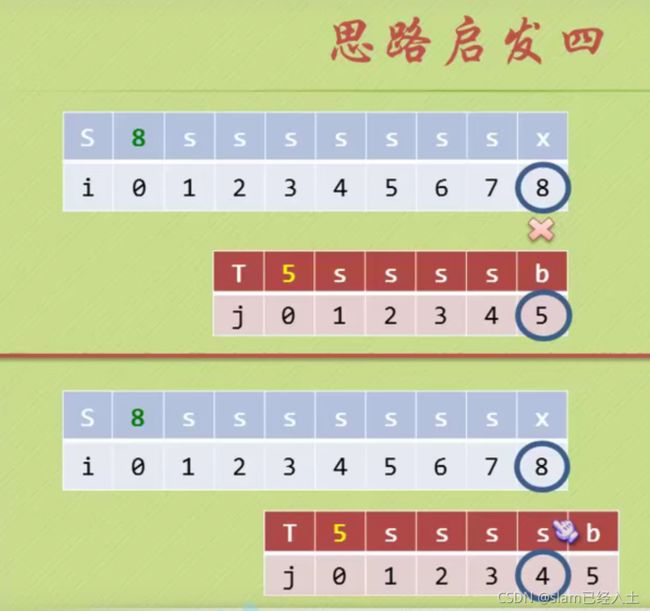



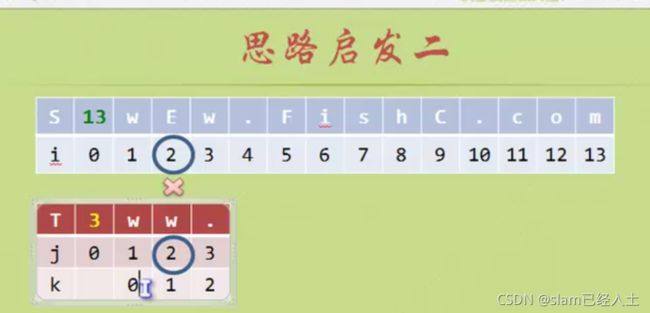
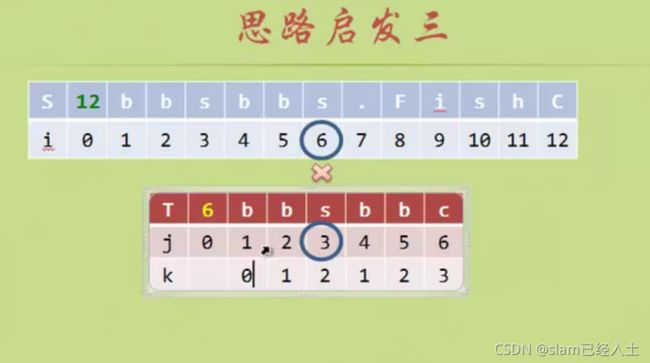
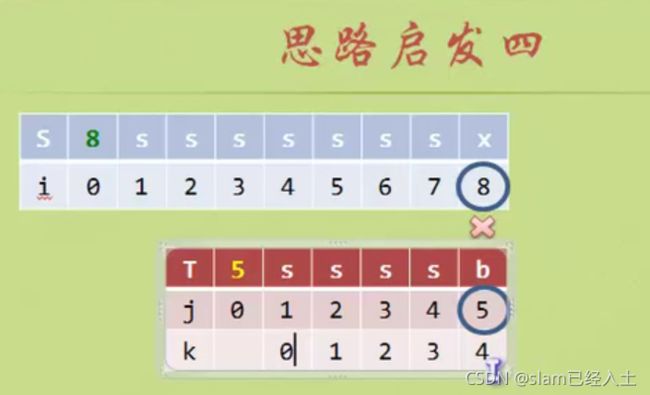

就是匹配到不等的时候,起始A到匹配不等的前一个位置构成的字符串的前缀和后缀有几个相等的字符,加入n个相等字符,那么 j 就从n+1的位置开始。(前缀后缀从位置上来说不是一个字符串)
KMP算法之NEXT数组代码原理分析
NEXT数组就是上面的K


void get_next(string T,int *next)
{
int j=0;
int i=1;
next[1]=0;
while(i<T[0])//后缀超过长度的时候,就匹配完成了
{
if(j==0|| T[i]==T[j])
{
i++;
j++;
next[i]=j;
}
else
{
//j回溯
j=next[j];
}
//因为前缀是固定的,后缀是相对的(前缀是其实的字符)
}
}
//返回字串T在主串S第pos个字符后的位置
//若不存在,则返回0
int Index_KMP(string S,string T,int pos)
{
int i=pos;
int j=1;
int next[255];
get_next(T,next);//得到next数组
while(i<=S[0]&&j<=T[0])//S[0]与T[0]存放的是字符串的长度
{
if(j==0|| S[i]==T[j])
{
i++;
j++;
}
else
{
j=next[j];//KMP算法的灵魂,利用next作为最高指引
}
}
//匹配成功后 j肯定比T的字符串要大一位
if(j>T[0])
{
return i-T[0];
}
else
{
return 0;
}
}
KMP算法之实现及优化

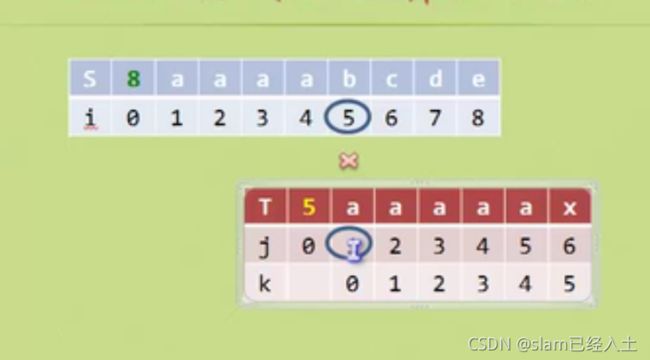
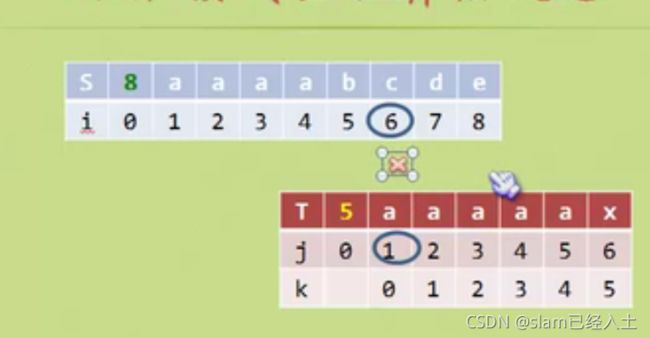
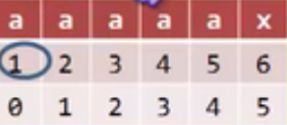
这个特殊情况则么办
这样,判断到不等的时候,假如这个位置是 m,那么m-1位置的T的字符和前缀字符都相等的时候,就直接让j回到前缀对应的位置,上图中就是回到0.
#include 树

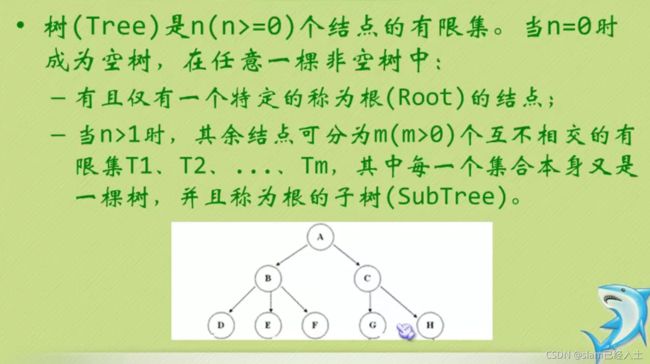
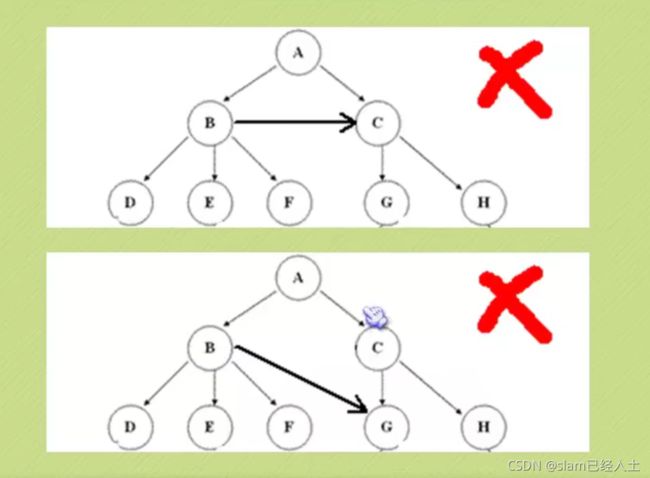

上图,整个树最大的节点是3.
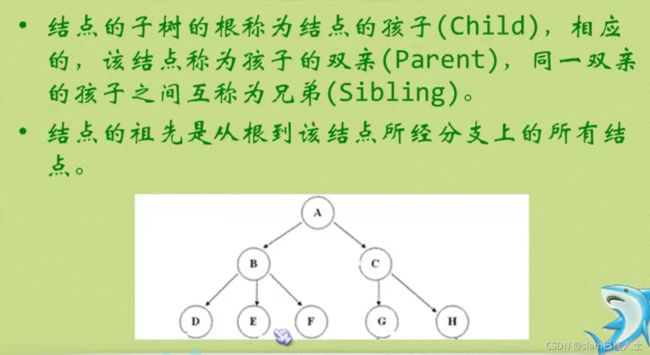
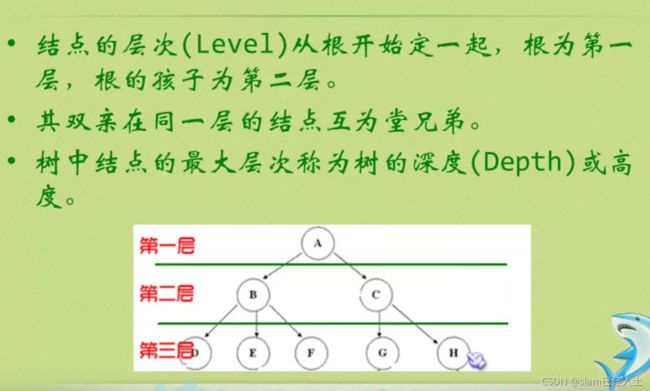
上图树的深度为3,因为它有三层。
树的存储结构


// 树的双亲表示法结点结构定义
#define MAX_TREE_SIZE 100
typedef int ElemType;
typedef struct PTNode
{
ElemType data; // 结点数据
int parent; // 双亲位置
}PTNode;
typedef struct
{
PTNode nodes[MAX_TREE_SIZE];
int r; // 根的位置
int n; // 结点数目
}PTree;
双亲表示法
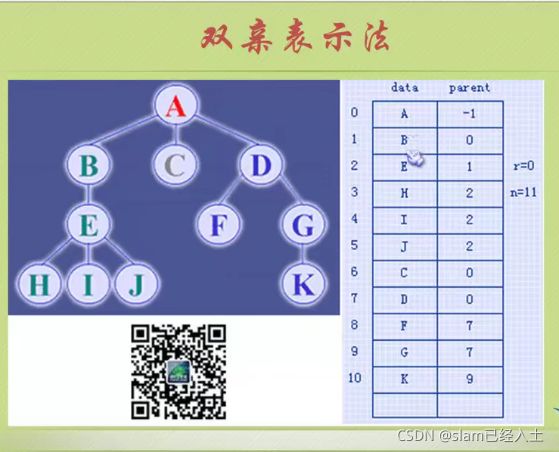
A是根没有双亲,所以为-1

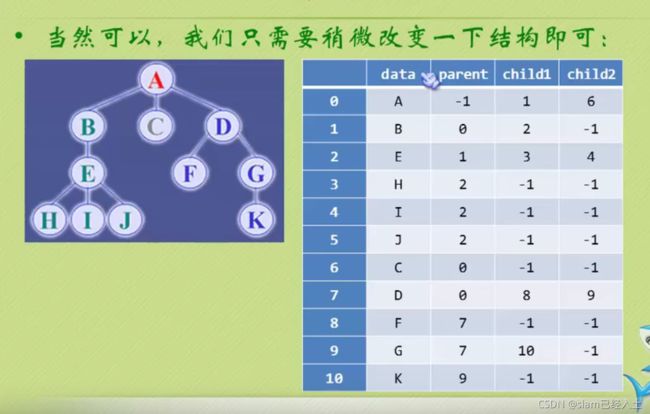

孩子表示法

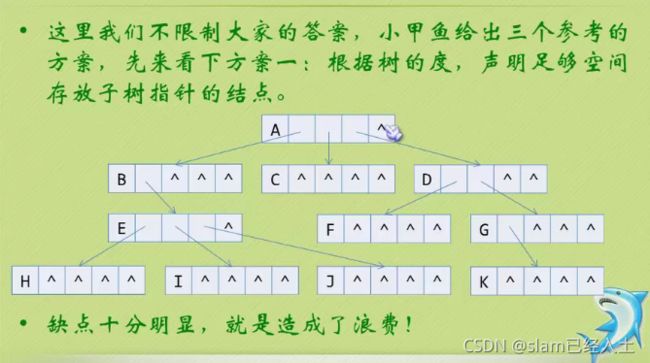


左边一块是数组,右边的是用链表链起来的

#define MAX_TREE_SIZE 100
typedef char ElemType;
//孩子节点
typedef struct CTNode
{
int child;//给孩子节点的下标
struct CTNode *next;//指向下一个孩子节点的指针
}* Childptr;
//表头结构
typedef struct
{
ElemType data; //存放在树种的节点的数据
int parent;//存放双亲的位置
Childptr firstchild;//指向第一个孩子额指针
}CTBox;
//树结构
typedef struct
{
CTBox nodes[MAX_TREE_SIZE];//节点数组
int r;//根的位置
int n;//树的节点的个数
};
二叉树
要注意区分左子树和右子树
二叉树五种心态
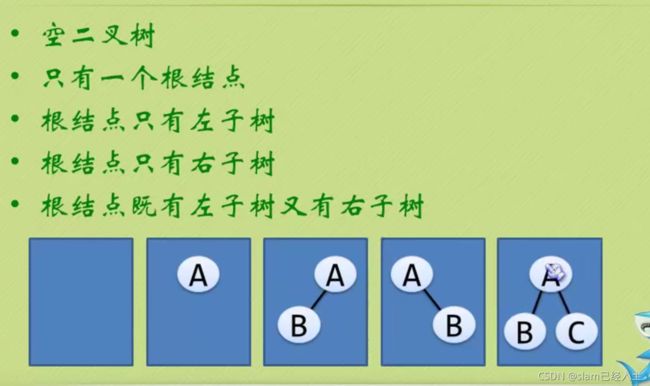


斜树只能全部往左斜或者全部往右斜。



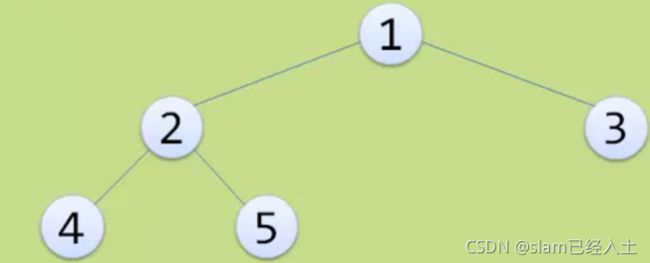
上图依旧是完全二叉树,但是不是满二叉树。
因为上面的序号依然是连在一起的,1 2 3 4 5

上面的特点在上图有体现出来
以下这些都不是完全二叉树
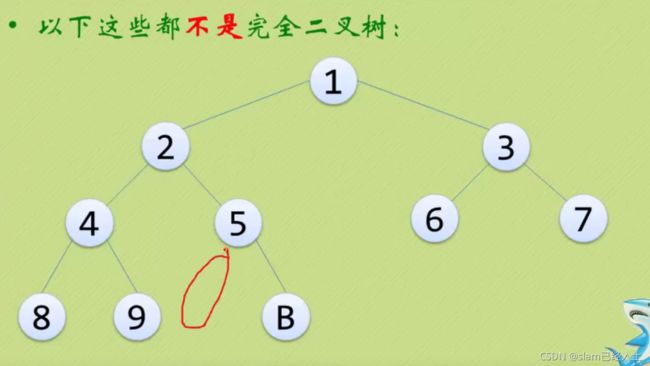
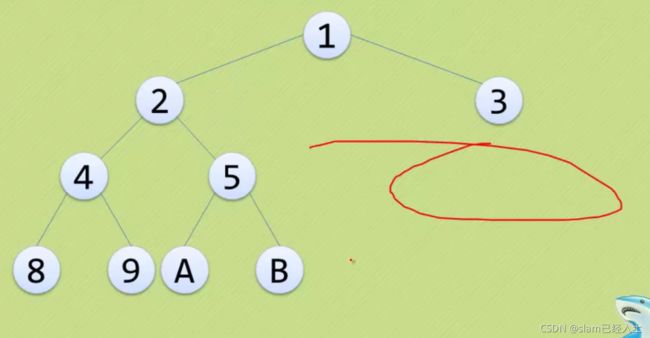
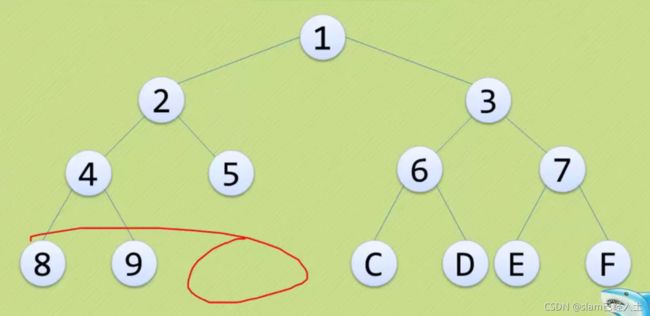
上面三个都只是普通二叉树

二叉树的性质

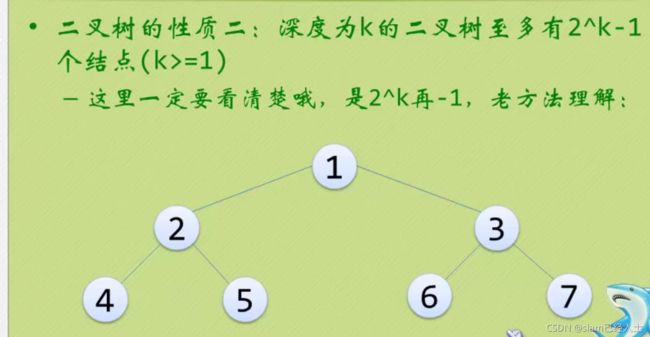


向上取整和向下取整。



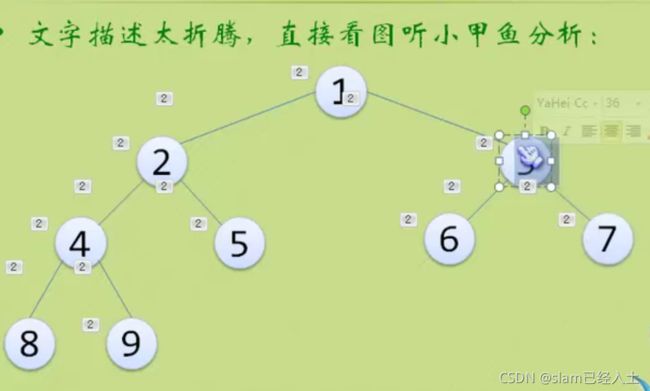
上面太理论了,看看就行,没什么意思。
二叉树的存储结构
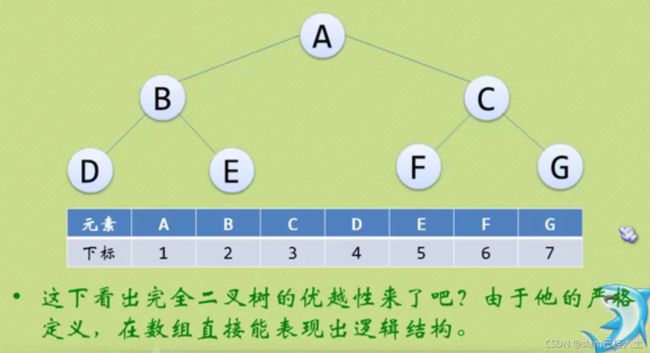

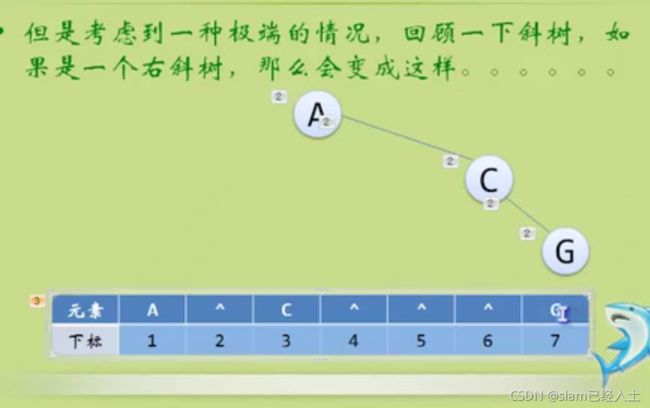
此时很浪费资源。

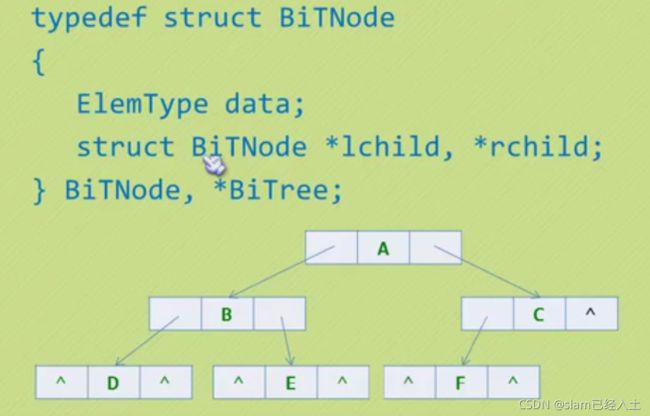
二叉树的遍历



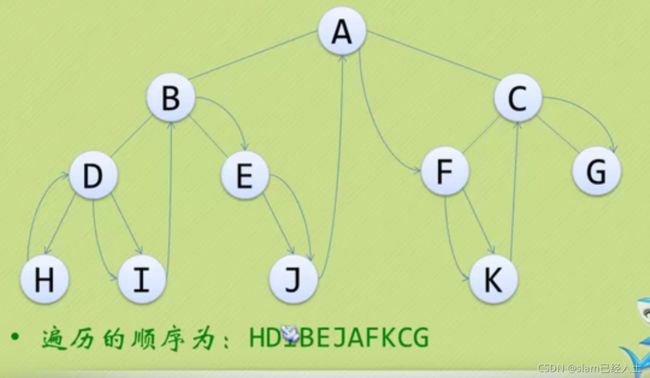

记住大家庭和小家庭概念就简单了


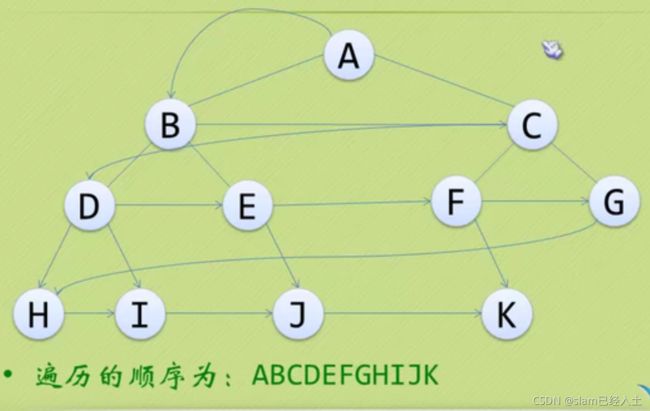
二叉树的建立和遍历算法
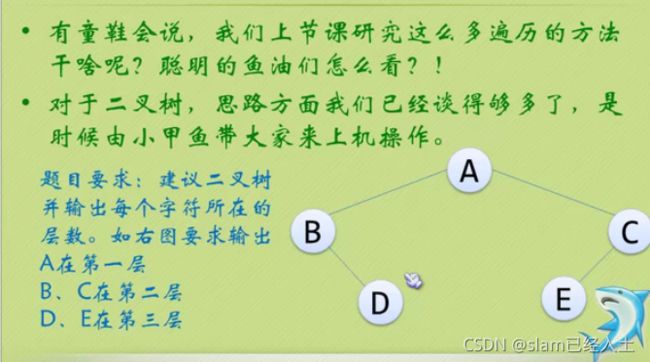
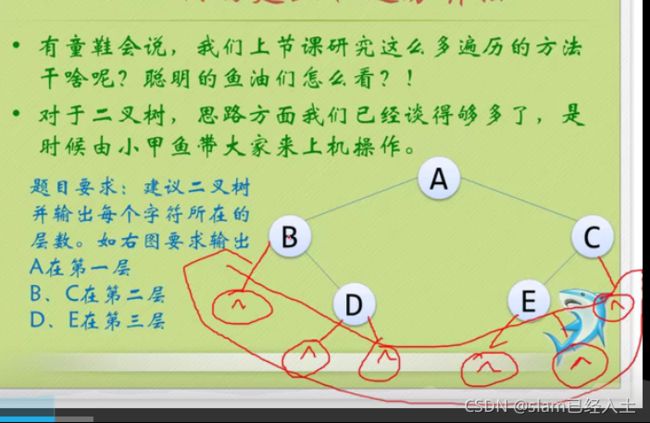
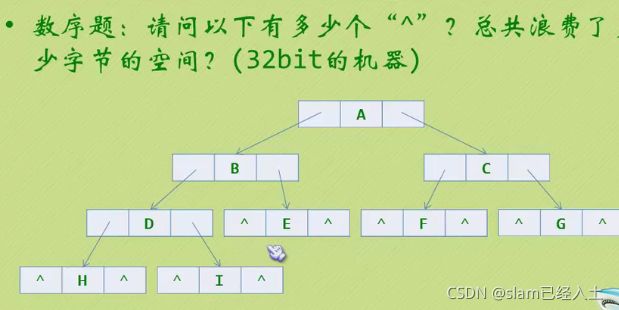
#include 线索二叉树
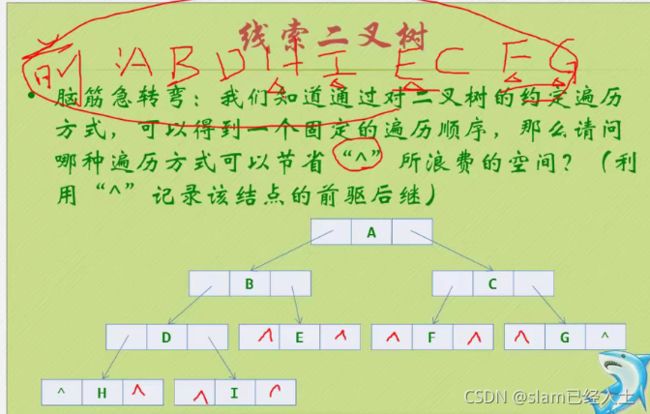
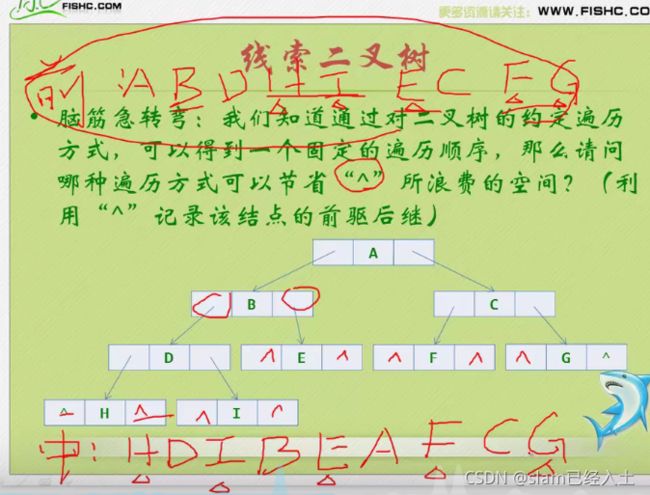
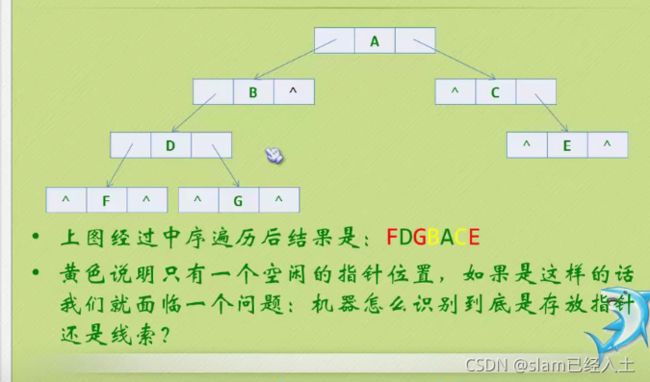
利用中序好像就可以解决这个问题了
因为发现都是隔一个隔一个的规律
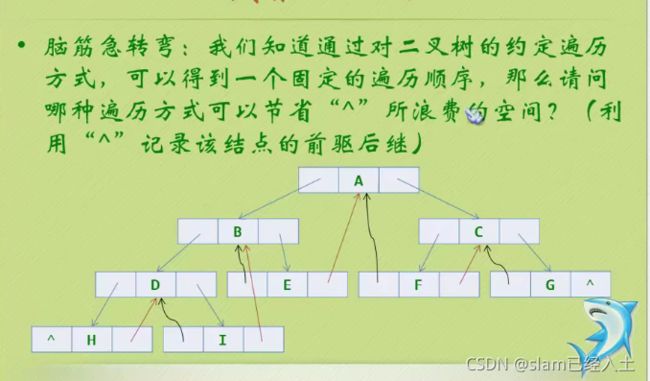
前驱用黑色曲线箭头表示
后继用红色直线箭头表示




这个程序比较难以理解,建议用debug调试。
#include 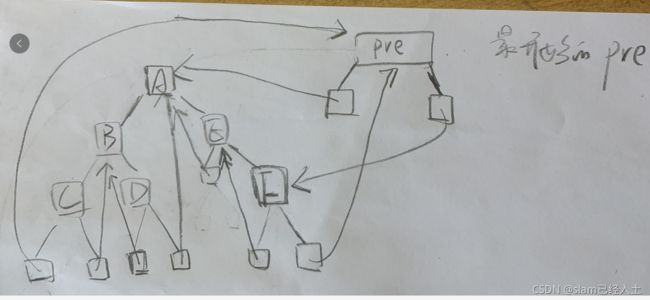
树、森林及二叉树的相互转换
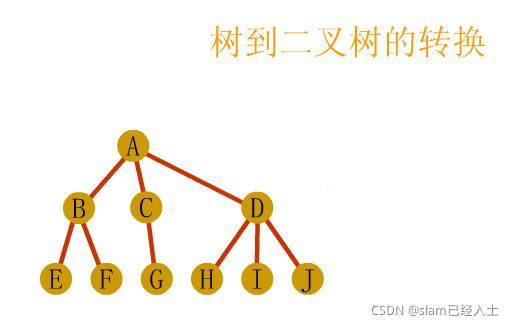
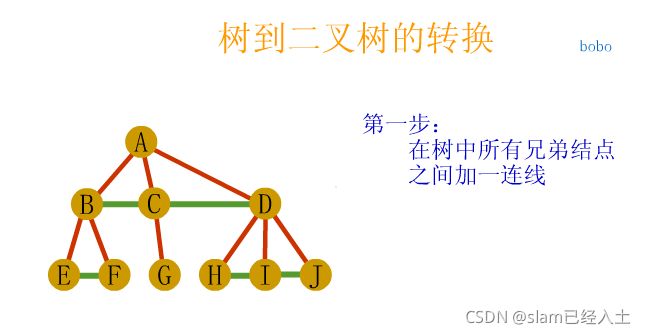
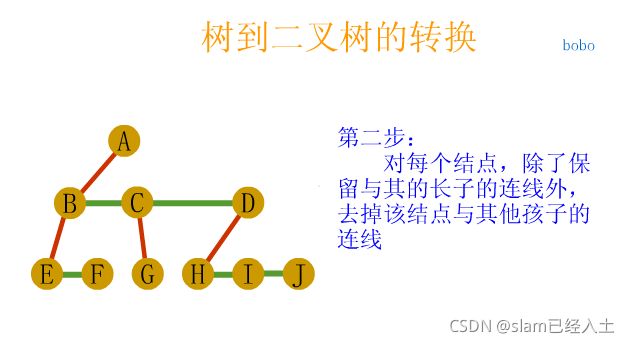



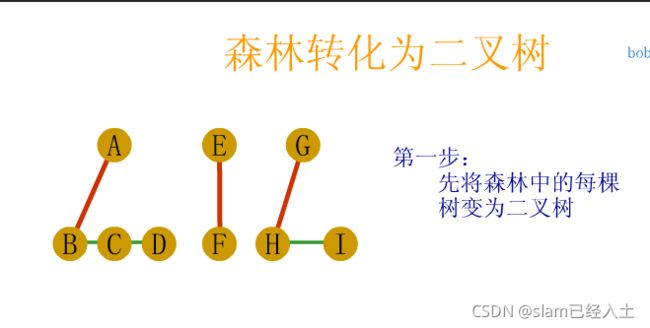

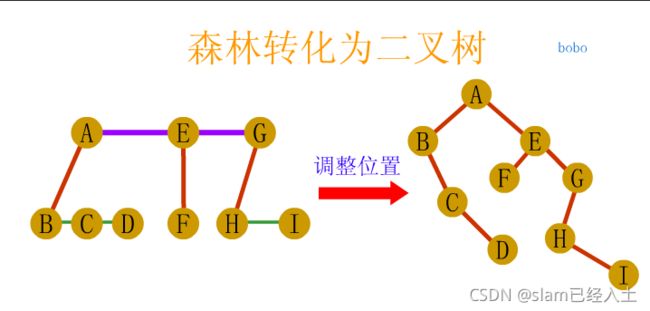


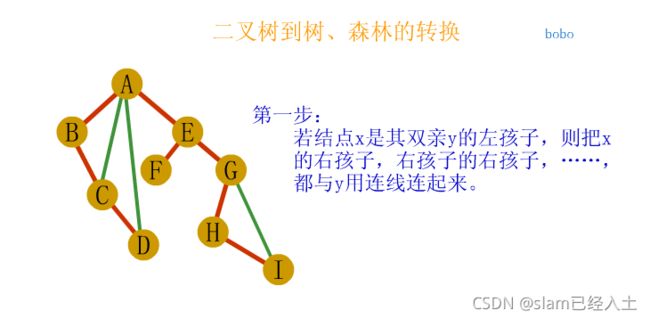
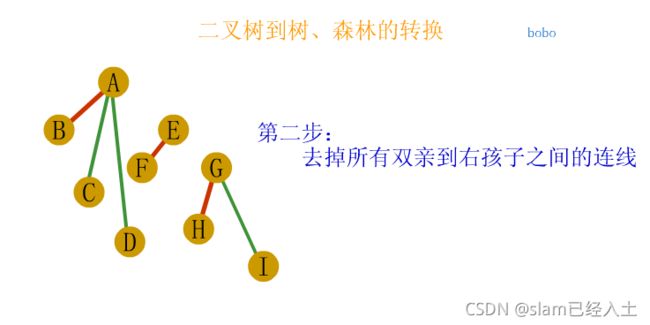
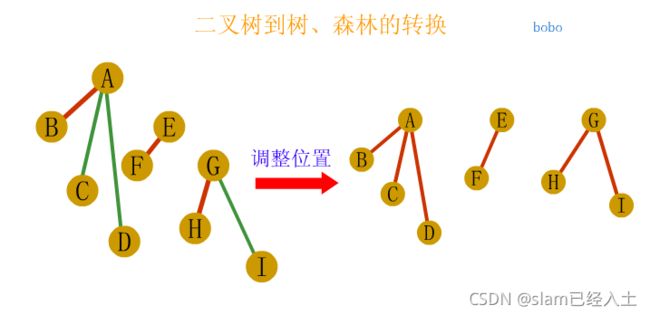

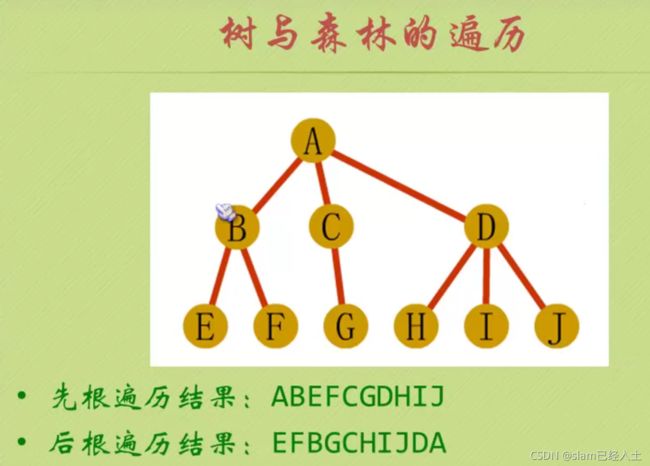
树与森林的遍历


赫夫曼树
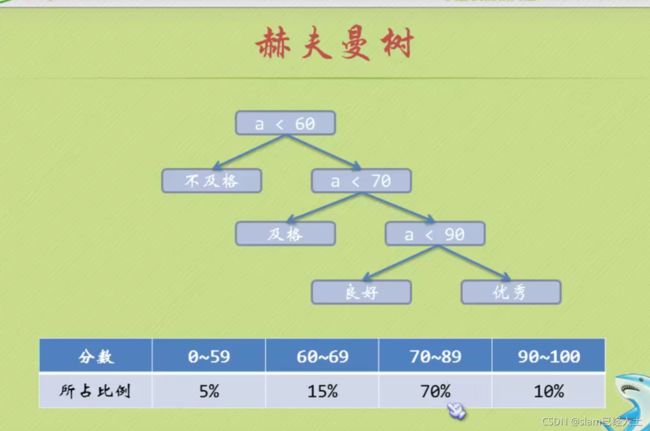
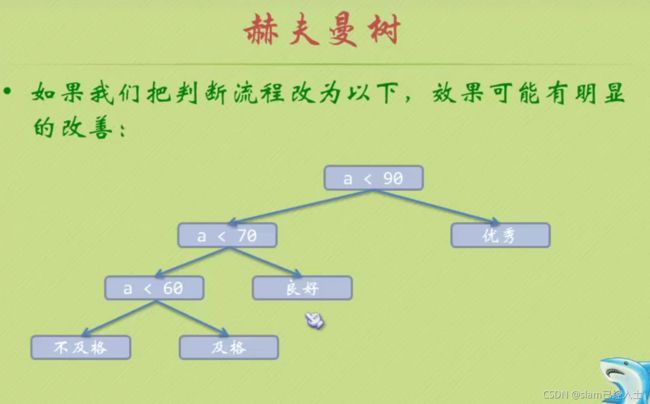
70-90分的人要进行三次判断才知道(这个分数段的人占比最大)。效率有点低
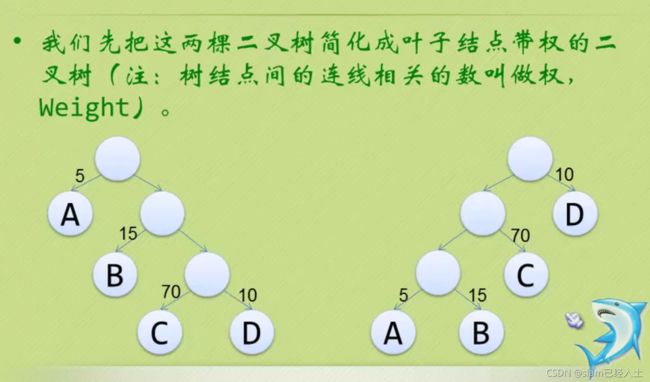

左边树的对应数据
以节点c为例:
C的路径长度:3
树的路径长度:1+2+3+3
C带权路径长度:70*3
树的带权路径长度WPL:1*5+15*2+70*3+10*3
右边树的对应数据
树的带权路径长度WPL:1*10+2*70+3*15+3*5
显然右边树的带权路径长度WPL小于左边树的带权路径长度WPL,所以右边树的效率更高。

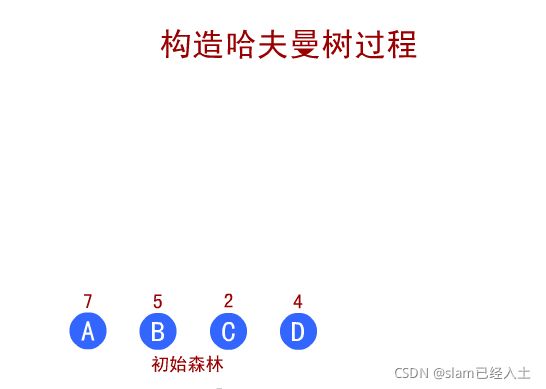
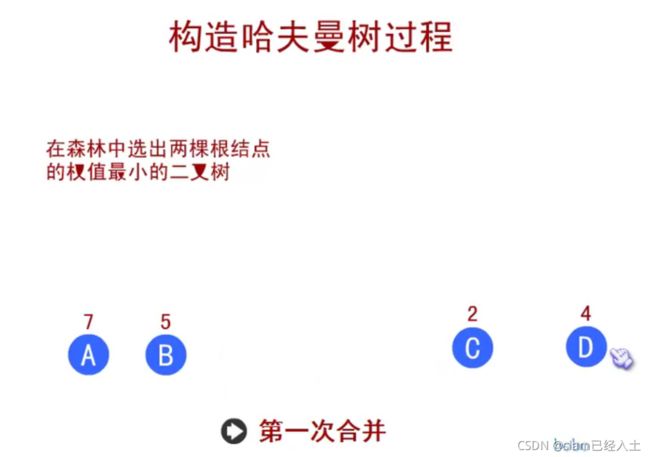
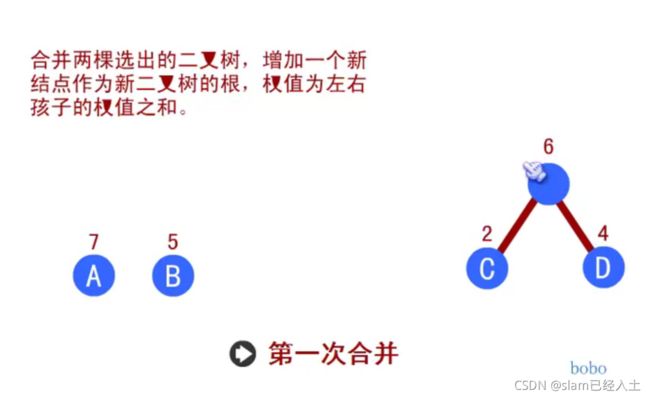

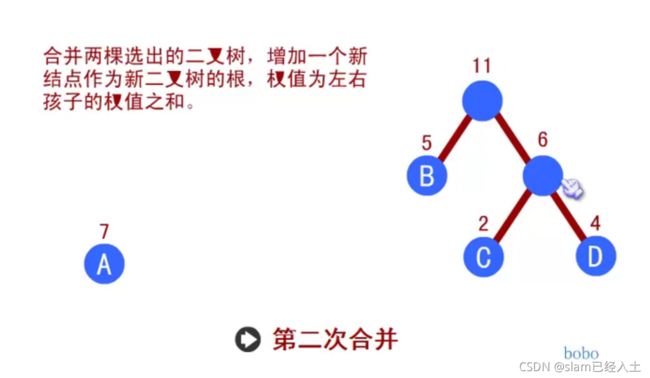
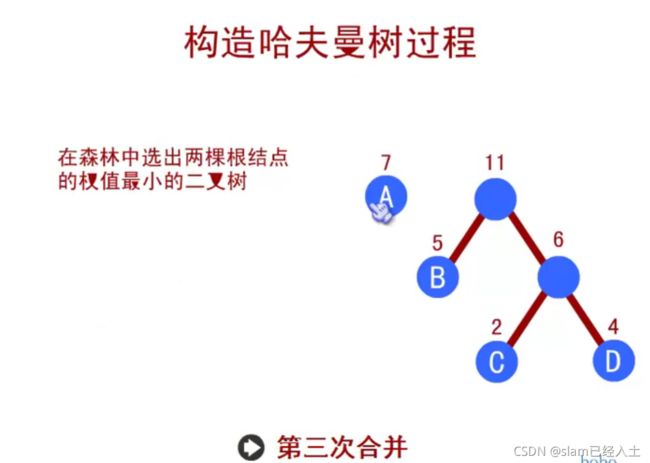
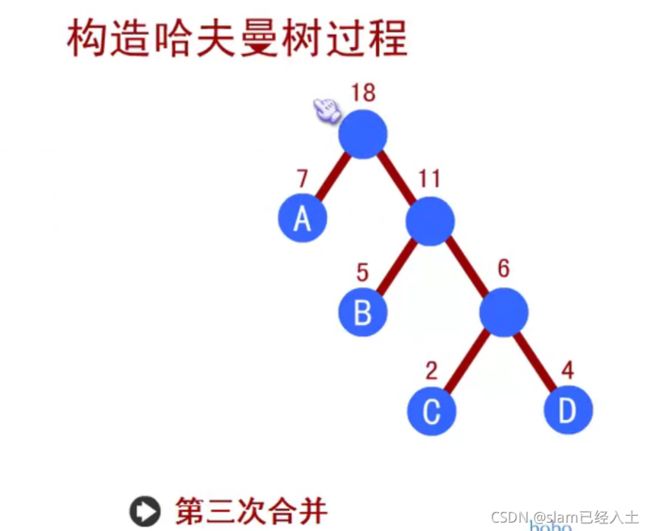
赫夫曼编码
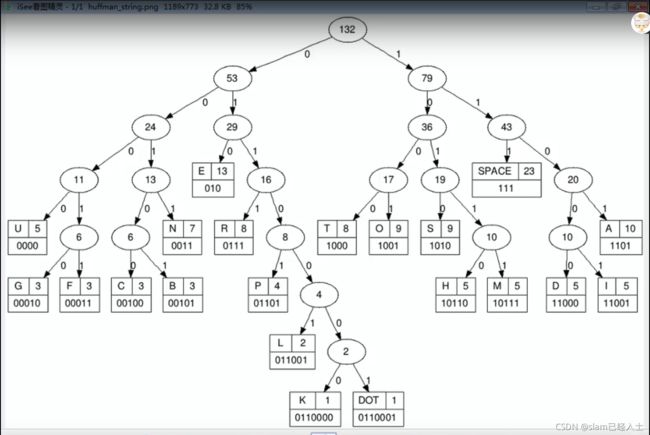


代码里面的一些数据结构
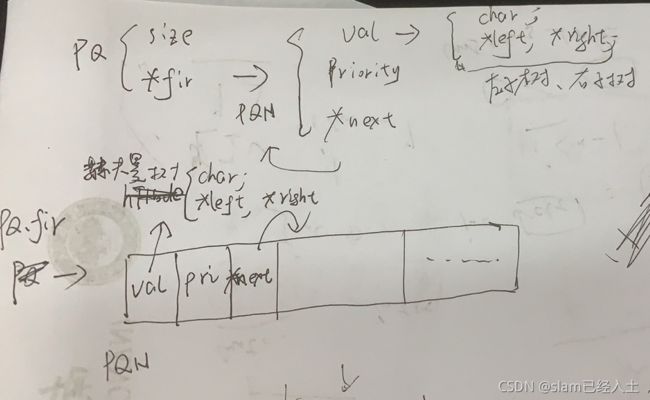
//队列的节点
typedef struct _pQueueNode {
TYPE val;//指向树节点
unsigned int priority;//字符出现的次数,也就是赫夫曼编码的权值
struct _pQueueNode *next;//指向下一个队列的节点
}pQueueNode;
// pQueue就是队列的头
typedef struct _pQueue {
unsigned int size; //存放队列的长度,最后一个就是树的根节点
pQueueNode *first; //指向队列的第一个节点
}pQueue;
//赫夫曼树节点
typedef struct _htNode {
char symbol;//存放字符
struct _htNode *left, *right;//左子树 右子树
}htNode;
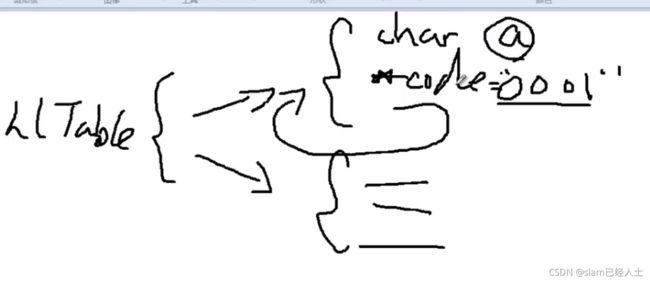
//The Huffman table nodes (linked list implementation)
typedef struct _hlNode {
char symbol; //存放字符 比如a
char *code;//存放字符a对应的赫夫曼编码 比如,0010
struct _hlNode *next; //指向下一个_hlNode
}hlNode;
//Incapsularea listei
typedef struct _hlTable {
hlNode *first;//指向第一个_hlNode
hlNode *last;//指向最后一个_hlNode
}hlTable;
代码如下:
pQueue.h
#pragma once//防止头文件重复定义
#ifndef _PQUEUE_H
#define _PQUEUE_H
#include "huffman.h"
//We modify the data type to hold pointers to Huffman tree nodes
#define TYPE htNode *
#define MAX_SZ 256
//队列的节点
typedef struct _pQueueNode {
TYPE val;//指向树节点
unsigned int priority;//字符出现的次数,也就是赫夫曼编码的权值
struct _pQueueNode *next;//指向下一个队列的节点
}pQueueNode;
// pQueue就是队列的头
typedef struct _pQueue {
unsigned int size; //存放队列的长度,最后一个就是树的根节点
pQueueNode *first; //指向队列的第一个节点
}pQueue;
void initPQueue(pQueue **queue);
void addPQueue(pQueue **queue, TYPE val, unsigned int priority);
TYPE getPQueue(pQueue **queue);
#endif
huffman.h
#pragma once
#ifndef _HUFFMAN_H
#define _HUFFMAN_H
//The Huffman tree node definition
//赫夫曼树节点
typedef struct _htNode {
char symbol;//存放字符
struct _htNode *left, *right;//左子树 右子树
}htNode;
/*
We "encapsulate" the entire tree in a structure
because in the future we might add fields like "size"
if we need to. This way we don't have to modify the entire
source code.
*/
typedef struct _htTree {
htNode *root;
}htTree;
//The Huffman table nodes (linked list implementation)
typedef struct _hlNode {
char symbol; //存放字符 比如a
char *code;//存放字符a对应的赫夫曼编码 比如,0010
struct _hlNode *next; //指向下一个_hlNode
}hlNode;
//Incapsularea listei
typedef struct _hlTable {
hlNode *first;//指向第一个_hlNode
hlNode *last;//指向最后一个_hlNode
}hlTable;
htTree * buildTree(char *inputString);
hlTable * buildTable(htTree *huffmanTree);
void encode(hlTable *table, char *stringToEncode);
void decode(htTree *tree, char *stringToDecode);
#endif
pQueue.cpp
#include "pQueue.h"
#include huffman.cpp
#include main.cpp
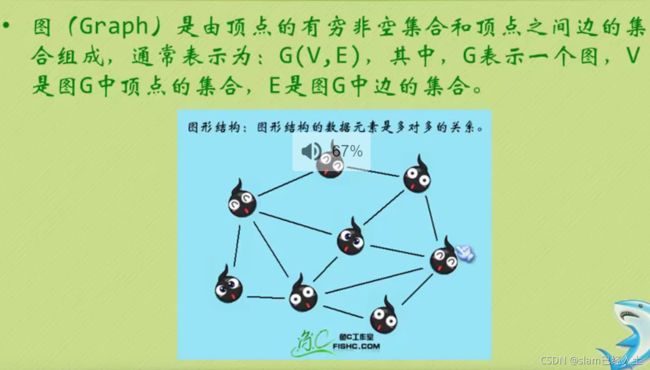
#include 图
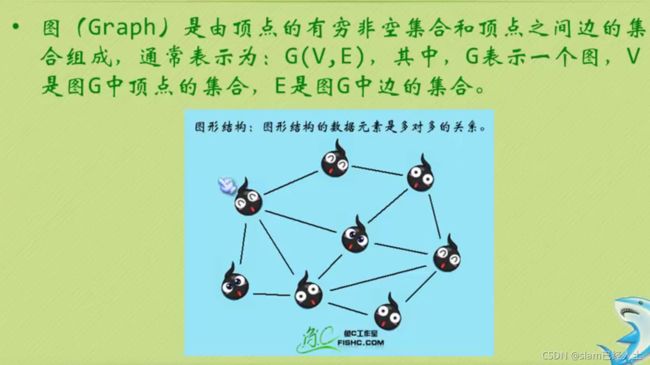
多对多的关系

无序偶里的vi vj的顺序
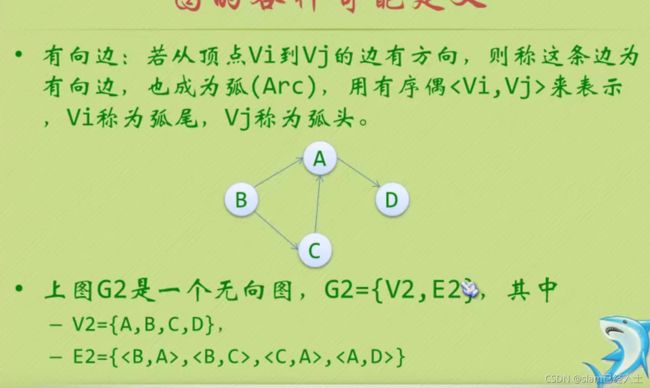
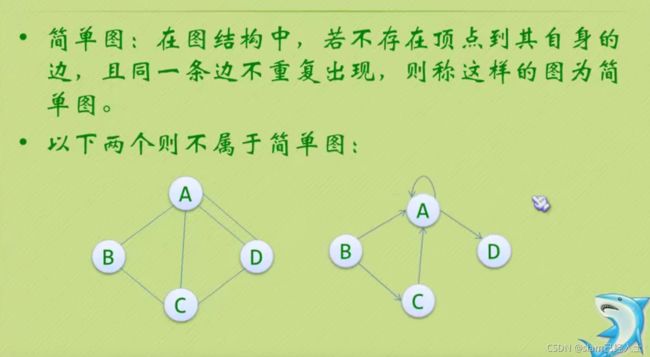
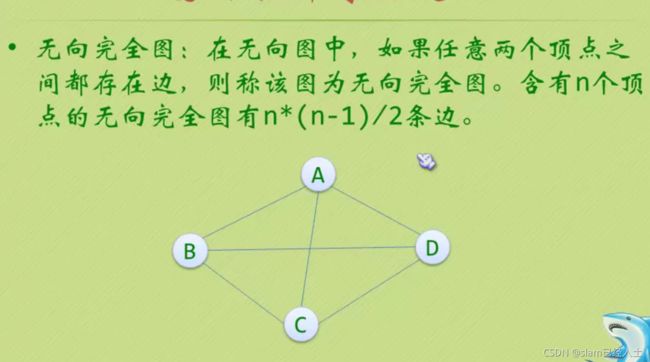
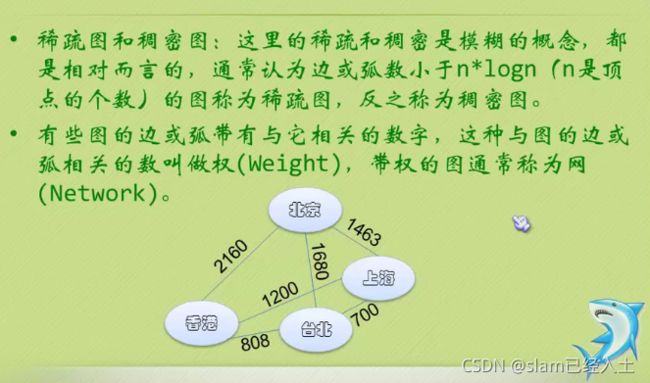
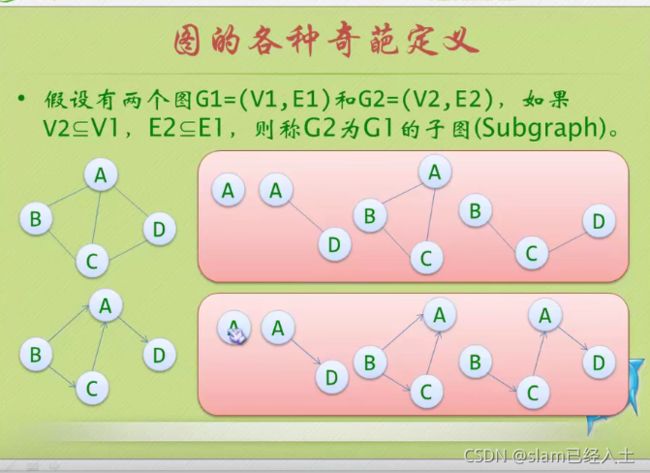


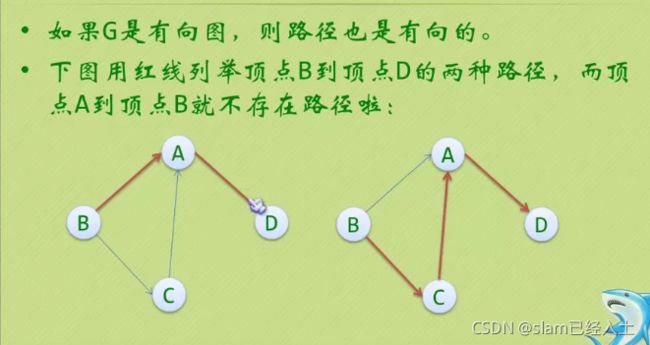

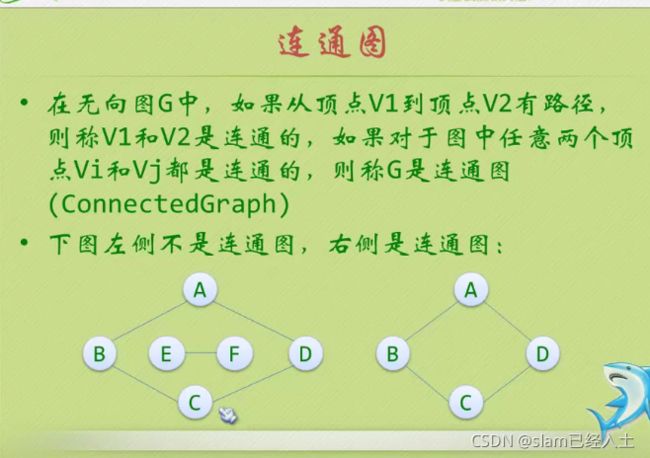
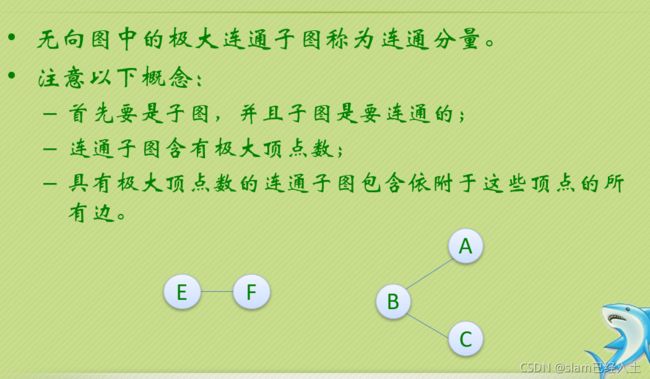

有向图就是加了强这个字
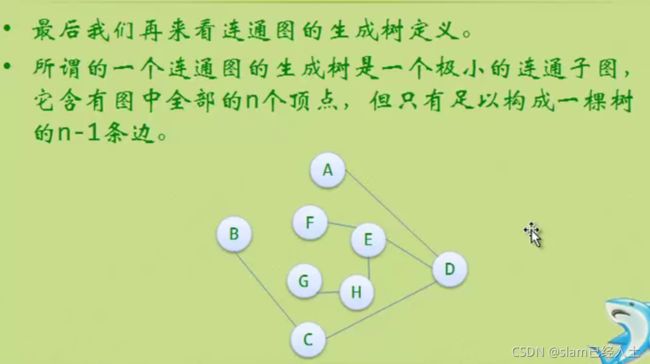
加两个边就不是生成树了
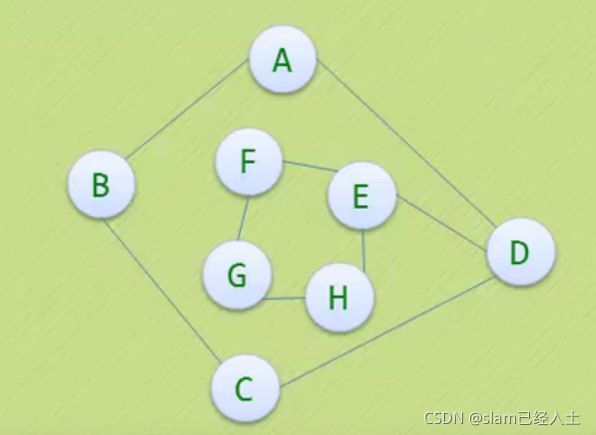
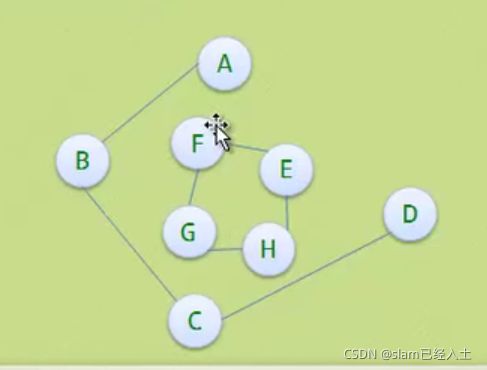
这个也不是生成树 因为是两个子图
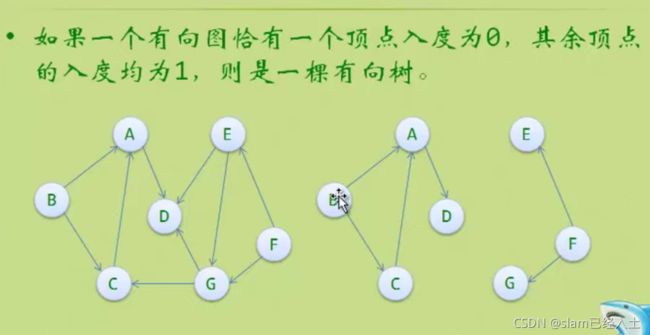
左边的有向图变成右边的森林,右边的森林由两个有向树构成。
图的存储结构

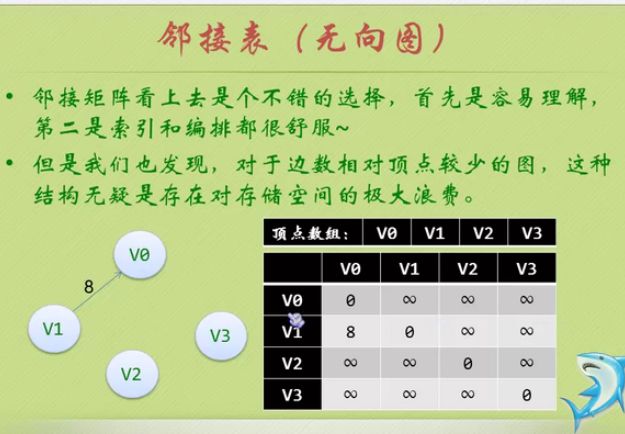
因为是无向图,二维数组是对称的。
邻接矩阵


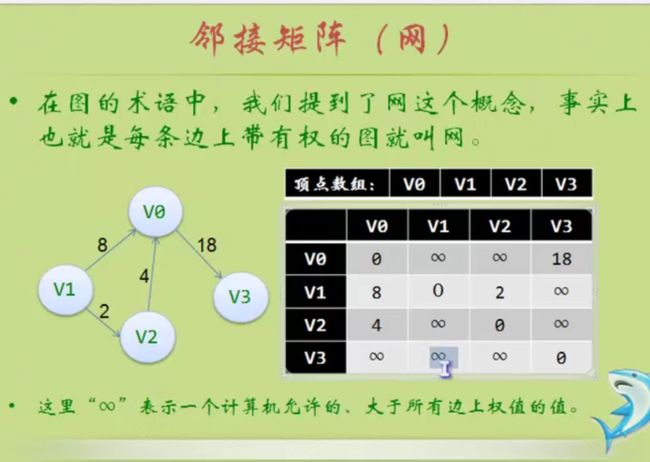

邻接矩阵—无向图和有向图的代码定义
// 时间复杂度为O(n+n^2+e)
#define MAXVEX 100 // 最大顶点数
#define INFINITY 65535 // 用65535来代表无穷大
typedef struct
{
char vexs[MAXVEX]; // 顶点表
int arc[MAXVEX][MAXVEX]; // 邻接矩阵
int numVertexes, numEdges; // 图中当前的顶点数和边数
} MGraph;
char flag;
// 建立无向网图的邻接矩阵
void CreateMGraph(MGraph *G)
{
int i, j, k, w;
int flag;
printf("请输入是生成无向还是有向,无向输入0,有向输入1:\n");
cin>>flag;
printf("请输入顶点数和边数:\n");
scanf("%d %d", &G->numVertexes, &G->numEdges);
for( i=0; i < G->numVertexes; i++ )
{
scanf("%c", &G->vexs[i]);
}
for( i=0; i < G->numVertexes; i++ )
{
for( j=0; j < G->numVertexes; j++ )
{
G->arc[i][j] = INFINITY; // 邻接矩阵初始化
}
}
if(flag==0)
{
for( k=0; k < G->numEdges; k++ )
{
printf("请输入边(Vi,Vj)上的下标i,下标j和对应的权w:\n"); // 这只是例子,提高用户体验需要进行改善
scanf("%d %d %d", &i, &j, &w);
G->arc[i][j] = w;
G->arc[j][i] = G->arc[i][j]; // 是无向网图,对称矩阵
}
}
else
{
for( k=0; k < G->numEdges; k++ )
{
printf("请输入边(Vi,Vj)上的下标i,下标j和对应的权w:\n"); // 这只是例子,提高用户体验需要进行改善
scanf("%d %d %d", &i, &j, &w);
G->arc[i][j] = w;
}
}
}
邻接表
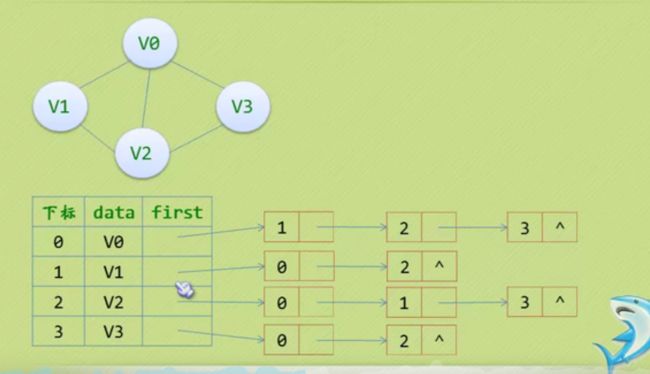
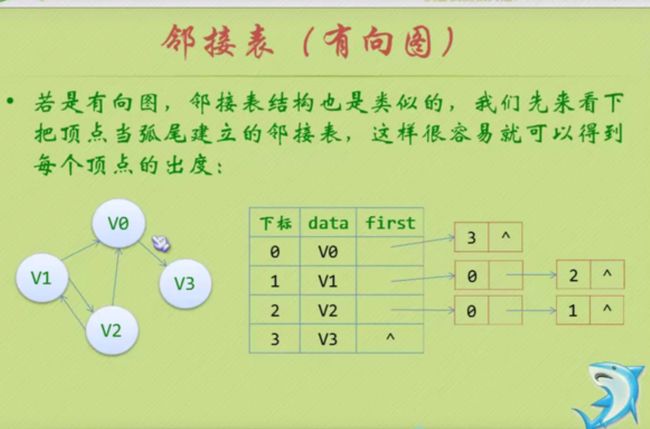
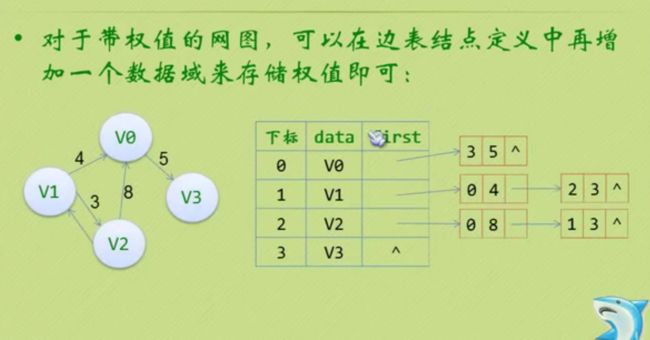
#define MAXVEX 100
//边表节点
typedef struct EdgeTNode
{
int vertx;//邻接顶点
int weight;//权重
EdgeTNode *next;//
}EdgeTNode;
//顶点表节点
typedef struct VertxTNode
{
char data; //顶点域 顶点信息
EdgeTNode *firstedge; // 指向第一个邻接节点
}VertxTNode ,Vertx[MAXVEX];
//整体图
typedef struct
{
Vertx vertx_;
int numVertexes, numEdges; // 图中当前的顶点数和边数
}Graph_LinJieT;
//建立
void CreatLinJie(Graph_LinJieT *G)
{
int i,j ,k;
EdgeTNode *e;
printf("请输入顶点数和边数:\n");
scanf("%d %d", &G->numVertexes, &G->numEdges);
for( i=0;inumVertexes;i++)
{
G->vertx_[i].firstedge=NULL;//初始化
}
for(k=0;knumEdges;k++)
{
//这里使用的头插,和图中的邻接表是反着来的,但最终也达到了目的
printf("请输入边(Vi,Vj)上的顶点序号:\n");
scanf("%d %d", &i, &j);
//i在左边 邻接序号为j
e = (EdgeTNode *)malloc(sizeof(EdgeTNode));
e->vertx=j;
e->next=G->vertx_[i].firstedge;//比如输入(0,1) 1就会指向NULL
G->vertx_[i].firstedge=e;
//若是无向图还得执行下面的语句
//j在左边 邻接序号为i
e = (EdgeTNode *)malloc(sizeof(EdgeTNode));
e->vertx=i;
e->next=G->vertx_[j].firstedge;//比如输入(0,1) 1就会指向NULL
G->vertx_[j].firstedge=e;
}
}
//课本答案:
#define MAXVEX 100
typedef struct EdgeNode // 边表结点
{
int adjvex; // 邻接点域,存储该顶点对应的下标
int weight; // 用于存储权值,对于非网图可以不需要
struct EdgeNode *next; // 链域,指向下一个邻接点
} EdgeNode;
typedef struct VertexNode // 顶点表结点
{
char data; // 顶点域,存储顶点信息
EdgeNode *firstEdge; // 边表头指针
} VertexNode, AdjList[MAXVEX];
typedef struct
{
AdjList adjList;
int numVertexes, numEdges; // 图中当前顶点数和边数
} GraphAdjList;
// 建立图的邻接表结构
void CreateALGraph(GraphAdjList *G)
{
int i, j, k;
EdgeNode *e;
printf("请输入顶点数和边数:\n");
scanf("%d %d", &G->numVertexes, &G->numEdges);
// 读取顶点信息,建立顶点表
for( i=0; i < G->numVertexes; i++ )
{
scanf("%c", &G->adjList[i].data);
G->adjList[i].firstEdge = NULL; // 初始化置为空表
}
//这里是无向图
for( k=0; k < G->numEdges; k++ )
{
printf("请输入边(Vi,Vj)上的顶点序号:\n");
scanf("%d %d", &i, &j);
e = (EdgeNode *)malloc(sizeof(EdgeNode));
e->adjvex = j; // 邻接序号为j
e->next = G->adjList[i].firstEdge;
G->adjList[i].firstEdge = e;
e = (EdgeNode *)malloc(sizeof(EdgeNode));
e->adjvex = i; // 邻接序号为i
e->next = G->adjList[j].firstEdge;
G->adjList[j].firstEdge = e;
}
}
十字链表
首先邻接表有出度,逆邻接表有入度,两个加起来就是十字链表


蓝色的代表出度—邻接表
红色的代表入读—逆邻接表


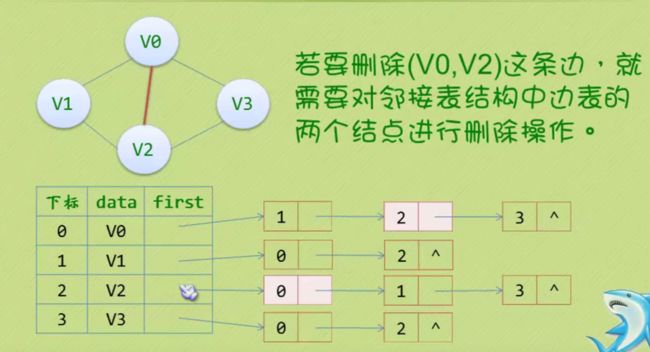
邻接多重表

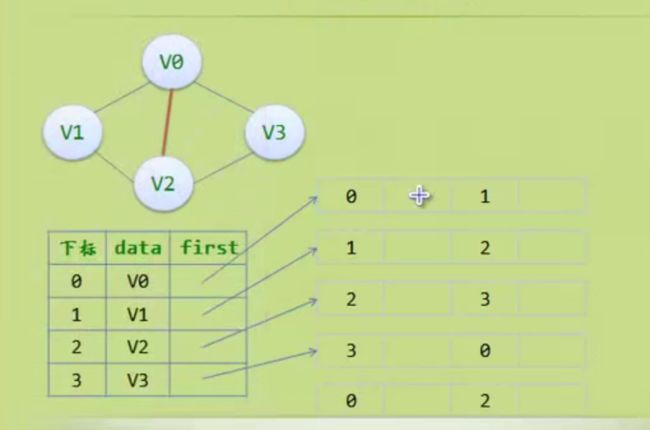
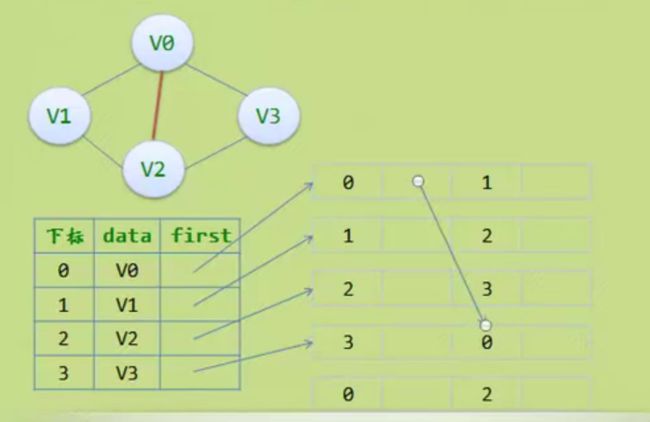
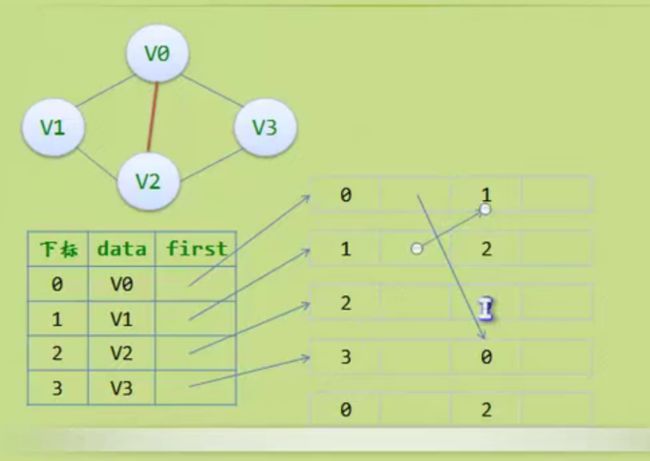
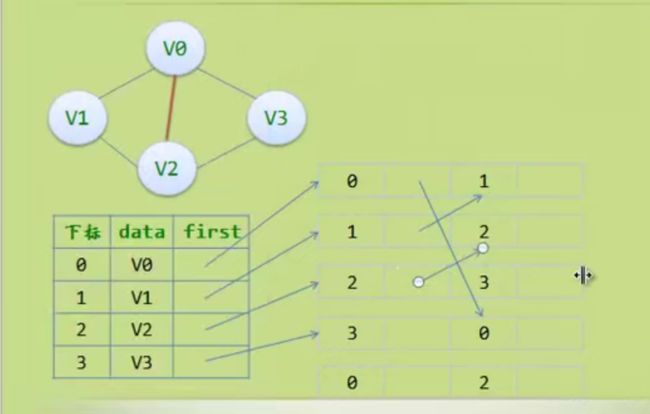
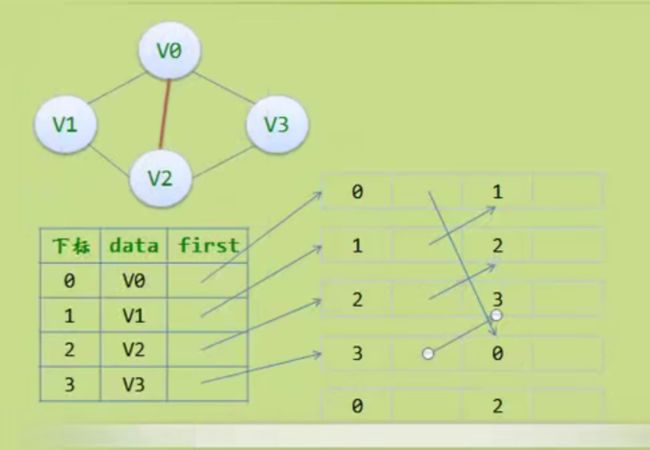

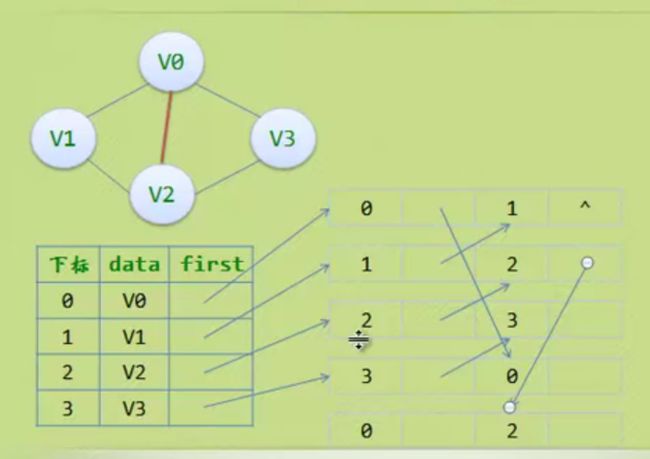

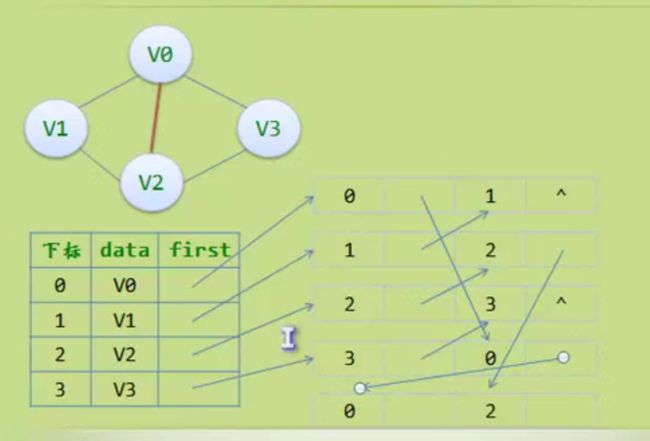

边集数组
弗洛伊德的冰山理论
图的遍历—深度优先遍历DFS

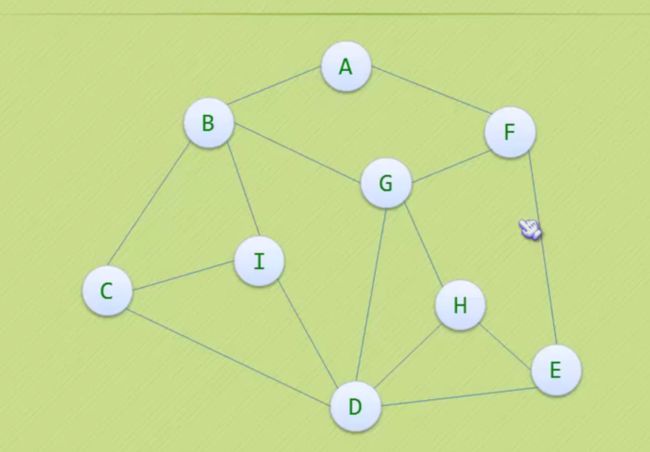

如果在某个点的右边的点已经走过了,那就退到之前的点

行走的路线如下图:
蓝色的是走通的,红色的是访问过的,不能走。
邻接矩阵深度遍历
下面的代码是以邻接矩阵的结构,进行深度遍历
#include
using namespace std;
#define MAXVEX 100 // 最大顶点数
#define INFINITY 65535 // 用65535来代表无穷大
typedef struct
{
char vexs[MAXVEX]; // 顶点表
int arc[MAXVEX][MAXVEX]; // 邻接矩阵
int numVertexes, numEdges; // 图中当前的顶点数和边数
} MGraph;
// 建立无向网图的邻接矩阵
void CreateMGraph(MGraph *G)
{
int i, j, k, w;
int flag;
printf("请输入是生成无向还是有向,无向输入0,有向输入1:\n");
cin>>flag;
printf("请输入顶点数和边数:\n");
scanf("%d %d", &G->numVertexes, &G->numEdges);
for( i=0; i < G->numVertexes; i++ )
{
scanf("%c", &G->vexs[i]);
}
for( i=0; i < G->numVertexes; i++ )
{
for( j=0; j < G->numVertexes; j++ )
{
G->arc[i][j] = INFINITY; // 邻接矩阵初始化
}
}
if(flag==0)//无向
{
for( k=0; k < G->numEdges; k++ )
{
printf("请输入边(Vi,Vj)上的下标i,下标j和对应的权w:\n"); // 这只是例子,提高用户体验需要进行改善
scanf("%d %d %d", &i, &j, &w);
G->arc[i][j] = w;
G->arc[j][i] = G->arc[i][j]; // 是无向网图,对称矩阵
}
}
else//有向
{
for( k=0; k < G->numEdges; k++ )
{
printf("请输入边(Vi,Vj)上的下标i,下标j和对应的权w:\n"); // 这只是例子,提高用户体验需要进行改善
scanf("%d %d %d", &i, &j, &w);
G->arc[i][j] = w;
}
}
}
#define TRUE 1
#define FALSE 0
#define MAX 256
typedef int Boolean; // 这里我们定义Boolean为布尔类型,其值为TRUE或FALSE
Boolean visited[MAX]; // 访问标志的数组
void DFS(MGraph G,int i)
{
visited[i]=true;//已经访问过顶点i
cout< 邻接表深度遍历
下面的代码是以邻接表的结构,进行深度遍历
#include
using namespace std;
#define MAXVEX 100
typedef struct EdgeNode // 边表结点
{
int adjvex; // 邻接点域,存储该顶点对应的下标
int weight; // 用于存储权值,对于非网图可以不需要
struct EdgeNode *next; // 链域,指向下一个邻接点
} EdgeNode;
typedef struct VertexNode // 顶点表结点
{
char data; // 顶点域,存储顶点信息
EdgeNode *firstEdge; // 边表头指针
} VertexNode, AdjList[MAXVEX];
typedef struct
{
AdjList adjList;
int numVertexes, numEdges; // 图中当前顶点数和边数
} GraphAdjList;
// 建立图的邻接表结构
void CreateALGraph(GraphAdjList *G)
{
int i, j, k;
EdgeNode *e;
printf("请输入顶点数和边数:\n");
scanf("%d %d", &G->numVertexes, &G->numEdges);
// 读取顶点信息,建立顶点表
for( i=0; i < G->numVertexes; i++ )
{
scanf("%c", &G->adjList[i].data);
G->adjList[i].firstEdge = NULL; // 初始化置为空表
}
//这里是无向图
for( k=0; k < G->numEdges; k++ )
{
printf("请输入边(Vi,Vj)上的顶点序号:\n");
scanf("%d %d", &i, &j);
//头插法
e = (EdgeNode *)malloc(sizeof(EdgeNode));
e->adjvex = j; // 邻接序号为j
e->next = G->adjList[i].firstEdge;
G->adjList[i].firstEdge = e;
e = (EdgeNode *)malloc(sizeof(EdgeNode));
e->adjvex = i; // 邻接序号为i
e->next = G->adjList[j].firstEdge;
G->adjList[j].firstEdge = e;
}
}
#define TRUE 1
#define FALSE 0
#define MAX 256
typedef int Boolean; // 这里我们定义Boolean为布尔类型,其值为TRUE或FALSE
Boolean visited[MAX]; // 访问标志的数组
//深度遍历 我们以邻接表的规则来遍历
void DFS(GraphAdjList GL,int i)
{
EdgeNode *e;
visited[i]= true;//表示已经访问过了
cout<adjvex]);
{
DFS(GL,e->adjvex);
}
e=e->next;//e指向下一个与i相邻的顶点
}
}
void DFSTraverse(GraphAdjList GL)
{
for(int i=0;i 骑士周游问题
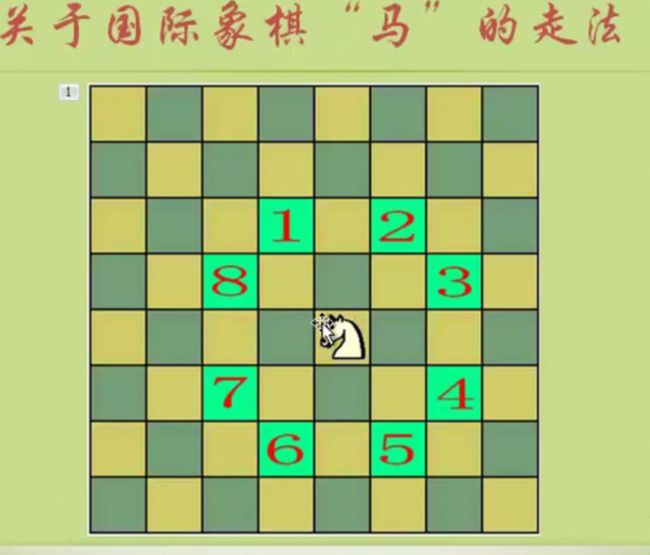
#include
#include
#include "stdio.h"
using namespace std;
//棋盘 8 x 8
#define X 8
#define Y 8
//棋盘
int chess[X][Y];
/**
* 基于找到(x,y)位置的下一个可走的情况
* @param x
* @param y
* @param count
* @return
*/
int nextxy(int *x,int *y,int count)
{
//八种走法
switch (count)
{
case 0:
if(*x+2<=X-1 && *y-1>=0 &&chess[*x+2][*y-1]==0)//往右跳,要在棋盘范围内 判断的是3这个位置 且这个位置没有遍历过
{
*x = *x + 2;
*y = *y - 1;
return 1;
}
break;
case 1:
if(*x+2<=X-1 && *y+1<=Y-1 &&chess[*x+2][*y+1]==0) //判断的是4这个位置
{
*x = *x + 2;
*y = *y + 1;
return 1;
}
break;
case 2:
if(*x+1<=X-1 && *y-2>=0 &&chess[*x+1][*y-2]==0) //判断的是2这个位置
{
*x = *x + 1;
*y = *y - 2;
return 1;
}
break;
case 3:
if(*x+1<=X-1 && *y+2<=Y-1 &&chess[*x+1][*y+2]==0) //判断的是5这个位置
{
*x = *x + 1;
*y = *y + 2;
return 1;
}
break;
case 4:
if(*x-2>=0 && *y-1>=0 &&chess[*x-2][*y-1]==0) //判断的是8这个位置
{
*x = *x - 2;
*y = *y - 1;
return 1;
}
break;
case 5:
if(*x-2>=0 && *y+1<=Y-1 && chess[*x-2][*y+1]==0) //判断的是7这个位置
{
*x = *x - 2;
*y = *y + 1;
return 1;
}
break;
case 6:
if(*x-1>=0 && *y-2>=0 && chess[*x-1][*y-2]==0) //判断的是1这个位置
{
*x = *x - 1;
*y = *y - 2;
return 1;
}
break;
case 7:
if(*x-1>=0 && *y+2<=Y-1 &&chess[*x-1][*y+2]==0) //判断的是6这个位置
{
*x = *x - 1;
*y = *y + 2;
return 1;
}
break;
default:
break;
}
return 0;
}
/**
* 打印棋盘
*/
void print()
{
int i,j;
for(i=0;i 马的起始位置 第二行第0列
运行结果:
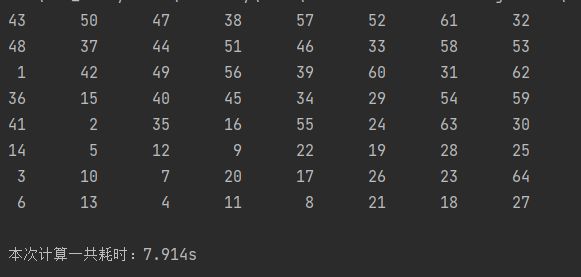
广度优先遍历BFS
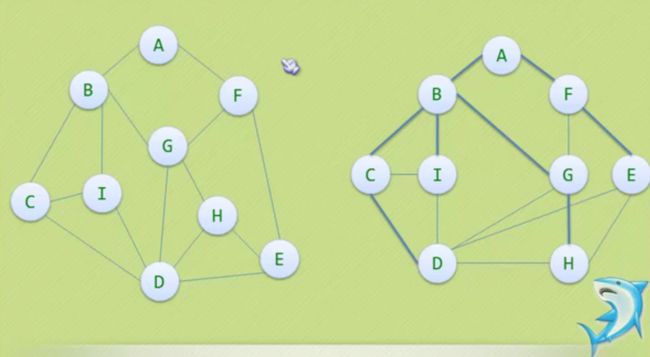
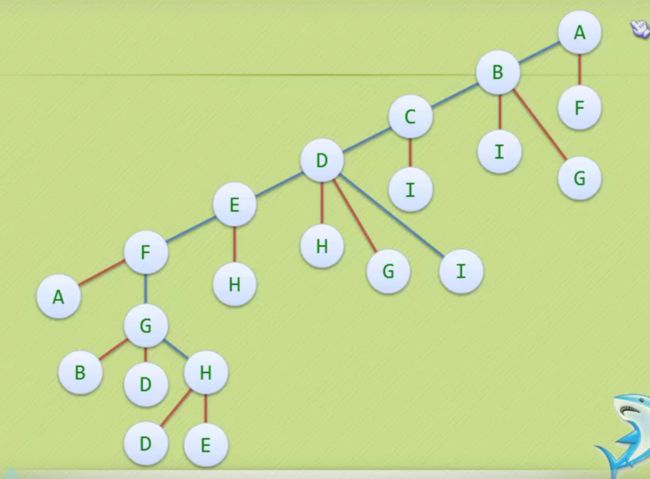
从右图来解释,
我们从A开始,以右边优先原则,先走到B,然后F,因为对于A来说,B F 最近。
因此遍历顺序是ABF CIGE DH
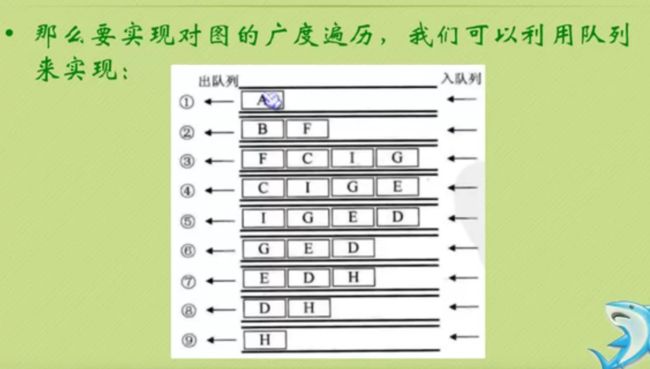
先进先出
邻接矩阵—-广度遍历
//邻接矩阵广度遍历
namespace LinJieMatrix
{
#include
using namespace std;
#define MAXVEX 100 // 最大顶点数
#define INFINITY 65535 // 用65535来代表无穷大
typedef struct
{
char vexs[MAXVEX]; // 顶点表
int arc[MAXVEX][MAXVEX]; // 邻接矩阵
int numVertexes, numEdges; // 图中当前的顶点数和边数
} MGraph;
// 建立无向网图的邻接矩阵
void CreateMGraph(MGraph *G)
{
int i, j, k, w;
int flag;
printf("请输入是生成无向还是有向,无向输入0,有向输入1:\n");
cin>>flag;
printf("请输入顶点数和边数:\n");
scanf("%d %d", &G->numVertexes, &G->numEdges);
for( i=0; i < G->numVertexes; i++ )
{
scanf("%c", &G->vexs[i]);
}
for( i=0; i < G->numVertexes; i++ )
{
for( j=0; j < G->numVertexes; j++ )
{
G->arc[i][j] = INFINITY; // 邻接矩阵初始化
}
}
if(flag==0)//无向
{
for( k=0; k < G->numEdges; k++ )
{
printf("请输入边(Vi,Vj)上的下标i,下标j和对应的权w:\n"); // 这只是例子,提高用户体验需要进行改善
scanf("%d %d %d", &i, &j, &w);
G->arc[i][j] = w;
G->arc[j][i] = G->arc[i][j]; // 是无向网图,对称矩阵
}
}
else//有向
{
for( k=0; k < G->numEdges; k++ )
{
printf("请输入边(Vi,Vj)上的下标i,下标j和对应的权w:\n"); // 这只是例子,提高用户体验需要进行改善
scanf("%d %d %d", &i, &j, &w);
G->arc[i][j] = w;
}
}
}
#define TRUE 1
#define FALSE 0
#define MAX 256
typedef int Boolean; // 这里我们定义Boolean为布尔类型,其值为TRUE或FALSE
Boolean visited[MAX]; // 访问标志的数组
// 邻接矩阵的广度遍历算法
void BFSTraverse(MGraph G)
{
int i, j;
Queue Q;
for( i=0; i < G.numVertexes; i++ )
{
visited[i] = FALSE;
}
initQueue( &Q );//初始化队列
for( i=0; i < G.numVertexes; i++ )
{
if( !visited[i] )
{
printf("%c ", G.vexs[i]);
visited[i] = TRUE;
EnQueue(&Q, i);//进入队列
while( !QueueEmpty(Q) )
{
DeQueue(&Q, &i);//出队列
//遍历与顶点i邻接的顶点
for( j=0; j < G.numVertexes; j++ )
{
if( G.arc[i][j]==1 && !visited[j] )//j为i的邻接顶点
{
printf("%c ", G.vexs[j]);
visited[j] = TRUE;
EnQueue(&Q, j);//入队列
}
}
}
}
}
}
}
邻接表—广度遍历
//邻接表广度遍历
namespace LinJieTable_BFS {
#include
using namespace std;
#define MAXVEX 100
typedef struct EdgeNode // 边表结点
{
int adjvex; // 邻接点域,存储该顶点对应的下标
int weight; // 用于存储权值,对于非网图可以不需要
struct EdgeNode *next; // 链域,指向下一个邻接点
} EdgeNode;
typedef struct VertexNode // 顶点表结点
{
char data; // 顶点域,存储顶点信息
EdgeNode *firstEdge; // 边表头指针
} VertexNode, AdjList[MAXVEX];
typedef struct {
AdjList adjList;
int numVertexes, numEdges; // 图中当前顶点数和边数
} GraphAdjList;
// 建立图的邻接表结构
void CreateALGraph(GraphAdjList *G) {
int i, j, k;
EdgeNode *e;
printf("请输入顶点数和边数:\n");
scanf("%d %d", &G->numVertexes, &G->numEdges);
// 读取顶点信息,建立顶点表
for (i = 0; i < G->numVertexes; i++) {
scanf("%c", &G->adjList[i].data);
G->adjList[i].firstEdge = NULL; // 初始化置为空表
}
//这里是无向图
for (k = 0; k < G->numEdges; k++) {
printf("请输入边(Vi,Vj)上的顶点序号:\n");
scanf("%d %d", &i, &j);
//头插法
e = (EdgeNode *) malloc(sizeof(EdgeNode));
e->adjvex = j; // 邻接序号为j
e->next = G->adjList[i].firstEdge;
G->adjList[i].firstEdge = e;
e = (EdgeNode *) malloc(sizeof(EdgeNode));
e->adjvex = i; // 邻接序号为i
e->next = G->adjList[j].firstEdge;
G->adjList[j].firstEdge = e;
}
}
#define TRUE 1
#define FALSE 0
#define MAX 256
typedef int Boolean; // 这里我们定义Boolean为布尔类型,其值为TRUE或FALSE
Boolean visited[MAX]; // 访问标志的数组
//广度遍历 我们以邻接表的规则来遍历
void BFS(GraphAdjList G) {
int i, j;
Queue Q;//队列
for (i = 0; i < G.numVertexes; i++) {
visited[i] = FALSE;
}
initQueue(&Q);//初始化队列
for (i = 0; i < G.numVertexes; i++) {
if (!visited[i]) {
printf("%c ", G.adjList[i].data);
visited[i] = TRUE;
EnQueue(&Q, i);//进入队列
while (!QueueEmpty(Q)) {
DeQueue(&Q, &i);//出队列
//遍历与顶点i邻接的顶点
for (j = 0; j < G.numVertexes; j++) {
EdgeNode *e;//邻接边节点
e = G.adjList[i].firstEdge;//e指向i的邻接边节点
if (e && !visited[e->adjvex])//e->adjvex就是顶点j
{
printf("%c ", e->adjvex);
visited[e->adjvex] = TRUE;
EnQueue(&Q, e->adjvex);//入队列
}
e = e->next;//指向下一个与i的邻接边节点
}
}
}
}
}
}
带权最小生成树
普里姆算法

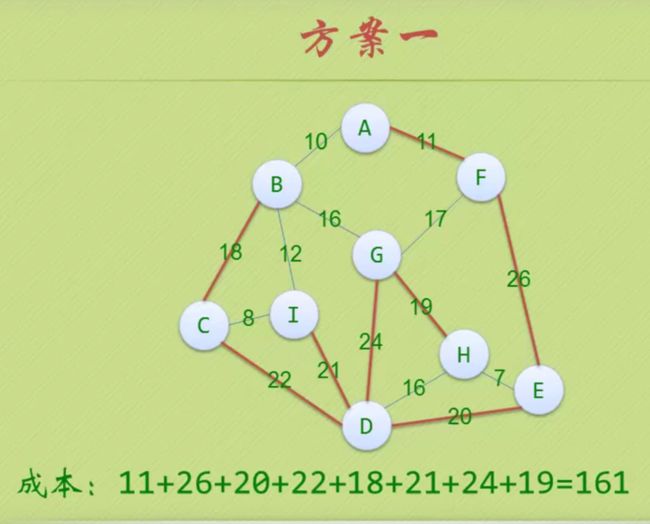
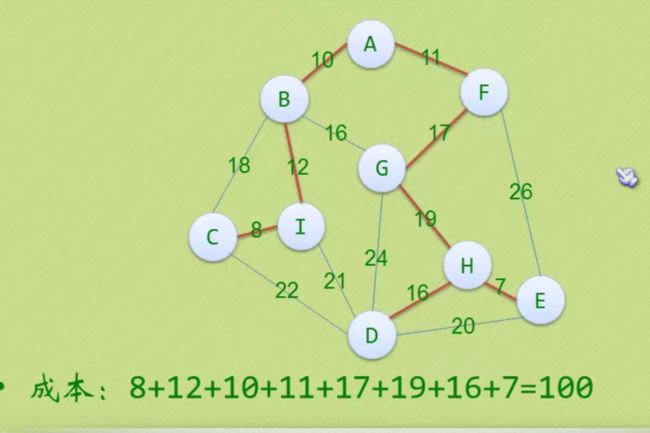



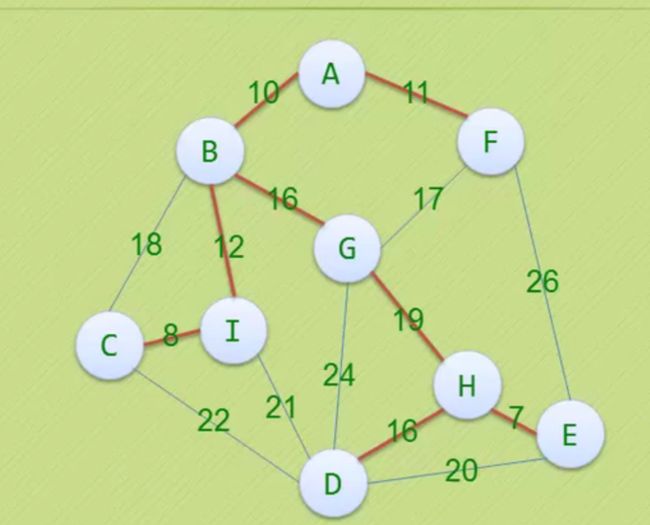
以PPT为例
下标: 0 1 2 3 4 5 6 7 8
初始化:lowcost[]: 0 10 ∞ ∞ ∞ 11 ∞ ∞ ∞ -----权重
adjvex[]: 0 0 0 0 0 0 0 0 0 ------顶点与顶点的关系 比如: [0 0 0 1 0 0 0 1 2]表示第第三个顶点、第七个顶点与第一个顶点有联系 ,第八个顶点与第二个顶点有联系
每次循环都从下标1开始
--------------
第一次循环:
min=10
k=1
输出:(0,1) 也就是(A,B)
lowcost[1]=0 表示B这个点访问过了。
下标: 0 1 2 3 4 5 6 7 8
lowcost[]: 0 0 ∞ ∞ ∞ 11 ∞ ∞ ∞ -----权重
adjvex[]: 0 0 0 0 0 0 0 0 0 ------顶点与顶点的关系 比如: [0 0 0 1 0 0 0 1 2]表示第第三个顶点、第七个顶点与第一个顶点有联系 ,第八个顶点与第二个顶点有联系
邻接矩阵 k行 逐个遍历全部顶点
lowcost[]: 0 0 ∞ ∞ ∞ 11 ∞ ∞ ∞ -----权重
10 0 18 ∞ ∞ ∞ 16 ∞ 12
两个从下标1开始 进行比较 把小的值赋给lowcost[],同时adjvex[j] = k j代表列 代表行
adjvex[]: 0 0 0 0 0 0 0 0 0 ------顶点与顶点的关系 比如: [0 0 0 1 0 0 0 1 2]表示第第三个顶点、第七个顶点与第一个顶点有联系 ,第八个顶点与第二个顶点有联系
更新 lowcost[] adjvex[]
lowcost[]: 0 0 18 ∞ ∞ 11 16 ∞ 12 -----权重
adjvex[]: 0 0 1 0 0 0 1 0 1
--------------
--------------
第二次循环
min=11
k=5
输出:(0,5)也就是(A,F)
lowcost[5]=0 表示F这个点访问过了。
lowcost[]: 0 0 18 ∞ ∞ 0 16 ∞ 12 -----权重
adjvex[]: 0 0 1 0 0 0 1 0 1
邻接矩阵 k行 逐个遍历全部顶点
lowcost[]: 0 0 18 ∞ ∞ 0 16 ∞ 12 -----权重
11 ∞ ∞ ∞ 26 0 17 ∞ ∞
两个从下标1开始 进行比较 把小的值赋给lowcost[],同时adjvex[j] = k j代表列 代表行
adjvex[]: 0 0 1 0 0 0 1 0 1
更新 lowcost[] adjvex[]
lowcost[]: 0 0 18 ∞ 26 0 16 ∞ 12 -----权重
adjvex[]: 0 0 1 0 5 0 1 0 1
--------------
--------------
第三次循环
min=12
k=8
输出:(1,8)也就是(B,I)
lowcost[8]=0 表示I这个点访问过了。
lowcost[]: 0 0 18 ∞ 26 0 16 ∞ 12 -----权重
adjvex[]: 0 0 1 0 5 0 1 0 1
邻接矩阵 k行 逐个遍历全部顶点
lowcost[]: 0 0 18 ∞ 26 0 16 ∞ 12 -----权重
∞ 12 8 21 ∞ ∞ ∞ ∞ 0
两个从下标1开始 进行比较 把小的值赋给lowcost[],同时adjvex[j] = k j代表列 代表行
adjvex[]: 0 0 1 0 5 0 1 0 1
更新 lowcost[] adjvex[]
lowcost[]: 0 0 8 21 26 0 16 ∞ 0 -----权重
adjvex[]: 0 0 8 8 5 0 1 0 8
--------------
--------------
第四次循环
min=8
k=2
输出:(8,2)也就是(I,C)
lowcost[2]=0 表示C这个点访问过了。
lowcost[]: 0 0 8 21 26 0 16 ∞ 0 -----权重
adjvex[]: 0 0 8 8 5 0 1 0 8
邻接矩阵 k行 逐个遍历全部顶点
lowcost[]: 0 0 8 21 26 0 16 ∞ 0 -----权重
∞ 18 0 22 ∞ ∞ ∞ ∞ 8
两个从下标1开始 进行比较 把小的值赋给lowcost[],同时adjvex[j] = k j代表列 代表行
adjvex[]: 0 0 8 8 5 0 1 0 8
更新 lowcost[] adjvex[]
lowcost[]: 0 0 0 21 26 0 16 ∞ 0 -----权重
adjvex[]: 0 0 2 8 5 0 1 0 8
--------------
--------------
第五次循环
min=16
k=6
输出:(1,6)也就是(B,G)
以此类推
源码如下:
// Prim算法生成最小生成树 是以邻接矩阵为结构
void MiniSpanTree_Prim(MGraph G)
{
int min, i, j, k;
int adjvex[MAXVEX]; // 保存相关顶点下标 比如[0 0 1 0 0 0 1 2]表示第第三个顶点、第七个顶点与第一个顶点有联系 ,第八个顶点与第二个顶点有联系
int lowcost[MAXVEX]; // 保存相关顶点间边的权值
lowcost[0] = 0; // V0作为最小生成树的根开始遍历,权值为0
adjvex[0] = 0; // V0第一个加入
// 初始化操作
for( i=1; i < G.numVertexes; i++ )
{
lowcost[i] = G.arc[0][i]; // 将邻接矩阵第0行所有权值先加入数组
adjvex[i] = 0; // 初始化全部先为V0的下标
}
//以PPT为例
//至此 lowcost[]里面的值是 0 10 INFINITY INFINITY INFINITY 11 INFINITY INFINITY INFINITY
// 真正构造最小生成树的过程
for( i=1; i < G.numVertexes; i++ )
{
min = INFINITY; // 初始化最小权值为65535等不可能数值
j = 1;
k = 0;
// 遍历全部顶点
while( j < G.numVertexes )
{
// 找出lowcost数组已存储的最小权值
if( lowcost[j]!=0 && lowcost[j] < min )// lowcost[j]!=0表示不让自己指向自己
{
min = lowcost[j];//找到最小的那个权值
k = j; // 将发现的最小权值的下标存入k,以待使用。k=1 k=5
}
j++;
}
// 打印当前顶点边中权值最小的边
printf("(%d,%d)", adjvex[k], k);//
lowcost[k] = 0; // 将当前顶点的权值设置为0,表示此顶点已经完成任务,进行下一个顶点的遍历
//对于顶点A来说,权值最小的边是B顶点 所以k=1
// 邻接矩阵k行逐个遍历全部顶点
//对于已经走过了的顶点间的边就设为0 更新顶点与顶点之间的联系
for( j=1; j < G.numVertexes; j++ )
{
//比较与k这个顶点相连顶点的权值与上一顶点相关连顶点的权值
if( lowcost[j]!=0 && G.arc[k][j] < lowcost[j] )
{
lowcost[j] = G.arc[k][j];//更新权重 选最小的权 权重的下标就代表着顶点的标号
// 这一步是最关键的,这里更新权重它是这样的原则,我们把第k个顶点与其他顶点边的权重拿出,与原来的权重数组做对比,选小的那个以更新权重数组 为了能够到达第j个顶点是最小的权重
adjvex[j] = k; //更新顶点与顶点之间的联系
//之后会在下一次大循环中用到更新的权重数组,再选最小的那个顶点 而且此时adjvex也是更新过的 ,那么第k个顶点到第adjvex[k]个顶点就是最小权重最小权重
}
}
}
}
克鲁斯卡尔算法
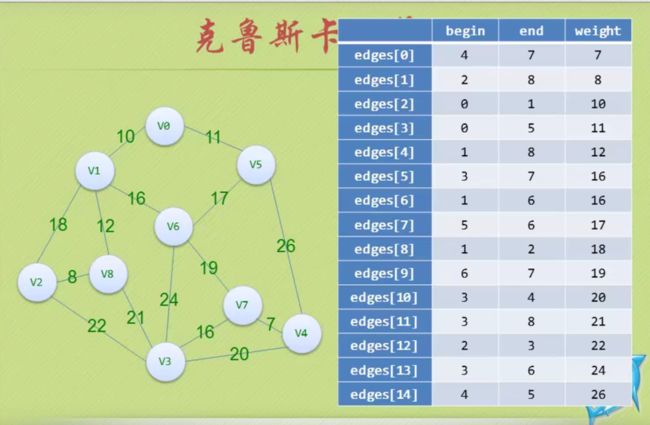
基于边集数组的图结构
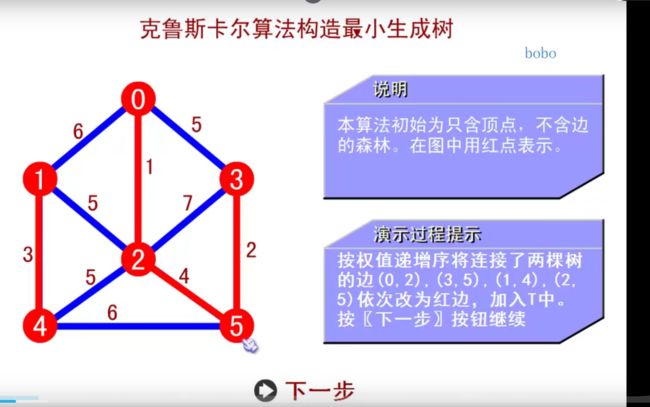
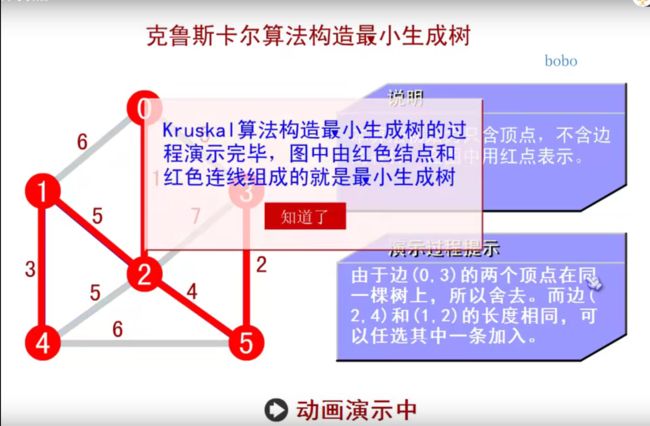
如果把(0,3)这个边加入,这样 0 2 3 5就构成了一个环路,就不是树了。
同理在(1,2) 和(4,2)选一个就行了

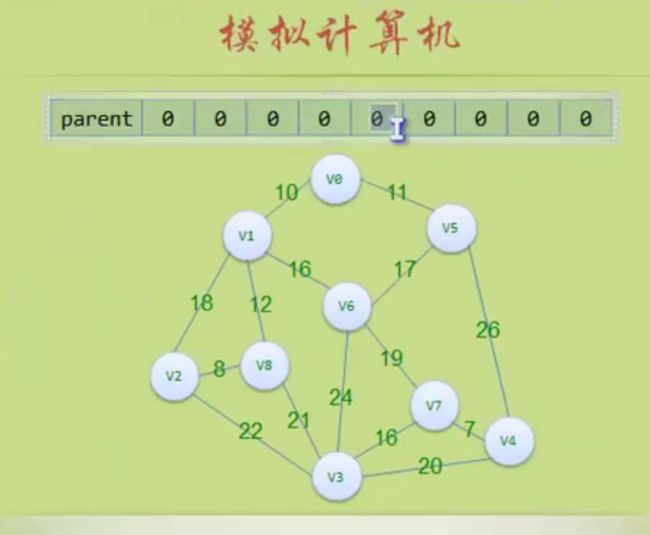
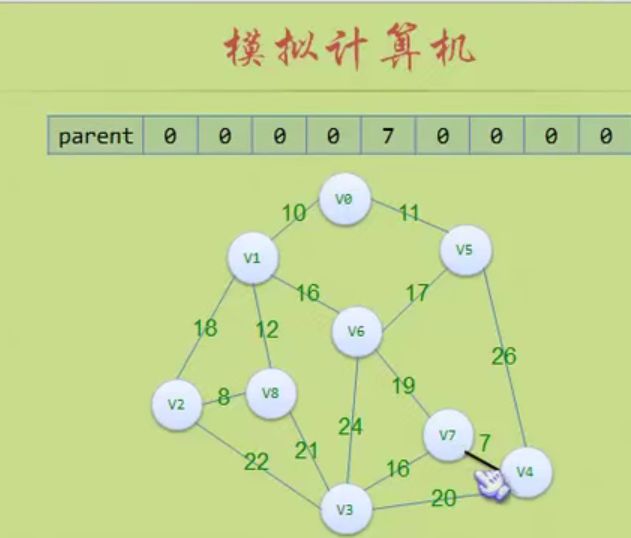
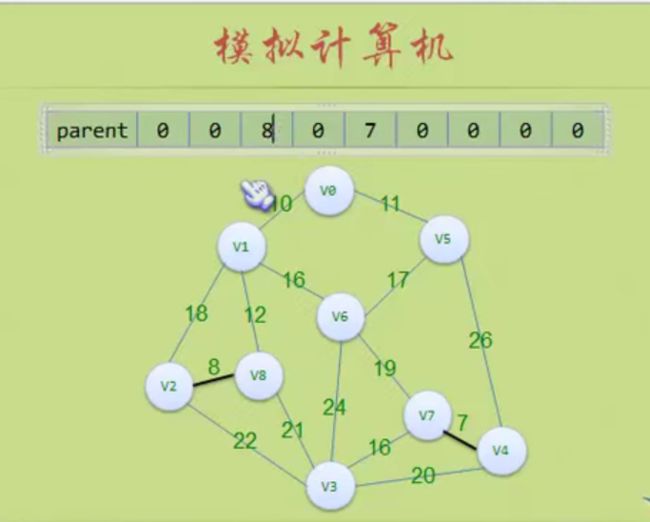
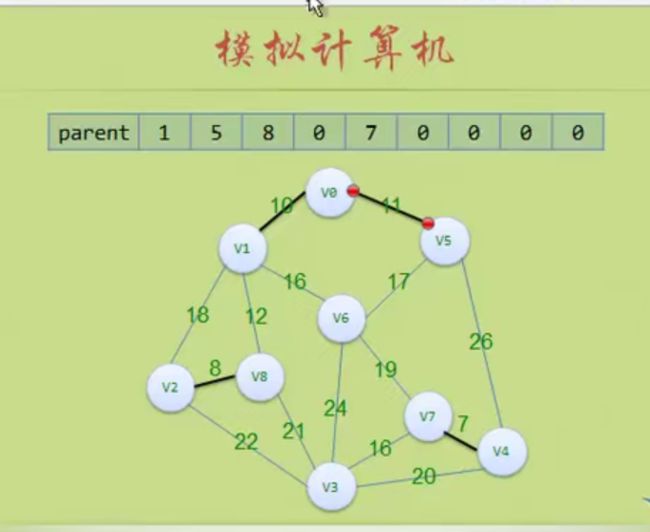



到这里就判断出环路了 (5,6)不能加入
并且下一个(1,2)也被判断为形成环路,不能加入
这里可以看出parent数组的作用,它里面其实是将树的顶点关联了起来。
比如(5,6):
对于5来说 parent[5]=8 parent[8]=6 parent[6]=0 返回6
对于6来说 parent[6]=0 ,返回6,n==m 那就形成环路,不是树了,不加入这个边
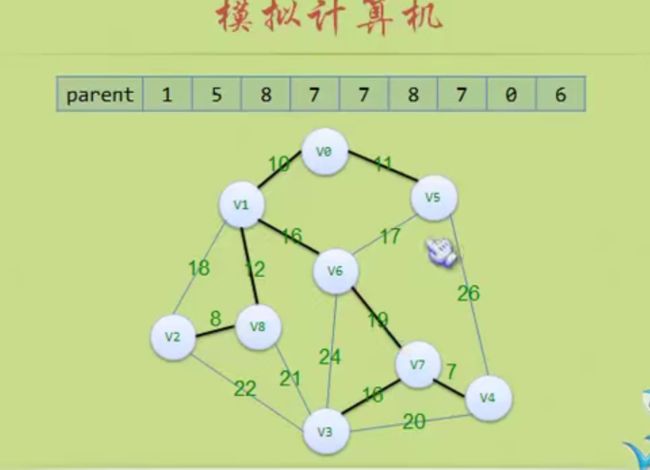
后面(3,4)也构成环路,不加入这个边
然后后面的都会构成环路!
这个算法更好理解!!!因为用的边集结构,好理解一点。
对于稀疏图来说(也就是边不是那么多),克鲁卡尔斯算法有优势。
对于稠密图(顶点比较少,边比较多的),普里姆算法有优势。
代码如下:
int Find(int *parent, int f)
{
while( parent[f] > 0 )
{
f = parent[f];
}
return f;
}
// Kruskal算法生成最小生成树
void MiniSpanTree_Kruskal(MGraph G)
{
int i, n, m;
Edge edges[MAGEDGE]; // 定义边集数组
int parent[MAXVEX]; 定义parent数组用来判断边与边是否形成环路
for( i=0; i < G.numVertexes; i++ )//初始化parent
{
parent[i] = 0;
}
for( i=0; i < G.numEdges; i++ )
{
n = Find(parent, edges[i].begin); // 4 2 0 1 5 3 8 6 6 6 7
m = Find(parent, edges[i].end); // 7 8 1 5 8 7 6 6 6 7 7
if( n != m ) // 如果n==m,则形成环路,不满足!
{
parent[n] = m; // 将此边的结尾顶点放入下标为起点的parent数组中,表示此顶点已经在生成树集合中
printf("(%d, %d) %d ", edges[i].begin, edges[i].end, edges[i].weight);
}
}
}
最短路径
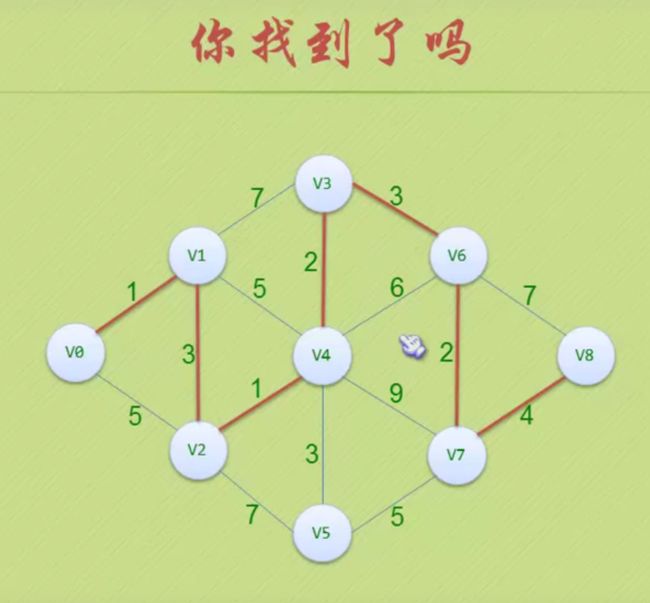
迪杰斯特拉
final[MAXVEX]; // final[w] = 1 表示已经求得顶点V0到Vw的最短路径
(*D)[w] = min + G.arc[k][w]; // 修改当前路径长度 用于存储到各点最短路径的权值和
(*p)[w] = k; // 存放前驱顶点 比如 p[2]=1 表示2的前驱顶点是1 也就是从顶点1走到顶点2 用于存储最短路径下标的数组



#define MAXVEX 9
#define INFINITY 65535
typedef int Patharc[MAXVEX]; // 用于存储最短路径下标的数组
typedef int ShortPathTable[MAXVEX]; // 用于存储到各点最短路径的权值和
void ShortestPath_Dijkstar(MGraph G, int V0, Patharc *P, ShortPathTable *D)
{
int v, w, k, min;
int final[MAXVEX]; // final[w] = 1 表示已经求得顶点V0到Vw的最短路径
// 初始化数据
for( v=0; v < G.numVertexes; v++ )
{
final[v] = 0; // 全部顶点初始化为未找到最短路径
(*D)[V] = G.arc[V0][v]; // 将与V0点有连线的顶点加上权值
(*P)[V] = 0; // 初始化路径数组P为0
}
(*D)[V0] = 0; // V0至V0的路径为0
final[V0] = 1; // V0至V0不需要求路径
// 开始主循环,每次求得V0到某个V顶点的最短路径
for( v=1; v < G.numVertexes; v++ )
{
min = INFINITY;
for( w=0; w < G.numVertexes; w++ )
{
if( !final[w] && (*D)[w]最终的结果
final[MAXVEX]; // final[w] = 1 表示已经求得顶点V0到Vw的最短路径
(*D)[w] = min + G.arc[k][w]; // 修改当前路径长度 用于存储到各点最短路径的权值和
(*p)[w] = k; // 存放前驱顶点 比如 p[2]=1 表示2的前驱顶点是1 也就是从顶点1走到顶点2 用于存储最短路径下标的数组
N代表无穷也就是代码里的65535
初始化:
final: 1 0 0 0 0 0 0 0 0
D: 0 1 5 N N N N N N
P: 0 0 0 0 0 0 0 0 0
从v=1开始 v表示顶点1
**********第一次主循环
k=1;
min=1;
更新final 表示V0到Vk的最短路径找到了
final: 1 1 0 0 0 0 0 0 0
更新D 、P
D: 0 1 4 N N N N N N
P: 0 0 1 0 0 0 0 0 0
**********第一次主循环
**********第二次主循环
final: 1 1 0 0 0 0 0 0 0
D: 0 1 4 N N N N N N
P: 0 0 1 0 0 0 0 0 0
k=2;
min=4;
更新final 表示V0到Vk的最短路径找到了
final: 1 1 1 0 0 0 0 0 0
更新D 、P
D: 0 1 4 N 5 N N N N
P: 0 0 1 0 2 0 0 0 0
**********第二次主循环
**********第三次主循环
final: 1 1 1 0 0 0 0 0 0
D: 0 1 4 N 5 N N N N
P: 0 0 1 0 2 0 0 0 0
k=4;
min=5;
更新final 表示V0到Vk的最短路径找到了
final: 1 1 1 0 1 0 0 0 0
更新D 、P
D: 0 1 4 7 5 N N N N
P: 0 0 1 4 2 0 0 0 0
**********第三次主循环
**********第四次主循环
final: 1 1 1 0 1 0 0 0 0
D: 0 1 4 7 5 N N N N
P: 0 0 1 4 2 0 0 0 0
k=3;
min=7;
更新final 表示V0到Vk的最短路径找到了
final: 1 1 1 1 1 0 0 0 0
更新D 、P
D: 0 1 4 7 5 N 10 N N
P: 0 0 1 4 2 0 3 0 0
**********第四次主循环
**********第五次主循环
final: 1 1 1 1 1 0 0 0 0
D: 0 1 4 7 5 N 10 N N
P: 0 0 1 4 2 0 3 0 0
k=6;
min=10
更新final 表示V0到Vk的最短路径找到了
final: 1 1 1 1 1 0 1 0 0
更新D 、P
D: 0 1 4 7 5 N 10 12 N
P: 0 0 1 4 2 0 3 6 0
**********第五次主循环
**********第六次主循环
final: 1 1 1 1 1 0 1 0 0
D: 0 1 4 7 5 N 10 12 N
P: 0 0 1 4 2 0 3 6 0
k=7;
min=12;
更新final 表示V0到Vk的最短路径找到了
final: 1 1 1 1 1 0 1 1 0
更新D 、P
D: 0 1 4 7 5 N 10 12 16
P: 0 0 1 4 2 0 3 6 7
**********第六次主循环
**********第七次主循环
final: 1 1 1 1 1 0 1 1 0
D: 0 1 4 7 5 N 10 12 16
P: 0 0 1 4 2 0 3 6 7
k=8;
min=14;
更新final 表示V0到Vk的最短路径找到了
final: 1 1 1 1 1 0 1 1 1
更新D 、P
D: 0 1 4 7 5 N 10 12 16
P: 0 0 1 4 2 0 3 6 7
**********第七次主循环
**********第八次主循环
final: 1 1 1 1 1 0 1 1 1
D: 0 1 4 7 5 N 10 12 16
P: 0 0 1 4 2 0 3 6 7
**********第八次主循环
结束循环
final: 1 1 1 1 1 0 1 1 1
D: 0 1 4 7 5 N 10 12 16
P: 0 0 1 4 2 0 3 6 7
路线是 0->1->2->4->3->6->7->8
弗洛伊德


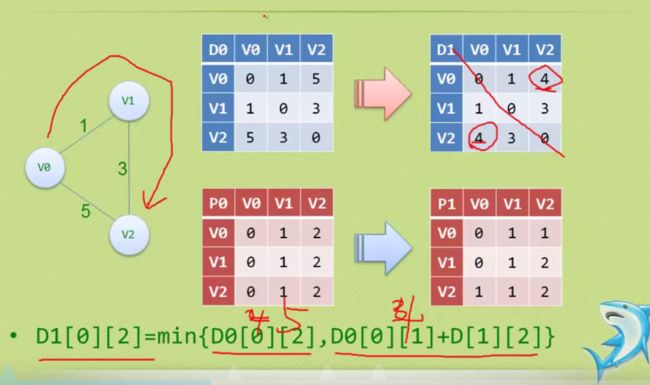
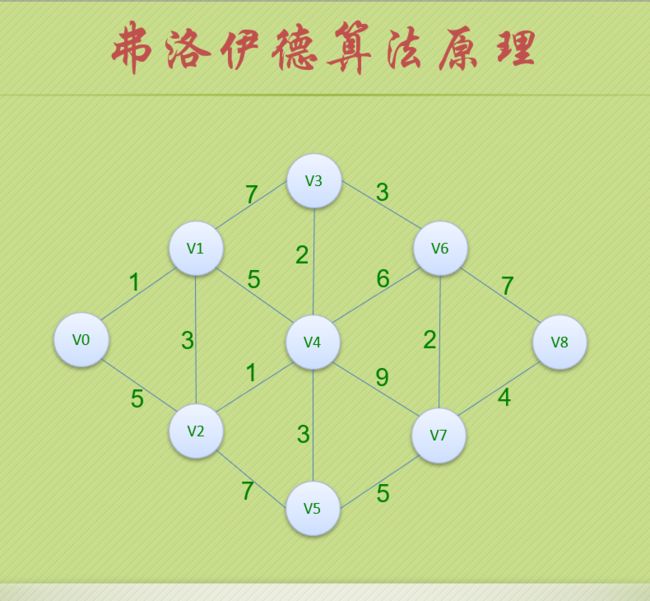
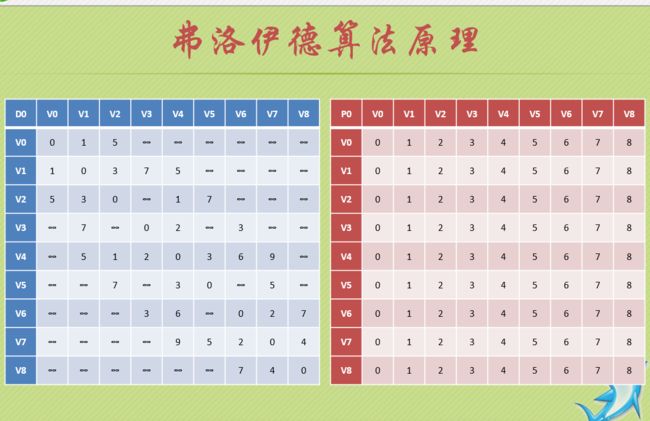

#define MAXVEX 9
#define INFINITY 65535
typedef int Pathmatirx[MAXVEX][MAXVEX];
typedef int ShortPathTable[MAXVEX][MAXVEX];
void ShortestPath_Floyd(MGraph G, Pathmatirx *P, ShortPathTable *D)
{
int v, w, k;
// 初始化D和P
for( v=0; v < G.numVertexes; v++ )
{
for( w=0; w < G.numVertexes; w++ )
{
(*D)[v][w] = G.matirx[v][w]; //获取邻接矩阵
(*P)[v][w] = w;//初始化各个边之间的前驱节点
}
}
// 优美的弗洛伊德算法
//这三层循环将所有边,两两之间都考虑进去了
//对于D数组来说
//需要改变的D的元素有内部由两个变量 v w 控制 也就是边(v,w)
//比如(0,2)也就是0->2这个路线 这时候会对应 以下几种情况 (0,2)>(0 ,0)+(0,2) (0,2)>(0 ,1)+(1,2)
// 也就是从0到2 我们可以这样走:从0到1,再从1到2
// (v,w)>(v,k)+(k,w), k起到了换路线的作用 而v w则是负责边的两端的顶点
//对于P数组来说 (*P)[v][w] = (*P)[v][k]; 也就是说对于(v,w)走向 可以利用(v,k)->(k,w)的路线,所以对于(v,w)的w来说,他的前驱节点就是k啦!!!
//经过三层循环,可以把所有情况考虑进去
//比如0->3 有这么几种走法 0->1 + 1->3
// 0->2 + 2->3 =0->1 + 1->2 + 2->4 + 4->3
// 上面两种情况都会被考虑进去,所以弗洛伊德算法很简单,但事件复杂度高 O(n^3)
for( k=0; k < G.numVertexes; k++ )
{
for( v=0; v < G.numVertexes; v++ )
{
for( w=0; w < G.numVertexes; w++ )
{
if( (*D)[v][w] > (*D)[v][k] + (*D)[k][w] )//这里的 v代表列 k达标
{
(*D)[v][w] = (*D)[v][k] + (*D)[k][w];
(*P)[v][w] = (*P)[v][k]; // 请思考:这里换成(*P)[k][w]可以吗?为什么?
}
}
}
}
}
拓扑排序



拓扑结构 一定要前面指向后面

采用邻接表


// 边表结点声明
typedef struct EdgeNode
{
int adjvex;
struct EdgeNode *next;
}EdgeNode;
// 顶点表结点声明
//邻接表
typedef struct VertexNode
{
int in; // 顶点入度
int data;
EdgeNode *firstedge;
}VertexNode, AdjList[MAXVEX];
//有向图结构
typedef struct
{
AdjList adjList;
int numVertexes, numEdges;
}graphAdjList, *GraphAdjList;
// 拓扑排序算法
// 若GL无回路,则输出拓扑排序序列并返回OK,否则返回ERROR
Status TopologicalSort(GraphAdjList GL)
{
EdgeNode *e;
int i, k, gettop;
int top = 0; // 用于栈指针下标索引
int count = 0; // 用于统计输出顶点的个数
int *stack; // 用于存储入度为0的顶点
stack = (int *)malloc(GL->numVertexes * sizeof(int));
//对入读为0的顶点下标入栈
for( i=0; i < GL->numVertexes; i++ )
{
if( 0 == GL->adjList[i].in )
{
stack[++top] = i; // 将度为0的顶点下标入栈
}
}
//这里top是12
while( 0 != top )
{
gettop = stack[top--]; // 出栈
printf("%d -> ", GL->adjList[gettop].data);
count++;
//这里是遍历栈里面顶点邻接的顶点
for( e=GL->adjList[gettop].firstedge; e; e=e->next )
{
k = e->adjvex;
// 注意:下边这个if条件是分析整个程序的要点!
// 将k号顶点邻接点的入度-1,因为他的前驱已经消除
// 接着判断-1后入度是否为0,如果为0则也入栈
if( !(--GL->adjList[k].in) ) //因为按算法原理来说,每拿出一个入读为零的顶点,用完之后,就把它从图中删掉。所以其邻接的顶点入度就会相应-1
//如果对于GL->adjList[k]这个顶点来说,它的入度为0,那么它也要入栈了
{
stack[++top] = k;
}
}
}
if( count < GL->numVertexes ) // 如果count小于顶点数,说明存在环
{
return ERROR;
}
else
{
return OK;
}
}
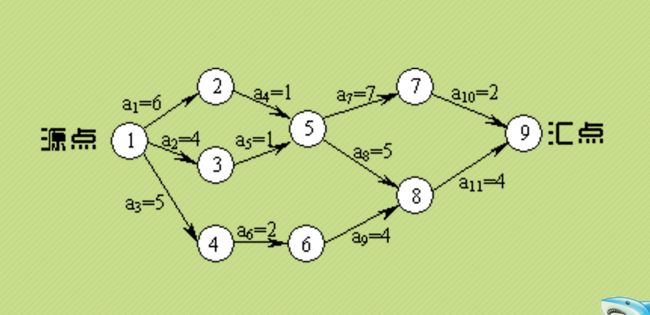
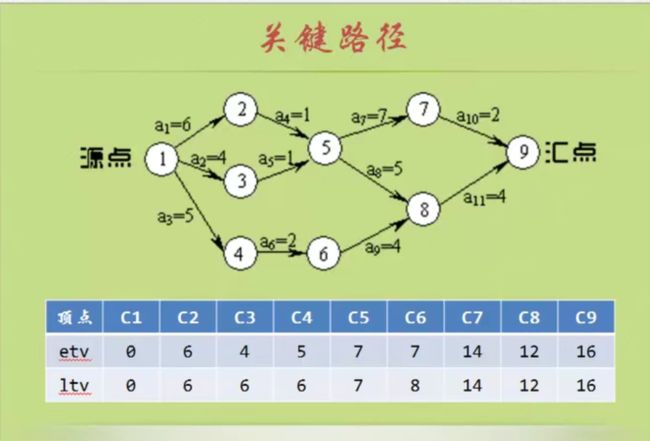
关键路径



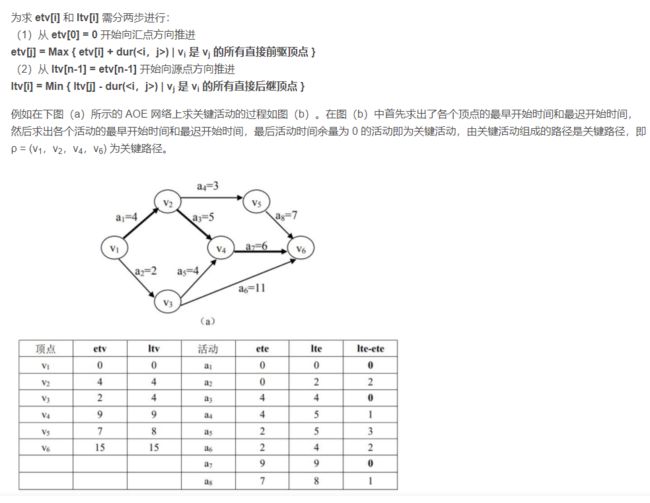

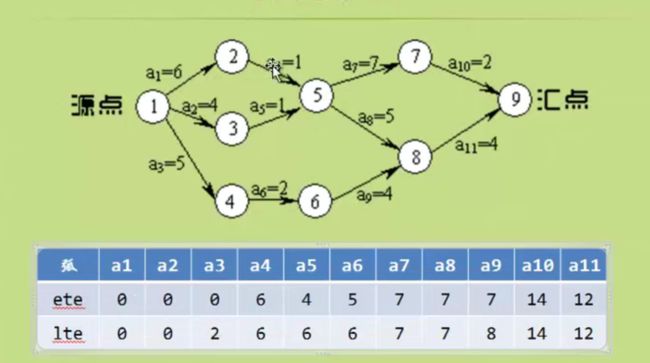
etv是从左往右推的
ltv是从右往左推的
对于顶点来说
顶点j在顶点i的后面,并且是相邻的
顶点Vi的最早发生时间 +(vi,vj)的权 = 顶点j的最早发生时间
顶点 Vj 的最晚发生时间 -(vi,vj)的权 = 顶点i的最晚发生时间
比如:
对于C8的ltv来说 可以这么理解
C8的最晚发生时间是8, 最早发生时间是7 ,说明C8可以 偷懒一个小时,为什么呢,因为顶点5到顶点8 要5个小时,而顶点6到顶点8只要4个小时
顶点8要开始工作,必须两个路线都走了才行,5->8时间久一点,那么6->8当然可以偷懒咯
对于弧来说。他们是时间持续的时间
顶点k在顶点j的后面,并且是相邻的
顶点k与顶点j之间的弧的最早发生时间=顶点j的最早发生时间
顶点k与顶点j之间的弧的的最晚发生时间= 顶点k的最晚发生时间- 顶点k与顶点j之间的权
比如:
对于弧a4来说它的ete最早发生时间就是顶点C2的最早发生时间etv。
lte也是从右往左推,比如a11,a11的最晚发生时间lte=顶点C9的最晚发生时间–4 =16-4=12 其他的以此类推。
总结:
对于顶点来说:
顶点j在顶点i的后面,并且是相邻的
顶点Vi的最早发生时间 +(vi,vj)的权 = 顶点j的最早发生时间
顶点 Vj 的最晚发生时间 -(vi,vj)的权 = 顶点i的最晚发生时间
对于弧来说。他们是时间持续的时间:
顶点k在顶点j的后面,并且是相邻的
顶点k与顶点j之间的弧的最早发生时间=顶点j的最早发生时间
顶点k与顶点j之间的弧的的最晚发生时间= 顶点k的最晚发生时间- 顶点k与顶点j之间的权
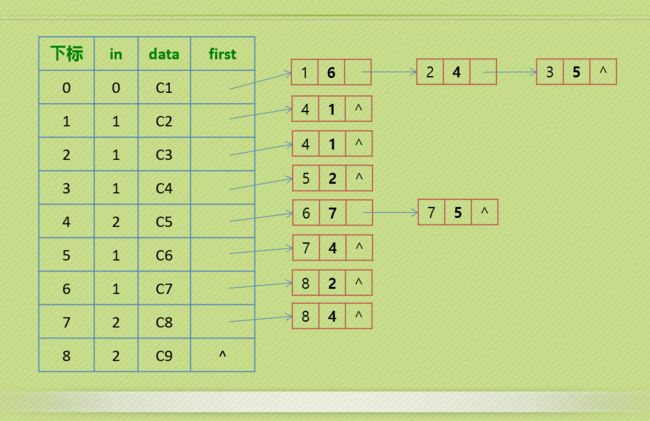
// 边表结点声明
typedef struct EdgeNode
{
int adjvex;
struct EdgeNode *next;
}EdgeNode;
// 顶点表结点声明
typedef struct VertexNode
{
int in; // 顶点入度
int data;
EdgeNode *firstedge;
}VertexNode, AdjList[MAXVEX];
typedef struct
{
AdjList adjList;
int numVertexes, numEdges;
}graphAdjList, *GraphAdjList;
int *etv, *ltv;
int *stack2; // 用于存储拓扑序列的栈
int top2; // 用于stack2的栈顶指针
// 拓扑排序算法
// 若GL无回路,则输出拓扑排序序列并返回OK,否则返回ERROR
/**
* 求出了拓扑排序,并且求出了etv
* @param GL
* @return
*/
Status TopologicalSort(GraphAdjList GL)
{
EdgeNode *e;
int i, k, gettop;
int top = 0; // 用于栈指针下标索引
int count = 0; // 用于统计输出顶点的个数
int *stack; // 用于存储入度为0的顶点
stack = (int *)malloc(GL->numVertexes * sizeof(int));
for( i=0; i < GL->numVertexes; i++ )
{
if( 0 == GL->adjList[i].in )
{
stack[++top] = i; // 将度为0的顶点下标入栈
}
}
// 初始化etv都为0
top2 = 0;
etv = (int *)malloc(GL->numVertexes*sizeof(int));
for( i=0; i < GL->numVertexes; i++ )
{
etv[i] = 0;
}
stack2 = (int *)malloc(GL->numVertexes*sizeof(int));
while( 0 != top )
{
gettop = stack[top--]; // 出栈
// printf("%d -> ", GL->adjList[gettop].data);
stack2[++top2] = gettop; // 保存拓扑序列顺序 C1 C2 C3 C4 .... C9
count++;
for( e=GL->adjList[gettop].firstedge; e; e=e->next )
{
k = e->adjvex;//k就是邻接的顶点
// 注意:下边这个if条件是分析整个程序的要点!
// 将k号顶点邻接点的入度-1,因为他的前驱已经消除
// 接着判断-1后入度是否为0,如果为0则也入栈
//这里是拓扑排序
if( !(--GL->adjList[k].in) )
{
stack[++top] = k;
}
//
if( (etv[gettop]+e->weight) > etv[k] )//这一步很关键 这里用来计算顶点的最早发生时间 这个根据PPT的图片来进行理解比较好
//大的值就是顶点k的最早发生时间,相当于就是顶点Vi的最早发生时间 +(vi,vj)的权 = 顶点j的最早发生时间
{
etv[k] = etv[gettop] + e->weight;
}
}
}
if( count < GL->numVertexes ) // 如果count小于顶点数,说明存在环
{
return ERROR;
}
else
{
return OK;
}
}
// 求关键路径,GL为有向图,输出GL的各项关键活动
void CriticalPath(GraphAdjList GL)
{
EdgeNode *e;
int i, gettop, k, j;
int ete, lte;
// 调用改进后的拓扑排序,求出etv和stack2的值
TopologicalSort(GL);
// 初始化ltv都为汇点的时间
ltv = (int *)malloc(GL->numVertexes*sizeof(int));
for( i=0; i < GL->numVertexes; i++ )
{
ltv[i] = etv[GL->numVertexes-1];
}
// 从汇点倒过来逐个计算ltv
while( 0 != top2 )
{
gettop = stack2[top2--]; // 注意,第一个出栈是汇点 第一个出栈的汇点其实没什么卵用,因为它的 firstedge指向空
//当到了C8的时候就开始真正的计算了
for( e=GL->adjList[gettop].firstedge; e; e=e->next )
{
k = e->adjvex;
if( (ltv[k] - e->weight) < ltv[gettop] )//这里要填一个小的,为了不让工期延误 从源点的ltv就可以看懂这个代码了
{
ltv[gettop] = ltv[k] - e->weight;//顶点gettop的最晚发生时间 = 顶点k的最晚发生时间 - 顶点gettop与顶点k之间的权
}
}
}
// 通过etv和ltv求ete和lte
for( j=0; j < GL->numVertexes; j++ )
{
//遍历顶点的左右邻接顶点
for( e=GL->adjList[j].firstedge; e; e=e->next )
{
k = e->adjvex;//获得邻接顶点
ete = etv[j];//换算得到ete 顶点k与顶点j之间的弧的最早发生时间 = 顶点j的最早发生时间
lte = ltv[k] - e->weight;//换算得到lte 顶点k与顶点j之间的弧的的最晚发生时间 = 顶点k的最晚发生时间- 顶点k与顶点j之间的权
if( ete == lte )//如果 ete等于lte就打印
{
printf(" length: %d , ", GL->adjList[j].data, GL->adjList[k].data, e->weight );
}
}
}
}
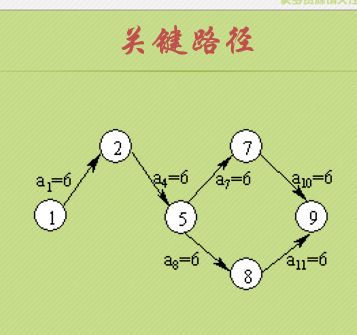
最终的结果
查找算法
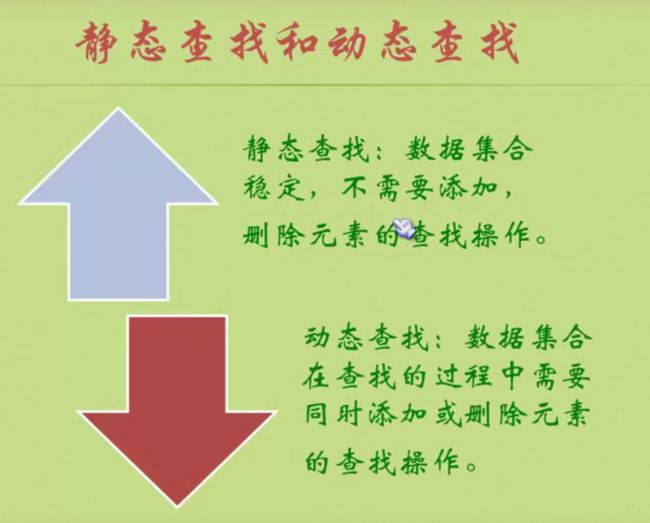

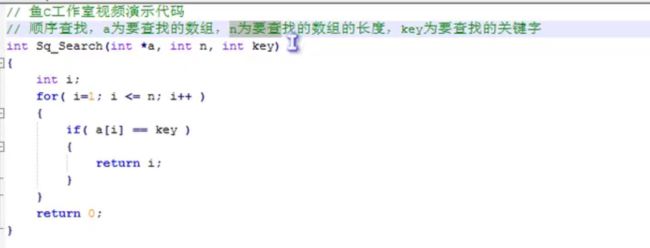
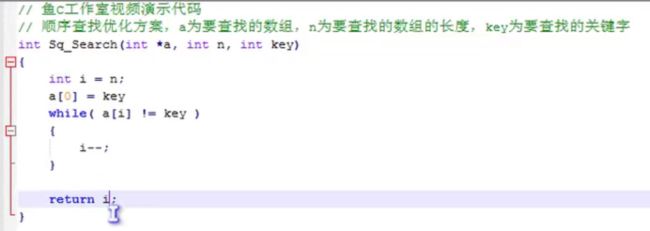
顺序查找


折半查找


插值查找(按比例查找)
插值就是利用比例得到最接近的位置。
插值法和折半法的时间复杂度都是 O(log2n)。
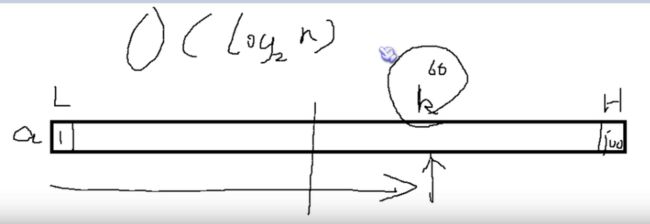
平均来说,插值法性能要比折半法高
但是,如果数据增长及其不均匀,比如 从1 到 1000到10000 到100000000,那么此时插值法效率就不行了,因为它的比例没什么意义
斐波那契查找(黄金比例查找)


//我们从代码里来看就懂了
//其实就是利用黄金比例来定位mid
//条件:(1)数据必须采用顺序存储结构;(2)数据必须有序。
//原理:(1)最接近查找长度的斐波那契值来确定拆分点;(2)黄金分割。
int Fibonacci_Search(int *a,int n,int key)
{
int low,high,mid,i,k;
low=1;
high=n;//a数组的最大下标
k=0;
while(n>F[k]-1)//计算n位于斐波那契数列的weizhi
{
k++;
}
for(i=n;ia[mid])
{
low=mid+1;//调整最低下标
k=k-2;//斐波那契数列下标-2
}
else//相等
{
if(mid<=n)
return mid;
else//如果mid>n 说明是不全数值,返回n
return n;
}
}
return 0;
}
参考博客
线性索引查找
稠密索引
稠密索引,应用在数据量不是特别大的情况。
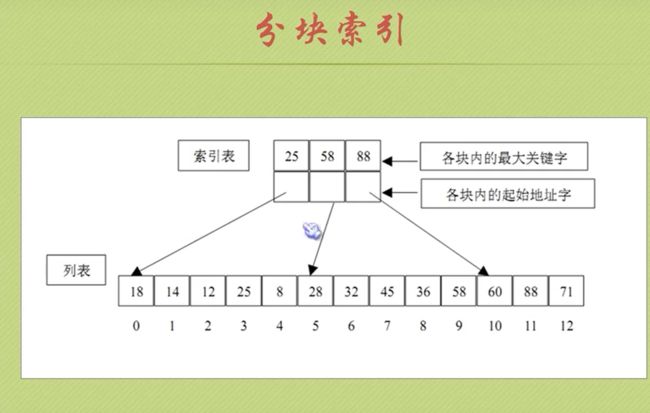
分块索引

倒排索引

二叉排序树
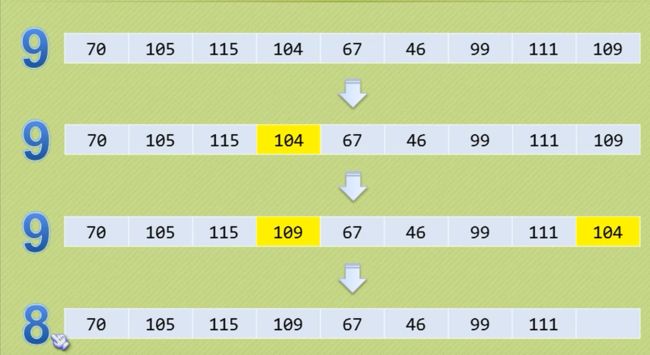
二叉排序树根据大小进行生成
总体原则就是大的在右,小的在左
二叉排序树查找
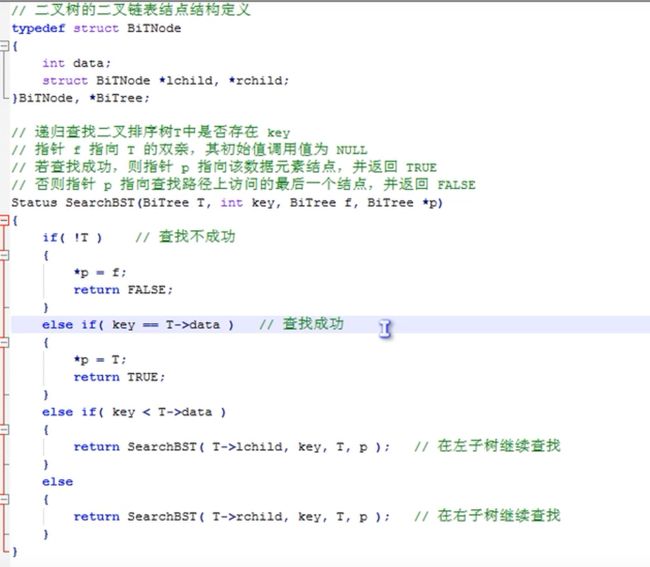
二叉排序树插入
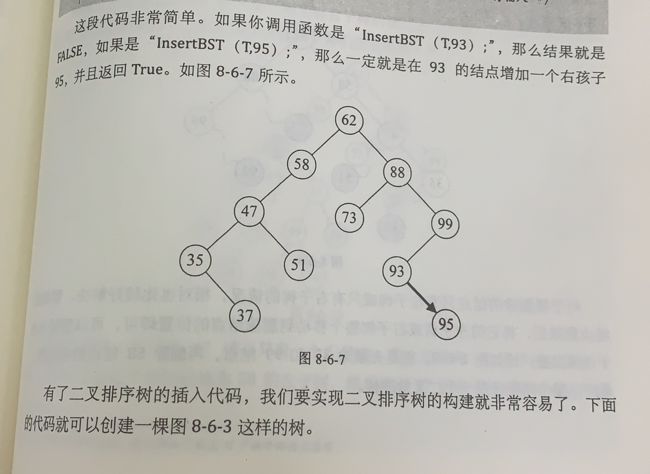

二叉排序树删除
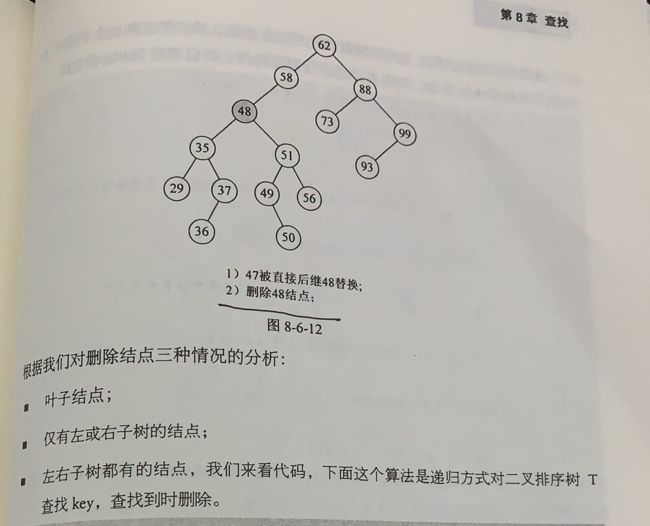
#include
typedef struct BiTNode
{
int data;
struct BiTNode *lchild,*rchild;
}BiTNode,*BiTree;
typedef int Status;
#define TRUE 1
#define FALSE 0
//二叉树排序查找
Status SearchBST()
{
}
/**
* 具体删除操作
* @param p
* @return
*/
Status Delete(BiTree *p)
{
BiTree q, s;
if((*p)->rchild==NULL)//右子树为空
{
q=*p;
*p=(*p)->lchild;//把左子树接过来
free(q);
}
else if((*p)->lchild==NULL)//左子树为空
{
q=*p;
*p=(*p)->rchild;//把右子树接过来
free(q);
}
//对于左右子树都是空的情况 直接用最上面的右子树为空的方法就行了
else//左右子树都不是空
{
//用直接前驱替换
//怎样找直接前驱呢 直接让s指向*p的左子树
//然后找s最下面的右子树就是前驱节点
q=*p;
s=(*p)->lchild;
while(s->rchild)
{
q=s;
s=s->rchild;
}
(*p)->data=s->data;
if(q!=*p)//这里的q应该是s的前驱节点
{
q->rchild=s->lchild;//重接q的右子树
}
else//也就是*p的左子树没有右子树
{
q->lchild=s->lchild;//重接q的左子树 这里的q 其实就是(*p)
}
free(s);
}
return TRUE;
}
/**
* 二叉树排序删除操作
* @param T
* @param key
* @return
*/
Status DeleteBST(BiTree *T,int key)
{
if(!*T)
{
return FALSE;
}
else
{
if(key==(*T)->data)//找到这个要删除的节点
{
return Delete(T);
}
else if(key<(*T)->data)//如果目标值小于当前节点的值,就递归调用 进入当前节点的左子树
{
return DeleteBST(&(*T)->lchild,key);
}
else //如果目标值大于当前节点的值,就递归调用 进入当前节点的右子树
{
return DeleteBST(&(*T)->rchild,key);
}
}
}
平衡二叉树


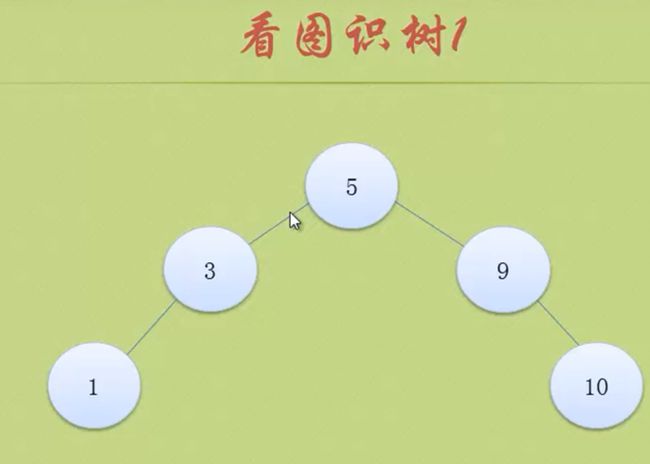
上图是一个平衡二叉排序树

上图不是平衡二叉排序树,它连二叉排序树都不是

上图也不是一个平衡二叉排序树,因为对于9那个节点来说,它的左子树深度是2 右子树深度是0 ,2-0=2 不符合平衡二叉树的条件
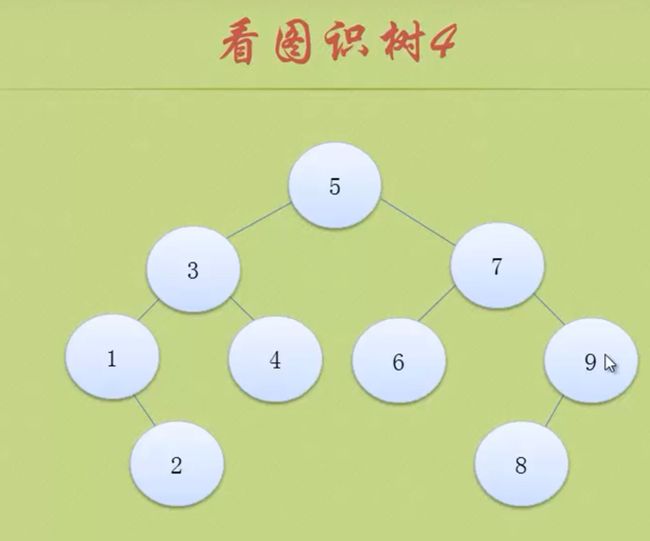
上图就是个平衡二叉排序树
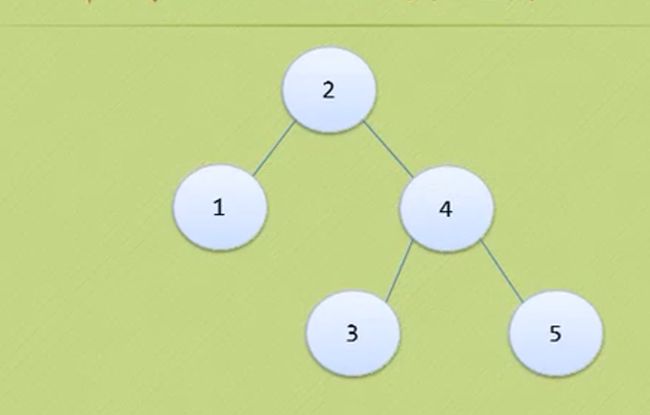
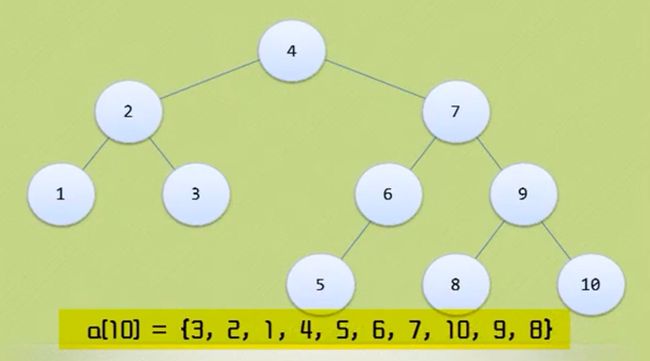
如何将图三转换为图四里的平衡二叉排序树。
每当插入这个节点都要检查 这个节点是否会导致失衡 也就是平衡因子是否大于1。
比如6这个节点插入进去后,节点9就的平衡因子就>1了。
9 7 6构成了最小子树。
我们先不管8这个节点
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QutSZOzl-1632644707197)(C:\Users\dell\AppData\Roaming\Typora\typora-user-images\image-20210923150821420.png)]
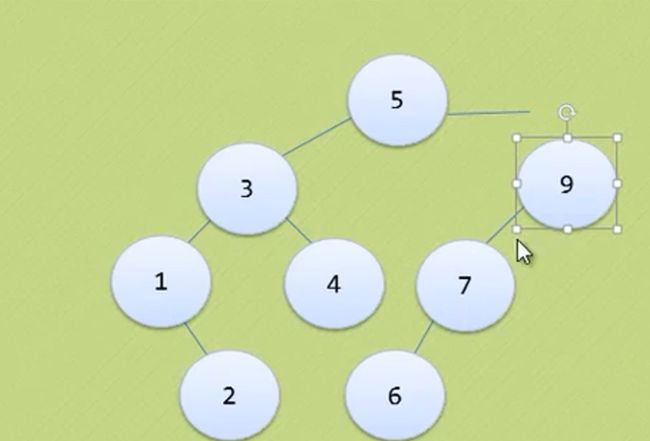
原理
上图是一个普通二叉排序树
那如何把上图的普通的二叉排序树变成平衡二叉排序树呢,我们一步一步来!!!

BF>1 右旋转

BF<-1左旋转


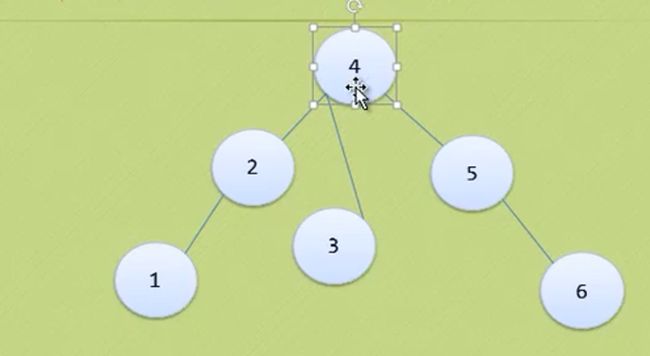

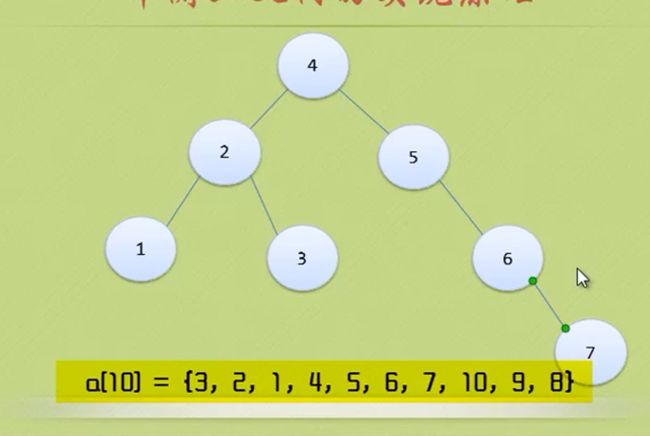
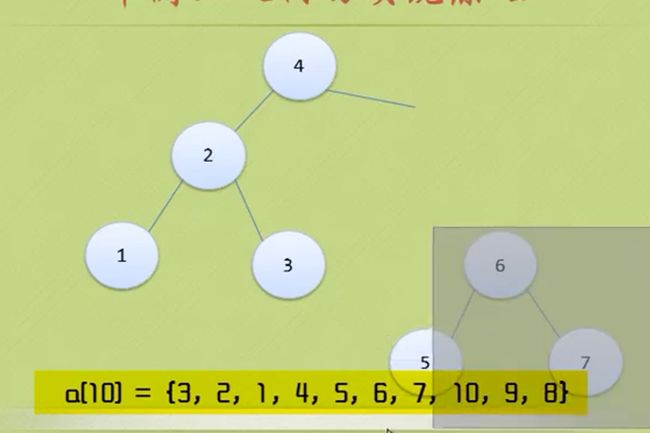

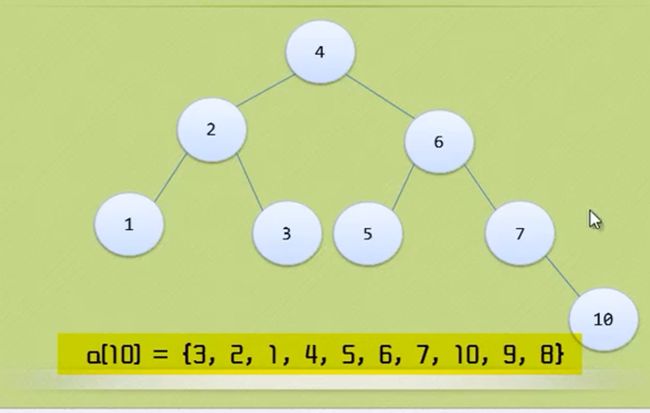

节点9进来后,导致节点4 BF=-2 、节点6 BF=-2 、节点7 BF=-2、节点10 BF=1 很奇怪 只有节点10的BF是正数
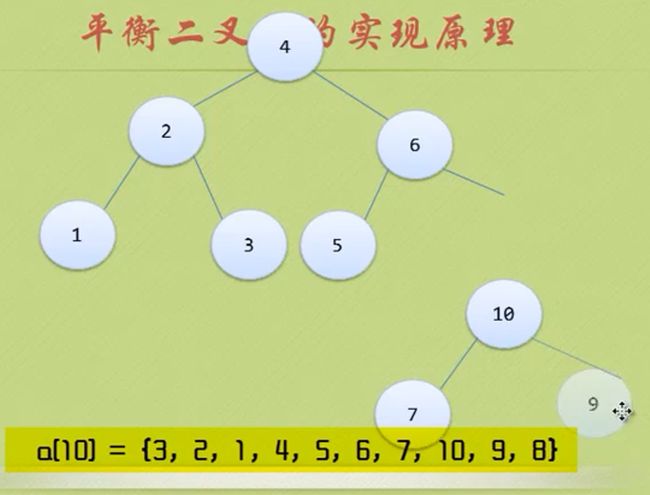
到这里明显不符合二叉树排序的规则。
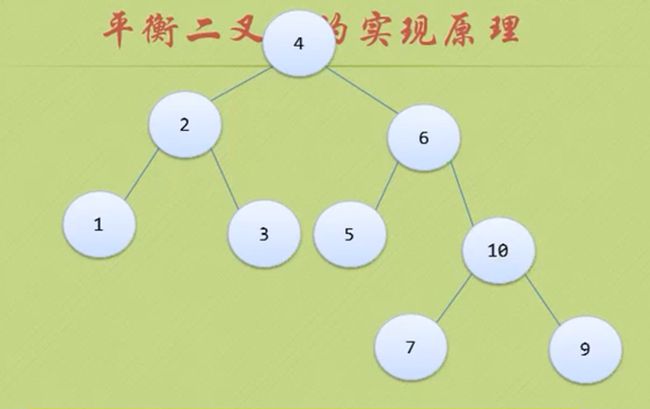
所以我们应该先处理 9与10
让节点 4 6 7 9 10 的BF都是负数

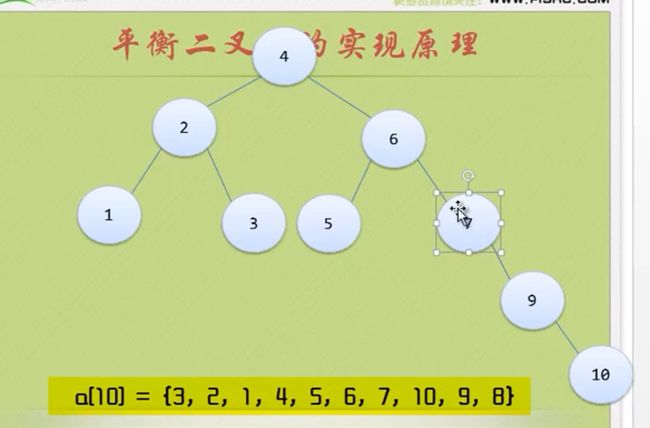
加入节点8
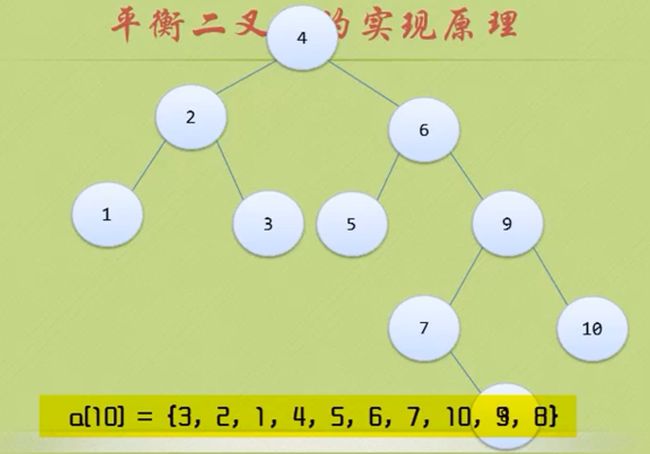
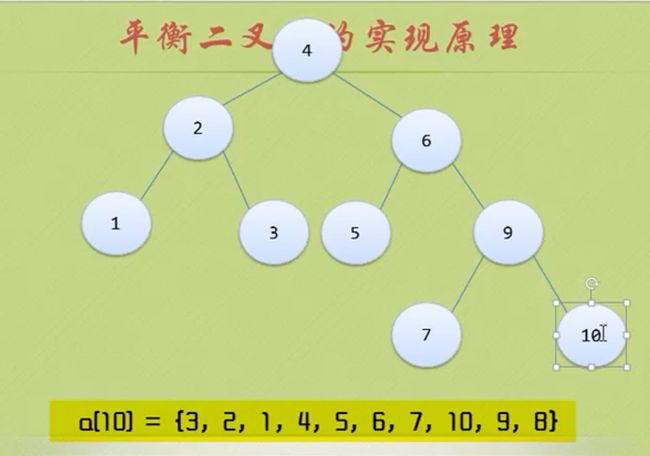
节点 4 和节点6的BF都是-2 ,节点 9的BF是1 是正数
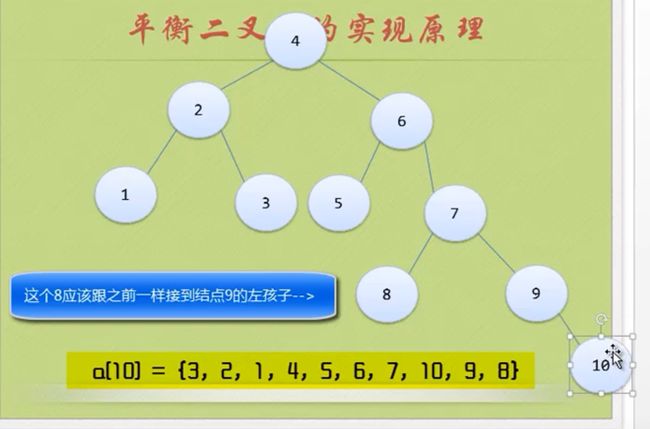
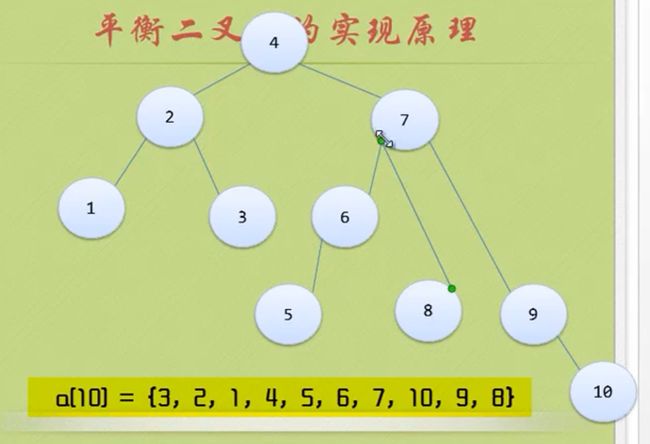
那么应该先把7 8 9 10处理一下 让 7 9 10节点的BF也为负数
实现
#include
typedef struct BiTNode
{
int data;
int bf;//平衡因子
struct BiTNode *lchild,*rchild;
}BiTNode,*BiTree;
typedef int Status;
#define TRUE 1
#define FALSE 0
#define LH 1 //左子树高了
#define EH 0 //左右子树等高
#define RH -1 //右子树高了
/**
* 右旋转
* @param p
*/
void R_Rotate(BiTree *p)
{
BiTree L;
L=(*p)->lchild;
(*p)->lchild=L->rchild;
L->rchild=(*p);
*p=L;//指向新的根节点
}
/**
* 左旋转
* @param p
*/
void L_Rotate(BiTree *p)
{
BiTree R;
R=(*p)->rchild;
(*p)->rchild=R->lchild;
R->lchild=(*p);
*p=R;//指向新的根节点
}
/**
* 左平衡
* @param T
*/
void LeftBalance(BiTree *T)
{
BiTree L,Lr;
L=(*T)->lchild;
switch (L->bf)//T的左孩子的bf
{
case LH://这一情况表示L与根节点的BF同符号 对根节点进行右旋转即可 并且旋转后恢复平衡 所以bf的值也要修改
(*T)->bf=L->bf=EH;
R_Rotate(T);
break;
case RH://这一情况表示L与根节点的BF符号相反 对L进行左旋转 之后对根节点进行右旋转
Lr=L->rchild;
//就是下面的switch想不通啊啊啊啊!!!!
switch (Lr->bf)
{
case LH://
(*T)->bf=RH;
L->bf=EH;
break;
case EH://
(*T)->bf=L->bf=EH;
break;
case RH://
(*T)->bf=EH;
L->bf=LH;
break;
}
Lr->bf=EH;
L_Rotate(&(*T)->lchild);//让符号相同
R_Rotate(T);
break;
}
}
/**
* 右平衡
* @param T
*/
void RightBalance(BiTree *T)
{
BiTree R,Rl;
R=(*T)->rchild;
switch (R->bf)//T的左孩子的bf
{
case RH://这一情况表示R与根节点的BF同符号 对根节点进行左旋转即可 并且旋转后恢复平衡 所以bf的值也要修改
(*T)->bf=R->bf=EH;
L_Rotate(T);
break;
case LH://这一情况表示R与根节点的BF符号相反 对R进行右旋转 之后对根节点进行左旋转
Rl=R->lchild;
//就是下面的switch想不通啊啊啊啊!!!!
switch (Rl->bf)
{
case RH://这个也可以画图假设一下
(*T)->bf=LH;
R->bf=EH;
break;
case EH://
(*T)->bf=R->bf=EH;
break;
case LH:// 这里自己可以画图假设一下
(*T)->bf=EH;
R->bf=RH;
break;
}
Rl->bf=EH;
R_Rotate(&(*T)->rchild);//让符号相同
L_Rotate(T);
break;
}
}
/**
*
* @param T
* @param e 插入的数据
* @param taller 这个树长高了没有长高了就不平衡啦
* @return
*/
int InsertAVL(BiTree *T,int e,int *taller)
{
if(!*T)
{
*T=(BiTree)malloc(sizeof(BiTNode));
(*T)->data=e;
(*T)->lchild=(*T)->rchild=NULL;
(*T)->bf=EH;
*taller=TRUE;
}
//对每个节点实时进行检测
else
{
if(e==(*T)->data)//已经有这个要插入的值了
{
*taller=FALSE;
}
if(e<(*T)->data)//向左走 插入左子树
{
if(!InsertAVL(&(*T)->lchild,e,taller))//递归
{
return FALSE;//如果找到相同的 就return FALSE
}
if(*taller)//长高了 咱们就要检测
{
switch ((*T)->bf)
{
case LH://原本就已经是左子树高于右子树了 那么就要处理呀
LeftBalance(T);//处理
*taller=FALSE;
break;
case EH://原本是左右子树平衡 现在要加一个左子树 那么就左子树比右子树高了
(*T)->bf=LH;
*taller=TRUE;
break;
case RH://原本右子树比左子树高 然后加一个左子树进来 这样就平衡了
(*T)->bf=EH;
*taller=FALSE;
break;
}
}
}
else//向右走 插入右子树
{
if(!InsertAVL(&(*T)->rchild,e,taller))//递归
{
return FALSE;//如果找到相同的 就return FALSE
}
if(*taller)//长高了 咱们就要检测
{
switch ((*T)->bf)
{
case LH://原本就已经是左子树高于右子树了 然后加一个右子树进来 这样就平衡了呀
(*T)->bf=EH;
*taller=FALSE;
break;
case EH://原本是左右子树平衡 现在要加一个右子树 那么就右子树比左子树高了
(*T)->bf=RH;
*taller=TRUE;
break;
case RH://原本右子树比左子树高 然后加一个右子树进来 这样就需要处理平衡了
RightBalance(T);//处理
*taller=FALSE;
break;
}
}
}
}
return TRUE;
}
int main() {
int i;
int a[10]={3,2,1,4,5,6,7,10,9,8};
BiTree T=NULL;
Status taller;
for(i=0;i<10;i++)
{
InsertAVL(&T,a[i],&taller);
}
return 0;
}
总结
右平衡函数里面对应的几种情况
/**
* 右平衡
* @param T
*/
void RightBalance(BiTree *T)
{
BiTree R,Rl;
R=(*T)->rchild;
switch (R->bf)//T的左孩子的bf
{
case RH://这一情况表示R与根节点的BF同符号 对根节点进行左旋转即可 并且旋转后恢复平衡 所以bf的值也要修改
(*T)->bf=R->bf=EH;
L_Rotate(T);
break;
case LH://这一情况表示R与根节点的BF符号相反 对R进行右旋转 之后对根节点进行左旋转
Rl=R->lchild;
//就是下面的switch想不通啊啊啊啊!!!!
switch (Rl->bf)
{
case RH://
(*T)->bf=LH;
R->bf=EH;
break;
case EH://这种情况我没找到具体的例子
(*T)->bf=R->bf=EH;
break;
case LH://总感觉哪里有问题 这里自己可以画图假设一下 我觉得是有点问题的
(*T)->bf=EH;
R->bf=RH;
break;
}
Rl->bf=EH;
R_Rotate(&(*T)->rchild);//让符号相同
L_Rotate(T);
break;
}
}
左平衡函数里面的几种情况
/**
* 左平衡
* @param T
*/
void LeftBalance(BiTree *T)
{
BiTree L,Lr;
L=(*T)->lchild;
switch (L->bf)//T的左孩子的bf
{
case LH://这一情况表示L与根节点的BF同符号 对根节点进行右旋转即可 并且旋转后恢复平衡 所以bf的值也要修改
(*T)->bf=L->bf=EH;
R_Rotate(T);
break;
case RH://这一情况表示L与根节点的BF符号相反 对L进行左旋转 之后对根节点进行右旋转
Lr=L->rchild;
//就是下面的switch想不通啊啊啊啊!!!!
switch (Lr->bf)
{
case LH://
(*T)->bf=RH;
L->bf=EH;
break;
case EH://
(*T)->bf=L->bf=EH;
break;
case RH://
(*T)->bf=EH;
L->bf=LH;
break;
}
Lr->bf=EH;
L_Rotate(&(*T)->lchild);//让符号相同
R_Rotate(T);
break;
}
}

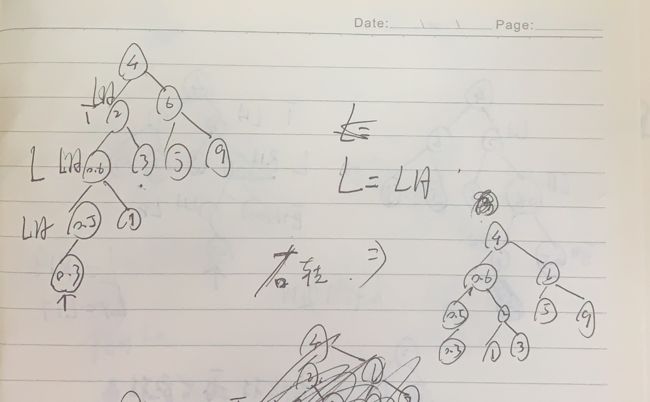
这一节内容蛮烧脑的。总算是搞懂了大概了!
多路查找树

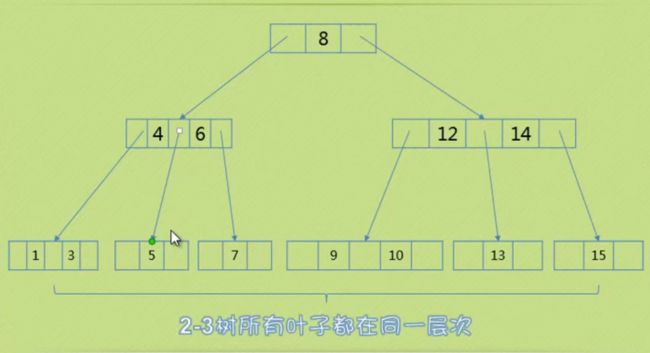
2-3树
2-3树要么有两个孩子。要么没有孩子
2-3树 二节点 三节点
插入原理
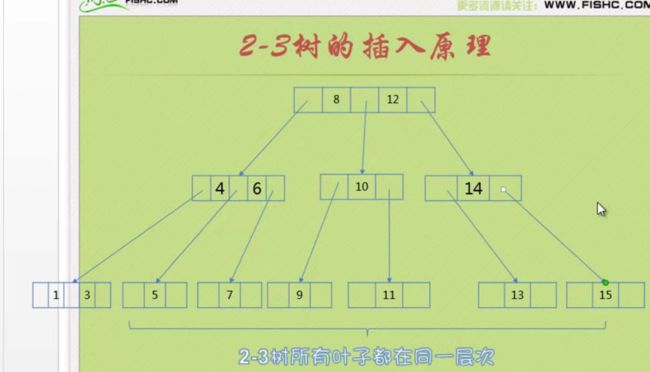
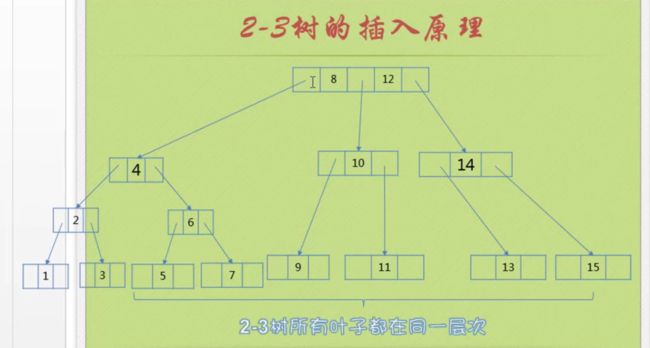
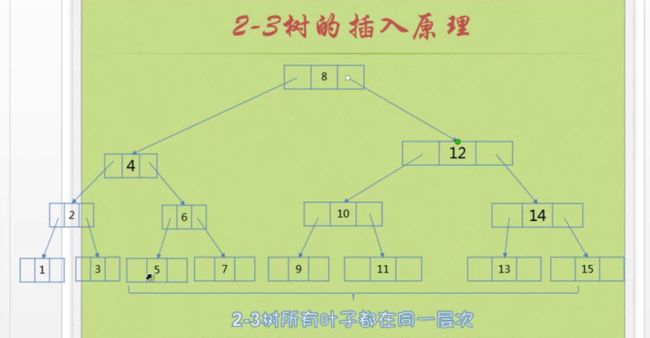
第一种情况,如果是一个空树的话,直接插入二节点,也就是根节点
第二种情况,插入到一个二节点上,二节点变成三节点
第三种情况比较复杂:
当插入的叶子是一个三节点,叶子的parent是二节点,通过扩展双亲,把新的数据插入进去
当插入的叶子是一个三节点,叶子的parent是三节点,就去找parent的parent ,看看parent的parent是不是二节点,能不能扩展
当插入的叶子是一个三节点,叶子的parent是三节点,就去找parent的parent ,追溯到根节点,根节点还是三节点的话,我们就要增加树的高度了,
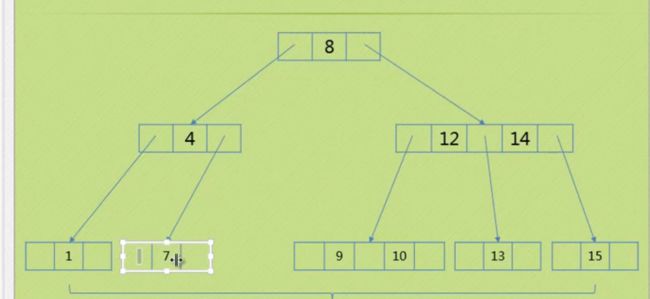
删除原理
删除叶子节点
一、如果要删除的叶子是三节点里面的元素,很简单,把三节点里面的其中一个删掉,再变成二节点就可以了
比如,下图,你要删掉6

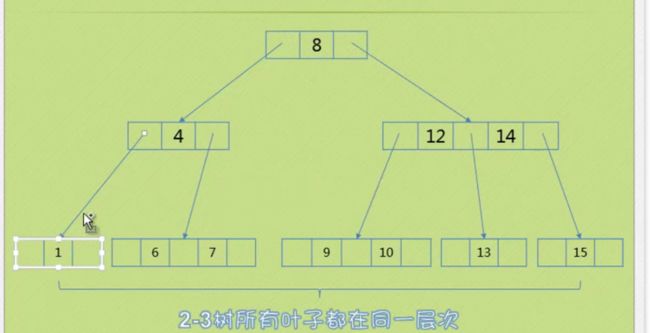
二、所删除的元素位于二节点上
1、第一种情况
这个二节点的双亲也是一个二节点,这个双亲的另一个孩子是三节点
如下图元素1
2、第二种情形
这个二节点的双亲是二节点,双亲的另一个孩子也是二节点
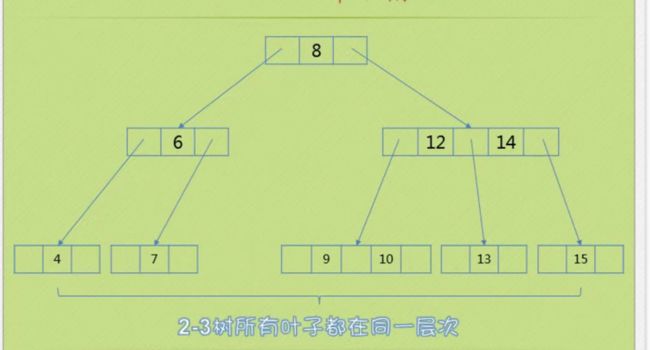
如下图 元素4

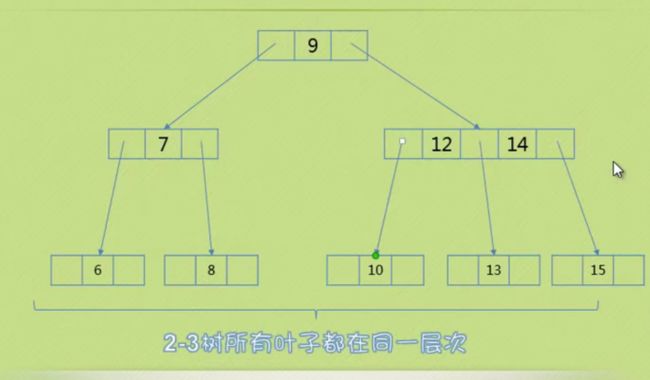
3、第三种情形
这个二节点的双亲是三节点
如下图元素10
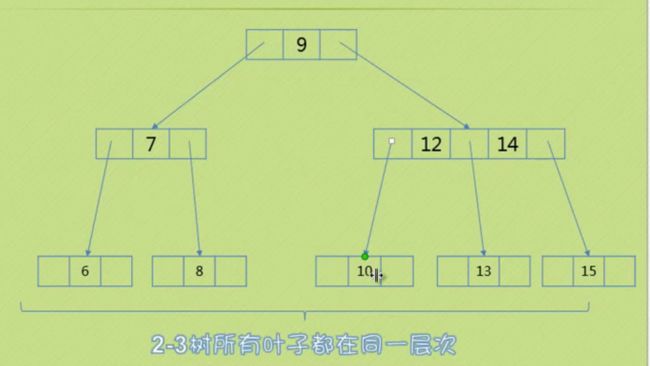
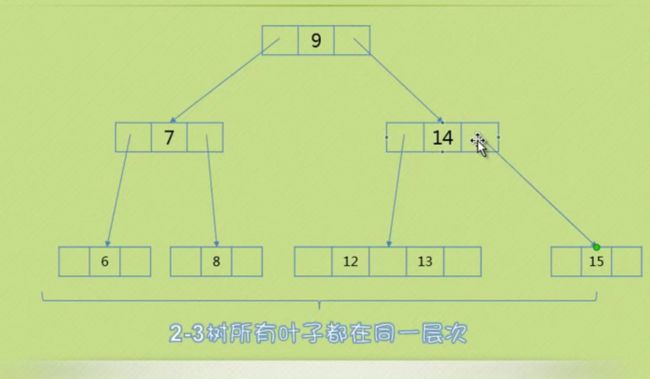
三、满二叉树的情况 所有节点都是二节点
如下图元素8

缩小一层 变三节点
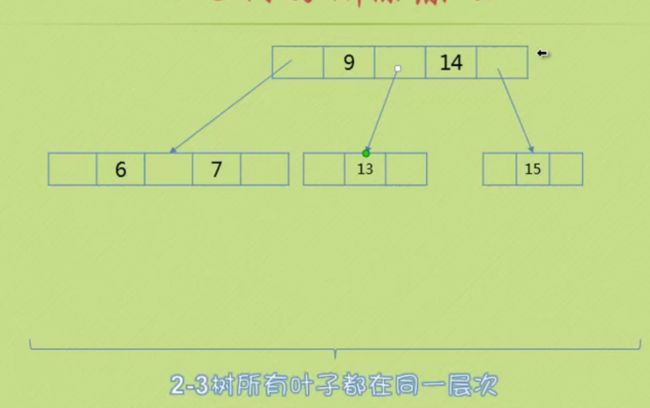
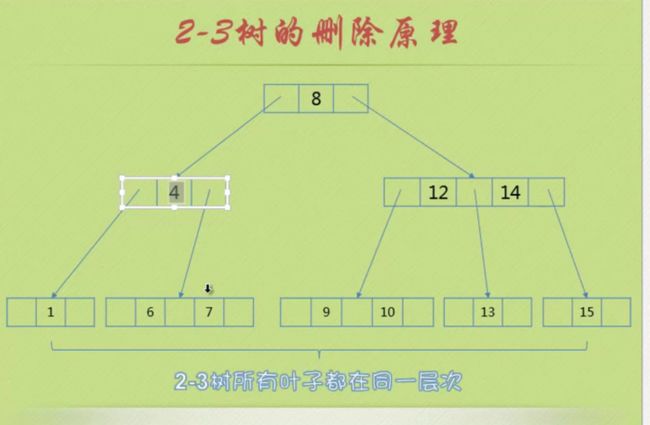
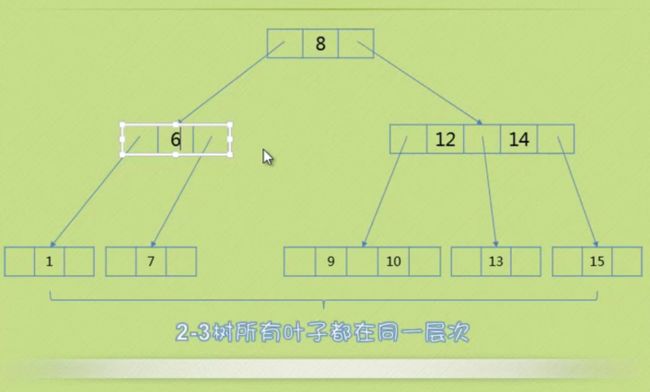
删除非叶子节点
一、删除的是二节点 。孩子有是三节点的情况
如下图 元素4
二、删除的元素在三节点 有一个三节点孩子
如下图元素12
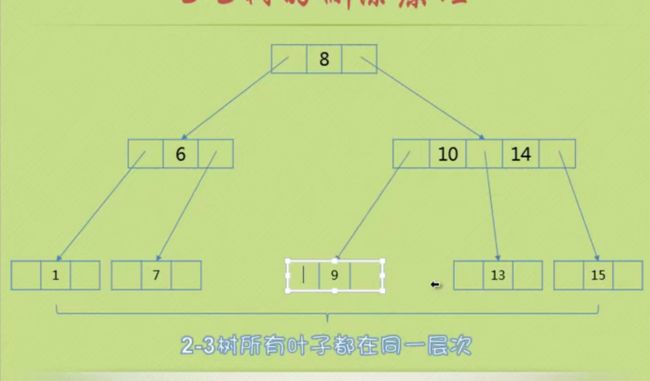
总的来说,这些删除原理比较简单,但是要考虑很多种情况
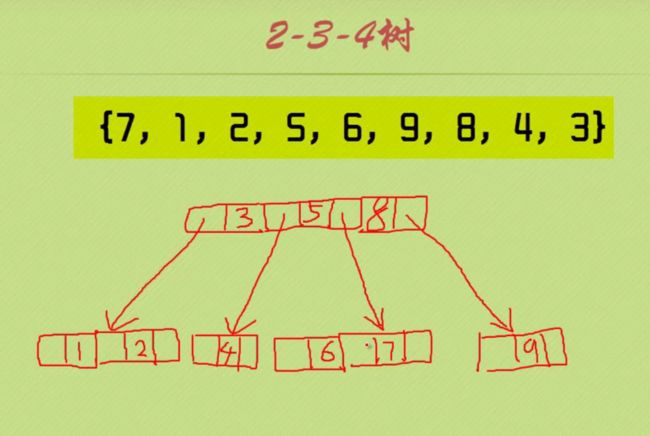
2-3-4树
要么就是二节点,要么就是三节点,要么就是四节点
插入
删除

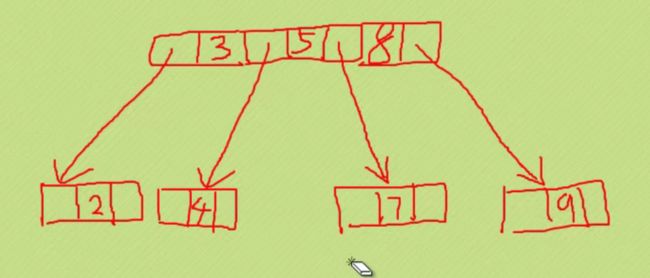
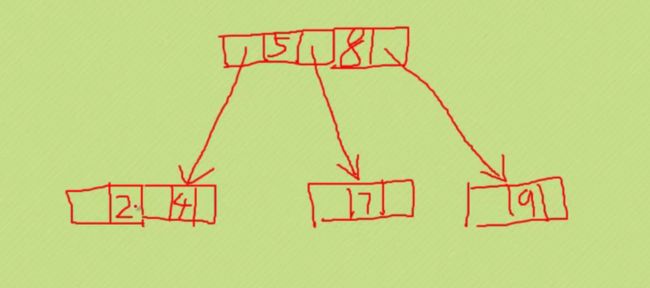
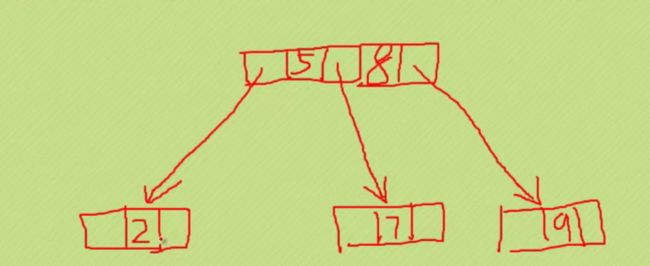
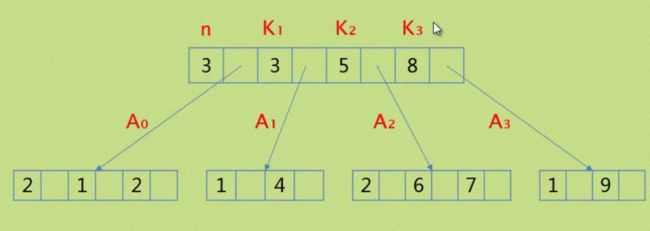
B树

性质
哈希表查找
构造方法
直接地址法

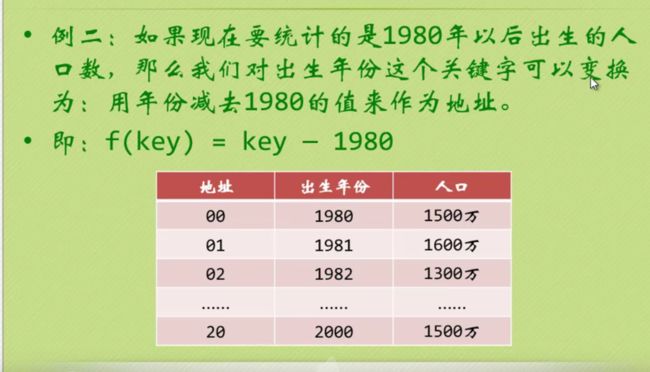

就是利用key,然后把key做线性的计算得到地址,就是直接地址法,不常用
数字分析法
适合处理数字比较大的情况
平方取中法
适合处理不知道关键字的分布,位数又不是很大的情况

折叠法
事先不知道关键字的分布,适合关键字位数比较多的情况
除留余树法
常用的方法
随机数法
适合于关键字长度不等的情况

处理哈希表冲突的方法
开放地址法
再散列函数法
多准备一些哈希函数。

链地址法
利用链表
侯捷老师讲过STL的底层实现里面,就用到过,好像是GUC4.9版本
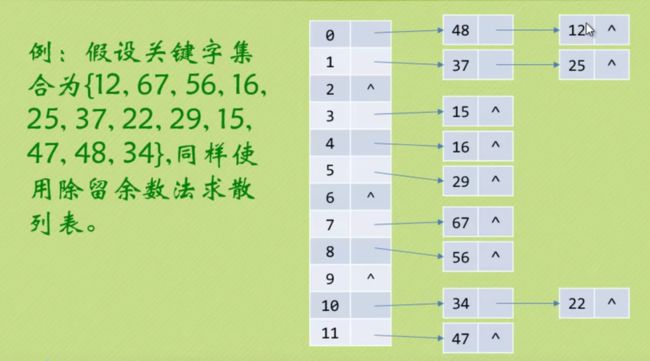
公共溢出区法
先查基本表,基本表没找到,再到溢出表找

哈希表查找代码实现
#include
using namespace std;
#define HASHSIZE 12
#define NULLKEY -32768
typedef struct
{
int *elem;//数据元素的基址,动态分配数组
int count;//当前数据元素的个数
}HashTable;
/**
* 哈希表初始化
* @param H
* @return
*/
int InitHahTable(HashTable *H)
{
H->count=HASHSIZE;
H->elem=(int *) malloc(HASHSIZE*sizeof (int));
if(!H->elem)
{
return -1;
}
for(int i=0;ielem[i]=NULLKEY;
}
return 0;
}
/**
* 除留余数法
* @param key
* @return
*/
int Hash(int key)
{
return key% HASHSIZE;
}
/**
* 插入关键字到哈希表
* @param H
* @param key
*/
void InsertHash(HashTable *H,int key)
{
int addr;
addr= Hash(key);
while(H->elem[addr]!=NULLKEY)//如果不为空,则冲突出现
{
//开放定址法
addr=(addr+1)%HASHSIZE;
}
H->elem[addr]=key;
}
/**
* 哈希表查找
* @param H
* @param key
* @param addr
* @return
*/
int SearchHash(HashTable H,int key,int *addr)
{
*addr= Hash(key);
while(H.elem[*addr]!=key)
{
*addr=(*addr+1)%HASHSIZE;
if(H.elem[*addr]==NULLKEY|| *addr == Hash(key))//查到最后一个或者回到原点 说明不存在这个key
{
return -1;
}
}
return 0;
}
/**
* 测试哈希表查找
*/
void test_HashTable()
{
HashTable H;
InitHahTable(&H);
int c;
int inputKey;
cout<<"输入插入的key: (12个)"<>inputKey;
InsertHash(&H,inputKey);
}
cout<<"请输入你要查找的数:(’#‘结束查找)"<>c;
while(c!=-32768)
{
int key=c;
cout<>c;
}
}
int main() {
test_HashTable();
return 0;
}
运行结果:
输入插入的key: (12个)
1
2
3
4
5
6
7
8
9
10
11
16
请输入你要查找的数:(’#‘结束查找)
16
16: 查找成功!
地址:0
请输入你要查找的数:(’#‘结束查找)
4
4: 查找成功!
地址:4
请输入你要查找的数:(’#‘结束查找)
12
12: 查无此数!
请输入你要查找的数:(’#‘结束查找)