YOLOV5
Yolov5的作者并没有发表论文,因此只能从代码角度进行分析。
Yolov5代码:https://github.com/ultralytics/yolov5
目录
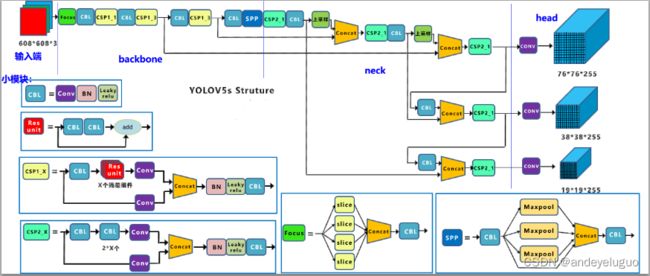
1 网络结构图
2 输入端
3 Backbone
4 Neck
5 输出端
1 网络结构图
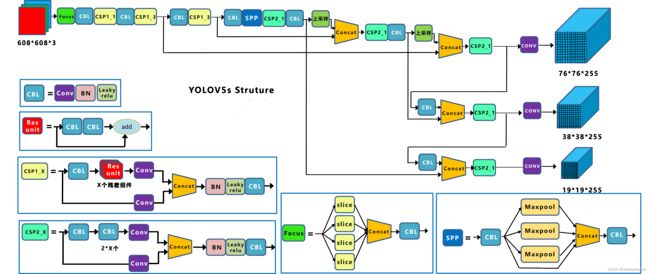
解释图,根据自己的理解更新
2 输入端
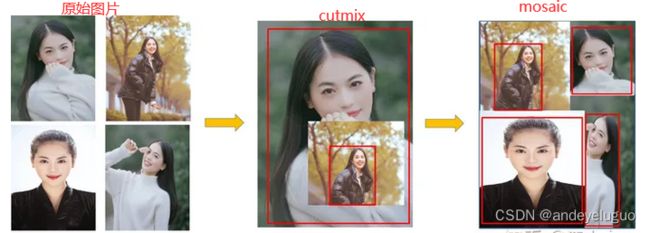
(1)Mosaic数据增强
Yolov5的输入端采用了和Yolov4一样的Mosaic数据增强的方式,随机缩放、随机裁剪、随机排布的方式进行拼接,对于小目标的检测效果还是很不错的。四张图片合成一张图片。

(2) 自适应锚框计算
在Yolo算法中,针对不同的数据集,都会有初始设定长宽的锚框。
在网络训练中,网络在初始锚框的基础上输出预测框,进而和真实框groundtruth进行比对,计算两者差距,再反向更新,迭代网络参数。
因此初始锚框也是比较重要的一部分,比如Yolov5在Coco数据集上初始设定的锚框:

在Yolov3、Yolov4中,训练不同的数据集时,计算初始锚框的值是通过单独的程序运行的。
但Yolov5中将此功能嵌入到代码中,每次训练时,自适应的计算不同训练集中的最佳锚框值。
当然,如果觉得计算的锚框效果不是很好,也可以在代码中将自动计算锚框功能关闭。
![]()
控制的代码即train.py中上面一行代码,设置成False,每次训练时,不会自动计算。
(3)自适应图片缩放
在常用的目标检测算法中,不同的图片长宽都不相同,因此常用的方式是将原始图片统一缩放到一个标准尺寸,再送入检测网络中。
比如Yolo算法中常用416*416,608*608等尺寸,比如对下面800*600的图像进行缩放。

但Yolov5代码中对此进行了改进,也是Yolov5推理速度能够很快的一个不错的trick。
作者认为,在项目实际使用时,很多图片的长宽比不同,因此缩放填充后,两端的黑边大小都不同,而如果填充的比较多,则存在信息冗余,影响推理速度。
因此在Yolov5的代码中datasets.py的letterbox函数中进行了修改,对原始图像自适应的添加最少的黑边。

图像高度上两端的黑边变少了,在推理时,计算量也会减少,即目标检测速度会得到提升。
这种方式在之前github上Yolov3中也进行了讨论:https://github.com/ultralytics/yolov3/issues/232
在讨论中,通过这种简单的改进,推理速度得到了37%的提升,可以说效果很明显。
但是有的同学可能会有大大的问号??如何进行计算的呢?
第一步:计算缩放比例

原始缩放尺寸是416*416,都除以原始图像的尺寸后,可以得到0.52,和0.69两个缩放系数,选择小的缩放系数。
第二步:计算缩放后的尺寸

原始图片的长宽都乘以最小的缩放系数0.52,宽变成了416,而高变成了312。
第三步:计算黑边填充数值

将416-312=104,得到原本需要填充的高度。再采用numpy中np.mod取余数的方式,得到8个像素,再除以2,即得到图片高度两端需要填充的数值。
此外,需要注意的是:
a.这里填充的是黑色,即(0,0,0),而Yolov5中填充的是灰色,即(114,114,114),都是一样的效果。
b.训练时没有采用缩减黑边的方式,还是采用传统填充的方式,即缩放到416*416大小。只是在测试,使用模型推理时,才采用缩减黑边的方式,提高目标检测,推理的速度。
c.为什么np.mod函数的后面用32?因为Yolov5的网络经过5次下采样,而2的5次方,等于32。所以至少要去掉32的倍数,再进行取余。
3 Backbone
(1)Focus结构
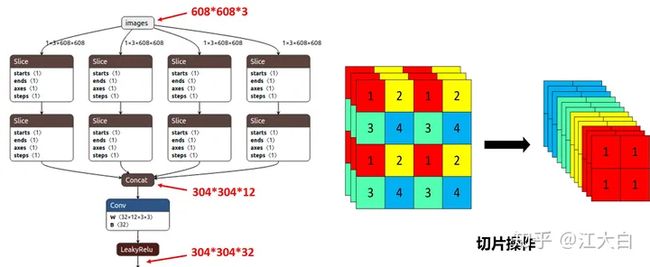
Focus结构,在Yolov3&Yolov4中并没有这个结构,其中比较关键是切片操作。
比如右图的切片示意图,4*4*3的图像切片后变成2*2*12的特征图。
以Yolov5s的结构为例,原始608*608*3的图像输入Focus结构,采用切片操作,先变成304*304*12的特征图,再经过一次32个卷积核的卷积操作,最终变成304*304*32的特征图。
需要注意的是:Yolov5s的Focus结构最后使用了32个卷积核,而其他三种结构,使用的数量有所增加,先注意下,后面会讲解到四种结构的不同点。
(2)CSP结构
Yolov4网络结构中,借鉴了CSPNet的设计思路,在主干网络中设计了CSP结构。
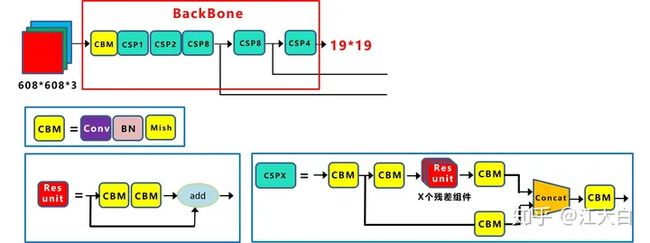
Yolov5与Yolov4不同点在于,Yolov4中只有主干网络使用了CSP结构。
而Yolov5中设计了两种CSP结构,以Yolov5s网络为例,CSP1_X结构应用于Backbone主干网络,另一种CSP2_X结构则应用于Neck中。

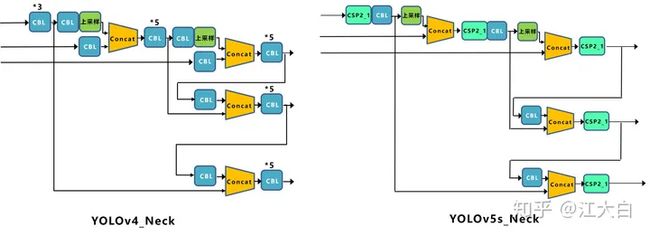
4 Neck
Yolov5现在的Neck和Yolov4中一样,都采用FPN+PAN的结构,但在Yolov5刚出来时,只使用了FPN结构,后面才增加了PAN结构,此外网络中其他部分也进行了调整。
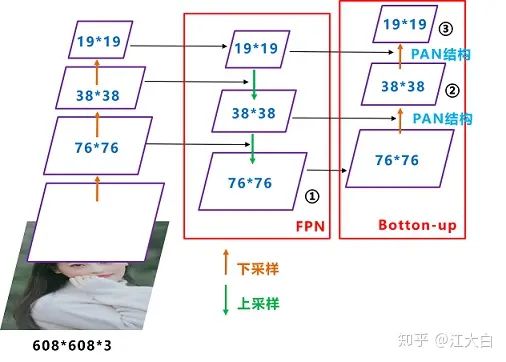
但如上面CSPNet结构中讲到,Yolov5和Yolov4的不同点在于,
Yolov4的Neck结构中,采用的都是普通的卷积操作。而Yolov5的Neck结构中,采用借鉴CSPnet设计的CSP2结构,加强网络特征融合的能力。
5 输出端
(1)Bounding box损失函数
Yolov5中采用其中的CIOU_Loss做Bounding box的损失函数。

Yolov4中也采用CIOU_Loss作为目标Bounding box的损失。

(2)nms非极大值抑制
在目标检测的后处理过程中,针对很多目标框的筛选,通常需要nms操作。
因为CIOU_Loss中包含影响因子v,涉及groudtruth的信息,而测试推理时,是没有groundtruth的。
所以Yolov4在DIOU_Loss的基础上采用DIOU_nms的方式,而Yolov5中采用加权nms的方式。
可以看出,采用DIOU_nms,下方中间箭头的黄色部分,原本被遮挡的摩托车也可以检出。

大白在项目中,也采用了DIOU_nms的方式,在同样的参数情况下,将nms中IOU修改成DIOU_nms。对于一些遮挡重叠的目标,确实会有一些改进。
比如下面黄色箭头部分,原本两个人重叠的部分,在参数和普通的IOU_nms一致的情况下,修改成DIOU_nms,可以将两个目标检出。
虽然大多数状态下效果差不多,但在不增加计算成本的情况下,有稍微的改进也是好的。
