RLHF与LLM训练的碰撞:寻找最佳实践之路!
了解更多公众号:芝士AI吃鱼
在讨论大型语言模型(LLM)时,无论是在研究新闻还是教程中,经常提到一个称为“带有人类反馈的强化学习”(RLHF)的过程。由于RLHF能够将人类偏好纳入优化过程,从而提高模型的有用性和安全性,它已成为现代LLM训练流程的一个重要部分。在本文中,将逐步分解RLHF,以提供对其核心理念和重要性的理解参考。
典型的LLM训练流程
现代基于transformer的LLM,如ChatGPT或Llama 2,经历了三个步骤的训练程序:
- 预训练
- 有监督微调
- 对齐
最初,在预训练阶段,模型从庞大的无标签文本数据集中吸收知识。随后的有监督微调使这些模型更好地遵循特定指令。最后,对齐阶段使LLM更有帮助和安全地响应用户提示。
请注意,这个训练流程基于OpenAI的InstructGPT论文,该论文详细描述了GPT-3的过程。这个过程被广泛认为是ChatGPT背后的方法。稍后,我们还将比较这种方法与Meta AI最新的Llama 2模型。
让我们从下面描述的初始步骤,预训练开始。

预训练通常在包含数十亿至数万亿个标记的庞大文本语料库上进行。在这个过程中,我们采用了一个简单的下一个词预测任务,其中模型从提供的文本中预测下一个单词(或标记)。
值得强调的一点是,这种类型的预训练允许我们利用大型的、未标记的数据集。只要我们可以在不侵犯版权或忽视创作者偏好的情况下使用数据,我们就可以访问大型数据集,而无需手动标记。实际上,在这个预训练步骤中,“标签”是文本中的后续单词,它已经是数据集本身的一部分(因此,这种预训练方法通常被称为自监督学习)。
接下来是有监督微调,如下图所示。

有监督微调阶段涉及另一轮下一个标记预测。然而,与前面的预训练阶段不同,我们现在使用指令-输出对,如上图所示。在这种情况下,指令是给模型的输入(有时还附加一个可选的输入文本,取决于任务)。输出代表我们期望模型产生的类似响应。
为了提供一个具体的例子,让我们考虑以下指令-输出对:
- 指令:“写一首关于鹈鹕的打油诗。”
- 输出:“有一个鹈鹕非常好...”
模型将指令文本(“写一首关于鹈鹕的打油诗”)作为输入,并对输出文本(“有一个鹈鹕非常好...”)进行下一个标记预测。
虽然两者都采用类似的下一个标记训练目标,但有监督微调通常使用的数据集比预训练小得多。这是因为它需要指令-输出对,而不仅仅是原始文本。为了编译这样的数据集,需要一个人(或另一个高质量的LLM)根据特定指令编写期望的输出——创建这样的数据集需要大量工作。
在这个有监督微调阶段之后,还有另一个通常被认为是“对齐”步骤的微调阶段,其主要目标是使LLM与人类偏好对齐。这就是RLHF发挥作用的地方。

在接下来的部分中,我们将深入了解基于RLHF的对齐步骤。然而,对于那些好奇它与第2步中预训练的基础模型和经过监督微调的模型的比较情况的人,我引用了InstructGPT论文中的一个图表(上图)。
上图比较了经过监督微调的175B GPT-3模型(淡点线)与其他方法。我们可以在图表底部看到基础GPT-3模型。
如果我们考虑一种提示方法,其中我们多次查询并每次选择最佳响应(“GPT-3 + 提示”),我们可以看到与基础模型(“GPT-3”)相比有所改善的表现,这是可以预期的。
将监督微调添加到GPT-3基础模型中,使性能(“GPT-3 + 监督微调”)比“GPT-3 + 提示”更好。然而,最佳性能可以从经过监督微调和RLHF的GPT-3模型中获得(“GPT-3 + 监督微调 + RLHF”)——图表顶部的两条图。 (请注意,图表顶部有两条线,因为研究人员尝试了两种不同的采样程序。)下一节将更详细地描述这个RLHF步骤。
带有人类反馈的强化学习(RLHF)
前一节讨论了像ChatGPT和Llama-2-chat这样的现代LLM背后的3步训练程序。在这一节中,我们将更详细地看看微调阶段,重点是RLHF部分。
RLHF流程采用一个预训练模型,并以监督方式微调它(前一节的第2步),然后进一步通过近似策略优化(前一节的第3步)与之对齐。
为简单起见,我们将RLHF流程分为三个单独的步骤:
- RLHF第1步:对预训练模型进行监督微调
- RLHF第2步:创建奖励模型
- RLHF第3步:通过近似策略优化进行微调
RLHF第1步,如下图所示,是一个监督微调步骤,用于创建进一步RLHF微调的基础模型。
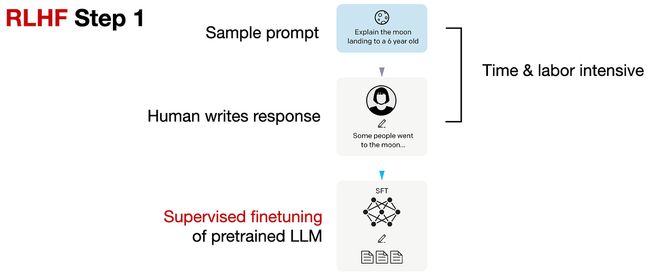
在RLHF第1步中,我们创建或从数据库中抽取提示,并请人类编写高质量的响应。然后,我们使用这个数据集以监督方式微调预训练的基础模型。
请注意,这个RLHF第1步与上一节“典型的LLM训练流程”中的第2步类似。我在这里再次列出它,因为它是RLHF不可或缺的一部分。
在RLHF第2步中,我们使用监督微调后的模型来创建一个奖励模型,如下图所示。

如上图所示,对于每个提示,我们从先前步骤创建的微调LLM生成四到九个响应。然后,个人根据他们的偏好对这些响应进行排序。尽管这个排序过程耗时,但可能比为监督微调创建数据集的工作量稍低。这是因为对响应进行排名可能比编写它们更简单。
在编制了这些排名的数据集之后,我们可以设计一个奖励模型,用于RLHF第3步中的后续优化阶段输出奖励分数。这个奖励模型通常来源于先前监督微调步骤中创建的LLM。我们将奖励模型称为RM,将监督微调步骤中的LLM称为SFT。要将RLHF第1步中的模型转换为奖励模型,其输出层(下一个标记分类层)被替换为一个回归层,该层具有单个输出节点。
RLHF流程的第三步是使用奖励(RM)模型来微调先前监督微调(SFT)模型,如下图所示。
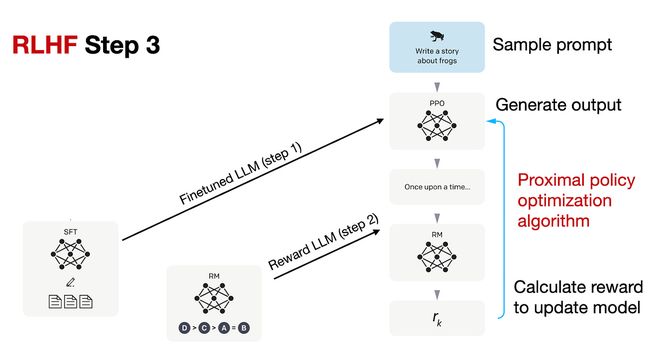
在RLHF第3步的最后阶段,我们现在正在使用近似策略优化(PPO)基于我们在RLHF第2步中创建的奖励模型的奖励分数更新SFT模型。
Llama 2中的RLHF
在上一节中,我们了解了OpenAI的InstructGPT论文中描述的RLHF程序。这种方法通常被引用为开发ChatGPT所采用的方法。但是,它与Meta AI最近的Llama 2模型相比如何呢?
Meta AI在创建Llama-2-chat模型时也使用了RLHF。然而,两种方法之间存在一些区别,我在下面的注释图中进行了突出显示。
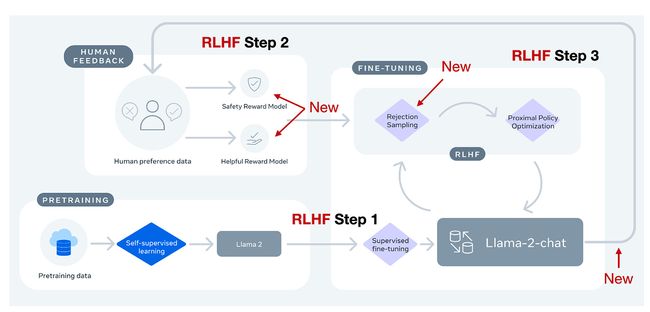
总的来说,Llama-2-chat在RLHF第1步中遵循与InstructGPT相同的指令数据上的监督微调步骤。然而,在RLHF第2步中,创建了两个奖励模型而不是一个。此外,Llama-2-chat模型通过多个阶段发展,奖励模型根据Llama-2-chat模型中出现的错误进行更新。还增加了一个拒绝采样步骤。
边际损失(Margin Loss)
上述注释图中未描述的另一个区别涉及如何对模型响应进行排名以生成奖励模型。在先前讨论的标准InstructGPT方法中,研究人员收集排名为4-9的输出响应,从中创建“k选2”比较。
例如,如果一个人类标注者对四个响应(A-D)进行排名,如A < C < D < B,这将产生“4选2”= 6个比较:
- A < C
- A < D
- A < B
- C < D
- C < B
- D < B
类似地,Llama 2的数据集基于响应的二元比较,如A < B。然而,看起来每个人类标注者在每轮标注中只被呈现2个响应(而不是4-9个响应)。
此外,新颖之处在于,每个二元排名旁边收集了一个“边际”标签(从“显著更好”到“微不足道更好”),可以选择性地用于二元排名损失中,通过附加的边际参数来计算两个响应之间的差距。
尽管InstructGPT使用了以下基于交叉熵的排名损失来训练奖励模型:
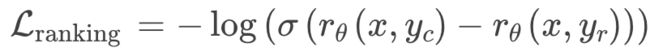
Llama 2 添加了边际“m(r)”作为偏好评级的离散函数,如下所示:
![]()
其中:
- r_θ(x,y) 是针对提示 x 和生成的响应 y 的标量分数输出;
- θ 是模型权重;
- σ 是将层输出转换为0到1范围内的分数的逻辑S型函数;
- y_c 是人类注释者选择的首选响应;
- y_r 是人类注释者选择的被拒绝的响应。
例如,通过“m(r)”返回更高的边际会使首选响应和被拒绝响应的奖励之间的差异变小,从而导致更大的损失,进而在策略梯度更新期间产生更大的梯度,最终导致模型变化。
两个奖励模型
如前所述,Llama 2中有两个奖励模型而不是一个。一个奖励模型基于帮助性,另一个基于安全性。然后用于模型优化的最终奖励函数是这两个分数的线性组合。

拒绝采样(Rejection sampling)
此外,Llama 2的作者采用了一个迭代产生多个RLHF模型(从RLHF-V1到RLHF-V5)的训练流程。他们不仅依赖于我们之前讨论的带PPO的RLHF方法,而且还采用了两种算法进行RLHF微调:PPO和拒绝采样。
在拒绝采样中,绘制出K个输出,并在优化步骤中选择奖励最高的一个进行梯度更新,如下图所示。

拒绝采样用于在每次迭代中选择具有高奖励分数的样本。因此,与基于每次仅更新一个样本的PPO相比,模型经历了具有更高奖励的样本的微调。
在监督微调的初始阶段之后,模型仅使用拒绝采样进行训练,然后将拒绝采样和PPO结合起来。
研究人员绘制了模型在RLHF阶段的性能,表明RLHF微调的模型在无害性和有用性轴上都有所改善。
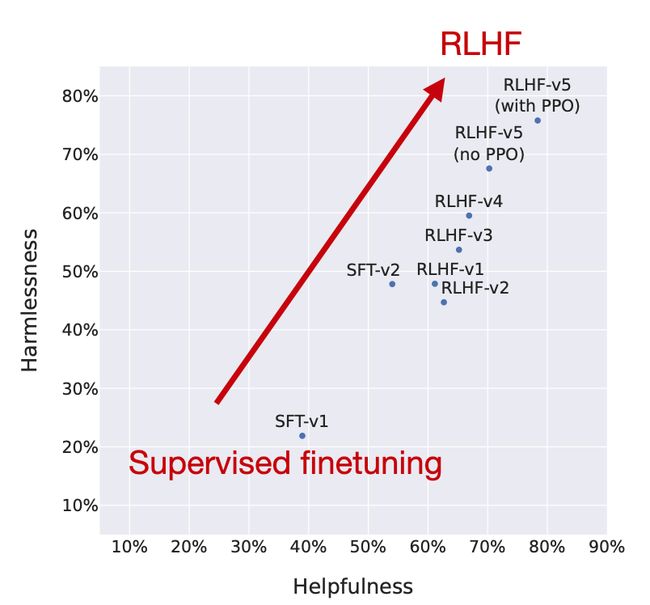
值得注意的是,研究人员在最后阶段使用了PPO,接着之前仅通过拒绝采样更新的模型。如上图所示的“RLHF-v5(带PPO)”与“RLHF-v5(无PPO)”比较表明,最后阶段使用PPO训练的模型比仅使用拒绝采样训练的模型更好。
RLHF的替代方案
现在我们已经讨论并定义了RLHF过程,这是一个相当复杂的程序,人们可能会想知道它是否值得这样的麻烦。之前从InstructGPT和Llama 2论文中展示的图表(如下所示)提供了证据,表明RLHF是值得的。

然而,许多正在进行的研究侧重于开发更高效的替代方案。下面总结了最有趣的方法。
- Constitutional AI: Harmlessness from AI Feedback (Dec 2022, https://arxiv.org/abs/2212.08073)
在这篇论文中,研究人员提出了一种基于人类提供的规则列表的自我训练机制。类似于之前提到的InstructGPT论文,提出的方法使用强化学习方法。
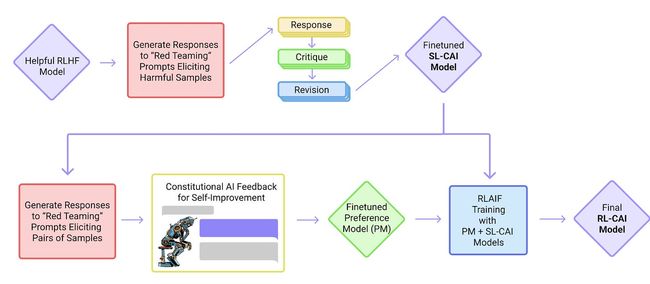
上图中研究人员使用的“红队行动”这一术语,起源于冷战时期的军事演习。在那时,“红队行动”指的是扮演苏联角色的一组人员,他们的任务是测试和挑战美国的战略及防御体系。如今,在人工智能研究的网络安全领域,这一术语被用来描述一种特殊的过程:通过模拟现实世界攻击者的战术、技术和程序,外部或内部专家扮演潜在对手的角色,挑战和测试相关系统,以此来提升这些系统的性能和安全性。
- The Wisdom of Hindsight Makes Language Models Better Instruction Followers (Feb 2023, https://arxiv.org/abs/2302.05206)
这篇论文表明,对LLM进行有监督的微调确实可以很好地工作。研究人员提出了一种基于重新标记的有监督方法进行微调,该方法在12个BigBench任务上胜过了RLHF。
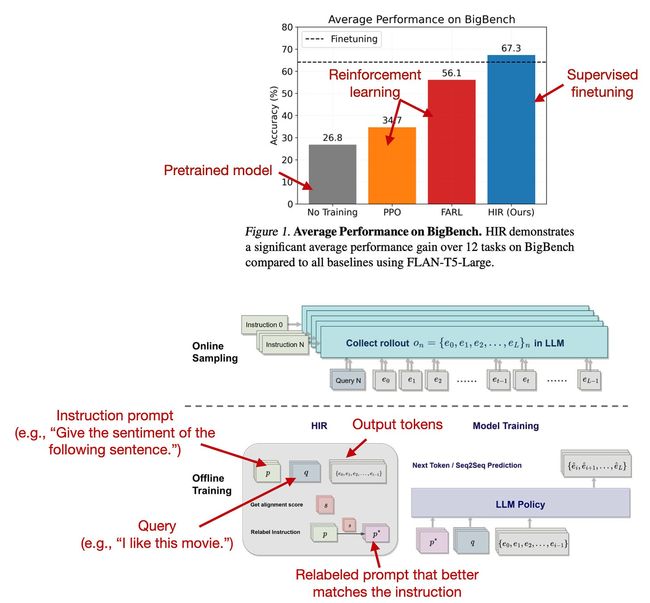
那么,这个所提出的后见之明指令标记(HIR)是如何工作的呢?简而言之,HIR方法包括两个步骤:采样和训练。在采样步骤中,指令和提示被输入到LLM中以收集响应。在训练阶段,根据一种对齐分数,将指令在适当的情况下进行重新标记。然后,使用这些重新标记的指令和原始提示来对LLM进行微调。通过这种重新标记的方法,研究人员有效地将失败案例(即LLM产生的输出与原始指令不符的情况)转化为有监督学习的有用训练数据。
请注意,这项研究与InstructGPT中的RLHF(基于强化学习的微调)工作并不直接可比,原因在于它似乎使用了启发式方法(“然而,由于大多数基于人类反馈的数据难以收集,我们采用了一种脚本化的反馈函数...”)。尽管如此,后见之明指令标记(HIR)方法的结果仍然非常引人注目。
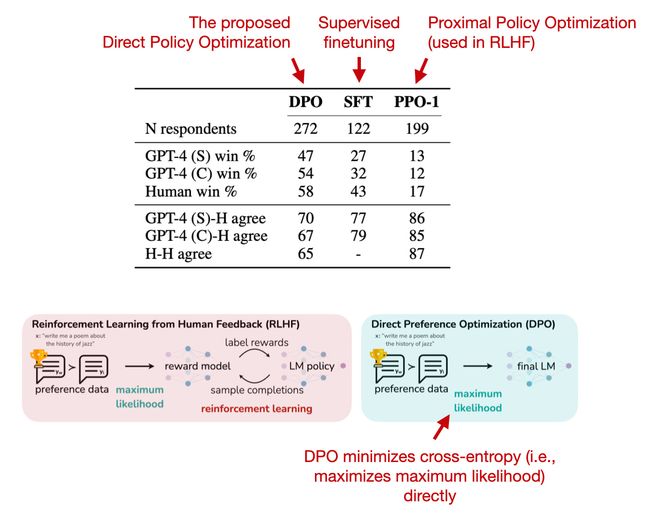
- Direct Preference Optimization: Your Language Model is Secretly a Reward Model (https://arxiv.org/abs/2305.18290, May 2023)
直接偏好优化(DPO)是RLHF和PPO的一个替代方案,研究人员表明,用于拟合RLHF中的奖励模型的交叉熵损失可以直接用于微调LLM。根据他们的基准测试,使用DPO通常比使用RLHF/PPO更高效,并且在响应质量方面也常常更受欢迎。
- Contrastive Preference Learning: Learning from Human Feedback without RL (Oct 2023, https://arxiv.org/abs/2310.13639)
类似于直接偏好优化(DPO),对比性偏好学习(CPL)是简化RLHF的一种方法,通过消除奖励模型学习。与DPO一样,CPL使用一种有监督的学习目标,特别是对比性损失。(在论文的附录中,作者表明DPO是CPL的一个特例。)尽管实验是基于机器人环境进行的,CPL也可以应用于LLM微调。
- Reinforced Self-Training (ReST) for Language Modeling (Aug 2023, https://arxiv.org/abs/2308.08998)
ReST是一种与人类反馈的强化学习(RLHF)相对的方法,用于使LLM与人类偏好对齐。ReST采用抽样方法创建改进的数据集,通过迭代训练更高质量的子集来细化其奖励函数。根据作者的说法,ReST通过离线生成其训练数据集,比标准在线RLHF方法(如带近似策略优化的RLHF,PPO)实现了更高的效率,但尚缺乏与InstructGPT或Llama 2中使用的标准RLHF PPO方法的全面比较。
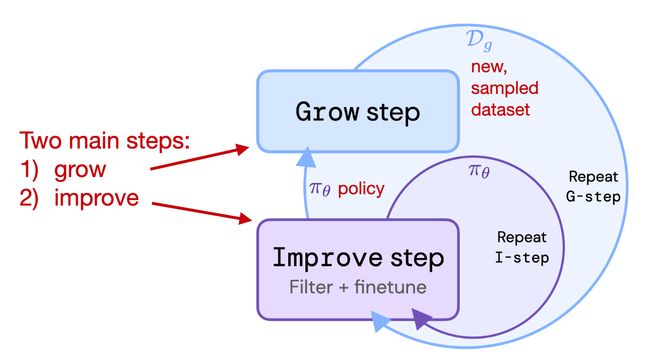
- RLAIF: Scaling Reinforcement Learning from Human Feedback with AI Feedback (Sep 2023, https://arxiv.org/abs/2309.00267)
最近的一项名为人工智能反馈强化学习(RLAIF)的研究表明,在强化学习中基于人类反馈的奖励模型训练(RLHF)并不一定需要由人类提供评分,而可以由大型语言模型(例如:PaLM 2)生成。人类评估者在RLAIF模型与传统RLHF模型之间的选择几乎各占一半,这意味着他们实际上并不偏好其中任何一个模型。
另一个有趣的附加观点是,无论是RLHF还是RLAIF,它们的性能都远远超过了那些仅通过有监督指令微调训练的模型。
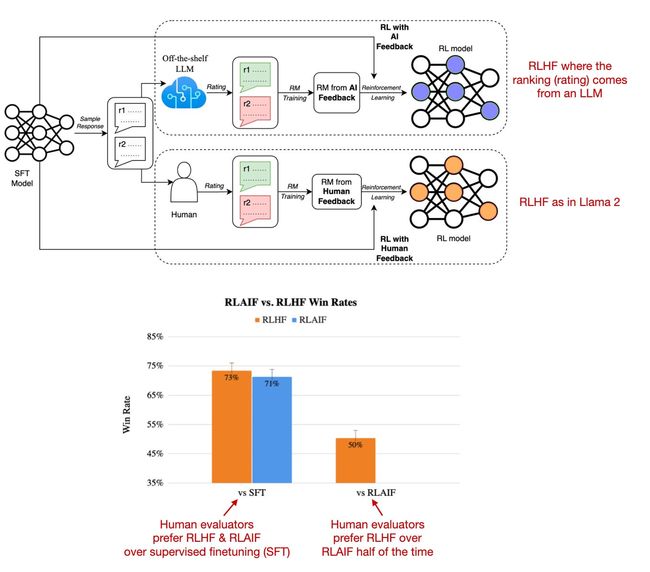
这项研究的结果非常有用且引人注目,因为它基本上意味着我们可能能够使基于RLHF的训练更加高效和易于获取。然而,这些RLAIF模型在关注安全性和信息内容真实性的定性研究中的表现如何,仍有待观察,这些是仅通过人类偏好研究部分能够捕捉到的。
结论
这些替代方案是否在实践中值得采用,目前还有待观察,因为目前还没有真正能与Llama 2和未经RLHF训练的Code Llama规模模型相匹敌的竞争者。