“双十一、二” 业务高峰如何扛住?韵达快递选择 TDengine
小 T 导读:
为了有效处理每日亿级的数据量,早在 2021 年,韵达就选择用 TDengine 替代了 MySQL,并在三台服务器上成功部署和上线了 TDengine 2.0 集群。如今,随着 TDengine 3.0 版本的逐渐成熟,韵达决定将现有的 2.0 版本升级到 3.0 版本,并基于本文为大家分享其在升级过程中所进行的优化措施以及升级后的性能表现。
作为一家头部物流公司,韵达每日的订单扫描量破亿级别,该类数据为典型的时序数据,这也是我们公司数据量最大的一块业务。系统需要汇总统计全国网点的扫描数据(韵达的所有订单数据),并实时反馈给用户。此外,这些数据也会给到网点、分拨中心的内部员工使用,用于个人工作量、站点扫描量等统计工作。在“双十一、二”期间,面对快递业务量的暴涨,TDengine 帮助我们很好地完成了既定规划,保障了“双十一、二”任务的顺利完成。
本文用于分享我司在 TDengine 上使用的历程和心得。
从 2.0 到 3.0
在早些年业务尚未扩张时,我们采用的是 MySQL 分区+索引方式进行扫描枪数据的处理,但随着企业的发展、业务量的增加,面对每日亿级的数据量,MySQL 显然已经无法满足当下的数据处理需求。
在这种背景下,我们决定进行时序数据库(Time Series Database)选型。经过严格的选项测试,我们最终选择了 TDengine 作为核心数据库处理该部分数据。在 2021 年,我们在三台 16C 64G 的服务器上部署上线了 TDengine 2.0 版本集群。(“一个扫描枪一张表”,韵达选择 TDengine 应对每日亿级数据量 - TDengine | 涛思数据)
该集群每天要承载日常 6 亿行数据的写入和一定量的查询,“双十一、二”等特殊业务期间,写入/查询量还要上涨 50% 左右,数据需要保留 2 个月。
我们的架构是 Spring Boot + MyBatis + MySQL + TDengine,TDengine 负责处理时序数据,MySQL 则负责非时序数据的存储及应用,如下:
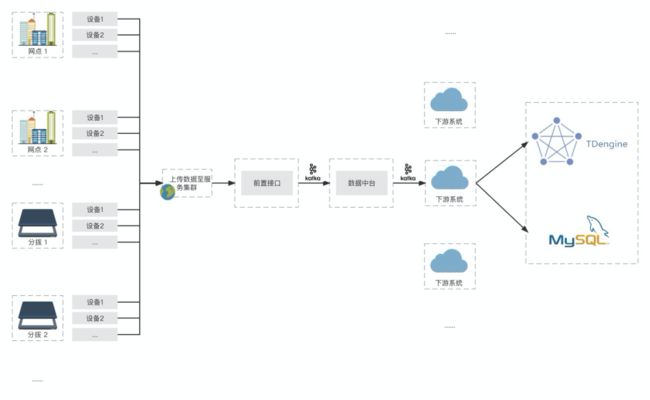
使用 2.0 的这两年数据库是很稳定的,但考虑到后期业务需求会用到 3.0 的新特性,所以我们自打 TDengine 3.0 发布之后,就一直在着手准备数据库的迁移工作。
数据迁移经验分享
数据库迁移是一项很重大的工作,在此期间,我们仔细梳理了 2.0 版本使用期间的一些使用情况,尝试做出针对性的优化。
在 2.0 时期,我们是根据“一个扫描枪一张表”的模型建表,把设备的地点和站点类型设置为标签。来到 3.0 时期后,我们和官方团队反复调试,选择了“一个站点一张表”的建模方式。这样一来,表数量从百万级直接缩减到了万级。
做这个改动的核心原因有两个:
- 我们有很多临时的虚拟扫描枪,由于只是临时使用,所以没有几条数据,但却单独占据了一个表。
- 虽然扫描枪写入频率较低,但是整个站点有很多扫描枪,这样的建模方式使得低频写入转化为了高频写入,降低了存储中碎片数据的比例。
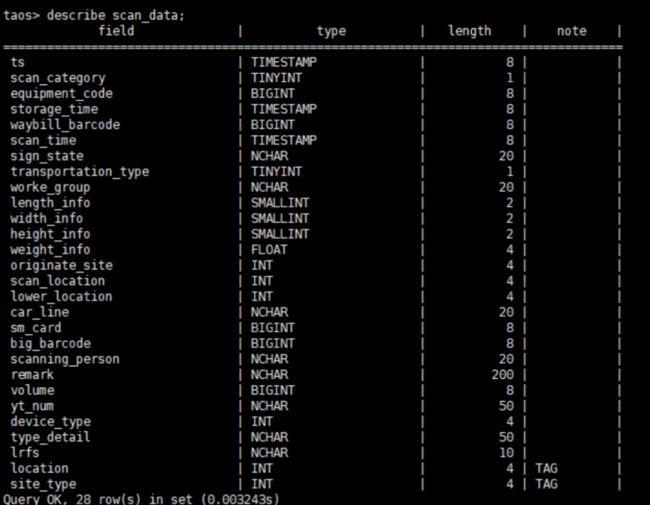
2.x 超级表结构:

优化过后,3.x 超级表的结构:
除此之外,3.0 由于底层有很多的重构,因此和 2.0 相比出现了很多的参数改动,可以参考:配置参数 | TDengine 文档 | 涛思数据,数据库 | TDengine 文档 | 涛思数据。优化思路可以参考这篇文章中的内容:万字解读|怎样激活 TDengine 最高性价比? - TDengine | 涛思数据。
尤其是 3.0 关于数据入库频率、数据乱序、更新、建表等处理逻辑的变化,均需要投入一定量的学习测试时间。尤其是在数据量极大的情况下,每一次测试环境的搭建都需要较大的时间人力成本。我们在 TDengine 官方团队的协助下,断断续续大概用了 2 个月的时间才完成这个阶段。
优化效果显著
最终优化过后,我们的查询速度得到了进一步提升。尤其是下面这类查询优化效果十分明显,该查询的逻辑是:从 6 亿行的当天数据中,通过标签、普通列做出多次筛选,最终返回分页后的十条结果。其中,最为耗时的便是从标签过滤之后的 1.5 亿条数据的普通列筛选。
在 2.6 版本中,这个过程需要大约 10 秒的时间,升级到 3.x 之后,只需要 2-3 秒左右便会返回结果:
select waybill_barcode,location,scanning_person,equipment_code,scan_category,remark,weight_info weight,scan_time,volume,lower_location,lrfs from base.scan_data WHERE ts >= #{beginTime} and ts <= #{endTime} and site_type=#{siteType} and equipment_code = #{equipmentCode} limit 0,10;
至此,我们从 TDengine 2.0 迁移到 3.0 版本的工作就圆满完成了。
写在最后
对于我们这种集快递、物流、电子商务配送和仓储服务为一体的快递企业,扫描枪设备产生的数据是相当庞大的,而 TDengine 可以轻松高效地处理和存储这些时序数据,它所具备的快速写入和查询的能力,使得我们的系统可以轻松应对高负载和大规模数据的需求。
落实到业务使用方面,通过实时了解包裹状态、配送进度等信息,我们能够更加方便地做出实时决策,物流运营的效率和效果也获得了大幅提高。
文章最后,祝 TDengine 越来越好,早日成为时序数据库领域的 NO.1。
了解更多 TDengine Database的具体细节,可在GitHub上查看相关源代码。