C2-3.3.2 机器学习/深度学习——数据增强
C2-3.3.2 数据增强
参考链接
1、为什么要使用数据增强?
-
※总结最经典的一句话:希望模型学习的更稳健
-
当数据量不足时候: 人工智能三要素之一为数据,但获取大量数据成本高,但数据又是提高模型精度和泛化效果的重要因素。 当数据量不足时,模型很容易过拟合,精度也无法继续提升,因此数据增强技术应运而生
-
通过执行数据增强,你可以阻止神经网络学习不相关的特征,从根本上提升整体性能。——见后面4、应用场景 举例
2、什么是数据增强?
数据增强(Data Augmentation):是一种通过利用算法来扩展训练数据的技术。利用算法,※让有限的数据产生更多的等价数据(通过 镜像,旋转,位移,等比例放缩等)来人工扩展训练数据集的技术,自动增强训练数据。
3、如果没有很多数据,我怎么去获得更多数据?
- 即:要对现有的数据集进行微小的改变。比如旋转(flips)、移位(translations)、旋转(rotations)等微小的改变。
你不必寻找新奇的图片增加到你的数据集中。为什么?因为,**神经网络在开始的时候并不是那么聪明。**比如,一个欠训练的神经网络会认为这三个如下的网球是不同、独特的图片。

所以,为了获得更多的数据,我们只要对现有的数据集进行微小的改变。比如旋转(flips)、移位(translations)、旋转(rotations)等微小的改变。我们的网络会认为这是不同的图片。
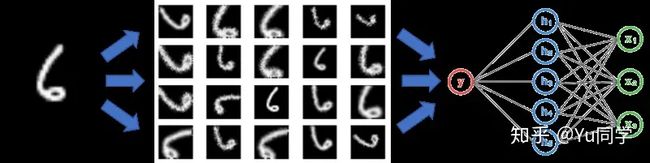
4、应用场景
【自己的总结】:我们的数据是有限的,但是我喂给模型数据之后,我想让模型自己会辨认物体。 比如我有 50张照片,是 猫 和 狗 的照片。**不光是我喂给模型那些数据情况下,还有不同角度,不同大小,不同位移,比例等等情况下,希望他都会辨认。。。**这就是 数据增强实现的效果。
一个卷积神经网络,如果能够对物体即使它放在不同的地方也能稳健的分类,就被称为具有不变性的属性。更具体的,CNN可以对移位(translation)、视角(viewpoint)、大小(size)、照明(illumination)(或者以上的组合)具有不变性。
这本质上是数据增强的前提。在现实场景中,我们可能会有一批在有限场景中拍摄的数据集。但是我们的目标应用可能存在于不同的条件,比如在不同的方向、位置、缩放比例、亮度等。我们通过额外合成的数据来训练神经网络来解释这些情况。
示例如下:

在我们的假想数据集中分为两类。左侧为品牌A(Ford),有车为品牌B(Chevrolet)。
假设我们有一个数据集,含两种品牌的车,如上所示。我们假设A品牌的车都如上面左侧一样对其(所有的车头朝向左侧)。同样B如右侧(所有的都朝向右侧)。现在,你将你的数据集送入“最先进的”神经网络,你希望等训练结束后获得令人印象深刻的结果。

Ford车(A品牌)却朝向右侧
当训练结束后,**你送入上面的品牌A车的图片。 但是你的神经网络却认为它是一辆B品牌的车!**你很困惑。难道不是刚刚通过这个“最先进的”神经网络获得了95%的准确率吗?我不是夸张,这个事情以往发生过
我们如何去阻止这件事发生呢? 我们不得不减少数据集中不相关的特征。对于上面的轿车模型分类器,一个简单的方案是增加分别朝向原始方向反向的两种车的图片。更好的方法是,你可以从沿着水平方向翻转图片以便它们都朝着反方向!现在,在新数据集上训练神经网络,你将会获得你想要获得的性能。
通过执行数据增强,你可以阻止神经网络学习不相关的特征,从根本上提升整体性能。
5、流行的数据增强技术
数据增强的两类方法:
在我们的机器学习管道(pipeline)的何处进行增强数据呢?
一种是事先执行所有转换,实质上会增强你的数据集的大小。
另一种选项是在送入机器学习之前,在小批量(mini-batch)上执行这些转换。
第一个选项叫做线下增强(offline augmentation)。这种方法适用于较小的数据集(smaller dataset)。你最终会增加一定的倍数的数据集,这个倍数等于你转换的个数。比如我要翻转我的所有图片,我的数据集相当于乘以2。
第二种方法叫做线上增强(online augmentation)或在飞行中增强(augmentation on the fly)。这种方法更适用于较大的数据集(larger datasets),因为你无法承受爆炸性增加的规模。另外,你会在喂入模型之前进行小批量的转换 。一些机器学习框架支持在线增强,可以再gpu上加速。
5.1 翻转(Flip)
可以对图片进行水平和垂直翻转。一些框架不提供垂直翻转功能。但是,一个垂直反转的图片等同于图片的180度旋转,然后再执行水平翻转。下面是我们的图片翻转的例子。

你可以使用你喜欢的工具包进行下面的任意命令进行翻转,数据增强因子=2或4
# NumPy.'img' = A single image.
flip_1 = np.fliplr(img)
# TensorFlow. 'x' = A placeholder for an image.
shape = [height, width, channels]
x = tf.placeholder(dtype = tf.float32, shape = shape)
flip_2 = tf.image.flip_up_down(x)
flip_3 = tf.image.flip_left_right(x)
flip_4 = tf.image.random_flip_up_down(x)
flip_5 = tf.image.random_flip_left_right(x)
从左侧开始,原始图片,水平翻转的图片,垂直翻转的图片。
4.2 旋转(Rotation)
一个关键性的问题是当旋转之后图像的维数可能并不能保持跟原来一样。如果你的图片是正方形的,那么以直角旋转将会保持图像大小。如果它是长方形,那么180度的旋转将会保持原来的大小。以更精细的角度旋转图像也会改变最终的图像尺寸。我们将在下一节中看到我们如何处理这个问题。以下是以直角旋转的方形图像的示例。

当我们从左向右移动时,图像相对于前一个图像顺时针旋转90度。
你可以使用你喜欢的工具包执行以下的旋转命令。数据增强因子= 2或4。
# Placeholders: 'x' = A single image, 'y' = A batch of images
# 'k' denotes the number of 90 degree anticlockwise rotations
shape = [height, width, channels]
x = tf.placeholder(dtype = tf.float32, shape = shape)
rot_90 = tf.image.rot90(img, k=1)
rot_180 = tf.image.rot90(img, k=2)
# To rotate in any angle. In the example below, 'angles' is in radians
shape = [batch, height, width, 3]
y = tf.placeholder(dtype = tf.float32, shape = shape)
rot_tf_180 = tf.contrib.image.rotate(y, angles=3.1415)
# Scikit-Image. 'angle' = Degrees. 'img' = Input Image
# For details about 'mode', checkout the interpolation section below.
rot = skimage.transform.rotate(img, angle=45, mode='reflect')
4.3 缩放比例(Scale)
图像可以向外或向内缩放。向外缩放时,最终图像尺寸将大于原始图像尺寸。大多数图像框架从新图像中剪切出一个部分,其大小等于原始图像。我们将在下一节中处理向内缩放,因为它会缩小图像大小,迫使我们对超出边界的内容做出假设。以下是缩放的示例或图像。

从左到右,原始图像,向外缩放10%,向外缩放20%
4.4 裁剪(Crop)
与缩放不同,我们只是从原始图像中随机抽样一个部分。然后,我们将此部分的大小调整为原始图像大小。这种方法通常称为随机裁剪。以下是随机裁剪的示例。仔细观察,你会发现此方法与缩放之间的区别。

从左至右,原始图像,左上角裁剪的图像,右下角裁剪的图像。裁剪的部分被缩放为原始图像大小。
你可以使用以下任何TensorFlow命令执行随机裁剪。数据增强因子=任意。
# TensorFlow. 'x' = A placeholder for an image.
original_size = [height, width, channels]
x = tf.placeholder(dtype = tf.float32, shape = original_size)
# Use the following commands to perform random crops
crop_size = [new_height, new_width, channels]
seed = np.random.randint(1234)
x = tf.random_crop(x, size = crop_size, seed = seed)
output = tf.images.resize_images(x, size = original_size)
4.5 移位(Translation)
移位只涉及沿X或Y方向(或两者)移动图像。在下面的示例中,我们假设图像在其边界之外具有黑色背景,并且被适当地移位。这种增强方法非常有用,因为大多数对象几乎可以位于图像的任何位置。这迫使你的卷积神经网络看到所有角落。
从左至右,原始图像,向右移位,向上移位
你可以使用以下命令在TensorFlow中执行转换。数据增强因子=任意。
# pad_left, pad_right, pad_top, pad_bottom denote the pixel
# displacement. Set one of them to the desired value and rest to 0
shape = [batch, height, width, channels]
x = tf.placeholder(dtype = tf.float32, shape = shape)
# We use two functions to get our desired augmentation
x = tf.image.pad_to_bounding_box(x, pad_top, pad_left, height + pad_bottom + pad_top, width + pad_right + pad_left)
output = tf.image.crop_to_bounding_box(x, pad_bottom, pad_right, height, width)
4.6 高斯噪声(Gaussian Noise)
当您的神经网络试图学习可能无用的高频特征(大量出现的模式)时,通常会发生过度拟合。具有零均值的高斯噪声基本上在所有频率中具有数据点,从而有效地扭曲高频特征。这也意味着较低频率的组件(通常是您的预期数据)也会失真,但你的神经网络可以学会超越它。添加适量的噪音可以增强学习能力。
一个色调较低的版本是盐和胡椒噪音,它表现为随机的黑白像素在图像中传播。这类似于通过向图像添加高斯噪声而产生的效果,但可能具有较低的信息失真水平。