【freespace】HybridNets: End-to-End Perception Network

目录
摘要
1. 介绍
1.1. 背景
1.2. 相关工作
2. 方法
2.1. 网络体系结构
2.2. 编码器
2.3. 译码器
2.4. 损失函数和训练
3. 实验与评估
3.1. 实验设置
3.2. 评价指标
3.3. 成本计算性能
3.4. 多任务性能
4. 结论与展望
摘要
端到端网络在多任务处理中变得越来越重要。一个突出的例子是驾驶感知系统在自动驾驶中的重要性越来越大。本文系统地研究了面向多任务的端到端感知网络,并提出了几个关键优化以提高准确性。首先,本文提出了基于加权双向特征网络的高效分割头和框/类预测网络。其次,本文提出了加权双向特征网络中每个层次的自动定制锚点。第三,本文提出了一种高效的训练损失函数和训练策略来平衡和优化网络。基于这些优化,我们开发了一个端到端感知网络,可以同时执行多任务,包括交通目标检测、可驾驶区域分割和车道检测,称为HybridNets,其准确性优于现有技术。特别是,HybridNets在Berkeley DeepDrive数据集上的平均精度达到77.3,优于车道检测,平均交叉口超过Union 31.6,参数1283万个,浮点运算156亿次。此外,它可以实时执行视觉感知任务,因此是多任务问题的实用而准确的解决方案。代码可从https://github.com/datvuthanh/HybridNets获得。
关键词:端到端网络,多任务学习,检测,分割,自动驾驶
1. 介绍
1.1. 背景
嵌入式系统的计算能力和神经网络的性能的最新进展,使自动驾驶成为计算机视觉中的一个活跃领域。理想情况下,要创造一辆能够自动驾驶的汽车,就是给它提供其周围环境中可用的每一点信息。然而,与传统思维不同的是,激光雷达和雷达并不需要为智能车辆创建一个准确的感知场。不时有研究表明,这类车辆只需借助a的辅助,就能做出相对较好的驾驶决策单摄像头安装在前方。普遍的共识是,引导智能车辆最关键的三个任务是:交通目标检测、可驾驶区域分割、车道线分割。
这些任务中的每一个都有其最先进的网络,包括但不限于用于目标检测的 SSD[14]、YOLO [21];UNet [23], SegNet [1], ERNet[10] 用 于 语 义 分 割 ;LaneNet[29]和SCNN[19]用于车道线检测。尽管如此,通过三个不同的网络传递图像会造成不合理的延迟。许多研究人员(多项网络[28],DLT-Net [20],YOLOP[30])已经考虑将网络组合成一个简单的编码器-解码器架构,其中主干
和颈部为三个不同的头部生成上下文进行处理。通过正确选择特征提取器,并将车道线与可驾驶区域融合到一个分割头中,该架构可以进一步改进。本实验在具有挑战性的BDD100K数据集上实现了最高的召回率92.8%和分割IoU70.8%,优于现有的多任务网络[31],定性如图1所示。
在effentdet[26]中出色的多尺度特征融合BiFPN,以及在ImageNet上预训练的effentnet[27]主干上进行了改进,并在准确性和计算开销之间进行了平衡。构造了一个BiFPN解码器,利用现有的多尺度特征到新设计的分割头中。对于640x384的输入分辨率,整个网络在12.83M参数下达到15.6 BFLOPS,与最新的多任务网络YOLOP在7.9M参数下达到18.6 BFLOPS相当。采用了多阶段
学习策略来帮助多个损失函数[5]的收敛。
为了进一步微调,我们还在本研究中对[22]中的锚框生成进行了修补。由于锚盒在理论上不能很好地推广到每个数据集,但对一级检测器的性能有重大影响,因此我们根据经验为驾驶数据集BDD100K选择了最佳的宽高比和尺度,其中的对象从大型前卡车到小型汽车都有变化。
综上所述,这项研究的主要贡献是:
1. 端到端感知网络HybridNets在BDD100K数据集上实现了出色的实时效果。
2. 在任何数据集上,为加权双向特征网络中的每个水平自动定制锚点。
3.高效的训练损失函数和训练策略,以平衡和优化多任务网络。

1.2. 相关工作
本节将回顾每个任务中一些最好的网络,然后以最新的多任务网络进行总结,以强调这种统一架构的力量。
目前在提高检测器性能方面的发展几乎将该领域分裂为两个不同的分支:基于区域的检测器和单阶段检测器。虽然基于区域的方法更精确,但单阶段检测器由于其在嵌入式中的效率而获得了更多的吸引力硬件限制有限的系统。当FPN出现时,它最初通过提供自上而下的路径来从语义丰富的层[11]构建更高分辨率层来支持RPNs。然后BiFPN正式展示了双向特征融合对单阶段检测器的性能提升。他们现在只需一遍就可以接收多个尺度的特征图,缓解了yolo等的明显弱点。
语义分割也通过深度学习取代了老式的分割算法,取得了令人瞩目的进展。FCN[25]点燃了第一个全卷积分割网络的火焰。从此,研究者们找到了各种提升性能的方法,比如使用UNet[23]的编码器-解码器架构,PSPNet[32]的金字塔池化模块,甚至是基于生成对抗网络[6]的半监督学习。
SSN[18]在后处理阶段加入了条件随机场单元,以提高分割性能。许多数据增强技术一直被测试,以增强道路检测网络[17]的学习泛化能力。在分割道路场景[9]中,图像分析仍在探索中。
传统的车道线检测算法一直被广泛使用,直到最近,一个值得注意的算法是Hough变换[33]。然后,LaneNet[29]提出将车道线作为实例进行分割。Spatial CNN[19]更喜欢逐层卷积而不是深层逐层卷积,强调具有较重空间关系但几乎没有明显外观的对象,如电线杆、交通灯或车道线。ENet-SAD[8]创建了self attention distillation,这是一种允许模型进行自学习的技术。它的工作原理是使用早期训练点生成的注意力图作为后期监督的一种形式,大大超过SCNN。
许多发表的论文试图将感知任务组合成一个统一的网络。Mask R-CNN[7]继承了Faster R-CNN的RPN,同时为对象Mask增加了第三个输出分支,实现了对象检测和实例分割的并行化。BlitzNet[4]还表明,目标检测和语义分割可以相互受益。LSNet[13]带有一个名为cross-IoU的新颖损失函数,可以将姿态估计添加到输出中。MultiNet提出了编码器-解码器结构,允许DLT-Net进行特殊设计解码器头之间的共享张量,用于互信息流。不久之后,YOLOP在车辆检测、
可驾驶区域和车道线分割三个感知任务上成为BDD100K数据集上的第一个实时最先进的算法。然而,这两个相似的分割头为明显的优化任务留下了空间,即将它们缩减为一个性能更好的单一优化任务。由于硬件约束对任何实时决策网络的应用也至关重要,因此必须考虑模型缩放。
2. 方法
2.1. 网络体系结构
基于这些挑战,本研究提出了一种可以多任务的端到端网络架构,命名为HybridNets。如图2所示,我们的单阶段网络包括一个共享的编码器和两个分离的解码器,以解决不同的任务。每个特征图级别的分辨率PIrepresents一个分辨率为1/2的特征级别Iof输入图像。例如,如果输入分辨率为640x384,P2代表特征级别2(640/2 2,384 /22)=(160,96),而P7代表分辨率为(5,3)的特征级
别7。
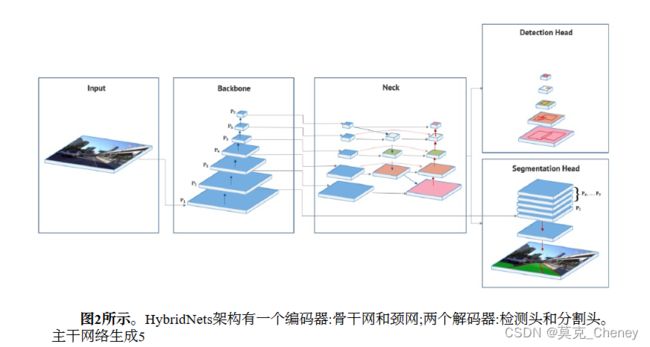

2.2. 编码器
作为骨干的特征提取是模型的重要组成部分,可以帮助各种网络在各种任务中实现出色的性能。许多现代网络架构目前都重用在ImageNet数据集中具有良好准确性的网络来提取特征。最近,EfficientNet表现出了比现有cnn更高的精度和高效的性能,将FLOPs降低了几个数量级。我们选择EfficientNet-B3作为主干,它通过基于神经架构搜索寻找深度、宽度和分辨率参数来解决网络优化问题,设计出稳定的网络。因此,我们的骨干网可以减少网络的计算成本,并获得几个至关重要的特征。
来自主干网络的特征图被馈送到颈部网络管道。多尺度特征表示是主要挑战;FPN最近提出了一种特征提取器设计,用于生成多尺度特征图以获得更好的信息。然而,FPN的局限性在于信息特征是由单向流继承的。因此,我们的颈部网络使用了基于EfficientDet的BiFPN模块。BiFPN通过每个双向(自顶向下和自底向上)路径对每个节点进行基于跨尺度连接的不同分辨率的特征融合,并为每个特征增加权重,以了解每个级别的重要性。我们在工作中采用了融合特征的方法。
2.3. 译码器
来自颈部网络的多尺度融合特征图的每个网格将被分配9个具有不同纵横比的先验锚点。与YOLOv4[2]类似,本文使用kmeans聚类[16]来确定锚点框。此外,我们为每个网格单元选择了9个簇和3个不同的尺度。为了不同的特征图层次,本文使用尺度常数来创建从小到大覆盖所有区域的边界框先验。因此,这个提出的网络可以很好地工作在复杂的数据集上。检测头将预测边界框和的
偏移量每个类别的概率以及预测框的置信度。这被描述为:
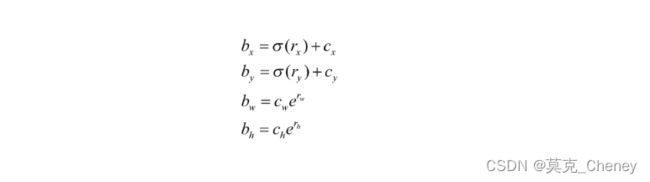
每个边界框的中心、宽度和高度分别来自哪里网络预测。每个锚框都有中心、宽度和高度。
分割头有3类输出,分别是背景、可行驶区域和车道线。本文保留了5个特征级别{P3,…,P7}从颈部网络到分割分支。首先,本文对每个级别进行向上采样,以具有相同大小的输出特征图(W
4,H4、64)。第二,将P2 level馈送到卷积层,使其具有与其他level相同的特征图通道。然后,我们将它们组合起来,通过对所有级别求和来获得更好的特征融合。最后,我们将输出特征还原为大小(W,H,3),表示每个所属像素类的概率。本研究将特征图缩放到P2级别的大小,因为P2级别是一个强语义的特征图。此外,我们将代表低级特征的主干网络的P2特征图输入到最终的特征融合中,这有助于网络提高输出精度,如图3所示。

2.4. 损失函数和训练
本文使用多任务损失来训练端到端网络。等式2通过两部分相加来表示总损失函数。

其中,是调整参数平衡总损失,是对象的损失吗检测任务和是分割任务的损失,公式可以写成如下




3. 实验与评估
3.1. 实验设置
伯克利DeepDrive数据集(BDD100K)用于训练和验证模型。由于20K图像的测试标签不可用,我们选择在10K图像的验证集上进行评估。三个任务的数据集是根据在BDD100K上训练的现有多任务网络准备的,以帮助比较。在目标检测的所有10个类别中,只有{car, truck, bus, train}被选择并合并为一个单一类别{vehicle},因为DLT-Net和MultiNet只能检测车辆。两个分割类{direct, alternative}也合并为{drivable}。我们遵循将两个车道线注释计算为一个中心注释的做法,将训练集中的注释膨胀到8像素,同时保持验证集完整的[8]。图像的大小从1280x720调整到640x384,根据重要性的顺序有三个主要原因:尊重原始的长宽比,在性能和精度之间保持良好的权衡,并确保
BiFPN的尺寸可以被128整除。使用了旋转、缩放、平移、水平翻转和HSV平移等基本的增强技术。马赛克增强首先在YOLOv4中引入,效果很好[2],在专门训练检测头时使用。
我们通过使用ImageNet上预训练的EfficientNet-B3权重来启动模型。的自定义锚框设置自动发现的比例和比例。选择的优化器是AdamW [15] with。当模型停留了3个时期,学习率降低了10倍。对于目标检测,模型使用平滑的L1损失with用于回归和focal loss with用于分类。当将锚框匹配到注释,模型对面积大于100像素的注释使用0.5的IoU阈值,但对较小的注释只使用0.25。我们强调回归比分类多4倍,因为单类分类容易收敛。对于可驾驶区域和车道分割,该模型使用了Tversky loss与and的组合焦点损失。我们在RTX 3090上训练200的批处理大小为16时代的发展。
3.2. 评价指标
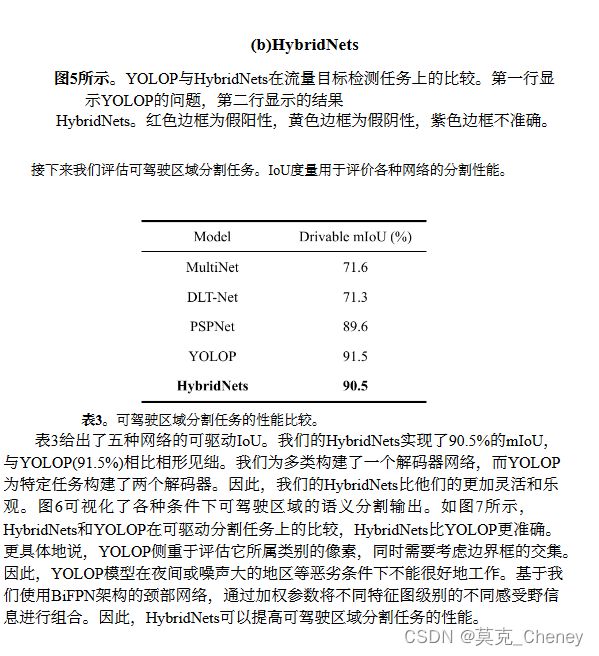
在流量目标检测任务上,采用mAP50算法。mAP50是通过在单个借据阈值0.5下为所有类计算的平均精密度的平均值来计算的。平均精密度是精密度-召回率曲线下的面积。本文只评估了一个类别,关注所提出的方法能在多大程度上找到所有正例。本文设置最低置信度,所有边界框由mAP50计算。在语义分割任务中,采用借据度量来评估可行驶区域和车道线分割。更具体地说,本文将mIoU表示为每个类别的借据平均值和单个类别的借据度量。
3.3. 成本计算性能
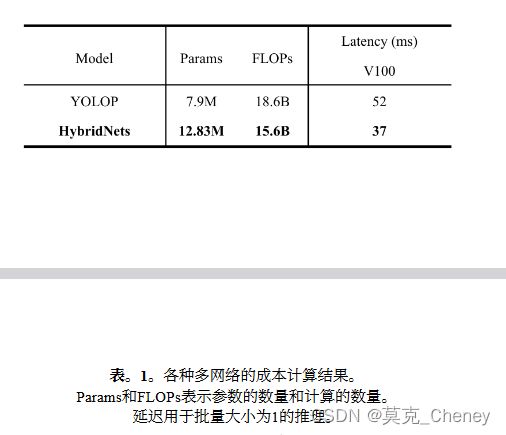
表1将HybridNets与其他多任务网络进行了比较。虽然我们的HybridNets具有比YOLOP(7900万)更广泛的参数(12.83万),但HybridNets的计算量比比较的网络要少。通过采用深度可分离卷积[3],计算量显著减少到15.6 BFLOPs。此外,我们还比较了V100 GPU FP16上的推理延迟。具体来说,我们的V100延迟是模型的时间处理,不包括预处理和NMS后处理。与以前的多网络相比,HybridNets在GPU上的速度提高了1.4倍。因此,HybridNets可以在标准设备和嵌入式设备上实时运行。
3.4. 多任务性能
第二个实验给出了三个任务的结果,包括交通目标检测、可驾驶区域分割和车道线分割。我们给出了车辆检测结果,并将其与BDD100K数据集上的六个模型进行了比较。
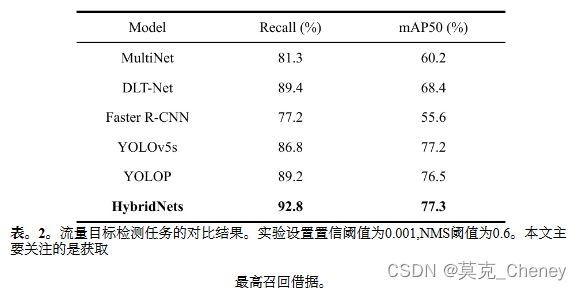
如表2所示,HybridNets在BDD100K数据集上的性能优于以前的网络。我们的模型达到了3.6%的召回率,达到了77.3%的最佳mAP50。我们可以在召回率和mAP50指标上优于之前的所有网络,因为我们的HybridNets可以检测到输入尺寸为(640,384,3)的3到10像素的小物体,这要归功于我们自动定制的锚点宽高比和比例。图4展示了交通对象检测的可视化。

如图5所示,与YOLOP相比,我们提出的体系结构做了进一步的改进。具体来说,在流量对象检测任务中,HybridNets可以检测小对象和大对象,而YOLOP的FalseNegative分数较高,会检测到错误对象。此外,HybridNets在各种复杂的天气条件下都能很好地工作,并且边界框更准确。





4. 结论与展望
本文系统地研究了多任务的网络架构设计选择,提出了一个高效的端到端感知网络,为加权双向特征网络中的每个层次定制自动长宽比,并构建高效的训练损失函数和训练策略,以提高精度和性能。基于这些优化,我们开发了一种新的端到端多网络,称为HybridNets,它在广泛的资源限制范围内实现了比现有技术更好的准确性和效率。最重要的是,我们的网络HybridNets以比以前的多网络模型更少的FLOPS实现了最先进的精度。
在未来的工作中,我们希望提出一个鲁棒的网络,它可以执行许多与感知相关的任务,并改善网络的参数和FLOPs。更具体地说,我们的工作将专注于自动驾驶中的处理问题,例如构建一个解码器网络,该网络可以只用一个输入就检测3d目标检测,并对几个目标进行分类。我们将尝试改善可驾驶区域分割中的车道线性能以及结构的上下文。