李宏毅机器学习第十六周周报NAT&HW5
文章目录
- week 16 Non-autoregressive Sequence Generation
- 摘要
- Abstract
- 一、李宏毅机器学习Non-autoregressive Sequence Generation
-
- 1. 问题阐述
-
- 1.1 Autoregressive model
- 1.2 Non-autoregressive model (mostly by Transformer)
- 2. Solution
-
- 2.1Vanilla NAT(Non-Autoregressive Translation)
- 2.2 Sequence-level knowledge distillation
- 2.3 Noisy Parallel Decoding(NPD)
- 3. Evolution of NAT
-
- 3.1 Iterative Refinement
- 3.2 Insertion Transformer
- 3.3 Kermit
- 3.4 Deletion
- 3.5 CTC
- 二、文献阅读
-
- 1. 题目
- 2. abstract
- 3. 网络架构——Levenshtein Transformer
-
- 3.1 model
- 3.2 Dual-policy Learning
- 3.3 Inference
- 4. 文献解读
-
- 4.1 Introduction
- 4.2 创新点
-
- 4.2.1 Sequence Generation and Refinement
- 4.2.2 Actions: Deletion & Insertion
- 4.3 实验过程
-
- 4.3.1 Sequence Generation
- 4.3.2 Sequence Refinement
- 4.4 结论
- 三、实验内容
-
- 1. 实验目的&实验结果
- 2.实验步骤
-
- 2.1 数据集
- 2.2 Evaluation
- 2.3 Wordflow
- 3. Preprocessing
-
- 3.1 环境配置
- 3.2 数据预处理
- 3.3 Subword Units
- 3.4 使用fairseq将资料转换为二进制
- 4. 环境配置
-
- 4.1 实验配置
- 4.2 logging
- 4.3 cuda环境
- 4.4 读取数据集
- 4.5 数据集迭代器
- 5. 模型框架
-
- 5.1 encoder
- 5.2 attention
- 5.3 decoder
- 5.4 Seq2Seq
- 5.5 build model
- 5.6 参数设置
- 5.7 Optimization
- 5.8 Optimizer
- 6. Training
- 7. Validation&Inference
- 8. Save and load model weights
- 9. Traning loop
- 小结
-
- 本周内容简报
- 下周规划
- 参考文献
week 16 Non-autoregressive Sequence Generation
摘要
本文主要讨论了NAT相关的模型。首先,本文介绍了各种基于非自回归序列生成思路的技术。在该思路下,模型能够更好的并行运行,从而该类技术能够提升模型的运行速度以及运行效果。其次,本文展示了题为Levenshtein Transformer论文的主要内容,这篇论文提出了基于删除和插入操作的部分自回归模型,该模型能够以更少的迭代次数实现比文中基线模型Transformer更好的效果。此外,这篇论文还提出了一种模型的两种基础操作的互补性的训练模式。最后,本文完成了HW5,使用Transformer模型完成了机器翻译任务。
Abstract
This article mainly discusses the NAT-related model. Firstly, this article introduces various techniques based on the idea of non-autoregressive sequence generation. Under this idea, models are better able to run in parallel, so that this type of technologies can improve the running speed and effect of models. Secondly, this article presents the main content of the paper entitled Levenshtein Transformer(LevT), which proposes a partial autoregressive model based on deletion and insertion operations, which can achieve better results than the baseline model Transformer with fewer iterations. In addition, this paper proposes a training model that complements the two basic operations of LevT. Finally, this paper completes HW5 and uses the Transformer model to complete the machine translation task.
一、李宏毅机器学习Non-autoregressive Sequence Generation
1. 问题阐述
在HW1中已经完成了语音辨识相关的序列任务,输入是一个语音序列,输出是一个文字序列
除此之外,输入还可以是一个图片,输出为一个文字序列,即图片解释
若输入为一个文字序列,输出为另一种语言的文字序列,则该任务为机器翻译
本节课程围绕机器翻译这一序列任务展开
1.1 Autoregressive model
这类模型在一个位置的输出需要该位置之前的输出作为参照,这使得生成的时间随着输入句子(问题规模)的增大而增大,如下式
p ( Y ∣ X ) = ∏ t = 1 T p ( y t ∣ y < t , X ) p(Y|X)=\prod_{t=1}^Tp(y_t|y_{
例如RNN中,在解码阶段,生成“好”需要参照“你”,该过程在Transformer中是类似的,如下图

1.2 Non-autoregressive model (mostly by Transformer)
但正如在之前的课程中介绍的那样,Transformer是可以并行运算的,这为非自回归模型提供了基础,从而上式可以该改写为另一种形式
p ( Y ∣ X ) = ∏ t = 1 T p ( y t ∣ y t , X ) p(Y|X)=\prod_{t=1}^Tp(y_t|y_{t},X) p(Y∣X)=t=1∏Tp(yt∣yt,X)
简单来说,可以将上图中transformer decoder部分的输入替换成预测出的输出序列长度以及位置编码
但若使用上述方式设计神经网络,会使得输出非结构化。例如下图右上角的情况,70%火车向左,30%向右,那么使用该方式的神经网络会输出两个方向叠加在一起的图片,即非结构化输出。
这是因为该方式后续输出并不参照之前输出,从而使得整个网络对于输出结构没有依赖性
有多种方式可以解决上述问题,第一种是修改前的transformer网络,因为该网络会根据之前的sample进行输出,因此该网络的输出也是具有结构性
另一种方式是GAN,下图右下角为Conditional GAN。其将经过归一化处理的分布z和训练数据c作为生成器G的输入,从而其输出Image或称x,即 x = G ( c , z ) x=G(c,z) x=G(c,z)。因为其参照了经过归一化处理的分布z,所以其输出也是结构化的。

上述阐述问题的是在图片生成任务中,若在文字序列生成中,则是下图的方式
下图左下角展示了两种错误结果,且其生成概率是较大的。这种问题即multi-modality problem

2. Solution
2.1Vanilla NAT(Non-Autoregressive Translation)
Fertility
直接将原始输入复制到decoder输入。此外,经过培育生成器由softmax输出,其输出确定复制的方式
但使用这种方法确定复制方式,可能其与输出位置的向量不对应,即输出序列和原序列的对应关系是错误的。
为了解决上述问题,可以使用其他校准方式,或者根据自回归模型的注意力权重分配
此外,当NAT模型收敛时,可以在培育分类部分使用强化学习

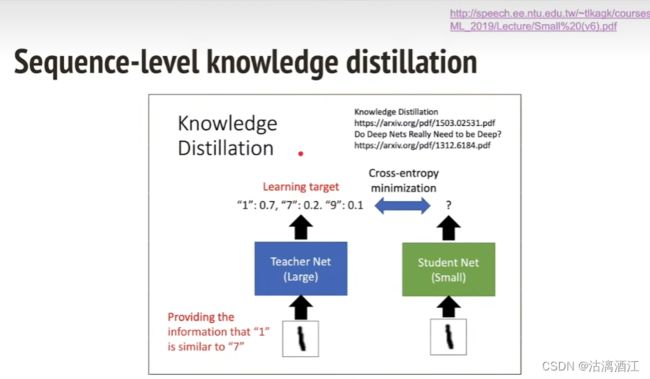
2.2 Sequence-level knowledge distillation
若要使得小模型达到大模型类似的效果,可以计算两者之间的交叉熵,调整小模型使得交叉熵最小化
- 对于本文中的问题,老师可以设置为自回归模型,而学生设置为非自回归模型
- 作为老师的自回归模型,构建新语料库
- 老师贪婪地将输出解码为学生的训练目标
2.3 Noisy Parallel Decoding(NPD)
- 采样一些培育序列
- 生成序列
- 由自回归模型评分
本部分比较简单,不再给出图片解释
3. Evolution of NAT
第一个即原型。
第二个递归增强,将生成的结果作为下次decoder的输入,从而在原序列上进行迭代。
第三个与第二的区别主要在于其迭代方式是将本次的输出插入到上次输出中,从而渐渐的完善
第四个与第三个的区别主要在于其可以删除原序列中生成错误的部分

3.1 Iterative Refinement
该方法的与原型的区别在于Decoder_2,该解码器用于生成第一次输出以外的迭代输出,可以将添加过噪声的数据作为其训练数据。

Mask-Predict
该方法也会预先生成序列长度,但其decoder为MaskedLM。该部分的输出会由 n = N ⋅ T − t T n=N\cdot \frac{T-t}T n=N⋅TT−t确定哪个位置进行遮罩,然后迭代出下一代序列

3.2 Insertion Transformer
插入的方式是在每两个字符之间设置一个输出位。对应位置输出若为空,则输出终止符。将其余非空位置插入原序列中。
训练时,直接生成一个0-1数组标识被删除的位置,将修改后序列作为训练数据即可

此外,更倾向于让序列优先生成靠近中间的字,这样整个序列的生成过程更接近平衡二叉树,因此可以将损失设置为 slot-loss ( x , y ^ , l ) = ∑ i = i t j t − log p ( y i , l ∣ x , y ^ ) ⋅ w l ( i ) \text{slot-loss}(x,\hat y,l)=\sum_{i=i_t}^{j_t}-\text{log}p(y_i,l|x,\hat y)\cdot w_l(i) slot-loss(x,y^,l)=∑i=itjt−logp(yi,l∣x,y^)⋅wl(i)
3.3 Kermit
他没有遵循encoder-decoder框架,而直接设计了一个encoder。该模型需要经过多个任务上的训练,才能表现出较好的效果,效果接近于BERT且是生成式神经网络。该模型可以用于完形填空

3.4 Deletion
即上文中的第四类模型。模型有三个decoder均接入encoder输出。第一个delete decoder用于确定哪个部分需要删除,第二个insert确定插入位置,第三个token确定插入内容。
首先Levenshtien给出了两个字符串之间举例、修改步骤的,修改步骤由三元组给出
训练方式:生成两个训练数据模式 y d e l , y i n s y_{del},y_{ins} ydel,yins,前者用于训练第一个decoder,后者用于训练后两个decoder

3.5 CTC
该模型在语音辨识部分已经介绍,故不再详细介绍,本部分主要介绍其迭代模型
原模型输入为声音讯号,而输出为文字序列,因此该模型不可以使用refined的方式进行优化。
Imputer
在此基础上,Imputer引入了Mask-Predict,即将带有遮罩的部分语句partial sentence作为输入的一部分,而相应的输出也是类似的形式,从而Imputer 可以refined
Block Decoding
设置块,每次至少生成对应块中的一个文字

以下是上文中提到的Knowledge Distillation的效果
可以看出当各个模型学习了多种翻译任务之后,自回归模型仍旧倾向于在一句话中输出单种语言的文字。但基础NAT和随机选择NAT则倾向于输出多种语言的文字序列,这显然与期望不符。而Knowledge Distillation的NAT在这方面具有和AT大致相同的倾向性,这是Knowledge Distillation的强大之处

二、文献阅读
1. 题目
标题:Levenshtein Transformer
作者:Jiatao Gu, Changhan Wang, Jake Zhaohttps://arxiv.org/search/stat?searchtype=author&query=Dean,+J)
链接:https://arxiv.org/abs/1905.11006
录用情况:NeurIPS2019
2. abstract
该文提出了Levenshtein Transformer,一种用于序列生成的部分自回归模型。该模型基于插入和删除。此外,根据两个操作的互补性,提出了一套针对性的训练技术。
This article proposes Levenshtein Transformer, a partially auto-regressive model for sequence generation. Insertion and deletion are key stone of this model. In addition, according to the complementarity of the two operations, this article proposes a targeted training technique.
3. 网络架构——Levenshtein Transformer
3.1 model
https://github.com/pytorch/fairseq/tree/master/examples/nonautoregressive_translation
基础模型使用transformer。
第l个区块的状态为
h 0 l + 1 , h 1 l + 1 , … , h n l + 1 = { E y 0 + P 0 , E y 1 + P 1 , … , E y n + P n , l = 0 T r a n s f o r m e r B l o c k ( h 0 l , h 1 l , … , h n l ) l > 0 (2) \mathbf h_0^{l+1},\mathbf h_1^{l+1},\dots,h_n^{l+1}= \begin{cases} E_{y_0}+P_0,E_{y_1}+P_1,\dots,E_{y_n}+P_n,\quad l=0\\ TransformerBlock(\mathbf h_0^{l},h_1^{l},\dots,h_n^{l})\quad l>0 \end{cases} \tag{2} h0l+1,h1l+1,…,hnl+1={Ey0+P0,Ey1+P1,…,Eyn+Pn,l=0TransformerBlock(h0l,h1l,…,hnl)l>0(2)
其中, E ∈ R ∣ V ∣ × d m o d e l , P ∈ R N m a x × d m o d e l E\in R^{|V|\times d_{model}}, P\in R^{N_{max}\times d_{model}} E∈R∣V∣×dmodel,P∈RNmax×dmodel是token以及位置编码
LevT模型的细化如下图所示

decoder的输出输入三个分类器,即deletion, placeholder, token。
-
Deletion:给出标记,删除或者保留
-
π θ d e l ( d ∣ i , y ) = softmax ( h i , A T ) , i = 1 , … , n − 1 (3) \pi_\theta^{del}(d|i,\mathbf y)=\text{softmax}(\mathbf h_i,A^T),\quad i=1,\dots,n-1 \tag{3} πθdel(d∣i,y)=softmax(hi,AT),i=1,…,n−1(3)
-
其中, A ∈ R 2 × d m o d e l A\in R^{2\times d_{model}} A∈R2×dmodel
-
-
Placeholder:将表示转换为分类分布来预测要在每个连接位置插入字节的数量
-
π θ p l h ( p ∣ i , y ) = softmax ( concat ( h i , h i + 1 ) ⋅ B T ) , i = 0 , … , n − 1 (4) \pi_\theta^{plh}(p|i,\mathbf y)=\text{softmax}(\text{concat}(\mathbf h_i,h_{i+1})\cdot B^T),\quad i=0,\dots,n-1 \tag{4} πθplh(p∣i,y)=softmax(concat(hi,hi+1)⋅BT),i=0,…,n−1(4)
-
其中, B ∈ R ( K m a x + 1 ) × ( 2 d m o d e l ) B\in R^{(K_{max}+1)\times(2d_{model})} B∈R(Kmax+1)×(2dmodel),根据预测标记数量确定当前位置插入占位符数量
-
-
Token:替换所有占位符标记
-
π θ t o k ( t ∣ i , y ) = softmax ( h i ⋅ C T ) , (5) \pi_\theta^{tok}(t|i,\mathbf y)=\text{softmax}(\mathbf h_i\cdot C^T), \tag{5} πθtok(t∣i,y)=softmax(hi⋅CT),(5)
-
其中, C ∈ R ∣ V ∣ × d m o d e l C\in R^{|V|\times d_{model}} C∈R∣V∣×dmodel的参数与编码矩阵共享
-
weight sharing 参数共享:本模型可以共享参数,也可以禁用该功能,但不影响整体推理时间
early exit 提前结束:中间层不再替换token,最后一层再替换
3.2 Dual-policy Learning
imitation learning 模拟学习:从专家策略 π ∗ \pi^* π∗中得出的行为,数据源自直接使用真实目标或者序列蒸馏过滤的噪声较小。
E y d e l ∼ d π ~ d e l , d ∗ ∼ π ∗ ∑ d i ∗ ∈ d ∗ log π θ d e l ( d i ∗ ∣ i , y d e l ) + E y i n s ∼ d π ~ i n s , p ∗ , t ∗ ∼ π ∗ [ ∑ p i ∗ ∈ p ∗ log π θ p l h ( p i ∗ ∣ i , y i n s ) + ∑ t i ∗ ∈ t ∗ log π θ t o k ( t i ∗ ∣ i , y i n s ′ ) ] \mathbf E_{y_{del}\sim d_{\tilde \pi_{del}},d^*\sim \pi^*}\sum_{d_i^*\in \mathbf d^*}\text{log}\pi_\theta^{del}(d_i^*|i,\mathbf y_{del})+\\\mathbf E_{y_{ins}\sim d_{\tilde \pi_{ins},\mathbf p^*,\mathbf t^*\sim \pi^*}}[\sum_{p_i^*\in \mathbf p^*}\text{log}\pi_\theta^{plh}(p_i^*|i,\mathbf y_{ins})+\sum_{t_i^*\in \mathbf t^*}\text{log}\pi_\theta^{tok}(t_i^*|i,\mathbf y'_{ins})] Eydel∼dπ~del,d∗∼π∗di∗∈d∗∑logπθdel(di∗∣i,ydel)+Eyins∼dπ~ins,p∗,t∗∼π∗[pi∗∈p∗∑logπθplh(pi∗∣i,yins)+ti∗∈t∗∑logπθtok(ti∗∣i,yins′)]
E y d e l ∼ d π ~ d e l , d ∗ ∼ π ∗ ∑ d i ∗ ∈ d ∗ log π θ d e l ( d i ∗ ∣ i , y d e l ) \mathbf E_{y_{del}\sim d_{\tilde \pi_{del}},d^*\sim \pi^*}\sum_{d_i^*\in \mathbf d^*}\text{log}\pi_\theta^{del}(d_i^*|i,\mathbf y_{del}) Eydel∼dπ~del,d∗∼π∗∑di∗∈d∗logπθdel(di∗∣i,ydel)——Deletion Objective
E y i n s ∼ d π ~ i n s , p ∗ , t ∗ ∼ π ∗ [ ∑ p i ∗ ∈ p ∗ log π θ p l h ( p i ∗ ∣ i , y i n s ) + ∑ t i ∗ ∈ t ∗ log π θ t o k ( t i ∗ ∣ i , y i n s ′ ) ] \mathbf E_{y_{ins}\sim d_{\tilde \pi_{ins},\mathbf p^*,\mathbf t^*\sim \pi^*}}[\sum_{p_i^*\in \mathbf p^*}\text{log}\pi_\theta^{plh}(p_i^*|i,\mathbf y_{ins})+\sum_{t_i^*\in \mathbf t^*}\text{log}\pi_\theta^{tok}(t_i^*|i,\mathbf y'_{ins})] Eyins∼dπ~ins,p∗,t∗∼π∗[∑pi∗∈p∗logπθplh(pi∗∣i,yins)+∑ti∗∈t∗logπθtok(ti∗∣i,yins′)]——Insertion Objective
y i n s ′ \mathbf y'_{ins} yins′是在 y i n s \mathbf y_{ins} yins上插入占位符 p ∗ \mathbf p* p∗后的输出。 π ~ d e l , π ~ i n s \tilde \pi_{del}, \tilde \pi_{ins} π~del,π~ins是滚入策略,从诱导状态分布 d π ~ d e l , d π ~ i n s d_{\tilde \pi_{del}},\ d_{\tilde \pi_{ins}} dπ~del, dπ~ins中反复绘制状态(序列)。由 π ∗ \pi^* π∗生成,然后最大化条件对数似然。根据定义,滚入策略决定了训练期间馈送到 π θ \pi_\theta πθ的状态分布。
下图显示了学习方式。

-
Learning to Delete:删除数据来源于原始输出和插入后序列的混合
-
d π ~ d e l = { y 0 if u < a else E ( E ( y ′ , p ∗ ) , t ~ ) , p ∗ ∼ π ∗ , t ~ ∼ π θ } (6) d_{\tilde \pi_{del}}=\{\mathbf y^0\ \text{if} u
-
其中, u ∼ Uniform[0,1] u\sim \text{Uniform[0,1]} u∼Uniform[0,1]以及 y ′ \mathbf y' y′是任意准备好插入token的序列。 t ~ \tilde t t~采样获得
-
-
Learning to Insert:来源于删除后的序列和随机删除词后目标序列的混合
- d π ~ i n s = { E ( y 0 , d ∗ ) , d ∗ ∼ π ∗ if u < β else E ( y ∗ , d ~ ) , d ~ ∼ π RND } (7) d_{\tilde \pi_{ins}}=\{\mathcal E(\mathbf y^0,\mathbf d^*),\mathbf d^*\sim \pi^*\ \text{if}\ u<\beta\ \text{else}\ \mathcal E(\mathbf y^*,\tilde{\mathbf d}),\tilde{\mathbf d}\sim \pi^{\text{RND}}\} \tag{7} dπ~ins={E(y0,d∗),d∗∼π∗ if u<β else E(y∗,d~),d~∼πRND}(7)
Expert Policy
即Dual-policy
-
Oracle:若有GT(ground-truth),则有从当前序列优化至GT的最优方式,这一概念在本文中即Levenshtein distance
-
a ∗ = argmin a D ( y ∗ , E ( y , a ) ) (8) \mathbf a^*=\text{argmin}_a\mathcal D(\mathbf y^*,\mathcal E(\mathbf y, \mathbf a)) \tag{8} a∗=argminaD(y∗,E(y,a))(8)
-
D \mathcal D D即Levenshtein distance
-
-
Distillation:使用相同数据训练一个自回归模型,使用该模型的beam search 结果替换GT
3.3 Inference
Greedy Decoding
使用训练完成的模型多次迭代 y 0 y_0 y0。作者发现使用贪婪策略的效果与噪音并行编码相近,这与自回归模型相反
- 可能由于自回归模型中贪婪策略获取的局部最优远离全局最优,搜索技术通过表格化解决了该问题。在本模型中,LevT动态插入或删除token,可以轻松撤销发现的次优token并重新插入更好token
- LevT的对数概率策略并不选择最佳输出的良好指标
Termination Condition
- Looping:两次迭代返回相同输出,则中止。可由以下操作导致
- 无操作
- 陷入训练,插入和删除相互抵消
- timeout
Penalty for Empty Placeholders
插入“空”占位符会导致更短的输出。因此在等式(4)中设置了惩罚组 γ ∈ [ 0 , 3 ] \gamma\in [0,3] γ∈[0,3]
4. 文献解读
4.1 Introduction
非自回归方法已经证明了在更少解码迭代次数内执行生成任务的可能性。本文提出了 Levenshtein Transformer (LevT),旨在解决当前解码模型缺乏灵活性的问题。LevT通过打破目前标准化的解码机制并用插入和删除这两个基本操作来代替它来弥补这一差距。
使用Imitation learning 来训练 LevT。最终模型包含两种以交替方式执行的策略。实验表明,LevT 在机器翻译和摘要方面取得了与标准 Transformer 模型相当或更好的结果,同时保持了与并行解码类似的效率优势(Lee et al., 2018)。这个模型使得解码变得更加灵活,可以同时解决翻译和refine的问题。
4.2 创新点
- 提出了LevT,一个序列生成模型,其性能和Transformer相近,同时提速5倍以上
- 模仿学习的框架下,针对二元策略的互补性和对抗性起初了相应的学习算法
- 由于模型的内在灵活性,是统一序列生成和refinement的先驱,从而使得在翻译任务上训练得到的LevT可以直接应用在译后编辑等refine任务上
4.2.1 Sequence Generation and Refinement
描述了一种将序列生成和序列改进问题统一为马尔可夫决策过程(MDP)的方法,决策过程由一个元组 ( Y , A , E , R , y 0 ) (\mathcal Y,\mathcal A,\mathcal E,\mathcal R,\mathcal y_0) (Y,A,E,R,y0) 定义。
- Y:由符号词汇表V构成的长度最大为Nmax的离散序列集合
- A:行动的集合
- E:环境,接受agent的编辑并返回修改后的序列
- R:奖励函数,衡量生成序列和真实序列的距离,可以用任何距离衡量函数,本文用的Levenshtein dis(也就是编辑距离)
- y0:初始序列,如果是一个已生成的那么agent就学习refine,如果是空,agent就退回到生成新序列的阶段
4.2.2 Actions: Deletion & Insertion
-
deletion:使用删除策略 π d e l ( d [ i , y ] ) \pi^{del}(d[i,y]) πdel(d[i,y])对每个标记 y i ∈ y y_i\in y yi∈y做二元决策,且 π d e l ( 0 ∣ 1 , y ) = π d e l ( 0 ∣ n , y ) = 1 \pi^{del}(0|1,y)=\pi^{del}(0|n,y)=1 πdel(0∣1,y)=πdel(0∣n,y)=1
-
insertion:该操作涉及两个阶段,占位符预测、token预测
- 对各个位置处理过程:判断是否要插入占位符,使用token替换占位符
-
Policy combination:将两者结合有,
- π ( a ∣ y ) = ∏ d i ∈ d π d e l ( d i ∣ i , y ) ⋅ ∏ p i ∈ p π p l h ( p i ∣ i , y ′ ) ⋅ ∏ t i ∈ t π t o k ( t i ∣ i , y ′ ′ ) (1) \pi(a|y)=\prod_{d_i\in \mathbf d}\pi^{del}(d_i|i,\mathbf y)\cdot\prod_{p_i\in \mathbf p}\pi^{plh}(p_i|i,\mathbf y')\cdot \prod_{t_i\in \mathbf t}\pi^{tok}(t_i|i,\mathbf y'') \tag{1} π(a∣y)=di∈d∏πdel(di∣i,y)⋅pi∈p∏πplh(pi∣i,y′)⋅ti∈t∏πtok(ti∣i,y′′)(1)
4.3 实验过程
4.3.1 Sequence Generation
特别的,该实验中序列设置为空
- 在MT任务上选择了3对语言
- WMT’16 Romanian-English (Ro-En)3
- WMT’14 English-German (En-De)4
- WAT2017 Small-NMT English-Japanese (En-Ja, Nakazawa et al., 2017)5
- 在TS任务上选择Annotated English Gigaword(Gigaword, Rush et al., 2015)6
- 该任务上使用BPE(BPE, Sennrich et al., 2016)[2]
- MT任务使用BLEU评估,TS任务使用ROUGE-1,2,L(三个标准)评估
下图是使用贪婪编码的自回归基线模型和LevT的在标准测试集上的相关测试结果

LevT实现了可比的甚至有时更好的生成质量,而LevT的解码效率要高得多。
Ablation on Efficiency:

上图为根据输入长度的平均迭代次数
将LevT分割为两部分,一部分用于删除,另一部分用于占位符预测,进行消融实验。质量略有下降,但执行速度相比Transformer的快五倍,结果如下图

Ablation on Weight Sharing:
使用不同权重评估LevT,下表列出了使用oracle或distilllation训练模型的结果。在两个插入操作之间权重共享有利于提高两者效果
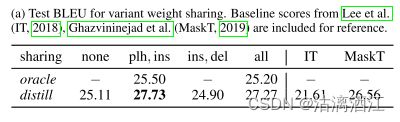
Importance of mixture roll-in policy:
训练了一个没有混合式(6)中 π θ \pi_\theta πθ的模型,称DAE。针对学习算法进行消融实验。结果如下表。DAE的删除损失较低,生成BLEU较差

4.3.2 Sequence Refinement
评估了LevT在APE任务上细化序列输出的能力
Dataset:
在合成APE实验中遵循一般协议(Grangier 和 Auli,2017)[3] :首先在一半数据集上训练输入 MT 系统。然后,将根据前一阶段的输出,在另一半上训练细化模型。
APE实验,使用En-De上WMT17自动后期编辑共享任务 8 的数据
Models&Evaluation:
基线模型是一个标准Transformer。此外,实验中还使用了两个模型,基于统计短语的 MT 系统(PBMT,Koehn 等人,2003)[4]和基于 RNN 的 NMT 系统(Bahdanau 等人,2015)[5]。除了BLEU之外,还使用翻译错误率(TER,Snover 等,2006)[6]
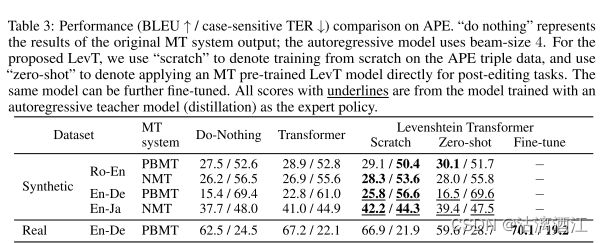
上表中显示了主要比较。从头开始训练时,LevT持续提高输入MT系统(PBMT或NMT)的性能。在大多数情况下,性能优于AT。
Pre-training on MT:由于LevT模型的通用性,证明了将生成训练的 LevT 模型直接应用于细化任务是可行的。根据上表,预训练的MT模型始终能够改进合成任务中的初始MT输入。
Collaborate with Oracle:由于插入和删除操作的分离,LevT具有更好的解释性和可控性。如下图所示,若每部都给出oracle删除,则MT和PE任务都有巨大的提升。

4.4 结论
该文提出了Levenshtein Transformer,一种基于插入和删除的神经序列生成模型。其相比现有模型提高了性能和解码效率,并在一个模型中包含了序列生成和细化。
三、实验内容
1. 实验目的&实验结果
本次的实验内容非常“简单”,将英文翻译为繁体中文。实验结果如下,实验内容结束(不是)

2.实验步骤
2.1 数据集
- training dataset
- TED2020: TED talks with transcriptions translated by a global community of volunteers to more than 100 language.
- we will use (en, zh-tw) aligned pairs.
- Monolingual data
- More TED talks in traditional chinese.
2.2 Evaluation
BLEU进行评估
-
朴素BLEU
-
Candidate the the the the the the the Reference1 the cat is on the mat Reference2 there is a cat on the mat 计算过程: 1. 候选翻译的每个词—the,都在参考译文中出现,分子为7; 2. 候选翻译一共就7个词,分母为7; 3. 这个翻译的得分: 7/7 = 1! 很明显,这样算是错的,需要改进一下。
-
-
改进型 BLEU 模型
-
C o u n t w i , j c l i p = m i n ( C o u n t w i , R e f j − C o u n t w i ) Count^{clip}_{w_{i,j}}=min(Count_{w_i},Ref_j-Count_{w_i}) Countwi,jclip=min(Countwi,Refj−Countwi)
-
C o u n t c l i p = m a x ( C o u n t w i , j c l i p ) , i = 1 , 2 , 3 , … Count^{clip}=max(Count_{w_{i,j}}^{clip}),i=1,2,3,\dots Countclip=max(Countwi,jclip),i=1,2,3,…
-
各变量解释
-
C o u n t w i Count_{w_i} Countwi:单词 w i w_i wi的个数
-
R e f j − C o u n t w i Ref_j-Count_{w_i} Refj−Countwi: w i w_i wi在第j个参考翻译中出现的次数
-
C o u n t w i , j c l i p Count_{w_{i,j}}^{clip} Countwi,jclip:对于第j个参考翻译, w i w_i wi的截断次数
-
C o u n t c l i p Count^{clip} Countclip: w i w_i wi在所有参考翻译中的综合截断次数
-
-
BLEU在文本段落中的使用
- p n = ∑ C ∈ C a n d i d a t e s ∑ n ⋅ g r a m ∈ C C o u n t c l i p ( n − g r a m ) ∑ C ∈ C a n d i d a t e s ∑ n ⋅ g r a m ′ ∈ C ′ ( n − g r a m ′ ) p_n=\frac{\sum_{C\in Candidates}\sum_{n\cdot gram\in C}Count_{clip}(n-gram)}{\sum_{C\in Candidates}\sum_{n\cdot gram'\in C'}(n-gram')} pn=∑C∈Candidates∑n⋅gram′∈C′(n−gram′)∑C∈Candidates∑n⋅gram∈CCountclip(n−gram)
-
最后加上brevity penalty
-
B P = { x i f c > r e ( 1 − r / c ) i f c ≤ r BP=\begin{cases}x\quad if\ c>r\\e^{(1-r/c)}\quad if\ c\leq r\end{cases} BP={xif c>re(1−r/c)if c≤r
-
B L E U = B P ⋅ exp ( ∑ n = 1 N w n log p n ) BLEU=BP\cdot \text{exp}(\sum_{n=1}^N w_n\text{log}p_n) BLEU=BP⋅exp(n=1∑Nwnlogpn)
-
最终形式
log B L E U = m i n ( 1 − r c , 0 ) + ∑ n = 1 N w n log p n \text{log}BLEU=min(1-\frac rc,0)+\sum_{n=1}^Nw_n\text{log}p_n logBLEU=min(1−cr,0)+n=1∑Nwnlogpn
-
一句话概括,模型翻译出来的句子和标签中的句子作比较,当二者相似的词越多,则翻译的准确率越高
2.3 Wordflow
- Preprocessing
- download raw data
- clean and normalize
- remove bad data(too long/short)
- Training
- initialize a model
- train it with training data
- Testing
- generate translation of data
- evaluate the performance
3. Preprocessing
3.1 环境配置
!pip install 'torch>=1.6.0' editdistance matplotlib sacrebleu sacremoses sentencepiece tqdm wandb
!pip install --upgrade jupyter ipywidgets
!git clone https://github.com/pytorch/fairseq.git
!cd fairseq && git checkout 9a1c4970
!pip install --upgrade ./fairseq/
在配置fairseq的过程中,若python version=3.11可能出现dataclass相关的错误,请使用上述语句进行配置
相关引入
import sys
import pdb
import pprint
import logging
import os
import random
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils import data
import numpy as np
import tqdm.auto as tqdm
from pathlib import Path
from argparse import Namespace
from fairseq import utils
import matplotlib.pyplot as plt
import sentencepiece as spm
3.2 数据预处理
- 处理的内容
- 下载并解压缩文件
- 将文件重命名
若使用windows系统,请自行配置最后几行语句,其作用为移动/修改文件
# 下载档案并解压缩
data_dir = './DATA/rawdata'
dataset_name = 'ted2020'
urls = (
'"https://onedrive.live.com/download?cid=3E549F3B24B238B4&resid=3E549F3B24B238B4%214989&authkey=AGgQ-DaR8eFSl1A"',
'"https://onedrive.live.com/download?cid=3E549F3B24B238B4&resid=3E549F3B24B238B4%214987&authkey=AA4qP_azsicwZZM"',
# # If the above links die, use the following instead.
# "https://www.csie.ntu.edu.tw/~r09922057/ML2021-hw5/ted2020.tgz",
# "https://www.csie.ntu.edu.tw/~r09922057/ML2021-hw5/test.tgz",
# # If the above links die, use the following instead.
# "https://mega.nz/#!vEcTCISJ!3Rw0eHTZWPpdHBTbQEqBDikDEdFPr7fI8WxaXK9yZ9U",
# "https://mega.nz/#!zNcnGIoJ!oPJX9AvVVs11jc0SaK6vxP_lFUNTkEcK2WbxJpvjU5Y",
)
file_names = (
'ted2020.tgz', # train & dev
'test.tgz', # test
)
prefix = Path(data_dir).absolute() / dataset_name
prefix.mkdir(parents=True, exist_ok=True)
for u, f in zip(urls, file_names):
path = prefix/f
if not path.exists():
if 'mega' in u:
!megadl {u} --path {path}
else:
!wget {u} -O {path}
if path.suffix == ".tgz":
!tar -xvf {path} -C {prefix}
elif path.suffix == ".zip":
!unzip -o {path} -d {prefix}
# 重命名文件,加上前缀train_dev/test
!mv {prefix/'raw.en'} {prefix/'train_dev.raw.en'}
!mv {prefix/'raw.zh'} {prefix/'train_dev.raw.zh'}
!mv {prefix/'test.en'} {prefix/'test.raw.en'}
!mv {prefix/'test.zh'} {prefix/'test.raw.zh'}
若使用windows系统,可以删除head开头的语句,其作用为展示结果,
可以尝试使用powershell相关指令解决
#设定语言
src_lang = 'en'
tgt_lang = 'zh'
data_prefix = f'{prefix}/train_dev.raw'
test_prefix = f'{prefix}/test.raw'
!head {data_prefix+'.'+src_lang} -n 5
!head {data_prefix+'.'+tgt_lang} -n 5
- 处理的内容
- 把字符串全形转半形
- 将字符串的特殊字符与内容以‘ ’分割
- 去掉或者替换掉一些特殊字符
以下代码可能会出现无法解码‘gbk’编码相关错误,可在打开文件时使用encoding='utf-8’解决。此问题还会再文中多处出现不再赘述
import re
def strQ2B(ustring):
"""Full width -> half width"""
# reference:https://ithelp.ithome.com.tw/articles/10233122
ss = []
for s in ustring:
rstring = ""
for uchar in s:
inside_code = ord(uchar)
if inside_code == 12288: # Full width space: direct conversion
inside_code = 32
elif (inside_code >= 65281 and inside_code <= 65374): # Full width chars (except space) conversion
inside_code -= 65248
rstring += chr(inside_code)
ss.append(rstring)
return ''.join(ss)
def clean_s(s, lang):
if lang == 'en':
s = re.sub(r"\([^()]*\)", "", s) # remove ([text])
s = s.replace('-', '') # remove '-'
s = re.sub('([.,;!?()\"])', r' \1 ', s) # keep punctuation
elif lang == 'zh':
s = strQ2B(s) # Q2B
s = re.sub(r"\([^()]*\)", "", s) # remove ([text])
s = s.replace(' ', '')
s = s.replace('—', '')
s = s.replace('“', '"')
s = s.replace('”', '"')
s = s.replace('_', '')
s = re.sub('([。,;!?()\"~「」])', r' \1 ', s) # keep punctuation
s = ' '.join(s.strip().split())
return s
def len_s(s, lang):
if lang == 'zh':
return len(s)
return len(s.split())
def clean_corpus(prefix, l1, l2, ratio=9, max_len=1000, min_len=1):
if Path(f'{prefix}.clean.{l1}').exists() and Path(f'{prefix}.clean.{l2}').exists():
print(f'{prefix}.clean.{l1} & {l2} exists. skipping clean.')
return
with open(f'{prefix}.{l1}', 'r', encoding='utf-8') as l1_in_f:
with open(f'{prefix}.{l2}', 'r', encoding='utf-8') as l2_in_f:
with open(f'{prefix}.clean.{l1}', 'w', encoding='utf-8') as l1_out_f:
with open(f'{prefix}.clean.{l2}', 'w', encoding='utf-8') as l2_out_f:
for s1 in l1_in_f:
s1 = s1.strip()
s2 = l2_in_f.readline().strip()
s1 = clean_s(s1, l1)
s2 = clean_s(s2, l2)
s1_len = len_s(s1, l1)
s2_len = len_s(s2, l2)
if min_len > 0: # remove short sentence
if s1_len < min_len or s2_len < min_len:
continue
if max_len > 0: # remove long sentence
if s1_len > max_len or s2_len > max_len:
continue
if ratio > 0: # remove by ratio of length
if s1_len / s2_len > ratio or s2_len / s1_len > ratio:
continue
print(s1, file=l1_out_f)
print(s2, file=l2_out_f)
clean_corpus(data_prefix, src_lang, tgt_lang)
clean_corpus(test_prefix, src_lang, tgt_lang, ratio=-1, min_len=-1, max_len=-1)
- 划分训练/验证集
valid_ratio = 0.01 # 3000~4000 would suffice
train_ratio = 1 - valid_ratio
# 最后划分为训练集和验证集 文件名称分别为 train.clean.en train.clean.zh valid.clean.en valid.clean.zh
if Path(f'{prefix}/train.clean.{src_lang}').exists() \
and Path(f'{prefix}/train.clean.{tgt_lang}').exists() \
and Path(f'{prefix}/valid.clean.{src_lang}').exists() \
and Path(f'{prefix}/valid.clean.{tgt_lang}').exists():
print(f'train/valid splits exists. skipping split.')
else:
line_num = sum(1 for line in open(f'{data_prefix}.clean.{src_lang}', encoding='utf-8'))
labels = list(range(line_num))
random.shuffle(labels)
for lang in [src_lang, tgt_lang]:
train_f = open(os.path.join(data_dir, dataset_name, f'train.clean.{lang}'), 'w', encoding='utf-8')
valid_f = open(os.path.join(data_dir, dataset_name, f'valid.clean.{lang}'), 'w', encoding='utf-8')
count = 0
for line in open(f'{data_prefix}.clean.{lang}', 'r', encoding='utf-8'):
if labels[count]/line_num < train_ratio:
train_f.write(line)
else:
valid_f.write(line)
count += 1
train_f.close()
valid_f.close()
3.3 Subword Units
对于为登录词,使用subword units作为短词单位解决,使用sentencepiece中unigram或byte-pair encoding,若未安装,则!pip install sentencepiece
# Subword Units
# 分词
# 使用sentencepiece中的spm对训练集和验证集进行分词建模,模型名称是spm8000.model,同时产生词汇库spm8000.vocab
# 使用模型对训练集、验证集、测试集进行分词处理,得到文件train.en, train.zh, valid.en, valid.zh, test.en, test.zh
import sentencepiece as spm
vocab_size = 8000
if Path(f'{prefix}/spm{vocab_size}.model').exists():
print(f'{prefix}/spm{vocab_size},model exits. skipping spm_train')
else:
spm.SentencePieceTrainer.train(
input=','.join([f'{prefix}/train.clean.{src_lang}',
f'{prefix}/valid.clean.{src_lang}',
f'{prefix}/train.clean.{tgt_lang}',
f'{prefix}/valid.clean.{tgt_lang}']),
model_prefix=f'{prefix}/spm{vocab_size}',
vocab_size=vocab_size,
character_coverage=1,
model_type='unigram', # 'bpe' 也可
input_sentence_size=1e6,
shuffle_input_sentence=True,
normalization_rule_name='nmt_nfkc_cf',
)
spm_model = spm.SentencePieceProcessor(model_file=str(f'{prefix}/spm{vocab_size}.model'))
in_tag = {
'train': 'train.clean',
'valid': 'valid.clean',
'test': 'test.raw.clean',
}
for split in ['train', 'valid', 'test']:
for lang in [src_lang, tgt_lang]:
out_path = Path(f'{prefix}/{split}.{lang}')
if out_path.exists():
print(f"{out_path} exists. skipping spm_encode.")
else:
with open(f'{prefix}/{split}.{lang}', 'w', encoding='utf-8') as out_f:
with open(f'{prefix}/{in_tag[split]}.{lang}', 'r', encoding='utf-8') as in_f:
for line in in_f:
line = line.strip()
tok = spm_model.encode(line, out_type=str)
print(' '.join(tok), file=out_f)
3.4 使用fairseq将资料转换为二进制
# 使用fairseq将数据二进制化 最终生成的文件在目录./data/data_bin下
binpath = Path('./data/data-bin')
if binpath.exists():
print(binpath, "exists, will not overwrite!")
else:
!python -m fairseq_cli.preprocess \
--source-lang en\
--target-lang zh\
--trainpref ./data/prefix/train\
--validpref ./data/prefix/valid\
--testpref ./data/prefix/test\
--destdir ./data/data_bin\
--joined-dictionary\
--workers 2
4. 环境配置
4.1 实验配置
config = Namespace(
datadir = "./DATA/data-bin/ted2020",
savedir = "./checkpoints/rnn",
source_lang = src_lang,
target_lang = tgt_lang,
# cpu threads when fetching & processing data.
num_workers=2,
# batch size in terms of tokens. gradient accumulation increases the effective batchsize.
max_tokens=8192,
accum_steps=2,
# the lr s calculated from Noam lr scheduler. you can tune the maximum lr by this factor.
lr_factor=2.,
lr_warmup=4000,
# clipping gradient norm helps alleviate gradient exploding
clip_norm=1.0,
# maximum epochs for training
max_epoch=15,
start_epoch=1,
# beam size for beam search
beam=5,
# generate sequences of maximum length ax + b, where x is the source length
max_len_a=1.2,
max_len_b=10,
# when decoding, post process sentence by removing sentencepiece symbols and jieba tokenization.
post_process = "sentencepiece",
# checkpoints
keep_last_epochs=5,
resume=None, # if resume from checkpoint name (under config.savedir)
# logging
use_wandb=False,
)
4.2 logging
logging.basicConfig(
format="%(asctime)s | %(levelname)s | %(name)s | %(message)s",
datefmt="%Y-%m-%d %H:%M:%S",
level="INFO", # "DEBUG" "WARNING" "ERROR"
stream=sys.stdout,
)
proj = "hw5.seq2seq"
logger = logging.getLogger(proj)
if config.use_wandb:
import wandb
wandb.init(project=proj, name=Path(config.savedir).stem, config=config)
4.3 cuda环境
cuda_env = utils.CudaEnvironment()
utils.CudaEnvironment.pretty_print_cuda_env_list([cuda_env])
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')

4.4 读取数据集
- 借用fairsq的TranslationTask
- 用来加载上面创建的二进制数据
- 实现良好的数据迭代器(dataloader)
- 字典task.source_directionary 和 task.targrt_directionary也很好用
- beam search
from fairseq.tasks.translation import TranslationConfig, TranslationTask
## setup task
task_cfg = TranslationConfig(
data=config.datadir,
source_lang=config.source_lang,
target_lang=config.target_lang,
train_subset="train",
required_seq_len_multiple=8,
dataset_impl="mmap",
upsample_primary=1,
)
task = TranslationTask.setup_task(task_cfg)
logger.info("loading data for epoch 1")
task.load_dataset(split="train", epoch=1, combine=True) # combine if you have back-translation data.
task.load_dataset(split="valid", epoch=1)
sample = task.dataset("valid")[1]
pprint.pprint(sample)
pprint.pprint(
"Source: " + \
task.source_dictionary.string(
sample['source'],
config.post_process,
)
)
pprint.pprint(
"Target: " + \
task.target_dictionary.string(
sample['target'],
config.post_process,
)
)
4.5 数据集迭代器
def load_data_iterator(task, split, epoch=1, max_tokens=4000, num_workers=1, cached=True):
batch_iterator = task.get_batch_iterator(
dataset=task.dataset(split),
max_tokens=max_tokens,
max_sentences=None,
max_positions=utils.resolve_max_positions(
task.max_positions(),
max_tokens,
),
ignore_invalid_inputs=True,
seed=seed,
num_workers=num_workers,
epoch=epoch,
disable_iterator_cache=not cached,
# Set this to False to speed up. However, if set to False, changing max_tokens beyond
# first call of this method has no effect.
)
return batch_iterator
demo_epoch_obj = load_data_iterator(task, "valid", epoch=1, max_tokens=20, num_workers=1, cached=False)
demo_iter = demo_epoch_obj.next_epoch_itr(shuffle=True)
sample = next(demo_iter)
sample
5. 模型框架
5.1 encoder
# 定义模型架构
# 使用fairsq的Encoder,decoder and model
class RNNEncoder(FairseqEncoder):
def __init__(self, args, dictionary, embed_tokens):
'''
:param args:
encoder_embed_dim 是embedding的维度,主要将one-hot vect的单词向量压缩到指定的维度
encoder_ffn_embed_dim 是RNN输出和隐藏状态的维度(hidden dimension)
encoder_layers 是RNN要叠多少层
dropout 是决定有大欧少的几率会将某个节点变为0,主要是为了防止overfitting,一般来说训练时用
:param dictionary: fairseq帮我们做好的dictionary 再次用来得到padding index,好用来得到encoder padding mask
:param embed_tokens: 事先做好的词嵌入(nn.Embedding)
'''
super().__init__(dictionary)
self.embed_tokens = embed_tokens
self.embed_dim = args.encoder_embed_dim
self.hidden_dim = args.encoder_ffn_embed_dim
self.num_layers = args.encoder_layers
self.dropout_in_module = nn.Dropout(args.dropout)
self.rnn = nn.GRU(
self.embed_dim,
self.hidden_dim,
self.num_layers,
dropout=args.dropout,
batch_first=False,
bidirectional=True,
)
self.dropout_out_module = nn.Dropout(args.dropout)
self.padding_idx = dictionary.pad()
def combine_bidir(self, outs, bsz:int):
out = outs.view(self.num_layers, 2, bsz, -1).transpose(1, 2).contiguous()
return out.view(self.num_layers, bsz, -1)
def forward(self, src_tokens, **unused):
'''
:param src_tokens: 英文的整数序列
:param unused:
:return:
outputs: 最上层RNN每个timestep的输出,最后可以用Attention再进行处理
final_hiddens: 每层最终timestep的隐藏状态,将传递到Decoder进行解码
encoder_padding_mask: 告诉我们那些事位置的资讯不重要
'''
bsz, seqlen = src_tokens.size()
# get embeddings
x = self.embed_tokens(src_tokens)
x = self.dropout_in_module(x)
# B x T x C => T x B x C
x = x.transpose(0, 1)
# 过双向RNN
h0 = x.new_zeros(2 * self.num_layers, bsz, self.hidden_dim)
x, final_hiddens = self.rnn(x, h0)
outputs = self.dropout_out_module(x)
# outputs = [sequence len, batch size, hid dim * directions] 是最上面RNN的输出
# hidden = [num_layers * directions, batch size , hid dim]
# 因为Encoder是双向的,我们需要链接两个方向的隐藏状态
final_hiddens = self.combine_bidir(final_hiddens, bsz)
# hidden = [num_layers x batch x num_directions*hidden]
encoder_padding_mask = src_tokens.eq(self.padding_idx).t()
return tuple(
(
outputs, # seq_len x batch x hidden
final_hiddens, # num_layers x batch x num_directions*hidden
encoder_padding_mask, # seq_len x batch
)
)
def reorder_encoder_out(self, encoder_out, new_order):
return tuple(
(
encoder_out[0].index_select(1, new_order),
encoder_out[1].index_select(1, new_order),
encoder_out[2].index_select(1, new_order),
)
)
5.2 attention
# Attention
class AttentionLayer(nn.Module):
def __init__(self, input_embed_dim, source_embed_dim, output_embed_dim, bias=False):
'''
:param input_embed_dim: key 的维度,应是 decoder 要做 attend 时的向量的维度
:param source_embed_dim: query 的维度,应是要被 attend 的向量(encoder outputs)的维度
:param output_embed_dim: value 的维度,应是做完 attention 后,下一层预期的向量维度
:param bias:
'''
super().__init__()
self.input_proj = nn.Linear(input_embed_dim, source_embed_dim, bias=bias)
self.output_proj = nn.Linear(
input_embed_dim + source_embed_dim, output_embed_dim, bias=bias
)
def forward(self, inputs, encoder_outputs, encoder_padding_mask):
'''
:param inputs: 就是key,要attend别人的向量
:param encoder_outputs: 是query/value,被attend的向量
:param encoder_padding_mask: 告诉我们哪些是位置的资讯不重要
:return:
output: 做完attention后的context vector
attention score: attention的分布
'''
# inputs: T, B, dim
# encoder_outputs: S x B x dim
# padding mask: S x B
# convert all to batch first
inputs = inputs.transpose(1, 0) # B, T, dim
encoder_outputs = encoder_outputs.transpose(1, 0) #B, S, dim
encoder_padding_mask = encoder_padding_mask.transpose(1, 0) # B, S
# 投影到encoder_outputs的维度
# (B, T, dm) x (B, dim, S) = (B, T, S)
attn_scores = torch.bmm(x, encoder_outputs.transpose(1, 2))
# 挡住padding位置的attention
if encoder_padding_mask is not None:
# 利用broadcast B, S -> (B, 1, S)
encoder_padding_mask = encoder_padding_mask.unsqueeze(1)
attn_scores = (
attn_scores.float()
.masked_dill_(encoder_padding_mask, float("-inf"))# 用来mask掉当前时刻后面时刻的序列信息
.type_as(attn_scores)# 按照给定的tensor进行类型转换
)
# 在source对应维度softmax
attn_scores = F.softmax(attn_scores, dim=-1)
# 形状(B, T, S) x (B, S, dim) = (B, T, dim)加权平均
x = torch.bmm(attn_scores, encoder_outputs)
# (B, T, dim)
x = torch.cat((x, inputs), dim=-1)
x = torch.tanh(self.output_proj(x)) # output + linear + tanh
# 回复形状(B, T, dim) -> (T, B, dim)
return x.transpose(1, 0), attn_scores
5.3 decoder
# Decoder
class RNNDecoder(FairseqIncrementalDecoder):
def __init__(self, args, dictionary, embed_tokens):
super().__init__(dictionary)
self.embed_tokens = embed_tokens
assert args.decoder_layers == args.encoder_layers, f"""seq2seq rnn requires that encoder
and decoder have same layers of rnn. got: {args.encoder_layers, args.decoder_layers}"""
assert args.decoder_ffn_embed_dim == args.encoder_ffn_embed_dim * 2, f"""seq2seq-rnn requires
that decoder hidden to be 2*encoder hidden dim. got: {args.decoder_ffn_embed_dim, args.encoder_ffn_embed_dim * 2}"""
self.embed_dim = args.decoder_embed_dim
self.hidden_dim = args.decoder_ffn_embed_dim
self.num_layers = args.decoder_layers
self.dropout_in_module = nn.Dropout(args.dropout)
self.rnn = nn.GRU(
self.embed_dim,
self.hidden_dim,
self.num_layers,
dropout=args.dropout,
batch_first=False,
bidirectional=False,
)
self.attention = AttentionLayer(
self.embed_dim, self.hidden_dim, self.embed_dim, bias=False
)
# self.attention = None
self.dropout_out_module = nn.Dropout(args.dropout)
if self.hidden_dim != self.embed_dim:
self.project_out_dim = nn.Linear(self.hidden_dim, self.embed_dim)
else:
self.project_out_dim = None
if args.share_decoder_input_output_embed:
self.output_projection = nn.Linear(
self.embed_tokens.weight.shape[1],
self.embed_tokens.weight.shape[0],
bias=False,
)
self.output_projection.weight = self.embed_tokens.weight
else:
self.output_projection = nn.Linear(
self.output_embed_dim, len(dictionary), bias=False
)
nn.init.normal_(
self.output_projection.weight, mean=0, std=self.output_embed_dim ** -0.5
)
def forward(self, prev_output_tokens, encoder_out, incremental_state=None, **unused):
# 取出encoder的输出
encoder_outputs, encoder_hiddens, encoder_padding_mask = encoder_out
# outputs: seq_len x batch x num_directions*hidden
# encoder_hiddens: num_layers x batch x num_directions*encoder_hidden
# padding_mask: seq_len x batch
if incremental_state is not None and len(incremental_state
)>0:
# 如果保留了上一个timestep留下的资讯,我们可以从那里进来,而不是从bos开始
prev_output_tokens = prev_output_tokens[:, -1:]
cache_state = self.get_incremental_state(incremental_state, "cache_state")
prev_hiddens = cache_state["prev_hiddens"]
else:
# 沒有incremental state代表这是training或者是test time时的第一步
# 准备seq2seq: 把encoder_hiddens pass进去decoder的hidden states
prev_hiddens = encoder_hiddens
bsz, seqlen = prev_output_tokens.size()
# embed tokens
x = self.embed_tokens(prev_output_tokens)
x = self.dropout_in_module(x)
# B x T x C -> T x B x C
x = x.transpose(0, 1)
# 做decoder-to-encoder attention
if self.attention is not None:
x, attn = self.attention(x, encoder_outputs, encoder_padding_mask)
# 过单向RNN
x, final_hiddens = self.rnn(x, prev_hiddens)
# outputs = [sequence len, batch size, hid dim]
# hidden = [num_layers * directions, batch size , hid dim]
x = self.dropout_out_module(x)
# 投影到embedding size (如果hidden 和embed size不一样,然后share_embedding又变成True,需要额外project一次)
if self.project_out_dim != None:
x = self.project_out_dim(x)
# 投影到vocab size 的分布
x = self.output_projection(x)
# T x B x C -> B x T x C
x = x.transpose(1, 0)
# 如果是Incremental, 记录这个timestep的hidden states, 下个timestep读回来
cache_state = {
"prev_hiddens": final_hiddens,
}
self.set_incremental_state(incremental_state, "cached_state", cache_state)
return x, None
def reorder_incremental_state(
self,
incremental_state,
new_order,
):
# 这个beam search时会用到,意思并不是很重要
cache_state = self.get_incremental_state(incremental_state, "cached_state")
prev_hiddens = cache_state["prev_hiddens"]
prev_hiddens = [p.index_select(0, new_order) for p in prev_hiddens]
cache_state = {
"prev_hiddens": torch.stack(prev_hiddens),
}
self.set_incremental_state(incremental_state, "cached_state", cache_state)
return
5.4 Seq2Seq
# Seq2Seq
class Seq2Seq(FairseqEncoderDecoderModel):
def __init__(self, args, encoder, decoder):
super().__init__(encoder, decoder)
self.args = args
def forward(self, src_tokens, src_lengths, prev_output_tikens, return_all_hiddens: bool = True):
encoder_out = self.encoder(
src_tokens, src_lengths=src_lengths, return_all_hiddens=return_all_hiddens
)
logits, extra = self.decoder(
prev_output_tikens,
encoder_out=encoder_out,
src_lengths=src_lengths,
return_all_hiddens=return_all_hiddens,
)
return logits, extra
5.5 build model
# # HINT: transformer architecture
from fairseq.models.transformer import (
TransformerEncoder,
TransformerDecoder,
)
# 模型初始化
def build_model(args, task):
src_dict, tgt_dict = task.source_dictionary, task.target_dictionary
# 词嵌入
encoder_embed_tokens = nn.Embedding(len(src_dict), args.encoder_embed_dim, src_dict.pad())
decoder_embed_tokens = nn.Embedding(len(tgt_dict), args.decoder_embed_dim, tgt_dict.pad())
# 编码器和解码器
encoder = RNNEncoder(args, src_dict, encoder_embed_tokens)
decoder = RNNDecoder(args, tgt_dict, decoder_embed_tokens)
# 序列到序列模型
model = Seq2Seq(args, encoder, decoder)
# 序列到序列模型的初始化很重要 需要特别处理
def init_params(module):
from fairseq.modules import MultiheadAttention
if isinstance(module, nn.Linear):
module.weight.data.normal_(mean=0.0, std=0.02)
if module.bias is not None:
module.bias.data.zero_()
if isinstance(module, nn.Embedding):
module.weight.data.normal_(mean=0.0, std=0.02)
if module.padding_idx is not None:
module.weight.data[module.padding_idx].zero_()
if isinstance(module, MultiheadAttention):
module.q_proj.weight.data.normal_(mean=0.0, std=0.02)
module.k_proj.weight.data.normal_(mean=0.0, std=0.02)
module.v_proj.weight.data.normal_(mean=0.0, std=0.02)
if isinstance(module, nn.RNNBase):
for name, param in module.named_parameters():
if "weight" in name or "bias" in name:
param.data.uniform_(-0.1, 0.1)
# 初始化模型
model.apply(init_params)
return model
5.6 参数设置
arch_args = Namespace(
encoder_embed_dim=256,
encoder_ffn_embed_dim=512,
encoder_layers=1,
decoder_embed_dim=256,
decoder_ffn_embed_dim=1024,
decoder_layers=1,
share_decoder_input_output_embed=True,
dropout=0.3,
)
model = build_model(arch_args, task)
logger.info(model)
5.7 Optimization
class LabelSmoothedCrossEntropyCriterion(nn.Module):
def __init__(self, smoothing, ignore_index=None, reduce=True):
super().__init__()
self.smoothing = smoothing
self.ignore_index = ignore_index
self.reduce = reduce
def forward(self, lprobs, target):
if target.dim() == lprobs.dim() - 1:
target = target.unsqueeze(-1)
# nll: Negative log likelihood,當目標是one-hot時的cross-entropy loss. 以下同 F.nll_loss
nll_loss = -lprobs.gather(dim=-1, index=target)
# 將一部分正確答案的機率分配給其他label 所以當計算cross-entropy時等於把所有label的log prob加起來
smooth_loss = -lprobs.sum(dim=-1, keepdim=True)
if self.ignore_index is not None:
pad_mask = target.eq(self.ignore_index)
nll_loss.masked_fill_(pad_mask, 0.0)
smooth_loss.masked_fill_(pad_mask, 0.0)
else:
nll_loss = nll_loss.squeeze(-1)
smooth_loss = smooth_loss.squeeze(-1)
if self.reduce:
nll_loss = nll_loss.sum()
smooth_loss = smooth_loss.sum()
# 計算cross-entropy時 加入分配給其他label的loss
eps_i = self.smoothing / lprobs.size(-1)
loss = (1.0 - self.smoothing) * nll_loss + eps_i * smooth_loss
return loss
# 一般都用0.1效果就很好了
criterion = LabelSmoothedCrossEntropyCriterion(
smoothing=0.1,
ignore_index=task.target_dictionary.pad(),
)
5.8 Optimizer
def get_rate(d_model, step_num, warmup_step):
# TODO: Change lr from constant to the equation shown above
lr = 0.001
return lr
class NoamOpt:
"Optim wrapper that implements rate."
def __init__(self, model_size, factor, warmup, optimizer):
self.optimizer = optimizer
self._step = 0
self.warmup = warmup
self.factor = factor
self.model_size = model_size
self._rate = 0
@property
def param_groups(self):
return self.optimizer.param_groups
def multiply_grads(self, c):
"""Multiplies grads by a constant *c*."""
for group in self.param_groups:
for p in group['params']:
if p.grad is not None:
p.grad.data.mul_(c)
def step(self):
"Update parameters and rate"
self._step += 1
rate = self.rate()
for p in self.param_groups:
p['lr'] = rate
self._rate = rate
self.optimizer.step()
def rate(self, step = None):
"Implement `lrate` above"
if step is None:
step = self._step
return 0 if not step else self.factor * get_rate(self.model_size, step, self.warmup)
optimizer = NoamOpt(
model_size=arch_args.encoder_embed_dim,
factor=config.lr_factor,
warmup=config.lr_warmup,
optimizer=torch.optim.AdamW(model.parameters(), lr=0, betas=(0.9, 0.98), eps=1e-9, weight_decay=0.0001))
plt.plot(np.arange(1, 100000), [optimizer.rate(i) for i in range(1, 100000)])
plt.legend([f"{optimizer.model_size}:{optimizer.warmup}"])
None
6. Training
from fairseq.data import iterators
from torch.cuda.amp import GradScaler, autocast
def train_one_epoch(epoch_itr, model, task, criterion, optimizer, accum_steps=1):
itr = epoch_itr.next_epoch_itr(shuffle=True)
itr = iterators.GroupedIterator(itr, accum_steps) # gradient accumulation: update every accum_steps samples
stats = {"loss": []}
scaler = GradScaler() # automatic mixed precision (amp)
model.train()
progress = tqdm.tqdm(itr, desc=f"train epoch {epoch_itr.epoch}", leave=False)
for samples in progress:
model.zero_grad()
accum_loss = 0
sample_size = 0
# gradient accumulation: update every accum_steps samples
for i, sample in enumerate(samples):
if i == 1:
# emptying the CUDA cache after the first step can reduce the chance of OOM
torch.cuda.empty_cache()
sample = utils.move_to_cuda(sample, device=device)
target = sample["target"]
sample_size_i = sample["ntokens"]
sample_size += sample_size_i
# mixed precision training
with autocast():
net_output = model.forward(**sample["net_input"])
lprobs = F.log_softmax(net_output[0], -1)
loss = criterion(lprobs.view(-1, lprobs.size(-1)), target.view(-1))
# logging
accum_loss += loss.item()
# back-prop
scaler.scale(loss).backward()
scaler.unscale_(optimizer)
optimizer.multiply_grads(1 / (sample_size or 1.0)) # (sample_size or 1.0) handles the case of a zero gradient
gnorm = nn.utils.clip_grad_norm_(model.parameters(), config.clip_norm) # grad norm clipping prevents gradient exploding
scaler.step(optimizer)
scaler.update()
# logging
loss_print = accum_loss/sample_size
stats["loss"].append(loss_print)
progress.set_postfix(loss=loss_print)
if config.use_wandb:
wandb.log({
"train/loss": loss_print,
"train/grad_norm": gnorm.item(),
"train/lr": optimizer.rate(),
"train/sample_size": sample_size,
})
loss_print = np.mean(stats["loss"])
logger.info(f"training loss: {loss_print:.4f}")
return stats
7. Validation&Inference
# fairseq's beam search generator
# given model and input seqeunce, produce translation hypotheses by beam search
sequence_generator = task.build_generator([model], config)
def decode(toks, dictionary):
# convert from Tensor to human readable sentence
s = dictionary.string(
toks.int().cpu(),
config.post_process,
)
return s if s else ""
def inference_step(sample, model):
gen_out = sequence_generator.generate([model], sample)
srcs = []
hyps = []
refs = []
for i in range(len(gen_out)):
# for each sample, collect the input, hypothesis and reference, later be used to calculate BLEU
srcs.append(decode(
utils.strip_pad(sample["net_input"]["src_tokens"][i], task.source_dictionary.pad()),
task.source_dictionary,
))
hyps.append(decode(
gen_out[i][0]["tokens"], # 0 indicates using the top hypothesis in beam
task.target_dictionary,
))
refs.append(decode(
utils.strip_pad(sample["target"][i], task.target_dictionary.pad()),
task.target_dictionary,
))
return srcs, hyps, refs
import shutil
import sacrebleu
def validate(model, task, criterion, log_to_wandb=True):
logger.info('begin validation')
itr = load_data_iterator(task, "valid", 1, config.max_tokens, config.num_workers).next_epoch_itr(shuffle=False)
stats = {"loss":[], "bleu": 0, "srcs":[], "hyps":[], "refs":[]}
srcs = []
hyps = []
refs = []
model.eval()
progress = tqdm.tqdm(itr, desc=f"validation", leave=False)
with torch.no_grad():
for i, sample in enumerate(progress):
# validation loss
sample = utils.move_to_cuda(sample, device=device)
net_output = model.forward(**sample["net_input"])
lprobs = F.log_softmax(net_output[0], -1)
target = sample["target"]
sample_size = sample["ntokens"]
loss = criterion(lprobs.view(-1, lprobs.size(-1)), target.view(-1)) / sample_size
progress.set_postfix(valid_loss=loss.item())
stats["loss"].append(loss)
# do inference
s, h, r = inference_step(sample, model)
srcs.extend(s)
hyps.extend(h)
refs.extend(r)
tok = 'zh' if task.cfg.target_lang == 'zh' else '13a'
stats["loss"] = torch.stack(stats["loss"]).mean().item()
stats["bleu"] = sacrebleu.corpus_bleu(hyps, [refs], tokenize=tok) # 計算BLEU score
stats["srcs"] = srcs
stats["hyps"] = hyps
stats["refs"] = refs
if config.use_wandb and log_to_wandb:
wandb.log({
"valid/loss": stats["loss"],
"valid/bleu": stats["bleu"].score,
}, commit=False)
showid = np.random.randint(len(hyps))
logger.info("example source: " + srcs[showid])
logger.info("example hypothesis: " + hyps[showid])
logger.info("example reference: " + refs[showid])
# show bleu results
logger.info(f"validation loss:\t{stats['loss']:.4f}")
logger.info(stats["bleu"].format())
return stats
8. Save and load model weights
def validate_and_save(model, task, criterion, optimizer, epoch, save=True):
stats = validate(model, task, criterion)
bleu = stats['bleu']
loss = stats['loss']
if save:
# save epoch checkpoints
savedir = Path(config.savedir).absolute()
savedir.mkdir(parents=True, exist_ok=True)
check = {
"model": model.state_dict(),
"stats": {"bleu": bleu.score, "loss": loss},
"optim": {"step": optimizer._step}
}
torch.save(check, savedir/f"checkpoint{epoch}.pt")
shutil.copy(savedir/f"checkpoint{epoch}.pt", savedir/f"checkpoint_last.pt")
logger.info(f"saved epoch checkpoint: {savedir}/checkpoint{epoch}.pt")
# save epoch samples
with open(savedir/f"samples{epoch}.{config.source_lang}-{config.target_lang}.txt", "w") as f:
for s, h in zip(stats["srcs"], stats["hyps"]):
f.write(f"{s}\t{h}\n")
# get best valid bleu
if getattr(validate_and_save, "best_bleu", 0) < bleu.score:
validate_and_save.best_bleu = bleu.score
torch.save(check, savedir/f"checkpoint_best.pt")
del_file = savedir / f"checkpoint{epoch - config.keep_last_epochs}.pt"
if del_file.exists():
del_file.unlink()
return stats
def try_load_checkpoint(model, optimizer=None, name=None):
name = name if name else "checkpoint_last.pt"
checkpath = Path(config.savedir)/name
if checkpath.exists():
check = torch.load(checkpath)
model.load_state_dict(check["model"])
stats = check["stats"]
step = "unknown"
if optimizer != None:
optimizer._step = step = check["optim"]["step"]
logger.info(f"loaded checkpoint {checkpath}: step={step} loss={stats['loss']} bleu={stats['bleu']}")
else:
logger.info(f"no checkpoints found at {checkpath}!")
9. Traning loop
model = model.to(device=device)
criterion = criterion.to(device=device)
logger.info("task: {}".format(task.__class__.__name__))
logger.info("encoder: {}".format(model.encoder.__class__.__name__))
logger.info("decoder: {}".format(model.decoder.__class__.__name__))
logger.info("criterion: {}".format(criterion.__class__.__name__))
logger.info("optimizer: {}".format(optimizer.__class__.__name__))
logger.info(
"num. model params: {:,} (num. trained: {:,})".format(
sum(p.numel() for p in model.parameters()),
sum(p.numel() for p in model.parameters() if p.requires_grad),
)
)
logger.info(f"max tokens per batch = {config.max_tokens}, accumulate steps = {config.accum_steps}")
epoch_itr = load_data_iterator(task, "train", config.start_epoch, config.max_tokens, config.num_workers)
try_load_checkpoint(model, optimizer, name=config.resume)
while epoch_itr.next_epoch_idx <= config.max_epoch:
# train for one epoch
train_one_epoch(epoch_itr, model, task, criterion, optimizer, config.accum_steps)
stats = validate_and_save(model, task, criterion, optimizer, epoch=epoch_itr.epoch)
logger.info("end of epoch {}".format(epoch_itr.epoch))
epoch_itr = load_data_iterator(task, "train", epoch_itr.next_epoch_idx, config.max_tokens, config.num_workers)
小结
本文主要讨论了NAT相关的模型。首先,本文介绍了各种基于非自回归序列生成思路的技术。在该思路下,模型能够更好的并行运行,从而该类技术能够提升模型的运行速度以及运行效果。其次,本文展示了题为Levenshtein Transformer论文的主要内容,这篇论文提出了基于删除和插入操作的部分自回归模型,该模型能够以更少的迭代次数实现比文中基线模型Transformer更好的效果。此外,这篇论文还提出了一种模型的两种基础操作的互补性的训练模式。最后,本文完成了HW5,使用Transformer模型完成了机器翻译任务。
本周内容简报
首先,简单介绍了NAT相较于AT的优点,展示了该方面研究的可行性。之后,提出了一种从AT模型简单改进而来的模型,以该模型为例展示了NAT方面研究所面临的困境。
其次,介绍了多种NAT模型,以及基于知识蒸馏的训练过程。
- NAT原型,将原始输入复制到decoder输入,复制方式由fertility generator确定
- 知识蒸馏,AT模型作为老师,生成NAT模型的训练资料
- 噪音并行解码,知识蒸馏的实现
之后,介绍了NAT模型的迭代过程,即原型 → \rightarrow →递归增强 → \rightarrow →基于插入的递归模型 → \rightarrow →基于删除、插入的递归模型
下周规划
开始生成式对抗网络的学习。本周仅实现了HW5的simple baseline,下周考虑进行迭代,或者实现GAN模型。阅读GAN模型相关论文。
参考文献
[1] Jiatao Gu, Changhan Wang, Jake Zhao:arXiv:1905.11006.[J]. arXiv:1905.11006
[2] Rico Sennrich, Barry Haddow, and Alexandra Birch. 2016. Neural machine translation of rare words with subword units. In Proceedings ofthe 54th Annual Meeting ofthe Association for Computational Linguistics (Volume 1: Long Papers), pages 1715–1725, Berlin, Germany. Association for Computational Linguistics.
[3] David Grangier and Michael Auli. 2017. Quickedit: Editing text & translations by crossing words
out. arXiv preprint arXiv:1711.04805.
[4] Philipp Koehn, Franz Josef Och, and Daniel Marcu. 2003. Statistical phrase-based translation.
In Proceedings of the 2003 Conference of the North American Chapter of the Association for
Computational Linguistics on Human Language Technology-Volume 1, pages 48–54. Association
for Computational Linguistics.
[5] Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. 2015. Neural machine translation by jointly learning to align and translate. In 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings.
[6] Matthew Snover, Bonnie Dorr, Richard Schwartz, Linnea Micciulla, and John Makhoul. 2006. A
study of translation edit rate with targeted human annotation. In In Proceedings ofAssociation for
Machine Translation in the Americas, pages 223–231.