一文看懂Prometheus告警原理及过程
目录
1. 自定义告警规则
2. 告警规则编写
3. prometheus配置
4. 告警过程
5. 告警解除
5.1 对startsAt和endsAt的处理
5.2 Prometheus告警解除后持续多久重复推送告警解除通知??
1. 自定义告警规则
基于规则告警是指利用已经采集的监控数据,匹配用户自定义的多维度告警规则,如果满足,则触发相应规则的告警。例如,性能告警规则一般是设定某个阈值、触发次数和告警行为,对于 CPU利用率、内存使用量、QPS等性能指标,如果在某个时间段内多次触发该阈值,则将其视为满足告警条件。
2. 告警规则编写
一条报警规则主要由以下几部分组成:
alert:告警规则的名称
expr:是用于进行报警规则 PromQL 查询语句
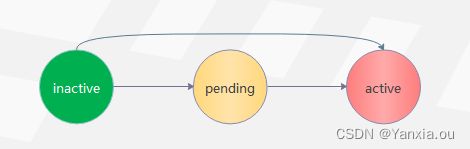
for:评估等待时间(Pending Duration),用于表示只有当触发条件持续一段时间后才发送告警,在等待期间新产生的告警状态为pending
labels:自定义标签,允许用户指定额外的标签列表,把它们附加在告警上
annotations:指定了另一组标签,它们不被当做告警实例的身份标识,它们经常用于存储一些额外的信息,用于报警信息的展示之类的。
告警规则示例:

3. prometheus配置
global:
# How frequently to scrape targets by default.
scrape_interval: 30s
# How long until a scrape request times out.
scrape_timeout: 10s
# How frequently to evaluate rules.
evaluation_interval: 1m
alerting:
alertmanagers:
- static_configs:
- targets:
- 172.0.20.1:8088
rule_files:
- ./rules/*.yml
Prometheus以scrape_interval(默认为1m)规则周期,从监控目标上收集信息。其中scrape_interval可以基于全局或基于单个metric定义;然后将监控信息持久存储在其本地存储上。
Prometheus以evaluation_interval(默认为1m)另一个独立的规则周期,对告警规则做定期计算。其中evaluation_interval只有全局值;然后更新告警状态。
4. 告警过程
1、告警流程图
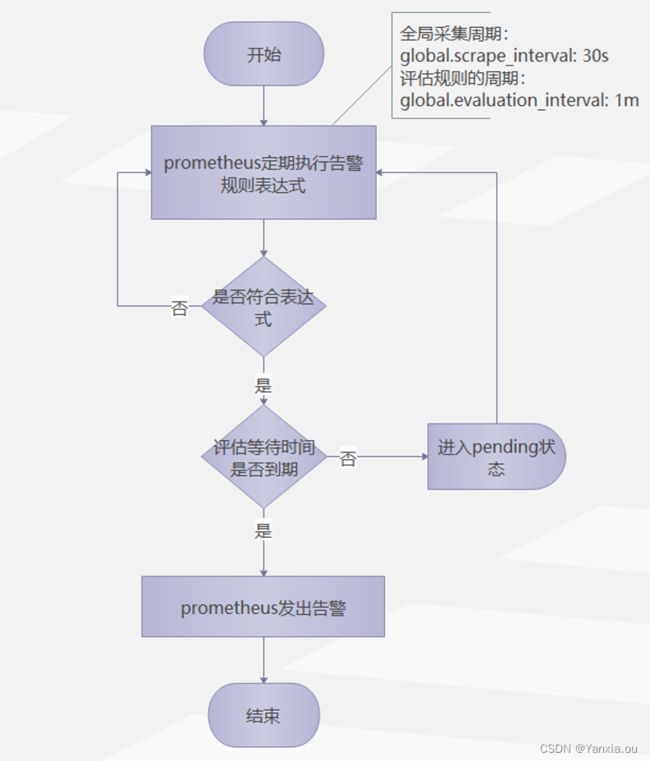
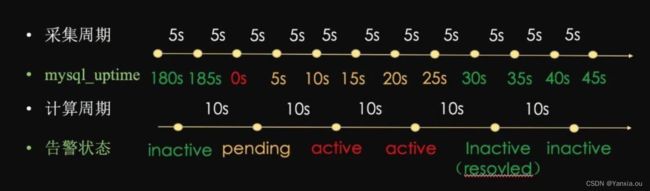
流程描述:
1.Prometheus以5s(scrape_interval)一个采集周期采集状态;
2.根据采集到状态按照10s(evaluation_interval)一个计算周期,计算表达式;
3.表达式为真,告警状态切换到pending;
4.下个计算周期,表达式仍为真,且符合for持续10s,告警状态变更为active, 并将告警从Prometheus发送给alert-manager;
5.下个计算周期,表达式仍为真,且符合for持续10s,持续发送告警给alert-manager。
5. 告警解除
5.1 对startsAt和endsAt的处理
1、两者都存在:不做处理
2、两者都未指定:startsAt指定为当前时间,endsAt为当前时间加上告警持续时间,默认为5分钟
3、只指定startsAt:endsAt指定为当前时间加上默认的告警持续时间
4、只指定endsAt:将startsAt设置为endsAt
即:如果 endsAt 没有提供,则自动等于 startsAt + resolve_timeout(默认 5m)
AlertManager一般以当前时间和告警实例的endsAt字段进行比较用以判断告警的状态:
* 若当前时间位于endsAt之前,则表示告警仍然处于触发状态(firing)
* 若当前时间位于endsAt之后,则表示告警已经消除(resolved)
Prometheus 需要 持续 地将 Firing 告警发送给 Alertmanager,遇到以下一种情况,Alertmanager 会认为告警已经解决,发送一个 resolved:
* Prometheus 发送了 Inactive 的消息给 Alertmanager,即 endsAt=当前时间
* Prometheus 在上一次消息的 endsAt 之前,一直没有发送任何消息给 Alertmanager
当告警没有再此触发时,多久后发送恢复的时间由什么因素决定:告警的endAt来决定。
告警的endAt默认情况下prometheus会设置为以下值来决定:
ts + max([check_interval], [resend_delay]) * 4
resendDelay,是程序启动参数 --rules.alert.resend-delay 规定的,默认 1m
interval,是我们配置的采集间隔
如果收到的告警里没有设置endAt,那么alertmanager设置endAt为以下值来决定:
now + resolve_timeout
即:对活跃告警的默认恢复时间决定为:如果发送方(prometheus等)指定了endAt,则以发送方为准,否则alertmanger统一设置为now + resolve_timeout,即一条告警等待了resolve_timeout还没收到新的告警内容,则视为恢复
5.2 Prometheus告警解除后持续多久重复推送告警解除通知??
模拟告警解除过程,配置10分钟评估等待时长,
prometheus实际告警解除时间:2023-12-26 16:44:23.995
告警记录的告警解除时间:2023-12-26 16:54:49
prometheus停止推送告警解除通知:2023-12-26 16:58:23.995
结论:Prometheus告警解除后持续12分钟重复推送告警解除通知(间隔2分钟推送一次)