【迁移学习论文五】Generate To Adapt Aligning Domains using Generative Adversarial Networks论文原理及复现工作
Generate To Adapt: Aligning Domains using Generative Adversarial Networks 生成适应:使用生成对抗网络对齐域
前言
- 好久没有更新了,开始记录下来,也好督促自己。
- 记录本人预备研究生阶段相关迁移学习论文的原理阐述以及复现工作。
问题
文章介绍
- 这篇文章于2018年发表在CVPR,作者是Swami Sankaranarayanan,Yogesh Balaji,Carlos D. Castillo,Rama Chellappa。
- 联合特征空间:通过模型学习到的源域和目标域之间共享的特征表示,在源域和目标域之间有较好的对齐,以便更好的进行迁移。
- 这篇文章的主要贡献是提出了一个能够直接学习联合特征空间的对抗图像生成的无监督领域自适应方法。该方法与之前方法相比的独特之处在于,同时使用了生成式和判别式两种思想,利用图像生成的对抗过程学习一个源域和目标域特征分布最小化的特征空间。
- 提出了一种对抗性图像生成方法,使用源域标记数据和来自目标未标记数据直接学习共享特征嵌入。
- 生成器 G 负责生成类似于源域数据的“假”数据,希望这些数据能够与真实的源域数据相似。鉴别器 D 的任务是辨别生成的数据是真实的还是伪造的。而特征提取器 F 的目标是学习一个能够同时适应源域和目标域的特征表示,使得经过 F 提取的特征能够更好地用于任务,同时也使得生成的数据更加接近真实数据,这样鉴别器就难以将其区分开来。
模型结构
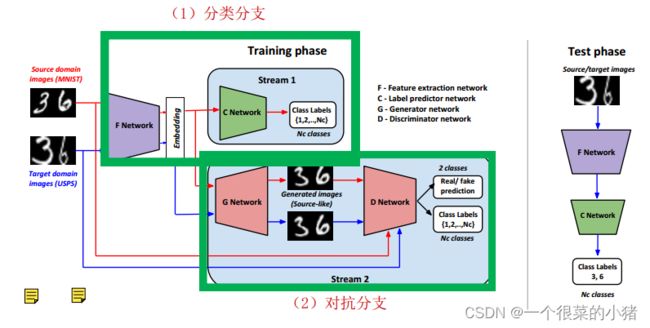
组件作用总论
- 上图中F是特征提取器,C是分类器,G是生成器,D是鉴别器。F用于提取源域和目标域图像特征,C用于源域数据标签的预测,G用于生成混淆视听的生成数据,D用于鉴别真实数据和生成数据。
- 模型总共分为两个支流:
- 标签预测网络(源域数据的处理):源域数据经过F得到特征,然后输入到C中进行分类,并计算交叉熵分类损失。
- 生成对抗网络(迁移学习和域适应):G用于生成数据混淆D的鉴别任务。G生成器通过对提取的源域数据特征进行处理(转置卷积,标签为0),产生与源域类似但不完全相同的数据,这些生成的数据被用作迁移学习中的混淆数据,G计算这些源域生成数据投入到D后的域分类损失和标签分类损失;D用于鉴别,区分真实数据和生成数据,它计算三个损失,首先是源域真实数据直接投入到D,计算域分类损失和标签分类损失,然后是G提取到的目标域生成数据投入到D计算的域分类损失。最后是G提取到的源域生成数据投入到D计算的域分类损失。
特征提取器F
-
源域真实数据分类损失最小化: 使 F 学习到更适合源域真实数据的特征表示
-
源域生成数据分类损失最小化: 使 F 能够理解并学习到源域生成数据的特征
-
让D误以为目标域生成数据为真: 使生成的数据更加适应目标域,混淆鉴别器D
-
源域真实数据标签分类损失:
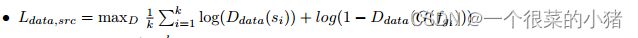
-
源域生成数据标签分类损失:
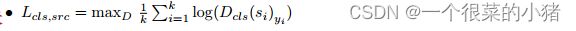
-
目标域生成数据域分类损失(为了混淆,所以域标签为1):
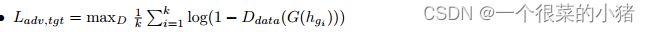
-
这些损失函数的设计和优化目的是通过调整特征提取器 F 的参数,使其能够更好地适应源域数据和目标域数据,从而实现更好的域自适应和迁移学习效果,只有直接使用源域数据的源域真实数据域分类损失是与F无关的。
鉴别器D
通过训练判定不同类型数据的真实性和分类信息。这些数据包括源域中的真实数据、生成器G生成的假数据以及目标域生成的假数据。
- 判定源域生成数据是否假,通过源域生成数据的域分类损失来学习,这些数据的域标签被设定为0(表示假数据)。
- 判定源域真实数据是否真,分类误差最小化——源域真实数据域分类损失(真,域标签为1)+源域真实数据标签分类损失
- 判定目标域生成数据是否假——目标域生成数据域分类损失(假,域标签为0)
生成器G
通过对抗训练与鉴别器D竞争,并促进特征提取器F的学习。
- 欺骗鉴别器D:让D误以为源域生成数据为真——源域生成数据域分类损失(为了混淆,所以域标签为1)
- 源域生成数据分类误差最小化——源域生成数据标签分类损失
分类器C
源域真实数据分类误差最小化:源域真实数据分类损失(上面提到的鉴别器中的分类损失与分类器C的参数是不共享的,也就是说是两个意义相同但参数不同的分类器,鉴别器中有一个小分类器用于自己使用而不是使用C来计算源域真实数据分类损失)
警告
从上面对特征提取器的介绍可以看出,这篇论文中的各个组件的反向传播是独立的,很多loss都涉及到了F,但是F的反向传播只与上述三个损失有关,其他损失更新参数的时候不会更新F的参数。也就是说我们在写代码设计模型的时候要把上述四个组件分开写,分别进行反向传播。
模型的目标
通过F提取的特征图使源域和目标域的同类数据特征分布越相似,从而提高测试精度。F(src)和F(tar)对G来说是类似的,这意味着参数调整是偏向于使得F(src)和F(tar)相近,这是模型优化的目标。
代码
import torch
import torch.nn as nn
from torch.autograd import Variable
"""
生成器G
"""
class _netG(nn.Module):
def __init__(self, opt, nclasses):
super(_netG, self).__init__()
self.ndim = 2 * opt.ndf
self.ngf = opt.ngf
self.nz = opt.nz
self.gpu = opt.gpu
self.nclasses = nclasses
# 定义生成器的主要神经网络结构
self.main = nn.Sequential(
nn.ConvTranspose2d(self.nz + self.ndim + nclasses + 1, self.ngf * 8, 2, 1, 0, bias=False),
nn.BatchNorm2d(self.ngf * 8),
nn.ReLU(True),
nn.ConvTranspose2d(self.ngf * 8, self.ngf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.ngf * 4),
nn.ReLU(True),
nn.ConvTranspose2d(self.ngf * 4, self.ngf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.ngf * 2),
nn.ReLU(True),
nn.ConvTranspose2d(self.ngf * 2, self.ngf, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.ngf),
nn.ReLU(True),
nn.ConvTranspose2d(self.ngf, 3, 4, 2, 1, bias=False),
nn.Tanh()
)
def forward(self, input):
batchSize = input.size()[0]
input = input.view(-1, self.ndim + self.nclasses + 1, 1, 1)
noise = torch.FloatTensor(batchSize, self.nz, 1, 1).normal_(0, 1)
if self.gpu >= 0:
noise = noise.cuda()
noisev = Variable(noise)
output = self.main(torch.cat((input, noisev), 1))
return output
"""
鉴别器D
"""
class _netD(nn.Module):
def __init__(self, opt, nclasses):
super(_netD, self).__init__()
self.ndf = opt.ndf
self.feature = nn.Sequential(
nn.Conv2d(3, self.ndf, 3, 1, 1),
nn.BatchNorm2d(self.ndf),
nn.LeakyReLU(0.2, inplace=True),
nn.MaxPool2d(2, 2),
nn.Conv2d(self.ndf, self.ndf * 2, 3, 1, 1),
nn.BatchNorm2d(self.ndf * 2),
nn.LeakyReLU(0.2, inplace=True),
nn.MaxPool2d(2, 2),
nn.Conv2d(self.ndf * 2, self.ndf * 4, 3, 1, 1),
nn.BatchNorm2d(self.ndf * 4),
nn.LeakyReLU(0.2, inplace=True),
nn.MaxPool2d(2, 2),
nn.Conv2d(self.ndf * 4, self.ndf * 2, 3, 1, 1),
nn.BatchNorm2d(self.ndf * 2),
nn.LeakyReLU(0.2, inplace=True),
nn.MaxPool2d(4, 4)
)
self.classifier_c = nn.Sequential(nn.Linear(self.ndf * 2, nclasses))
self.classifier_s = nn.Sequential(
nn.Linear(self.ndf * 2, 1),
nn.Sigmoid())
def forward(self, input):
output = self.feature(input)
output_s = self.classifier_s(output.view(-1, self.ndf * 2))
output_s = output_s.view(-1)
output_c = self.classifier_c(output.view(-1, self.ndf * 2))
return output_s, output_c
"""
特征提取器F
"""
class _netF(nn.Module):
def __init__(self, opt):
super(_netF, self).__init__()
self.ndf = opt.ndf
self.feature = nn.Sequential(
nn.Conv2d(3, self.ndf, 5, 1, 0),
nn.ReLU(inplace=True),
nn.MaxPool2d(2, 2),
nn.Conv2d(self.ndf, self.ndf, 5, 1, 0),
nn.ReLU(inplace=True),
nn.MaxPool2d(2, 2),
nn.Conv2d(self.ndf, self.ndf * 2, 5, 1, 0),
nn.ReLU(inplace=True)
)
def forward(self, input):
output = self.feature(input)
return output.view(-1, 2 * self.ndf)
"""
分类器C
"""
class _netC(nn.Module):
def __init__(self, opt, nclasses):
super(_netC, self).__init__()
self.ndf = opt.ndf
self.main = nn.Sequential(
nn.Linear(2 * self.ndf, 2 * self.ndf),
nn.ReLU(inplace=True),
nn.Linear(2 * self.ndf, nclasses),
)
def forward(self, input):
output = self.main(input)
return output