Spark内容分享(二十二):eBay最佳实践:Spark SQL优化之物化视图
目录
背 景
什么是物化视图?
物化视图的实现
概览
MV Optimizer的实现
验证部分
重写部分
物化视图应用场景及收益
应用场景:物化视图重写普通视图
应用场景:物化视图重定义表结构
物化视图应用收益
总结及后续计划
背 景
Carmel是eBay内部基于Apache Spark打造的一款SQL-on-Hadoop查询引擎。通过对Apache Spark的改进,eBay Carmel团队为用户提供了一套高可用高性能的服务,用以满足eBay内部大量的分析型查询需求。如今单日查询量已超过40万。
近年来,eBay Carmel开发团队一直致力于改进Spark SQL的查询性能,如各类Join场景的优化,数据倾斜的优化等等。基于内部的SQL信息收集系统,我们发现不同的SQL存在大量的重复数据访问,比如,相同视图的重复访问。对于这类问题,业界早已有了物化视图这一方案,用来预计算需要重复访问的数据,以此降低访问延迟及资源消耗。本文将详细介绍如何在Spark SQL实现物化视图及在eBay的相关实践。
什么是物化视图?
物化视图主要用于预先计算并保存表连接或聚合等耗时较多的操作的结果,在执行查询时,就可以避免进行这些耗时的操作,从而快速得到结果。物化视图使用Logical Plan重写机制,不需要修改原有的查询语句,引擎自动选择合适的物化视图进行Plan重写,完全对原始SQL透明。它和视图的区别在于,视图只是存储SQL语句,而物化视图相当于存储了SQL语句的表。使用物化视图的基本流程为:
-
创建物化视图
-
SQL查询
-
基于物化视图,重写SQL对应的Logical Plan,生成新的Logical Plan
-
基于新的Logical Plan进行查询
下图展示了物化视图的使用流程,user,item,users_items是3张表,先创建物化视图mv,使用SQL查询时,将基于mv对SQL生成的Logical Plan进行重写,生成新的基于物化视图的Plan,再进行查询。在这个例子中可以看到,在最终生成的Plan里,消除了所有的join操作,将3表join查询转换成了单表查询。对于大数据查询引擎来说,大表join将会产生shuffle过程,是造成查询缓慢的瓶颈之一,这种转换将极大的提升查询效率,并减少查询时资源的消耗。

传统数据库,如Oracle,MSSQL Server等都已经支持物化视图。在大数据领域里,SnowFlake(企业版),StarRocks,Hive等等也都具备了该特性。Spark社区从2019年已经开始对该特性进行了讨论,但目前还没有相关的实现,涉及到的Issue如下:
-
SPARK-29038:SPIP: Support Spark Materialized View
-
SPARK-26764:[SPIP] Spark Relational Cache
-
SPARK-29059: [SPIP] Support for Hive Materialized Views in Spark SQL
基于eBay生产上的SQL,数据的重复访问场景较多,物化视图在降本增效方面预期会产生较大的收益,所以决定基于Spark实现该功能,并希望具备的基本特性如下:
-
支持对View生成物化视图,并能将View重写为物化视图。
-
支持多表Join场景,及多种Join类型(Inner Join, Left Join)。
-
实时感知到原表数据发生变化。
-
能验证重写后的Logical Plan是否正确。
物化视图的实现
概览
下图是物化视图工作的整体流程(基于Hive Metastore及HDFS),其中包含了最重要的2个实现模块,MV Optimizer和MV Cache Manager。其中MV Optimizer会基于已有的物化视图尝试重写用户SQL生成的Logical Plan,而MV Cache Manager主要用来缓存物化视图元数据供MV Optimizer使用。

物化视图整体工作流程如下:
-
基于定时任务,定期刷新物化视图。
-
MV Cache Manager定时获取最新的物化视图元数据并缓存。
-
用户提交SQL并生成优化后的Logical Plan。
-
MV Optimizer获取物化视图,对优化后的Logical Plan进行重写。
-
对重写后的Logical Plan进行数据校验
-
校验成功后,对重写后的Logical Plan进行优化并执行。
MV Optimizer的实现
MV Optimizer模块包含了物化视图中最核心的Logical Plan重写逻辑。基于参考资料[1],在重写逻辑的实现过程中主要考虑了2个方面:
-
物化视图的数据是否包含用户SQL所要查询的数据?
-
用户SQL的相关表达式是否能用物化视图的输出列替换?
为了满足上述的两个条件,重写逻辑的实现上又分为了2部分:验证部分和重写部分。
验证部分
该部分主要用来比对用户SQL的Logical Plan和物化视图的Logical Plan的相关信息,判断是否可以被重写,主要流程有:
-
判断原始Logical Plan格式是否被支持,目前仅SPJG (Select-Project-Join-GroupBy)格式的Logical Plan可以被重写。
-
判断原始Logical Plan的相关表达式是否能被物化视图的输出列替换。
-
比较Join信息,包括Join的表,Join的类型等。
-
比较Filter信息,如where语句里的条件,join语句里的条件。
-
比较GroupBy信息。
重写部分
该部分会基于物化视图重写Logical Plan,主要的逻辑有:
-
将查询的表替换为物化视图。
-
在Join场景下,添加补偿表,如,用户SQL包含T1,T2,T3这3张表join,而物化视图仅包含T1,T2,则在最终的重写结果里需要添加T3。
-
在Group场景下,添加补偿列,如,用户SQL包含group by c1,而物化视图包含group by c1,c2,则在最终重写的结果里需要添加group by c1。
-
在Filter场景下,添加补偿条件,如,用户SQL包含where c1 > 1,而物化视图包含where c1 >0,则在最终重写的结果里需要添加where c1 > 1。
-
用物化视图的输出列替换用户SQL的相关列。
在MV Optimizer模块的实现过程中,基本思路是从Logical Plan里获取相关信息,然后进行判断及比对,最终进行重写,下图简单展示了如何基于Logical Plan获取需要的信息:

为了节省篇幅,该模块整体的实现细节就不再进一步说明了,下面举几个例子来介绍下实现中需要考虑到的场景:
-
列等场景:基于用户SQL或物化视图,在重写的时候需要考虑到列相等的情况,避免重写失败。
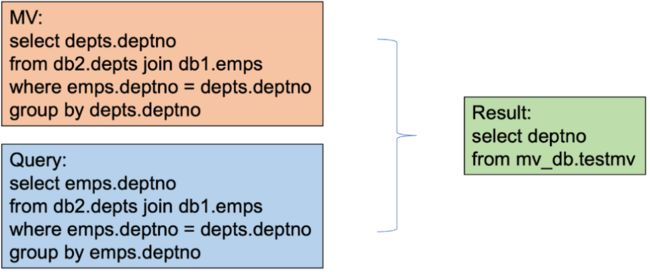
-
Filter场景:当物化视图的Filter条件范围大于用户SQL时,需要在重写时添加补偿条件。

-
表达式支持:物化视图支持使用表达式,并能在重写的过程中整体替换。

-
Join场景:添加补偿表(上文已有描述)

-
Group场景:添加补偿列(上文已有描述)
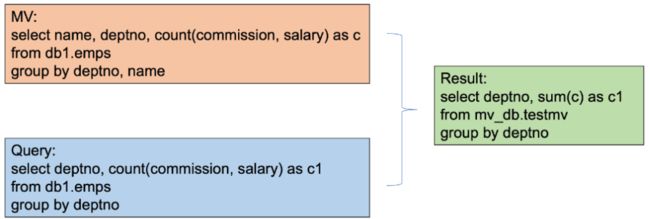
MV Cache Manager的实现
该模块用来管理及缓存物化视图,便于MV Optimizer能更快的找到合适的物化视图,下图展示了该模块的缓存信息及相关接口:

实现过程中需要考虑的场景如下:
-
哪些信息需要缓存,包括,物化视图包含的表名,物化视图的Logical Plan等,这些缓存信息会用来判断物化视图的数据是否为最新的,还能提供可重用的Logical Plan,避免性能损耗。
-
定时和Metastore交互,更新物化视图的缓存。
-
提供接口,基于HDFS的文件信息,用来判断物化视图的数据是否为最新的。
物化视图应用场景及收益
由于eBay内部对于用户SQL的使用模式,有较为完善的监控及统计,比如,视图的使用状况,非Parition表的使用状况等。下文所有描述的物化视图的落地场景,都是基于这些统计信息,简单来说,物化视图的收益大小取决于数据的重用次数,而完善的统计信息能让我们更直观的判断该如何创建物化视图,从而获取更多的收益。
应用场景:物化视图重写普通视图
视图在日常工作中使用非常频繁,通过对视图的监控发现,有部分消耗较多资源的视图会被反复使用,用物化视图重写的话会取得较大收益。下图展示了查询语句 select * from view 的原始Logical Plan和使用物化视图重写后的Logical Plan:

可以看到,视图里的多表Join已经被重写为单表查询,在实际应用中减少了文件读取和Shuffle阶段,降低资源使用的同时还提升了SQL的查询效率。基于例行SQL任务,下图展示了在物化视图生效后(标记为蓝色及之后的统计信息),计算资源的使用和SQL的执行时间都有了提升。

应用场景:物化视图重定义表结构
通过对全表扫描的监控发现,有很多非partition/bucket的大表( > 1TB)会被反复使用,再基于使用方式进一步分析,这类表被转换成partition/bucket表会有较大收益,如,partition表能支持分区裁剪,减少数据扫描,bucket表能减少Shuffle次数等。由于表的数据生成涉及到上下游的任务改造,所以推动起来比较耗时,所以我们尝试将这类表做成物化视图。一方面可以在任务改造未完成前提升SQL的性能,另一方面也能根据执行结果验证SQL的改造方案。下图是在该场景下使用物化视图后的收益举例。

物化视图应用收益
目前eBay内部落地的物化视图都是基于上述两个场景,对于普通视图来说,判断是否需要创建物化视图的依据较为简单,是否包含Join/GroupBy语句,Shuffle次数是否较多等,都可以基于物化视图获取收益。而对于非partition/bucket的大表,需要对历史SQL进行分析,包括各个列在Join/Filter/GroupBy语句中的使用情况,在这个基础上创建的物化视图会获取更大的收益。
下图是某个队列在不断增加物化视图后的整体资源消耗趋势,可以看到7/8月的数据相比之前有20%左右的节省。
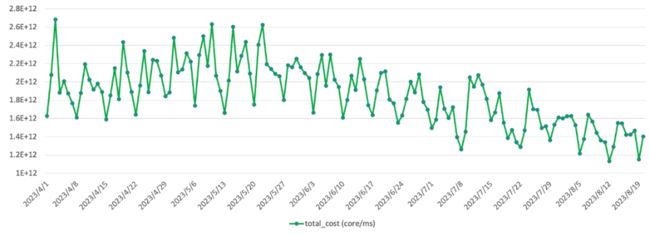
资源消耗降低的同时,该队列SQL的整体响应时间也得到了20%左右的提升,如下图:
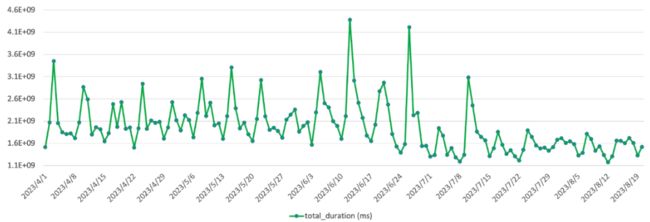
再观察下85分位和95分位的SQL响应时间,提升也在20%左右,如下图:
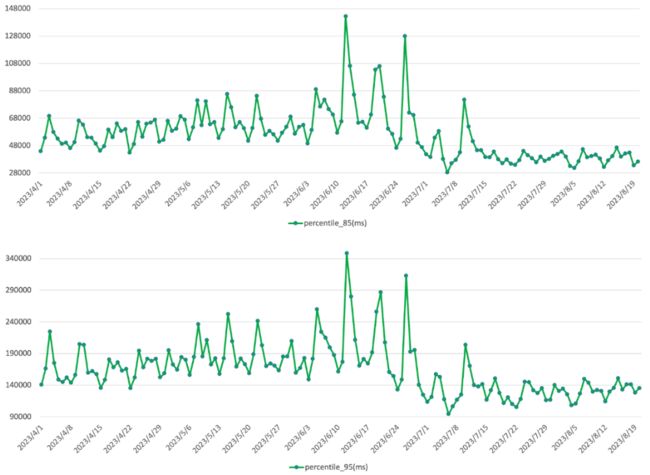
总的来说,不论是单个SQL还是集群整体状况,基于物化视图优化后,性能都有明显提升,基本满足我们对于该功能在降本增效方面的预期。
总结及后续计划
本文介绍了物化视图的基本原理及Spark SQL物化视图的实现。通过介绍了eBay内部的落地实践及效果,说明了在数据重复访问的场景下,这类预计算功能在降本增效方面有较大的收益,对于Spark SQL是个有力的补充。
对于物化视图功能本身来说,目前还有很多场景不能支持,比如,同表自Join,多物化视图的选择等,完善匹配逻辑,适配更多场景将是功能优化的下一步目标。
为了创建更多的物化视图,需要持续优化SQL统计信息,基于历史信息,甚至和AI联动,能自动推荐合理的物化视图,使得集群的各类资源的消耗能进一步降低。
eBay长期在Spark社区中贡献各类PR,对于物化视图,我们依然计划和社区加强沟通,希望能将该功能开源并回馈到社区。