【本地缓存篇】LFU、LRU 等缓存失效算法

LFU、LRU 等缓存失效算法
- ✔️ 解析
- ✔️FIFO
- ✔️LRU
- ✔️LFU
- ✔️W-TinyLFU
✔️ 解析
缓存失效算法主要是进行缓存失效的,当缓存中的存储的对象过多时,需要通过一定的算法选择出需要被淘汰的对象,一个好的算法对缓存的命中率影响是巨大的。常见的缓存失效算法有FIFO、LRU、LFU,以及Caffeine中的Window TinyLFU算法。
✔️FIFO
FIFO 算法是一种比较容易实现也最容易理解的算法。它的主要思想就是和队列是一样的,即先进先出(First in First Out)。
一般认为一个数据是最先进入的,那么可以认为在将来它被访问的可能性很小。
因为FIFO刚好符合队列的特性,所以通常FIFO的算法都是使用队列来实现的:
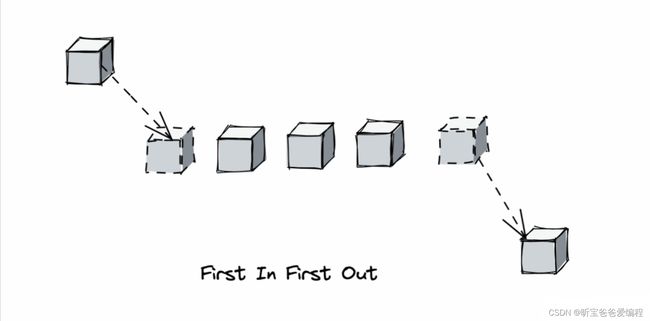
1 . 新数据插入到队列尾部,数据在队列中顺序移动
2 . 淘汰队列头部的数据
Code.1:
/**
* FIFO算法实现Demo,使用一个自定义的Node类来表示队列中的元素
*/
class Node {
int data;
Node next;
Node(int data) {
this.data = data;
this.next = null;
}
}
public class ComplexFIFOQueue {
private Node head;
private Node tail;
private int size;
public ComplexFIFOQueue() {
head = null;
tail = null;
size = 0;
}
// 入队操作
public void enqueue(int item) {
Node newNode = new Node(item);
if (tail == null) {
head = newNode;
tail = newNode;
} else {
tail.next = newNode;
tail = newNode;
}
size++;
}
// 出队操作
public int dequeue() {
if (head == null) {
return -1; // 队列为空,返回一个特殊值表示错误
} else {
int item = head.data;
head = head.next;
size--;
return item;
}
}
// 查看队首元素
public int peek() {
if (head == null) {
return -1; // 队列为空,返回一个特殊值表示错误
} else {
return head.data;
}
}
// 检查队列是否为空
public boolean isEmpty() {
return head == null;
}
// 获取队列大小
public int size() {
return size;
}
}
一个自定义的Node类来表示队列中的每个元素。每个节点都有一个数据字段和一个指向下一个节点的指针。我们还增加了一些其他方法,例如检查队列是否为空,获取队列大小等。这使得FIFO算法的实现更加完整和复杂。
✔️LRU
LRU (The Least Recently Used,最近最少使用)是一种常见的缓存算法,在很多分布式缓存系统(如RedisMemcached)中都有广泛使用。
LRU算法的思想是:如果一个数据在最近一段时间没有被访问到,那么可以认为在将来它被访问的可能性也很小因此,当空间满时,最久没有访问的数据最先被淘汰。
最堂见的实现是使用一个链表保存缓存数据,详细算法实现如下:
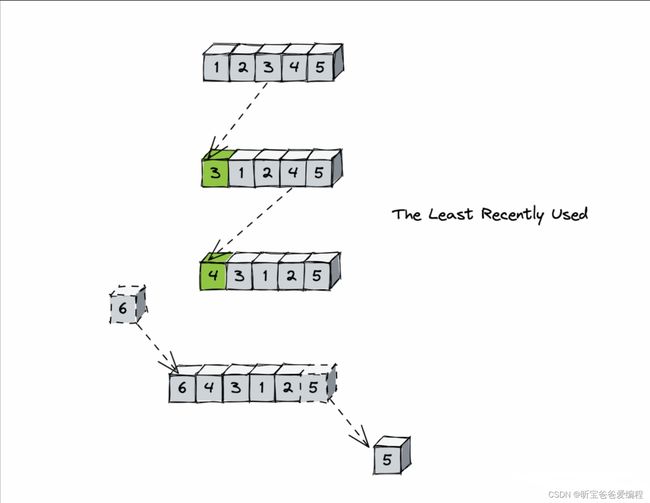
1 . 新数据插入到链表头部
2 . 每当缓存命中,则将数据移到链表头部
3 . 当链表满时,将链表尾部的数据丢失
Code.2:
import java.util.HashMap;
import java.util.Map;
/**
* LRU算法实现Demo,使用双向链表和哈希表来存储缓存数据,并支持动态调整缓存大小
*/
public class ComplexLRUCache<K, V> {
private static final int DEFAULT_INITIAL_CAPACITY = 4;
private static final float DEFAULT_LOAD_FACTOR = 0.75f;
private final int capacity;
private final Map<K, Node<K, V>> cacheMap;
private final Node<K, V> head;
private final Node<K, V> tail;
private static class Node<K, V> {
K key;
V value;
Node<K, V> prev;
Node<K, V> next;
Node(K key, V value) {
this.key = key;
this.value = value;
}
}
public ComplexLRUCache(int capacity) {
this.capacity = capacity;
this.cacheMap = new HashMap<>(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
this.head = new Node<>(null, null);
this.tail = new Node<>(null, null);
head.next = tail;
tail.prev = head;
}
public synchronized V get(K key) {
Node<K, V> node = cacheMap.get(key);
if (node == null) {
return null;
}
moveToHead(node);
return node.value;
}
public synchronized void put(K key, V value) {
Node<K, V> node = cacheMap.get(key);
if (node == null) {
if (cacheMap.size() >= capacity) {
evict(); // 缓存已满,删除最老的数据(即尾部数据)
}
node = new Node<>(key, value); // 创建新节点并添加到头部
cacheMap.put(key, node); // 将新节点添加到哈希表中
addToHead(node); // 将新节点添加到双向链表头部(表示最近使用)
} else { // 更新节点值并移动到头部(表示最近使用)
node.value = value;
moveToHead(node);
}
}
private void addToHead(Node<K, V> node) {
node.prev = head;
node.next = head.next;
head.next.prev = node;
head.next = node;
}
private void moveToHead(Node<K, V> node) {
removeNode(node); // 先从链表中移除该节点(防止出现循环引用)
addToHead(node); // 再将节点添加到链表头部(表示最近使用)
}
private void removeNode(Node<K, V> node) {
node.prev.next = node.next; // 将当前节点从链表中移除(前驱节点的后继指向当前节点的后继)
node.next.prev = node.prev; // 将当前节点从链表中移除(后继节点的前驱指向当前节点的后继的前驱)
}
private void evict() { // 删除最老的数据(即尾部数据)并从哈希表中删除该节点引用(防止出现循环引用)
Node<K, V> tailNode = tail.prev; // 获取尾部节点的前驱节点(即最老的数据)
removeNode(tailNode); // 从链表中移除该节点(前驱节点的后继指向当前节点的后继)和从哈希表中删除该节点引用(防止出现循环引用)
cacheMap.remove(tailNode.key); // 从哈希表中删除该键的引用(防止出现循环引用)
}
}
✔️LFU
LFU (Least Frequently Used ,最近最不常用)也是 种常见的缓存算法。
顾名思义,LFU算法的思想是:如果一个数据在最近一段时间很少被访问到,那么可以认为在将来它被访问的可能性也很小。因此,当空间满时,最小频率访问的数据最先被淘汰。
LFU的每个数据块都有一个引用计数,所有数据块按照引用计数排序,具有相同引用计数的数据块则按照时间排
序。
具体实现如下:

1 . 新加入数据插入到队列尾部 (因为引用计数为1)
2 . 队列中的数据被访问后,引用计数增加,队列重新排序
3 . 当需要淘汰数据时,将已经排序的列表最后的数据块删除
Code.3
import java.util.*;
/**
* LFUCache实现Demo,包括删除和更新操作
*/
public class LFUCache<K, V> {
private static final int DEFAULT_INITIAL_CAPACITY = 4;
private static final float DEFAULT_LOAD_FACTOR = 0.75f;
private final int capacity;
private final Map<K, Node<K, V>> cacheMap;
private final Map<K, Integer> accessCountMap;
private final Deque<Node<K, V>> deque;
private static class Node<K, V> {
K key;
V value;
int count;
Node<K, V> prev;
Node<K, V> next;
Node(K key, V value, int count) {
this.key = key;
this.value = value;
this.count = count;
}
}
public LFUCache(int capacity) {
this.capacity = capacity;
this.cacheMap = new HashMap<>(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
this.accessCountMap = new HashMap<>();
this.deque = new LinkedList<>();
}
public synchronized V get(K key) {
Node<K, V> node = cacheMap.get(key);
if (node == null) {
return null;
}
updateAccessCount(node); // 更新访问次数
moveToHead(node); // 移动到头部(表示最近使用)
return node.value;
}
public synchronized void put(K key, V value) {
Node<K, V> node = cacheMap.get(key);
if (node == null) { // 新增节点(不存在该键)
if (cacheMap.size() >= capacity) { // 缓存已满,删除最少使用的数据(即尾部数据)
evict(); // 删除最少使用的数据(即尾部数据)并从哈希表中删除该节点引用(防止出现循环引用)和从访问次数映射中删除该键的引用(防止出现循环引用)
}
node = new Node<>(key, value, 1); // 创建新节点并设置访问次数为1,表示首次访问该键的数据(即新增数据)
/** 将新节点添加到哈希表中,并将该键与节点引用的映射关系保存到访问次数映射中,
以便快速获取节点引用和更新节点引用指向链表中的位置(头部)和访问次数(最近使用)等信息。
同时,将新节点添加到链表头部(表示最近使用)和从哈希表中删除该键的引用(防止出现循环引用)。
*/
cacheMap.put(key, node);
}
}
✔️W-TinyLFU
LFU 通常能带来最佳的缓存命中率,但 LFU 有两个缺点:
1 . 它需要给每个记录项维护频率信息,每次访问都需要更新,需要一个巨大的空间记录所有出现过的 key 和其对应的频次;
2 ,如果数据访问模式随时间有变,LFU 的频率信息无法随之变化,因此早先频繁访问的记录可能会占据缓存而后期访问较多的记录则无法被命中;
3 . 如果一个刚加入缓存的元素,它的频率并不高,那么它可能会会直接被淘汰。
其中第一点过于致命导致我们通常不会使用 LFU。我们最常用的 LRU 实现简单,内存占用低,但其并不能反馈访问频率。LFU 通常需要较大的空间才能保证较好的缓存命中率。
W-TinyLFU是一种高效的缓存淘汰算法,它是TinyLFU算法的一种改进版本,主要用于处理大规模缓存系统中的淘汰问题。W-TinyLFU的核心思想是基于窗口的近似最少使用算法,即根据数据的访问模式动态地调整缓存中教据的淘汰策略。W-TinyLFU 综合了LRU和LFU的长处: 高命中率、低内存占用。
W-TinyLFU由多个部分组合而成,包括窗口缓存、过滤器和主缓存。
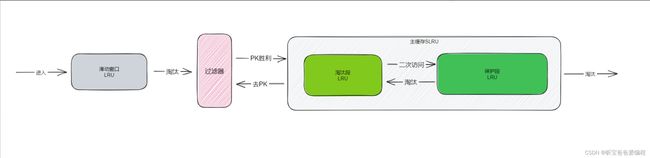
使用LRU来作为一个窗口缓存,主要是让元素能够有机会在窗口缓存中去积累它的频率,避免因为频率很低而直接被淘汰。
主缓存是使用SLRU,元素刚进入W-TinyLFU会在窗口缓存暂留一会,被挤出窗口缓存时,会在过滤器中和主缓存中最容易被淘汰的元素进行PK,如果频率大于主缓存中这个最容易被淘汰的元素,才能进入主缓存。
Code .4:
import java.util.*;
public class WTLFUCache<K, V> {
private static final int DEFAULT_INITIAL_CAPACITY = 4;
private static final float DEFAULT_LOAD_FACTOR = 0.75f;
private final int capacity;
private final Map<K, Node<K, V>> cacheMap;
private final Map<K, Integer> accessCountMap;
private final Deque<Node<K, V>> deque;
private final Map<K, Integer> weightMap;
private int totalWeight;
private static class Node<K, V> {
K key;
V value;
int count;
int weight;
Node<K, V> prev;
Node<K, V> next;
Node(K key, V value, int count, int weight) {
this.key = key;
this.value = value;
this.count = count;
this.weight = weight;
}
}
public WTLFUCache(int capacity) {
this.capacity = capacity;
this.cacheMap = new HashMap<>(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
this.accessCountMap = new HashMap<>();
this.deque = new LinkedList<>();
this.weightMap = new HashMap<>();
this.totalWeight = 0;
}
public synchronized V get(K key) {
Node<K, V> node = cacheMap.get(key);
if (node == null) {
return null;
}
updateAccessCount(node); // 更新访问次数和权重计数器
moveToHead(node); // 移动到头部(表示最近使用)
return node.value;
}
public synchronized void put(K key, V value) {
Node<K, V> node = cacheMap.get(key);
if (node == null) { // 新增节点(不存在该键)
if (cacheMap.size() >= capacity) { // 缓存已满,删除最少使用的数据(即尾部数据)
evict(); // 删除最少使用的数据
}
//
}
}