linux内核block层Multi queue多队列核心点分析
内核块设备层单队列时代,我们IO传输的底层函数是从submit_bio开始: submit_bio->generic_make_request-> blk_queue_bio。如果看过相关源码,会发现经常用到q->queue_lock自旋锁,在IO发送过程、IO传输完成、IO合并都有。多核多进程IO传输时,会在q->queue_lock锁上自旋等待浪费不少时间,内核引入Multi queue多队列架构应该就是为了解决这个问题。
Multi queue多队列架构主要有两个数据结构:每个CPU独有的软件队列、一定数目的硬件队列,多核多进程IO传输时,每个进程在它所属的CPU的软件队列上进行锁操作,避免多核之间竞争锁,提高了传输效率。初涉该块代码时觉得很神奇,具体软件实现原理是什么?最近研究了一下Multi queue多队列内核代码,写这个文章做个总结,有描述出错的地方请指出。
单队列架构涉及的数据结构其实不多,大多是对struct bio和struct request的分分合合处理,发起IO传输的核心函数是blk_queue_bio()。Multi queue多队列核心IO传输函数是blk_mq_make_request()。Multi queue多队列架构引入了struct blk_mq_tag_set、struct blk_mq_tag、struct blk_mq_hw_ctx、struct blk_mq_ctx等数据结构。最初阅读这些代码时,感觉比单队列复杂多了,很容易绕晕。
1:struct blk_mq_ctx代表每个CPU独有的软件队列;
2:struct blk_mq_hw_ctx代表硬件队列,块设备至少有一个;
3:struct blk_mq_tag每个硬件队列结构struct blk_mq_hw_ctx对应一个;
4:struct blk_mq_tag主要是管理struct request(下文简称req)的分配。struct request大家应该都比较熟悉了,单队列时代就存在,IO传输的最后都要把bio转换成request;
5:struct blk_mq_tag_set包含了块设备的硬件配置信息,比如支持的硬件队列数nr_hw_queues、队列深度queue_depth等,在块设备驱动初始化时多处使用blk_mq_tag_set初始化其他成员;
每个CPU对应唯一的软件队列blk_mq_ctx,blk_mq_ctx对应唯一的硬件队列blk_mq_hw_ctx,blk_mq_hw_ctx对应唯一的blk_mq_tag,三者的关系在后续代码分析中多次出现。
本文首先讲解这些数据结构的来源,最后结合blk_mq_make_request()函数重点讲解Multi queue多队列IO发送过程的处理细节。源码基于centos 7.6 内核3.10.0.957.27.2.e17。本文介绍的相关函数,更详细的源码注释见https://github.com/dongzhiyan-stack/kernel-code-comment。
1 多队列块设备驱动初始化
1.1 多队列块设备驱动初始化前半部分
这里找了一下nvme驱动的初始化代码,它用的就是Multi queue多队列架构。先从驱动nvme_probe()-> nvme_dev_add()开始讲解。nvme_dev_add()函数中设置blk_mq_tag_set结构的关键成员;分配设置每个硬件队列独有blk_mq_tag结构;分配并设置struct blk_mq_tag_set *set的set->mq_map[]数组,该数组下标是CPU的编号,数组成员是硬件队列的编号,这样就完成了CPU编号与硬件队列编号的映射等等。下文用多次提到的req是struct request的简称,函数执行流程图如下:
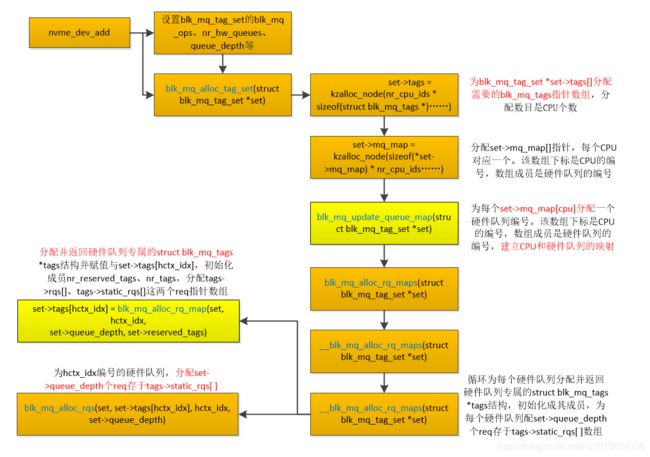
关键源码精简后如下,每个函数的作用都做了详细注释。
static int nvme_dev_add(struct nvme_dev *dev)
{
//设置blk_mq_tag_set的blk_mq_ops为nvme_mq_ops
dev->tagset.ops = &nvme_mq_ops;
//设置硬件队列个数
dev->tagset.nr_hw_queues = dev->online_queues - 1;
dev->tagset.timeout = NVME_IO_TIMEOUT;
dev->tagset.numa_node = dev_to_node(dev->dev);
//设置队列深度
dev->tagset.queue_depth =min_t(int, dev->q_depth, BLK_MQ_MAX_DEPTH) - 1;
dev->tagset.cmd_size = nvme_cmd_size(dev);
dev->tagset.flags = BLK_MQ_F_SHOULD_MERGE;
dev->tagset.driver_data = dev;
//调用blk_mq_alloc_tag_set(),target是struct blk_mq_tag_set tagset
ret = blk_mq_alloc_tag_set(&dev->tagset);
}
int blk_mq_alloc_tag_set(struct blk_mq_tag_set *set)
{
//硬件队列数大于CPU个数,
if (set->nr_hw_queues > nr_cpu_ids)
set->nr_hw_queues = nr_cpu_ids;
//按照CPU个数分配struct blk_mq_tag_set需要的struct blk_mq_tags指针数组,每个CPU都有一个blk_mq_tags
set->tags = kzalloc_node(nr_cpu_ids * sizeof(struct blk_mq_tags *),GFP_KERNEL, set->numa_node);
//分配mq_map[]指针数组,按照CPU的个数分配nr_cpu_ids个unsigned int类型数据,该数组成员对应一个CPU
set->mq_map = kzalloc_node(sizeof(*set->mq_map) * nr_cpu_ids,GFP_KERNEL, set->numa_node);
//为每个set->mq_map[cpu]分配一个硬件队列编号。该数组下标是CPU的编号,数组成员是硬件队列的编号
ret = blk_mq_update_queue_map(set);
/*分配每个硬件队列独有的blk_mq_tags结构,根据硬件队列的深度queue_depth分配对应个数的request存到
struct blk_mq_tags * tags->static_rqs[],并设置blk_mq_tags结构的nr_reserved_tags、nr_tags等其他成员*/
ret = blk_mq_alloc_rq_maps(set);
}
如注释,关键是调用函数blk_mq_alloc_rq_maps()分配每个硬件队列独有的blk_mq_tags结构,并初始化其成员,该函数源码如下
static int blk_mq_alloc_rq_maps(struct blk_mq_tag_set *set)
{
do {
/*分配每个硬件队列独有的blk_mq_tags结构,根据硬件队列的深度queue_depth分配对应个数的request存到
struct blk_mq_tags * tags->static_rqs[],并设置blk_mq_tags结构的nr_reserved_tags、nr_tags等其他成员*/
err = __blk_mq_alloc_rq_maps(set);
if (!err)// __blk_mq_alloc_rq_maps分配成功返回0,这里就直接break了,只循环一次
break;
} while (set->queue_depth);
}
static int __blk_mq_alloc_rq_maps(struct blk_mq_tag_set *set)
{
for (i = 0; i < set->nr_hw_queues; i++)
/*分配每个硬件队列独有的blk_mq_tags结构,根据硬件队列的深度queue_depth分配对应个数的request存到
struct blk_mq_tags * tags->static_rqs[],并设置blk_mq_tags结构的nr_reserved_tags、nr_tags等其他成员*/
if (!__blk_mq_alloc_rq_map(set, i))
goto out_unwind;
}
static bool __blk_mq_alloc_rq_map(struct blk_mq_tag_set *set, int hctx_idx)
{
/*分配并返回硬件队列专属的blk_mq_tags结构,分配设置其成员nr_reserved_tags、nr_tags、rqs、static_rqs。主要
是分配struct blk_mq_tags *tags的tags->rqs[]、tags->static_rqs[]这两个req指针数组。hctx_idx是硬件队列编号,每
一个硬件队列独有一个blk_mq_tags结构*/
set->tags[hctx_idx] = blk_mq_alloc_rq_map(set, hctx_idx,set->queue_depth, set->reserved_tags);
/*针对hctx_idx编号的硬件队列,分配set->queue_depth个req存于tags->static_rqs[i]。具体是分配N个page,将page
的内存一片片分割成req结构大小。然后tags->static_rqs[i]记录每一个req首地址,接着执行磁盘底层驱
动初始化函数,建立request与nvme队列的关系吧*/
ret = blk_mq_alloc_rqs(set, set->tags[hctx_idx], hctx_idx,set->queue_depth);
}
blk_mq_alloc_rq_map()函数只分配struct blk_mq_tags *tags的tags->static_rqs[]这个req指针数组,实际分配req是在blk_mq_alloc_rqs()函数,源码如下。blk_mq_alloc_rqs()函数源码不再列出
struct blk_mq_tags *blk_mq_alloc_rq_map(struct blk_mq_tag_set *set,
unsigned int hctx_idx,// hctx_idx是硬件队列编号
unsigned int nr_tags,//nr_tags是set->queue_depth
unsigned int reserved_tags)
{
//分配一个每个硬件队列结构独有的blk_mq_tags结构,设置其成员nr_reserved_tags和nr_tags,分配
//blk_mq_tags的bitmap_tags、breserved_tags结构
tags = blk_mq_init_tags(nr_tags, reserved_tags,set->numa_node,BLK_MQ_FLAG_TO_ALLOC_POLICY(set->flags));
//分配nr_tags个struct request *指针赋于tags->rqs[],不是分配struct request结构
tags->rqs = kzalloc_node(nr_tags * sizeof(struct request *),
GFP_NOIO | __GFP_NOWARN | __GFP_NORETRY,
set->numa_node)
//分配nr_tags个struct request *指针赋予tags->static_rqs[]
tags->static_rqs = kzalloc_node(nr_tags * sizeof(struct request *),GFP_NOIO | __GFP_NOWARN | __GFP_NORETRY,set->numa_node);
}
1.2 多队列块设备驱动初始化后半部分
接着是初始化的后半部分,在 blk_mq_init_queue()中完成。该函数主要分配块设备的运行队列request_queue,接着分配每个CPU专属的软件队列并初始化,分配硬件队列并初始化,然后建立软件队列和硬件队列的映射。整体流程图如下(高清大图查看方法:鼠标右键点击图片后,点击"在新标签页中打开图片",然后在新窗口点击图片即可查看高清大图):
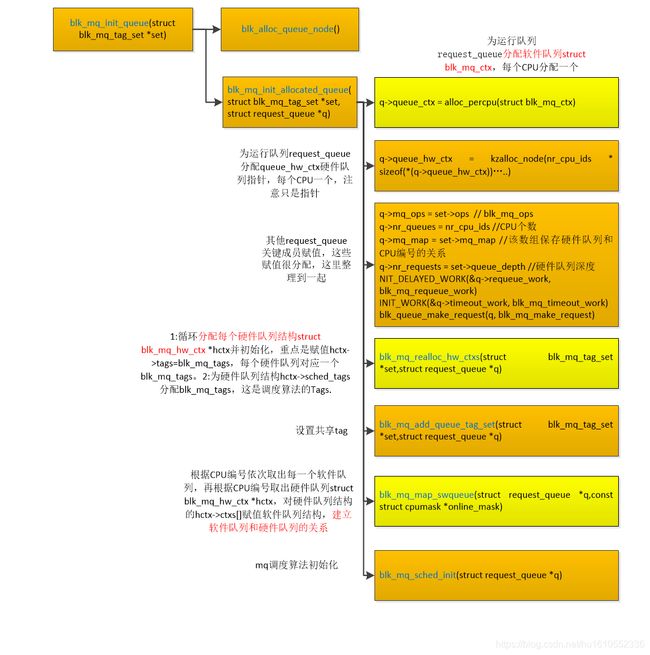
struct request_queue *blk_mq_init_queue(struct blk_mq_tag_set *set)
{
struct request_queue *uninit_q, *q;
//分配struct request_queue并初始化
uninit_q = blk_alloc_queue_node(GFP_KERNEL, set->numa_node, NULL);
if (!uninit_q)
return ERR_PTR(-ENOMEM);
//分配每个CPU专属的软件队列,分配硬件队列,对二者做初始化,并建立软件队列和硬件队列联系
q = blk_mq_init_allocated_queue(set, uninit_q);
if (IS_ERR(q))
blk_cleanup_queue(uninit_q);
return q;
}
blk_mq_init_queue函数整体来说,是创建request_queue运行队列并初始化其成员,分配每个CPU专属的软件队列,分配硬件队列,对二者做初始化,并建立软件队列和硬件队列联系。
struct request_queue *blk_mq_init_allocated_queue(struct blk_mq_tag_set *set,
struct request_queue *q)
{
//为每个CPU分配一个软件队列struct blk_mq_ctx,软件队列结构在这里分配
q->queue_ctx = alloc_percpu(struct blk_mq_ctx);
//分配硬件队列,这看着也是每个CPU分配一个queue_hw_ctx指针
q->queue_hw_ctx = kzalloc_node(nr_cpu_ids * sizeof(*(q->queue_hw_ctx)),
GFP_KERNEL, set->numa_node);
//赋值q->mq_map,这个数组保存了每个CPU对应的硬件队列编号
q->mq_map = set->mq_map;
/* 1 循环分配每个硬件队列结构blk_mq_hw_ctx并初始化,即对每个struct blk_mq_hw_ctx *hctx硬件队列结构大部
分成员赋初值。重点是赋值hctx->tags=blk_mq_tags,即每个硬件队列唯一对应一个blk_mq_tags,blk_mq_tags来自
struct blk_mq_tag_set 的成员struct blk_mq_tags[hctx_idx]。然后分配hctx->ctxs软件队列指针数组,注意只是指针数
组!
2 为硬件队列结构hctx->sched_tags分配blk_mq_tags,这是调度算法的tags。接着根据为这个blk_mq_tags分配
q->nr_requests个request,存于tags->static_rqs[],这是调度算法的blk_mq_tags的request!
*/
blk_mq_realloc_hw_ctxs(set, q);
//设置rq的make_request_fn为blk_mq_make_request
blk_queue_make_request(q, blk_mq_make_request);
//nr_requests被设置为队列深度
q->nr_requests = set->queue_depth;
/*依次取出每个CPU唯一的软件队列struct blk_mq_ctx *__ctx ,__ctx->cpu记录CPU编号,还根据CPU编号取出该CPU对应的硬件队列blk_mq_hw_ctx*/
blk_mq_init_cpu_queues(q, set->nr_hw_queues);
//共享tag设置
blk_mq_add_queue_tag_set(set, q);
/*1:根据CPU编号依次取出每一个软件队列,再根据CPU编号取出硬件队列struct blk_mq_hw_ctx *hctx,对硬件队
列结构的hctx->ctxs[]赋值软件队列结构
2:根据硬件队列数,依次从q->queue_hw_ctx[i]数组取出硬件队列结构体struct blk_mq_hw_ctx *hctx,然后对
hctx->tags赋值blk_mq_tags结构,前边的blk_mq_realloc_hw_ctxs()函数已经对hctx->tags赋值blk_mq_tags结构,这
里又赋值,有猫腻???????????????*/
blk_mq_map_swqueue(q, cpu_online_mask);
}
简单总结来说,blk_mq_init_allocated_queue函数负责分配每个CPU专属的软件队列,分配硬件队列,对二者做初始化,分配,并建立软件队列和硬件队列联系。该函数中调用的blk_mq_realloc_hw_ctxs()、blk_mq_map_swqueue()是两个重点函数,下文列出了源码注释。
static void blk_mq_realloc_hw_ctxs(struct blk_mq_tag_set *set,struct request_queue *q)
{
struct blk_mq_hw_ctx **hctxs = q->queue_hw_ctx;
for (i = 0; i < set->nr_hw_queues; i++)
{
//分配每一个硬件队列结构blk_mq_hw_ctx
hctxs[i] = kzalloc_node(sizeof(struct blk_mq_hw_ctx),GFP_KERNEL, node);
hctxs[i]->numa_node = node;
hctxs[i]->queue_num = i;
/* 1 为分配的struct blk_mq_hw_ctx *hctx 硬件队列结构大部分成员赋初值。重点是赋值hctx->tags=blk_mq_tags,
即每个硬件队列唯一对应一个blk_mq_tags,blk_mq_tags来自struct blk_mq_tag_set 的成员struct blk_mq_tags[hctx_idx]。
然后分配hctx->ctxs软件队列指针数组,注意只是指针数组!
2 为硬件队列结构hctx->sched_tags分配blk_mq_tags,这是调度算法的tags。接着为这个blk_mq_tags分配
q->nr_requests个request,存于tags->static_rqs[],这是调度算法的blk_mq_tags的request!
*/
if (blk_mq_init_hctx(q, set, hctxs[i], i))
{………}
}
//设置硬件队列数
q->nr_hw_queues = i;
}
blk_mq_realloc_hw_ctxs()函数很重要,分配每一个硬件队列具体的数据结构blk_mq_hw_ctx。然后主要为该结构的tags和sched_tags成员,分配赋值每个硬件队列必须的blk_mq_tags。之后进行IO传输前,要从hctx->tags-> static_rqs[]或者hctx->sched_tags-> static_rqs[]分配一个req。该函数中调用的blk_mq_init_hctx()主要是初始化blk_mq_hw_ctx硬件队列成员,分配调度算法hctx->sched_tags需要的blk_mq_tags。源码如下:
static int blk_mq_init_hctx(struct request_queue *q,
struct blk_mq_tag_set *set,
struct blk_mq_hw_ctx *hctx, unsigned hctx_idx)
{
//运行队列
hctx->queue = q;
//硬件队列编号
hctx->queue_num = hctx_idx;
//赋值hctx->tags的blk_mq_tags,每个硬件队列对应一个blk_mq_tags,这个tags在__blk_mq_alloc_rq_map()中赋值
hctx->tags = set->tags[hctx_idx];
//为每个CPU分配软件队列blk_mq_ctx指针,只是指针
hctx->ctxs = kmalloc_node(nr_cpu_ids * sizeof(void *),GFP_KERNEL, node);
/*为硬件队列结构hctx->sched_tags分配blk_mq_tags,一个硬件队列一个blk_mq_tags,这是调度算法的blk_mq_tags,
与硬件队列专属的blk_mq_tags不一样。然后根据为这个blk_mq_tags分配q->nr_requests个request,存于
tags->static_rqs[]*/
if (blk_mq_sched_init_hctx(q, hctx, hctx_idx))
{…..}
}
blk_mq_map_swqueue()函数主要作用是,根据CPU编号取出硬件队列结构struct blk_mq_ctx *ctx和软件队列结构struct blk_mq_ctx *ctx,然后把软件队列结构赋值给硬件队列结构,即hctx->ctxs[hctx->nr_ctx++] = ctx,相当于完成硬件队列与软件队列的映射吧。
static void blk_mq_map_swqueue(struct request_queue *q,
const struct cpumask *online_mask)
{
struct blk_mq_hw_ctx *hctx;
struct blk_mq_ctx *ctx;
struct blk_mq_tag_set *set = q->tag_set;
/*根据CPU编号依次取出每一个软件队列,再根据CPU编号取出硬件队列struct blk_mq_hw_ctx *hctx,对硬件
队列结构的hctx->ctxs[]赋值软件队列结构blk_mq_ctx*/
for_each_possible_cpu(i) {
//根据CPU编号取出硬件队列编号
hctx_idx = q->mq_map[i];
//根据CPU编号取出每个CPU对应的软件队列结构struct blk_mq_ctx *ctx
ctx = per_cpu_ptr(q->queue_ctx, i);
//根据CPU编号取出每个CPU对应的硬件队列struct blk_mq_hw_ctx *hctx
hctx = blk_mq_map_queue(q, i);
/*硬件队列关联的第几个软件队列。硬件队列每关联一个软件队列,都hctx->ctxs[hctx->nr_ctx++] = ctx,把
软件队列结构保存到hctx->ctxs[hctx->nr_ctx++],即硬件队列结构的hctx->ctxs[]数组,而ctx->index_hw会先保存
hctx->nr_ctx*/
ctx->index_hw = hctx->nr_ctx;
//软件队列结构以hctx->nr_ctx为下标保存到hctx->ctxs[]
hctx->ctxs[hctx->nr_ctx++] = ctx;
}
/*根据硬件队列数,依次从q->queue_hw_ctx[i]数组取出硬件队列结构体struct blk_mq_hw_ctx *hctx,然后对
hctx->tags赋值blk_mq_tags结构*/
queue_for_each_hw_ctx(q, hctx, i) {
//i是硬件队列编号,这是根据硬件队列编号i从struct blk_mq_tag_set *set取出硬件队列专属的blk_mq_tags
hctx->tags = set->tags[i];
sbitmap_resize(&hctx->ctx_map, hctx->nr_ctx);
}
}
这个初始化还是有点复杂的,其实我们需要重点关注一点:每个CPU对应唯一的软件队列blk_mq_ctx,blk_mq_ctx对应唯一的硬件队列blk_mq_hw_ctx,blk_mq_hw_ctx对应唯一的blk_mq_tags。我们在进行发起bio请求后,需要从blk_mq_tags结构的相关成员分配一个tag(其实是一个数字),再根据tag分配一个req,最后才能进行IO派发,磁盘数据传输。
2 块设备多队列IO的分配、派送处理
这部分涉及的流程相当繁琐,块设备多队列的代码比单队列复杂了好几倍,主要以流程图讲解,再配合关键的代码。
流程图中有各种各样颜色,颜色含义是:
1:浅粉红色表示启动硬件IO派送
2:深蓝色表示把req加入到各种队列
3:紫色表示req direct派送
4:浅青色表示分配req和tag
5:深青色表示把req派送给设备驱动
6:浅蓝色表示执行blk_mq_do_dispatch_sched()
7:浅黄色表示执行blk_mq_dispatch_rq_list()
8:浅棕色表示执行blk_mq_do_dispatch_ctx()
流程图中某个函数执行的中间环节出现的虚线表示进入一个新的函数。
再次强调一下:代码注释中的req、request都代表struct request结构,即IO请求。
2.1 blk_mq_make_request() req的分配、派送
先上整体流程图(高清大图查看方法:鼠标右键点击图片后,点击"在新标签页中打开图片",然后在新窗口点击图片即可查看高清大图)
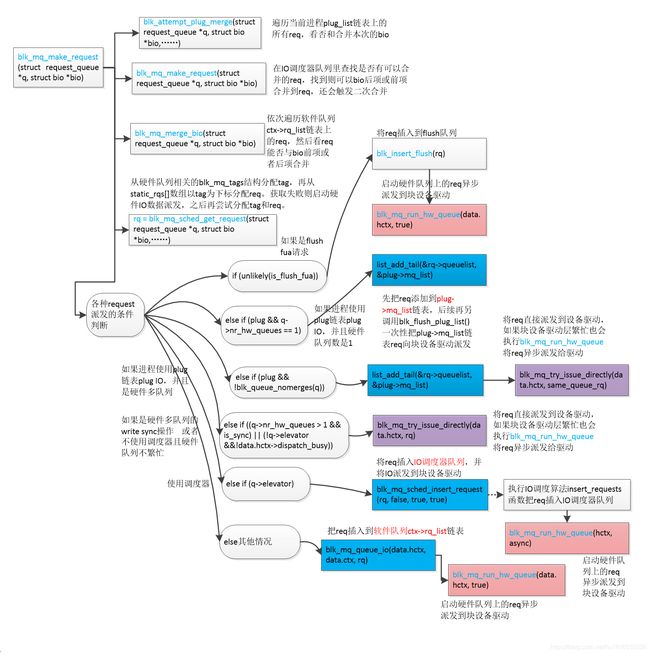
blk_mq_make_request() 函数关键源码如下
static void blk_mq_make_request(struct request_queue *q, struct bio *bio)
{
//遍历当前进程plug_list链表上的所有req,检查bio和req代表的磁盘范围是否挨着,挨着则把bio合并到req
if (!is_flush_fua && !blk_queue_nomerges(q) &&blk_attempt_plug_merge(q, bio, &request_count, &same_queue_rq))
return;
//在IO调度器队列里查找是否有可以合并的req,找到则可以bio后项或前项合并到req,还会触发二次合并
if (blk_mq_sched_bio_merge(q, bio))
return;
//依次遍历软件队列ctx->rq_list链表上的req,然后看req能否与bio前项或者后项合并
if (blk_mq_merge_bio(q, bio))
return;
/*从硬件队列的blk_mq_tags结构体的tags->bitmap_tags或者tags->nr_reserved_tags分配一个空闲tag,然后req =
tags->static_rqs[tag]从static_rqs[]分配一个req,再req->tag=tag。接着hctx->tags->rqs[rq->tag] = rq,一个req必须分配一
个tag才能IO传输。分配失败则启动硬件IO数据派发,之后再尝试分配tag*/
rq = blk_mq_sched_get_request(q, bio, bio->bi_rw, &data);
if (unlikely(!rq))
return;
plug = current->plug;
if (unlikely(is_flush_fua)) {//如果是flush fua请求
//赋值req扇区起始地址,req结束地址,rq->bio = rq->biotail=bio,并且统计磁盘使用率等数据
blk_mq_bio_to_request(rq, bio);
//将request插入到flush队列
blk_insert_flush(rq);
//启动req磁盘硬件队列异步派送
blk_mq_run_hw_queue(data.hctx, true);
}else if (plug && q->nr_hw_queues == 1){// 如果进程使用plug链表plug IO,并且硬件队列数是1
//赋值req扇区起始地址,req结束地址,rq->bio = rq->biotail=bio,并且统计磁盘使用率等数据
blk_mq_bio_to_request(rq, bio);
//只是先把req添加到plug->mq_list链表上,等后续再一次性把plug->mq_list链表req向块设备驱动派发
list_add_tail(&rq->queuelist, &plug->mq_list)
}else if (plug && !blk_queue_nomerges(q)) {//如果进程使用plug链表plug IO,并且是硬件多队列
//赋值req扇区起始地址,req结束地址,rq->bio = rq->biotail=bio,统计磁盘使用率等数据
blk_mq_bio_to_request(rq, bio);
//将req直接派发到设备驱动,如果块设备驱动层繁忙也会执行blk_mq_run_hw_queue将req异步派发给驱动
blk_mq_try_issue_directly(data.hctx, same_queue_rq);
}else if ((q->nr_hw_queues > 1 && is_sync) || (!q->elevator &&
!data.hctx->dispatch_busy)) {//如果是硬件多队列的write sync操作或者不使用调度器且硬件队列不繁忙
//赋值req扇区起始地址,req结束地址,rq->bio = rq->biotail=bio,并且统计磁盘使用率等数据
blk_mq_bio_to_request(rq, bio);
//将req直接派发到设备驱动,如果块设备驱动层繁忙也会执行blk_mq_run_hw_queue将req异步派发给驱动
blk_mq_try_issue_directly(data.hctx, rq);
}else if (q->elevator) {//使用调度器
//赋值req扇区起始地址,req结束地址,rq->bio = rq->biotail=bio,并且统计磁盘使用率等数据
blk_mq_bio_to_request(rq, bio);
//将req插入IO调度器队列,并执行blk_mq_run_hw_queue()将IO派发到块设备驱动
blk_mq_sched_insert_request(rq, false, true, true);
}else {
//赋值req扇区起始地址,req结束地址,rq->bio = rq->biotail=bio,并且统计磁盘使用率等数据
blk_mq_bio_to_request(rq, bio);
//把req插入到软件队列ctx->rq_list链表
blk_mq_queue_io(data.hctx, data.ctx, rq);
//启动硬件队列上的req异步派发到块设备驱动
blk_mq_run_hw_queue(data.hctx, true);
}
}
blk_mq_make_request()函数包含的核心函数不少,基本流程是,先尝试把bio合并到软件队列或plug队列或调度算法队列。如果无法合并,则执行blk_mq_sched_get_request()分配tag和req。这里终于出现”分配tag”了。tag是什么?有什么作用?这是与单队列时代的一个明显区别。
这里先简单介绍一下,多队列IO传输,将bio转换成req(就是sturct request),大体过程是这样的:先根据当前进程所在CPU,找到CPU对应的软件队列blk_mq_ctx(获取过程见blk_mq_get_ctx函数,每个CPU都有一个唯一的软件队列),再根据软件队列blk_mq_ctx得到其映射的硬件队列blk_mq_hw_ctx(获取过程见blk_mq_map_queue函数,每个软件队列对应唯一的硬件队列)。硬件队列blk_mq_hw_ctx结构中有两个关键成员struct blk_mq_tags *tags(针对无调度算法)和struct blk_mq_tags *sched_tags(针对有调度算法),这里只介绍前者。
有了硬件队列结构blk_mq_hw_ctx,得到其成员struct blk_mq_tags *tags指向的blk_mq_tags结构。blk_mq_tags结构又有几个关键成员:struct sbitmap_queue bitmap_tags、struct sbitmap_queue breserved_tags、struct request **static_rqs、unsigned int nr_reserved_tags。static_rqs这个指针数组保存了nr_tags个req指针,实际的req结构在前文的__blk_mq_alloc_rq_map->blk_mq_alloc_rqs分配。
struct sbitmap_queue bitmap_tags和struct sbitmap_queue breserved_tags分析下来有点像ext4 文件系统的inode bitmap,一个bit位表示一个req的使用情况,1为已经分配,0为未分配。struct sbitmap_queue breserved_tags管理static_rqs[0~ (nr_reserved_tags-1]]这nr_reserved_tags个req,struct sbitmap_queue bitmap_tags管理static_rqs[ nr_reserved_tags ~ nr_tags]这nr_tags- nr_reserved_tags个req。这点是根据实际代码分析出的结果,如果有不对的地方请指出。
好的,有了前文的介绍,可以说一下分配tag和req的一般情况:从struct sbitmap_queue bitmap_tags分析出哪个req是空闲的,返回一个数字,这个数字就是tag,表示了static_rqs[] 中哪个位置的req是空闲的。实际情况tag+ nr_reserved_tags才能表示实际空闲的req在static_rqs[]中的下标。每一个req在派发给驱动时,必须得先分配一个tag。
有时req在派发给驱动时,如果遇到磁盘硬件驱动繁忙,则先把req的tag从struct sbitmap_queue bitmap_tags释放掉。稍等一段时间,再次尝试把req派发给驱动,此时还需要再为req从struct sbitmap_queue bitmap_tags中分配一个tag。其实我有个问题,这是分配的tag不能在表示req在static_rqs[]数组中的位置了????能代表的是第一次req和tag分配时的那个tag,这个问题需要后续实际调试验证。
2.2 blk_mq_sched_get_request()分配tag和req
还是先上流程图

struct request *blk_mq_sched_get_request(struct request_queue *q,
struct bio *bio,
unsigned int op,
struct blk_mq_alloc_data *data)
{
//data->ctx 获取当前进程所属CPU的专有软件队列
data->ctx = blk_mq_get_ctx(q);
//获取软件队列的硬件队列,CPU、软件队列、硬件队列是一一对应关系
data->hctx = blk_mq_map_queue(q, data->ctx->cpu);
if (e) {//使用调度器
//使用调度时设置BLK_MQ_REQ_INTERNAL标志
data->flags |= BLK_MQ_REQ_INTERNAL;
rq = __blk_mq_alloc_request(data, op);
}else{ //无调度器
//同理
rq = __blk_mq_alloc_request(data, op);
}
return rq;
}
该函数主要作用是:从硬件队列的blk_mq_tags结构体的tags->bitmap_tags或者tags->nr_reserved_tags分配一个空闲tag,然后req = tags->static_rqs[tag]从static_rqs[]分配一个req,再req->tag=tag。接着hctx->tags->rqs[rq->tag] = rq,一个req必须分配一个tag才能IO传输。分配失败则启动硬件IO数据派发,之后再尝试分配tag。如果留意的话,这就是上一节介绍的tag和req的分配过程,更详细的步骤看下边的__blk_mq_alloc_request函数。
2.2.1 __blk_mq_alloc_request()分配tag和req
struct request *__blk_mq_alloc_request(struct blk_mq_alloc_data *data, int rw)
{
/*从硬件队列有关的blk_mq_tags结构体的static_rqs[]数组里得到空闲的request。获取失败则启动硬件IO数据派
发,之后再尝试从blk_mq_tags结构体的static_rqs[]数组里得到空闲的request。注意,这里返回的是空闲的request
在static_rqs[]数组的下标*/
tag = blk_mq_get_tag(data);
if (tag != BLK_MQ_TAG_FAIL) //分配tag成功
{
//有调度器时返回硬件队列的hctx->sched_tags,无调度器时返回硬件队列的hctx->tags
struct blk_mq_tags *tags = blk_mq_tags_from_data(data);
//从tags->static_rqs[tag]得到空闲的req,tag是req在tags->static_rqs[ ]数组的下标
rq = tags->static_rqs[tag]; //这里真正分配得到本次传输使用的req
if (data->flags & BLK_MQ_REQ_INTERNAL) //用调度器时设置
{
rq->tag = -1;
__rq_aux(rq, data->q)->internal_tag = tag;//这是req的tag
}
else
{
//赋值为空闲req在blk_mq_tags结构体的static_rqs[]数组的下标
rq->tag = tag;
__rq_aux(rq, data->q)->internal_tag = -1;
//这里边保存的req是刚从static_rqs[]得到的空闲的req
data->hctx->tags->rqs[rq->tag] = rq;
}
//对新分配的req进行初始化,赋值软件队列、req起始时间等
blk_mq_rq_ctx_init(data->q, data->ctx, rq, rw);
return rq;
}
return NULL;
}
该函数的大体过程是:从硬件队列的blk_mq_tags结构体的tags->bitmap_tags或者tags->nr_reserved_tags分配一个空闲tag,然后req = tags->static_rqs[tag]从static_rqs[]分配一个req,再req->tag=tag。接着hctx->tags->rqs[rq->tag] = rq,一个req必须分配一个tag才能IO传输。分配失败则启动硬件IO数据派发,之后再尝试分配tag。函数核心是执行blk_mq_get_tag()分配tag,看下边。
2.2.2 blk_mq_get_tag()分配tag
流程图来了(高清大图查看方法:鼠标右键点击图片后,点击"在新标签页中打开图片",然后在新窗口点击图片即可查看高清大图)
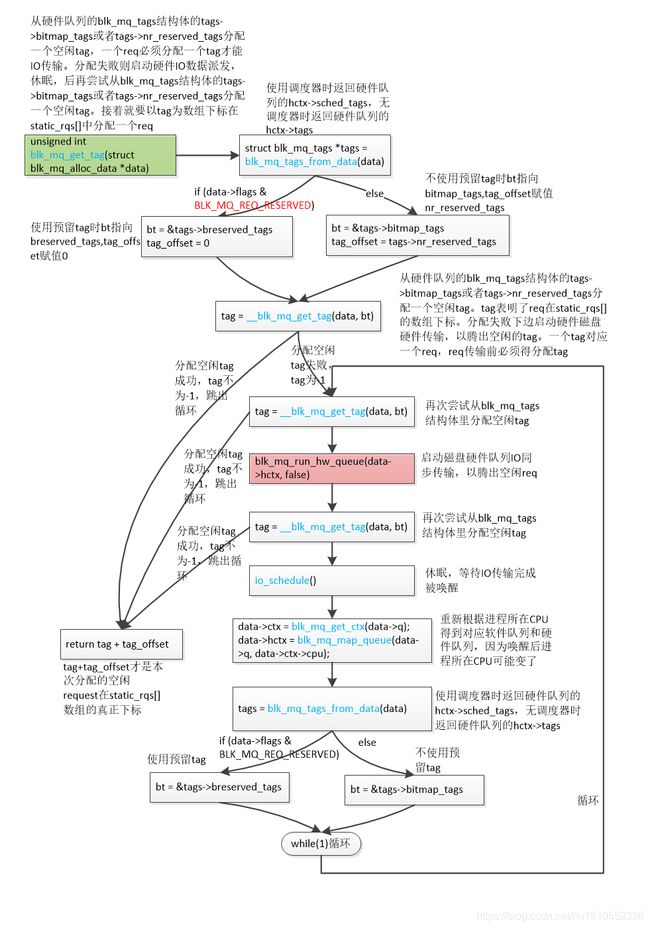
unsigned int blk_mq_get_tag(struct blk_mq_alloc_data *data)
{
//使用调度器时返回硬件队列的hctx->sched_tags,无调度器时返回硬件队列的hctx->tags。返回的是硬件队列
唯一对应的的blk_mq_tags
struct blk_mq_tags *tags = blk_mq_tags_from_data(data);
if (data->flags & BLK_MQ_REQ_RESERVED) {//使用预留tag
bt = &tags->breserved_tags;
tag_offset = 0;
} else {//不使用预留tag
//返回blk_mq_tags的bitmap_tags
bt = &tags->bitmap_tags;
//应该是static_rqs[]里空闲的request的数组下标偏移,见该函数最后
tag_offset = tags->nr_reserved_tags;
}
/*从硬件队列的blk_mq_tags结构体的tags->bitmap_tags或者tags->nr_reserved_tags分配一个空闲tag。tag表明了req在
static_rqs[]的数组下标。分配失败下边启动硬件磁盘硬件传输,以腾出空闲的tag。一个tag就是一个req,req传输前必须
得分配tag*/
tag = __blk_mq_get_tag(data, bt);
if (tag != -1)
goto found_tag;
/*走到这一步,说明硬件队列有关的blk_mq_tags里没有空闲的request可分配,那就会陷入休眠等待,并且执行
blk_mq_run_hw_queue启动IO 数据传输,传输完成后可以释放出request,达到分配request的目的*/
do {
//再次尝试从blk_mq_tags结构体里分配空闲tag
tag = __blk_mq_get_tag(data, bt);
if (tag != -1)
break;
//启动磁盘硬件队列IO同步传输,以腾出空闲req
blk_mq_run_hw_queue(data->hctx, false);
//再次尝试从blk_mq_tags结构体里分配空闲tag
tag = __blk_mq_get_tag(data, bt);
if (tag != -1)
break;
//休眠调度
io_schedule();
//重新根据进程所在CPU得到对应软件队列和硬件队列,因为唤醒后进程所在CPU可能变了
data->ctx = blk_mq_get_ctx(data->q);
data->hctx = blk_mq_map_queue(data->q, data->ctx->cpu);
//使用调度器时返回硬件队列的hctx->sched_tags,无调度器时返回硬件队列的hctx->tags
tags = blk_mq_tags_from_data(data);
if (data->flags & BLK_MQ_REQ_RESERVED)
bt = &tags->breserved_tags;
else//再次获取bitmap_tags,流程跟前边一模一样
bt = &tags->bitmap_tags;
} while (1);
found_tag:
// tag+tag_offset才是本次分配的空闲request在static_rqs[]数组的真正下标
return tag + tag_offset;
}
该函数是分配tag的核心实现:从硬件队列的blk_mq_tags结构体的tags->bitmap_tags或者tags->nr_reserved_tags分配一个空闲tag,一个req必须分配一个tag才能IO传输。分配失败则启动硬件IO数据派发,休眠后再尝试从blk_mq_tags结构体的tags->bitmap_tags或者tags->nr_reserved_tags分配一个空闲tag。需要说明的一点是,tag并不能一次就能分配成功,当时可能IO传输进程很多,把tag分配完了。那只能先休眠等待,同时执行blk_mq_run_hw_queue()把其他req派发给磁盘驱动,等它传输完成就会释放tag。然后当前进程唤醒,就能分配到tag,但是需要重新获取硬件队列和软件队列,因为休眠后唤醒,进程所属CPU可能变了。
好的,这几小节把分配tag和req的过程终于讲解完了,不熟悉的可能需要反复看几次。下边需要讲解req的派发。
2.3 blk_mq_try_issue_directly() 将req direct直接派发给磁盘设备驱动
还是先上该函数流程图(高清大图查看方法:鼠标右键点击图片后,点击"在新标签页中打开图片",然后在新窗口点击图片即可查看高清大图)

static void blk_mq_try_issue_directly(struct blk_mq_hw_ctx *hctx,
struct request *rq)
{
/*从硬件队列的blk_mq_tags结构体的tags->bitmap_tags或者tags->nr_reserved_tags分配一个空闲tag赋于rq->tag,
然后hctx->tags->rqs[rq->tag] = rq,一个req必须分配一个tag才能IO传输。分配失败则启动硬件IO数据派发,之后再尝
试分配tag,循环,直到分配req成功。然后调用磁盘驱动queue_rq接口函数向驱动派发req,启动磁盘数据传输。如果
遇到磁盘驱动硬件忙,则释放req的tag,设置硬件队列忙*/
ret = __blk_mq_try_issue_directly(hctx, rq, false);
//如果硬件队列忙,把req添加到硬件队列hctx->dispatch队列,间接启动req硬件派发
if (ret == BLK_MQ_RQ_QUEUE_BUSY || ret == BLK_MQ_RQ_QUEUE_DEV_BUSY)
blk_mq_request_bypass_insert(rq, true);
/*req磁盘数据传输完成了,增加ios、ticks、time_in_queue、io_ticks、flight、sectors扇区数等使用计数。依次取出req->bio
链表上所有req对应的bio,一个一个更新bio结构体成员数据,执行bio的回调函数。还更新req->__data_len和
req->buffer*/
else if (ret != BLK_MQ_RQ_QUEUE_OK)
blk_mq_end_request(rq, ret);
}
核心是执行 __blk_mq_try_issue_directly()函数。
static int __blk_mq_try_issue_directly(struct blk_mq_hw_ctx *hctx,
struct request *rq,
bool bypass_insert)
{
/*从硬件队列的blk_mq_tags结构体的tags->bitmap_tags或者tags->nr_reserved_tags分配一个空闲tag赋于rq->tag,然后hctx->tags->rqs[rq->tag] = rq,一个req必须分配一个tag才能IO传输。分配失败则启动硬件IO数据派发,
之后再尝试分配tag,循环。但是如果req已经有tag 了,会直接返回,不用再分配tag*/
blk_mq_get_driver_tag(rq, NULL, false));
/*调用磁盘驱动queue_rq接口函数,根据req设置command,把req添加到q->timeout_list,并且启动q->timeout
定时器,把新的command复制到sq_cmds[]命令队列,这看着是req直接发给磁盘驱动进行数据传输了。如果遇到磁盘
驱动硬件忙,则设置硬件队列忙,还释放req的tag。*/
return __blk_mq_issue_directly(hctx, rq);
}
再总结一下__blk_mq_try_issue_directly函数的详细流程:从硬件队列的blk_mq_tags结构体的tags->bitmap_tags或者tags->nr_reserved_tags分配一个空闲tag赋于rq->tag,然后hctx->tags->rqs[rq->tag] = rq,一个req必须分配一个tag才能IO传输。分配失败则启动硬件IO数据派发,之后再尝试分配tag,循环,直到分配req成功。然后调用磁盘驱动queue_rq接口函数向驱动派发req,启动磁盘数据传输。如果遇到磁盘驱动硬件忙,则释放req的tag,设置硬件队列忙。
其实核心就两点:1为req分配tag;2把req派发给磁盘驱动,启动磁盘数据传输。有人可能会问,不是在blk_mq_make_request->blk_mq_sched_get_request 中已经为req分配过tag了,为什么这里还要再分配?关于这一点,我的分析是,如果req已经分配过tag了,执行blk_mq_get_driver_tag函数(下一节讲)会直接返回。但是会存在这种情况,req在派发给磁盘驱动时,磁盘驱动硬件繁忙,派发失败,则会把req加入硬件队列hctx->dispatch链表,然后把req的tag释放掉,则req->tag=-1,等空闲时派发该req。好的,空闲时间来了,再次派发该req,此时就需要执行blk_mq_get_driver_tag为req重新分配一个tag。一个req在派发给驱动时,必须分配一个tag!
__blk_mq_issue_directly是直接将req派发给驱动的核心函数。
static int __blk_mq_issue_directly(struct blk_mq_hw_ctx *hctx, struct request *rq)
{
//根据req设置磁盘驱动 command,把req添加到q->timeout_list,并且启动q->timeout,把command复制到nvmeq->sq_cmds[]队列等等
ret = q->mq_ops->queue_rq(hctx, &bd);
switch (ret) {
case BLK_MQ_RQ_QUEUE_OK://成功把req派发给磁盘硬件驱动
blk_mq_update_dispatch_busy(hctx, false);//设置硬件队列不忙,看着就hctx->dispatch_busy = ewma
break;
case BLK_MQ_RQ_QUEUE_BUSY:
case BLK_MQ_RQ_QUEUE_DEV_BUSY://这是遇到磁盘硬件驱动繁忙,req没有派送给驱动
blk_mq_update_dispatch_busy(hctx, true);//设置硬件队列忙
//硬件队列繁忙,则从tags->bitmap_tags或者breserved_tags中按照req->tag这个tag编号释放tag
__blk_mq_requeue_request(rq);
break;
default:
//标记硬件队列不忙
blk_mq_update_dispatch_busy(hctx, false);
break;
}
return ret;
}
基本是调用磁盘驱动层的函数,将req有关的磁盘传输信息发送给驱动,然后会进行磁盘数据传输。如果遇到磁盘驱动硬件忙,则设置硬件队列忙,还释放req的tag。
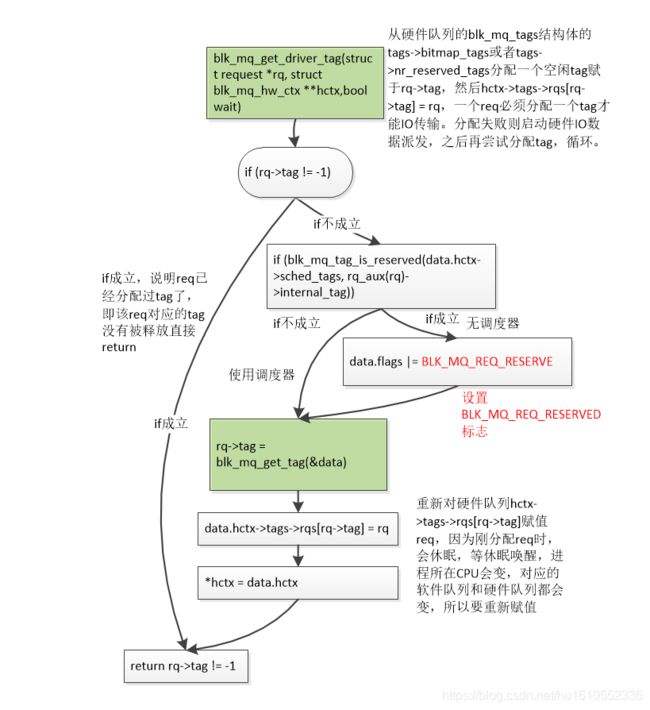
2.4 blk_mq_get_driver_tag() 在req派发给驱动前分配tag
还是先上该函数流程图
函数源码是
bool blk_mq_get_driver_tag(struct request *rq, struct blk_mq_hw_ctx **hctx,
bool wait)
{
/*如果req对应的tag没有被释放,则直接返回完事,其实还有一种情况rq->tag被置-1。就是__blk_mq_alloc_request()
函数分配过tag和req后,如果使用了调度器,则rq->tag = -1。这种情况,rq->tag != -1也成立,但是再直接执行
blk_mq_get_driver_tag()分配tag也没啥意思呀,因为tag已经分配过了。所以感觉该函数主要还是针对req因磁盘硬
件驱动繁忙无法派送,然后释放了tag,再派发时分配tag的情况。*/
if (rq->tag != -1)
goto done;
//判断tag是否预留的,是则加上BLK_MQ_REQ_RESERVED标志
if (blk_mq_tag_is_reserved(data.hctx->sched_tags, rq_aux(rq)->internal_tag))
data.flags |= BLK_MQ_REQ_RESERVED;
/*从硬件队列的blk_mq_tags结构体的tags->bitmap_tags或者tags->nr_reserved_tags分配一个空闲tag赋于rq->tag,
然后hctx->tags->rqs[rq->tag] = rq,一个req必须分配一个tag才能IO传输。分配失败则启动硬件IO数据派发,之后再
尝试分配tag,循环。*/
rq->tag = blk_mq_get_tag(&data);
//对hctx->tags->rqs[rq->tag]赋值
data.hctx->tags->rqs[rq->tag] = rq;
//之所以这里重新赋值,是因为blk_mq_get_tag中可能会休眠,等再次唤醒进程所在CPU就变了,就会重新获取
一次硬件队列保存到data.hctx
*hctx = data.hctx;
//分配成功返回1
return rq->tag != -1;
}
函数流程再总结一下:从硬件队列的blk_mq_tags结构体的tags->bitmap_tags或者tags->nr_reserved_tags分配一个空闲tag赋于rq->tag,然后hctx->tags->rqs[rq->tag] = rq,一个req必须分配一个tag才能IO传输。分配失败则启动硬件IO数据派发,之后再尝试分配tag,循环。
可以发现,该函数本质还是调用前文介绍过的blk_mq_get_tag()去硬件队列的blk_mq_tags结为req分配一个tag。该函数只是分配tag,没有分配req。blk_mq_get_driver_tag()存在的意义是:req派发给磁盘驱动时,遇到磁盘硬件队列繁忙,无法派送,则释放掉tag,req加入硬件hctx->dispatch链表异步派发。等再次派发时,就会执行blk_mq_get_driver_tag()为req分配一个tag。
2.5 blk_mq_run_hw_queue类软件队列ctx->rq_list、硬件hctx->dispatch、IO算调度法队列链表上的req派发
blk_mq_try_issue_directly()类的req direct 派发是针对单个req的,blk_mq_run_hw_queue()是派发类软件队列ctx->rq_list、硬件hctx->dispatch链表、IO调度算法队列上的req的,这是二者最大的区别。
还是先上该函数流程图(高清大图查看方法:鼠标右键点击图片后,点击"在新标签页中打开图片",然后在新窗口点击图片即可查看高清大图)
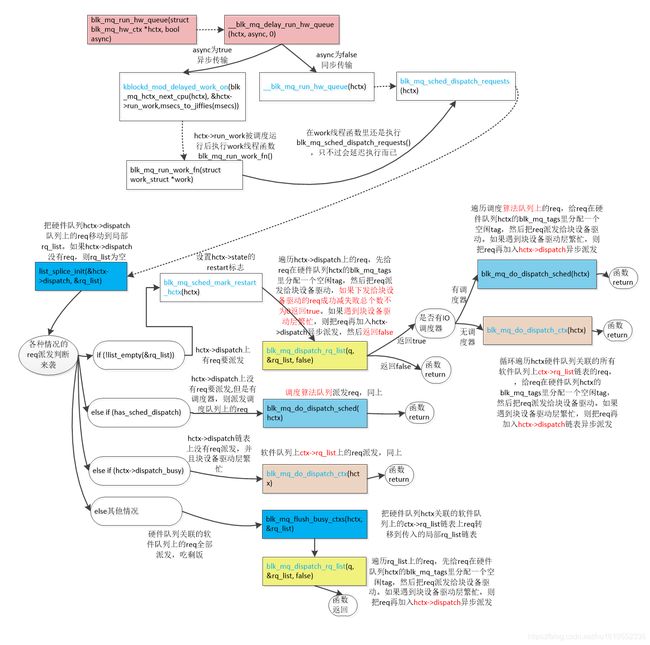
可以发现是软件队列ctx->rq_list、硬件hctx->dispatch、调度器算法队列链表上req的派发情况,套路看清了也就那样,只是真的很繁琐!函数源码一点点展开。
//启动硬件队列上的req派发到块设备驱动
bool blk_mq_run_hw_queue(struct blk_mq_hw_ctx *hctx, bool async)//async为true表示异步传输,false表示同步
{
//有req需要硬件传输
if (need_run) {
__blk_mq_delay_run_hw_queue(hctx, async, 0);
return true;
}
return false
}
static void __blk_mq_delay_run_hw_queue(struct blk_mq_hw_ctx *hctx, bool async,//async为true则异步,false则同步传输unsigned long msecs)// msecs决定派发延时
{
//同步传输
if (!async && !(hctx->flags & BLK_MQ_F_BLOCKING)) {
/*各种各样场景的req派发,hctx->dispatch硬件队列dispatch链表上的req派发;有deadline调度算法时红黑树或
者fifo调度队列上的req派发;无IO调度器时,硬件队列关联的所有软件队列ctx->rq_list上的req的派发等等。派发过程
应该都是调用blk_mq_dispatch_rq_list(),磁盘驱动硬件不忙直接启动req传输,繁忙的话则把剩余的req转移到
hctx->dispatch队列,然后启动异步传输*/
__blk_mq_run_hw_queue(hctx);
return;
}
/*启动异步传输,开启kblockd_workqueue内核线程workqueue,异步执行hctx->run_work对应的work函数
blk_mq_run_work_fn, 实际blk_mq_run_work_fn里执行的还是__blk_mq_run_hw_queue*/
kblockd_mod_delayed_work_on(blk_mq_hctx_next_cpu(hctx), &hctx->run_work,msecs_to_jiffies(msecs));
}
static void __blk_mq_run_hw_queue(struct blk_mq_hw_ctx *hctx)
{
//上硬件队列锁,这时如果是同一个硬件队列,就有锁抢占了
hctx_lock(hctx, &srcu_idx);
/*各种各样场景的req派发,hctx->dispatch硬件队列dispatch链表上的req派发;有deadline调度算法时红黑树或者fifo
调度队列上的req派发;无IO调度算法时,硬件队列关联的所有软件队列ctx->rq_list上的req的派发等等。派发
都是调用blk_mq_dispatch_rq_list(),磁盘驱动硬件不忙直接启动req传输,繁忙的话则把剩余的req转移到
hctx->dispatch队列,然后启动异步传输*/
blk_mq_sched_dispatch_requests(hctx);
hctx_unlock(hctx, srcu_idx);
}
核心是调用blk_mq_sched_dispatch_requests ()函数。
2.5.1 blk_mq_sched_dispatch_requests()函数派发各种队列的req
void blk_mq_sched_dispatch_requests(struct blk_mq_hw_ctx *hctx)
{
LIST_HEAD(rq_list);
if (!list_empty_careful(&hctx->dispatch)) {
//把hctx->dispatch链表上的req转移到局部rq_list
list_splice_init(&hctx->dispatch, &rq_list);
}
//如果hctx->dispatch上有req要派发,hctx->dispatch链表上的req已经转移到rq_list
if (!list_empty(&rq_list))
{
//这里设置了hctx->state的BLK_MQ_S_SCHED_RESTART标志位
blk_mq_sched_mark_restart_hctx(hctx);
/*rq_list上的req来自hctx->dispatch硬件派发队列,遍历list上的req,先给req在硬件队列hctx的blk_mq_tags
里分配一个空闲tag,就是建立req与硬件队列的联系吧,然后把req派发给块设备驱动。看着任一个req要启动硬
件传输,都要从blk_mq_tags结构里得到一个空闲的tag。如果磁盘驱动硬件繁忙,还要把list剩余的req转移到
hctx->dispatch,启动异步传输。下发给块设备驱动的req成功减失败总个数不为0返回true。否则false。*/
if (blk_mq_dispatch_rq_list(q, &rq_list, false))
{
if (has_sched_dispatch) //有调度器则接着派发调度器队列上的req
//派发调度器队列上的req
blk_mq_do_dispatch_sched(hctx);
else
//派发硬件队列绑定的所有软件队列上的req
blk_mq_do_dispatch_ctx(hctx);
}
}
else if (has_sched_dispatch){
blk_mq_do_dispatch_sched(hctx); //派发调度器队列上的req
} else if (hctx->dispatch_busy){
blk_mq_do_dispatch_ctx(hctx); //派发硬件队列绑定的所有软件队列上的req
}else{
//把硬件队列hctx关联的软件队列上的ctx->rq_list链表上req转移到传入的rq_list链表
blk_mq_flush_busy_ctxs(hctx, &rq_list);
/*遍历rq_list上的req,先给req在硬件队列hctx的blk_mq_tags里分配一个空闲tag,然后把req派发给块设备
驱动。如果遇到块设备驱动层繁忙,则把req再加入hctx->dispatch异步派发*/
blk_mq_dispatch_rq_list(q, &rq_list, false);
}
}
该函数功能再总结一下:各种各样场景的req派发,hctx->dispatch硬件队列dispatch链表上的req派发;调度器队列上的req派发;无IO调度算法时,硬件队列关联的所有软件队列ctx->rq_list上的req的派发等等。派发都是调用blk_mq_dispatch_rq_list(),磁盘驱动硬件不繁忙直接启动req传输,繁忙的话则把剩余的req转移到hctx->dispatch队列,然后启动异步传输。
总结下来,主要是3种情况
1 执行blk_mq_dispatch_rq_list()派发硬件队列hctx->dispatch链表上的req
2执行blk_mq_do_dispatch_sched()派发调度器队列上的req。
3执行blk_mq_do_dispatch_ctx ()函数派发软件队列ctx->rq_list链表上的req。
blk_mq_do_dispatch_sched() 和blk_mq_flush_busy_ctxs()最后也是指定的blk_mq_dispatch_rq_list()函数进行实际的派发,下文一一讲解。
2.5.2 blk_mq_do_dispatch_sched()派发调度器队列上的req
还是先上函数流程图,这里以deadline调度算法为例。

static void blk_mq_do_dispatch_sched(struct blk_mq_hw_ctx *hctx)
{
LIST_HEAD(rq_list);
do {
/*执行deadline算法派发函数,从fifo或者红黑树队列选择待派发的req返回。然后设置新的next_rq,并把
req从fifo队列和红黑树队列剔除,req来源有:上次派发设置的next_rq;read req派发过多而选择的write req;fifo 队列上
超时要传输的req,统筹兼顾,有固定策略*/
rq = e->aux->ops.mq.dispatch_request(hctx);//dd_dispatch_request
//把选择出来派发的req加入局部变量rq_list链表
list_add(&rq->queuelist, &rq_list);
// blk_mq_dispatch_rq_list()才会调度算法队列上的req进行派发
}
while (blk_mq_dispatch_rq_list(q, &rq_list, true))
}
函数功能总结一下:执行deadline算法派发函数,循环从fifo或者红黑树队列选择待派发给传输的req,然后给req在硬件队列hctx的blk_mq_tags里分配一个空闲tag,接着把req派发给块设备驱动。如果磁盘驱动硬件繁忙,则把req转移到hctx->dispatch队列,然后启动req异步传输。硬件队列繁忙或者算法队列没有req了则跳出循环返回。
2.5.3 blk_mq_do_dispatch_ctx ()派发软件队列ctx->rq_list链表上的req
老话,上函数流程图
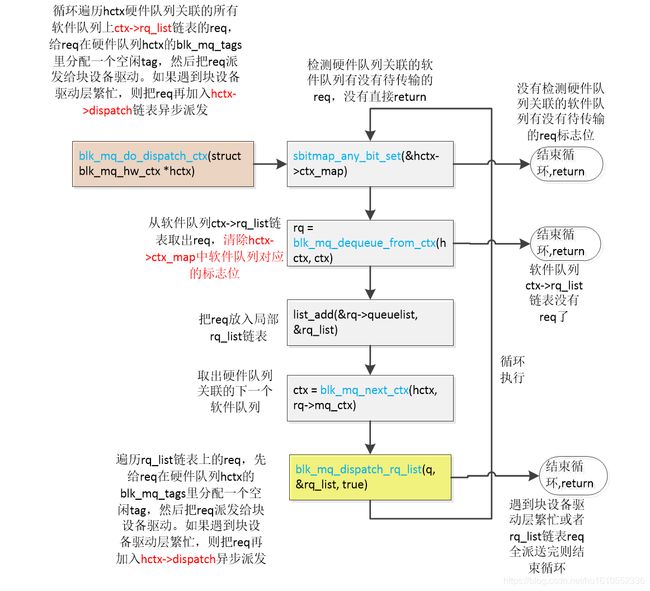
static void blk_mq_do_dispatch_ctx(struct blk_mq_hw_ctx *hctx)
{
//依次遍历hctx硬件队列关联的所有软件队列
do {
//从软件队列ctx->rq_list链表取出req,然后从软件队列中剔除req。接着清除hctx->ctx_map中软件队列对应的标志位???????
rq = blk_mq_dequeue_from_ctx(hctx, ctx);
if (!rq) {
break;
}
//req加入到rq_list
list_add(&rq->queuelist, &rq_list);
//取出硬件队列关联的下一个软件队列
ctx = blk_mq_next_ctx(hctx, rq->mq_ctx);
// blk_mq_dispatch_rq_list()中才完成对rq_list链表上的软件队列的req的派发
} while (blk_mq_dispatch_rq_list(q, &rq_list, true))
}
总结一下大体功能:循环遍历hctx硬件队列关联的所有软件队列上ctx->rq_list链表的req,给req在硬件队列hctx的blk_mq_tags里分配一个空闲tag,然后把req派发给块设备驱动。如果遇到块设备驱动层繁忙,则把req再加入hctx->dispatch链表异步派发。
2.5.4 blk_mq_dispatch_rq_list()实际完成对各个队列上的req的派发
看函数流程图(高清大图查看方法:鼠标右键点击图片后,点击"在新标签页中打开图片",然后在新窗口点击图片即可查看高清大图)
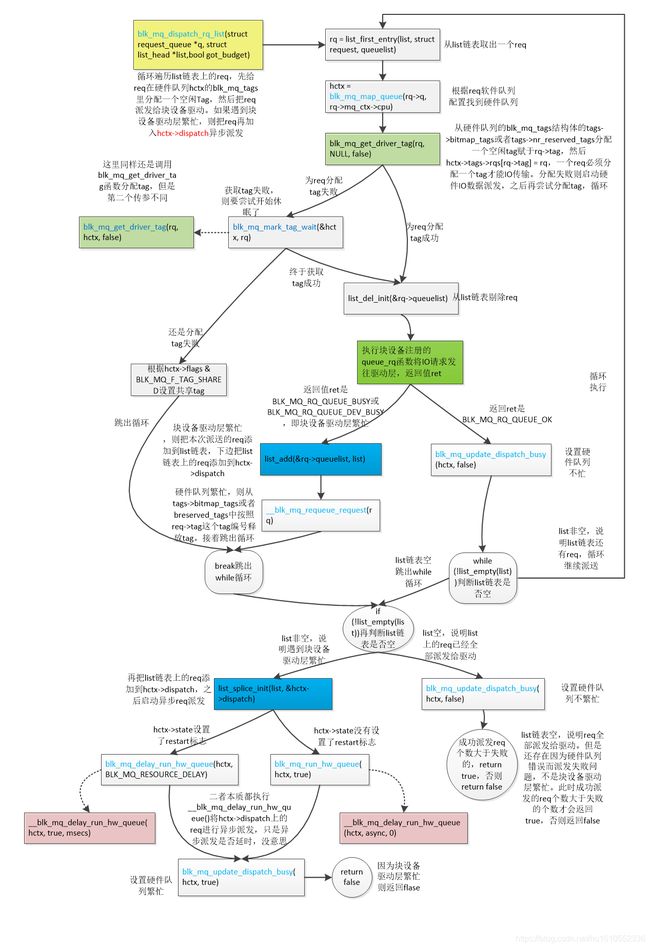
该函数流程相对就复杂多了,是各个队列上的req派发核心。
bool blk_mq_dispatch_rq_list(struct request_queue *q, struct list_head *list,
bool got_budget)
{
do {
//从list链表取出一个req
rq = list_first_entry(list, struct request, queuelist);
/*先根据rq->mq_ctx->cpu这个CPU编号从q->mq_map[cpu]找到硬件队列编号,再q->queue_hw_ctx
[硬件队列编号]返回硬件队列唯一的blk_mq_hw_ctx结构体,每个CPU都对应了唯一的硬件队列*/
hctx = blk_mq_map_queue(rq->q, rq->mq_ctx->cpu);
/*从硬件队列的blk_mq_tags结构体的tags->bitmap_tags或者tags->nr_reserved_tags分配一个空闲tag赋于rq->tag,然后hctx->tags->rqs[rq->tag] = rq,一个req必须分配一个tag才能IO传输。分配失败则启动硬件IO数据派发,之后再尝试分配tag 。分配成功返回true,一般情况都分配成功*/
if (!blk_mq_get_driver_tag(rq, NULL, false)) {
//获取tag失败,则要尝试开始休眠了,再尝试分配,函数返回时获取tag就成功了
if (!blk_mq_mark_tag_wait(&hctx, rq)) {
blk_mq_put_dispatch_budget(hctx);
//如果还是分配tag失败,但是硬件队列有共享tag标志
if (hctx->flags & BLK_MQ_F_TAG_SHARED)
no_tag = true;//设置no_tag标志位
//直接跳出循环,不再进行req派发
break;
}
}
//从list链表剔除req
list_del_init(&rq->queuelist);
//根据req设置nvme_command,把req添加到q->timeout_list,并且启动q->timeout,把新的cmd复制到
nvmeq->sq_cmds[]队列。真正把req派发给驱动,启动硬件nvme硬件传输
ret = q->mq_ops->queue_rq(hctx, &bd);//nvme_queue_rq
switch (ret) {
case BLK_MQ_RQ_QUEUE_OK://传输完成,queued++表示传输完成的req
queued++;
break;
case BLK_MQ_RQ_QUEUE_BUSY:
case BLK_MQ_RQ_QUEUE_DEV_BUSY:
if (!list_empty(list)) {
nxt = list_first_entry(list, struct request, queuelist);
blk_mq_put_driver_tag(nxt);
}
//磁盘驱动硬件繁忙,要把本次派送的req再添加到list链表
list_add(&rq->queuelist, list);
//tags->bitmap_tags中按照req->tag把req的tag编号释放掉,与blk_mq_get_driver_tag()获取tag相反
__blk_mq_requeue_request(rq);
break;
default:
pr_err("blk-mq: bad return on queue: %d\n", ret);
case BLK_MQ_RQ_QUEUE_ERROR:
errors++;//下发给驱动时出错errors加1,这种情况一般不会有吧,除非磁盘硬件有问题了
rq->errors = -EIO;
blk_mq_end_request(rq, rq->errors);
break;
}
//如果磁盘驱动硬件繁忙,break跳出do...while循环
if (ret == BLK_MQ_RQ_QUEUE_BUSY || ret == BLK_MQ_RQ_QUEUE_DEV_BUSY)
break;
}while (!list_empty(list));
//list链表不空,说明磁盘驱动硬件繁忙,有部分req没有派送给驱动
if (!list_empty(list)) {
//这里是把list链表上没有派送给驱动的的req再移动到hctx->dispatch链表
list_splice_init(list, &hctx->dispatch);
/*因为硬件队列繁忙没有把hctx->dispatch上的req全部派送给驱动,则下边就再执行一次
blk_mq_run_hw_queue()或者blk_mq_delay_run_hw_queue(),再进行一次异步派发,就那几招,一个套路*/
//测试hctx->state是否设置了BLK_MQ_S_SCHED_RESTART位,blk_mq_sched_dispatch_requests()就会设置这个标志位
needs_restart = blk_mq_sched_needs_restart(hctx);
if (!needs_restart ||(no_tag && list_empty_careful(&hctx->dispatch_wait.task_list)))
//再次调用blk_mq_run_hw_queue()启动异步req派发true表示允许异步
blk_mq_run_hw_queue(hctx, true);
//如果设置了BLK_MQ_S_SCHED_RESTART标志位,并且磁盘驱动硬件繁忙导致了部分req没有来得及传输完
else if (needs_restart && (ret == BLK_MQ_RQ_QUEUE_BUSY))
//调用blk_mq_delay_run_hw_queue,但这次是异步传输,即开启kblockd_workqueue内核线程派发req
blk_mq_delay_run_hw_queue(hctx, BLK_MQ_RESOURCE_DELAY);
//更新hctx->dispatch_busy,设置硬件队列繁忙
blk_mq_update_dispatch_busy(hctx, true);
//返回false,说明硬件队列繁忙
return false;
}
if (ret == BLK_MQ_RQ_QUEUE_BUSY || ret == BLK_MQ_RQ_QUEUE_DEV_BUSY)
return false;//返回false表示硬件队列忙
/*queued表示成功派发给驱动的req个数,errors表示下发给驱动时出错的req个数,二者加起来不为0才返回true,这点有点不太理解,errors一般都是0*/
return (queued + errors) != 0;
}
还是先总结一下大体流程:list来自hctx->dispatch硬件派发队列、软件队列rq_list链表上、调度算法队列等req。遍历list上的req,先给req在硬件队列hctx的blk_mq_tags里分配一个空闲tag,然后调用磁盘驱动queue_rq函数派发req。任一个req要启动硬件传输前,都要从blk_mq_tags结构里得到一个空闲的tag。如果遇到磁盘驱动硬件繁忙,则要把这个派发失败的req再添加list链表,再把list链表上的所有req转移到hctx->dispatch队列,之后启动异步派发时再从hctx->dispatch链表上取出这些req派发。成功派发req返回true,遇到因busy导致req派发失败则返回flase。
可以发现一个规律,最终肯定调用磁盘驱动的queue_rq函数才能把req派送给磁盘驱动,然后才能进行磁盘数据传输。但是该函数有三个返回值,一是BLK_MQ_RQ_QUEUE_OK,表示派送req成功;BLK_MQ_RQ_QUEUE_DEV_BUSY或者BLK_MQ_RQ_QUEUE_BUSY,表示磁盘驱动硬件繁忙,则无法派送req,需要把req再放入hctx->dispatch链表,之后进行异步派发。异步派发最后还是执行blk_mq_dispatch_rq_list()函数。套路搞清楚了也没啥。
最好还剩下plug形式的req派送还没讲解,入口函数是blk_flush_plug_list()
3 req plug形式的派发
3.1 blk_flush_plug_list()派发plug->mq_list链表上的req
看流程图

void blk_flush_plug_list(struct blk_plug *plug, bool from_schedule)
{
if (!list_empty(&plug->mq_list))
blk_mq_flush_plug_list(plug, from_schedule);
if (list_empty(&plug->list))
return;
}
核心是执行blk_mq_flush_plug_list函数。
void blk_mq_flush_plug_list(struct blk_plug *plug, bool from_schedule)
{
LIST_HEAD(ctx_list);//ctx_list临时保存了当前进程plug->mq_list链表上的部分req
unsigned int depth;
//就是令list指向plug->mq_list的吧
list_splice_init(&plug->mq_list, &list);
//对plug->mq_list链表上的req进行排序吧,排序规则基于req的扇区起始地址
list_sort(NULL, &list, plug_ctx_cmp);
//循环直到plug->mq_list链表上的req空
while (!list_empty(&list))
{
//plug->mq_list取一个req
rq = list_entry_rq(list.next);
//从链表删除req
list_del_init(&rq->queuelist);
/*this_ctx是上一个req的软件队列,rq->mq_ctx是当前req的软件队列。二者软件队列相等则if不成立,只是
把req添加到局部ctx_list链表。如果二者软件队列不等,则执行if里边的blk_mq_sched_insert_requests把
局部ctx_list链表上的req进行派送。然后把局部ctx_list链表清空,重复上述循环*/
if (rq->mq_ctx != this_ctx)
{
if (this_ctx)
{
//派发this_ctx链表上的req
blk_mq_sched_insert_requests(this_q, this_ctx,&ctx_list,from_schedule);
//this_ctx赋值为req软件队列
this_ctx = rq->mq_ctx;
this_q = rq->q;
//遇到不同软件队列的req,depth清0
depth = 0;
}
}
depth++;
//把req添加到局部变量ctx_list链表,看着是向ctx_list插入一个req,depth深度就加1
list_add_tail(&rq->queuelist, &ctx_list);
}
/*如果plug->mq_list上的req,rq->mq_ctx都指向同一个软件队列,前边的blk_mq_sched_insert_requests
执行不了,则在这里执行一次,将ctx_list链表上的req进行派发。还有一种情况,是plug->mq_list链表上的
最后一个req也只能在这里派发*/
if (this_ctx) {
//派发this_ctx链表上的req
blk_mq_sched_insert_requests(this_q, this_ctx, &ctx_list,from_schedule);
}
}
先总结一下该函数核心流程:每次循环,取出plug->mq_list上的req,添加到ctx_list局部链表。如果每两次取出的req都属于一个软件队列,只是把这些req添加到局部ctx_list链表,该函数最后执行blk_mq_sched_insert_requests把ctx_list链表上的req进行派发。如果前后两次取出的req不属于一个软件队列,则立即执行blk_mq_sched_insert_requests()将ctx_list链表已经保存的req进行派发,然后把本次循环取出的req继续添加到ctx_list局部链表。
简单来说,blk_mq_sched_insert_requests()只会派发同一个软件队列上的req。该函数req的派发,如果有调度器,则把req先插入到IO算法队列;如果无调度器,会尝试执行blk_mq_try_issue_list_directly直接将req派发给磁盘设备驱动。最后再执行blk_mq_run_hw_queue()把剩余的因各种原因未派发的req进行同步或异步派发。
3.2 blk_mq_sched_insert_requests真正派发plug->mq_list链表上的req
函数流程图来了(高清大图查看方法:鼠标右键点击图片后,点击"在新标签页中打开图片",然后在新窗口点击图片即可查看高清大图)
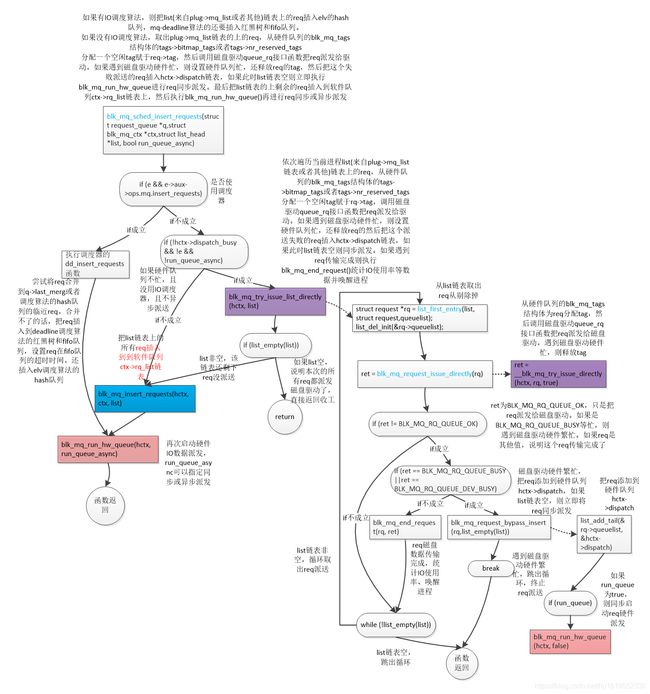
void blk_mq_sched_insert_requests(struct request_queue *q,
struct blk_mq_ctx *ctx,
struct list_head *list, bool run_queue_async)
{
if (e && e->aux->ops.mq.insert_requests) //使用调度器
{
/*尝试将req合并到q->last_merg或者调度算法的hash队列的临近req。合并不了的话,把req插入到deadline
调度算法的红黑树和fifo队列,设置req在fifo队列的超时时间。还插入elv调度算法的hash队列*/
e->aux->ops.mq.insert_requests(hctx, list, false);
}
else
{
//硬件队列不能忙,没用IO调度器,不能异步处理,if才成立
if (!hctx->dispatch_busy && !e && !run_queue_async) {
//将list链表上的req进行直接派发
blk_mq_try_issue_list_directly(hctx, list);
//如果list空,说明所有的req都派发磁盘驱动了,直接返回收工
if (list_empty(list))
return;
}
// 到这里,说明list链表上还有剩余的req没有派发硬件队列传输,则需把list链表上的剩下的所
//有req插入到到软件队列ctx->rq_list链表
blk_mq_insert_requests(hctx, ctx, list);
}
//再次启动硬件IO数据派发
blk_mq_run_hw_queue(hctx, run_queue_async);
}
总结一下函数整体流程:如果有IO调度算法,则把list(来自plug->mq_list)链表上的req插入elv的hash队列,mq-deadline算法的还要插入红黑树和fifo队列。如果没有使用IO调度算法,则执行blk_mq_try_issue_list_directly函数,在该函数中:取出list链表的上的req,从硬件队列的blk_mq_tags结构体的tags->bitmap_tags或者tags->nr_reserved_tags分配一个空闲tag赋于req->tag,然后调用磁盘驱动queue_rq接口函数把req派发给驱动。如果遇到磁盘驱动硬件忙,则设置硬件队列忙,还释放req的tag。然后把这个失败派送的req插入hctx->dispatch链表,此时如果list链表空则执行blk_mq_run_hw_queue同步派发req(这个过程见blk_mq_request_bypass_insert),接着就return返回了。
因为此时磁盘驱动硬件忙,不能再继续把list剩余的req再强制进行派发了,则执行blk_mq_insert_requests函数把这些剩余未派发的req插入到软件队列ctx->rq_list链表上,然后执行blk_mq_run_hw_queue再进行req同步或异步派发。下文重点介绍函数blk_mq_try_issue_list_directly。
void blk_mq_try_issue_list_directly(struct blk_mq_hw_ctx *hctx,struct list_head *list)
{
//list临时保存了当前进程plug->mq_list链表上的部分req,遍历该链表上的req
while (!list_empty(list))
{
//从plug->mq_list链表取出一个req
struct request *rq = list_first_entry(list, struct request,queuelist);
//从list链表剔除req
list_del_init(&rq->queuelist);
//真正req派送在这里
ret = blk_mq_request_issue_directly(rq);
/*如果ret为BLK_MQ_RQ_QUEUE_OK,说明只是把req派发给磁盘驱动。如果是BLK_MQ_RQ_QUEUE_BUSY或
者BLK_MQ_RQ_QUEUE_DEV_BUSY,则说明遇到磁盘驱动硬件繁忙,直接break。如果req是其他值,说明这个req传输
完成了,则执行blk_mq_end_request()进行IO统计*/
if (ret != BLK_MQ_RQ_QUEUE_OK)
{
if (ret == BLK_MQ_RQ_QUEUE_BUSY ||ret == BLK_MQ_RQ_QUEUE_DEV_BUSY)
{
//磁盘驱动硬件繁忙,把req添加到硬件队列hctx->dispatch队列,如果list链表空为true,则同步启动req硬件派发
blk_mq_request_bypass_insert(rq,list_empty(list));
//注意,磁盘驱动硬件的话,直接直接跳出循环,函数返回了
break;
}
//该req磁盘数据传输完成了,增加ios、ticks、time_in_queue、io_ticks、flight、sectors扇区数等使用
//计数。依次取出req->bio链表上所有req对应的bio,一个一个更新bio结构体成员数据,执行bio的回调函数。
//还更新req->__data_len和req->buffer。
blk_mq_end_request(rq, ret);
}
}
}
还是先整体总结一下函数要点:依次遍历list(来自plug->mq_list)链表上的req,执行blk_mq_request_issue_directly()派发该req。在该函数中,从硬件队列的blk_mq_tags结构体的tags->bitmap_tags或者tags->nr_reserved_tags分配一个空闲tag赋于rq->tag,调用磁盘驱动queue_rq接口函数把req派发给驱动。如果遇到磁盘驱动硬件忙,则设置硬件队列忙,还释放req的tag,然后把这个派送失败的req插入hctx->dispatch链表,此时如果list链表空则执行blk_mq_run_hw_queue同步派发req,之后就从blk_mq_request_issue_directly函数返回。如果遇到req传输完成则执行blk_mq_end_request()统计IO使用率等数据并唤醒进程。
blk_mq_request_issue_directly函数呢,调用__blk_mq_try_issue_directly()执行具体的req派发工作。
int blk_mq_request_issue_directly(struct request *rq)
{
//req所在的软件队列
struct blk_mq_ctx *ctx = rq->mq_ctx;
//与ctx->cpu这个CPU编号对应的硬件队列
struct blk_mq_hw_ctx *hctx = blk_mq_map_queue(rq->q, ctx->cpu);
//硬件队列加锁
hctx_lock(hctx, &srcu_idx);
ret = __blk_mq_try_issue_directly(hctx, rq, true);
hctx_unlock(hctx, srcu_idx);
}
__blk_mq_try_issue_directly函数在前一节介绍blk_mq_try_issue_directly函数时介绍过。这里只把它的核心流程再介绍一遍:从硬件队列的blk_mq_tags结构体的tags->bitmap_tags或者tags->nr_reserved_tags分配一个空闲tag赋于rq->tag,然后hctx->tags->rqs[rq->tag] = rq,一个req必须分配一个tag才能IO传输。分配失败则启动硬件IO数据派发,之后再尝试分配tag,循环。然后调用磁盘驱动queue_rq接口函数,根据req设置command,启动q->timeout定时器等等,将req直接派发磁盘硬件传输了。如果遇到磁盘驱动硬件忙,则设置硬件队列忙,还释放req的tag。
简单总结一下,进程plug->mq_list链表上的req派送,一个个是先执行blk_mq_try_issue_list_directly直接将req派送给磁盘驱动进行数据传输。如果遇到磁盘驱动硬件繁忙,还是要把req加入hctx->dispatch链表。接着还要把plug->mq_list链表上剩余未派发的req加入软件队列ctx->rq_list链表上。最后执行blk_mq_run_hw_queue()再把hctx->dispatch链表和ctx->rq_list链表上的req进行同步或者异步派发。
4 block层多队列req派发总结
经过前文介绍的req各种形式的派发形式,表面看着啰里啰嗦,实际关键点感觉并不多,所以还是总结一下。像blk_mq_try_issue_list_directly、__blk_mq_try_issue_directly这种direct 模式,是直接把req派发给磁盘设备驱动。剩余的就是各种队列的req派发:软件队列ctx->rq_list链表、硬件队列hctx->dispatch链表、IO调度算法队列的相关链表、req plug模式的plug->mq_list。
硬件队列hctx->dispatch链表,感觉它是个背锅侠,正常情况下它用不到。只有在req派发时,发现磁盘驱动硬件繁忙,暂时没空搭理该req,又不能不管,只能先把req添加到硬件队列hctx->dispatch链表。接着执行blk_mq_run_hw_queue类的函数,该函数会在磁盘驱动硬件空闲时,从hctx->dispatch链表取出刚才没来得及派发的req,再次尝试派发给磁盘设备驱动。
软件队列ctx->rq_list链表,向该链表插入req的情况是:发起bio请求过程的blk_mq_make_request()->blk_mq_queue_io();执行blk_mq_sched_insert_requests派发req时:情况1,如果硬件队列繁忙或者使用了调度器或者异步派发,不能执行blk_mq_try_issue_list_directly()直接将req派发给设备驱动的情况下,那就执行blk_mq_insert_requests()将派发req的临时list链表上的req插入到软件队列ctx->rq_list链表;情况2,硬件队列空闲且没有使用调度器且同步派发,则执行blk_mq_try_issue_list_directly()将临时list链表上的req派发给磁盘设备驱动。但派发过程遇到了磁盘驱动硬件繁忙,只能被迫返回,接着还是执行blk_mq_insert_requests()将list链表上剩下未派发的req插入到ctx->rq_list链表。之后执行blk_mq_run_hw_queue类函数,在磁盘驱动硬件空闲时,从软件队列ctx->rq_list链表取req,再次尝试派发给设备驱动。
IO调度算法队列的相关链表,这是执行设置了IO调度算法的情况下,肯定要先把派发的req插入的IO算法队列相关链表进行处理。它的派发见blk_mq_make_request()和blk_mq_sched_insert_requests()中调用的blk_mq_sched_insert_request函数。
req plug模式的plug->mq_list链表,这个还好。就是当前进程集聚了很多bio在plug->mq_list,然后一下次全部派发给磁盘设备驱动。它的发起函数是blk_flush_plug_list。基本原理是,先取出plug->mq_list链表上的req,如果设置了IO调度器,则把req插入到IO算法队列。否则,则先执行blk_mq_try_issue_list_directly()将这些req直接派发给磁盘设备驱动。如果无法直接派发给磁盘设备驱动,就先把req添加到软件队列ctx->rq_list链表,等稍后执行blk_mq_run_hw_queue类函数,再次尝试派发这些req。
5 block层多队列代码研究透还有路要走
谈了这么多,其实还并没有感觉到block层引入多队列情况下,每个CPU都分配一个软件队列,到底是怎么做到减少多进程多核之间抢占锁的。目前看代码只能发现很少用到锁,偶尔见到使用软件队列锁和硬件队列锁,但是很快就释放了。不像单队列时代,一把spin_lock锁加了很长时间,并且加锁的地方很多。感觉这些认知还比较肤浅,没有数据证据,估计得后期再深入研究一下,解开谜团。