《Java并发编程的艺术》第3章 Java内存模型
3.1.1 Java并发模型的两个关键问题
并发编程中,两个关键问题:线程通信以及线程同步
这里的线程是并发执行的活动实体。
通信是指线程以何种机制交换消息。机制有两种:共享内存(写读内存中的状态隐式通信)和消息传递(发送消息显式通信)。
同步是控制不同线程相对发生顺序的机制。共享内存模型里,同步是显示进行的,程序员必须指定某方法或代码互斥执行,消息传递模型里,消息的发送必须在消息接收之前,通信是隐式进行的。
3.1.2 Java 内存模型的抽象结构
所有实例,静态,数组元素存在堆中,局部变量,方法定义参数,异常处理器参数不会在线程间共享,不会有内存可见性问题,不受内存模型影响
Java线程之间通信由JMM控制,决定对一个线程对共享变量(在主内存中)写入何时被另一个线程看见。
线程间的共享变量存储在主内存中。
每个线程都有私有的本地内存,存着该线程用来读写共享变量的副本。
本地内存是JMM抽象概念,有缓存,写缓冲区,寄存器以及其他的硬件和编译器优化
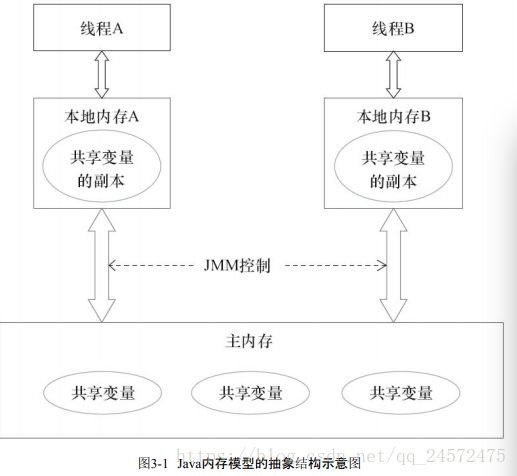
要通信遵循以下步骤:
- 线程A把本地内存A更新的共享变量更到主内存中。
线程B去主内存读取B更新过的共享变量
JMM通过控制主内存和线程的本地内存的交互,为程序员提供内存可见性保证
3.1.3 从源代码到指令序列的重排序
(写缓冲区只对自己的处理器可见)
为提高性能,编译器和处理器通常会对指令进行重排序。
- 编译器优化:不改变单线程程序的语义下
- 指令级并行:不存在数据依赖性
- 内存系统:处理器使用缓存和读写缓冲区,使得加载和存储像乱序执行
上述2,3同属处理器重排序(为保证内存可见性,内存屏障指令可以禁止特定的处理器重排序)
3.1.4 并发编程模型的分类
处理器对内存对读写顺序,不一定与实际发生对读写顺序一致。
(可能新数据刚写到本地内存,旧数据就被着急地取走了)
3.1.5 happens before简介
如果一个操作结果对另一个操作可见,两者必存在happens before关系
监视器锁规则:先解锁,再加锁
volatile规则:对volatile域的写,先于读
(要求前一个操作对后一个可见,且前操作顺序排在前面,先不论执行)
3.2.1 数据依赖性
重排序所不能撼动
两个操作访问同一个变量,且其中一个为写操作,则他们间存在数据依赖性。
这里只针对:单个处理器中执行的指令序列和单个线程中执行的操作。
3.2.2 as -if -serial 语义
不管怎么重排序,程序的执行结果不能被改变。编译器、runtime和处理器都必须遵守此语义。
给单线程程序员创建了一个幻觉:单线程程序是按程序顺序来执行的,无需担心可见性问题。
3.2.3 程序顺序规则
在不改变程序执行结果的前提下,尽可能提高并行度(JMM临界区可以重排序)
3.2.4 重排序对多线程的影响
操作1和操作2没有数据依赖关系,编译器和处理器可以对这两个操作重排序;同样,操作3和操作4无数据依赖关系,同上。比如,没说好借多少钱(声明),就同意借钱(flag==true),最后借出的钱和想得不一样就很自然了。
当代码中存在控制依赖性时,会影响指令序列执行的并行度。为此,编译器和处理器会采用猜测执行来克服控制相关性。执行代码B的处理器可以提前读取并计算a*a,然后把计算结果临时保存到一个重排序缓存中的硬件缓存中。重排序在这里破坏了多线程程序的语义!
3.3.2 顺序一致性内存模型
是被计算机科学家理想化的参考模型,有两大特性:
**一个线程中的所有操作必须按照程序的顺序来执行。
(不管程序是否同步)所有线程都只能看到一个单一的操作执行顺序。每个操作都必须原子执行且立刻对所有线程可见。**
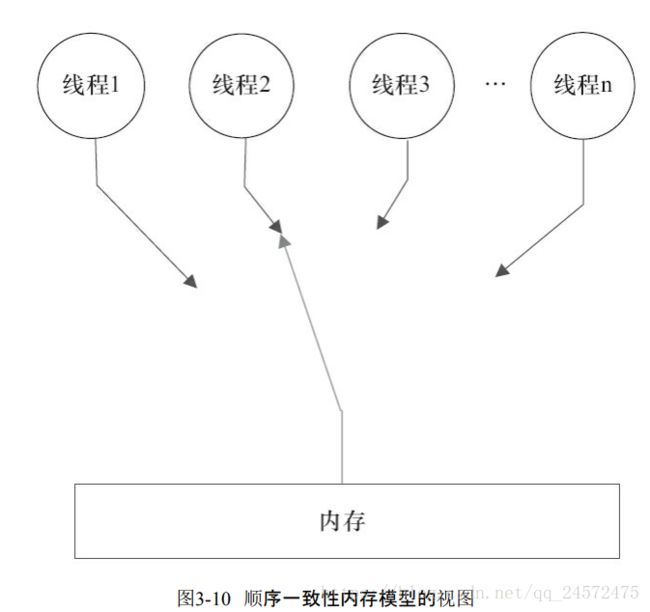
内存通过一个左右摆动的开关可以连接到任意一个线程。任意时刻最多一个线程可以连接到内存。
JMM中没有这个保证。当前线程和其他线程看到的操作执行顺序不一致。
3.4.1 volatile的特性
可见性:对一个volatile变量的读,总能看到任意线程对此变量最后的写入
原子性:对单个volatile变量的读写,具有原子性,复合操作没有原子性
3.4.4 volatile内存语义的实现
JMM根据编译器制定的规则表:
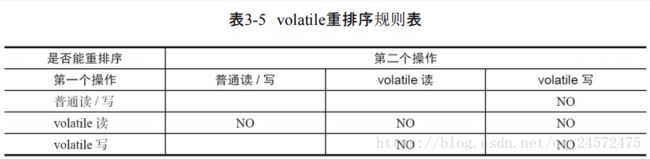
当第一个操作是volatile读或第二个操作是volatile写时,都不能重排序。
或分别为volatile写和volatile读时,不能重排序。
为防止重排序,编译器插入内存屏障:
具体为在volatile写前后插入StoreStore,StoreLoad;
在volatile读前后插入LoadLoad,LoadStore。
StoreLoad不能省略,因为第二个volatile写后,方法立即return,无法判断后面是否以volatile读或写。所以volatile写的开销比读大很多。
X86处理器仅会对写读作重排序
3.5.3 锁内存语义的实现
公平和非公平锁释放时,都要写一个volatile变量,公平锁获取时,首先会去读volatile变量,非公平锁获取时,首先用CAS更新volatile变量。
3.5.4 concurrent包的实现
通用化的源代码实现模式:
- 首先声明共享变量为volatile
- 然后使用CAS的原子条件更新来实现线程间的同步。
- 同时,配合以volatile的读写和CAS所具有的volatile读和写的内存语义来实现线程间的通信。
3.6.1 final域的重排序规则
- 在构造函数内对一个final域的写入,与随后把这个被构造对象的引用赋值给一个引用变量,这两个操作间不能重排序。
- 初次读一个包含final域对象的引用,与随后初次读这个final域,他们之间不能重排序。
写final域的重排序规则禁止把final域的写重排序到构造函数之外
编译器会在final域的写之后,构造函数return之前,插入一个Store Store屏障
读final域的重排序规则是,一个线程中,初次读对象引用与初次读对象包含的final域,JMM禁止处理器重排序这两个操作。
在构造函数内对一个final引用的对象成员域的写入,与随后在构造函数外把这个被构造对象的引用赋值给引用变量,这两个操作之间不能重排序。
final域的读写不会插入任何内存屏障
3.7.1 JMM的设计
程序员希望强内存模型,易于理解,易于编程
编译器和处理器希望弱内存模型,希望内存模型对他们的束缚越少越好,以做尽可能多的优化提高性能。
3.8 双重检查锁定与延迟初始化
双重检查锁定的错误在于,instance不为null时,instance引用的对象有可能还没有完成初始化。
创建对象可分为三步:
- 分配对象的内存空间
- 初始化对象
- 设置instance指向刚分配的内存地址
2,3可能被重排序,先分配空间,然后设置Instance指向分配的地址,然而此时还未初始化对象
但其实只要第4步:初次访问对象在初始化对象后面,单线程内的执行结果就没问题。
解决方法是:1.不允许2,3重排序 2.允许重排序,但不允许其他线程看到重排序
1.把 static Instance instance的声明加上volatile即可。(禁止2,3重排序)
2.
public class InstanceFactory{
private static class InstanceHolder{
public static Instance instance=new Instance();
}
public static Instace getInstance(){
return InstanceHolder.instance();
}
}