Linux进阶系列(二)——lscpu、htop、seq、shuf、sort
1. lscpu
lscpu 命令是Linux系统中用来显示关于CPU架构的信息的工具。它详细展示了CPU的相关信息,包括型号、核心数、架构类型、缓存大小等等。
1.1 物理CPU与逻辑CPU
物理CPU指的是实际存在于硬件系统上的中央处理单元。每个物理CPU都是一个独立的处理器芯片或处理器核心。在多核心处理器中,一个物理CPU可以包含多个核心,每个核心能够独立执行指令。例如,一个四核处理器有四个物理CPU核心,每个都能独立执行任务。
逻辑CPU,又称为虚拟CPU或线程,是超线程技术(Intel的Hyper-Threading技术)的产物。超线程允许每个物理CPU核心模拟两个或更多的逻辑CPU。这样,操作系统会认为有更多的CPU可用于任务,从而可以更有效地管理和调度进程和线程。例如,一个有四个物理核心的处理器,如果启用了超线程,可能会显示为有八个逻辑CPU。
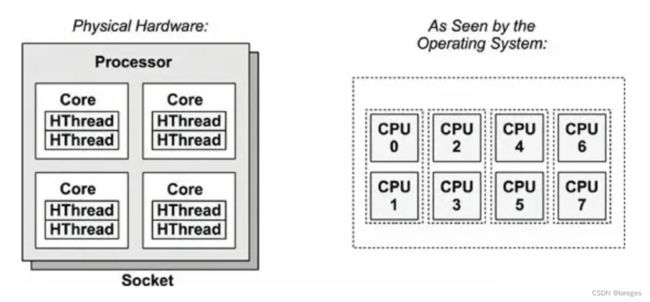
一言以蔽之,物理CPU是能看得见摸得着的,但逻辑CPU是虚拟的。
执行 lscpu 后重点关注以下四行:
CPU(s): 48
Thread(s) per core: 2
Core(s) per socket: 12
Socket(s): 2
其中 Socket(s) 是指物理CPU的数量,因为系统中有两个CPU插槽,每个插槽装有一个物理CPU。Core(s) per socket 表示每个物理CPU中的核心数。Thread(s) per core 是每个核心能够启动的超线程数量。CPU(s) 则是逻辑CPU的个数。不难发现有以下公式成立:
CPU(s) = Thread(s) per core × Core(s) per socket × Socket(s) \text{CPU(s)}=\text{Thread(s) per core}\times \text{Core(s) per socket}\times \text{Socket(s)} CPU(s)=Thread(s) per core×Core(s) per socket×Socket(s)
我们也可以简单执行 nproc 命令来查看逻辑CPU的个数。
2. top与htop
2.1 top
ps(process status)命令和 top(table of processes)命令都用于显示运行在Unix/Linux操作系统上的进程信息。不同之处在于,ps 显示一次性的进程信息,它捕捉的是命令执行时刻的快照,而 top 则显示持续更新的进程信息,它会不断刷新显示,提供实时的系统状态。
ps -ef 和 ps aux 都可用于显示所有进程的详细信息。两者的主要区别在于,ps -ef 是Standard(System V)风格的命令,这种风格的命令通常使用连字符 - 作为选项的前缀,并支持更多的选项和组合。而 ps aux 则是BSD风格的命令,通常不需要连字符 - 作为选项的前缀。
如果需要实时更新 ps 的输出,可采用 watch ps -ef 这样的语法。
回到正题,接下来讲解 top 命令的使用。
使用 top 的方法很简单,只需要在终端输入 top,然后按下回车即可,你大概会看到如下的界面:
top - 14:28:18 up 102 days, 21:16, 0 users, load average: 5.78, 6.98, 7.36
Tasks: 10 total, 1 running, 9 sleeping, 0 stopped, 0 zombie
%Cpu(s): 19.0 us, 0.3 sy, 0.0 ni, 80.6 id, 0.0 wa, 0.0 hi, 0.1 si, 0.0 st
MiB Mem : 450847.3 total, 9293.5 free, 27216.4 used, 414337.4 buff/cache
MiB Swap: 0.0 total, 0.0 free, 0.0 used. 419325.4 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1 root 20 0 14752 2760 2460 S 0.0 0.0 0:00.03 bash
696 root 20 0 717716 19512 4 S 0.0 0.0 2:59.17 supervisord
711 root 20 0 12172 4656 3812 S 0.0 0.0 0:00.01 sshd
712 root 20 0 439968 78508 21492 S 0.0 0.0 0:04.00 tensorboard
713 root 20 0 354340 88600 14040 S 0.0 0.0 0:06.48 jupyter-lab
714 root 20 0 2691952 209820 39464 S 0.0 0.0 0:13.32 autopanel
716 root 20 0 728180 14316 9648 S 0.0 0.0 0:02.19 proxy
752 root 20 0 351580 6512 4884 S 0.0 0.0 0:00.37 server
856 root 20 0 15216 4408 3768 S 0.0 0.0 0:00.21 bash
2481 root 20 0 17124 3856 3316 R 0.0 0.0 0:00.00 top
top 命令的输出信息主要包括了五大方面:
- 系统概况(第1行)
- 任务概况(第2行)
- CPU使用概况(第3行)
- 内存使用概况(第4、5行)
- 进程列表
2.1.1 系统概况
14:28:18:当前系统时间up 102 days, 21:16:系统已连续运行了102天21小时16分钟0 users:当前登录系统的用户数为0load average: 5.78, 6.98, 7.36:分别表示过去1分钟、5分钟和15分钟的平均负载。负载平均值是活跃进程的数量,这些值超过了CPU核心数时,表明系统可能过载
2.1.2 任务概况
10 total:当前总共有10个进程1 running:1个进程正在运行9 sleeping:9个进程处于休眠状态0 stopped:没有进程被停止0 zombie:没有僵尸进程
2.1.3 CPU使用概况
19.0 us:即User Space,用户空间占用了19.0%的CPU0.3 sy:即System Space,内核空间占用了0.3%的CPU0.0 ni:即Nice,改变优先级的进程占用了0.0%的CPU80.6 id:即Idle,80.6%的CPU时间处于空闲0.0 wa:即I/O Wait,等待I/O的CPU时间占0.0%0.0 hi:即Hardware IRQ,硬件中断占用了0.0%的CPU0.1 si:即Software IRQ,软件中断占用了0.1%的CPU0.0 st:即Steal Time,虚拟机偷取的时间占0.0%
2.1.4 内存使用概况
MiB Mem : 关于物理内存的使用情况(单位为MiB)
450847.3 total:总共有约450847.3 MiB的物理内存9293.5 free:空闲内存为9293.5 MiB27216.4 used:已使用27216.4 MiB内存414337.4 buff/cache:用作缓冲和缓存的内存约为414337.4 MiB
以上四条信息分别对应于执行了 free -h 后的四列:total、free、used、buff/cache。
MiB Swap: 关于交换空间的使用情况(单位为MiB)
0.0 total:没有配置交换空间或者交换空间未启用0.0 free:空闲的交换空间为0.0 MiB0.0 used:已使用的交换空间为0.0 MiB419325.4 avail Mem:估计可用于启动新应用程序的内存约为419325.4 MiB
2.1.5 进程列表
这部分显示了各个进程的详细信息:
PID:Process ID,进程的ID,具有唯一性USER:运行该进程的用户的用户名PR:Priority,进程的调度优先级。数字越小,优先级越高NI:Nice value, 一个影响进程调度优先级的值。正值表示较低的优先级,负值表示较高的优先级VIRT:Virtual,进程使用的虚拟内存总量,包括所有代码、数据和共享库,以及交换空间RES:Resident size,进程使用的、未被换出的物理内存大小SHR:Shared Memory,进程使用的共享内存大小S:Status,进程的状态。常见的状态有:R (running), S (sleeping), D (uninterruptible sleep), Z (zombie), T (stopped or traced)%CPU:进程使用的CPU时间百分比%MEM:进程使用的物理内存百分比TIME+:进程自启动以来占用的总CPU时间COMMAND:启动进程的命令
top 命令支持多种选项,如下列举了一些常见的选项:
-d <秒数>:设置屏幕刷新间隔。默认是3秒(可通过左上角看出),但你可以设置成任何你想要的值。-p <进程ID>:只监控特定的进程。-u <用户名>:只显示特定用户的进程。-n <次数>:更新的次数。如果不指定则默认为无限次更新(即持续监控),如果指定了,则更新了相应的次数之后会自动退出。-c:显示完整的命令行。
最常使用的是 top -c。
2.2 htop
类似地,在使用 htop 时,只需要在终端输入 htop,然后按下回车即可,你大概会看到如下的界面:
其中上方显示了所有逻辑CPU的负载情况,下方的进程列表和 top 命令的返回结果几乎相同。
htop 支持鼠标操作。
3. seq
seq 命令有点类似于Python的 range 函数,其使用语法如下:
seq start step stop
seq start stop
seq stop
不同于 range,这里是左闭右闭的。省略 step 时,step 默认为1。省略 start 时,start 也默认为1
seq 1 2 11
# 1
# 3
# 5
# 7
# 9
# 11
seq 3 7
# 3
# 4
# 5
# 6
# 7
seq 5
# 1
# 2
# 3
# 4
# 5
seq 命令也有一些选项可以使用。
-w 会使输出的所有数字具有相同的宽度,不足的部分会用前导零填充
seq -w 5 10
# 05
# 06
# 07
# 08
# 09
# 10
使用 -s 可以自定义数字之间的分隔符,默认是换行符
seq -s " " 5
# 1 2 3 4 5
seq -s ',' 5
# 1,2,3,4,5
还可以通过指定 -f 来达到 printf 样式的输出
seq -f "Number: %g" 1 3
# Number: 1
# Number: 2
# Number: 3
4. shuf
顾名思义,shuf 命令用于将给定的输入打乱并输出打乱后的结果,shuf 命令接受以下三种类型的输入:
- 文件:
shuf filename会打乱该文件的所有行。 - 标准输入:例如
echo -e "line1\nline2\nline3" | shuf。 - 数字范围:通过
-i选项来指定,左闭右闭,例如shuf -i 1-10。
shuf 会将打乱后的结果输出到标准输出,如下是一些示例:
shuf -i 1-10
# 9
# 3
# 1
# 6
# 4
# 10
# 2
# 5
# 8
# 7
echo -e "a\nb\nc\nd" | shuf
# d
# a
# c
# b
shuf 1.txt # 文件内容为:"1\n2\n3\n4"
# 4
# 1
# 3
# 2
如果不想输出完整的打乱结果而是仅仅输出其中的 n n n 行(即从输入中随机抽取 n n n 行),则可以指定 -n 选项:
shuf -i 1-10 -n 3
# 3
# 9
# 6
如果要想从一个文件中随机抽取 10 10 10 行并将结果保存到新的文件中,可执行:
shuf -n 10 old_filename > new_filename
当加了 -r 选项时,shuf 则会进行重复随机抽样,即输出的结果中可能会出现重复的元素:
shuf -r -i 1-10 -n 3
# 6
# 2
# 2
⚠️ 使用
-r时必须要加上-n来限制次数,不然会进入无限循环
还可以通过指定 -e 选项来将输入参数视为行:
shuf -e a b c d -n 3
# b
# d
# c
4.1 shuf的工作原理
当使用 shuf 命令时,如果不指定 -n 选项,则 shuf 会将输入完整地读入到内存中然后进行打乱,所采用的算法是 Fisher-Yates洗牌(Knuth洗牌)算法。
当指定了 -n 选项时,shuf 并不会将输入全部读入到内存中,而是采用蓄水池抽样(Reservoir Sampling)算法进行采样。
5. sort
顾名思义,sort 命令用于将给定的输入进行排序,sort 命令接受以下两种类型的输入:
- 文件:
sort filename会对纯文本文件中的所有行按照字典序进行升序排序。 - 标准输入:例如
echo -e "line1\nline2\nline3" | sort。
sort 会排序后的结果输出到标准输出,如下是一些示例:
echo -e "2\n11\n111" | sort
# 11
# 111
# 2
sort 1.txt # 文件内容为:"4\n3\n2\n1"
# 1
# 2
# 3
# 4
可以通过添加 -r 选项来进行降序排序:
echo -e '1\n3\n2\n4' | sort -r
# 4
# 3
# 2
# 1
通过指定 -m 可以将多个已排序的文件合并成一个排序后的文件:
sort -m 1.txt 2.txt 3.txt
sort 在排序时是会区分字母的大小写的,可以通过添加 -f 来忽略大小写。
sort -R 的作用和 shuf 类似,但是效率会低于 shuf。