ELK+kafka集群实战
ELK+Kafka集群
前言
前言
业务层可以直接写入到kafka队列中,不用担心elasticsearch的写入效率问题。
图示

Kafka
Apache kafka是消息中间件的一种,是一种分布式的,基于发布/订阅的消息系统。能实现一个为处理实时数据提供一个统一、高吞吐、低延迟的平台,且拥有分布式的,可划分的,冗余备份的持久性的日志服务等特点。
术语
1、kafka是一个消息队列服务器。kafka服务称为broker(中间人), 消息发送者称为producer(生产者), 消息接收者称为consumer(消费者);通常我们部署多个broker以提供高可用性的消息服务集群.典型的是3个broker;消息以topic的形式发送到broker,消费者订阅topic,实现按需取用的消费模式;创建topic需要指定replication-factor(复制数目, 通常=broker数目);每个topic可能有多个分区(partition), 每个分区的消息内容不会重复
2、kafka-broker-中间人
3、webserver/logstash-producer[prəˈdu:sə®]-消息生产者/消息发送者
Producer:
kafka集群中的任何一个broker都可以向producer提供metadata信息,这些metadata中包含"集群中存活的servers列表"/“partitions leader列表"等信息;
当producer获取到metadata信息之后, producer将会和Topic下所有partition leader保持socket连接;
消息由producer直接通过socket发送到broker,中间不会经过任何"路由层”,事实上,消息被路由到哪个partition上由producer客户端决定;比如可以采用"random"“key-hash”"轮询"等,如果一个topic中有多个partitions,那么在producer端实现"消息均衡分发"是必要的。
在producer端的配置文件中,开发者可以指定partition路由的方式。
Producer消息发送的应答机制设置发送数据是否需要服务端的反馈,有三个值0,1,-1
0:producer不会等待broker发送ack
1:当leader接收到消息之后发送ack
-1:当所有的follower都同步消息成功后发送ack
4、elasticsearch-consumer-消费者
5、logs-topic-话题
6、replication-facter-复制数目-中间人存储消息的副本数=broker数目
7、一个topic有多个分区partition
partition:
(1)、Partition:为了实现扩展性,一个非常大的topic可以分布到多个broker(即服务器)上,一个topic可以分为多个partition,每个partition是一个有序的队列。partition中的每条消息都会被分配一个有序的id(offset)。kafka只保证按一个partition中的顺序将消息发给consumer,不保证一个topic的整体(多个partition间)的顺序。
(2)、在kafka中,一个partition中的消息只会被group中的一个consumer消费(同一时刻);一个Topic中的每个partions,只会被一个consumer消费,不过一个consumer可以同时消费多个partitions中的消息。
实战
拓扑
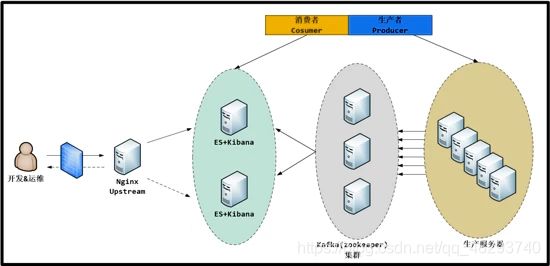
说明
说明
1、使用一台Nginx代理访问kibana的请求;
2、两台es组成es集群,并且在两台es上面都安装kibana;( 以下对elasticsearch简称es )
3、中间三台服务器就是我的kafka(zookeeper)集群啦; 上面写的 消费者/生产者 这是kafka(zookeeper)中的概念;
4、最后面的就是一大堆的生产服务器啦,上面使用的是logstash,
当然除了logstash也可以使用其他的工具来收集你的应用程序的日志,例如:Flume,Scribe,Rsyslog,Scripts……
角色
1、nginx-proxy(略):192.168.0.109
2、es1:192.168.0.110
3、es2:192.168.0.111
4、kafka1:192.168.0.112
5、kafka2:192.168.0.113
6、kafka3:192.168.0.115
7、webserver:192.168.0.114
软件说明
1、elasticsearch - 1.7.3.tar.gz
2、Logstash - 2.0.0.tar.gz
3、kibana - 4.1.2 - linux - x64 . tar . gz(略):
以上软件都可以从官网下载 : https : //www.elastic.co/downloads
4、java - 1.8.0 , nginx 采用 yum 安装
步骤
1、ES集群安装配置;
2、Logstash客户端配置(直接写入数据到ES集群,写入系统messages日志);
3、Kafka(zookeeper)集群配置;(Logstash写入数据到Kafka消息系统);
4、Kibana部署;
5、Nginx负载均衡Kibana请求;
演示
1、ES集群安装配置
es1:
(1)、安装java-1.8.0以及依赖包(每台服务器都安装JAVA)
# yum -y install epel-release
# yum -y install java-1.8.0 git wget lrzsz
#缓存这个java的包
#可以使用只下载不安装,缓存这些包
# yum -y install java-1.8.0 git wget lrzsz --downloadonly --downloaddir=./
#注释: --downloadonly 只下载不安装 downloaddir 目录
(2)、获取es软件包
# wget https://download.elastic.co/elasticsearch/elasticsearch/elasticsearch-1.7.3.tar.gz
# tar -xf elasticsearch-1.7.3.tar.gz -C /usr/local/
# ln -sv /usr/local/elasticsearch-1.7.3/ /usr/local/elasticsearch/
(3)、修改配置文件
# vim /usr/local/elasticsearch/config/elasticsearch.yml
cluster.name: es-cluster #组播的名称地址
node.name: "es-node1" #节点名称,不能和其他节点重复
node.master: true #节点能否被选举为master
node.data: true #节点是否存储数据
index.number_of_shards: 5 #索引分片的个数
index.number_of_replicas: 1 #分片的副本个数
path.conf: /usr/local/elasticsearch/config #配置文件的路径
path.data: /data/es/data #数据目录路径
path.work: /data/es/worker #工作目录路径
path.logs: /usr/local/elasticsearch/logs #日志文件路径
path.plugins: /data/es/plugins #插件路径
bootstrap.mlockall: true #内存不向swap交换
http.enabled: true #启用http
(4)、创建相关目录
# mkdir -p /data/es/{data,worker,plugins}
#注释:data:放数据的文件 worker:工作临时文件 plugins:插件 日志文件会自己建立
(5)、获取es服务管理脚本
#为了方便配置文件
# git clone https://github.com/elastic/elasticsearch-servicewrapper.git
# mv elasticsearch-servicewrapper/service/ /usr/local/elasticsearch/bin/
#在/etc/init.d/目录下,自动安装上es的管理脚本啦
# /usr/local/elasticsearch/bin/service/elasticsearch install
(6)、启动es,并检查服务是否正常
# systemctl start elasticsearch
# systemctl enable elasticsearch
# ss -nptl |grep -E "9200|9300"
LISTEN 0 50 :::9200 ::