6、LLaVA
简介
LLaVA官网
LLaVA使用Vicuna(LLaMA-2)作为LLM f ϕ ( ⋅ ) f_\phi(·) fϕ(⋅),使用预训练的CLIP图像编码器 ViT-L/14 g ( X v ) g(X_v) g(Xv)。

输入图像 X v X_v Xv,首先获取feature Z v = g ( X v ) Z_v=g(X_v) Zv=g(Xv)。考虑到最后一层Transformer前后的网格特征,采用简单的线性层连接图像特征到词嵌入空间,即使用一个可训练的投影矩阵 W 将 Z v Z_v Zv 转换为语言嵌入令牌 H v H_v Hv(与语言模型中词嵌入空间具有相同的维数)。
![]()
简单投影方案是轻量级的,它允许快速迭代以数据为中心的实验。还可以考虑更复杂的方案来连接图像和语言表征,例如Flamingo中的 gated cross-attention 和BLIP-2中的Q-former。
Training
对于每张图像 X v X_v Xv,生成多回合对话数据 ( X q 1 , X a 1 , ⋅ ⋅ ⋅ , X q T , X a T ) (X^1_q, X^1_a,···,X^T_q, X^T_a) (Xq1,Xa1,⋅⋅⋅,XqT,XaT),其中 T 为总回合数。将它们组织成一个序列,将所有的回答视为 assistant 响应,并将指令 X i n s t r u c t t X^t_{instruct} Xinstructt在第 t 个回合处为:

这导致了下表中所示的多模态指令跟随序列的统一格式。使用其原始的自回归训练目标对预测 token 执行LLM的指令调优。

具体来说,对于长度为 L 的序列,计算目标答案 X a X_a Xa的概率为:

其中,θ 为可训练参数, X i n s t r u c t , < i X_{instruct,}Xinstruct,<i 和 X a , < i X_{a,}Xa,<i分别为当前预测 token x i x_i xi之前所有回合的指令 tokens 和 回答 tokens。
对于上述公式中的条件,显式地添加了 X v X_v Xv,以强调图像是基于所有答案的事实,并且为了更好的可读性,省略了 X s y s t e m − m e s s a g e X_{system-message} Xsystem−message 和所有前面的 < S T O P >
对于LLaVA模型训练,考虑一个两阶段的指令调优过程。
Stage one:Pre-training for Feature Alignment
为了在 concept coverage 和 训练效率 之间取得平衡,将 CC3M 过滤到 595K 图像-文本对。将这些数据对转换为跟随指令的数据(如下图所示)。每个样本都可以视为单回合对话。为了构造输入 X i n s t r u c t X_{instruct} Xinstruct,对于图像 X v X_v Xv,随机采样一个问题 X q X_q Xq,这是一个语言指令,要求 assistant 对图像进行简要描述。最基本的预测答案 X a X_a Xa 是原始的标题。在训练中,保持视觉编码器和LLM权值不变,并最大化公式(3)的似然值,只有可训练参数 θ = W(投影矩阵)。这样,图像特征 H v H_v Hv 可以与预训练的LLM词嵌入对齐。
这个阶段可以理解为为冻结的LLM训练一个兼容的视觉标记器。

利用仅语言的GPT-4或ChatGPT作为强大的教师(两者都只接受文本作为输入),以创建包含视觉内容的指令跟随数据。
具体来说,为了将图像编码为其视觉特征以提示纯文本GPT,使用两种类型的符号表示:
- 通常从不同角度描述视觉场景的字幕;
- 边界框通常对场景中的物体进行定位,每个边界框对物体概念及其空间位置进行编码。
Stage two:Fine-tuning End-to-End.
保持视觉编码器权值不变,并不断更新投影层和LLM的预训练权值;即,在公式(3)中,可训练的参数是θ = {W, φ}。
考虑两个具体的用例场景:
-
Multimodal Chatbot.通过对158K语言图像指令跟踪数据进行微调来开发聊天机器人。在这三种类型的响应中,会话是多回合的,而其他两种是单回合的。它们在训练中被统一采样。
-
Science QA.在ScienceQA基准上研究,这是第一个大规模的多模态科学问题数据集,它用详细的讲座和解释注释了答案。每个问题都以自然语言或图像的形式提供上下文。该 assistant 以自然语言提供推理过程,并从多个选项中选择答案。对于(2)中的训练,将数据组织为单回合对话,问题和上下文作为 X i n s t r u c t X_{instruct} Xinstruct,推理和答案作为 X a X_a Xa。
模型搭建
github
环境搭建
- Clone this repository and navigate to LLaVA folder
git clone https://github.com/haotian-liu/LLaVA.git
cd LLaVA
- Install Package
conda create -n llava python=3.10 -y
conda activate llava
pip install --upgrade pip # enable PEP 660 support
pip install -e .
- Install additional packages for training cases
pip install -e ".[train]"
pip install flash-attn --no-build-isolation
下载预训练权重
liuhaotian/llava-v1.5-13b 权重
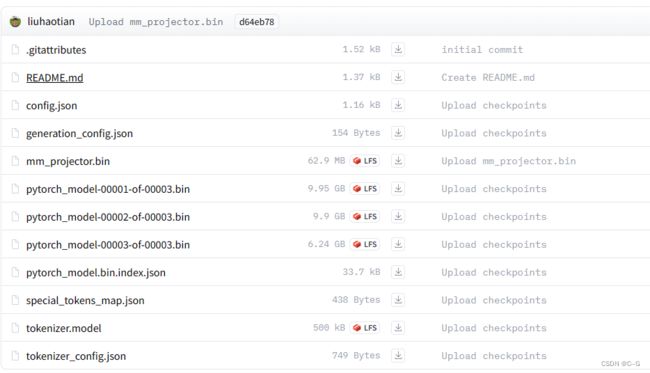
sudo apt-get install git-lfs
git init
# Make sure you have git-lfs installed (https://git-lfs.com)
git lfs install
git clone https://huggingface.co/liuhaotian/llava-v1.5-13b
# if you want to clone without large files – just their pointers
# prepend your git clone with the following env var:
GIT_LFS_SKIP_SMUDGE=1
加载模型
# 分词器
tokenizer = AutoTokenizer.from_pretrained(model_base, use_fast=False)
# 配置文件
cfg_pretrained = AutoConfig.from_pretrained(model_base) # config.json
# 主model
model = LlavaLlamaForCausalLM.from_pretrained(model_base, low_cpu_mem_usage=True, config=cfg_pretrained, **kwargs)
# 加载 图像映射token 的权重
mm_projector_weights = torch.load(os.path.join(model_base, 'mm_projector.bin'), map_location='cpu')
mm_projector_weights = {k: v.to(torch.float16) for k, v in mm_projector_weights.items()}
model.load_state_dict(mm_projector_weights, strict=False)
# 是否修改input embedding
mm_use_im_start_end = getattr(model.config, "mm_use_im_start_end", False) # False
mm_use_im_patch_token = getattr(model.config, "mm_use_im_patch_token", True)# False
if mm_use_im_patch_token:
tokenizer.add_tokens([DEFAULT_IMAGE_PATCH_TOKEN], special_tokens=True)
if mm_use_im_start_end:
tokenizer.add_tokens([DEFAULT_IM_START_TOKEN, DEFAULT_IM_END_TOKEN], special_tokens=True)
model.resize_token_embeddings(len(tokenizer))
# 加载CLIP 图像编码器
# LlavaMetaForCausalLM.get_vision_tower() --> LlavaLlamaForCausalLM.get_model() --> LlavaMetaModel.get_vision_tower()
vision_tower = model.get_vision_tower()
if not vision_tower.is_loaded:
vision_tower.load_model()
vision_tower.to(device=device, dtype=torch.float16)
image_processor = vision_tower.image_processor
if hasattr(model.config, "max_sequence_length"):
context_len = model.config.max_sequence_length
else:
context_len = 2048
tokenizer, model, image_processor, context_len
config.json
{
"_name_or_path": "llava-v1.5-13b",
"architectures": [
"LlavaLlamaForCausalLM"
],
"bos_token_id": 1,
"eos_token_id": 2,
"freeze_mm_mlp_adapter": false,
"freeze_mm_vision_resampler": false,
"hidden_act": "silu",
"hidden_size": 5120,
"image_aspect_ratio": "pad",
"initializer_range": 0.02,
"intermediate_size": 13824,
"max_length": 4096,
"max_position_embeddings": 4096,
"mm_hidden_size": 1024,
"mm_projector_type": "mlp2x_gelu",
"mm_resampler_type": null,
"mm_use_im_patch_token": false,
"mm_use_im_start_end": false,
"mm_vision_select_feature": "patch",
"mm_vision_select_layer": -2,
"mm_vision_tower": "openai/clip-vit-large-patch14-336",
"model_type": "llava",
"num_attention_heads": 40,
"num_hidden_layers": 40,
"num_key_value_heads": 40,
"pad_token_id": 0,
"pretraining_tp": 1,
"rms_norm_eps": 1e-05,
"rope_scaling": null,
"tie_word_embeddings": false,
"torch_dtype": "float16",
"transformers_version": "4.31.0",
"tune_mm_mlp_adapter": false,
"tune_mm_vision_resampler": false,
"unfreeze_mm_vision_tower": false,
"use_cache": true,
"use_mm_proj": true,
"vocab_size": 32000
}
主model
LlavaLlamaForCausalLM
图像编码器+映射+大NLP
class LlavaConfig(LlamaConfig):
model_type = "llava"
# Llama NLP 模型 图像编码器 映射
class LlavaLlamaModel(LlavaMetaModel, LlamaModel):
config_class = LlavaConfig
def __init__(self, config: LlamaConfig):
super(LlavaLlamaModel, self).__init__(config)
# 主模型
class LlavaLlamaForCausalLM(LlamaForCausalLM, LlavaMetaForCausalLM):
config_class = LlavaConfig
def __init__(self, config):
super(LlamaForCausalLM, self).__init__(config)
# Llama NLP 模型 图像编码器 映射
self.model = LlavaLlamaModel(config)
self.pretraining_tp = config.pretraining_tp # 1
self.vocab_size = config.vocab_size # 32000
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False) # 5120 3200
# Initialize weights and apply final processing
self.post_init()
def get_model(self):
return self.model
def forward(
self,
input_ids: torch.LongTensor = None,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.LongTensor] = None,
past_key_values: Optional[List[torch.FloatTensor]] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
labels: Optional[torch.LongTensor] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
images: Optional[torch.FloatTensor] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple, CausalLMOutputWithPast]:
if inputs_embeds is None:
(
input_ids,
position_ids,
attention_mask,
past_key_values,
inputs_embeds,
labels
) = self.prepare_inputs_labels_for_multimodal(
input_ids,
position_ids,
attention_mask,
past_key_values,
labels,
images
)
return super().forward(
input_ids=input_ids,
attention_mask=attention_mask,
position_ids=position_ids,
past_key_values=past_key_values,
inputs_embeds=inputs_embeds,
labels=labels,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict
)
def prepare_inputs_for_generation(self, input_ids, past_key_values=None, inputs_embeds=None, **kwargs):
images = kwargs.pop("images", None)
_inputs = super().prepare_inputs_for_generation(
input_ids, past_key_values=past_key_values, inputs_embeds=inputs_embeds, **kwargs
)
if images is not None:
_inputs['images'] = images
return _inputs
AutoConfig.register("llava", LlavaConfig)
AutoModelForCausalLM.register(LlavaConfig, LlavaLlamaForCausalLM)
图像编码器
LlavaMetaModel
class LlavaMetaModel:
def __init__(self, config):
super(LlavaMetaModel, self).__init__(config)
if hasattr(config, "mm_vision_tower"):
# clip 图像编码器
self.vision_tower = build_vision_tower(config, delay_load=True)
# 图像特征映射到token
self.mm_projector = build_vision_projector(config)
def get_vision_tower(self):
vision_tower = getattr(self, 'vision_tower', None)
if type(vision_tower) is list:
vision_tower = vision_tower[0]
return vision_tower
def initialize_vision_modules(self, model_args, fsdp=None):
vision_tower = model_args.vision_tower
mm_vision_select_layer = model_args.mm_vision_select_layer
mm_vision_select_feature = model_args.mm_vision_select_feature
pretrain_mm_mlp_adapter = model_args.pretrain_mm_mlp_adapter
self.config.mm_vision_tower = vision_tower
if self.get_vision_tower() is None:
vision_tower = build_vision_tower(model_args)
if fsdp is not None and len(fsdp) > 0:
self.vision_tower = [vision_tower]
else:
self.vision_tower = vision_tower
else:
if fsdp is not None and len(fsdp) > 0:
vision_tower = self.vision_tower[0]
else:
vision_tower = self.vision_tower
vision_tower.load_model()
self.config.use_mm_proj = True
self.config.mm_projector_type = getattr(model_args, 'mm_projector_type', 'linear')
self.config.mm_hidden_size = vision_tower.hidden_size
self.config.mm_vision_select_layer = mm_vision_select_layer
self.config.mm_vision_select_feature = mm_vision_select_feature
if getattr(self, 'mm_projector', None) is None:
self.mm_projector = build_vision_projector(self.config)
else:
# In case it is frozen by LoRA
for p in self.mm_projector.parameters():
p.requires_grad = True
if pretrain_mm_mlp_adapter is not None:
mm_projector_weights = torch.load(pretrain_mm_mlp_adapter, map_location='cpu')
def get_w(weights, keyword):
return {k.split(keyword + '.')[1]: v for k, v in weights.items() if keyword in k}
self.mm_projector.load_state_dict(get_w(mm_projector_weights, 'mm_projector'))
clip 图像编码器
build_vision_tower
def build_vision_tower(vision_tower_cfg, **kwargs):
# openai/clip-vit-large-patch14-336
vision_tower = getattr(vision_tower_cfg, 'mm_vision_tower', getattr(vision_tower_cfg, 'vision_tower', None))
is_absolute_path_exists = os.path.exists(vision_tower)
if is_absolute_path_exists or vision_tower.startswith("openai") or vision_tower.startswith("laion"):
return CLIPVisionTower(vision_tower, args=vision_tower_cfg, **kwargs)
raise ValueError(f'Unknown vision tower: {vision_tower}')
CLIPVisionTower
class CLIPVisionTower(nn.Module):
def __init__(self, vision_tower, args, delay_load=False):
super().__init__()
self.is_loaded = False
self.vision_tower_name = vision_tower
self.select_layer = args.mm_vision_select_layer
self.select_feature = getattr(args, 'mm_vision_select_feature', 'patch')
if not delay_load:
self.load_model()
else:
self.cfg_only = CLIPVisionConfig.from_pretrained(self.vision_tower_name)
def feature_select(self, image_forward_outs):
# 从前向传播的输出中获取隐藏状态(特征表示)
image_features = image_forward_outs.hidden_states[self.select_layer]
# 根据选择的特征进行处理
if self.select_feature == 'patch':
# 选择除了第一个位置(CLS位置)之外的所有位置的特征
image_features = image_features[:, 1:]
elif self.select_feature == 'cls_patch':
# 选择所有位置的特征
image_features = image_features
else:
raise ValueError(f'Unexpected select feature: {self.select_feature}')
return image_features
@torch.no_grad()
def forward(self, images):
if type(images) is list:
image_features = []
for image in images:
image_forward_out = self.vision_tower(image.to(device=self.device, dtype=self.dtype).unsqueeze(0),
output_hidden_states=True)
image_feature = self.feature_select(image_forward_out).to(image.dtype)
image_features.append(image_feature)
else:
# 对单个图像进行前向传播,获取隐藏状态
image_forward_outs = self.vision_tower(images.to(device=self.device, dtype=self.dtype),
output_hidden_states=True)
# 从隐藏状态中选择特征
image_features = self.feature_select(image_forward_outs).to(images.dtype)
return image_features
@torch.no_grad()
def forward(self, images):
if type(images) is list:
image_features = []
for image in images:
image_forward_out = self.vision_tower(image.to(device=self.device, dtype=self.dtype).unsqueeze(0), output_hidden_states=True)
image_feature = self.feature_select(image_forward_out).to(image.dtype)
image_features.append(image_feature)
else:
image_forward_outs = self.vision_tower(images.to(device=self.device, dtype=self.dtype), output_hidden_states=True)
image_features = self.feature_select(image_forward_outs).to(images.dtype)
return image_features
@property
def dummy_feature(self):
return torch.zeros(1, self.hidden_size, device=self.device, dtype=self.dtype)
@property
def dtype(self):
return self.vision_tower.dtype
@property
def device(self):
return self.vision_tower.device
@property
def config(self):
if self.is_loaded:
return self.vision_tower.config
else:
return self.cfg_only
@property
def hidden_size(self):
return self.config.hidden_size
@property
def num_patches(self):
return (self.config.image_size // self.config.patch_size) ** 2
图像特征映射到token
build_vision_projector
def build_vision_projector(config, delay_load=False, **kwargs):
projector_type = getattr(config, 'mm_projector_type', 'linear')
if projector_type == 'linear':
# mm_hidden_size:1024
# hidden_size 5120
return nn.Linear(config.mm_hidden_size, config.hidden_size)
mlp_gelu_match = re.match(r'^mlp(\d+)x_gelu$', projector_type)
if mlp_gelu_match:
mlp_depth = int(mlp_gelu_match.group(1))
modules = [nn.Linear(config.mm_hidden_size, config.hidden_size)]
for _ in range(1, mlp_depth):
modules.append(nn.GELU())
modules.append(nn.Linear(config.hidden_size, config.hidden_size))
return nn.Sequential(*modules)
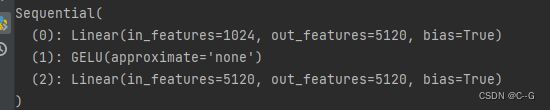
GELU激活函数

研究者表明,收到dropout、ReLU等机制的影响,它们都希望将不重要的激活信息规整为0,我们可以理解为,对于输入的值,我们根据它的情况乘上1或者0,更数学一点的描述是,对于每一个输入x,其服从标准的正太分布N(0,1) ,它会乘上一个伯努利分布 B e r n o u l l i ( ϕ ( x ) ) Bernoulli(\phi(x)) Bernoulli(ϕ(x)) ,其中, KaTeX parse error: Undefined control sequence: \leqx at position 12: \phi(x)=P(X\̲l̲e̲q̲x̲) 。
GELU :高斯误差线性单元激活函数,随着x的降低,它被归零的概率会升高。对于ReLU来说,这个界限就是0,输入少于零就会被归为0,这一类激活函数,不仅保留了概率性,同时也保留了对输入的依赖性。
在最近的Transformer模型(谷歌的BERT和OpenAI的GPT-2)中得到了应用,GELU的论文来自2016年,但是最近才引起关注,这种激活函数的形式为:

一般情况下会使用:

可得出来,这就是某些函数(比如双曲正切函数tanh)与近似数值的组合,详细的介绍可以参看下面的链接:
On the GELU Activation Function
我们可以看看GELU到底长什么样子,其函数图像(左)及其导数图像(右)如下图所示:

主模型功能实现类(重点)
class LlavaMetaForCausalLM(ABC):
@abstractmethod
def get_model(self):
pass
def get_vision_tower(self):
return self.get_model().get_vision_tower()
def encode_images(self, images):
image_features = self.get_model().get_vision_tower()(images)
image_features = self.get_model().mm_projector(image_features)
return image_features
def prepare_inputs_labels_for_multimodal(
self, input_ids, position_ids, attention_mask, past_key_values, labels, images
):
vision_tower = self.get_vision_tower()
if vision_tower is None or images is None or input_ids.shape[1] == 1:
if past_key_values is not None and vision_tower is not None and images is not None and input_ids.shape[1] == 1:
target_shape = past_key_values[-1][-1].shape[-2] + 1
attention_mask = torch.cat((attention_mask, torch.ones(
(attention_mask.shape[0], target_shape - attention_mask.shape[1]),
dtype=attention_mask.dtype,
device=attention_mask.device
)), dim=1)
position_ids = torch.sum(attention_mask, dim=1).unsqueeze(-1) - 1
return input_ids, position_ids, attention_mask, past_key_values, None, labels
if type(images) is list or images.ndim == 5:
concat_images = torch.cat([image for image in images], dim=0)
image_features = self.encode_images(concat_images)
split_sizes = [image.shape[0] for image in images]
image_features = torch.split(image_features, split_sizes, dim=0)
image_features = [x.flatten(0, 1).to(self.device) for x in image_features]
else:
image_features = self.encode_images(images).to(self.device)
# TODO: image start / end is not implemented here to support pretraining.
if getattr(self.config, 'tune_mm_mlp_adapter', False) and getattr(self.config, 'mm_use_im_start_end', False):
raise NotImplementedError
# Let's just add dummy tensors if they do not exist,
# it is a headache to deal with None all the time.
# But it is not ideal, and if you have a better idea,
# please open an issue / submit a PR, thanks.
_labels = labels
_position_ids = position_ids
_attention_mask = attention_mask
if attention_mask is None:
attention_mask = torch.ones_like(input_ids, dtype=torch.bool)
else:
attention_mask = attention_mask.bool()
if position_ids is None:
position_ids = torch.arange(0, input_ids.shape[1], dtype=torch.long, device=input_ids.device)
if labels is None:
labels = torch.full_like(input_ids, IGNORE_INDEX)
# remove the padding using attention_mask -- TODO: double check
input_ids = [cur_input_ids[cur_attention_mask] for cur_input_ids, cur_attention_mask in zip(input_ids, attention_mask)]
labels = [cur_labels[cur_attention_mask] for cur_labels, cur_attention_mask in zip(labels, attention_mask)]
new_input_embeds = []
new_labels = []
cur_image_idx = 0
for batch_idx, cur_input_ids in enumerate(input_ids):
num_images = (cur_input_ids == IMAGE_TOKEN_INDEX).sum()
# 没有图像标记
if num_images == 0:
cur_image_features = image_features[cur_image_idx]
cur_input_embeds_1 = self.get_model().embed_tokens(cur_input_ids)
# 连接文本嵌入和空的图像特征(占位符,确保张量的维度一致性)
cur_input_embeds = torch.cat([cur_input_embeds_1, cur_image_features[0:0]], dim=0)
new_input_embeds.append(cur_input_embeds)
new_labels.append(labels[batch_idx])
cur_image_idx += 1
continue
# 存在图像标记
## 分割成不包含图像标记的子序列
image_token_indices = [-1] + torch.where(cur_input_ids == IMAGE_TOKEN_INDEX)[0].tolist() + [cur_input_ids.shape[0]]
cur_input_ids_noim = []
cur_labels = labels[batch_idx]
cur_labels_noim = []
for i in range(len(image_token_indices) - 1):
cur_input_ids_noim.append(cur_input_ids[image_token_indices[i]+1:image_token_indices[i+1]])
cur_labels_noim.append(cur_labels[image_token_indices[i]+1:image_token_indices[i+1]])
## 计算每个子序列的长度,用于后续的嵌入操作
split_sizes = [x.shape[0] for x in cur_labels_noim]
## 对不包含图像标记的文本标识符进行嵌入操作
cur_input_embeds = self.get_model().embed_tokens(torch.cat(cur_input_ids_noim))
## 将嵌入结果按照子序列长度切分
cur_input_embeds_no_im = torch.split(cur_input_embeds, split_sizes, dim=0)
# 构建新的嵌入和标签列表
cur_new_input_embeds = []
cur_new_labels = []
for i in range(num_images + 1):
cur_new_input_embeds.append(cur_input_embeds_no_im[i])
cur_new_labels.append(cur_labels_noim[i])
# 添加相应的图像特征,并用 IGNORE_INDEX 填充对应的标签
if i < num_images:
cur_image_features = image_features[cur_image_idx]
cur_image_idx += 1
cur_new_input_embeds.append(cur_image_features)
cur_new_labels.append(torch.full((cur_image_features.shape[0],), IGNORE_INDEX, device=cur_labels.device, dtype=cur_labels.dtype))
cur_new_input_embeds = torch.cat(cur_new_input_embeds)
cur_new_labels = torch.cat(cur_new_labels)
new_input_embeds.append(cur_new_input_embeds)
new_labels.append(cur_new_labels)
# Truncate sequences to max length as image embeddings can make the sequence longer
tokenizer_model_max_length = getattr(self.config, 'tokenizer_model_max_length', None)
if tokenizer_model_max_length is not None:
new_input_embeds = [x[:tokenizer_model_max_length] for x in new_input_embeds]
new_labels = [x[:tokenizer_model_max_length] for x in new_labels]
# 对输入的嵌入进行填充,使得它们具有相同的长度
# Combine them
max_len = max(x.shape[0] for x in new_input_embeds)
batch_size = len(new_input_embeds)
new_input_embeds_padded = []
new_labels_padded = torch.full((batch_size, max_len), IGNORE_INDEX, dtype=new_labels[0].dtype, device=new_labels[0].device)
attention_mask = torch.zeros((batch_size, max_len), dtype=attention_mask.dtype, device=attention_mask.device)
position_ids = torch.zeros((batch_size, max_len), dtype=position_ids.dtype, device=position_ids.device)
for i, (cur_new_embed, cur_new_labels) in enumerate(zip(new_input_embeds, new_labels)):
cur_len = cur_new_embed.shape[0]
if getattr(self.config, 'tokenizer_padding_side', 'right') == "left":
new_input_embeds_padded.append(torch.cat((
torch.zeros((max_len - cur_len, cur_new_embed.shape[1]), dtype=cur_new_embed.dtype, device=cur_new_embed.device),
cur_new_embed
), dim=0))
if cur_len > 0:
new_labels_padded[i, -cur_len:] = cur_new_labels
attention_mask[i, -cur_len:] = True
position_ids[i, -cur_len:] = torch.arange(0, cur_len, dtype=position_ids.dtype, device=position_ids.device)
else:
new_input_embeds_padded.append(torch.cat((
cur_new_embed,
torch.zeros((max_len - cur_len, cur_new_embed.shape[1]), dtype=cur_new_embed.dtype, device=cur_new_embed.device)
), dim=0))
if cur_len > 0:
new_labels_padded[i, :cur_len] = cur_new_labels
attention_mask[i, :cur_len] = True
position_ids[i, :cur_len] = torch.arange(0, cur_len, dtype=position_ids.dtype, device=position_ids.device)
new_input_embeds = torch.stack(new_input_embeds_padded, dim=0)
if _labels is None:
new_labels = None
else:
new_labels = new_labels_padded
if _attention_mask is None:
attention_mask = None
else:
attention_mask = attention_mask.to(dtype=_attention_mask.dtype)
if _position_ids is None:
position_ids = None
return None, position_ids, attention_mask, past_key_values, new_input_embeds, new_labels
def initialize_vision_tokenizer(self, model_args, tokenizer):
if model_args.mm_use_im_patch_token:
tokenizer.add_tokens([DEFAULT_IMAGE_PATCH_TOKEN], special_tokens=True)
self.resize_token_embeddings(len(tokenizer))
if model_args.mm_use_im_start_end:
num_new_tokens = tokenizer.add_tokens([DEFAULT_IM_START_TOKEN, DEFAULT_IM_END_TOKEN], special_tokens=True)
self.resize_token_embeddings(len(tokenizer))
if num_new_tokens > 0:
input_embeddings = self.get_input_embeddings().weight.data
output_embeddings = self.get_output_embeddings().weight.data
input_embeddings_avg = input_embeddings[:-num_new_tokens].mean(
dim=0, keepdim=True)
output_embeddings_avg = output_embeddings[:-num_new_tokens].mean(
dim=0, keepdim=True)
input_embeddings[-num_new_tokens:] = input_embeddings_avg
output_embeddings[-num_new_tokens:] = output_embeddings_avg
if model_args.tune_mm_mlp_adapter:
for p in self.get_input_embeddings().parameters():
p.requires_grad = True
for p in self.get_output_embeddings().parameters():
p.requires_grad = False
if model_args.pretrain_mm_mlp_adapter:
mm_projector_weights = torch.load(model_args.pretrain_mm_mlp_adapter, map_location='cpu')
embed_tokens_weight = mm_projector_weights['model.embed_tokens.weight']
assert num_new_tokens == 2
if input_embeddings.shape == embed_tokens_weight.shape:
input_embeddings[-num_new_tokens:] = embed_tokens_weight[-num_new_tokens:]
elif embed_tokens_weight.shape[0] == num_new_tokens:
input_embeddings[-num_new_tokens:] = embed_tokens_weight
else:
raise ValueError(f"Unexpected embed_tokens_weight shape. Pretrained: {embed_tokens_weight.shape}. Current: {input_embeddings.shape}. Numer of new tokens: {num_new_tokens}.")
elif model_args.mm_use_im_patch_token:
if model_args.tune_mm_mlp_adapter:
for p in self.get_input_embeddings().parameters():
p.requires_grad = False
for p in self.get_output_embeddings().parameters():
p.requires_grad = False
Trainging


两阶段训练超参数设置

训练就算了,pass
Finetuning
finetuning 才是主流,且有卡的情况。

Finetune LLaVA on Custom Datasets
json数据格式:A sample JSON for finetuning LLaVA for generating tag-style captions for Stable Diffusion
[
{
"id": "997bb945-628d-4724-b370-b84de974a19f",
"image": "part-000001/997bb945-628d-4724-b370-b84de974a19f.jpg",
"conversations": [
{
"from": "human",
"value": "\nWrite a prompt for Stable Diffusion to generate this image."
},
{
"from": "gpt",
"value": "a beautiful painting of chernobyl by nekro, pascal blanche, john harris, greg rutkowski, sin jong hun, moebius, simon stalenhag. in style of cg art. ray tracing. cel shading. hyper detailed. realistic. ue 5. maya. octane render. "
},
]
},
...
]

Training script with DeepSpeed ZeRO-3: finetune.sh
任务特定数据有限,使用 LoRA 从 LLaVA 检查点进行微调:finetune_lora.sh
任务的数据量足够,从 LLaVA(lora) 检查点进行微调,然后进行全模型微调:finetune_task.sh(finetune_task_lora.sh)
这里使用finetune_task.sh
#!/bin/bash
deepspeed llava/train/train_mem.py \
# config
--deepspeed ./scripts/zero3.json \
# base bmodel
--model_name_or_path liuhaotian/llava-v1.5-13b \
--version v1 \
# data
--data_path ./playground/data/llava_v1_5_mix665k.json \
--image_folder ./playground/data \
# image encoding model
--vision_tower openai/clip-vit-large-patch14-336 \
--mm_projector_type mlp2x_gelu \
##clip-vit 取倒数第二层特征输出作为图像编码
--mm_vision_select_layer -2 \
--mm_use_im_start_end False \
--mm_use_im_patch_token False \
## 将图片扩展为正方形再进行图像预处理
--image_aspect_ratio pad \
# 数据采样
--group_by_modality_length True \
--bf16 True \
--output_dir ./checkpoints/llava-v1.5-13b-task \
--num_train_epochs 1 \
--per_device_train_batch_size 16 \
--per_device_eval_batch_size 4 \
--gradient_accumulation_steps 1 \
--evaluation_strategy "no" \
--save_strategy "steps" \
--save_steps 50000 \
--save_total_limit 1 \
--learning_rate 2e-5 \
--weight_decay 0. \
--warmup_ratio 0.03 \
--lr_scheduler_type "cosine" \
--logging_steps 1 \
--tf32 True \
--model_max_length 2048 \
--gradient_checkpointing True \
--dataloader_num_workers 4 \
--lazy_preprocess True \
--report_to wandb
zero3.json
训练相关
{
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"bf16": {
"enabled": "auto"
},
"train_micro_batch_size_per_gpu": "auto",
"train_batch_size": "auto",
"gradient_accumulation_steps": "auto",
"zero_optimization": {
"stage": 3,
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": true
}
}
train_mem.py
# 检查硬件
from llava.train.llama_flash_attn_monkey_patch import replace_llama_attn_with_flash_attn
replace_llama_attn_with_flash_attn()
from llava.train.train import train
if __name__ == "__main__":
train()
检查硬件
def replace_llama_attn_with_flash_attn():
cuda_major, cuda_minor = torch.cuda.get_device_capability()
if cuda_major < 8:
warnings.warn(
"Flash attention is only supported on A100 or H100 GPU during training due to head dim > 64 backward."
"ref: https://github.com/HazyResearch/flash-attention/issues/190#issuecomment-1523359593"
)
# Disable the transformation of the attention mask in LlamaModel as the flash attention
transformers.models.llama.modeling_llama.LlamaModel._prepare_decoder_attention_mask = (
_prepare_decoder_attention_mask
)
# 修改Llama的attention
transformers.models.llama.modeling_llama.LlamaAttention.forward = forward
模型fintune入口——train.py
def train():
global local_rank
# 解析命令行参数并将其分配给相应的数据类中的对象
parser = transformers.HfArgumentParser(
(ModelArguments, DataArguments, TrainingArguments))
model_args, data_args, training_args = parser.parse_args_into_dataclasses()
# 当前进程所使用的 GPU 设备的索引
local_rank = training_args.local_rank
# 统一数据类型
compute_dtype = (torch.float16 if training_args.fp16 else (torch.bfloat16 if training_args.bf16 else torch.float32))
bnb_model_from_pretrained_args = {}
if training_args.bits in [4, 8]:
from transformers import BitsAndBytesConfig
bnb_model_from_pretrained_args.update(dict(
device_map={"": training_args.device},
load_in_4bit=training_args.bits == 4,
load_in_8bit=training_args.bits == 8,
quantization_config=BitsAndBytesConfig(
load_in_4bit=training_args.bits == 4,
load_in_8bit=training_args.bits == 8,
llm_int8_skip_modules=["mm_projector"],
llm_int8_threshold=6.0,
llm_int8_has_fp16_weight=False,
bnb_4bit_compute_dtype=compute_dtype,
bnb_4bit_use_double_quant=training_args.double_quant,
bnb_4bit_quant_type=training_args.quant_type # {'fp4', 'nf4'}
)
))
# 加载模型
## openai/clip-vit-large-patch14-336
if model_args.vision_tower is not None:
if 'mpt' in model_args.model_name_or_path:
config = transformers.AutoConfig.from_pretrained(model_args.model_name_or_path, trust_remote_code=True)
config.attn_config['attn_impl'] = training_args.mpt_attn_impl
model = LlavaMPTForCausalLM.from_pretrained(
model_args.model_name_or_path,
config=config,
cache_dir=training_args.cache_dir,
**bnb_model_from_pretrained_args
)
else:
# liuhaotian/llava-v1.5-13b
model = LlavaLlamaForCausalLM.from_pretrained(
model_args.model_name_or_path,
cache_dir=training_args.cache_dir,
**bnb_model_from_pretrained_args
)
else:
model = transformers.LlamaForCausalLM.from_pretrained(
model_args.model_name_or_path,
cache_dir=training_args.cache_dir,
**bnb_model_from_pretrained_args
)
model.config.use_cache = False
## 冻结权重
if model_args.freeze_backbone:
model.model.requires_grad_(False)
if training_args.bits in [4, 8]:
from peft import prepare_model_for_kbit_training
model.config.torch_dtype=(torch.float32 if training_args.fp16 else (torch.bfloat16 if training_args.bf16 else torch.float32))
model = prepare_model_for_kbit_training(model, use_gradient_checkpointing=training_args.gradient_checkpointing)
## 开启编码器映射层权重
if training_args.gradient_checkpointing:
if hasattr(model, "enable_input_require_grads"):
model.enable_input_require_grads()
else:
def make_inputs_require_grad(module, input, output):
output.requires_grad_(True)
model.get_input_embeddings().register_forward_hook(make_inputs_require_grad)
if training_args.lora_enable:
# 加载lora
from peft import LoraConfig, get_peft_model
lora_config = LoraConfig(
r=training_args.lora_r,
lora_alpha=training_args.lora_alpha,
target_modules=find_all_linear_names(model),
lora_dropout=training_args.lora_dropout,
bias=training_args.lora_bias,
task_type="CAUSAL_LM",
)
if training_args.bits == 16:
if training_args.bf16:
model.to(torch.bfloat16)
if training_args.fp16:
model.to(torch.float16)
rank0_print("Adding LoRA adapters...")
model = get_peft_model(model, lora_config)
# 加载分词器
if 'mpt' in model_args.model_name_or_path:
tokenizer = transformers.AutoTokenizer.from_pretrained(
model_args.model_name_or_path,
cache_dir=training_args.cache_dir,
model_max_length=training_args.model_max_length,
padding_side="right"
)
else:
tokenizer = transformers.AutoTokenizer.from_pretrained(
model_args.model_name_or_path,
cache_dir=training_args.cache_dir,
model_max_length=training_args.model_max_length,
padding_side="right",
use_fast=False,
)
# v1
if model_args.version == "v0":
if tokenizer.pad_token is None:
smart_tokenizer_and_embedding_resize(
special_tokens_dict=dict(pad_token="[PAD]"),
tokenizer=tokenizer,
model=model,
)
elif model_args.version == "v0.5":
tokenizer.pad_token = tokenizer.unk_token
else:
tokenizer.pad_token = tokenizer.unk_token
if model_args.version in conversation_lib.conv_templates:
conversation_lib.default_conversation = conversation_lib.conv_templates[model_args.version]
else:
conversation_lib.default_conversation = conversation_lib.conv_templates["vicuna_v1"]
# 初始化图像编码器映射层
if model_args.vision_tower is not None:
model.get_model().initialize_vision_modules(
model_args=model_args,
fsdp=training_args.fsdp
)
vision_tower = model.get_vision_tower()
vision_tower.to(dtype=torch.bfloat16 if training_args.bf16 else torch.float16, device=training_args.device)
data_args.image_processor = vision_tower.image_processor
data_args.is_multimodal = True
model.config.image_aspect_ratio = data_args.image_aspect_ratio
model.config.tokenizer_padding_side = tokenizer.padding_side
model.config.tokenizer_model_max_length = tokenizer.model_max_length
# 开启图像编码映射权重
model.config.tune_mm_mlp_adapter = training_args.tune_mm_mlp_adapter = model_args.tune_mm_mlp_adapter
if model_args.tune_mm_mlp_adapter:
model.requires_grad_(False)
for p in model.get_model().mm_projector.parameters():
p.requires_grad = True
# 关闭图像编码映射权重
model.config.freeze_mm_mlp_adapter = training_args.freeze_mm_mlp_adapter
if training_args.freeze_mm_mlp_adapter:
for p in model.get_model().mm_projector.parameters():
p.requires_grad = False
if training_args.bits in [4, 8]:
model.get_model().mm_projector.to(dtype=compute_dtype, device=training_args.device)
model.config.mm_use_im_start_end = data_args.mm_use_im_start_end = model_args.mm_use_im_start_end
model.config.mm_projector_lr = training_args.mm_projector_lr
training_args.use_im_start_end = model_args.mm_use_im_start_end
model.config.mm_use_im_patch_token = model_args.mm_use_im_patch_token
model.initialize_vision_tokenizer(model_args, tokenizer=tokenizer)
if training_args.bits in [4, 8]:
from peft.tuners.lora import LoraLayer
for name, module in model.named_modules():
if isinstance(module, LoraLayer):
if training_args.bf16:
module = module.to(torch.bfloat16)
if 'norm' in name:
module = module.to(torch.float32)
if 'lm_head' in name or 'embed_tokens' in name:
if hasattr(module, 'weight'):
if training_args.bf16 and module.weight.dtype == torch.float32:
module = module.to(torch.bfloat16)
# 制作输入数据
data_module = make_supervised_data_module(tokenizer=tokenizer,
data_args=data_args)
trainer = LLaVATrainer(model=model,
tokenizer=tokenizer,
args=training_args,
**data_module)
if list(pathlib.Path(training_args.output_dir).glob("checkpoint-*")):
trainer.train(resume_from_checkpoint=True)
else:
trainer.train()
trainer.save_state()
model.config.use_cache = True
if training_args.lora_enable:
state_dict = get_peft_state_maybe_zero_3(
model.named_parameters(), training_args.lora_bias
)
non_lora_state_dict = get_peft_state_non_lora_maybe_zero_3(
model.named_parameters()
)
if training_args.local_rank == 0 or training_args.local_rank == -1:
model.config.save_pretrained(training_args.output_dir)
model.save_pretrained(training_args.output_dir, state_dict=state_dict)
torch.save(non_lora_state_dict, os.path.join(training_args.output_dir, 'non_lora_trainables.bin'))
else:
safe_save_model_for_hf_trainer(trainer=trainer,
output_dir=training_args.output_dir)
三个dataclass
制作数据集
make_supervised_data_module
def make_supervised_data_module(tokenizer: transformers.PreTrainedTokenizer,
data_args) -> Dict:
"""Make dataset for supervised fine-tuning."""
train_dataset = LazySupervisedDataset(tokenizer=tokenizer,
data_path=data_args.data_path, # ./playground/data/llava_v1_5_mix665k.json
data_args=data_args)
"""Make collator for supervised fine-tuning."""
data_collator = DataCollatorForSupervisedDataset(tokenizer=tokenizer)
return dict(train_dataset=train_dataset,
eval_dataset=None,
data_collator=data_collator)
train_dataset
class LazySupervisedDataset(Dataset):
"""Dataset for supervised fine-tuning."""
def __init__(self, data_path: str,
tokenizer: transformers.PreTrainedTokenizer,
data_args: DataArguments):
super(LazySupervisedDataset, self).__init__()
# 加载json文件
list_data_dict = json.load(open(data_path, "r"))
rank0_print("Formatting inputs...Skip in lazy mode")
# 分词器
self.tokenizer = tokenizer
self.list_data_dict = list_data_dict
self.data_args = data_args
def __len__(self):
return len(self.list_data_dict)
@property
def lengths(self):
# 计算token长度
length_list = []
for sample in self.list_data_dict:
img_tokens = 128 if 'image' in sample else 0
length_list.append(sum(len(conv['value'].split()) for conv in sample['conversations']) + img_tokens)
return length_list
@property
def modality_lengths(self):
# 计算modality token长度
length_list = []
for sample in self.list_data_dict:
cur_len = sum(len(conv['value'].split()) for conv in sample['conversations'])
cur_len = cur_len if 'image' in sample else -cur_len
length_list.append(cur_len)
return length_list
def __getitem__(self, i) -> Dict[str, torch.Tensor]:
sources = self.list_data_dict[i]
if isinstance(i, int):
sources = [sources]
assert len(sources) == 1, "Don't know why it is wrapped to a list" # FIXME
if 'image' in sources[0]:
image_file = self.list_data_dict[i]['image']
image_folder = self.data_args.image_folder
processor = self.data_args.image_processor
image = Image.open(os.path.join(image_folder, image_file)).convert('RGB')
# 图片预处理
if self.data_args.image_aspect_ratio == 'pad':
# 图片转换为正方形
def expand2square(pil_img, background_color):
width, height = pil_img.size
if width == height:
return pil_img
elif width > height:
result = Image.new(pil_img.mode, (width, width), background_color)
result.paste(pil_img, (0, (width - height) // 2))
return result
else:
result = Image.new(pil_img.mode, (height, height), background_color)
result.paste(pil_img, ((height - width) // 2, 0))
return result
image = expand2square(image, tuple(int(x * 255) for x in processor.image_mean))
image = processor.preprocess(image, return_tensors='pt')['pixel_values'][0]
else:
image = processor.preprocess(image, return_tensors='pt')['pixel_values'][0]
# 对conversations进行处理
sources = preprocess_multimodal(
copy.deepcopy([e["conversations"] for e in sources]),
self.data_args)
else:
sources = copy.deepcopy([e["conversations"] for e in sources])
# QA NLP 处理
data_dict = preprocess(
sources,
self.tokenizer,
has_image=('image' in self.list_data_dict[i]))
if isinstance(i, int):
data_dict = dict(input_ids=data_dict["input_ids"][0],
labels=data_dict["labels"][0])
# image exist in the data
if 'image' in self.list_data_dict[i]:
data_dict['image'] = image
elif self.data_args.is_multimodal:
# image does not exist in the data, but the model is multimodal
crop_size = self.data_args.image_processor.crop_size
data_dict['image'] = torch.zeros(3, crop_size['height'], crop_size['width'])
return data_dict
def preprocess_multimodal(
sources: Sequence[str],
data_args: DataArguments
) -> Dict:
is_multimodal = data_args.is_multimodal
if not is_multimodal:
return sources
for source in sources:
for sentence in source:
if DEFAULT_IMAGE_TOKEN in sentence['value']: # 和 移除字符串的开头和结尾的空白字符(例如空格、制表符、换行符等)
sentence['value'] = sentence['value'].replace(DEFAULT_IMAGE_TOKEN, '').strip()
# 在句子开头加上 \n
sentence['value'] = DEFAULT_IMAGE_TOKEN + '\n' + sentence['value']
# 移除字符串的开头和结尾的空白字符(例如空格、制表符、换行符等)
sentence['value'] = sentence['value'].strip()
if "mmtag" in conversation_lib.default_conversation.version:
sentence['value'] = sentence['value'].replace(DEFAULT_IMAGE_TOKEN,
'' + DEFAULT_IMAGE_TOKEN + '')
replace_token = DEFAULT_IMAGE_TOKEN
if data_args.mm_use_im_start_end:
replace_token = DEFAULT_IM_START_TOKEN + replace_token + DEFAULT_IM_END_TOKEN
sentence["value"] = sentence["value"].replace(DEFAULT_IMAGE_TOKEN, replace_token)
return sources
def preprocess(
sources: Sequence[str],
tokenizer: transformers.PreTrainedTokenizer,
has_image: bool = False
) -> Dict:
"""
Given a list of sources, each is a conversation list. This transform:
1. Add signal '### ' at the beginning each sentence, with end signal '\n';
2. Concatenate conversations together;
3. Tokenize the concatenated conversation;
4. Make a deepcopy as the target. Mask human words with IGNORE_INDEX.
"""
if conversation_lib.default_conversation.sep_style == conversation_lib.SeparatorStyle.PLAIN:
return preprocess_plain(sources, tokenizer)
if conversation_lib.default_conversation.sep_style == conversation_lib.SeparatorStyle.LLAMA_2:
return preprocess_llama_2(sources, tokenizer, has_image=has_image)
if conversation_lib.default_conversation.version.startswith("v1"):
return preprocess_v1(sources, tokenizer, has_image=has_image) # 使用这个
if conversation_lib.default_conversation.version == "mpt":
return preprocess_mpt(sources, tokenizer)
...# 后面的不重要
def preprocess_v1(
sources,
tokenizer: transformers.PreTrainedTokenizer,
has_image: bool = False
) -> Dict:
# 获取conversation模板类
conv = conversation_lib.default_conversation.copy()
roles = {"human": conv.roles[0], "gpt": conv.roles[1]}
# Apply prompt templates
conversations = []
for i, source in enumerate(sources):
if roles[source[0]["from"]] != conv.roles[0]:
# Skip the first one if it is not from human
source = source[1:]
conv.messages = []
for j, sentence in enumerate(source):
role = roles[sentence["from"]]
assert role == conv.roles[j % 2], f"{i}"
conv.append_message(role, sentence["value"])
conversations.append(conv.get_prompt())
# Tokenize conversations
if has_image:
input_ids = torch.stack(
[tokenizer_image_token(prompt, tokenizer, return_tensors='pt') for prompt in conversations], dim=0)
else:
input_ids = tokenizer(
conversations,
return_tensors="pt",
padding="longest",
max_length=tokenizer.model_max_length,
truncation=True,
).input_ids
targets = input_ids.clone()
assert conv.sep_style == conversation_lib.SeparatorStyle.TWO
# Mask targets
sep = conv.sep + conv.roles[1] + ": "
for conversation, target in zip(conversations, targets):
total_len = int(target.ne(tokenizer.pad_token_id).sum())
rounds = conversation.split(conv.sep2)
cur_len = 1
target[:cur_len] = IGNORE_INDEX
for i, rou in enumerate(rounds):
if rou == "":
break
parts = rou.split(sep)
if len(parts) != 2:
break
parts[0] += sep
if has_image:
round_len = len(tokenizer_image_token(rou, tokenizer))
instruction_len = len(tokenizer_image_token(parts[0], tokenizer)) - 2
else:
round_len = len(tokenizer(rou).input_ids)
instruction_len = len(tokenizer(parts[0]).input_ids) - 2
target[cur_len: cur_len + instruction_len] = IGNORE_INDEX
cur_len += round_len
target[cur_len:] = IGNORE_INDEX
if cur_len < tokenizer.model_max_length:
if cur_len != total_len:
target[:] = IGNORE_INDEX
print(
f"WARNING: tokenization mismatch: {cur_len} vs. {total_len}."
f" (ignored)"
)
return dict(
input_ids=input_ids,
labels=targets,
)
default_conversation = conv_vicuna_v1
conv_vicuna_v1 = Conversation(
system="A chat between a curious user and an artificial intelligence assistant. "
"The assistant gives helpful, detailed, and polite answers to the user's questions.",
roles=("USER", "ASSISTANT"),
version="v1",
messages=(),
offset=0,
sep_style=SeparatorStyle.TWO,
sep=" ",
sep2="",
)
data_collator
# 批量化、填充和限制输入长度
@dataclass
class DataCollatorForSupervisedDataset(object):
"""Collate examples for supervised fine-tuning."""
tokenizer: transformers.PreTrainedTokenizer
def __call__(self, instances: Sequence[Dict]) -> Dict[str, torch.Tensor]:
input_ids, labels = tuple([instance[key] for instance in instances]
for key in ("input_ids", "labels"))
input_ids = torch.nn.utils.rnn.pad_sequence(
input_ids,
batch_first=True,
padding_value=self.tokenizer.pad_token_id)
labels = torch.nn.utils.rnn.pad_sequence(labels,
batch_first=True,
padding_value=IGNORE_INDEX)
input_ids = input_ids[:, :self.tokenizer.model_max_length]
labels = labels[:, :self.tokenizer.model_max_length]
batch = dict(
input_ids=input_ids,
labels=labels,
attention_mask=input_ids.ne(self.tokenizer.pad_token_id),
)
if 'image' in instances[0]:
images = [instance['image'] for instance in instances]
if all(x is not None and x.shape == images[0].shape for x in images):
batch['images'] = torch.stack(images)
else:
batch['images'] = images
return batch