电商数据分析-03-电商数据采集
参考
最最最全数据仓库建设指南,速速收藏!!
第1章 数据仓库概念
数据仓库规划

1.1 数仓搭建
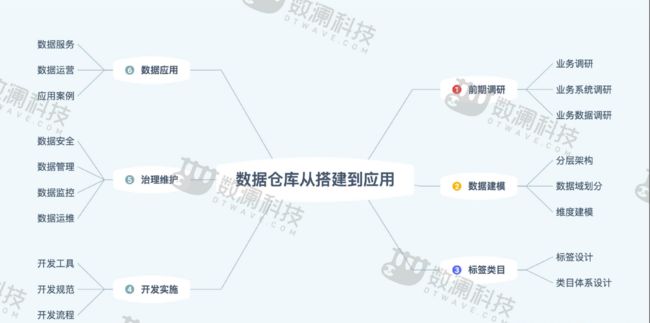
我们这里所说的数据仓库,是基于大数据体系的,里面包含标签类目,区别于传统的数据仓库。下面我们来将这张图分解,逐个做简要分析。
一、前期调研
调研是数仓搭建的基础,根据建设目标,我们将调研分为三类:业务调研、业务系统调研、业务数据调研。
业务调研内容:
项目承载的业务是什么,业务的特征和性质
当前的业务流程,有真实流程表格和报告最好,用一个实例的方式来展示整个业务流程
业务专业术语、产品资料、规则算法、逻辑条件等资料
关注用户对流程中存在的问题和痛点描述、以及期望
业务系统调研内容:
清楚了解项目有哪些系统,每个系统对接人,重点系统详细介绍功能和交互
整体系统架构,调用规模,子系统交互方式,并发和吞吐量目标
系统技术选型和系统当前技术难点
数据调研内容:
可提供的数据
数据源类型、环境、数据规模
数据接口方式:文件接口、数据库接口、web service接口等
数据目录,数据字段类型、字典、字段含义、使用场景
数据在业务系统中流向等
二、数据建模
数据建模是数仓搭建的灵魂,是数据存储、组织关系设计的蓝图。
分层架构是对数据进行逻辑上的梳理,按照不同来源、不同使用目的、不同颗粒度等进行区分,使数据使用者在使用数据的时候更方便和容易理解,使数据管理者在管理数据的时候更高效和具有条理。我们推荐的分层架构是:
维度建模是Kimball在《数据仓库工具箱》中所倡导的数据建模方法,也是目前在大数据场景下我们推荐使用的建模方法。因为维度建模以分析决策的需求出发来构建模型,构建的数据模型为分析需求服务,因此它重点解决用户如何更快速完成分析需求,同时还有较好的大规模复杂查询的响应性能。
维度建模的核心步骤如下:
选择业务过程:对业务生命周期中的活动过程进行分析
声明粒度:选择事实表的数据粒度
维度设计:确定维度字段,确定维度表的信息
事实设计:基于粒度和维度,将业务过程度量
设计原则:
易用性:冗余存储换性能,公共计算下沉,明细汇总并存
高内聚低耦合:核心与扩展分离,业务过程合并,考虑产出时间
数据隔离:业务与数据系统隔离,建设与使用隔离
一致性:业务口径一致,主要实体一致,命名规范一致
中性原则:弱业务属性,数据驱动
三、标签类目
标签,是数据资产的逻辑载体。数据资产,指的是能够给业务带来经济效益的数据。所以,标签类目的建设在整个数据中心的建设过程中具有核心地位。
标签的设计需要结合数据情况和业务需求,因为标签值就是数据字段值,同时标签是要服务于业务的,需要具备业务意义。假如,标签的设计仅基于业务方以往的经验得出,那么最终开发出来的标签值可能会失去标签的使用意义,比如值档次分布不均、有值的覆盖率低等。
基于标签开发方式,我们将标签分为以下三类:
基础标签:直接对应的业务表字段,如性别、城市等
统计标签:标签定义含有常规的统计逻辑,开发时需要通过简易规则进行加工,如年增长率、月平均收益率等
算法标签:标签定义含有复杂的统计逻辑,开发时需要通过算法模型进行加工,如企业信用分、预测年销量等
基于标签应用场景,我们将标签分为以下二类:
后台标签:开发场景下,面向开发人员,不涉及业务场景,聚焦标签设计、开发、管理。
前台标签:应用场景下,面向业务人员,结合业务场景,聚焦对后台标签的直接使用或组合使用。
随着大量的标签产生,为了更好的管理和使用,我们需要将标签进行分类。所有的事物都可以归类于三类对象:人、物、关系,所以我们可以对标签按照人、物、关系来划分一级类目,再按照业务特性对每个一级类目进行二级、三级的拆分,通常我们建议将标签类目划分到三级。

四、开发实施
经过前期调研、数据建模、标签设计之后,接着会进入到开发阶段,开发实施的关键环节由以下几部分组成:
同步汇聚
清洗加工
测试校验
调度配置
发布上线
工欲善其事,必先利其器。一个好的开发工具对开发进度、成本、质量等具有举足轻重的影响。目前市面上很多开源,如Kettle、Azkaban、Hue等多多少少具有部分功能,但是要形成一个从端到端的数据自动化生产,需要将多个开源工具进行组合并通过复杂甚至人工方式进行衔接,整个过程复杂、低效和可靠性低。数栖云一站式离线开发平台,就是为了解决上述问题而生的。
开发落地,规范先行,遵守一套标准规范是整个开发质量和效率的保障。该套数据开发规范应该具备以下几个核心内容:
公共规范
层次调用约定
数据类型规范
数据冗余拆分
空值处理原则
刷新周期标识
增量全量标识
生命周期管理
…
ODS层模型开发规范
ODS层架构
数据同步及处理规范数据同步方式
数据清洗规范命名规范
表命名规范
任务命名规范
DW层模型开发规范
…
通过工具+规范,促使我们的开发实施快速做好。
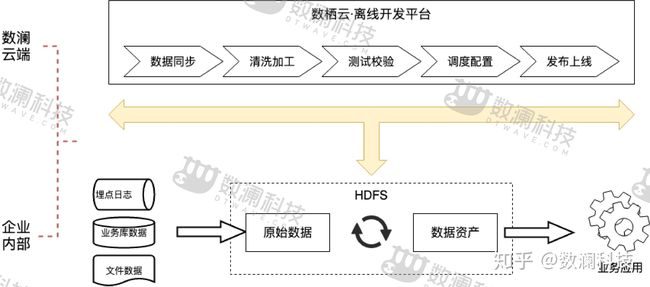
五、治理维护
随着调度作业和数据量的增长,管理和维护会成为一项重要任务。
数据管理的范围很大,贯穿数据采集、应用和价值实现等整个生命周期全过程。所谓的数据管理就是通过对数据的生命周期的管理,提高数据资产质量,促进数据在“内增值,外增效”两方面的价值表现。数据管理的核心内容为:
数据标准管理
数据模型管理
元数据管理
主数据管理
数据质量管理
数据安全管理
数据监控是数据质量的保障,会根据数据质量规则制定监控策略,当触发规则时能够自动通知到相关人。基础的数据质量监控维度有以下几部分:
完整性
特定完整性:必须有值的字段中,不允许为空
条件完整性:根据条件字段值必须始终存在
唯一性
特定唯一性:字段必须唯一
条件唯一性:根据业务条件,字段值必须唯一
有效性
范围有效性:字段值必须在指定的范围内取值
日期有效性:字段是日期的时候取值必须是有效的
形式有效性:字段值必须和指定的格式一致
一致性
参照一致性:数据或业务具有参照关系的时候,必须保持其一致性
数据一致性:数据采集、加工或迁移后,前后的数据必须保持一致性
准确性
逻辑正确性:业务逻辑之间的正确性
计算正确性:复合指标计算的结果应符合原始数据和计算逻辑的要求
状态正确性:要维护好数据的产生、收集和更新周期
当出现数据异常后,需要快速的进行恢复。基于异常和修复场景,有以下几种数据运维方式:
平台环境问题引起的异常
重跑:当环境问题解决后,重新调度作业,对当天的数据进行修复
重跑下游:当环境问题解决后,重新调度某一个工作流节点的作业及其下游,对当天该作业及其下游的数据进行修复
业务逻辑变更或代码 bug 引起的异常
补数据:对应作业代码更新并重新发布到生产后,重新生成异常时间段内的该作业数据
补下游:对应作业代码更新并重新发布到生产后,重新生成异常时间段内的该作业及其下游的数据
其他
终止:终止正在被执行的作业
数据安全主要是保障数据不被窃取、破坏和滥用,包括核心数据和隐私数据,以及确保数据系统的安全可靠运行。需要构建系统层面、数据层面和服务层面的数据安全框架,从技术保障、管理保障、过程保障和运行保障多维度保障大数据应用和数据安全。
系统层面
技术架构
网络传输
租户隔离
权限管理
数据层面
数据评估:对数据来源、用途、合法性等进行评估
数据脱敏:对隐私数据进行脱敏处理
数据权限:根据数据使用者的不同角色和需求,开放不同权限
血缘追溯:建立数据血缘关系,可追溯数据生产的来龙去脉
下载限制:限制数据结果集的下载条数,防止数据外泄
服务层面
应用监控:监控数据使用端、使用次数、使用流量等
接口管理:生产和管理数据输出接口
数据脱敏
六、数据应用
给业务赋能,是数据价值的最终体现,也就是我们讲的数据业务化。数据业务化的方向有两种:业务优化和业务创新。在数据业务化的过程中,为了更方便的服务于上层应用,我们先将数据形成服务接口,然后让业务应用直接调用服务接口,即形成 数据服务化+服务业务化。
如何通过已有的 产品 + 方法论 + 最佳实践 去完成一个业务优化和业务创新呢?这里有一张完整的图,帮助你更快的理解全过程。

项目需求及架构设计
2.1 项目需求分析
1)项目需求
(1)用户行为数据采集平台搭建
(2)业务数据采集平台搭建
(3)数据仓库维度建模
(4)分析,设备、会员、商品、地区、活动等电商核心主题,统计的报表指标近100个,完全对比中型公司
(5)采用即席查询工具,随时进行指标分析
(6)对集群性能进行监控,发生异常需要报警
(7)元数据管理
(8)质量监控
2)思考
(1)项目技术如何选型
(2)框架版本如何选型(Apache、CDH、HDP)
(3)服务器使用物理机还是云主机
(4)如何确认集群规模(假设每台服务器8T硬盘)
2.2 项目框架
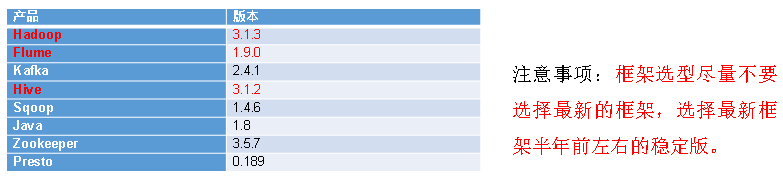
2.2.1 技术选型
技术选型主要考虑因素:数据量大小、业务需求、行业内经验、技术成熟度、开发维护成本、总成本预算
1)数据采集传输:Flume,Kafka,Sqoop,Logstash,DataX
2)数据存储:Mysql,HDFS,HBase,Redis,MongoDB
3)数据计算:Hive,Tez,Spark,Flink,Storm
4)数据查询:Presto,Kylin,Impala,Druid
5)数据可视化:Echarts,Superset,QuickBI,DataV
6)任务调度:Azkaban、Oozie
7)集群监控:Zabbix
8)元数据管理:Atlas
2.2.2 系统数据流程设计

2.2.3 框架版本选型
如何选择Apache/CDH/HDP版本?
(1)Apache:运维麻烦,组件间兼容性需要自己调研。(一般大厂使用,技术实力雄厚,有专业的运维人员)
(2)CDH:国内使用最多的版本,但CM不开源,今年开始要收费,一个节点1万美金
(3)HDP:开源,开源进行二次开发,但是没有CDH稳定,国内使用较少,目前被CDH收购
2.2.4 服务器选型
服务器选择物理机还是云主机
1)物理机:
(1)128G内存,20核物理CPU,40线程,8THDD核2TSSD硬盘,戴尔品牌,单台报价4W出头,一般寿命在5年左右
(2)需要专业的运维人员,平均每月1W,电费、网络、散热、机房等等开销
2)云主机
(1)以阿里云为例,差不多相同配置,每年5W
(2)很多运维工作由阿里云完成,运维相对轻松
3)企业选择
(1)金融有钱公司和阿里没有直接冲突的公司选择阿里云
(2)中小公司、为了融资上市,选择阿里云,拉到融资后再购买物理机
(3)有长期打算,资金比较足,选择物理机
2.2.5 集群资源规划设计
1)如何确定集群规模?(假设每台服务器8T磁盘,128G内存)
(1)每天日活跃用户100万,每人一天平均100条:100万 * 100条 = 1亿条
(2)每条日志1k左右,每天1亿条:100000000 / 1024 / 1024 = 100G(1G=1024MB,1MB=1024KB)
(3)半年内不扩容服务器来算:100G * 180天 = 18T (1T=1024G)
(4)保存3个副本:18T * 3 = 54T
(5)预留20%~30%Buf :54T / 0.7 = 77T
(6)服务器数量:77 / 8 = 10台(每台8个T)
2)若考虑数仓分层,数据采用压缩,则需要重新进行计算
3)测试集群服务器规划

数据生成模块
3.1 目标数据
我们要收集和分析的数据主要包括页面数据、事件数据、曝光数据、启动数据和错误数据。
3.1.1 页面
页面数据主要记录一个页面的用户访问情况,包括访问时间、停留时间、页面路径等信息。

1)所有页面id如下
home(“首页”),
category(“分类页”),
discovery(“发现页”),
top_n(“热门排行”),
favor(“收藏页”),
search(“搜索页”),
good_list(“商品列表页”),
good_detail(“商品详情”),
good_spec(“商品规格”),
comment(“评价”),
comment_done(“评价完成”),
comment_list(“评价列表”),
cart(“购物车”),
trade(“下单结算”),
payment(“支付页面”),
payment_done(“支付完成”),
orders_all(“全部订单”),
orders_unpaid(“订单待支付”),
orders_undelivered(“订单待发货”),
orders_unreceipted(“订单待收货”),
orders_wait_comment(“订单待评价”),
mine(“我的”),
activity(“活动”),
login(“登录”),
register(“注册”);
2)所有页面对象类型如下:
sku_id(“商品skuId”),
keyword(“搜索关键词”),
sku_ids(“多个商品skuId”),
activity_id(“活动id”),
coupon_id(“购物券id”);
3)所有来源类型如下:
promotion(“商品推广”),
recommend(“算法推荐商品”),
query(“查询结果商品”),
activity(“促销活动”);
3.1.2 事件
事件数据主要记录应用内一个具体操作行为,包括操作类型、操作对象、操作对象描述等信息。

1)所有动作类型如下:
favor_add(“添加收藏”),
favor_canel(“取消收藏”),
cart_add(“添加购物车”),
cart_remove(“删除购物车”),
cart_add_num(“增加购物车商品数量”),
cart_minus_num(“减少购物车商品数量”),
trade_add_address(“增加收货地址”),
get_coupon(“领取优惠券”);
注:对于下单、支付等业务数据,可从业务数据库获取。
2)所有动作目标类型如下:
sku_id(“商品”),
coupon_id(“购物券”);
3.1.3 曝光
曝光数据主要记录页面所曝光的内容,包括曝光对象,曝光类型等信息。
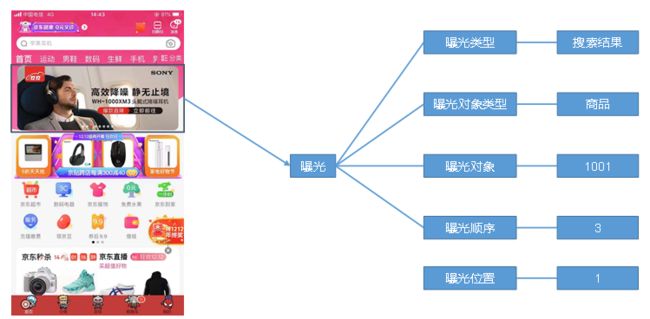
1)所有曝光类型如下:
promotion(“商品推广”),
recommend(“算法推荐商品”),
query(“查询结果商品”),
activity(“促销活动”);
2)所有曝光对象类型如下:
sku_id(“商品skuId”),
activity_id(“活动id”);
3.1.4 启动
启动数据记录应用的启动信息。

1)所有启动入口类型如下:
icon(“图标”),
notification(“通知”),
install(“安装后启动”);
3.1.5 错误
错误数据记录应用使用过程中的错误信息,包括错误编号及错误信息。
3.2数据埋点
3.2.1 主流埋点方式(了解)
目前主流的埋点方式,有代码埋点(前端/后端)、可视化埋点、全埋点三种。
代码埋点
代码埋点是通过调用埋点SDK函数,在需要埋点的业务逻辑功能位置调用接口,上报埋点数据。例如,我们对页面中的某个按钮埋点后,当这个按钮被点击时,可以在这个按钮对应的 OnClick 函数里面调用SDK提供的数据发送接口,来发送数据。
可视化埋点:
可视化埋点只需要研发人员集成采集 SDK,不需要写埋点代码,业务人员就可以通过访问分析平台的“圈选”功能,来“圈”出需要对用户行为进行捕捉的控件,并对该事件进行命名。圈选完毕后,这些配置会同步到各个用户的终端上,由采集 SDK 按照圈选的配置自动进行用户行为数据的采集和发送。
全埋点:
全埋点是通过在产品中嵌入SDK,前端自动采集页面上的全部用户行为事件,上报埋点数据,相当于做了一个统一的埋点。然后再通过界面配置哪些数据需要在系统里面进行分析。
3.2.2 埋点数据日志结构
们的日志结构大致可分为两类,一是普通页面埋点日志,二是启动日志。
普通页面日志结构如下,每条日志包含了,当前页面的页面信息,所有事件(动作)、所有曝光信息以及错误信息。除此之外,还包含了一系列公共信息,包括设备信息,地理位置,应用信息等,即下边的common字段。
1)普通页面埋点日志格式
{
"common": { -- 公共信息
"ar": "230000", -- 地区编码
"ba": "iPhone", -- 手机品牌
"ch": "Appstore", -- 渠道
"is_new": "1",--是否首日使用,首次使用的当日,该字段值为1,过了24:00,该字段置为0。
"md": "iPhone 8", -- 手机型号
"mid": "YXfhjAYH6As2z9Iq", -- 设备id
"os": "iOS 13.2.9", -- 操作系统
"uid": "485", -- 会员id
"vc": "v2.1.134" -- app版本号
},
"actions": [ --动作(事件)
{
"action_id": "favor_add", --动作id
"item": "3", --目标id
"item_type": "sku_id", --目标类型
"ts": 1585744376605 --动作时间戳
}
],
"displays": [
{
"displayType": "query", -- 曝光类型
"item": "3", -- 曝光对象id
"item_type": "sku_id", -- 曝光对象类型
"order": 1, --出现顺序
"pos_id": 2 --曝光位置
},
{
"displayType": "promotion",
"item": "6",
"item_type": "sku_id",
"order": 2,
"pos_id": 1
},
{
"displayType": "promotion",
"item": "9",
"item_type": "sku_id",
"order": 3,
"pos_id": 3
},
{
"displayType": "recommend",
"item": "6",
"item_type": "sku_id",
"order": 4,
"pos_id": 2
},
{
"displayType": "query ",
"item": "6",
"item_type": "sku_id",
"order": 5,
"pos_id": 1
}
],
"page": { --页面信息
"during_time": 7648, -- 持续时间毫秒
"item": "3", -- 目标id
"item_type": "sku_id", -- 目标类型
"last_page_id": "login", -- 上页类型
"page_id": "good_detail", -- 页面ID
"sourceType": "promotion" -- 来源类型
},
"err":{ --错误
"error_code": "1234", --错误码
"msg": "***********" --错误信息
},
"ts": 1585744374423 --跳入时间戳
}
2)启动日志格式(启动日志结构相对简单,主要包含公共信息,启动信息和错误信息)
{
"common": {
"ar": "370000",
"ba": "Honor",
"ch": "wandoujia",
"is_new": "1",
"md": "Honor 20s",
"mid": "eQF5boERMJFOujcp",
"os": "Android 11.0",
"uid": "76",
"vc": "v2.1.134"
},
"start": {
"entry": "icon", --icon手机图标 notice 通知 install 安装后启动
"loading_time": 18803, --启动加载时间
"open_ad_id": 7, --广告页ID
"open_ad_ms": 3449, -- 广告总共播放时间
"open_ad_skip_ms": 1989 -- 用户跳过广告时点
},
"err":{ --错误
"error_code": "1234", --错误码
"msg": "***********" --错误信息
},
"ts": 1585744304000
}
3.2.3 埋点数据上报时机
埋点数据上报时机包括两种方式。
方式一,在离开该页面时,上传在这个页面产生的所有数据(页面、事件、曝光、错误等)。优点,批处理,减少了服务器接收数据压力。缺点,不是特别及时。
方式二,每个事件、动作、错误等,产生后,立即发送。优点,响应及时。缺点,对服务器接收数据压力比较大。
数据采集模块
