c++primer—读书笔记【全能详细版】
第1章 开始
1.1 编写一个简单的c++程序
1.1.1 编译.运行程序
int类型是一种内置类型,即语言自身定义的类型
1.2 初识输入输出
输入流和输出流而言,一个流就是一个字符序列。术语“流”的意思表示,随时间的推移,字符是顺序生成或消耗的
标准库的四个标准输入输出流:cin、cout、cerr、clog。
cout 可以重定向(比如输出到文件),通过缓冲区。cerr 不可以重定向(只能输出到显示器),不通过缓冲区。cerr的作用是在一些特殊的紧急情况下还可以输出(比如调用栈用完了,没有出口的递归等)。缓冲区的目的是减少刷屏的次数,多个字符同时输出到显示器。
endl 可以刷新缓冲。在添加打印语句时,应保证一直刷新流,以防程序崩溃,输出还留在缓冲区内。
1.3 注释简介
当修改代码时,不要忘记修改注释。
C++ 有两种注释:
- 单行注释:以双斜线(//)开始,以换行符结束。
- 界定符对注释:以 /* 开始,以 */ 结束。
1.4 控制流
1.4.1 while语句
while 语句的执行过程中交替地检测条件和执行关联地语句,直到条件为假。
1.4.2 for语句
因为在循环条件中检测变量、在循环体中递增变量的模式使用非常频繁,所以 C++ 专门定义了第二种循环语句:for 语句,来简化这种模式。
1.4.3 读取数量不定的输入数据
使用 while(cin>>value) 来读取数量不定的输入,循环会一直执行到遇到文件结束符或输入错误为止。windows的文件结束符是 Ctrl+Z 然后按 Enter
在编译时,最好修改一个错误编译一次,或者最多修改了一小部分后重新编译。
对于c++程序的缩进和格式,不存在唯一正确的风格,但是保持一致性是十分重要的。
1.5 类简介
类是 c++ 最重要的特性之一。
类定义了行为。**类的作者决定了类类型对象上可以使用的所有操作
1.5.2 初识成员函数
成员函数是定义为类的一部分的函数,也被称为方法。
通常以类对象的名义来调用成员函数:Item.isbn()。即使用点运算符(.)
问题
- 四个标准输入输出流是什么
- cout 和 cerr 的两点区别
- 缓冲区有什么作用?可以通过什么刷新缓冲区
- while(cin>>value)什么情况下会停止
- windows 的文件结束符是什么
回答
- cin、cout、cerr、clog
- cout 可重定向,通过缓冲区;cerr 不可重定向,不通过缓冲区
- 缓冲区能减少刷屏的次数,每个 endl 都会刷新一次缓冲区
- 遇到文件结束符或输入错误
- 先 ctrl+z 后 enter
第2章 变量和基本类型
C++定义了几种基本内置类型,如字符、整型、浮点数等。
2.1 基本内置类型
基本内置类型包括算数类型和空类型。算数类型包括字符、整型数、浮点数和布尔值。
2.1.1 算术类型
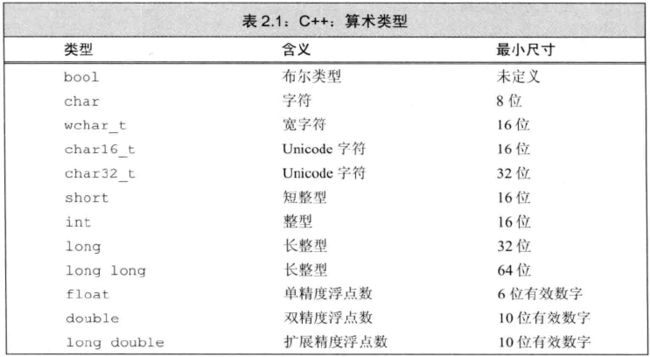
算数类型分为整型和浮点型两类。字符和布尔值都属于整型。
C++ 定义了各类型的最小尺寸:bool 未定义、char 8位、short 16位、int 16位、long 32位、long long 64位;
float 是 32 位 4 字节,包括6位有效数字、double 是 64 位 8 字节,包括10位有效数字。
int、short、long 都是带符号类型。char 是否有符号由编译器决定。
因为 char 是否有符号并不确定,因此可以使用 signed char 或 unsigned char 来指定是否有符号。
C++ 提供了几种字符类型:
- char:一个 char 的空间应确保可以存放机器基本字符集中任意字符对于的数字值,即一个 char 的大小和一个机器字节一样。
- wchar_t:宽字符,用于扩展字符集,wchar_t 确保可以存放机器最大扩展字符集中的任意一个字符。
- char16_t 和 char32_t:为 Unicode 字符集服务。
类型选择:
明确知晓数值不可能为负时,选用无符号类型。
整数运算用 int,数值太大时用 long long,不用 short 和 long
浮点数运算用 double。float 和 double 的计算代价相差无几
2.1.2 类型转换
几种类型转换的情况:
- 把浮点数赋给整型时,结果仅保留小数点前的部分。
- 赋给无符号类型超出范围的值时,结果是初始值对无符号类型表示数值总数取模后的余数。比如 -1 赋给 8 位 unsigned char 的结果是 255(-1=256*(-1)+255)
- 赋给带符号类型超出范围的值时,结果是未定义的。程序可能工作,可能崩溃。
程序尽量避免依赖于实现环境的行为。比如 int 的尺寸在不同环境可能不同。
含有无符号类型的表达式**
一个表达式中既有无符号数又有int值时,int会被转换成无符号数。
无符号减无符号数,结果还是无符号数,如果是负值就等于该符数加上无符号数的模
unsigned u = 10;
int i = -42;
u + i = -32 + 2^32 = 4294967264
2.1.3 字面值常量
整型和浮点型字面值
整型字面值中 0 开头的整数是 8 进制,0x 开头的整数是十六进制。
整型字面值的具体数据类型由它的值和符号决定。默认情况下十进制字面值是带符号数,类型是 int, long, long long 中能容纳当前值的尺寸最小的那个。
浮点型字面值可以用小数或科学计数法表示,科学计数法中的指数部分用 E 或 e 标识。
3.14 0. 0e0 .001 3.14E2
字符和字符串字面值
单引号括起来的一个字符是 char 型字面值,双引号括起来的 0 个或多个字符则构成字符串型字面值。
字符串字面值的类型实际上是字符数组,编译器会向每个字符串结尾添加一个空字符(‘\0’),因此字符串字面值的实际长度要比它的内容多 1。如 “A” 代表了一个长度为 2 的字符数组。
如果两个字符串字面值紧邻且仅由空格、缩进和换行符分隔,则它们实际上是一个整体。因此字符串比较长时可以直接分行书写。
"A is B" "and B is A"; //两个字符串实际上是一个整体。
转义序列
C++ 定义的转移序列包括:
换行符:\n,横向制表符:\t,,报警符:\a,纵向制表符:\v,退格符:\b,双引号:",
反斜线:\,单引号:',问号:?,回车符:\r,进纸符:\f
在程序中,上述转义序列被当作一个字符使用。
也可以使用泛化的转移序列,形式是 / 后跟 1~3 个八进制数字或 \x 后跟 1 个或多个十六进制数字。
\0 //空字符
\12 //换行符
\40 //空格
\x4d //字符 M
\115 //字符 M
指定字面值的类型
可以通过给字面值增加前缀和后缀来改变字面值的默认类型。
'整型字面值'
12 // 默认类型为 int
12u 12U // 最小匹配类型 unsigned
12l 12L // 最小匹配类型 long
12ul 12UL // 最小匹配类型 unsigned long
12ll 12LL // 最小匹配类型 long long
12ull 12ULL // 最小匹配类型 unsigned long long
'浮点型字面值' 3.14 // 默认类型为 double
3.14f 3.14F // 类型为 float
3.14l 3.14L // 类型为 long double
'字符字符串字面值'
u'a' u"abandon" // Unicode 16 字符,类型为 char16_t
U'a' U"abandon" // Unicode 32 字符,类型为 char32_t
L'a' L"abandon" // 宽字符,类型为 wchar_t
u8"abandon" // 类型为 char,u8 的含义是 UTF-8,仅用于字符串字面值。
注意 12f 是错的,不能给整型字面值加 f 后缀,可以使用 12.f。
布尔字面值和指针字面值
true false // bool 类型的字面值
nullptr // 指针字面值
2.2 变量
对于c++而言,”变量“和”对象“一般可以互换使用。
c++中,对象通常指一块能存储数据并具有某种类型的内存
2.2.1 变量定义
初始化
可以在同一条定义语句中使用先定义的变量去初始化后定义的其他变量。
double price = 109.99, discount = price * 0.6;
初始化不是赋值,初始化是创建变量时赋予一个初始值,赋值是把对象的当前值擦除并用一个新值来替代。
列表初始化
下面四种初始化方式都是可行的,其中使用花括号的方式叫做列表初始化。
int i = 0;
int i = {0};
int i{0};
int i(0);
当用于内置类型的变量时,使用列表初始化且初始值存在信息丢失的风险,编译器会报错。
long double ld = 3.1415926536;
int a{ld}, b={ld}; //错误,存在信息丢失的风险,转换未执行。
int c(ld), d=ld; //正确
默认初始化
定义于函数体内的内置类型的对象如果没有初始化,则其值未定义。定义于任何函数之外的内置类型则被初始化为0;
类的对象如果没有显式地初始化,则其由类确定。string 默认初始化为一个空串。
不能使用未初始化的变量,否则会引发运行时故障。
建议初始化每一个内置类型的变量。
2.2.2 变量声明和定义的关系
声明和定义是严格区分的。
要声明一个变量加 extern,声明变量不能赋值。
任何包含了显式初始化的声明即成为定义。
extern int i; // 声明 i
int i; // 定义i;
extern int i = 1; // 定义 i,初始化抵消了 extern 的作用。
变量只能被定义一次,但是可以多次声明。
声明和定义的区分很重要
c++是静态类型语言,其含义是在编译阶段检查类型。
2.2.3 标识符
标识符组成:字母、数字、下划线。不能以数字开头,对大小写敏感。标识符的长度没有限制。
用户自定义的标识符不能连续出现两个下划线,也不能以下划线紧连大写字母开头。定义在函数体外的标识符不能以下划线开头。
变量命名规范:
- 标识符要体现其实际含义。
- 变量名一般用小写字母。
- 用户自定义的类型一般以大写字母开头。
- 包含多个单词的标识符,使用驼峰命名法或使用下划线连接不同单词。
对于嵌套作用域,可以在内层作用域中重新定义外层作用域已有的名字,但是最好不要这样做。
2.3 复合类型
复合类型就是基于其他类型定义的类型,引用和指针是其中两种。
2.3.1 引用
引用是给对象起的别名。初始化引用时,是将引用和对象绑定在一起。引用无法重定向,只能一直指向初始值。
引用必须初始化。引用的初始值必须是一个对象,不能是字面值。
对引用的所有操作都是对与之绑定的对象的操作。
引用非对象。
不能定义对引用的引用,因为引用非对象。
int &r = i;
引用只能绑定在对象上,不能与字面值或表达式绑定。
引用只能绑定同类型对象。
2.3.2 指针
在块作用域内,指针如果没有被初始化,值将不确定。
指针必须指向指定的类型,不能指向其他类型。
int i = 0;
double *dp = &i; // 错误
long *lp = &i; // 错误
int *ip = i; // 这个也是错误的,但 int *ip = 0; 是正确的
指针与引用的不同:
- 指针是一个对象而引用不是;
- 指针可以重定向引用不可以;
- 有指向指针的指针无引用的引用;
- 指针不需要在定义时赋初值而引用需要。
不能定义指向引用的指针。可以定义指向指针的引用。
int *p;
int* &r = p; // r是对指针p的引用
面对如上 *&r 这样比较复杂的指针或引用的声明语句时,从右向左读比较易于弄清。
利用解引用符(*)可以访问指针指向的对象。
空指针
int *p = nullptr; // 三种定义空指针的方式。最好用第一种
int *p = 0;
int *p = NULL; // NULL 是在头文件 cstdlib 中定义的预处理变量,值为 0。
建议初始化所有指针。
非零指针对应的条件值是 ture,零指针对应的条件值是 false。
void*指针
void* 指针和空指针不是一回事。
void* 指针是特殊的指针类型,可以存放任意对象的地址。它的用处比较有限。
2.3.3 理解复合类型的声明
定义复合类型的变量要比定义基本类型的变量复杂很多。
一条声明语句是由一个基本数据类型和紧随其后的声明符列表组成的。
引用符 & 和指针符 * 都是类型说明符,类型说明符是声明符的一部分。
int &a=b, &c=b;
int *a=nullptr, b=1;
2.4 const限定符
const 对象必须初始化,因为一旦创建就不能再改变值。
默认情况下,const 对象仅在文件内有效。
如果想在多个文件间共享 const 对象,必须在变量的定义前添加 extern 关键字并在本文件中声明。声明和定义都要加 extern
2.4.1 const的引用
常量引用是对 const 的引用,对象不必是常量。对 const 对象的引用也必须是常量。
引用必须初始化,因此常量引用也必须初始化。
注意引用不是对象,因此常量引用不是说引用是常量,引用本来就只能绑定一个对象,而是引用不能改变引用的对象了。
const int ci = 42;
const int &r = ci; // 用于声明引用的 const 都是底层 const
不能用非常量引用指向一个常量对象。可以用常量引用指向一个非常量对象。
引用的类型必须与其所引用对象的类型一致,但是有两个例外。其中一个例外就是初始化常量引用时允许用任意表达式作为初始值(包括常量表达式),只要该表达式结果可以转换为引用的类型。
const int &r = 42; // 常量引用可以绑定字面值
当用常量引用绑定一个非常量对象时,不能通过引用改变引用对象的值,但是可以通过其他方式改变值。常量指针也一样。
2.4.2 指针和const
指向常量的指针的用法和常量引用相似,**但是是不一样的。**它既可以指向常量也可以指向非常量,不能改变对象的值。但是非常量对象可以通过其他途径改变值
2.4.3 顶层const
顶层 const 表示指针本身是个常量,底层 const 表示指针所指的对象是一个常量。顶层 const 对任何数据类型通用,底层 const 只用于引用和指针。
顶层 const 的指针表示该指针是 const 对象,因此必须初始化。底层 const 的指针则不用。
实际上只有指针类型既可以是顶层 const 也可以是底层 const,因为引用实际上只能是底层 const,常量引用即为底层 const,不存在顶层 const 的引用。
const int &const p2 = p1;// 错误
从右向左读来判断是顶层 const 还是底层 const。
对于指针和引用而言,顶层 const 在右边,底层 const 在左边。对于其他类型,全都是顶层 const
const int* const p3 = p2; // 从右向左读,右侧const是顶层const,表明p3是一个常量,左侧const是底层const,表明指针所指的对象是一个常量
const int* p2 = &c; // 这是一个底层const,允许改变 p2 的值
int* const p1 = &i; // 这是一个顶层const,不能改变 p1 的值
执行对象的拷贝操作时,不能将底层 const 拷贝给非常量,反之可以,非常量将会转化为常量。
2.4.4 constexpr和常量表达式
常量表达式是指值不会改变并且在编译过程就能得到计算结果的表达式。
字面值属于常量表达式,由常量表达式初始化的 const 对象也是常量表达式。
const int a = 32; // 是常量表达式
const int b = a + 1; // 是常量表达式
const int sz = get_size(); // 不是常量表达式,因为虽然 sz 是常量,但它的具体值等到运行时才知道。
cosntexpr变量
在实际应用中很难分辨一个初始值是否是常量表达式,通过将变量声明为 constexpr 类型即可由编译器来检查。
由 constexpr 声明的变量必须用常量表达式初始化。
建议:如果认定一个变量是常量表达式,就把它声明为 constexpr 类型。
新标准允许定义 constexpr,这种函数应该足够简单以使得编译时就可以计算其结果。
不能用普通函数初始化 constexpr 变量,但可以使用 constexpr 函数初始化 constexpr 变量。
constexpr int sz = size(); //只有当 size() 是一个 constexpr 函数时这才是一条正确的声明语句。
字面值类型
算术类型、引用、指针都属于字面值类型,自定义类则不属于。
cosntexpr 指针的初始值必须是 nullptr 或 0 或存储于固定地址的对象。函数体之外的对象和静态变量的地址都是固定不变的。
指针和constexpr
注意区分 constexpr 和 const 。constexpr 都是顶层 const,仅对指针本身有效。
const int *p = nullptr; // p 是一个指向整型常量的指针
constexpr int *q = nullptr; // q 是一个指向整数的常量指针
区分const和constexpr
constexpr 限定了变量是编译器常量,即变量的值在编译器就可以得到。
const 则并未区分是编译器常量还是运行期常量。即 const 变量可以在运行期间初始化,只是初始化后就不能再改变了。
constexpr 变量是真正的“常量”,而 const 现在一般只用来表示 “只读”。
2.5 处理类型
2.5.1 类型别名
有两种方法定义类型别名。
typedef double wages; // 使用 typedef 关键字
using wages = double; // 使用 using 关键字进行别名声明
typedef 作为声明语句中的基本数据类型的一部分出现。含有 typedef 的声明语句定义的不再是变量而是类型别名。和其他声明语句一样,typedef 的声明语句中也可以包含类型修饰符,从而构造符合类型。
typedef wages base, *p; // base 是 double 的别名,p 是 double* 的别名。
指针、常量和类型别名
typedef char* pstring;
const pstring cstr = 0; // 注意:const 是一个指向 char 的常量指针。不能采用直接替换的方式将其理解为 const char* cstr = 0,这是错误的。
2.5.2 auto类型说明符
auto 说明符让编译器根据初始值来分析表达式所属的类型。理解:使用 auto 会增加编译时间,但不会增加运行时间。
auto 可以在一条语句中声明多个变量,但是多个变量必须是同一个基本数据类型(整型与整型指针和整型引用算一个类型)。
复合类型、常量和auto
编译器推断出的 auto 类型有时和初始值并不一样,编译器会进行适当的调整:
- auto 根据引用来推断类型时会以引用对象的类型作为 auto 的类型。
- auto 一般会忽略掉顶层 const,因此对于非指针类型的常量对象,auto 推断出的结果是不含 const 的。如果希望 auto 是一个顶层 const,需要明确指出。
- auto 会保留底层 const。
概括一下就是 auto 会忽略引用与顶层 const。
const int ci = 1, cr = ci;
auto b = ci; // b 是一个普通的 int。
auto c = cr; // c 是一个普通的 int。
const auto d = ci; // d 是一个 const int
auto &e = ci; // e 是一个常量引用(常量引用是底层 const)。注意这个微妙的地方。
auto f = &ci; // f 是一个 const int*(位于左边的 const 是底层 const)
int 与 int *、int & 是一个基本数据类型,而 const int 与 int 不是一种类型。
用 auto 定义引用时,必须用 & 指明要定义的是引用。
2.5.3 decltype类型指示符
当希望获得表达式的类型但是不要值的时候,可以使用类型说明符 decltype。
如果 decltype 使用的表达式是一个变量,则它返回该变量的类型(包括顶层 const 和引用在内)。
decltype 与 auto 的不同:decltype 不会忽略引用和顶层 const。
注意当获得的类型是引用时,必须初始化。
const int ci = 0, &cj = ci;
decltype(ci) x = 0; // x 的类型是 const int
decltype(cj) y = x; // y 的类型是 const int&
decltype(cj) z; // z 是一个引用,必须初始化
引用从来都是作为对象的别名出现,只有在 decltype 处是例外。
decltype 和引用
如果 decltype 使用的表达式不是一个变量,则 decltype 返回表达式结果对应的类型。可以使用这种方式来保证不获取引用类型。
注意解引用指针的结果是一个引用类型。给变量加括号的结果也是引用类型。赋值操作的结果也是引用类型。
int i = 42, &r = i, *p;
decltype(r+0) b; // b 的类型是 int,因为 r+0 的结果类型是 int。
decltype(*p) c = i; // c 的类型是 int&。
decltype((i)) d = i; // d 的类型是 int&。
decltype((var)) 的结果永远是引用,而 decltype(var) 的结果只有当 var 本身就是引用时才是引用。
2.6 自定义数据结构
2.6.1 定义sales_data类型
struct+类名+类体+**分号。**类体可以为空。
struct Sales_data{}; // 注意:结尾加分号
定义类时可以给数据成员提供类内初始值以进行初始化。没有类内初始值的成员则被默认初始化。
类内初始值可以放在花括号中或等号的右边,不能使用圆括号。
2.6.3 编写自己的头文件
类通常定义在头文件中,类所在头文件的名字应与类的名字一样。
头文件通常定义那些只能被定义一次的实体,比如类、const、constexpr 等。
头文件一旦改变,相关的源文件必须重新编译以获取更新过的声明。
预处理器概述
确保头文件多次包含仍能安全工作的常用技术是预处理器。
预处理变量有两种状态:已定义和未定义。一般把预处理变量的名字全部大写。
整个程序中的预处理变量包括头文件保护符必须唯一,通常基于头文件中类的名字来构建保护符的名字,以确保其唯一性。
c++ 中包含三个头文件保护符****:
- #define:把一个名字设定为预处理变量
- #ifndef:当且仅当变量已定义时为真,一旦检查结果为真,则执行后续操作直到遇到 #endif 为止
- #endif
预处理变量无视作用域的规则,作用范围是文件内
问题
- 指针和引用有4点不同,分别是哪些?
- const 对象必须怎样
- const 对象的作用范围
- 什么是常量引用,如何声明,是顶层还是底层
- 常量引用与常量对象、非常量对象的关系。
- 什么是常量指针,如何声明,是顶层还是底层
- 常量指针与常量对象、非常量对象的关系。
- 顶层 const 和底层 const 都是什么,在什么位置
- 如何区分顶层 const 和底层 const
- constexpr 是什么,特点是什么
回答
- 指针是对象而引用不是;指针可以重定向引用不可以;有指向指针的指针无引用的引用;引用必须初始化指针不需要
- 必须初始化
- 默认范围是文件内
- 不能改变对象的引用是常量引用,const int& i = a,是底层 const
- 不能用非常量引用绑定常量对象,可以用常量引用绑定非常量对象。
- 常量指针表明指针是个常量,其内存储的地址不能改变,但是指针还能修改所指对象的值。int* const p = a,是顶层const。
- 可以用常量指针指向非常量对象。
- 顶层 const 表示指针本身是常量,底层 const 表示所指对象是常量**。顶层 const 在右边,底层 const 在左边**
- 只有指针同时有顶层和底层,const 在星号右边是顶层,左边是底层。引用的 const 是底层,其他类型 const 是顶层。
- 常量表达式。两个点:值不能改变、在编译阶段就可以计算出值
问题
- 浮点数赋给整型变量时如何舍入?
- decltype 是什么,如何使用
- 如何声明而非定义一个变量
- 如果指针不初始化会有什么影响
- 如何在多个文件间共享 const 对象
- 使用 auto 来定义引用时要注意什么
- 预处理变量的作用范围是什么
- C++属于静态类型语言,静态类型语言的含义是什么?
- C++有两种定义类型别名的方式,分别是什么
回答
- 只保留小数点前的部分,即向零舍入
- 用来获取变量类型,decltype© a;
- 使用 extern 修饰符: extern int i:
- 在块作用域中,未初始化的指针的值是未定义的。
- 如果想在多个文件间共享const对象,必须在变量的定义前添加extern关键字并在本文件中声明。声明和定义都要加extern
- 用 auto 定义引用时,必须要加 & 符号。尤其是在范围 for 循环中,当想要修改值时,一定要记得加上引用符。
- 文件内。
- 静态类型语言在编译时检查变量类型。
- typedef unsigned int size_type 和 using size_type = unsigned int;
第3章 字符串、向量和数组
string、vector是两种最重要的标准库类型,迭代器是一种与 string 和 vector 配套的标准库类型。
内置数组和其他内置类型一样,数组的实现和硬件密切相关,因此与string和vector相比,数组在灵活性上稍显不足。
3.1 命名空间的using声明
可以对单个名字进行独立的using声明
using std::cin;
头文件里不应包含 using 声明
3.2 标准库类型string
string 表示可变长的字符序列。
string 定义在命名空间 using 中。
3.2.1 定义和初始化string对象
string 默认初始化为一个空的 string。
string s1; //将 s1 默认初始化为一个空的 string
string s1(s2); //使用拷贝构造函数进行的拷贝初始化。s1 是 s2 的拷贝。
string s1 = s2; //使用拷贝赋值运算符进行的拷贝初始化。s1 是 s2 的拷贝。
string s1("value"); //s1 是字面值 "value" 去除最后一个空字符后的拷贝。
string s1 = "value"; //同上。
string s1(n,'c'); //s1 初始化为 n 个 'c'。
注意:使用字符串字面值或字符数组初始化 string 对象时,string 对象中是不包含末尾的空字符的,它会将字符数组中末尾的空字符去掉。
初始化方式
拷贝初始化:使用等号
直接初始化:不使用等号
列表初始化:使用花括号{}
3.2.2 string对象上的操作
getline(is, s2);//从输入流 is 中读取一行赋给 s2,is 是输入流。
s.empty();//s为空则返回 ture
s.size(); //返回字符数,类型为 size_type,无符号整数
s[n]; //对 s 中元素的索引
s3 = s1 + s2;//连接 s1 与 s2,加号两边必须至少有一个是 string,不能都是字面值,比如 "world"+"hello" 是错误的
<.<=,>,>=; //比较时从前往后比较单个字母的大小
因为 cin 会自动忽略开头的空白并遇到空白就停止读取,因此不能使用 cin 读取句子;
字符串字面值与 string 是两种不同的类型
读写string对象
可以使用 cin, cout 来读写 string 对象,也可以使用 stringstream 来读写 string 对象。
getline 函数
getline() 定义在头文件 string 中,以一个 istream 对象和一个 string 对象为输入参数。getline() 读取输入流的内容直到遇到换行符停止,然后将读入的数据存入 string 对象。
注意 getline 会将换行符也读入,但是不将换行符存入 string 对象。即触发 getline() 函数返回的那个换行符实际上被丢弃掉了。
getline() 只要一遇到换行符就结束读取操作并返回结果,即使一开始就是换行符也一样,这种情况下会得到一个空 string。
**getline() 与 << 一样,会返回它的流参数。**所以可以用 getline 的结果作为条件。
string::size_type 类型
string 的 size() 成员函数返回一个 string::size_type 类型的值。
大多数标准库类型都定义了几种配套的类型,这些配套类型体现了标准库与机器无关的特性。
在具体使用时,通过作用域操作符来表明 size_type 是在类 string 中定义的。
string::size_type 是无符号值,可以确定的是它足够存放任何 string 对象的大小。
C++11 允许通过 auto 和 decltype 来获得此类型。
auto len = s.size();// len 的类型是 string::size_type
不要在同一个表达式中混用 size_type 和 int 类型。
3.2.3 处理string对象中的字符
cctype 头文件中有下列标准库函数来处理 string 中的字符。
下面这些函数的输入和返回值实际都是 int 类型的,且输入的值 c 必须满足 -1<=c<=255,即输入必须是 ASCII 字符。
int isalnum(int c); // 当c是字母或数字时为真
isalpha(c); // 当c是字母时为真
isdigit(c); // 当c是数字时为真
islower(c); // 当c是小写字母时为真
isupper(c); // 当c是大写字母时为真
ispunct(c); // 标点符号
isspace(c); // 空白(包括空格、制表符、回车符、换行符等)
tolower(c); // 字符转换为小写,返回转换结果
toupper(c); // 字符转换为大写,返回转换结果
'应用'
tolower(string[4]);
建议:使用 c++ 版本的标准库头文件,即 cname 而非 name.h 类型的头文件。cname 头文件中的名字都从属于命名空间 std;
范围for语句
string str;
for(auto c:str) // 对于str中的每个字符
cout << c << endl; // 输出当前字符,后面紧跟一个换行符
当要改变 string 对象中的值时,需要把循环变量定义成引用类型。必须通过显示添加 & 符号来声明引用类型。
不能在范围 for 语句中改变所遍历序列的大小。
for(auto &c:str)
c = toupper(c); // 转换为大写
对 string 的最后一个字符进行索引:s[s.size()-1];
索引必须大于等于 0 小于 size,使用索引前最好用 if(!s.empty()) 判断一下字符串是否为空。
任何表达式只要是整型值就可以作为索引。索引是无符号类型 size_type;
3.3 标准库类型vector
vector 是一个类模板
vector 是模板,vector 是类型
3.3.1 定义和初始化vector对象
vector 默认初始化为一个空 vector。
vector v2(v1); // v2=v1
vector v3(10,"hi"); // 10个string
vector v4(10); // 10个空string
vector v5{"an","the"}; // 列表初始化
值初始化
**值初始化的方式:**如果对象是内置类型,则初始值为 0,如果是类类型,则由类默认初始化。
列表初始化
使用花括号一般表示列表初始化:初始化过程会尽量把花括号内的值当作一个初始值列表来处理。
如果花括号内的值不能用来列表初始化,比如对一个 string 的 vector 初始化,但是花括号内的值为整型,如下:
vector v {10}; // v 有 10 个默认初始化的元素
vector v {10, "hi"}; // v 有 10 个值为 "hi" 的元素
3.3.2 向vector对象中添加元素
vector可以高效增长,通常先定义一个空 vector,然后在添加元素会更快速。
定义 vector 时,已知 vector 的大小,如果初始值都一样,初始化时确定大小与值会更快。如果初始值不全一样,即使已知大小,最好也先定义一个空的 vector,再添加元素。
3.3.3 其他vector操作
v.size();
v.empty();
v.push_back(t);
可以用范围 for 语句处理 vector 序列的元素
3.4 迭代器介绍
所有标准库容器都可以使用迭代器
3.4.1 使用迭代器
auto b = v.begin(), e = v.end();
auto d = v.cbegin(); f = v.cend(); // 返回的是const_iterator
end 成员指向容器的”尾后元素“
如果容器为空,则 begin 和 end 返回的都是尾后迭代器
*iter // 返回iter所指元素的引用
iter->mem // 等价于 (*iter).mem
++iter // 指向下一个元素
迭代器的类型是 iterator 或 const_iterator 来表示
vector::iterator it = v.begin();
string::iterator it;
3.4.2 迭代器运算
string 和 vector 支持的迭代器运算。注意不能将两个迭代器相加。
iter + n;
iter += n;
iter1 - iter2; // 返回两个迭代器之间的距离,difference_type类型的带符号整数
>, >=, <, <=; // 比较运算符
3.5 数组
数组的大小确定不变
3.5.1 定义和初始化内置数组
int a[10]; // 数组的维度必须是个常量表达式
数组和 vector 的元素都必须是对象,不能是引用
数组不能用 auto 来定义。
字符数组的特殊性
char a1[] = {'c', '+', '+'}; // 列表初始化,没有空字符,维度是3
char a2[] = "c++"; // 有空字符,维度是4
const char a4[3] = "c++"; // 错误,没有空间存放空字符
不能用数组为另一个数组赋值或拷贝。可以按元素一个一个拷贝,但不能直接拷贝整个数组。
按照由内向外的顺序理解数组的类型
int *ptrs[10]; // ptrs是一个含有10个整型指针的数组
int (*ptrs)[10] = &arr; // ptrs是一个指针,指向一个含有10个整数的数组
int (&ptrs)[10] = &arr; // ptrs是一个引用,引用一个含有10个整数的数组
3.5.2 访问数组元素
数组下标通常用 size_t 类型
使用范围 for 语句遍历数组元素
3.5.3 指针和数组
在大多数情况,使用数组类型的对象其实是使用一个指向该数组首元素的指针
标准库类型(如 string、vector 等)的下标都是无符号类型,而数组内置的下标没有这个要求。
指向数组元素的指针等价于 vector 中的迭代器
3.5.4 C风格字符串
c++ 支持 c 风格字符串,但是最好不要使用,c 风格字符串使用不便,并且极易引发程序漏洞
c 风格字符串不是一种类型,而是一种写法,是为了表达和使用字符串而形成的一种约定俗成的写法。
用这种写法书写的字符串存放在字符数组中并以**空字符(‘\0’)**结束。
c 风格字符串函数
strlen(p); // 返回 p 的长度,不包括空字符
strcmp(p1, p2); // 比较 p1 与 p2,如果 p1 大于 p2,返回一个正值,如果相等返回 0,否则返回负值。
strcat(p1, p2); // 把 p2 附到 p1 之后,并返回 p1
strcpy(p1, p2); // 把 p2 拷贝给 p1,返回 p1
这些函数都不验证参数。传入参数的指针必须指向以空字符结束的数组。必须确保数组足够大。
char ca[] = {'q','b','d'}; // 使用列表定义的都没有空字符
对于 string,可以使用 s = s1 + s2,s1 > s2 等加和与比较,而 c 风格字符串不行,因为他们实际上是指针。
3.5.5 与旧代码的接口
string对象和C风格字符串的混用
可以使用字符串字面值来初始化 string 对象或与 string 对象加和,所有可以用字符串字面值的地方都可以使用以空字符结束的字符数组来代替。
反过来不能使用 string 对象初始化字符数组,必须要用 c_str() 函数将 string 对象转化为 c 风格字符串
const char* cp = s.c_str(); // s.c_str() 返回一个指向以空字符结束的字符数组的指针。
使用数组初始化 vector 对象
可以使用数组来初始化 vector 对象,用两个指针来表明范围(左闭合区间)
int arr[] = {0, 1, 2, 3, 4, 5};
vector ivec(begin(arr), end(arr));
建议不要使用 c 风格字符串和内置数值,都使用标准库容器
3.6 多维数组
严格来说 C++ 中没有多维数组,那实际是数组的数组。
int arr[10][20][30] = {0}; // 将所有元素初始化为 0
多维数组的初始化
'显式初始化所有元素'
int arr[2][3] = {1,2,3,4,5,6};
int arr[2][3] = { {1,2,3},{4,5,6} };//上面这两种方式效果是一样的
'显式初始化部分元素'
int arr[2][3] = { {1},{4,5} };//将第一行第一个元素和第二行第一、二个元素初始化为1,4,5,其他元素执行值初始化。
多维数组的下标引用
int arr[2][3];
arr[0];//这是一个有三个元素的一维数组
arr[0][0];//第一行第一列的元素
使用范围 for 语句处理多维数组
新标准中可以使用范围 for 语句处理多维数组。
注意范围 for 语句中改变元素值要显示使用 & 符号声明为引用类型。
注意:使用范围 for 循环处理多维数组时,除了最内层的循环外,其他所有循环的控制变量都应该是引用类型。
因为如果不声明为引用类型,编译器会自动将控制变量转换为指向数组首元素的指针,就不能在内层继续使用范围 for 循环处理该控制变量了。
for(auto& row : arr)
for(auto col : row)
使用 3 种方式来输出 arr 的元素
// 范围 for 语句-不使用类型别名
for (const int (&row)[4] : arr)
for (int col : row)
cout << col << " "; cout << endl;
// 范围 for 语句-使用类型别名
using int_array = int[4];
for (int_array &p : ia)
for (int q : p)
cout << q << " ";
cout << endl;
// 普通 for 循环
for (size_t i = 0; i != 3; ++i)
for (size_t j = 0; j != 4; ++j)
cout << arr[i][j] << " ";
cout << endl;
// 指针
for (int (*row)[4] = arr; row != arr + 3; ++row)
for (int *col = *row; col != *row + 4; ++col)
cout << *col << " ";
cout << endl;
问题
- 使用加号连接字符串/string时要注意什么
- string 的索引是什么类型,s.size() 返回什么类型。
- 如何方便地判断 string 中的某个字符的类型(比如是数字还是字母)以及转换某个字符的大小写。
- 值初始化的结果是怎样的
- 定义 c 风格数组时数组维度的限制条件
- 如何使用数组来初始化 vec
- string 类型可以隐式转化为 c 风格字符串(即字符数组)吗?
- 如何将 string 类型转化为 c 风格字符串
- 使用 getline() 函数从输入流读取字符串存到 string 中,存储的内容有换行符吗?
- 使用范围for循环要注意什么?
回答
- 加号两边至少有一个是 string 类型,不能都是字符串
- 都是 string::size_type 类型,是无符号值。
- 使用 cctype 头文件中的 isalnum(), isalpha(), isdigit(), isupper(), islowwer(), ispunct(), isspace(), tolower(), toupper() 等类型。
- 值初始化会将内置类型初始化为 0,类类型由类自己来默认初始化。
- 维度必须是个常量表达式,即在编译阶段就可以确定值。(因为数组维度是数组的类型的一部分,而 C++ 是静态语言,即在编译阶段就要确定类型)
- vector vec(begin(arr),end(arr));
- 不可以(从 C 风格字符串到 string 的转换是用了 string 的转换构造函数,而 string 并没有定义到 C 风格字符串的类型转换运算符)
- 使用 c_str() 函数
- 没有换行符。
- 如果要修改循环变量的值要将其声明为引用类型:auto &
问题
- 如果容器为空,begin() 的返回值是什么?
- 使用数组时要注意数组维度的什么特点?
- 区分 int *ptrs[10]; int (*ptrs)[10]; int (&ptrs)[10] 的不同含义
- C风格字符串属于什么类型?
回答
- 返回的是尾后迭代器,和 end() 的返回值一样。
- 使用数组时注意数组的维度必须是个常量表达式,因为数组的维度也属于数组类型的一部分,而编译器在编译阶段就需要知道数组类型。
- 他们分别定义了:一个包含10个整型指针的数组,一个指向包含10个整型值的数组的指针,一个包含10个整型值的数组的引用。
- C风格字符串本身不是类型,而是一种写法,它的类型是字符数组。要从字符数组的角度来理解C风格字符串的各项操作。
第4章 表达式
4.1 基础
4.1.1 基本概念
一般二元运算符都要求两个运算对象的类型相同或可以转换为同一种类型。
小整型(bool, char, short)通常会被提升为大整型,主要是 int。
运算符作用于类类型的对象时,用户可以自行定义含义,即重载运算符。
左值和右值
C++ 表达式要么是左值,要么是右值。
左值和右值不以位置来区分:
- 右值:当一个对象被用作右值时,用的是对象的值(内容)
- 左值:当一个对象被用作左值时,用的是对象的身份(在内存中的位置)
需要右值的地方可以用左值来代替,但是右值不能代替左值。
使用关键字 decltype 时,如果表达式的求值结果是左值,decltype 作用于该表达式(不是变量)得到一个引用类型。
运算符对于作用对象是左值还是右值会有要求,比如赋值运算符的左侧运算对象必须是左值。
4.1.2 优先级与结合律
左结合律:如果运算符优先级相同,按照从左向右的顺序组合运算对象。
大部分二元运算符满足左结合律,赋值运算符满足右结合律。
4.1.3 求值顺序
在一个复合表达式中,各个运算对象的求值顺序是不固定的。
cout << i << ++i << end;//错误!未定义的行为,不知道先求 i 还是先求 ++i
4种运算符明确规定了运算对象的求值顺序:逻辑与(&&)、逻辑或(||)、条件(?、逗号(,)
处理复合表达式的两个建议:
- 不确定优先级与结合律时使用括号
- 如果改变了某个运算对象的值,在同一表达式中不要再使用该运算对象。
4.2 算术运算符
算术运算符有 3 组,按优先级从高到低依次是
- +、- :一元正号与一元负号
- *、/、% :乘法、除法、求余
- +、- :加法、减法
注意一元正负号的优先级最高,求余也是一种算术运算。
整数除法的结果是向零舍入。
求余运算符的运算对象必须是整数,运算结果始终与被除数符号相同
4.3 逻辑和关系运算符
- 逻辑运算符:!、&&、||。逻辑运算符的作用对象必须是能转换成布尔值的类型
- 关系运算符:<, <=, >, >=, !=, == :大于小于的优先级高于等于和不等于
逻辑运算符与关系运算符的求值结果都是布尔值。
逻辑与和逻辑或都是先求左侧对象的值再求右侧。也就是 && 和 || 两个运算符自带了个 if 的功能。
布尔字面值
使用算术值做条件时直接用,不要与布尔值做比较
if(a);//正确
if(a == true);//错误:会将 true 先转换为 int 再比较,比较结果是不相等
4.4 赋值运算符
赋值运算符的左侧运算对象必须是一个可修改的左值
C++ 11 允许使用花括号括起来的初始值列表作为右侧运算对象。初始化列表可以为空,此时将进行值初始化。
赋值运算符满足右结合律。
a = b = 1;//正确,b 被赋值为 1,而后 a 被赋值为 b 的值。
赋值运算符优先级较低。
复合赋值运算符
+=; -=; *=; /=; %=; <<=; >>=; &=; ^=; |=;
位运算也可以使用赋值运算符。
复合赋值运算符只求值一次,而普通运算符需要两次。(a=a+1 要先求一次 a+1,再将结果赋值给 a)
4.5 递增和递减运算符
分为两种版本:前置版本和后置版本。
前置版本:首先将运算对象加 1,然后将改变后的对象作为求值结果。
后置版本:也是将运算对象加 1,但是求值结果是运算对象改变之前那个值的副本。
前置版本将对象本身作为左值返回,后置版本将对象的原始值的副本返回。
如无必要,不要使用后置版本。
前置版本直接返回改变了的运算对象,后置版本需要将原始值保存下来以便于返回,是一种浪费。
后置版本对于整数和指针来说影响不大,对于迭代器而言消耗巨大。
在一条语句中混用解引用和递增运算符
*p++ :p++将 p 的值加一,然后返回 p 的初始值的副本作为求值结果用于解引用。(递增运算符优先级高于解引用)
这是一种提倡的写法,更加简洁,应该习惯于这种写法。
auto pbeg = v.begin();
while(pbeg != v.end())
cout << *pbeg++ << endl;
4.6 成员访问运算符
点运算符和箭头运算符都可以用来访问成员。
ptr->mem 等价于 (*ptr)->mem
4.7 条件运算符
cond ? expr1 : expr2
可以使用嵌套条件运算符
finalgrade = (grade>90) ? "high pass" : (grade<60) ? "fail" : "pass";
条件运算符优先级非常低,通常都要加括号
4.8 位运算符
位运算符作用于整数类型的对象。
位运算符有六种:位求反、位与、位或、位异或、左移、右移。
~a; a&b; a|b; a^b; a<<2; a>>2;
如果运算对象是“小整型”,值会被自动提升为较大的整数类型。
运算对象可以带符号,也可以不带符号。不带符号的运算结果是固定的,带符号的运算结果依赖于机器。
左移操作处理带符号值是一种未定义的行为。
在 C++ 中,建议仅用位运算符来处理无符号类型。
移位运算符
使用移位运算符,移动的位数必须严格小于结果的位数,否则会产生未定义的行为。
<< 运算符在右侧插入 0,左侧移动超出边界的值舍弃掉。
>> 运算符处理无符号数时在左侧插入 0,右侧移动超出边界的值舍弃掉。
>> 运算符处理有符号数时可能在左侧插入 0 也可能插入符号位的副本,由机器决定使用哪种方式。
标准 IO 库所使用的 << 和 >> 都是重载版本。
移位运算符满足左结合律,以下两种等价。
cout << a << b << endl;
((cout << a) <位求反、位与、位或、位异或
这几种运算符处理 char 时,都会把 char 类型的运算对象首先零扩展提升成 int 类型再进行位运算。
在写代码时,考虑到可移植性,选取数据类型应考虑到某一类型的最大字节和最小字节,比如 int 的最小位是 2 字节。
4.9 sizeof运算符
sizeof 是一个运算符。
sizeof 返回一条表达式或一个类型名字所占的字节数,值为 size_t 类型。
sizeof(type)
sizeof expr;//返回表达式结果类型的大小
对数组执行 sizeof 运算符得到的是整个数组所占空间的大小。不会把数组转换为指针来处理。
但是对指针执行 sizeof 运算符得到的是指针类型的大小,也就是 8。
对 string 或 vector 对象执行 sizeof 运算只返回该类型固定部分的大小,不会计算对象中的元素占了多少空间。
可以用 sizeof 获得数组中元素的个数:
sizeof(arr)/sizeof(*arr);//返回的是数组 arr 的元素数量
4.10 逗号运算符
在 for 循环中可以用逗号分隔两个不同的条件
for(int i=0; i!=n; i++,j++)
注意不要在判断条件那里使用逗号分隔不同的条件,那样只会返回逗号分隔的最后一个表达式的值。
4.11 类型转换
c++ 不会直接将两个不同类型的值相加,会先通过类型转换把运算对象的类型统一后再求值。
隐式类型转换****的发生场景
- 比 int 类型小的整型值首先提升为较大的整数类型
- 在条件里,把非布尔值转换成布尔值
- 初始化过程中,初始值转换为变量的类型
- 赋值时,右侧运算对象转换成左侧类型
- 算数运算或关系运算的运算对象有多种类型,转换成一种。
4.11.1 算术转换
运算符的运算对象将转换成所有运算对象中最宽的类型。如果表达式中既有整型也有浮点型,一般会把整型转换为浮点型。
3.14159L + 'a';//先将'a'提升成 int,然后把 int 转换成 long double
整型提升
整型提升把小整数类型(包括 char、bool等)转换成较大的整数类型。如果 int 可以就转换成 int,否则提升成 unsigned int 类型
无符号类型的运算对象
如果一个是无符号一个带符号。如果无符号类型不小于带符号类型(比如都是 4 字节),则带符号转换为无符号
如果无符号类型小于带符号,转换结果依赖机器。尽量避免。
4.11.2 其他隐式类型转换
数组转换成指针
大多数情况下数组自动转换成指向数组首元素的指针。(decltype关键字参数、取地址符(&)、sizeof、typeid 都不会发生这种转换)
指针的转换
0 或 nullptr 都能转换成任意指针类型。指向非常量的指针能转换成 void*。指向所有对象的指针都能转换成 const void*。
转换成常量
指向非常量的指针转换成指向相应常量类型的指针
类类型定义的转换
while(cin>>s);//将 cin 转换为 bool 值
string s = "value";//将 c 风格字符串转换为 string
4.11.3 显式转换
显示转换即使用强制类型转换。
强制类型转换非常危险,尽量避免使用。如果使用了,应反复思考是否可以用其他方式代替。
castname(expression);
castname 有四种:static_cast、dynamic_cast、const_cast、reinterpret_cast 。它指定了执行哪种转换。
static_cast
任何类型转换,只要不包含底层 const,都可以用 static_cast
double slope = static_cast(j)/i; //将 j 转换成 double 以便执行浮点数除法
当把较大的类型转换为较小的类型时,static_cast 很有用。这时它告诉读者和编译器:我们知道且不在乎精度损失。平时编译器会给警告,显式转换后就不警告了。
const_cast
const_cast 只能改变对象的底层 const。可以去掉或增加 const 性质。
只有 const_cast 能改变表达式的常量属性,其他都不行。
const_cast 常用于有函数重载的上下文中。
string& s;
const_cast (s);// 将 s 转换为常量引用
const_cast (s);// 将 s 转换回非常量引用
reinterpret_cast
它依赖于机器,使用门槛很高,且使用时充满风险,不要用它。
旧式的强制类型转换
int(a);// 函数形式的强制类型转换
(int)a;// c 语言风格的强制类型转换
旧式的强制类型转换本质上采用 const_cast、static_cast 或 reinterpret_cast 的一种。
旧式与新式相比没那么清晰明了,如果出现问题,追踪困难。
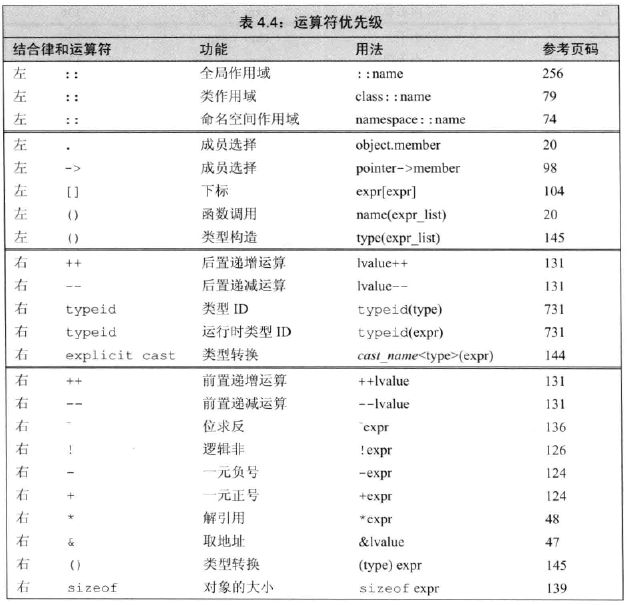
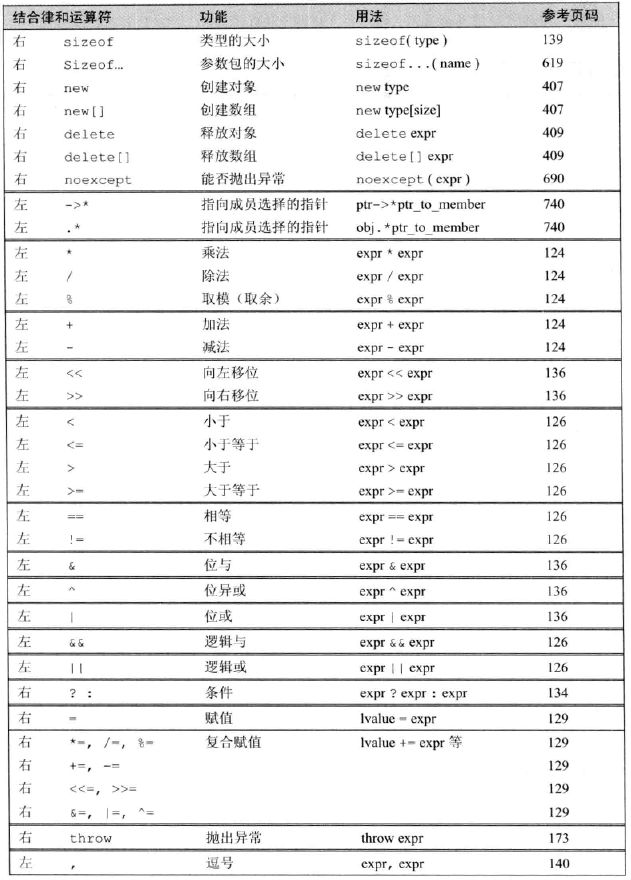
4.12 运算符优先级表
:: //作用域
. 和 -> //成员访问。注意它非常高,比括号还高。
[] 和 () ++、-- //注意递增递减运算符的优先级非常高,括号之下最高的。
, //逗号是最低的
问题
- 左值与右值的不同
- 左值与右值对 decltype 的影响
- 整数除法的结果是如何舍入的
- 理解运算符的返回值
- 区分递增运算符的前置与后置版本。
- 位运算符的使用要注意什么
- 运算符的结合顺序是怎样的
- sizeof 运算符的返回值是什么
- 常见的隐式类型转换的方式
- 四种显示类型转换是什么
- 常见的如 int 转换为 double 这样的转换用什么
- const_cast 用于什么时候
- 旧式的两种强制类型转换方式
- 需要记住的典型运算符的优先级
回答
- 使用左值使用的是对象的身份(在内存中的位置),使用右值使用的是对象的值(内容)。需要右值的地方可以用左值代替,反之不行。
- 如果 decltype 中的表达式返回的是左值,那么 decltype 得到是一个引用类型。
- 向零舍入
- 采用运算符进行各类运算时,把运算符理解为函数,返回值是运算符函数的返回值,cin>>10 的返回值是运算符 >> 的返回值
- 前置版本直接返回改变后的运算对象,后置版本返回的是运算对象改变前的原始值的副本。对迭代器使用后置递增消耗很大。
- 建议使用位运算符处理无符号类型。C++中使用位运算符处理带符号数的运算结果依赖于机器。
- 如果优先级相同,除了赋值运算符,其他运算符都是从左向右结合。
- sizeof 也是运算符,它返回一条表达式或一个类型所占的字节数。
- 算数运算中小整型(bool,char,short)提升为大整型(int)、整型转换为浮点型,条件里非布尔值转换为布尔值,初始化时初始值转换为变量的类型,赋值时右侧转换为左侧类型,算术运算或关系运算的运算对象被转换为同一种类型。数组和函数转换为指针,指向非常量的指针转换为指向常量的指针,c风格字符串转换为string,cin>>s 返回的的 cin 转换为 bool 值。
- static_cast(expression), const_cast, dynamic_cast, reinterpret_cast(不要用它)。
- 使用 static_cast(num) 来转换。
- const_cast 用于移除或增加对象的底层 const,即用于使不能修改引用对象值的引用和不能修改指向对象值的指针变成可以修改的,或者反过来。
- int(a) 和 (int)a。两种都可以,但是建议使用新式的代替。
- 作用域运算符优先级是最高的,成员访问运算符(. 和 ->)的优先级高于括号,也是非常高的。递增和递减的优先级也很高,是括号之下最高的。
第5章 语句
5.1 简单语句
表达式语句
一个表达式加上分号就是表达式语句。表达式的语句执行表达式并丢弃掉求值结果
ival + 3;//一条没有实际用处的表达式语句 cout << ival;//一条有用的表达式语句
空语句
空语句是最简单的语句,只有一个分号
;//空语句
用处:用在语法上需要一条语句但逻辑上不需要的地方。比如当循环的全部工作在条件部分就可以完成时。
使用空语句应该加上注释。
复合语句(块)
花括号括起来的语句和声明序列都是复合语句(块)。一个块就是一个作用域
空块的作用等价于空语句。
5.2 语句作用域
可以在 if、switch、while、for 语句的控制结构内定义变量。
常见的语句有条件语句、循环语句、跳转语句三种。
5.3 条件语句
两种:if 语句和 switch 语句
5.3.1 if语句
if 语句有两种形式,一种有 else 分支,另一种没有。
c++ 规定 else 与离他最近的尚未匹配的 if 匹配。注意不要搞错。
使用 if 语句最好在所有的 if 和 else 之后都用花括号。
5.3.2 switch语句
switch 语句计算一个整型表达式的值,然后根据这个值从几条执行路径中选择一条。
case 关键字和它对应的值一起被称为 case 标签,case 标签必须为整型常量表达式。
default 也是一种特殊的 case 标签。
switch(ch){
case 'a': ++aCnt; break;
case 'b': ++bCnt; break;
}
注意:如果 switch 条件值于某个 case 标签匹配成功后,程序将从该 case 标签一直执行到 switch 末尾或遇到 break。
一条 case 后可以跟多条语句,不必用花括号括起来。
一般在每个 case标签后都有一条 break 语句。如果需要两个或多个值共享同一组操作,可以故意省略掉 break 语句。
c++ 程序的形式比较自由,case 标签之后不一定要换行。
switch(ch){
case 'a': case 'b':
++Cnt;
break;
}
一般不要省略 case 分支最后的 break 语句。如果没有 break 语句,最好注释一下。
如果没有任何一个 case 标签匹配 switch 表达式的值,就执行 default 分支。
即使不准备在 default 下做任何工作,最好也定义一个 default 标签。
如果要在 case 分支定义并初始化变量,应该定义在块内以约束其作用域。
5.4 迭代语句
三种:while 语句、for 语句(包括范围 for 语句)、do while 语句
5.4.1 while语句
while 的条件不能为空。条件部分可以是一个表达式或带初始化的变量声明。
定义在 while 条件部分或循环体内的变量每次迭代都会重新创建和销毁。
while 适合不知道循环多少次的情况。
5.4.2 传统的for语句
for(init-statement; condition; expression)
statement;
init-statement 可以是声明语句、表达式语句或空语句。init-statement 可以定义多个对象,但是只能有一条声明语句。
expression 在每次循环之后执行。
for 语句头能省略掉三者中的任意一个或全部。
省略 condition 等于条件恒为 true。
5.4.3 范围for语句
范围 for 语句用来遍历容器或其他序列的所有元素。
for(declaration : expression)
statement
expression 表示的必须是一个序列,可以是花括号括起来的初始值列表。这些序列的共同的是都可以返回迭代器的 begin 和 end 成员。
declaration 定义一个能从序列中元素转换过来的变量(不是迭代器)。最简单的方法是使用 auto 类型说明符。
如果需要对容器中的元素执行写操作,必须将循环变量声明成引用类型。
循环变量可以声明为对常量的引用,不需要写时最好都声明为常量引用
每次迭代都会重新定义循环控制变量,并将其初始化为序列的下一个值。
范围 for 语句不能改变序列的元素数量。因为其预存了 end() 的值,改变元素数量后 end() 的值就可能失效了。
5.4.4 do while语句
do while 语句与 while 语句的唯一区别就是它先执行循环体后检查条件。即至少执行一次循环。
注意:do while 后不要忘了加分号。
因为 condition 在循环体后面,所以 condition 使用的变量应该定义在循环体外面。
5.5 跳转语句
四种:break、continue、goto、return
5.5.1 break语句
break 语句终止离它最近的 while、do while、for 或 switch 语句,并从这些语句之后的第一条语句开始执行。
break 语句只能出现在迭代语句或 switch 内部。
5.5.2 continue语句
continue 语句终止最近的循环中的当前迭代并开始下一次迭代。
continue 适用范围比 break 少了一个 switch
5.5.3 goto语句
goto 语句的作用是从 goto 语句无条件跳转到同一函数内的另一条语句。
label: int a = 1;
goto label;
label 是用于标识一条语句的标示符
标签标示符独立于变量或其他标示符的名字,标签标示符可以和程序中其他实体的标示符使用同一个名字而不会相互干扰。
如果 goto 语句跳回了一条变量的定义之前意味着系统将会销毁该变量,然后重新创建它。
不要使用 goto,它会令程序又难理解又难修改。
5.6 try语句块和异常处理
异常是指存在于运行时的反常行为,典型的异常有失去数据库连接和遇到意外输入等。处理异常可能是设计系统时最难的一部分。
当程序检测到一个无法处理的问题时,就需要异常处理,此时检测到问题的部分应该发出检测信号。
如果程序里有可能引发异常的代码,也应该有专门的代码处理问题。
C++ 的异常处理机制为异常检测和异常处理提供支持,它包括:
- **throw 表达式:**异常检测部分使用 throw 表达式来表示遇到了无法处理的问题。称为 throw 引发了异常。
- **try 语句块:**异常处理部分使用 try 语句块处理异常。try 语句块以关键字 try 开始,以一个或多个 catch 子句结束。
- **一套异常类:**用于在 throw 表达式和相关的 catch 子句间传递异常的具体信息。
5.6.1 throw 表达式
throw 表达式包含关键字 throw 和紧随其后的一个表达式,表达式的类型就是抛出的异常类型。
即 throw 后面跟一个异常类型的对象(必须同时使用 string 或 C 风格字符串对其初始化)。
throw runtime_error("Data must be same as size");//使用 throw 表达式抛出一个运行时错误。
5.6.2 try语句块
跟在 try 块后面的是一个或多个 catch 子句。catch 子句包括三部分:关键字 catch、括号内一个异常类型的对象的声明(叫做异常声明)、一个块。
当 try 语句块中抛出了一个异常,如果该异常类型与 catch 子句括号中的异常类型相同,就会执行该 catch 子句。
catch 一旦完成,程序就跳转到 try 语句块最后一个 catch 子句之后的那条语句继续执行。
在 catch 后面的括号里使用省略号(…)可以让 catch 捕获所有类型的异常。
每个标准库异常类都有一个 what 成员函数,它没有参数,返回初始化该对象时所用的 C 风格字符串。
try{
throw runtime_error("Data must be same as size");//try 语句块抛出了一个异常
}
catch(runtime_error err)//在 catch 后面的括号中声明了一个“runtime_error”类型的对象,与 try 抛出的异常类型相同,接下来执行此子句。
{
cout << err.what();//输出 "Data must be same as size"
}//
函数在寻找处理代码的过程中退出
throw 语句可能出现在嵌套的 try 语句块中或在 try 语句块中调用的某个函数内。当异常被抛出,程序会从内到外一层层寻找相应类型的 catch 子句。如果最后还是没找到,系统会调用 terminate 函数并终止当前程序的执行。
如果 throw 语句外就没有 try 语句块,也会执行 terminate 函数。
理解:异常中断了程序的正常流程。当发生异常,程序执行到一半就中断了,可能会存在如资源没有正常释放,对象没有处理完成等情况。异常安全的代码要求在异常发生时能正确执行清理工作。这个非常困难。
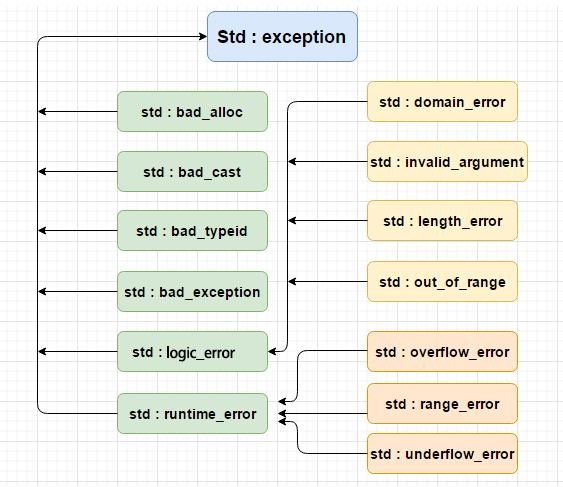
5.6.3 标准异常
C++ 标准库定义了一组异常类,用于报告标准库函数遇到的问题。他们定义在 4 个头文件中。
定义在 std::except 头文件中的类型必须使用 string 对象或 C 风格字符串来初始化他们。其他 3 个头文件中的 3 中类型则只能默认初始化,不能提供初始值。
异常类型只有一个 what 成员函数,该函数没有参数,返回是一个 C 风格字符串的指针,目的是提供关于异常的文本信息。
对于无初始值的异常类型,what 返回的内容由编译器决定,有初始值的返回初始值。
'exception头文件'
exception // 异常类 exception 是最通用的异常类。它只报告异常的发生,不提供额外信息。
'new头文件'
bad_alloc // 异常类 bad_alloc。在使用 new 分配动态内存失败时抛出
'type_info头文件'
bad_cast // 异常类型 bad_cast。经常发生在使用 dynamic_cast 时发生。
'stdexcept头文件'
exception
runtime_error // 只有在运行时才能检测出的问题
range_error // 运行时错误:生成的结果超出了有意义的值域范围
overflow_error // 运行时错误:计算上溢
underflow_error // 运行时错误:计算下溢
logic_error // 程序逻辑错误
domain_error // 逻辑错误:参数对象的结果值不存在
invalid_argument // 逻辑错误:无效参数
length_error // 逻辑错误:试图创建一个超出该类型最大长度的对象
out_of_range // 逻辑错误:使用一个超出有效范围的值
上面的异常类之间存在继承关系,其中 exception 是所有其他类的基类,总的继承关系如下图
例子
void StrBlob::check(size_type i, const string& msg) {
if (i >= data->size())
throw out_of_range(msg);
}
问题
- 使用范围 for 语句注意什么?
- try 语句块的使用方式
- C++ 定义了哪些异常类型
回答
- 如果要写元素的话必须要使用引用方式 auto&,但是建议不论何时都使用引用,且当不需要写时使用常量引用。
- throw 放在 try 块内,catch 用来捕获异常,可以使用省略号来捕获所有的异常类型。如果抛出了异常而未使用 catch 捕获,系统会调用 terminate 终止程序的运行。
- 如 exceptIon, bad_alloc, bad_cast,runtime_error, logic_error 等。定义在头文件 exception, new, type_info, std::except 等头文件中。
第6章 函数
6.1 函数基础
通过调用运算符 () 来执行函数。
函数的调用会完成****两项工作
- 用实参初始化函数对应的形参。
- 将控制器转移给被调用函数。
调用函数后,主调函数被中断,被调函数开始执行。
函数执行的第一步:隐式地定义并初始化它的形参。实参是形参的初始值,第一个实参初始化第一个形参。
return 语句完成****两项工作:
- 返回 return 语句中的值(如果有的话)
- 将控制权从被调函数转移回主调函数。
形参
可以没有形参名,但是函数无法使用未命名的形参,即使形参未命名,也要传入实参。
返回类型
返回类型不能是数组或函数类型,但是可以是数组指针或函数指针。
6.1.1 局部对象
名字有作用域,对象有生命周期
- 名字的作用域是程序文本的一部分,名字在其中可见
- 对象的生命周期是程序执行过程中该对象存在的一段时间
形参和函数体内定义的变量统称局部变量。
函数开始时为形参申请存储空间,函数终止形参被销毁
在所有函数外定义的对象存在于程序的整个执行过程中
局部静态变量
如果要让局部变量的声明周期不局限于函数内,可以将局部变量定义成 static 类型。
局部静态变量的生命周期:在程序的执行路径第一次经过对象定义语句时初始化,直到程序终止被销毁。
如果局部静态变量没有显式的初始值,将执行值初始化。
注意:局部静态变量是 static 型而不是 const 型
6.1.2 函数声明
函数的名字必须在使用前声明。
函数可以只声明无定义。
函数的声明和定义的区别在于声明不需要函数体,用一个分号代替。
函数的声明无需形参的名字(因为声明不包含函数体)。
函数的三要素:返回类型、函数名、形参类型。三要素描述了函数的接口。
建议在头文件中声明函数,在源文件中定义函数。
6.1.3 分离式编译
分离式编译允许把程序分割到几个文件中,每个文件独立编译。
6.2 参数传递
形参初始化的机理和变量初始化一样。
6.2.1 传值参数
c++ 中建议使用引用形参代替指针形参
6.2.2 传引用参数
引用形参在传递实参时直接传入对象。
如果函数不需要改变引用形参的值,最好声明为常量引用。
6.2.3 const形参和实参
用实参初始化形参时会忽略掉顶层 const,即形参类型为 const int 和 const 是一样的。理解:引用是没有顶层 const 的,因此顶层 const 适用于指针及其他类型,对于传值来说传递的是实参的副本,无论如何都不会改变实参,因此形参加不加顶层 const 都是一样的。
尽量使用常量引用做形参
注意常量引用的 const 是底层 const。
可以用字面值初始化常量引用
不能把 const 对象、字面值或需要类型转换的对象传递给普通的引用形参。但是可以传递给常量引用形参。
注意如果函数 a 把形参定义为了常量引用,函数 b 形参是普通引用,那么不能在 a 中使用 b 调用该常量引用形参。
6.2.4 数组形参
数组的两个特殊性质:不允许拷贝数组、使用数组时常会将其转换成指针
void print(const int*);
void print(const int[]);
void print(const int[10]);//三种声明等价,数字 10 没有什么实际影响
编译器只检查传入的实参是否为 const int* 类型。
使用数组做形参确保数组访问不越界的方法:
- 使用一个结束标记指定数组已结束,典型代表为 C 风格字符串
- 传递指向数组首元素和尾后元素的指针
- 专门定义一个表示数组大小的形参。
数组引用形参
可以定义数组引用形参。注意数组的大小是构成数组类型的一部分
func(int &arr[10]);//错误:arr 是引用的数组
func(int (&arr)[10]);//正确:array 是包含 10 个整数的整型数组的引用
int *arr[10];//指针的数组
int (*arr)[10];//指向数组的指针
6.2.5 main:处理命令行选项
可以给 main 函数传递实参,不过情况很少。
6.2.6 含有可变形参的函数
处理不同数量实参的主要方法有两种:
- 如果所有实参类型相同,传递一个 initializer_list 类型
- 使用省略符形参,它可以传递可变数量的实参,注意它一般仅用于与 C 函数交互的接口程序
initializer_list 形参
initializer_list 也是一种模板类型,定义在同名的头文件中。
initializer_list 与 vector 容器大致相同,但是它的元素都是常量值。
initializer_list 对象只能使用花括号初始化。
C++ 里的 vector 等各类容器使用列表初始化时本质上都是通过一个采用了 initializer_list 形参的构造函数进行初始化的。
initializer_list initlst;//默认初始化:空列表
initializer_list initlst{1,2,3,4};//initlast 的元素数量与初始值一样多
lst2(initlst); lst2 = initlst;//拷贝或赋值一个 initializer_list 对象不会复制元素,而是拷贝后两者共享元素。
initlst.size();
initlst.begin(); initlst.end();//注意返回的是指针
如果向 initailizer_list 形参中传递一个值的序列,必须把序列放在花括号里。
void func(initializer_list il)
func({3,4,5,2});
省略符形参
省略符形参仅用于 C 和 C++ 通用的类型,大多数类类型的对象传递给省略符形参都无法正确拷贝。
省略符形参只能出现于形参列表的最后一个位置
void func(parm_list,...);
void func(...);
6.3 返回类型和return语句
return的两个作用:
- 返回 return 语句中的值
- 终止当前正在执行的函数,将控制权返回到调用该函数的地方
6.3.1 无返回值函数
没有返回值的 return 只能用于无返回值函数
返回 void 的函数可以没有 return 语句,因为它会在最后一句后面隐式地执行 return。
6.3.2 有返回值函数
在含有 return 语句的循环和条件后面也应该有一条 return 语句。
返回一个值和初始化一个变量或形参的方式一样,返回的值用于初始化调用点的变量。
不要返回局部对象的引用和指针
const string& func() {
return "LiMing"
}//错误,字符串字面值转换成一个局部临时变量,不能返回局部对象的引用
引用返回左值
返回引用的函数返回的是左值,其他返回类型得到右值。
可以为返回类型是非常量引用的函数的结果赋值。
get_val(s,0) = 'A';
列表初始化返回值
vector process() {
string s;
if(condition1)
return {};// 返回一个空 vector 对象
else if(condition2)
return {"funcitonX",s};//返回一个列表初始化的 vector 对象
}
main 的返回值
允许 main 函数没有 return 语句直接结束,编译器隐式地插入一条 return 0;
main 函数地返回值相当于一种状态指示器,返回 0 表示执行成功,返回其他值表示执行失败。
cstdlib 头文件定义了两个预处理变量来表示成功与失败
return EXIT_FAILURE;//失败
return EXIT_SUCCESS;//成功
6.3.3 返回数组指针
函数可以返回数组的指针或引用
声明一个返回数组指针的函数
int *pf[10]; // 错误,指针的数组
int (*pf)[10]; // 正确,数组的指针
int (*func())[10];// 定义返回数组指针的函数。
auto func() -> int(*)[10];// 同上,此处使用了尾置返回类型
using arrT = int[10]; arrT* func();// 使用而类型别名
decltype(arr)* func();// 使用 decltype
有三种方法简化返回数组指针的函数的声明。
使用类型别名
可以使用类型别名简化数组指针的使用
typedef int arrT[10]; // arrT 表示含有 10 个整数的数组
using arrT = int[10];
arrT* func(int i); // 函数 func 返回一个指向含有 10 个整数的数组的指针
使用尾置返回类型
任何函数的定义都可以使用尾置返回,但是它更适用于返回类型复杂的函数
auto func() -> int;//返回 int 类型
auto func() -> int(*)[10];//返回一个指向 int 数组的指针
使用 decltype
如果已知函数返回的指针将指向哪个数组,可以使用 decltype
int odd[]={1,3,5,7,9};
decltype(odd)* func();//返回一个数组指针
注意 decltype 的结果是一个数组,要返回数组指针要加星号。
6.4 函数重载
main 函数不能重载
函数重载无法区分顶层 const 形参和非顶层 const 形参,但是可以区分底层 const 形参与普通形参
int func(int i);
int func(const int i);//顶层const,无法区分,相当于重复声明
int func(int* p);
int func(int* const p);//顶层const,无法区分,相当于重复声明
int func(int* p);
int func(const int* p);//底层const,可以区分,一个普通指针,一个常量指针
int func(int& i);
int func(const int& i);//底层const,可以区分,一个普通引用,一个常量引用
最好只重载确实非常相似的操作
const_cast 在重载中的应用
强制类型转换 const_cast 在重载函数中最有用。一个函数可能同时要有接受常量引用的版本也要有接受非常量引用的版本。
当要重载常量引用与非常量引用的版本时,在非常量引用的版本中可以通过 const_cast 将参数和返回值从常量引用转换为非常量引用,以实现对常量引用版本的调用。
string& s;
const_cast (s);// 将 s 转换为常量引用
const_cast (s);// 将 s 转换回非常量引用
6.4.1 重载与作用域
不同的重载版本要定义在同一作用域中(一般都是全局)
6.5 特殊用途语言特性
6.5.1 默认实参
设置默认值的形参必须都放在没有默认值的形参后面。
使用默认实参的时候省略该实参即可。默认实参负责填补函数调用时缺少的尾部实参。
通常应该在函数声明中指定默认实参,并将该声明放在合适的头文件中。
局部变量不能作为默认实参,全局变量和字面值都可以。
如果函数有默认实参,则调用函数时传入的实参数量可能少于它实际使用的实参数量
6.5.2 内联函数和constexpr函数
将规模较小的操作定义为函数****的优点:
- 阅读和理解函数调用更简单
- 使用函数可以确保行为统一
- 修改函数更方便
- 函数可以被重复利用
使用函数的缺点:
- 调用函数更慢
原因:需要保护现场及恢复等一系列操作,可能要拷贝实参,程序要转到新位置继续执行。
使用内联函数可****以避免调用函数的时间开销
在函数前用 inline 声明一下即表明是内联函数
内联函数适用于规模小、流程直接、频繁调用的函数
constexpr函数
constexpr 函数被隐式地指定为内联函数
cosntexpr 是指能用于常量表达式的函数。但是 constexpr 函数不一定返回常量表达式。
constexpr 函数的返回类型及所有的形参类型都必须是字面值类型,函数体中必须有且只有一条 return 语句。
内联函数和 constexpr 函数可以多次定义,但是多个定义必须完全一致。
应该把内联函数和constexpr函数的定义放到头文件里。
6.5.3 调试帮助
assert 预处理宏
用法:assert(expr); assert 宏定义在头文件 cassert 中。
如果表达式 expr 为假,assert 输出信息并终止程序,如果表达式为真,assert 什么也不做。
assert 常用于检查“不能发生”的条件
NDEBUG 预处理变量
如果定义了 NDEBUG,则 assert 什么也不做,默认状态下没有定义 NDEBUG。
预处理器定义了 5 个对于程序调试很有用的名字。
__func__;//当前函数名的字符串字面值
__FILE__;//当前文件名的字符串字面值
__LINE__;//当前行号的整型字面值
__TIME__;//文件编译时间的字符串字面值
__DATA__;//文件编译日期的字符串字面值
6.6 函数匹配
当有多个重载函数时,选出要调用的重载函数的流程:
1、找出所有的候选函数:同名函数并且在调用点声明可见。
2、从候选函数中找出所有的可选函数:实参数量与形参数量相同且类型相同或能转换为形参的类型。
3、从可行函数中找出最佳匹配。如果不存在最佳匹配会报错:二义性。
调用重载函数应尽量避免强制类型转换。
6.6.1 实参类型转换
实参类型到形参类型的转换分为几个等级,排序如下:
1、从数组类型或函数类型转化为对应的指针类型,添加顶层const或删除顶层const
2、通过const转换实现的匹配。
3、通过类型提升实现的匹配
4、通过算术类型转换或指针转换实现的匹配
5、通过类类型转换实现的匹配
注意:所有算数类型转换的级别都一样。
6.7 函数指针
函数指针是指向函数类型的指针,就像 int 指针是指向 int 类型的指针。
一种函数指针只能指向一种特定的函数类型:
bool Compare(const string&, const string&); // 此函数的类型是 bool(const string&, const string&);
bool (*pf)(const string&, const string&); // 声明了一个指向 bool(const string&, const string&) 类型函数的指针,注意括号不能少;
pf = Compare; // 给指针赋值,指向 Compare 函数
pf = &Compare; // 这两种赋值语句完全等价
bool b1 = pf("hello","goodbye"); // 可以直接使用指针替代函数名调用函数。
bool b2 = (*pf)("hello","goodbye"); // 与上面的等价
当把函数名作为一个值使用时,函数自动地转换成指针。
不同函数类型的指针间不能相互转换。函数指针也可以指向 nullptr 或 0。
对于重载函数,指针类型必须与重载函数中的某一个精确比配。
函数指针的别名
函数指针写起来很复杂,尤其是将函数指针作为函数的返回值时,因此一般为其定义别名。定义别名时要注意区分函数类型、函数指针。
下面几个等价:定义的别名都是函数类型。
typedef bool func(const string&, const string&); // 定义了一个别名:func,但是 func 是函数类型
typedef decltype(Compare) func2; // 定义了一个别名:func2,func2 也是函数类型
using func3 = bool(const string&, const string&); // 定义了一个别名:func3,func3 也是函数类型
注意 decltype(函数名) 返回的不是指针,是函数类型,加上 * 才表示函数指针。
下面几个等价:定义的别名都是函数指针。
typedef bool (*func)(const string&, const string&); // 定义了一个别名:func, func 是函数指针
typedef decltype(Compare)* func2; // 定义了一个别名:func2,func2 也是函数指针
using func3 = bool(*)(const string&, const string&); // 定义了一个别名:func3,func3 也是函数指针
函数指针形参
函数不能作形参,但是函数指针可以做形参,之后在调用时可以直接传入函数名作实参
函数名做形参也会自动的转换为指针。
bool GetBigger(const string& s1, const string& s2, bool(*comp)(const string&, const string&)); // 函数指针做形参
GetBigger(s1, s2, Compare); // 实参直接传入函数名 Compare
返回函数指针
不能返回一个函数,但是可以返回函数指针(注意这时函数名不会自动转换为函数指针)。
声明一个返回函数指针的函数有几种方法,其中直接声明最麻烦,使用尾置类型和 decltype 更简单一些,但是最好使用类型别名。
'直接声明'
bool (*f1(int))(double); // f1 是一个函数,函数的形参列表为 int,返回类型为函数指针。这个函数指针的类型为 bool (*)(double),即形参为 double,返回类型为 bool。
'使用尾置类型' auto f1(int) -> bool(*)(double);
'使用 decltype'
bool func(double);
decltype(func)* f1(double);
'使用类型别名'
using PF = bool(*)(double);
PF f1(int);
问题
- 函数执行的第一步是什么。
- 知识点:在函数调用时会发生控制权的转移:主调函数被终端,被调函数开始执行。
- 知识点:函数的返回类型不可以是数组或函数,但是可以是数组指针或函数指针。
- 局部静态变量的生命周期
- 函数的三要素
- 函数使用引用形参时的注意事项
- 处理可变形参(即可以传递不同数量实参的形参)的方法。
- 理解 initializer_list
- 函数返回引用和非引用的区别。
- 知识点:可以在 return 语句中直接构造返回的对象,比如在 return 语句中调用某个类的构造函数临时构造对象以返回,或直接使用列表初始化。
回答
- 隐式地定义并初始化它的实参。
- 知识点:在函数调用时会发生控制权的转移:主调函数被终端,被调函数开始执行。
- 函数的返回类型不可以时数组或函数,但是可以是数组指针或函数指针。
- 从程序执行到静态变量定义开始,到程序执行结束。
- 返回类型、函数名、形参类型
- 尽量使用常量引用形参,const 对象、字面值、需要类型转换的对象都只能传递给常量引用形参,不能传递给普通引用形参。
- 可以使用 initailizer_list 类型或省略符形参(基本不用)。
- initializer_list 是一个模板,只能使用花括号初始化,本质上 vector 等容器的列表初始化就是采用了 initializer_list 类型作为构造函数的形参。
- 返回引用的函数返回的是左值,返回非引用的函数返回的是右值。可以为返回类型是非常量引用的函数的结果赋值。注意返回引用时不能返回局部变量的引用。
- 知识点:可以在 return 语句中直接构造返回的对象,比如在 return 语句中调用某个类的构造函数临时构造对象以返回,或直接使用列表初始化。
问题
- main 的返回值是什么
- assert 预处理宏的用法
- 预处理器定义了 5 个对程序调试很有用的名字。
- 如何定义函数指针?如何定义类型别名来使用函数指针
- 如何使用默认实参
回答
- 如果程序执行成功,main 返回 0,返回其他值表示执行失败。
- 用于调试 assert(expr)。
- func, FILE, LINE, TIME, DATA
- int (pf) (const int &n); 定义类型别名:using PF = int()(const int &n); PF 和 pf 类型相同。
- 通常在函数声明时指定默认实参。有默认值的形参应该在没有默认值的形参之后。可以用全局变量和字面值作为默认实参,不能用局部变量。(区分函数的默认实参和类的类内初始值)
第7章 类
类的基本思想:数据抽象和封装
封装:将接口和实现分离
7.0 积累总结
7.0.0 类的 const 成员函数
const 成员函数不会修改类的数据成员。
const 成员函数的声明和定义处都要加 const,声明方式:
int age() const;//在类内的声明
int Student::age() const {};//在类外的定义
使用 const 成员函数要注意,不能用它调用本类的非 const 成员函数,调用的也必须是 const 成员函数。
7.0.1 关于类的 private 成员的访问权限
在类的成员函数中可以访问同类型实例的私有成员。
7.1 定义抽象数据类型
7.1.1 设计sales_data类
设计类的接口时,要考虑如何使类易于使用。当使用类时,不应该顾及类的实现机理。
7.1.2 定义改进的sales_data类
定义在类内部的函数是隐式的inline函数
7.1.3 定义类相关的非成员函数
空
7.1.4 构造函数
构造函数用来初始化类对象的数据成员。当类的对象被创建时,就会执行构造函数
构造函数没有返回类型。
构造函数可以重载。
如果类没有任何构造函数则编译器自己会创建默认构造函数(适用范围很小,尽量不要如此)
7.1.5 拷贝、赋值和折构
对于拷贝、赋值和销毁对象等操作,类都通过相应的成员函数实现其功能,如果不主动定义这些操作,编译器就合成默认的版本。
对于某些类来说,无法使用默认合成的版本,比如管理动态内存的类就不能。
7.2 访问控制与封装
class 和 struct 的唯一一点区别就是默认访问权限不同。
当希望类的所有成员是 public 时,用struct
7.2.1 友元
类可以允许其他类或函数访问它的非公有成员,方法就是令其他函数或类成为它的**友元****。
要将一个函数作为类的友元,只需在类内部加一条关键字 friend 开头的函数声明语句即可。
友元声明只能出现在类的内部,但是具体位置不限,不是类的成员,不受public、private 限制。
最好在类的开始或结束位置集中声明友元。
友元的声明
类内对友元的声明只是指定了访问权限,并不是通常意义上的函数声明。如果要调用友元函数,还需要在类的外部再次声明。并且要在调用位置之前声明。
7.3 类的其他特性
类的其他特性还有:类型成员、类的成员的类内初始值、可变数据成员、内联成员函数、从成员函数返回 *this
7.3.1 类成员再探
定义类型成员
类可以自定义某种类型在类内的别名。类型成员一样有访问限制。
typedef string::size_type pos;//
using pos = string::size_type;//使用类型别名,两种方式都可以
类型成员必须先定义后使用,因此类型成员应该出现在类开始的地方。
默认构造函数
当定义了构造函数,不会再有默认构造函数,如果需要必须显式声明,如下
Student() = default;
类内初始值
成员变量可以在类内定义的时候直接初始化。
此时构造函数的初始化列表可以不包含该成员变量,隐式使用其类内初始值。
类内初始值必须使用等号或花括号初始化。
内联成员函数
4种方式使成员成为内联函数:
- 在类内定义函数,为隐式内联。
- 在类内用关键字 inline 显式声明成员函数。
- 在类外用关键字 inline 定义成员函数。
- 同时在类内类外用 inline 修饰
inline 成员函数应该与类定义在同一个头文件中
可变数据成员
const 成员函数不能修改成员变量。
但是用 mutable 将成员修饰为可变数据成员,就可以修改了。
7.3.2 返回*this的成员函数
this 指针指向类本身,即 this 是类的地址,*this 就是类本身。
可以定义****返回类型为类对象的引用的函数。如果定义的返回类型不是引用,返回的就是*this 的副本了。
const 函数如果以引用的形式返回 this,返回类型就是一个常量引用。
7.3.3 类类型
一个类的成员类型不能是它自己,但是类允许包含指向它自身类型的引用或指针。
7.3.4 友元再探
可以把其他的类定义成友元,也可以把其他类的成员函数定义成友元。
如果一个类指定了友元类。则友元类的成员函数可以访问此类的所有成员。
友元关系不具有传递性。
重载函数名字相同,但是是不同的函数。如果想把一组重载函数声明为类的友元,需要对每一个分别声明。
7.4 类的作用域
当类的成员函数的返回类型也是类的成员时,在定义它时要指明类
Student::age Student::Getage(){}
7.4.1 名字查找与类的作用域
普通程序名字查找的过程
- 首先在名字所在的块中寻找声明语句
- 如果没找到,继续查找外层作用域
- 如果最终还是没找到,报错
类的定义过程
- 首先,编译成员的声明。
- 直到全部类可见后才编译函数体。
特殊:在类内定义的类型名要放在类的开始,放在后面其他成员是看不见的。
类型名如果在类外已经定义过,不能在类内重定义。
不建议使用其他成员的名字作为某个成员函数的参数。
7.5 构造函数再探
7.5.1 构造函数初始值列表
使用初始值列表对类的成员初始化才是真正的初始化,在构造函数的函数体内赋值并不是初始化。
如果定义构造函数,必须对类的所有数据成员初始化或赋值。
如果成员是 const 或者是引用的话,必须初始化。
如果成员是类并且该类没有定义构造函数的话,必须初始化。(如果该类定义了构造函数的话,就不用了)
使用初始值列表初始成员时,成员初始化的顺序是按照类定义种出现的顺序初始化的。
默认实参和构造函数
如果一个构造函数为所有参数提供了默认实参,则它实际上相当于定义了默认构造函数。
7.5.2 委托构造函数
委托构造函数通过其他构造函数来执行自己的初始化过程。
class Student{
public:
Student(string nameIn,int ageIn):name(nameIn),age(ageIn){}
Student():Student(" ",18){} //这就是委托构造函数
Student(string s):Student(s,18){} //这也是委托构造函数
}
7.5.3 默认构造函数的作用
在实际中,如果定义了其他构造函数,最好也提供一个默认构造函数。
7.5.4 隐式的类类型转换
如果构造函数只接受一个实参,则称作转换构造函数,它实际上定义了转换为此类类型的隐式转换机制。
一个实参的构造函数定义了一条从构造函数的参数类型向类类型隐式转换的规则
只允许一步类型转换
在进行隐式转换时,编译器只会自动地执行一步类型转换。
string null_book = "9-999";
item.combine(null_book); //conbine 函数接受 Sales_data 类类型,但该类定义了一个接受 string 参数的转换构造函数,所以这里会执行从 string 到该类类型的隐式转换,是正确的。
item.combine("9-999"); //隐式地使用了两种转换规则,所以是错误的。
item.combine(string("9-999")); //先显示地转换为 string,再隐式地转换为 Sales_data 类类型。是正确的。
explicit-抑制构造函数定义的隐式转换
将转换构造函数声明为 explicit 会阻止隐式转换。
关键字 explicit 只对一个实参的构造函数有效。因为需要多个实参的构造函数本来就不执行隐式转换。
explicit 只在类内声明构造函数时使用,在类外定义时不加。类似 static 成员函数
class Sales_data {
public:
explicit Sales_data(const string& s) : bookNo(s) { } //不能再执行从 string 到 Sales_data 的隐式转换。
private:
string bookNo;
}
iter.combine(null_book); //错误,不能执行从 string 到 Sales_data 的隐式初始化
explicit 构造函数只能用于直接初始化
explicit 构造函数只能用于直接初始化,不能用于使用 “=” 的拷贝初始化。理解:因为 “=” 实际上是采用了拷贝赋值运算符,在传参时会进行隐式转换。
理解:不加 explicit 的转换构造函数,可以在赋值、传参、从函数返回等场合执行隐式转换,加了 explicit 后,就不能隐式转换了,也就是加了 explicit 的转换构造函数的意义就只是定义了一个新的构造函数,不具有提供隐式转换机制的额外功能了。
Sales_data item1(null_book); //正确
Sales_data item2 = null_book; //错误
为转换显式地使用构造函数
explicit 只是阻止了构造函数进行隐式转换,但是在传递实参时可以显式转换。
可以使用 explicit 的构造函数显式地强制进行转换。
iter.combine(static_cast(null_book)); //正确,static_cast 可以使用 explicit 的构造函数。 iter.combine(Sales_data(null_book)); //正确
标准库中有显式构造函数的类
下面是常见的两个例子:
- 接受一个单参数的 const char* 的 string 构造函数:不是 explicit 的
- 接受一个容量参数的 vector 构造函数:是 explicit 的
7.5.5 聚合类
满足以下四个条件的类是聚合类:
- 所有成员都是public的
- 没有定义任何构造函数
- 没有类内初始值
- 没有基类和 virtual 函数
聚合类可以像结构体一样用花括号初始值列表初始化。如果花括号内元素数量少于类成员数量,靠后的成员将被值初始化。
Student stu = {"Li Ming",18};
7.5.6 字面值常量类
constexpr 函数的参数和返回值都必须是字面值类型。
算术类型、引用和指针都是字面值类型,此外字面值常量类也是字面值类型。
字面值类型属于常量表达式,constexpr 就是用来声明常量表达式的。
聚合类属于字面值常量类。
如果不是聚合类,满足以下四个条件的类也是字面值常量类:
- 数据成员都是字面值类型。
- 类至少含有一个 constexpr 构造函数
- 如果一个数据成员有类内初始值,则初始值必须是常量表达式(如果成员是类,则初始值必须使用成员自己的 constexpr 构造函数)
- 类必须使用析构函数的默认定义。
constexpr 构造函数
类的构造函数不能是 const 的,但字面值常量类的构造函数可以是 constexpr 函数。
constexpr 构造函数可以声明成 =default 或 =delete。
constexpr 构造函数的函数体应该是空的(原因:constexpr 函数的函数体只能包含一条返回语句,而构造函数不能包含返回语句)
constexpr 构造函数必须初始化所有数据成员。初始值必须是常量表达式或使用其自己的 constexpr 构造函数。
使用前置关键字 constexpr 来声明 constexpr 构造函数
class Debug{
public:
constexpr Debug(bool b=true):a(b){};
private:
bool a;
};//定义一个类记得加分号
constexpr Debug prod(false);//定义一个 Debug 类型的对象。实参应为常量表达式。
7.6 类的静态成员
类的静态成员与类本身直接关联,而不是与类的对象保持关联。
静态成员可以是 public 或 private 的。
静态成员不与任何对象绑定在一起。
静态数据成员可以是常量、引用、指针、类等。
静态成员函数不包含 this 指针,不能声明为 const 的,不能在 static 函数体内使用 this 指针。
理解:因为 static 函数不能使用 this 指针,所以它是无法使用类的非 static 数据成员的。
使用作用域运算符可以直接访问静态成员。类的对象也可以直接访问静态成员
定义静态成员
可以在类内或类外定义静态成员。当在类外定义时,不能重复 static 关键字,static 只出现在类内的声明中。
只有 constexpr 类型的静态数据成员可以在类内初始化,但是也需要在类外定义。
其他的静态数据成员都在类内声明,类外定义并初始化。
静态成员可以用的特殊场景
静态数据成员可以是不完全类型,比如静态数据成员的类型可以是它所属的类类型本身。
静态成员可以作为默认实参。
问题
- 类的基本思想是什么
- class 和 struct 的区别
- 什么时候用 struct
- 委托构造函数是什么?如何使用
- 什么是友元?如何声明?
- 声明友元函数/类要注意什么?
- 声明重载函数为友元需要注意什么
- 类的什么成员必须初始化
- 类的静态成员如何声明和定义
- const 成员函数的使用需要注意什么
答案
- 数据抽象和封装
- 默认访问权限不同
- 数据成员都为 public 时
- 借助另一个已有的构造函数定义新构造函数的一种方式。student():student(int n, 10){}
- 允许其访问类的私有成员的东西为类的友元。在类内声明,可以在类内任何位置声明,但是最好在开始或结束位置。声明方式为用 friend 来修饰一个正常的声明,比如 friend class StrBlobPtr; 或 friend void func();
- 友元声明并不是通常意义上的访问声明。必须要在类外且是类的前面声明该函数/类。
- 每个版本的重载都要声明一遍
- 引用和 const 成员
- 在类内用 static 声明,在类外定义和初始化,类外不加 static
- 不能在 const 成员函数内调用类的其他非 const 成员函数。
问题
- 定义类型别名要注意什么
- 如何显式声明默认构造函数
- 一般 const 成员函数不能修改成员变量,用什么方法可以修改
- 如何定义内联函数
- 什么是委托构造函数
- 什么是转换构造函数
- explicit 的用法
答案
- 使用 typedef 或 using,类型别名必须先定义再使用,因此要将类型别名定义在类的开始位置。
- Student() = default;
- 使用 mutable 修饰成员变量,就可以用 const 成员函数修改它了。
- 在类内定义,或用 inline 声明等。内联函数应该和类在同一个头文件定义。
- 一个构造函数通过另一个构造函数来实现自己。
- 如果一个构造函数只接受一个实参,那就是转换构造函数。转换构造函数实际上定义了从实参类型到类类型的隐式转换机制。
- 如果定义了转换构造函数,可能会发生从某个类型到类类型的隐式转换,使用 explicit 来声明只接受一个实参的构造函数可以阻止这种隐式转换。
第7章 类
类的基本思想:数据抽象和封装
封装:将接口和实现分离
7.0 积累总结
7.0.0 类的 const 成员函数
const 成员函数不会修改类的数据成员。
const 成员函数的声明和定义处都要加 const,声明方式:
int age() const;//在类内的声明
int Student::age() const {};//在类外的定义
使用 const 成员函数要注意,不能用它调用本类的非 const 成员函数,调用的也必须是 const 成员函数。
7.0.1 关于类的 private 成员的访问权限
在类的成员函数中可以访问同类型实例的私有成员。
7.1 定义抽象数据类型
7.1.1 设计sales_data类
设计类的接口时,要考虑如何使类易于使用。当使用类时,不应该顾及类的实现机理。
7.1.2 定义改进的sales_data类
定义在类内部的函数是隐式的inline函数
7.1.3 定义类相关的非成员函数
空
7.1.4 构造函数
构造函数用来初始化类对象的数据成员。当类的对象被创建时,就会执行构造函数
构造函数没有返回类型。
构造函数可以重载。
如果类没有任何构造函数则编译器自己会创建默认构造函数(适用范围很小,尽量不要如此)
7.1.5 拷贝、赋值和折构
对于拷贝、赋值和销毁对象等操作,类都通过相应的成员函数实现其功能,如果不主动定义这些操作,编译器就合成默认的版本。
对于某些类来说,无法使用默认合成的版本,比如管理动态内存的类就不能。
7.2 访问控制与封装
class 和 struct 的唯一一点区别就是默认访问权限不同。
当希望类的所有成员是 public 时,用struct
7.2.1 友元
类可以允许其他类或函数访问它的非公有成员,方法就是令其他函数或类成为它的友元****。
要将一个函数作为类的友元,只需在类内部加一条关键字 friend 开头的函数声明语句即可。
友元声明只能出现在类的内部,但是具体位置不限,不是类的成员,不受public、private 限制。
最好在类的开始或结束位置集中声明友元。
友元的声明
类内对友元的声明只是指定了访问权限,并不是通常意义上的函数声明。如果要调用友元函数,还需要在类的外部再次声明。并且要在调用位置之前声明。
7.3 类的其他特性
类的其他特性还有:类型成员、类的成员的类内初始值、可变数据成员、内联成员函数、从成员函数返回 *this
7.3.1 类成员再探
定义类型成员
类可以自定义某种类型在类内的别名。类型成员一样有访问限制。
typedef string::size_type pos;//
using pos = string::size_type;//使用类型别名,两种方式都可以
类型成员必须先定义后使用,因此类型成员应该出现在类开始的地方。
默认构造函数
当定义了构造函数,不会再有默认构造函数,如果需要必须显式声明,如下
Student() = default;
类内初始值
成员变量可以在类内定义的时候直接初始化。
此时构造函数的初始化列表可以不包含该成员变量,隐式使用其类内初始值。
类内初始值必须使用等号或花括号初始化。
内联成员函数
4种方式使成员成为内联函数:
- 在类内定义函数,为隐式内联。
- 在类内用关键字 inline 显式声明成员函数。
- 在类外用关键字 inline 定义成员函数。
- 同时在类内类外用 inline 修饰
inline 成员函数应该与类定义在同一个头文件中
可变数据成员
const 成员函数不能修改成员变量。
但是用 mutable 将成员修饰为可变数据成员,就可以修改了。
7.3.2 返回*this的成员函数
this 指针指向类本身,即 this 是类的地址,*this 就是类本身。
可以定义****返回类型为类对象的引用的函数。如果定义的返回类型不是引用,返回的就是*this 的副本了。
const 函数如果以引用的形式返回 this,返回类型就是一个常量引用。
7.3.3 类类型
一个类的成员类型不能是它自己,但是类允许包含指向它自身类型的引用或指针。
7.3.4 友元再探
可以把其他的类定义成友元,也可以把其他类的成员函数定义成友元。
如果一个类指定了友元类。则友元类的成员函数可以访问此类的所有成员。
友元关系不具有传递性。
重载函数名字相同,但是是不同的函数。如果想把一组重载函数声明为类的友元,需要对每一个分别声明。
7.4 类的作用域
当类的成员函数的返回类型也是类的成员时,在定义它时要指明类
Student::age Student::Getage(){}
7.4.1 名字查找与类的作用域
普通程序名字查找的过程
- 首先在名字所在的块中寻找声明语句
- 如果没找到,继续查找外层作用域
- 如果最终还是没找到,报错
类的定义过程
- 首先,编译成员的声明。
- 直到全部类可见后才编译函数体。
特殊:在类内定义的类型名要放在类的开始,放在后面其他成员是看不见的。
类型名如果在类外已经定义过,不能在类内重定义。
不建议使用其他成员的名字作为某个成员函数的参数。
7.5 构造函数再探
7.5.1 构造函数初始值列表
使用初始值列表对类的成员初始化才是真正的初始化,在构造函数的函数体内赋值并不是初始化。
如果定义构造函数,必须对类的所有数据成员初始化或赋值。
如果成员是 const 或者是引用的话,必须初始化。
如果成员是类并且该类没有定义构造函数的话,必须初始化。(如果该类定义了构造函数的话,就不用了)
使用初始值列表初始成员时,成员初始化的顺序是按照类定义种出现的顺序初始化的。
默认实参和构造函数
如果一个构造函数为所有参数提供了默认实参,则它实际上相当于定义了默认构造函数。
7.5.2 委托构造函数
委托构造函数通过其他构造函数来执行自己的初始化过程。
class Student{
public:
Student(string nameIn,int ageIn):name(nameIn),age(ageIn){}
Student():Student(" ",18){} //这就是委托构造函数
Student(string s):Student(s,18){} //这也是委托构造函数
}
7.5.3 默认构造函数的作用
在实际中,如果定义了其他构造函数,最好也提供一个默认构造函数。
7.5.4 隐式的类类型转换
如果构造函数只接受一个实参,则称作转换构造函数,它实际上定义了转换为此类类型的隐式转换机制。
一个实参的构造函数定义了一条从构造函数的参数类型向类类型隐式转换的规则
只允许一步类型转换
在进行隐式转换时,编译器只会自动地执行一步类型转换。
string null_book = "9-999";
item.combine(null_book); //conbine 函数接受 Sales_data 类类型,但该类定义了一个接受 string 参数的转换构造函数,所以这里会执行从 string 到该类类型的隐式转换,是正确的。
item.combine("9-999"); //隐式地使用了两种转换规则,所以是错误的。
item.combine(string("9-999")); //先显示地转换为 string,再隐式地转换为 Sales_data 类类型。是正确的。
explicit-抑制构造函数定义的隐式转换
将转换构造函数声明为 explicit 会阻止隐式转换。
关键字 explicit 只对一个实参的构造函数有效。因为需要多个实参的构造函数本来就不执行隐式转换。
explicit 只在类内声明构造函数时使用,在类外定义时不加。类似 static 成员函数
class Sales_data {
public:
explicit Sales_data(const string& s) : bookNo(s) { } //不能再执行从 string 到 Sales_data 的隐式转换。
private:
string bookNo;
}
iter.combine(null_book); //错误,不能执行从 string 到 Sales_data 的隐式初始化
explicit 构造函数只能用于直接初始化
explicit 构造函数只能用于直接初始化,不能用于使用 “=” 的拷贝初始化。理解:因为 “=” 实际上是采用了拷贝赋值运算符,在传参时会进行隐式转换。
理解:不加 explicit 的转换构造函数,可以在赋值、传参、从函数返回等场合执行隐式转换,加了 explicit 后,就不能隐式转换了,也就是加了 explicit 的转换构造函数的意义就只是定义了一个新的构造函数,不具有提供隐式转换机制的额外功能了。
Sales_data item1(null_book); //正确 Sales_data item2 = null_book; //错误
为转换显式地使用构造函数
explicit 只是阻止了构造函数进行隐式转换,但是在传递实参时可以显式转换。
可以使用 explicit 的构造函数显式地强制进行转换。
iter.combine(static_cast(null_book)); //正确,static_cast 可以使用 explicit 的构造函数。 iter.combine(Sales_data(null_book)); //正确
标准库中有显式构造函数的类
下面是常见的两个例子:
- 接受一个单参数的 const char* 的 string 构造函数:不是 explicit 的
- 接受一个容量参数的 vector 构造函数:是 explicit 的
7.5.5 聚合类
满足以下四个条件的类是聚合类:
- 所有成员都是public的
- 没有定义任何构造函数
- 没有类内初始值
- 没有基类和 virtual 函数
聚合类可以像结构体一样用花括号初始值列表初始化。如果花括号内元素数量少于类成员数量,靠后的成员将被值初始化。
Student stu = {"Li Ming",18};
7.5.6 字面值常量类
constexpr 函数的参数和返回值都必须是字面值类型。
算术类型、引用和指针都是字面值类型,此外字面值常量类也是字面值类型。
字面值类型属于常量表达式,constexpr 就是用来声明常量表达式的。
聚合类属于字面值常量类。
如果不是聚合类,满足以下四个条件的类也是字面值常量类:
- 数据成员都是字面值类型。
- 类至少含有一个 constexpr 构造函数
- 如果一个数据成员有类内初始值,则初始值必须是常量表达式(如果成员是类,则初始值必须使用成员自己的 constexpr 构造函数)
- 类必须使用析构函数的默认定义。
constexpr 构造函数
类的构造函数不能是 const 的,但字面值常量类的构造函数可以是 constexpr 函数。
constexpr 构造函数可以声明成 =default 或 =delete。
constexpr 构造函数的函数体应该是空的(原因:constexpr 函数的函数体只能包含一条返回语句,而构造函数不能包含返回语句)
constexpr 构造函数必须初始化所有数据成员。初始值必须是常量表达式或使用其自己的 constexpr 构造函数。
使用前置关键字 constexpr 来声明 constexpr 构造函数
class Debug{
public:
constexpr Debug(bool b=true):a(b){};
private:
bool a;
};//定义一个类记得加分号
constexpr Debug prod(false);//定义一个 Debug 类型的对象。实参应为常量表达式。
7.6 类的静态成员
类的静态成员与类本身直接关联,而不是与类的对象保持关联。
静态成员可以是 public 或 private 的。
静态成员不与任何对象绑定在一起。
静态数据成员可以是常量、引用、指针、类等。
静态成员函数不包含 this 指针,不能声明为 const 的,不能在 static 函数体内使用 this 指针。
理解:因为 static 函数不能使用 this 指针,所以它是无法使用类的非 static 数据成员的。
使用作用域运算符可以直接访问静态成员。类的对象也可以直接访问静态成员
定义静态成员
可以在类内或类外定义静态成员。当在类外定义时,不能重复 static 关键字,static 只出现在类内的声明中。
只有 constexpr 类型的静态数据成员可以在类内初始化,但是也需要在类外定义。
其他的静态数据成员都在类内声明,类外定义并初始化。
静态成员可以用的特殊场景
静态数据成员可以是不完全类型,比如静态数据成员的类型可以是它所属的类类型本身。
静态成员可以作为默认实参。
问题
- 类的基本思想是什么
- class 和 struct 的区别
- 什么时候用 struct
- 委托构造函数是什么?如何使用
- 什么是友元?如何声明?
- 声明友元函数/类要注意什么?
- 声明重载函数为友元需要注意什么
- 类的什么成员必须初始化
- 类的静态成员如何声明和定义
- const 成员函数的使用需要注意什么
答案
- 数据抽象和封装
- 默认访问权限不同
- 数据成员都为 public 时
- 借助另一个已有的构造函数定义新构造函数的一种方式。student():student(int n, 10){}
- 允许其访问类的私有成员的东西为类的友元。在类内声明,可以在类内任何位置声明,但是最好在开始或结束位置。声明方式为用 friend 来修饰一个正常的声明,比如 friend class StrBlobPtr; 或 friend void func();
- 友元声明并不是通常意义上的访问声明。必须要在类外且是类的前面声明该函数/类。
- 每个版本的重载都要声明一遍
- 引用和 const 成员
- 在类内用 static 声明,在类外定义和初始化,类外不加 static
- 不能在 const 成员函数内调用类的其他非 const 成员函数。
问题
- 定义类型别名要注意什么
- 如何显式声明默认构造函数
- 一般 const 成员函数不能修改成员变量,用什么方法可以修改
- 如何定义内联函数
- 什么是委托构造函数
- 什么是转换构造函数
- explicit 的用法
答案
- 使用 typedef 或 using,类型别名必须先定义再使用,因此要将类型别名定义在类的开始位置。
- Student() = default;
- 使用 mutable 修饰成员变量,就可以用 const 成员函数修改它了。
- 在类内定义,或用 inline 声明等。内联函数应该和类在同一个头文件定义。
- 一个构造函数通过另一个构造函数来实现自己。
- 如果一个构造函数只接受一个实参,那就是转换构造函数。转换构造函数实际上定义了从实参类型到类类型的隐式转换机制。
- 如果定义了转换构造函数,可能会发生从某个类型到类类型的隐式转换,使用 explicit 来声明只接受一个实参的构造函数可以阻止这种隐式转换。
第8章 IO库
8.1 IO类
IO 库类型定义在三个头文件中:
- **iostream:**定义了读写流的类型:istream, ostream, iostream, wistream, wostream, wiostream
- **fstream:**读写命名文件的类型:ifstream, ofstream, fstream, wifstream, wofstream, wfstream
- **sstream:**读写内存 string 对象的类型:istringstream, ostringstream, stringstream
其中带 w 前缀的类型用来操作宽字符语言(wchar_t)。宽字符版本的类型和函数前都有一个 w,如 wcin, wcout, wcerr。
fstream 和 sstream 中的类型都继承自 iostream 中的类型。
可以将一个派生类对象当成基类对象来使用。
所有这些输入输出流对象的 >> 操作都是读取一个单词。
理解:
- 输入流和输出流都是流对象,输入流就是要用 >> 把流对象中的内容保存到变量中,输出流就是要用 << 把变量保存到流对象中。一个流是和控制台窗口或一个文件或字符串等相关联的,如 cin、cout 都和控制台窗口相关联。
8.1.1 IO对象无拷贝或赋值
不能拷贝或对 IO 对象赋值,因此也不能将形参或返回类型设置成流类型。
进行 IO 操作的函数通常以引用形式传递和返回流。读写 IO 对象会改变其状态,因此引用不能是 const 的。
8.1.2 条件状态
IO 操作的问题是可能发生错误。因此在使用一个流之前,应该先检查它是否处于良好状态。
条件状态用来查看流的状态。
IO 库的状态
iostream::iostate;//作为位集合来使用,可以表达流的完整状态。通过位运算符可以一次性检测或设置多个标志位。
iostream::badbit; cin.badbit;//表示流已崩溃,是系统及错误或不可恢复的读写错误。流无法再使用。
iostream::failbit; cin.failbit;//表示一个 IO 操作失败了,是可恢复错误。修正后流可以继续使用。
iostream::eofbit; cin.eofbit;//表示流到达了文件结束 iostream::goodbit;//表示流未处于错误状态
检查流的状态
while(cin >> word);// >> 表达式返回流的状态
while(cin.good());// 意义同上
while(!cin.fail());// 意义同上。
管理条件状态
cin.rdstate();//返回一个 iostate 值表示当前状态。
cin.setstate(state);//接受一个 iostate 类型的参数,将给定条件位置位。
cin.clear();//清除(复位)所有错误标志位,cin.clear() 后,cin.good() 会返回 true
cin.clear(state);//接受一个 iostate 类型的参数,设为流的新状态。
设置某个标志位的方式
cin.clear(cin.rdstate() & ~cin.failbit);//将 failbit 复位
8.1.3 管理输出缓冲
每个输出流都管理一个缓冲区。
缓冲刷新(即数据真正写到设备或文件)的原因:
- 程序正常结束,比如执行到了 return。
- 缓冲区满了
- 使用操纵符如 endl, flush, ends 来显示刷新缓冲区
- 当读写被关联的流时,如读 cin 或写 cerr 都会刷新 cout 的缓冲区
- 使用操纵符 unitbuf 设置流的内部状态来清空缓冲区。
操纵符 endl, flush, ends
cout << a << endl;//输出 a 和一个换行,然后刷新缓冲区
cout << a << flush;//输出 a,然后刷新缓冲区
cout << a << ends;//输出 a 和一个空字符,然后刷新缓冲区
操纵符 unitbuf, nounitbuf
- **unitbuf:**告诉流接下来每次写操作之后都进行一次 flush 操作
- **nounitbuf:**重置流,恢复正常的刷新机制
cout << unitbuf; //后面的所有输出操作都会立即刷新缓冲区
cout << nounitbuf; //回到正常的缓冲方式
注意:如果程序异常终止,将不会刷新缓冲区,即此时相应的输出操作已执行但没有打印。
关联输入和输出流
当一个输入流关联到一个输出流,每次从该输入流读取数据前都会先刷新关联的输出流。
标准库将 cin 和 cout 关联在一起。
输入流的成员函数 tie 可以用来查看关联的输出流或关联到输出流:
cin.tie();//返回指向关联到 cin 的输出流的指针,如果没有关联的输出流,返回空指针。
cin.tie(&cerr);//接受一个指向输出流 cerr 的指针作为参数,将 cin 与 cerr 关联在一起
cin.tie(NULL);//cin 不再与其他流关联
每个流最多关联到一个输出流,但一个输出流可以被多个流关联。
8.2 文件输入输出
头文件 fstream 中定义的 ifstream, ofstream, fstream 类型用来对文件进行读写。
当要读写一个文件时,创建一个文件流对象并将之绑定到该文件。
8.2.1 使用文件流对象
C++11 中,文件名可以是 string 类型对象,也可以是 C 风格字符串
fstream 定义和初始化
fstream fs; // 创建一个未绑定的文件流 fs
fstream fs('data.txt'); // 创建一个绑定到文件 data.txt 的文件流 fs,并打开文件 data.txt
fstream fs('data.txt', mode); // 与上一个构造函数类似,但是按指定模式 mode 打开文件
fstream 特有操作
getline(ifs, s); // 从一个输入流 ifs 读取一行字符串存入 s 中
fs.open('data.ext'); // 将 fs 与文件 data.txt 绑定并打开该文件。如果已打开会发生错误。
fs.close(); // 关闭 fs 绑定的文件。
fs.is_open(); // 返回一个 bool 值,指出关联文件是否成功打开。
当定义了一个空的文件流对象,使用 open 函数将其与文件关联并打开文件。
如果 open 失败,failebit 会被置位,建议每次 open 后检测 open 是否成功。
不能对已打开的文件流调用 open。
当文件关闭后,可以将文件流关联到另一个文件。
当一个 fstream 对象被销毁时,close 函数会自动被调用。
用 fstream 代替 iostream
使用 iostream 类型的引用作为函数参数的地方,都可以使用 fstream 来代替。
8.2.2 文件模式
每次打开文件都以某种模式打开,如未指定即以该文件流类型的默认模式打开。
每个流都有一个关联的文件模式,用来指出如何使用文件
- in:以只读方式打开
- out:以只写方式打开
- **app:**每次写操作前均定位到文件末尾
- **ate:**打开文件后即定位到文件末尾
- **trunc:**截断文件
- binary:以二进制方式进行 IO
文件模式的使用:
- 每个流对象都有默认的文件模式,ifstream 默认 in 模式打开文件,ofstream 默认 out,fstream 默认 in 和 out。
- 对 ifstream 对象不能设置 out 模式,对 ofstream 对象不能设置 in 模式
- 只有设置了 out 才能设置 trunc 模式,只设置 out 模式会默认也设置 trunc 模式
- 设置了 trunc 就不能再设置 app 模式
- 默认情况下以 out 模式打开文件会使文件内容被清空,如果要保留文件内容需要同时指定 app 模式或 in 模式。
- app 模式下,会将写入的数据追加写到文件末尾
ofstream fout("file1.txt"); // 以输出模式打开文件并截断文件(即清空文件内容)
ofstream fout("file1.txt", ofstream::app); // 显示指定 app 模式(+隐含的 out 模式)
ofstream fout("file1.txt", ofstream::app | ofstream::out); // 同上,只是将 out 模式显式地指定了一下。
fout.open("file1.txt", ofstream::out);
8.3 string流
sstream 定义了 istringstream, ostringstream, stringstream 来读写 string。
sstream 定义和初始化
stringstream strm(); // 定义一个未绑定的 stringstream 对象
stringstream strm(s); // 定义一个 stringstream 对象 strm,strm 中保存着 string s 的拷贝。
8.3.1 使用istringstream
stringstream 特有操作
strm.str(); // 返回 strm 中保存的 str 的拷贝
strm.str(s); // 将 string s 拷贝到 strm 中,返回 void
8.3.2 使用ostringstream
理解:
- istringstream 是输入流,即读操作,要将流中的内容输入到字符串中,因此定义和使用 istringstream 时流内必须有内容,所以在使用前要提前在流内保存一个字符串
- ostringstream 是输出流,即写操作,将流中的内容输出到字符串中,ostringstream 可以在定义时即在流中保存一个字符串,也可以通过 << 操作符获得字符串。
知识点
- IO 对象是不能拷贝或赋值的,可以使用非常量引用来将 IO 对象作为函数参数或返回值。
- 使用流对象要检查流的状态,如 cin.good() 和 cin.fail() 都会返回流的状态,运算符 >> 的返回值是流对象的引用,流对象可以转换为 bool 值,故可以用 while(cin >> word)。
- 输入流和输出流可以相关联,使用函数 tie() 来将一个输入流关联到一个输出流。
- 文件打开模式中使用 app 模式可以避免清空文件内容。
- 打开文件后可以使用 fs.is_open() 来检查是否打开成功。
- 定义一个 istringstream 对象时要提供一个字符串初始值,因为它是输入流,内部要保存了字符串才能输入到变量。或者使用一个 sstrm.str(s)来将一个string对象拷贝到输入流 sstrm 内部。
第九章 顺序容器
9.1 顺序容器概述
所有容器都提供高效的动态内存管理
几种顺序容器
vector:支持快速随机访问。在尾部插入/删除速度快。
deque:支持快速随机访问。在头尾插入/删除都很快。
list:**双向链表。只支持双向顺序访问**。在任何位置插入/删除都很快。
forward_list:单项链表。只支持单向顺序访问。在任何位置插入/删除都很快。
string:支持快速随机访问。在尾部插入/删除速度快。
**array:**固定大小数组。支持快速随机访问。
可以发现:vector\deque\string\array 都是顺序存储结构。 list 是链式存储结构。但是他们都是顺序容器
list 的额外内存开销相比其他大很多。
array 是一种比内置数组更好的类型。
farward_list 没有 size 操作。这种列表与最好的手写链表性能一样好。
新标准库容器的性能至少与同类手写数据结构一样好或更好,c++ 程序应该使用标准库容器。
容器选择
vector/list/deque 三种容器的比较:
- 如果没有特殊的理由,使用 vector 是最好的选择
- 如果有很多小的元素,不用 list
- 如果空间开销很重要,不用 list
- 如果需要在中间位置插入/删除,用 list
- 如果需要在头尾位置插入/删除,用 deque
- 如果需要随机访问,用 vector 或 deque
- 如果需要在中间位置插入,而后随机访问:
①如果可以通过排序解决,就像插到尾部,而后排序
②在输入阶段用 list ,输入完成后拷贝到 vector 中
9.2 容器库概览
通用容器操作
'类型别名'
iterator const_iterator
value_type // 容器元素类型。定义方式:vector::value_type
reference // 元素类型的引用。定义方式: vector::reference
const_reference // 元素的 const 左值类型
'构造函数'-'三种通用的构造函数:同类拷贝、迭代器范围初始化、列表初始化'
C c1(c2); // 拷贝构造函数,容器类型与元素类型必须都相同
C c1(c2.begin(),c2.end()); // 要求两种元素类型可以转换即可。
C c1{a,b,c,...}; // 使用初始化列表,容器的大小与初始化列表一样大
C c(n); // 这两种接受大小参数的初始化方式只有顺序容器能用,且 string 无法使用
C c(n,t);
'赋值与swap'
c1 = c2;
c1 = {a,b,c,....}
a.swap(b);
swap(a, b); // 两种 swap 等价
'大小'
c.size();
c.max_size(); // c 可以保存的最大元素数目,是整个内存层面的容量,不是已分配内存。不同于 caplity, caplity 只能用于 vector,queue,string
c.empty();
'添加/删除元素(不适用于array)'
c.insert(args); // 将 args 中的元素拷贝进 c
c.emplace(inits); // 使用 inits 构造 c 中的一个元素
c.erase(args); // 删除指定的元素
c.clear();
'关系运算符' ==; !=; <; <=; >; >= // 所有容器都支持相等和不等运算符。无序关联容器不支持大于小于运算符。
'获取迭代器'
c.begin(); c.end();
c.cbegin(); c.cend();
// 返回 const_iterator '反向容器的额外成员'
reverse_iterator // 逆序迭代器,这是一个和 iterator 不同的类型
const_reverse_iterator
c.rbegin();c.rend();
c.crbegin();c.crend();
9.2.1 迭代器
用两个迭代器表示的范围都是左闭合空间,即 [begin,end) :如果 begin 和 end 相等,则为空。
所有迭代器都可以递增,forward_list 不可以递减
vector::iterator iter = vec.begin(); // 准确定义迭代器的方式。
9.2.4 容器定义和初始化
vector articles = {"a", "an", "the"};
list words(articles.begin(), articles.end()); // 正确, const char* 类型可以转换成 string类型
array初始化
定义一个array,既需要指定元素类型,也需要指定大小
array; // 定义一个有 42 个 0 的数组
array::size_type; // 定义数组类型也需要包括元素类型和大小
array的所有元素默认初始化为 0;
array 列表初始化时,列表元素个数小于等于 array 大小,剩余元素默认初始化为 0
array 只能默认初始化或列表初始化**,如果定义的数组很大并且需要初始化,可以先默认初始化然后用 fill 函数填充值。**
array赋值
不能对内置数组拷贝或赋值,但是 array 可以。
使用一个 array 对另一个 array 赋值,需要两个array 元素类型与大小都相同。
不能用花括号列表对 array 赋值(只可以初始化)
9.2.5 赋值和swap
“=”赋值
对容器使用赋值运算符(除 array 外),将会使该容器的所有元素被替换。如果两个容器大小不等,赋值后都与右边容器的原大小相同。
array要求赋值前大小就必须一样。
assign
assign 是赋值操作,可以用于顺序容器。
“=” 要求两边类型相同, assign 要求只要可以转换即可
lst.assign(vec.begin(), vec.end()); // 使用迭代器范围赋值
lst.assign(il); // il是一个花括号包围的元素值列表
lst.assign(n, t); // 将 lst 的元素替换为 n 个 t
'操作等价于'
lst.clear();
lst.insert(lst.begin(), n, t);
swap
对 array ,swap 交换两个 array 中的元素值。指针、引用和迭代器绑定的元素不变(值变)。
对于其他容器,swap 不交换元素,只交换数据结构,因此 swap 操作非常快。
对于 string,swap 后,指针、引用和迭代器会失效。对于其他容器,交换后指针指向了另一个容器的相同位置。
建议统一使用 swap(a,b),而非 a.swap(b)
对于 array,swap 操作的时间与元素数目成正比,对于其他容器,swap 操作的时间是常数。
9.2.6 容器大小操作
max_size 返回一个大于或等于该类型容器所能容纳的最大元素数的值。
9.3 顺序容器操作
9.3.1 添加元素
主要是三类函数:push、emplace 和 insert。
注意向 vector、string 或 deque 插入元素会使所有指向容器的迭代器、引用和指针失效。
添加的都是元素的拷贝,不是元素本身。
头尾添加返回 void,中间添加返回指向新添加元素的迭代器
push
vector 和 string 不支持 push_front 和 emplace_front;forward_list 不支持 push_back 和 emplace_back;
c.push_back(t); // 尾部添加一个 t
c.push_front(t); // 头部添加一个 t
emplace(c++11 新标准)
push 和 insert 传递的是元素类型的对象, emplace 则将参数传递给元素类型的构造对象。
即 emplace参数即为元素类型构造函数的参数,因此一般可以为空(默认初始化)。
emplace 返回值是指向添加元素的迭代器
c.emplace_back(args); // 在尾部添加一个由 args 构建的元素
c.emplace_front(args); // 在头部添加一个由 args 构建的元素
c.emplace(p,args); // 在迭代器 p 所指元素之前添加一个由 args 构建的元素
insert
insert 返回值是指向添加的元素中第一个元素的迭代器
c.insert(p, t); // 在迭代器 p 所指元素之前添加一个 t
c.insert(p, n, t); // 在迭代器 p 所指元素之前添加 n 个 t
c.insert(p, b, e); // 在迭代器 p 所指元素之前添加迭代器范围 [b,e) 中的元素。注意不能是自己的子序列
c.insert(p, il); // 在迭代器 p 所指元素之前添加花括号列表
应用
在一个位置反复插入元素
while(cin>>word)
iter = lst.insert(iter,word);
9.3.2 访问元素
访问容器应首先确保容器非空
begin/end
begin()/end() 返回迭代器
front/back
front()/back() 返回元素的引用
c.front();
c.back(); //返回的是尾元素的引用(注意不同于尾后迭代器)
at/下标
可以快速随机访问的容器都可以使用下标。
使用下标一定要保证下标不越界,可以用 at 函数。当下标越界,at 函数会抛出一个 out_of_range 异常
c[n]
c.at(n); //返回下标为 n 的元素的引用
如果要通过 auto 获得元素的引用,定义时一定要记得加上引用符号
理解:c.front() 返回的是引用,因此可以通过 c.front() = 32; 来给 c 的首元素赋值。而 auto b = c.front() 得到的 b 是等号右端元素的拷贝,不是引用
auto &v1 = c.back(); // v1 是元素的引用 auto v2 = c.back(); // v2 是元素的拷贝
9.3.3 删除元素
三类删除操作:pop/ erase/ clear
头尾删除返回 void,特定位置删除返回被删除元素之后元素的迭代器
vector/string 不支持 pop_front,forward_list 不支持 pop_back。
forward_list 有自己特殊版本的 erase。
c.pop_back(); // 注意没有返回值,如果想要需要提前保存
c.pop_front();
c.erase(p); // 删除迭代器 p 所指元素
c.erase(b, e); // 删除迭代器范围 [b, e) 内的元素
删除元素之前应确保元素存在。
删除 deque 种除首尾之外的任何元素都会使所有迭代器、引用和指针失效。删除 vector 或 string 中的元素会使指向删除点之后位置的迭代器、引用和指针失效。删除 list 中的元素不会影响指向其他位置的迭代器、引用、指针。
删除多个元素
c.clear();
c.erase(c.begin(), c.end()); // 和 c.clear() 等价
9.3.4 特殊的forward_list操作
forward_list 是单向链表,添加和删除操作都会同时改变前驱和后继结点,因此一般的添加和删除都不适用于 forward_list
forward_list 定义了首前迭代器:before_begin() 可以返回首前迭代器,用来删除首元素。
lst.insert_after(p,t); // 在迭代器 p 之后添加一个元素 t;insert_after 与 insert 的差别只在于是插入在元素前还是元素后 lst.insert_after(p,n,t);
lst.insert_after(p,b,e);
lst.insert_after(p,il);
lst.emplace_after(p,args); // 在 p 之后构建新元素。
lst.erase_after(p); // 删除 p 之后的元素,注意 p 不能是尾元素。
lst.erase_after(b,e); // 删除迭代器返回 (b,e) 中的元素,注意不包含 b 和 e
9.3.5 改变容器大小
resize() 用来增大或缩小容器。
如果要求的大小小于当前大小,尾部会被删除,如果要求的大小大于当前大小,会把新元素添加到尾部
list lst(10,42); // 10 个 42
lst.resize(15); // 添加 5 个 0 到末尾
lst.resize(25,-1); // 添加 10 个 -1 到末尾
lst.resize(5); // 把后面 20 个元素都删除
9.3.6 容器操作可能使迭代器失效
添加和删除元素都可能使指针、引用、迭代器失效。使用失效的指针、引用、迭代器是很严重的错误。
编写改变容器的循环程序
必须保证每次改变容器后都更新迭代器。
insert 和 erase 都会返回迭代器,更新很容易。调用 erase 后,不需要递增迭代器,调用 insert 后,需要递增两次。
不要保存 end() 返回的迭代器
push、pop、首尾 emplace 操作都没有返回值,但是都会改变尾后迭代器,因此不能保存 end() 返回值。
for 循环判断条件中的 end() 每轮都会重新获取迭代器进行判断,因此不用担心(也因此速度会略慢,当不改变容器大小时,采用下标更快)
9.4 vector对象是如何增长的
vector 和 string 是连续存储的,为了避免每增加一个元素就要重新分配一次空间,在每次必须获取新的内存空间时,通常会分配比新的空间需求更大的内存空间。容器预留多的空间作为备用。
这种方法在实现时性能恨好,虽然每次重新分配内存都要移动所有元素,但是其扩张操作通常比 list 和 deque 还快。
管理容量
c.capacity(), c.reserve(), c.shrink_to_fit 都适用于 vector 和 string,c.shrink_to_fit 还另外适用于 deque。
c.capacity(); // 不重新分配内存空间的话,c 可以保存多少元素。
c.reserve(n); // 分配至少能容纳 n 个元素的空间(只预分配内存)
c.shrink_to_fit(); // 请求将 capacity() 减少为与 size() 相同大小。
c.reserve(n) 不会减小容量,只会增大容量,当需求容量大于当前容量,才会分配内存,否则什么都不做。
c.shrink_to_fit() 只是一个请求,,实现时标准库可能会不执行。
9.5 额外的string操作
string 提供了一些额外的操作,主要是用于 C风格字符数组 和 下标访问 两方面
9.5.1 构造string的其他方法
构造string的基础方法
注意:string 不支持在初始化时接受一个数字以指定 string 的大小。
如果想要指定大小,可以先默认初始化,再调用 resize() 函数调整大小。
C c1(c2);
C c1(c2.begin(), c2.end());
C c1{a, b, c, ...};
构造string的其他方法
string 的构造函数可以接受一个 string 或 const char* 参数用来指定开始位置,然后接受一个计数值用来指定范围。
如果没有传递计数值用来确定范围,拷贝操作遇到空字符停止(因此此时必须要有空字符)
开始位置必须保证是在拷贝对象的范围内,计数值也没有上限要求,当计数值指定的范围大于拷贝对象,就最多拷贝到结尾。
string s(cp, n); // cp 是一个字符数组,s 是 cp 指向的字符数组前 n 个字符的拷贝。
string s(s2, pos2); // s2 是一个 string 对象,s 是从 s2 的下标 pos 处开始到最后的字符的拷贝。
string s(s2, pos2, len2); // s 是从 s2 的下标 pos2 处开始的 len2 个字符的拷贝。
substr
s.substr(pos,n) 返回 s 的一个子序列,范围由参数指定。
string s2 = s1.substr(0,5); // 返回从下标 0 开始,长度为 5 的子序列
string s2 = s1.substr(6); // 返回从下标 6 开始到最后的子序列
如果 pos 的值超过了 string 的大小,则 substr 函数会抛出一个 out_of_range 异常;若 pos+n 的值超过了 string 的大小,则 substr 会调整 n 的值,只拷贝到 string 的末尾。
9.5.2 改变string的其他方法
string 支持顺序容器的 assign、insert、erase 操作,此外还增加了两个额外的操作
- 接受下标版本的 insert 和 erase
- 接受 C 风格字符数组的 insert 和 assign
- append 和 replace 函数
接受下标的 insert 和 erase
insert 和 erase 接受下标的版本返回的是一个指向 s 的引用(区别于迭代器版本返回指向第一个插入字符的迭代器)。
insert 的所有版本都是第一部分参数为 pos,后面的参数为待插入的字符
erase 的所有版本的参数都是 pos,pos 分为 起始位置 和 终止位置/长度
s.insert(s.size(), 5, '!'); // 在 s 末尾(s[s.size()]之前)插入 5 个感叹号,注意实际上不存在 s[s.size()];
s.insert(0, s2, 3, s2.size()-3); // 在 s[0] 之前插入 s2 第四个字符开始的 s2.size()-3 个字符
s.erase(s.size()-5, 5); // 从 s 删除最后 5 个字符
接受 C 风格字符数组的 insert 和 assign
assign 的所有版本的参数都是要赋的值,由 起始位置 + 终止位置/长度 组成
replace 的所有版本的参数都是第一部分参数为要删除的范围,第二部分为要插入的字符。
const char* cp = "stately,plump Buck";
s.assign(cp, 7); // 用从 cp 开始的前 7 个字符向 s 赋值
s.insert(s.size(), cp+7); // 将从 cp+7 开始到 cp 末尾的字符插入到 s 末尾
append 和 replace
append:在 string 末尾进行插入操作的简写形式
replace:调用 erase 和 insert 操作的简写形式
s.append(" 4th Ed."); // 等价于 s.insert(s.size()," 4th Ed.");
s.replace(11, 3, "Fifth"); // 从下标 11 开始,删除三个字符并插入 5 个新字符
9.5.3 string搜索操作
string 类提供了 6 个不同的搜索函数,每个函数有 4 个重载版本。
搜索操作返回 string::size_type 类型,代表匹配位置的下标。
搜索失败则返回一个名为 string::npos 的 static 成员,值初始化为 -1。因为 npos 是一个 unsigned 类型,这个初始值意味着 npos 等于任何 string 最大的可能大小。
注意:find 和 rfind 查找的是给定的整个 args,而剩下的查找的是给定的 args 中包含的任意一个字符。
s.find(args); // 查找 s 中 args 第一次出现的位置
s.rfind(args); // 查找 s 中 args 最后一次出现的位置
s.find_first_of(args); // 查找 s 中 args 的任意一个字符第一次出现的位置
s.find_last_of(args); // 查找 s 中 args 的任意一个字符最后一次出现的位置
s.find_first_not_of(args); // 查找 s 中第一个不在 args 中的字符
s.find_last_not_of(args); // 查找 s 中最后一个不在 args 中的字符
'args为以下形式' c,pos // 字符,pos 为搜索开始位置
s2,pos // 字符串
cp,pos // 以空字符结尾的 c 风格字符串
cp,pos,n // c 风格字符串的前 n 个字符
使用 pos 循环查找所有 str 包含的字符的位置
string::size_type pos = 0;
while((pos=s.find_first_of(str,pos)) != string::npos ){
cout << pos << endl;
++pos;
}
9.5.4 compare函数
用于比较两个字符串,可以是比较整个或一部分字符串。
小于返回负数,大于返回正数,等于返回零
int F = s.compare(s2);
int F = s.compare(pos1,n1,s2); // 将 s 中 pos1 开始的前 n1 个字符与 s2 比较
int F = s.compare(pos1,n1,s2,pos2,n2); // 将 s 中 pos1 开始的前 n1 个字符与 s2 中从 pos2 开始的 n2 个字符进行比较
int F = s.compare(cp) // 将 s 与 cp 指向的字符数组比较
int F = s.compare(pos1,n1,cp);
int F = s.compare(pos1,n1,cp,n2);
9.5.5 数值转换
有多个函数可以实现数值数据与标准库 string 之间的转换
stoi 中要转换的 string 的第一个非空白符必须是数字或 “+”、“-”、“.”
to_string(val); // 数值转换为字符串
stoi(s, p, b); // 返回 s 的起始子串的数值。参数 p 用来保存 s 中第一个非数值字符的下标,默认为 0,即不保存下标。参数 b 默认为 10,表示十进制 stol();stoul();stoll();stoull();
stof(s, p); // 返回 s 的起始子串的数值。
stod();stold();
例子
string s2 = "pi = 3.14";
double d = stod(s2.substr(s2.find_first_of("+-.0123456789")));
// 先使用查询方法找出第一个数值字符,返回下标后截取这一个子串,将子串转换为 double
9.6 容器适配器
标准库定义了三个顺序容器适配器:stack、queue、priority_queue。
适配器是一种机制,是某种事物的行为看起来像另一种事物。
适配器类型
size_type;
value_type;
container_type; // 实现适配器的底层容器类型。
初始化操作
默认情况下,stack 和 queue 是基于 deque 实现的, priority_queue 是在 vector 之上实现的。
因此可以直接用一个 deque 来初始化 stack 和 queue。注意:是直接使用容器对象,不是使用迭代器表示的范围。
priority_queue 不能使用无序的 vector 初始化。
deque deq;
stack sta(deq); // 用 deq 初始化 sta
如果要使用其他顺序容器实现适配器,要在创建适配器时用一个顺序容器作为第二个类型参数。
stack> sta; // 定义基于 vector 实现的 stack
stack 可以构造于 vector, list, deque 之上。
queue 可以构造于 list, deque 之上。
priority_queue 可以构造于 vector、deque 之上。
栈适配器:stack
栈的操作
s.pop();
s.push(item);
s.emplace(args); // 由 args 构造元素并压入栈顶
s.top();
s.size();
s.empty();
swap(s, s2); s.swap(s2);
队列适配器:queue
queue 和 priority_queue 都定义在头文件 queue 中
队列适配器的操作
q.pop(); // 删除 queue 的首元素
q.push(item); // 在 queue 末尾插入一个元素
q.emplace(args); // 构造元素
q.front(); // 返回首元素
q.back(); // 返回尾元素。
q.size();
q.empty();
swap(q,q2);q.swap(q2);
queue 为先进先出队列。
优先队列:priority_queue
queue 和 priority_queue 都定义在头文件 queue 中。
创建 stack, queue, priority_queue 时都可以用一个顺序容器作为第二个类型参数,此外创建 priority_quque 时还可以额外传递第三个参数:一个函数对象来决定如何对 priority_queue 中的元素进行排序。
大根堆和小根堆
priority_queue 默认采用的是 less ,默认情况下 q.top() 是最大的元素,即大根堆。
priority_queue q; // 默认采用 vector 作为容器,采用 less 比较元素,是大根堆
priority_queue , greater > q; // 采用 greater 比较元素,生成小根堆
其他操作:
q.pop(); // 删除 priority_queue 的最高优先级元素
q.push(item); // 在 priority_queue 适当的位置插入一个元素
q.emplace(args); // 构造元素
q.top(); // 返回最高优先级元素
q.size();
q.empty();
swap(q, q2); q.swap(q2);
priority_queue 为元素建立优先级。新加入的元素排在所有优先级比它低的元素之前。priority_queue 元素可以重复
priority_queue 不能使用无序的 vector 初始化。
问题
- 基本的顺序容器有 6 种,分别是什么?哪几种容器算是通用型?存储结构分别是什么?
- 顺序容器的通用操作有哪些
- vector 特点是什么,支持哪些操作
- deque 特点是什么,支持哪些操作
- list 特点是什么,支持哪些操作
- forward_list 特点是什么,支持哪些操作
- array 特点是什么,支持哪些操作
- string 特点是什么,支持哪些操作
- vector, deque, list 应用场景分析
- 基本的顺序容器适配器有 3 种,分别是什么?默认底层容器分别是什么?
- 适配器有哪些共同特点?
- queue 特点是什么,支持哪些操作
- priority_queue 特点是什么,支持哪些操作
- stack 特点是什么,支持哪些操作
回答
vector, deque, list, forward_list, string, array。vector, deque, list 算是最通用的通用型。两个 list 是链式结构,其他都是顺序结构
empty(), size(), swap(), clear(), “=”, assign() (注意:仅限于顺序容器通用,适配器不行)--------例外:forward_list 不支持 size()
vector 支持快速随机访问、在尾部快速插入删除。支持
- front(),back()
- push_back(), pop_back(),
- capcity()
- emplace_back(), emplace(p,args)
- insert(p, t)
deque 支持快速随机访问、在头尾快速插入删除。支持
- front(),back()
- push_front(), push_back(), pop_front(), pop_back()
- empace_back(), emplace_front(),emplace(p,args)
- insert(p,t)
list 支持双向顺序访问,在任何位置插入删除都很快。缺点是额外内存开销很大。支持
- front(),back()
- push_front(), push_back(), pop_front(), pop_back()
- empace_back(), emplace_front(),emplace(p,args)
- insert(p,t)
forward_list 支持正向顺序访问,在任何位置插入删除都很快。
string 支持快速随机访问、在尾部快速插入删除。
array 支持快速随机访问,是固定大小数组。
一般用 vector,需要头部插入删除用 deque,需要中间插入删除用 list。元素数量多且单个元素小不用 list,空间开销很重要不用 list,需要随机访问用 vector,deque。
queue, priority_queue, stack ,queue 和 stack 的底层容器是 deque,priority_queue 的底层容器是 vector
适配器不能用底层容器的操作。适配器不支持迭代器。clear() 是通过迭代器实现的,因此适配器都不支持 clear()。
queue:先进先出。支持 front(), back(), push(), pop(), emplace(args) ;empty(), size(), swap();
stack:先进后出。支持 top(), push(), pop(),emplace(args) ;empty(), size(), swap();
priority_queue:最高优先级出。支持 top(), push(), pop(), emplace(args) ;empty(), size(), swap();
问题
- 所有的迭代器都支持什么操作?
- array 使用时要注意什么?
- swap 操作的特点
- max_size 返回值是什么
- 可以向容器添加元素的三类函数分别是什么,分别可以用于哪种情况?
- 如何在一个位置反复插入元素
- 访问容器元素的三类操作分别是什么,用于哪种情况?
- 删除元素的三类操作分别是什么?用于哪种情况?
- farword_list 有哪些操作?
- 控制容器大小的操作有哪些
回答
都支持 ++iter,除了 forward_list 都支持 --iter,包括顺序容器和关联容器
array 的类型和大小是捆绑的,定义: array arr;
对于 array 以外的其他容器,swap 只交换数据结构,不交换元素,所以非常快,运行常数时间。对于 array,swap 交换两个容器的元素值
返回一个大于等于该容器所能容纳最大元素数量的值
push, emplace, insert 三类:
- push:包括 push_back(), push_front() 两种,单纯的 push() 操作只用于三种顺序容器适配器,一次只能添加一个元素
- emplace:包括 emplace(), emplace_back(), emplace_front() 三种,用参数来构造元素,一次只能添加一个元素
- insert:包括 insert() 一种,传入一个迭代器指明位置,再迭代器前插入,可以添加单个元素、多个相同元素、某迭代器范围内的所有元素,花括号列表
在同一位置反复调用 insert 或 emplace 。 iter = c.insert(iter, word);
以下三类:
- begin(),end() 返回迭代器
- front(), back() 返回元素的引用,back() 返回尾元素
- vec.at(),vec[] :下标访问法。at() 函数可以检查下标越界。可用于 vector,deque,string,array
以下三类:
- pop 类:包括 pop_front(), pop_back() 两种,都返回 void 。单纯的 pop 操作只用于顺序容器适配器。
- erase 类:包括 erase() 一种,接受迭代器做参数,可以删除一个元素或一个迭代器范围。返回删除元素之后的元素的迭代器
- clear:清空整个容器。不能用于适配器。
farword_list 的操作有 erase_after(iter), insert_after(), emplace_after() 。before_begin() 返回一个首前迭代器。
resize() :调整容器大小。reserve():为vector 和 string 预分配内存;capacity(), shrink_to_fit()
第10章 泛型算法
标准库提供了一组算法,用来处理不同的容器
10.1 概述
大多数算法定义在头文件 algorithm 中,部分在 numeric 中
这些算法不直接操作容器,而是遍历两个迭代器指定的一个元素范围来进行操作。
算法不会改变容器的大小。
10.2 初识泛型算法
标准库提供了超过100个算法。
标准库算法都对一个范围内的元素进行操作,此元素范围称为“输入范围”
部分算法从两个序列中读取元素,两个序列不必相同(如vector和list),序列中的元素也不必相同(如double和int),要求是只要能比较两种元素即可。
几种假定
操作两个序列的算法有的接受三个迭代器:前两个表示第一个序列的元素范围,第三个表示第二个序列的元素范围。这种情况假定第二个序列至少与第一个一样长。
向目的位置迭代器写入 n 个数据的算法假定目的位置足够大(大于等于 n)
10.2.1 只读算法
对于只读算法,最好使用 cbegin() 和 cend()。
int sum = accumulate(vec.cbegin(),vec.cend(),val);
//对输入范围内的元素在 val 的基础上求和。可以对字符串“+”。注意元素是加在val上,如果元素是double,val是int,和会被转换成int
bool F = equal(vec1.cbegin(),vec1,end(),vec2.cbegin());
//比较两个序列的元素是否全部相等(假定第二个序列至少与第一个序列一样长)
auto iter = find_if(vec.begin(),vec.end(),'一元谓词');
//查找符合某条件的元素,返回迭代器,如果没有就返回尾迭代器
10.2.2 写容器元素的算法
fill(vec.begin(),vec.end(),val);//将 val 赋予输入序列中的每一个元素
fill(vec.begin(),vec.begin() + vec.size()/2,10);//将一个容器的前一半的值写为10
fill_n(dest,n,val);//将 val 赋予从 dest 开始的连续 n 个元素。假定dest开始的序列有至少 n 个元素
fill_n(vec.begin(),vec.size(),0);//将 vec 的所有元素重置为0
for_each(vec.begin(),vec.end(),'可调用对象');
//对输入范围内的每一个元素执行可调用对象的内容。注意:可调用对象是一元谓词,参数类型是迭代器指向的类型
插入迭代器
插入迭代器是一种向容器中添加元素的迭代器。
当通过插入迭代器向容器赋值时,一个新的元素被添加到容器中。
函数 back_inserter 定义在头文件 iterator 中。
vector vec;
auto it = back_inserter(vec);//it 即为vec新加的插入迭代器
*it = 24;//给 it 赋值后,vec 现在有一个元素为 24
可以用 back_inserter() 函数的返回值作为算法的目的位置
fill_n(back_inserter(vec),10,0);//添加 10 个元素到 vec
拷贝算法
auto ret = copy(begin(a1),end(a1),begin(a2));//把数组 a1 的内容拷贝给 a2,返回的是目的位置迭代器(递增后)的值 replace(ilst.begin(),ilst.end(),0,42);//把输入范围内所有值为 0 的元素改为 42
replace_copy(ilst.begin(),ilst.end(),dest,0,42);//把输入范围内所有值为 0 的元素改为 42 并拷给 dest 开头的序列。
10.2.3 重排容器元素的算法
sort(words.begin(),words.end());//默认按字典序从小到达排列输入范围内的元素。重复的元素会相邻
auto end_unique = unique(words.begin(),words.end());
//将输入范围内的元素重排,将重复的元素里不是第一次出现的元素都放到序列的后端。返回指向序列后端重复元素中的第一个重复元素的迭代器。 words.erase(end_unique,words.end());//删除重复的元素。erase()函数可以接受两个相等的迭代器作为参数。
10.3 定制操作
可以使用自定义操作符来替代默认运算符。
10.3.1 向算法传递函数
谓词是一个可调用的表达式,返回结果是一个可以作为条件的值,如返回一个 bool 值。
谓词的参数类型必须是元素类型可以转换到的类型。谓词的实参是输入序列的元素(是元素本身不是迭代器)
谓词分为一元谓词和二元谓词,分别接受一个参数和两个参数。不同的标准库算法会接受不同的谓词作为参数。
10.3.2 lambda表达式
lambda 表达式适合那种只在一两个地方使用的简单操作。
可以向一个算法传递任何类别的可调用对象。
总共有四种可调用对象:函数、函数指针、重载了函数调用运算符的类、lambda表达式
lambda表达式组成部分:捕获列表、参数列表、返回类型、函数体
[capture list](parameter list)->return type {function body}
捕获列表的内容为 lambda所在函数中定义的局部变量(直接写局部变量的名字即可,通常为空)。捕获列表只用于局部非 static 变量。
参数列表和返回类型都可以省略。如果忽略返回类型,则根据 return 语句推断返回类型(此时函数体必须只有 return 语句)。
auto f = []{ return 42};//定义了一个可调用对象 f,返回 42
lambda表达式的调用方式也是使用调用运算符,内含实参。
lambda 没有默认参数。
10.3.3 lambda捕获和返回
定义一个 lambda 时,编译器生成一个与 lambda 对应的未命名的类类型。
当向一个函数传递一个 lambda 时,同时定义了一个新类型和该类型的一个对象:传递的参数实际上就是此编译器生成的类类型的未命名对象。
类似,auto f = [ ]{ return 42; } 实际上定义了一个类类型的对象。
默认情况下,从 lambda 生成的类都包含一个对应该 lambda 所捕获的变量的数据成员。
lambda 捕获变量的方式分为值捕获和引用捕获,类似参数传递。
值捕获
注意采用值捕获的前提是变量可以拷贝。(iostream 等类型不可拷贝)
被值捕获的变量的值是在 lambda 创建时拷贝,而非调用时拷贝。因此在 lambda 创建后改变被捕获的变量不会影响 lambda 中对应的值。
引用捕获
采用引用捕获时,在捕获列表中的变量名前加上引用符即可。
注意采用引用捕获必须确保被引用的对象在 lambda 执行时是存在的。
lambda 捕获的都是上层函数的局部变量,在函数结束后就都不复存在了。
引用捕获可以用于捕获变量是 IO 类型时。
使用 lambda
lambda 和含有可调用对象的类对象都可以作为函数的返回值,要注意此时 lambda 不能包含引用捕获。
应该尽量减少捕获的数据量,同时尽量避免捕获指针或引用。
捕获列表中可以同时有值捕获的变量和引用捕获的变量
隐式捕获
一般在捕获列表中显式地列出所有的捕获变量,但也可以采用隐式捕获。隐式捕获情况下,编译器会根据 lambda 中的代码来推断要使用的变量。
隐式捕获只需在捕获列表中写一个 & 或 = 即可,& 表示采用引用捕获,= 表示采用值捕获。
wc = find_if(words.begin(), words.end(), [=](const string& s){ return s.size()>=sz; });
混合显式捕获与隐式捕获
可以通过混合使用隐式捕获和显示捕获来实现对一部分变量使用值传递,而另一部分使用引用传递。
混合捕获时捕获列表中的第一个元素必须是一个 & 或 =:
- 如果是 &,表示采用隐式的引用捕获,此时后面显式捕获的变量必须都采用值捕获。
- 如果是 =,表示采用隐式的值捕获,此时后面显式捕获的变量必须都采用引用捕获。
for_each(words.begin(), words.end(), [&,c](const string& s){ os<捕获列表
总结可得,捕获列表可以有六种形式
[],[参数序列] // 空列表与显式捕获
[=],[&] // 隐式值捕获与隐式引用捕获
[=,参数列表],[&,参数列表] // 混合捕获
可变 lambda
默认情况下,通过值捕获拷贝的变量,lambda 不会改变其值。如果希望改变,必须在参数列表后加上关键字 mutable。
引用捕获的变量是否可以修改依赖于引用指向的是 const 还是非 const 类型。
指定 lambda 返回类型
如果 lambda 中只包含一个单一的 return 语句,可以省略返回类型。
如果 lambda 中除了 return 还有其他语句,此时应该指明返回类型。
10.3.4 参数绑定
lambda 表达式适合那种只在一两个地方使用的简单操作。如果操作需要很多语句或要在很多地方使用,通常应该定义一个函数。
对于捕获列表为空的 lambda,通常可以用函数来代替。对于捕获列表不为空的 lambda,不容易使用函数替换。
标准库 bind 函数
bind 函数接受一个可调用对象,生成一个新的调用对象来“适应”原对象的参数列表。bind 函数定义在头文件 functional 中。
bind 使用示例
要将 comp2 绑定到 comp1。
comp1 比较两个 int 的大小,comp2 相当于第二个参数的默认实参为 6 的 comp1。
comp1(5, 6);//比较 5 和 6 的大小
auto comp2 = bind(comp1, _1, 6);
//bind 中第一个参数是 comp1 的函数名,后面的参数是 comp1 的参数列表。bind 的返回值是新生成的可调用对象
//_1 表示 comp2 的第一个参数,这里表示将 comp2 的第一个参数和 comp1 的第一个参数绑定在了一起。
comp2(7);//使用 comp2 比较 7 和 6 的大小。在调用 comp2(7) 时会将其映射为 comp1(7,6);
bind 占位符
_1,_2,_n 等占位符分别表示新可调用对象的第 1,2,n 个参数,将 _n 放在 bind 中不同的参数位置,表示将新可调用对象的第 n 个参数和旧可调用对象在该位置的参数绑定在了一起。
_1,_2 等定义在命名空间 placeholders 中,placeholders 这个名字定义在 std 中。placeholders 的实现定义在 functional 头文件中。
using namespace std::placeholders;//使用 _1,_2 前要先声明使用命名空间 placeholders。
bind 绑定的主要功能有两个:
- 可以减少参数数目。(减少掉的参数被设为一个固定值)
- 可以改变参数顺序。
auto g = bind(f, a, b, _2, c, _1); // g 只有两个参数,两个参数分别传递给 f 的第 5 个和第 3 个参数
将 bind 用于算法的谓词
因为算法的谓词只能是一元谓词或二元谓词,所以除了使用 lambda 外,也可以使用 bind 来将函数的参数缩减为 1 个或 2 个来作为谓词使用。
auto wc = find_if(words.begin(), words.end(), bind(comp2, _1, 6));
绑定引用参数
默认情况下,bind 的那些不是占位符的参数是值传递,被拷贝到 bind 返回的可调用对象中。
如果要传递引用或该参数类型不能拷贝(如 os)怎么办?使用 ref 函数。
ref 函数接受一个参数,返回一个可以拷贝的对象,该对象含有参数的引用。cref 生成保存 const 引用的类。ref 和 cref 也定义在头文件 functional 中。
bind(print, os, _1, '\n'); // 错误,os 不能拷贝
bind(print, ref(os), _1, 'n'); // 正确
10.4 再探迭代器
除了每个容器各自的迭代器外,标准库在头文件 iterator 中定义了四种迭代器:
- **插入迭代器:**绑定到容器上,可以来向容器插入元素。
- **流迭代器:**绑定到输入或输出流上,可以用来遍历所关联的 IO 流。
- **反向迭代器:**这些迭代器向后移动,除了 forward_list 外的标准库容器都有反向迭代器。
- **移动迭代器:**移动迭代器不拷贝其中的元素,而是移动他们。
10.4.1 插入迭代器
插入器是一种迭代器适配器,它接受一个容器,生成一个迭代器,能实现向给定容器添加元素。
插入器实际上是一个函数。
注意 back_inserter 是插入器,back_insert_iterator> 是插入迭代器类型。back_inserter(v) 返回绑定到容器 v 的 back_insert_iterator,并实现其自增。
插入器的三种类型
- back_inserter:创建一个使用 push_back 的迭代器。只有容器支持 push_back 才能使用 back_inserter。
- **front_inserter:**创建一个使用 push_front 的迭代器。只有容器支持 push_front 才能使用 front_inserter。
- **inserter:**创建一个使用 insert 的迭代器。此函数接受第二个参数,这个参数必须是一个指向给定容器的迭代器,元素将被插入到给定迭代器所表示的元素之前。
插入迭代器的定义
有两种方式,一种是直接定义,另一种是通过插入器生成
vector v; '使用插入器生成'
auto bIn = back_inserter(v); // bIn 是一个绑定到 v 的插入迭代器。
'直接定义'
back_insert_iterator> bIn(v); // bIn 是一个绑定到 v 的插入迭代器。
insert_iterator> iIn(v, v.begin()); // iIn 是一个绑定到 v 的插入迭代器
插入迭代器的操作
有实际意义的插入迭代器操作只有一种,就是赋值操作。
当通过插入迭代器赋值时,插入迭代器调用容器操作来向给定容器的指定位置插入一个元素。
*bIn = 30;//在 bIn 所绑定的容器的尾元素之后插入一个 30
*iIn = 10;//在 iIn 所绑定的容器的相应元素之前插入一个 10
插入器 inserter 与函数 insert 的不同
下面的 1 和 2 的效果是一样的。
插入迭代器是恒定指向同一个元素的。而 insert 返回的是指向所插入元素的迭代器
'1' auto iIn = inserter(v, v.begin());
*iIn = 10; '2' iter = v.insert(v.begin(), 10);
++iter;
插入迭代器的使用
vector v1,v2;
*back_inserter(v1) = 1; // 在 v1 的尾元素之后插入一个 1
*inserter(v1, v1.begin()) = 3; // 在 v1 的首元素之前插入一个 3
copy(v1.begin(),v1.end(),back_inserter(v2)); // 将 v1 的所有元素按顺序拷贝到 v2 的尾元素之后。 copy(v1.begin(),v1.end(),inserter(v2,v2.begin())); // 将 v1 的所有元素按顺序拷贝到 v2的首元素之前
10.4.2 iostream迭代器
iostream 有两类
- istream_iterator:读取输入流。
- ostream_iterator:向输出流写数据。
流迭代器可以绑定到 iostream,fstream,stringstream。它将对应的流当作一个元素序列来处理。
流迭代器的主要作用是辅助使用泛型算法从流对象读取数据和写入数据。
创建流迭代器时,必须指定迭代器将要读写的对象类型。
istream_iterator 的定义
可以为任何具有输入运算符的(>>)类型定义 istream_iterator,即所有内置类型和重置了 >> 的类。
创建流迭代器时,有两种情况:
- 绑定到一个流
- 默认初始化:采用这种方式创建的迭代器可以当作尾后值使用,可以在 for 循环中作为终止条件。
istream_iterator iInt(cin);
//创建了一个流迭代器 iInt,iInt 从 cin 读取 int
istream_iterator intEof;
//尾后迭代器。当关联的流遇到文件尾或遇到错误,迭代器的值就与尾后迭代器相等。
istream_iterator 操作
in1 == in2;
in1 != int2;//首先 in1 和 in2 必须读取相同类型。如果 in1 和 in2 都是尾后迭代器或绑定到相同的输入,则两者相等。
*in;//返回从流中读取的值
++in;in++;//递增操作
istream_iterator 的使用
流迭代器可以用于一部分泛型算法。
istream_iterator inInt(cin),eof;
'1'
while(inInt != eof)
vec.push_back(*inInt++);
'2'
vector vec(inInt,eof);//和上面效果相同,当遇到文件尾或遇到第一个不是 int 的数据停止。
ostream_iterator 定义
可以为任何具有输出运算符的(<<)类型定义 ostream_iterator,即所有内置类型和重置了 << 的类。
ostream_iterator<double> out(os);//out 将类型为 double 的值写到输出流 os 中
ostream_iterator<double> out(os,str);//out 将类型为 double 的值写到 os 中,每个值后面都跟着一个C风格字符串 str。
ostream_iterator 操作
ostream_iterator 的赋值操作等价于输出流的输出操作。每赋一次值,输出一次。
out = 3.14;//等价于 os<<3.14。将 3.14 写入到 out 绑定的输出流中。
*out;
++out;
out++;//这些运算符存在但没有意义。
ostream_iterator 的使用
for(auto e:vec)
out = e;//赋值语句将元素写到 cout,每赋一次值,写操作就会被提交一次。
for(auto e:vec)
*out++ = e;//与上面的语句实际效果相同,看起来更清晰。
也可以使用 copy 来打印 vec 中的元素,更为简单。
copy(vec.begin(),vec.end(),out);//将 vec 中的元素写入到了 out 绑定的输出流中
10.4.3 反向迭代器
除了 forward_list 外,其他容器都支持反向迭代器。
反向迭代器支持递增和递减操作。注意流迭代器不支持递减操作。
反向迭代器的颠倒
函数 riter.base() 返回相应的正向迭代器,正向迭代器指向靠后一个元素。
auto riter = string.rbegin()//反向迭代器 riter 指向 string 的尾元素 auto iter = riter.base();//正向迭代器 iter 指向 string 的尾后元素
10.5 泛型算法结构
10.5.1 5类迭代器
算法所要求的迭代器操作可以分为 5 类,每个算法都会为它的迭代器参数指明需提供哪类迭代器
- **输入迭代器:**只读,不写;单遍扫描,只能递增。
- **输出迭代器:**只写,不读;单遍扫描,只能递增。
- **前向迭代器:**可读写;多遍扫描,只能递增。
- **双向迭代器:**可读写;多遍扫描,可递增递减。
- **随机访问迭代器:**可读写,多遍扫描,支持全部迭代器运算。
迭代器根据支持的操作的多少分层。C++ 标准指明了泛型算法的每个迭代器参数的最小类别。
输入迭代器
输入迭代器只用于顺序访问,只能用于单遍扫描算法,如算法 find 和 accumulate。
Istream_iterator 是一种输入迭代器。
输出迭代器
只能向一个输出迭代器赋值一次,只能用于顺序访问的单遍扫描算法。如 copy 函数的第三个参数。
ostream_iterator 是一种输出迭代器。
前向迭代器
可以读写元素。只能在序列中沿一个方向移动,可以多次读写同一个元素。
可以保存前向迭代器的状态,使用前向迭代器的算法可以对序列多遍扫描。
算法 replace 要求前向迭代器,forward_list 的迭代器是前向迭代器。
双向迭代器
可以正向/反向读写序列中的元素。支持递增递减运算符。
算法 reverse 要求双向迭代器。list 的迭代器是双向迭代器。
随机访问迭代器
提供在常量时间内访问序列中任意元素的能力。
支持以下操作:
- 支持 <, <=, >, >= 等关系运算符。
- 支持迭代器与整数的加减。
- 支持两个迭代器之间的相减。
- 支持下标运算符。iter[n] 和 *(iter[n]) 含义相同。
算法 sort 要求随机访问迭代器。array, deque, vector, string 的迭代器是随机访问迭代器。
10.5.2 算法形参模式
算法的形参一般是以下 4 种模式之一
- alg(beg, end, other args);
- alg(beg, end, dest, other args); dest 经常是一个插入迭代器或一个 ostream_iterator,他们都能确保不管写多少元素都肯定是安全的。
- alg(beg, end, beg2, other args);
- alg(beg, end, beg2, end2, other args);
10.5.3 算法命名规范
算法遵循一同命名和重载规范。
重载谓词的算法
一些算法使用重载形式传递一个谓词,来代替 < 或 ==。
unique(beg, end); // 使用 == 比较元素 unique(beg, end, comp); // 使用 comp 比较元素
_if 版本的算法
接受一个元素值的算法通常有另一个不同名的 _if 版本。
find(beg, end, val); // 查找范围内 val 第一次出现的版本。
find_if(beg, end, pred); // 查找第一个令 pred 为真的元素。
拷贝版本的算法
默认情况下,重排元素的算法会将重排后的元素写回给定的输入序列中。拷贝版本则将元素写到一个给定的位置。
reverse(beg, end); // 反转序列中的元素。
reverse_copy(beg, end, dest); // 将元素按逆序拷贝到 dest。
remove_if(v1.begin(), v1.end(), [](int i){return i%2;}); // 从 v1 中删除奇数元素。 remove_copy_if(v1.begin(), v1.end(), back_inserter(v2), [](int i){return i%2;}); // 将去掉了奇数元素的 v1 序列拷到 v2 中。
10.6 特定容器算法
链表类型 list 和 forward_list 定义了几个成员函数形式的算法。它们定义了独有的 sort, merge, remove, reverse 和 unique。
通用版本的 sort 要求随机访问迭代器,而 list 和 forward_list 分别提供双向迭代器和前向迭代器,因此不能用于 list 和 forward_list。
其他链表类型定义的算法的通用版本可以用于链表,但是性能差很多,应该优先使用成员函数版本的算法。
成员函数版本的算法
lst.merge(lst2); // 将 lst2 的元素合并入 lst。两者必须都是有序的,合并后 lst2 将变为空。使用 < 比较元素。
lst.merge(lst2,comp); // 上面的 merge 的重载版本,用给定的 comp 代替 <
lst.remove(val); // 调用 erase 删除掉与给定值相等的每个元素。
lst.remove_if(pred); // pred 是个一元谓词,删除掉 lst 中使 pred 为真的每个元素。
lst.reverse(); // 反转 lst 中元素的顺序。
lst.sort(); // 使用 < 给元素排序
lst.sord(comp); // 重载版本
lst.unique(); // 调用 erase 删除同一个值的连续拷贝。
lst.unique(pred); // pred 是个二元谓词,删除使 pred 为真的连续拷贝。
splice算法
链表类型定义了 splice 算法,此算法是链表特有的,没有通用版本。
splice 算法用来在两个链表间移动元素或在一个链表中移动元素的位置。
lst.splice(p, lst2);
flst.splice_after(p, lst2);
// p 是一个指向 lst 中元素的迭代器,或一个指向 flst 首前位置的迭代器。
// 函数将 lst2 中的所有元素移动到 lst 中 p 之前的位置或 flst 中 p 之后的位置。
lst.splice(p, lst2, p2);
flst.splice_after(p, lst2, p2);
// p2 是一个指向 lst2 中位置的迭代器。
// 函数将 p2 指向的元素移动到 lst 中,或将 p2 之后的元素移动到 flst 中,lst2 可以是与 lst 或 flst 相同的链表。
lst.splice(p, lst2, b, e);
flst.splice_after (p, lst2, b, e);
// b 和 e 表示 lst2 中的合法范围。
// 将给定范围中的元素从 lst2 移动到 lst 中。lst2 可以是与 lst 或 flst 相同的链表,但是 p 不能指向 b 和 e 之间的元素。
问题
- 算法的操作对象是什么?
- 算法在哪两个头文件中?
- 算法处理的元素类型有什么要求?
- 算法关于输入参数的两个假定
- 常见的只读算法:求和、判等、按条件查找分别如何调用
- 常见的写算法:填充、按长度填充、拷贝、替代、替代拷贝、遍历执行;分别如何调用
- 常见的重排算法:排序、稳定排序、去重复排序;分别如何调用
- 插入迭代器是什么?如何使用?
- 谓词是什么?有几种?
- 可调用对象有几种?分别是什么?
回答
- 迭代器表示的范围
- algorithm 和 numeric
- 可以互相比较
- 参数为三个迭代器时假定第二个范围不小于第一个,参数为 1 个迭代器时假定范围不小于 n
- sum = accumulate(vec.begin(),vec.end(),sum0); bool F = equal(vec1.begin(),vec1.end(),vec2.begin());auto iter = find_if(vec.begin(),vec.end(),可调用对象);
- fill、fill_n、copy、replace、replace_copy、for_each
- sort、stable_sort、unique
- auto iter = back_inserter(vec);
- 谓词返回可以作为条件的值,有一元谓词和二元谓词两种
- 四种:函数、函数指针、重载了函数运算符的类、lambda表达式
问题
- lambda表达式适用于什么情况?
- lambda表达式有几个组成部分?分别是什么?哪两个必不可少?
- lambda 如何使用?
- 捕获列表的元素是什么?如何使用捕获列表?
- [&]{return s;} 是什么含义?[=]{return s;}是什么含义
- accumulate求出的和的类型由什么决定
- bind 函数有什么作用?如何使用?
- ref 函数有什么作用
- 插入迭代器常用于什么地方?
- 区分插入器和插入迭代器
- 什么是流迭代器?有什么用
- 反向迭代器如何颠倒?
- 泛型算法命名规范中,同类算法不同版本的三种扩展方式
- 链表 list 因为其链式结构的特殊性,定义了一些独有的算法版本作为成员函数,有哪些
回答
- 要用的参数不只一个或两个时
- 四个组成部分:捕获列表、参数列表、返回值、函数体。捕获列表和函数体不能省略
- auto f = []{return 0;} ; f();
- lambda 所在函数的非 static 变量。捕获列表可以进行值传递和引用传递,如果是值传递直接写变量的名字即可,如果是引用传递就在变量名前加一个 &。
- [&]表示隐式的引用传递,这时可以在函数体内直接使用外层函数的所有非 static 变量,函数体中的 s 必然是外层函数中的一个局部变量。[=] 表示隐式的值传递。
- 由第三个参数类型决定。
- bind 函数可以改变函数的参数数量和顺序,函数返回改变参数后的新调用对象,常用于泛型算法中。comp2 = bind(comp1,_1,6); comp2(3); bind 中的占位符定义在命名空间 placeholders 中。
- ref 函数接收一个参数,返回一个可以拷贝的对象,该对象内含该参数的引用。
- 插入迭代器常用于泛型算法中,可以用来向一个序列中插入元素,解决了泛型算法不能向序列添加元素的问题。
- 插入器是 back_inserter, front_inserter, inserter 等函数,这些函数会返回一个插入迭代器。
- 流迭代器包括 istream_iterator 和 ostream_iterator 两类。流迭代器绑定到一个流,常用于一部分泛型算法,从流对象读取数据和写入数据。
- 使用 base() 成员函数: auto iter = riter.base()。返回的正向迭代器指向靠后一个元素。
- 同一函数的重载版本多传递一个谓词参数;_if 版本的算法,_copy 版本的算法。
- 合并两个链表 merge,移除等于某个值的元素 remove,排序 sort,删除重复元素 unique,移动元素 splice
第11章 关联容器
关联容器中的元素按关键字来保存和访问,顺序容器中的元素按他们在容器中的位置来保存和访问
关联容器包括 map 和 set 。
map 和 multimap 在头文件 map 中,set 和 multiset 在头文件 set 中,无序 map 和无序 set 分别在头文件 unordered_map 和 unordered_set 中。
'按关键字有序保存元素'
map;//保存关键字-值对
set;//关键字就是值,只保存关键字
multimap;//关键字可重复出现的map
multiset;//关键字可重复出现的set
'无序集合'
unordered_map;//无序map
unordered_set;//无序set
unordered_multimap;//哈希组织的 map,关键字可重复出现
unordered_multiset;//哈希组织的 set,关键字可重复出现
11.1 使用关联容器
使用 map
map 可以使用范围 for 循环
map 的一个经典应用是单词计数程序
while(cin>>word)
++word_count[word];
使用 set
set 也可以使用范围 for 循环。
11.2 关联容器概述
所有的有序、无序关联容器都支持下面这些通用操作。
关联容器不支持顺序容器的位置相关的操作,关联容器中的元素是根据关键字存储的。
关联容器的迭代器都是双向的。
'类型别名'
iterator
const_iterator
value_type //容器元素类型。定义方式: vector::value_type
reference //元素类型的引用。定义方式: vector::reference
const_reference //元素的 const 左值类型
'构造函数'-'三种通用的构造函数:同类拷贝、迭代器范围初始化、列表初始化'
C c1; // 默认构造函数,构造空容器。
C c1 (c2); // 拷贝构造函数,容器类型与元素类型必须都相同
C c1 (c2.begin(), c2.end()); // 要求两种元素类型可以转换即可。
C c1 {a, b, c, ...}; // 使用初始化列表,容器的大小与初始化列表一样大
// 只有顺序容器的构造函数可以接受大小参数,关联容器不行。
'赋值与swap'
c1 = c2;
c1 = {a,b,c,....}
a.swap(b);
swap(a,b);//两种 swap 等价
'大小'
c.size();
c.max_size();//c 可以保存的最大元素数目,是整个内存层面的容量,不是已分配内存。不同于 caplity, caplity 只能用于 vector,queue,string
c.empty();
'添加/删除元素(不适用于array)'
c.insert(args); //将 args 中的元素拷贝进 c,args 是一个迭代器或迭代器范围
c.emplace(inits);//使用 inits 构造 c 中的一个元素
c.erase(args);//删除指定的元素,args 是一个迭代器或迭代器范围
c.clear();
'关系运算符'
==; !=; <; <=; >; >= //所有容器都支持相等和不等运算符。无序关联容易不支持大于小于运算符。
'获取迭代器'
c.begin(); c.end();
c.cbegin(); c.cend(); //返回 const_iterator
'反向容器的额外成员'
reverse_iterator //逆序迭代器,这是一个和 iterator 不同的类型
const_reverse_iterator
c.rbegin();c.rend();
c.crbegin();c.crend();
上面是关联容器和顺序容器的通用操作,下面是关联容器的额外操作
'类型别名'
key_type //关键字类型
mapped_type //每个关联的类型,只适用于 map
value_type //对于 set,与 key_type 相同,对于 map,为 pair
11.2.1 定义关联容器
只有顺序容器的构造函数可以接受大小参数,关联容器不行。
关联容器的初始化可以使用直接初始化(使用小括号)、列表初始化(使用花括号)、拷贝初始化(使用等号)。
使用迭代器范围进行直接初始化时,如果迭代器范围中有重复关键字,生成的 set 和 map 会自动去除重复的元素。
值初始化
除了三种构造函数外,关联容器可以进行值初始化。初始化器必须能转换为容器中元素的类型。
set ss = {"the","and"};
map sm = { {"LiLin","男"},{"HeFan","男"} };
初始化 map 时,将关键字-值对包括在一个花括号中 {key, value} 就可以构成 map 的一个元素。
初始化 multiset 和 multimap
使用迭代器范围进行直接初始化时,无论有没有重复关键字,都会生成包含所有元素的 multiset 和 multimap。
11.2.2 关键字类型的要求
有序容器的关键字类型
有序容器的关键字类型必须定义元素比较的方法,标准库默认使用 < 来比较关键字。可以使用如 vector 等容器的迭代器来作为有序容器的关键字。
重载了 < 运算符的类可以直接用作关键字。
可以向算法提供一个自己定义的比较操作,操作必须在关键字类型上定义一个严格弱序,类似小于等于但不一样:
- 两个关键字不能同时”小于等于“对方。
- 该操作有传递性。
- 如果两个关键字互不”小于等于“对方,那么两个就是等价的。容器将它们看做相等。
当两个关键字是等价的,map 只能存储一个,但是也可以通过另一个关键字来访问值。
使用关键字类型的比较函数
当自己定义了比较操作,必须在定义关联容器时指出来,自定义的操作类型(函数指针类型)应在尖括号中紧跟元素类型给出。并将函数名作为参数传递给构造函数。
比较函数应该返回 bool 值,两个参数的类型应该都是容器的关键字类型。当第一个参数小于第二个参数时返回真。
'比较函数的定义方式'
bool comp(const Sales_data &lhs, const Sales_data &rhs)
{
return lhs.isbn() < rhs.isbn();
}
'定义容器对象'
multiset bookstore(comp);
注意当使用 decltype 获取函数指针时要加上 * 运算符。
11.2.3 pair类型
pair 类型定义在头文件 utility 中。
pair 也是一个模板。
pair 定义
pair 的默认构造函数对数据成员进行值初始化,因此 string,vector 等类型会默认为空,int 会默认为 0。
'直接定义'
pair p;//默认初始化
pair p(str, i);
pair p{"LiLin", 17};
pair p = {"LiLin", 17};
'使用 make_pair'
auto p = make_pari(v1, v2);//pair 的类型根据 v1 和 v2 的类型推断。
pair 操作
p.first //返回 p 的第一个成员
p.second //返回 p 的第二个成员
p1 < p2; //当 p1.first < p2.first && p1.second < p2.second 时为真。
p1<=p2; p1>p2; p1>=p2;
p1 == p2;//当 first 和 second 成员都相等时,两个 pair 相等。
p1 != p2;
创建 pair 类型的返回值
如果一个函数返回一个 pair,可以对返回值进行列表初始化或隐式构造返回值
pair process(bool a){
if(a)
return {"LiLin",17};//列表初始化
else
return pair();//隐式构造返回值
}
11.3 关联容器操作
关联容器除了上面列出的类型别名,还有如下三种
'类型别名'
key_type //关键字类型
mapped_type //每个关联的类型,只适用于 map
value_type //对于 set,与 key_type 相同,对于 map,为 pair
注意 set 的 key_type 类型不是常量,pair 的 first 成员也不是常量,只有 map 的 value_type 中的 first 成员是常量。
11.3.1 关联容器迭代器
解引用关联容器迭代器得到的是 value_type 的引用。
set 的迭代器
set 的关键值与 map 的关键值一样,都是不能改变的。
可以用 set 的迭代器读取元素值,但不能修改。
关联容器和算法
当对关联容器使用泛型算法时,一般要么把它作为源序列,要么把它作为目的序列。比如从关联容器拷贝元素,向关联容器插入元素等。
11.3.2 添加元素
插入容器中已存在的元素对 map 和 set 没有影响。
使用 insert 添加元素
关联容器添加元素一般使用 insert 成员,可以添加一个元素也可以添加一个元素范围,或者初始化列表。
set s;
s.insert(10); // 插入一个元素(s中没有关键字时才插入)。返回一个pair,pair包含一个迭代器指向具有指定关键字的元素,和一个表明是否插入成功的 bool 值
s.insert(vec.begin(), vec.end(); // 插入迭代器范围。返回 void
s.insert({1, 2, 3}); // 插入初始化列表。返回 void
s.insert(iter, 10); // 类似于 insert(10),iter 是一个迭代器,提示从哪里开始搜索新元素应该存储的位置。返回一个迭代器,指向具有制定关键字的元素。
向 map 添加临时构造的元素
map m;
'四种方法'
m.insert({str, 1}); //最简单的方法,直接使用花括号
m.insert(make_pair(str, 1));
m.insert(pair(str, 1)); //pair 类型直接定义
m.insert(map::value_type(str, 1));
使用 emplace 添加元素
s.emplace(args);//args用来构造一个元素,其他和 s.insert(10) 相同
s.emplace(iter, args);//除了 args 其他和 s.insert(iter, 10) 相同
检测 insert 的返回值
注意 insert 返回的值不是固定的,依赖于容器类型和参数
- 对于不重复的map和set,添加的单一元素的 insert 和 emplace 都返回一个 pair,pair 内是具有给定关键字的元素的迭代器和一个 bool 值
- 对于不重复的map和set,添加多个元素都返回 void
在向 map 或 set 添加元素时,检测 insert 的返回值可以很有用,要灵活使用。
while(cin>>word){
auto ret = word_count.insert({word,1});
if(ret.second = false)
++ret.first->second;
}
向 multiset 或 multimap 添加元素
在 multiset 或 multimap 上调用 insert 总会插入元素。
插入单个元素的 insert 返回一个指向新元素的迭代器。
11.3.3 删除元素
关联容器定义了一个额外版本的 erase 和两个与顺序容器相似版本的 erase
- **额外版本:**输入参数为关键字(注意不是关键字的迭代器),返回删除的元素数量,对于非重复关键字的容器,返回值总是 1 或 0。
- **与顺序容器相似版本:**注意顺序容器会返回删除元素后一个元素的迭代器,而这里的 erase 返回 void
'与顺序容器相似版本的 erase'
s.erase(iter); // 删除一个元素,返回 void
s.erase(iter1, iter2) // 删除一个范围,返回 void
'额外版本'
auto cnt = s.erase("LiLin");//
删除关联容器的最后一个元素
m.erase(--m.end()); // 正确!m 的迭代器支持自增与自减
m.erase(m.rbegin()); // 错误!
遍历容器删除元素
注意 map 和 vector 的不同
'map'
map m;
for(auto iter = m.begin(); iter != m.end(); ){
if(iter->second == 0)
m.erase(iter++); //这是循环map删除指定元素的唯一方式。利用了 i++ 的原理
else
iter++;
}
'vector'
vector v;
for(auto iter = v.begin(); iter != v.end(); ){
if(*iter == 0)
iter = v.erase(iter);//vecotr 的 erase 操作返回所删除元素之后的迭代器
else
iter++;
}
11.3.4 map的下标操作c
map 和 unordered_map 都支持下标操作和对应的 at 函数。set 类型则不支持下标。multimap 和 unordered_multimap 不支持下标操作。
map 的下标操作会返回一个 mapped_type 对象。
如果关键字不再 map 中,会创建一个元素并插入到 map 中,关联值将进行值初始化。
注意:因为关联值是值初始化,所以在单词计数程序中,可以直接 map[word]++ ,不必特意插入元素。
注意:map 的下标操作只能返回非常量引用(不同于顺序容器的下标操作),如果 map 本身是常量,则无法使用下标访问元素,这时要用 at() 函数。
at 函数
m.at(k) 会访问关键字为 k 的元素,带参数检查;如果 k 不在 m 中,抛出一个 out_of_range 异常。
11.3.5 访问与查找元素
访问元素
map 可以通过下标或 at() 函数访问元素。
set 只能通过迭代器来访问元素。
'基本的访问操作'
c[k];
c.at(k);
访问 map/set 的最后一个元素:m.rbegin() 或 --m.end()。
查找元素
关联容器查找一个指定元素的方法有多种。一般 find 是最佳选择。
对于不允许重复关键字的容器,find 和 count 差别不大,对于允许重复关键字的容器,count 会统计有多少个元素有相同的关键字。
'查找操作'
c.find(k);//返回一个迭代器,指向关键字为 k 的元素,如果 k 不在容器中,返回尾后迭代器。
c.count(k);//返回关键字等于 k 的元素数量。
c.lower_bound(k);//返回一个迭代器,指向第一个关键字大于等于 k 的元素。
c.upper_bound(k);//返回一个迭代器,指向第一个关键字大于 k 的元素。
c.equal_range(k);//返回一个迭代器 pair,表示关键字等于 k 的元素范围。若干 k 不存在,pair 的两个成员相等,指向可以安全插入 k 的位置
检查元素是否存在
检查元素是否存在用 find 或 count。
if(word_count.find("LiLin") == word_count.end())
if(word_count.count("LiLin") == 0)
在 multimap 或 multiset 中查找元素
要在 multimap 或 multiset 中查找所有具有给定关键字的元素比较麻烦,有三种方法
- 使用 find 和 count 配合,找到第一个关键字为 k 的元素和所有关键字为 k 的元素数目,遍历完成。
- 使用 lower_bound 和 upper_bound 配合。注意当关键字 k 不存在时,这两个函数返回相同的迭代器,可能是尾后迭代器也可能不是。
- 使用 equal_range。最直接的方法
for(auto pos = multiM(item); pos.first != pos.second; ++pos.first)
cout << pos.first->second;
11.4 无序容器
4 个无序容器使用哈希函数和关键字类型的 == 运算符来组织元素,而非比较运算符。
无序容器用于关键字类型不好排序的情况。
使用无序容器
无序容器也有 find,insert,迭代器等操作。
在大多数情况下,可以用无序容器替换对应的有序容器,反之亦然。但是注意无序容器中元素未按顺序存储。
管理桶
无序容器在存储上组织为一组桶,每个桶保存零个或多个元素。
无序容器使用哈希函数将元素映射到桶,并将具有一个特定哈希值的所有元素保存在相同的桶中。如果容器允许重复关键字,那所有具有相同关键字的元素也都在同一个桶中。不同关键字的元素也可能映射到相同的桶。
对于相同的参数,哈希函数总是产生相同的结果。
当一个桶中保存了多个元素,需要顺序搜索这些元素来查找想要的那个。计算一个元素的哈希值和在桶中搜索通常都很快。
管理桶的函数
'桶接口'
c.bucket_count(); //返回正在使用的桶的数目
c.max_bucket_count(); //返回容器能容纳的最多的桶的数量
c.bucket_size(n); //返回第 n 个桶中有多少个元素
c.bucket(k); //返回关键字为 k 的元素所在的桶
'桶迭代'
local_iterator //类型别名,可以用来访问桶中元素的迭代器类型
const_local_iterator //类型别名,桶迭代器的常量版本
c.begin(n), c.end(n) //返回桶 n 的首元素迭代器和尾后迭代器
c.cbegin(n),c.cend(n)
'哈希策略'
c.load_factor(); //返回每个桶的平均元素数量,类型为 float
c.max_load_factor(); //返回 c 试图维护的平均桶大小,类型为 float。c 会在需要时添加新的桶,始终保持 load_factor <= max_loat_factor
c.rehash(n); //重组存储,使得 bucket_count >= n 且 bucket_count > size / max_load_factor
c.reserve(n); //重组存储,使得 c 可以保存 n 个元素而不必 rehash。
无序容器对关键字的要求
默认情况下,无序容器使用 == 运算符比较关键字,使用用一个 hash (hash 模板)类型的对象来生成每个元素的哈希值。
标准库为内置类型(包括指针)和 string、智能指针等都定义了 hash,因此内置类型,string 和智能指针类型都能直接用来作为无序容器的关键字。
对于自定义的类类型,不能直接用来作为无序容器的关键字,因为他们不能直接使用 hash 模板,除非提供自己的 hash 模板版本。
'定义自己的 hash 模板版本'
size_t hasher(const Sales_data &sd){
return hash() (sd.isbn());//这里采用了标准库的 hash 类型对象来计算 isbn 成员的哈希值,作为整个 Sale_data 对象的哈希值。
}
'重载比较函数(这里是相等)'
bool eq(const Sales_data &lhs, const Sales_data &rhs){
return lhs.isbn() == rhs.isbn();
}
'定义 unordered_multiset'
unordered_multiset< Sales_data, decltype(hasher)*, decltype(eq)* > sals;
无论是有序容器还是无序容器,具有相同关键字的元素都是相邻存储的。
问题
- 关联容器删除元素有哪些方法?
- 关联容器添加元素有哪些方法?
- 关联容器定义了哪些类型别名?
- 如何使用 decltype 获取函数指针类型
- pair 的默认构造函数对数据成员进行什么初始化
- 可以使用花括号列表来对 pair 初始化吗
- 定义一个 pair 类型对象的方式
- set 的元素可以改变值吗
- insert 有哪些应用方式
- 循环删除 map 中元素的方式。
回答
- 使用 s.erase 删除元素,erase 除了接受迭代器为参数(返回void,不同于顺序容器)外,也可以直接接受关键值作为参数**(返回删除的元素数量)**。
- 可以使用 insert 函数和 emplace 函数,map 还可以直接通过索引添加。
- 迭代器类型、value_type、reference、const_reference、key_type、mapped_type(只用于 map)
- 后面加上 * 运算符:decltype(comp)*
- 值初始化
- 可以,比如 pair p = {“LiLin”,17};
- 直接定义和使用 makr_pair 两种方法
- 不可以,set 的元素即是关键字又是值。理解:改变关键字实际上就相当于变为了另一个元素,所以不能改变。
- 两种基础应用是可以直接接受一个元素值或接受一个迭代器范围。**注意:添加单一元素的 insert 返回的是一个 pair,这个很有用。**其他 insert 都返回 void
- 循环内删除时使用 m.erase(iter++)。
问题
- map 访问元素的方式?set 访问元素的方式?
- map 和 set 查找元素的方式
- 在 multimap 和 multiset 中查找元素的方法
- 无序容器如何使用
回答
map 可以使用下标和 at() 函数访问元素,注意两者在遇到不包含元素时的不同处理。set 可以使用 at() 函数访问元素,不能使用下标。
可以使用 find 和 count 查找元素,此外还有 lower_bound, upper_bound, equal_range 三个查找大于某个值或等于某个值的元素的方式。
比较麻烦,有三种方法:
- 直接使用 equal_range
- 使用 find 和 count 配合
- 使用 lower_bound 和 upper_bound 配合。
默认情况下,无序容器的关键字只能是内置类型、string、智能指针。无序容器也可以使用 find、insert、迭代器。无序容器还有一些桶相关的操作。
第12章 动态内存
动态分配对象的生存期通过显示的分配与释放来控制。
动态对象的正确释放是一个极容易出错的地方。
静态内存用来保存全局变量与局部 static 对象,类 static 数据成员。
栈内存用来保存定义在函数内的非 static 对象。
堆保存动态分配的对象。
12.0 补充知识
堆内存和栈内存的比较:
-
控制权:
-
- 栈由编译器自动分配和释放;
- 堆由程序员分配和释放
-
空间大小:
-
- 栈:windows下,栈是向低地址扩展的,是连续的内存区域,所以栈顶地址和栈的最大容量都是确定的,似乎一般是 2M 或 1M
- 堆:堆是向高地址扩展的,是不连续的内存区域。系统是用链表来存储空闲地址的。堆的大小由计算机的有效虚拟内存决定,因此空间大得多。
-
分配效率:
-
- 栈:速度较快。
- 堆:速度较慢,但使用方便。
-
系统响应:
-
- 栈:如果剩余空间不足,异常提示栈溢出
- 堆:在记录空闲地址的链表中寻找空间大于所申请空间的堆结点,然后将该结点从空闲节点链表中删除。一般会在首地址处记录本次分配空间的大小。
-
存储内容:
-
- 栈:存储函数的各个参数、局部变量、函数返回地址等。第一个进栈的就是函数返回地址
- 堆:内容由程序员决定。
12.1 动态内存与智能指针
c++ 使用 new 和 delete 管理动态内存
- new:在堆中为对象分配空间并返回指向该对象的指针
- delete:接受一个动态对象的指针,销毁该对象并释放内存。
忘记释放内存会引起内存泄漏,释放了后继续引用指针会引用非法内存。
如果忘记释放内存,在程序结束时会由操作系统自动回收。
新标准库提供两种智能指针和一个伴随类管理动态内存,都定义在头文件 memory 中:
- shared_ptr:允许多个指针指向一个对象
- unique_tpr:独占所指的对象
- weak_ptr:一种弱引用,指向 shared_ptr 所管理的对象
要注意到:智能指针实际上是一个类模板。但是它的操作与指针十分相似
12.1.1 shared_ptr类
智能指针也是模板,类似 vector。在创建模板时,必须提供指针指向的类型。
shared_ptr p1; // 可以指向
string shared_ptr> p2; // 可以指向 int 的 vector
默认初始化的智能指针中保存着空指针。
定义 shared_ptr 的方式
可以使用另一个 shared_ptr 或一个 unique_ptr 或 new 的指针来初始化一个 shared_ptr。
shared_ptr p; // 默认初始化为空指针
shared_ptr p(q); // q 也是一个 shared_ptr,p 是 q 的拷贝,此操作会递增 q 中的计数器。
shared_ptr p(qnew); // qnew 是一个指向动态内存的内置指针(qnew = new int;))
shared_ptr p(u); // u 是一个 unique_ptr。p 从 u 接管了对象的所有权,u 被置为空
shared_ptr p(q, deleter); // q 是一个内置指针。p 将使用可调用对象 deleter 来代替 delete
shared_ptr p(p2, deleter); // p2 是一个 shared_ptr,p 是 p2 的拷贝,唯一的区别是 p 将可调用对象 d 来代替 delete。
auto p = make_shared(10); //返回一个 shared_ptr,指向一个初始化为 10 的动态分配的 int 对象。注意不同于 make_pair
shared_ptr 操作
sp // 智能指针作为 if 的判断条件时检查其是否为空,若 sp 指向一个对象,则为 true
sp->mem; // 等价于 (*p).mem。用于当 sp 指向一个类时
sp.get(); // 返回 sp 中保存的指针。要小心使用!
swap(p, q); // 交换 p 和 q 中的指针
p.swap(q); // 同上
p = q; // 此操作会递增 q 中的计数器,递减 p 原来的计数器,若其变为 0,则释放。
p.unique(); // 若 p.use_count() 为 1,返回 true,否则返回 false
p.use_count(); // 返回与 p 共享对象的智能指针数量。可能运行很慢,主要用于调试
p.reset(); // 将 p 置为空,如果 p 计数值为 1,释放对象。
p.reset(q); // q 是一个内置指针,令 p 指向 q。
p.reset(q, d); // 调用可调用对象 d 而不是 delete 来释放 q
make_shared 函数
这是最安全的分配和使用动态内存的方法
make_shared 类似顺序容器的 emplace 成员,用参数来构造对象。
通常用 auto 来定义一个对象保存 make_shared 的结果。
make_shared 是函数模板,要提供模板参数
shared_ptr p1 = make_shared(10);
auto p2 = make_shared(10,'s');
shared_ptr 的拷贝和赋值
每个 shared_ptr 都有一个关联的计数器,如果拷贝一个 shared_ptr,计数器就会递增。
例如初始化,或作为参数传递给函数,或作为函数返回值时。
如果 shared_ptr 的计数器变为 0,就会自动释放管理的对象。
auto r = make_shared(42); // r 指向的 int 只有一个引用者
r = q; // 给 r 赋值,令它指向另一个地址。
//这会递增 q 指向的对象的引用计数,并递减 r 原来指向的对象的引用计数。因为 r 原来指向的对象没有已经没有引用者,所以会自动释放。
shared_ptr 自动销毁所管理的对象
shared_ptr 通过析构函数来完成销毁。
它的析构函数会递减对象的引用计数,如果计数变为 0,则销毁对象并释放内存。
shared_ptr 自动释放相关联的内存
由于最后一个 shared_ptr 销毁前内存都不会释放,所以要保证 shared_ptr 无用之后就不要再保留了。
如果忘记销毁不再需要的 shared_ptr,程序不会出错,但会浪费内存。
一种常量的情况是将 shared_ptr 存放在一个容器中,后来其中有一部分元素不再用到了,这时要注意用 erase 删除不需要的元素。
析构函数
每个类都有析构函数。析构函数控制对象销毁时执行什么操作。
析构函数一般用来释放对象分配的资源。如 vector 的析构函数销毁它的元素并释放内存。
使用动态内存的三种情况
- 不知道需要使用多少对象。例如容器类
- 不知道对象的准确类型。
- 需要在多个对象间共享内存。
使用动态内存在多个对象间共享内存
定义一个类,类的数据成员为一个 shared_ptr。使用此 shared_ptr 来管理一个 vector,即可实现在多个类对象间共享同一个 vector。当所有类对象都被销毁时 vector 才会被销毁。注意一个类只会与它的拷贝共享一个 vector,单独定义的两个类是不共享的。
一个实例:StrBlob类
StrBlob 类是一个使用动态内存在多个对象间共享内存的例子。
StrBlob 类中仅有一个 shared_ptr 成员,这个 shared_ptr 指向一个 string 的 vector。
#include
#include
#include
#include
#include
using std::vector; using std::string;
class StrBlob {
public:
using size_type = vector::size_type; // 灵活使用类型别名
StrBlob():data(std::make_shared>()) { }
StrBlob(std::initializer_list il):data(std::make_shared>(il)) { } //定义了一个接受初始化列表的转换构造函数(注意不是 explicit 的)
size_type size() const { return data->size(); } // size() 函数不改变数据成员,所以声明为 const 的
bool empty() const { return data->empty(); } // 声明为 const 的
void push_back(const string &t) { data->push_back(t); }
void pop_back() {
check(0, "pop_back on empty StrBlob");
data->pop_back();
}
std::string& front() {
check(0, "front on empty StrBlob");
return data->front();
}
std::string& back() {
check(0, "back on empty StrBlob");
return data->back();
}
const std::string& front() const { //在普通的 front() 函数外又重载了一个 const 的版本
check(0, "front on empty StrBlob");
return data->front();
}
const std::string& back() const { //在普通的 back() 函数外又重载了一个 const 的版本
check(0, "back on empty StrBlob");
return data->back();
}
private:
void check(size_type i, const string &msg) const { //定义了一个 check 函数来检查索引是否超出边界
if (i >= data->size()) throw std::out_of_range(msg); //不检查 i 是否小于 0 是因为 i 的类型是 size_type,是无符号类型,如果 i<0 会被自动转换为大于 0 的数
}
private:
std::shared_ptr> data;
};
在实现上面这个类时要注意的几点:
- 对于不改变类的成员的函数,要声明为 const 的。
- 对于 front(), back() 等返回成员的函数,既要定义返回普通引用的版本,也要定义返回常量引用的版本。返回常量引用的版本要声明为 const 的,这样才能成功地进行重载,不然只有返回值类型不同,编译器无法区分。
- check 函数不检查 i 是否小于 0 是因为 i 的类型是 size_type,是无符号类型,如果 i<0 会被自动转换为大于 0 的数
- 这里的接受 initializer_list 的转换构造函数没有定义为 explicit 的,这样的好处是使用方便,可以进行隐式的转换。缺点是不易调试。
12.1.2 直接管理内存
可以使用 new 和 delete 来直接管理内存。相比于智能指针,它们非常容易出错。
自己直接管理内存的类不能依赖默认合成的拷贝控制成员,通常都需要自己定义。而使用了智能指针的类则可以使用默认合成的版本。
使用new动态分配和初始化对象
new 无法为分配的对象命名,只是返回一个指针。
默认情况下,动态分配的对象被默认初始化。可以用直接初始化或列表初始化或值初始化初始动态分配的对象。
int* p = new int; //默认初始化
string* sp = new string(10,'g');//直接初始化
vector* vp = new vector{0,1,2,3};//列表初始化
区分值初始化和默认初始化
对于类来说,值初始化与默认初始化没有什么区别,对于内置类型来说,值初始化对象会有一个良好的值,默认初始化对象值未定义。
值初始化只需加括号即可。
int* p1 = new int; // 默认初始化,p1 所指对象的值是未定义的
int* p2 = new int(); // 值初始化,p2 所指对象的值初始化为 0
建议对动态分配的对象进行值初始化,如同变量初始化一样。
使用 auto
当用括号提供了单个初始化器,就可以使用 auto(前后都用 auto)
auto p1 = new auto(a); // p1 指向一个与 a 类型相同的对象,该对象用 a 初始化
auto p1 = new auto{a, b, c}; // 错误,不是单一初始化器,有多个。
动态分配的 const 对象
可以使用 new 分配 const 对象,前后都要加 const
const int* pci = new const int(10);
动态分配的 const 对象必须初始化,类类型可以隐式初始化。
内存耗尽
如果没有可用内存了,new 就会失败。
默认情况下,如果 new 失败,会爆出一个 bad_alloc 类型的异常。
使用定位 new 可以向 new 传递参数,传递 nothrow 可以阻止 new 在分配失败的情况下抛出异常。
bad_alloc 和 nothrow 都定义在头文件 new 中
int* p = new(nothrow) int;//如果分配失败,返回一个空指针
释放动态内存
使用 delete 表达式来释放动态内存,包括动态分配的 const 对象也是直接 delete 即可。
delete执行两个动作:
- 销毁指针所指对象(但没有销毁指针本身)
- 释放对应内存
delete p; // p 必须指向一个动态分配的对象或是一个空指针
释放一个不是动态分配的指针和相同的指针释放多次的行为都是未定义的。
通常编译器不能分辨 delete 的对象是动态还是静态分配的对象,也不能分辨一个指针所指的内存是否已被释放。
动态对象直到被显式释放前都是存在的。
两种特殊情况:
-
指针不在内存还在
-
- 当指针是一个局部变量,因超出作用域而被销毁时,其指向的动态内存不会自动释放。当没有指针指向这块内存时,就无法再释放了。这就是忘记 delete 产生的内存泄漏的问题。
-
指针还在内存不在
-
-
delete一个指针后,指针值已经无效,但是指针还是保存着地址,此时就变成了空悬指针。有两个解决方法
-
- delete 之后将指针置为空指针
- 在指针作用域的末尾 delete
-
如果有多个指针指向同一块动态内存,只能 delete 一个指针,因为 delete 的是空间,如果 delete 两个指针,可能会破坏自由空间。但必须将多个指针都重置。
使用 new 和 delete 的三个常见错误:
- 忘记 delete 内存:内存泄漏。
- 使用已释放的的对象。
- 同一块内存释放两次。
一个会导致内存泄漏的例子
bool b() {
int* p = new int; // p 是一个 int 型指针
return p; // 函数返回值是 bool 类型,将 int 型指针转换为 bool 类型会使内存无法释放,造成内存泄漏
}
12.1.3 shared_ptr和new结合使用
可以使用 new 初始化智能指针。但是最好还是用 make_shared
接受指针参数的智能指针构造参数是 explicit 的,不能将内置指针隐式地转换为智能指针**。**因此不能使用赋值,只能用直接初始化。
shared_ptr p1(new int(42)); // 正确:调用了转换构造函数
shared_ptr p2 = new int(42); // 错误:转换构造函数是 explicit 的,不能隐式转换
默认情况下用于初始化智能指针的普通指针只能指向动态内存,因为智能指针默认使用 delete 释放对象。
如果将智能指针绑定到一个指向其他类型资源的指针上,要定义自己的删除器(函数) 来代替 delete
建议不要混用智能指针和普通指针
shared_ptr 可以协调对象的析构,但仅限于自身的拷贝之间。这就是推荐使用 make_shared 而不是 new 的原因。
使用普通指针(即 new 返回的指针)来创建一个 shared_ptr 有两个易错之处:
- 使用普通指针创建 shared_ptr 后,又使用该普通指针访问动态对象。普通指针并不知道该对象何时被 shared_ptr 所释放,随时可能变成空悬指针。
- 使用同一个普通指针创建了多个 shared_ptr ,这就将同一块内存绑定到多个独立创建的 shared_ptr 上了。
当将一个 shared_ptr 绑定到一个普通指针后,就不要再用内置指针来访问所指内存了。
不要使用 get 初始化另一个智能指针或为智能指针赋值
智能指针的 get 函数返回一个内置指针。
shared_ptr p(new int(42));
int* q = p.get(); // 这是正确的,但是要极小心地使用,这会非常容易出错。
注意:不要使用 get 初始化另一个智能指针或为智能指针赋值。也不能通过 get 返回的指针来 delete 此指针。
shared_ptr 的关联计数只应用于自己的拷贝,如果使用某智能指针的 get 函数初始化另一个智能指针,两个指针的计数是不关联的,销毁一个就会直接释放内存使另一个成为空悬指针。
一个错误的例子
auto p = sp.get();
delete p; //错误,这会造成 double free。
12.1.4 智能指针和异常
使用异常处理的程序能在异常发生后令程序流程继续,它需要确保在异常发生后资源能被正确地释放,一种简单的方法是使用智能指针。
使用智能指针时发生异常,智能指针管理的内存会被释放掉,而如果是直接管理内存时,在 new 和 delete 之间发生了异常,则内存不会被释放。
智能指针和哑类
所有标准库类都定义了析构函数,负责清理对象使用的资源。
但是那些为 C 和 C++ 两种语言设计的类,通常都没有良好定义的析构函数,必须显式释放资源。
如果在资源分配和释放之间发生了异常,或程序员忘记释放资源,程序也会发生资源泄漏。
例如网络连接中的在释放连接前发生了异常,那么连接就不会被释放了。
使用自己的释放操作
默认情况下,shared_ptr 假定它们指向的是动态内存,在销毁时会使用 delete 操作。
但也可以使用 shared_ptr 管理其他对象,如网络连接,这时就需要定义一个相应的删除器函数来代替 delete。
可以定义一个函数来代替 delete,称为删除器。
share_ptr p(&t, deleter); //deleter 必须是一个接受一个 T* 类型参数的函数
使用 shared_ptr 管理网络连接
shared_ptr p(&c, end_connection);// end_connection 是 p 的删除器,它接受一个 connection* 参数
智能指针陷阱
- 不使用相同的内置指针值初始化或 reset 多个智能指针
- 不 delete get() 返回的指针
- 不使用 get() 初始化或 reset 另一个智能指针
- 如果使用 get() 返回的指针,当最后一个对应的智能指针被销毁后,指针就变为无效的了
- 如果智能指针管理的不是 new 分配的内存,记住传递给它一个删除器
12.1.5 unique_ptr
同一时刻只能有一个 unique_ptr 指向一个给定对象。
当 unique_ptr 被销毁时,指向对象也被销毁。
定义 unique_ptr 时,需要绑定到一个 new 返回的指针上(不同于 shared_ptr)。c++14 中加入了 make_unique
类似 shared_ptr,初始化 unique_ptr 必须采用直接初始化。(这里指使用 new 初始化)
因为 unique_ptr 独有它指向的对象,所有它不支持拷贝和赋值操作。实际上 unique_ptr 的拷贝构造函数被定义为删除的。
unique_ptr 定义和初始化
unique_ptr u1; // 定义一个空 unique_ptr
unique_ptr u1(new int()); // 正确
unique_ptr u; // 定义一个空 unqiue,用可调用对象 deleter 代替 delete
unique_ptr u(d); // 空 unique,用类型为 deleter 的对象 d 代替delete
unique_ptr u(new int(42),d);
unique_ptr u2(u1); // 错误:不支持拷贝
注意 unique_ptr 管理删除器的方式与 shared_ptr 不一样。unique_ptr 将删除器放在尖括号中
unique_ptr 操作
u.get();
u1.swap(u2);swap(u1,u2);
u = nullptr; // 释放 u 指向的对象并将 u 置为空
auto u2 = u.release(); // u 放弃对指针的控制权,返回 u 中保存的内置指针,并将 u 置为空,注意 u2 的类型是内置指针,而不是 unique_ptr
u.reset(); // 释放 u 指向的对象
u.reset(nullptr); // 释放 u 指向的对象,并将 u 置为空,等价于 u = nullptr;
u.reset(q); // 令 u 指向内置指针 q 指向的对象
可以通过 release 或 reset 将指针的所有权从一个 unique_ptr 转移给另一个 unique
unique_ptr u2(u1.release()); // 控制器转移给 u2,u1 置为空
u3.reset(u1.release()); // 释放 u3 原来指向的内存,u3 接管 u1 指向的对象。
release的使用
release 返回的指针通常用来初始化其他智能指针或给其他智能指针赋值。
release 返回的指针不能空闲,必须有其他指针接管对象。如果是一个内置指针接管了 release 返回的指针,那么程序就要负责资源的释放。
u.release(); // 错误:release 不会释放内存,没有其他指针接管内存。
auto u2 = u1.release(); // 正确,但必须记得 delete p
传递unique_ptr参数和返回unique_ptr
不能拷贝 unique_ptr 参数的规则有一个例外:可以拷贝或赋值一个将要被销毁的 unique_ptr。如从函数返回一个 unique_ptr
unique_ptr clone(int p) {
unique_ptr ret(new int(p));
return ret;
}
上面这种情况,编译器知道要返回的对象将要被销毁,在此情况下,编译器执行一种特殊的拷贝。
向 unique_ptr 传递删除器
类似 shared_ptr,unique_ptr 默认情况下使用 delete 释放它指向的对象。可以重载 unique_ptr 中默认的删除器。
但 unique_ptr 管理删除器的方式与 shared_ptr 不一样。unique_ptr 将删除器放在尖括号中
因为对于 unique_ptr 来说,删除器的类型是构成 unique_ptr 类型的一部分。
auto_ptr
auto_ptr 是标准库的较早版本包含的一个类,它具有 unique_ptr 的部分特性。相比于 unique_ptr,不能在容器中保存 auto_ptr,也不能从函数返回 auto_ptr。
错误案例
int ix = 1024, *pi = &ix, *pi2 = new int(2048);
unique_ptr p0(ix); // 错误:从 int 到 unique_ptr 的无效的转换
unique_ptr p1(pi); // 运行时错误:当 p1 被销毁时会对 pi 调用 delete,这是一个对非动态分配返回的指针调用 delete 的错误。
unique_ptr p2(pi2); // 不会报错,但当 p2 被销毁后会使 pi2 成为一个悬空指针
unique_ptr p3(new int(2048)); // 正确,推荐的用法
12.1.6 weak_ptr
weak_ptr 指向一个由 shared_ptr 管理的对象,它不控制所指向对象的生存期。
将一个 weak_ptr 绑定到 shared_ptr 不会改变 shared_ptr 的引用计数。
如果 shared_ptr 都被销毁,即使还有 weak_ptr 指向对象,对象依然会释放(因此不能使用 weak_ptr 直接访问对象)。
weak_ptr 初始化
创建 weak_ptr 时,要用 shared_ptr 来初始化它。
weak_ptr w; // 默认初始化,定义一个空 weak_ptr w,w 可以指向类型为 T 的对象
w = p; // p 可以是一个 shared_ptr 或 weak_ptr,赋值后 w 与 p 共享对象
weak_ptr w(sp); // 定义一个与 shared_ptr sp 指向相同对象的 weak_ptr。T 必须能转换成 sp 指向的类型(不必相同)
weak_ptr 操作
因为 weak_ptr 的对象可能被释放的,因此不能直接访问对象,必须调用 lock()。lock() 检查 weak_ptr 所指的对象是否仍存在,如果存在,返回一个指向共享对象的 shared_ptr。
理解:返回的这个 shared_ptr 会使引用计数加 1。
w = p; // p 可以是一个 shared_ptr 或 weak_ptr。赋值后 w 与 p 共享对象。
w.reset(); // 将 w 置为空
w.use_count(); // 返回与 w 共享对象的 shared_ptr 的数量
w.expired(); // 若 w.use_count() 为 0,返回 true,否则返回 false。expired 是 “过期的” 意思
w.lock(); // 如果 w.expired 为 true,返回一个空 shared_ptr;否则返回一个指向 w 的对象的 shared_ptr
weak_ptr 操作的应用
if(shared_ptr np = wp.lock()) // 如果 np 不为空则条件成立
一个实例:StrBlobPtr类
StrBlobPtr 类起到一个充当 StrBlob 迭代器的作用,指向 StrBlob 管理的容器中的某个元素。
StrBlobPtr 构造函数接受的是 StrBlob 的非常量引用,因此无法使用 const StrBlob,如果想要使用,那需要再定一个 ConstStrBlobPtr 类。
class StrBlobPtr
{
public:
StrBlobPtr() : curr(0) {}
StrBlobPtr(StrBlob &a, size_t sz = 0) : wptr(a.data), curr(sz) {}
string &deref() const;
StrBlobPtr &incr();
bool operator!=(const StrBlobPtr &rhs) const { return this->curr != rhs.curr; }
private:
shared_ptr> check(std::size_t, const string &msg) const; //不能在 const 成员函数内调用本类的非 const 成员函数,调用的必须也是 const 成员函数
private:
weak_ptr> wptr;
size_t curr;
};
shared_ptr> StrBlobPtr::check(std::size_t sz, const string &msg) const{
auto ret = wptr.lock();
if (!ret) throw std::runtime_error("unbound StrBlobPtr"); //检查 wptr 是否绑定了一个 StrBlob
if (sz >= ret->size()) throw std::out_of_range("msg");
return ret;
}
string &StrBlobPtr::deref() const { //const 成员函数在定义时也要加上 const
auto p = check(curr, "dereference past end");
return (*p)[curr];
}
StrBlobPtr &StrBlobPtr::incr(){
check(curr, "increment past end of StrBlobPtr");
++curr;
return *this;
}
12.2 动态数组
new 和 delete 运算符一次分配/释放一个对象。
C++ 中提供了两种一次分配一个对象数组的方法:
- 使用如 new int[10] 来分配一个对象数组;
- 使用 allocator 类。allocator 类的优点是可以实现内存分配与对象构造的分离,更灵活地管理内存。
一般不需要使用动态分配的数组,而是使用如 vector 之类的 STL 容器。使用容器的类可以使用默认版本的拷贝、赋值、析构等操作,而分配动态数组的类必须定义自己版本的函数在相关操作时管理内存。
12.2.1 new和数组
使用方括号来分配一个对象数组,new 分配成功后返回指向第一个对象的指针。
方括号中的大小必须是整型,但不必是常量。
int *pia = new int[get_size()]; // pia 指向第一个 int
也可以使用一个表示数组类型的类型别名来分配一个数组。
typedef int arrT[42]; // arrT 表示 42 个 int 的数组类型。
int *p = new arrT; //分配一个包含 42 个 int 的数组;p 指向第一个 int
分配一个数组得到一个元素类型的指针
虽然常把 new T[] 分配的内存叫做动态数组,但是实际上它并不是一个数组,而只是返回第一个元素的指针。
理解:数组类型是包含其维度的,而 new 分配动态数组时提供的大小不必是常量,这正是因为它并非分配了一个“数组类型”。
因为动态数组不是数组类型所以不能对它调用 begin() 或 end() 函数(这两个函数根据数组维度返回指向首元素和尾后元素的指针),也不能使用范围 for 语句来处理动态数组。
初始化动态分配对象的数组
默认情况下 new 分配的对象不管是单个的还是动态数组,都是默认初始化的。
可以对动态数组进行值初始化和列表初始化
int *pia = new int[10]; // 10 个未初始化的 int
int *pia2 = new int[10](); // 10 个值初始化为 0 的 int
int *pia3 = new int[10]{0, 1, 2, 3, 4, 5}; // 前 5 个元素用给定的值初始化,剩余的进行值初始化
可以用空括号对数组中的元素进行值初始化,但不能在括号中给出初始化器,因此也不能使用 auto 分配数组。
因为值初始化时不能提供参数,所以没有默认构造函数的类是无法动态分配数组的。
动态分配一个空数组是合法的
虽然不能创建一个大小为 0 的数组对象,但当 n=0 时,调用 new int[n] 是合法的,它返回一个合法的非空指针。此指针保证与 new 返回的其他任何指针都不相同。
对零长度的数组来说,此指针就像尾后指针一样,不能解引用,但是可以用在循环的终止条件判断中。
释放动态数组
使用 delete [] 来释放动态数组
delete p; // p 必须指向一个动态分配的对象或为空
delete [] pa; // pa 必须指向一个动态分配的数组或为空
使用 delete [] 会将动态数组中的元素按逆序销毁并释放内存。
如果在 delete 一个指向动态数组的指针时忽略了方括号,行为是未定义的。
智能指针和动态数组-unique_ptr
标准库提供了一个可以管理 new 分配的数组的 unique_ptr 版本。这一版本的 unique_ptr 自动使用 delete[] 来释放数组。
unique_ptr up(new int[10]); // up 指向一个包含 10 个未初始化 int 的数组
for(size_t i=0; i!=10; ++i) up[i] = i; // 可以通过 up 使用下标运算符来访问数组中的元素
up.release(); // 自动使用 delete[] 销毁其指针
指向数组的 unique_ptr 不支持成员访问运算符(点和箭头),但支持通过下标访问数组中的元素。
unique_ptr u // u 可以指向一个动态分配的数组,数组元素类型为 T
unique_ptr u(p) // u 指向内置指针 p 所指向的动态分配的数组,p 必须能转换为类型 T*
u[i] // 返回 u 拥有的数组中位置 i 处的对象
智能指针和动态数组-shared_ptr
shared_ptr 不支持直接管理动态数组。如果希望使用 shared_ptr 管理动态数组,需要为它提供一个删除器。
shared_ptr sp(new int[10], [](int* p) { delete[] p; });
sp.reset(); //使用上面提供的 lambda 释放数组
如果不提供删除器,shared_ptr 将会使用 delete 来销毁动态数组,这种行为是未定义的。
shared_ptr 不直接支持动态数组管理,所以要访问数组中的元素需要使用 get()
for(size_t i = 0; i != 10; ++i)
*(sp.get() + i) = i; // 使用 get() 获取一个内置指针,然后来访问元素。
12.2.2 allocator类
new 有一个局限性是它将内存分配和对象构造结合在了一起,对应的 delete 将对象析构和内存释放结合在了一起。
标准库 allocator 类定义在头文件 memory 中,可以实现内存分配与对象构造的分离。
allocator 是一个类模板。定义时需指出这个 allocator 可以分配的对象类型,它会根据对象类型来分配恰当的内存。
allocator 的定义与操作
下面的 string 可以替换为其他类型。
allocator alloc; // 定义一个可以分配 string 的 allocator 对象
auto const p = alloc.allocate(n); // 分配 n 个未初始化的 string,返回一个 string* 指针
alloc.construct(p, args); // p 是一个 string* 指针,指向原始内存。arg 被传递给 string 的构造函数,用来在 p 指向的内存中构造对象。
alloc.destory(p); // p 是一个 string* 指针,此算法对 p 指向的对象执行析构函数
alloc.deallocate(p, n); // 释放从 p 开始的长度为 n 的内存。p 是一个 allocate() 返回的指针,n 是 p 创建时要求的大小。
// 在 deallocate 之前必须先 destory 掉这块内存中创建的每个对象。
理解:定义的 allocator 对象是一个工具,这个工具可以管理指定类型的内存分配、对象构造、对象销毁、内存释放四种操作,且这四种操作是分开的,分别对应一个函数。
allocator 分配未构造的内存
allocator 分配的内存是未构造的,需要使用 construct 成员函数按需在内存中构造对象。
construct 成员函数接受一个指针和零个或多个额外参数,在给定位置构造一个元素,额外参数用来初始化构造的对象。
alloc.construct(q++); // 在 q 指向的位置构造一个空字符串并递增 q。q 应该指向最后构造的元素之后的位置。
alloc.construct(q++, 5, 'c'); // 在 q 指向的位置构造一个 “ccccc” 并递增 q。
还未构造对象就使用原始内存的结果是未定义的,可能造成严重后果。
destory 销毁对象
使用完对象后,必须对每个构造的元素都调用 destory 来摧毁它们。
destory 接受一个指针,对指向的对象执行析构函数。注意只能对构造了的元素执行 destory 操作。
元素被销毁后可以重新在这块内存构造对象也可以释放掉内存。
construct 和 destory 一次都只能构造或销毁一个对象,要想完成对所有元素的操作,需要通过指针来遍历对每个元素进行操作。
deallocate 释放内存
传递给 deallocate 的 p 必须指向由 allocate 分配的内存,大小参数 n 必须与 allocate 分配内存时提供的大小参数一样。
alloc.deallocate(p, n);
拷贝和填充未初始化内存的算法
除了使用 construct 构造对象外,标准库还提供了两个伴随算法,定义在头文件 memory 中,他们在给定的位置创建元素。
uninitialized_copy(b, e, b2); // 从迭代器 b 和 e 指定的输入范围中拷贝元素到从迭代器 b2 开始的未构造的原始内存中。b2 指向的内存需要足够大。
uninitialized_copy_n(b, n, b2); // 从迭代器 b 指向的元素开始,拷贝 n 个元素到 b2 开始的内存中。
uninitialized_fill(b, e, t); // 在 b 和 e 指定的范围内创建对象,对象均为 t 的拷贝
uninitialized_fill_n(b, n, t); // 在从 b 开始的 n 个位置创建对象,对象均为 t 的拷贝。
uninitialized_copy 函数返回指向构造的最后一个元素之后位置的指针。
比如希望将一个 vector 拷贝到动态内存中,并对后一半空间用给定值填充。
allocator alloc;
auto p = alloc.allocate( v.size() * 2 );
auto q = uninitialized_copy( v.begin(), v.end(), p );
uninitialized_fill_n( q,v.size(),42);
问题
- 静态内存、栈、堆分别存放什么对象
- c++ 管理动态内存的工具有哪些
- shared_ptr 有哪些通用操作,有哪些独有操作
- 栈和堆有那些不同
- 定义 shared_ptr 的方式?哪种方式最安全?
- new 有哪些特点?
- 使用 new 时要注意什么?
- 内存耗尽时使用 new 会发生什么?
- delete 使用不当的情况有哪些?会有什么后果?
- 使用 delete 时建议怎么做?
回答
- 静态内存存放全局与局部 static 对象和类的 static 成员,栈存放局部非 static 对象,堆存放动态分配的对象。
- 有 new 和 delete 及两个智能指针:shared_ptr、unique_ptr、weak_ptr
- 通用操作:默认初始化,两种 swap**,get(),解引用**;独有操作:等号赋值,直接初始化,make_shared,unique(),use_count(),reset()
- 从控制权、存储内容、空间大小、分配效率、系统响应五个角度分析。
- 可以直接用构造函数定义或使用 make_shared 函数。make_shared 函数最安全。
- 需要使用 delete 手动释放内存,很危险。new 分配的对象没有名字,只有指向它的指针,因为它将内存分配和对象构造结合在一起了。如果不提供初始值,new 分配的对象会进行默认初始化。
- 在合适的地方 delete。采用值初始化,如 new int(),而不是默认初始化,如 new int。一般使用小括号就是直接初始化。
- 爆出异常 bad_alloc。
- 忘记 delete,会造成内存泄露。 delete 后继续使用该指针,结果未定义。delete 两次。
- delete 后将指针置为空指针,或在指针作用域的末尾 delete。因为 delete 后指针不会消失,还指向原地址。
问题
- 智能指针 get 函数的使用
- 几个智能指针陷阱
- unique_ptr 的特点。
- unique_ptr 的定义。
- unique_ptr 的操作。
- weak_ptr 的基本概念。
- allocator 类模板的作用和使用方法。
回答
- get 返回的是一个内置指针(即相当于 new 得到的指针)。一定不能通过 get 返回的指针来初始化另一个智能指针,因为这不是于拷贝,所以初始化的结果是产生另一个指向相同地址的独立的智能指针。
- 不要使用相同的内置指针初始化或 reset 多个智能指针。不要 delete get() 返回的指针或用 get() 初始化或 reset 另一个智能指针。如果智能指针管理的不是 new 分配的内存,要传递给它一个删除器。
- 同一时刻只有一个 unique_ptr 指向一个给定对象。当 unique_ptr 被销毁,指向的对象也会被销毁。
- 要使用一个 new 返回的指针来初始化 unique_ptr 对象。这点不同于 shared_ptr。
- get(),reset(), release()
- weak_ptr 指向由 shared_ptr 管理的对象,能提供一些辅助操作。
- allocator 可以将内存分配和对象构造分离开。使用 allocator 的过程包括:实例化一个 allocator 对象,分配内存,构造对象,销毁对象,释放内存。
第13章 拷贝控制
构造函数控制类的对象初始化时做什么,拷贝控制成员控制类的对象在拷贝、赋值、移动、销毁时做什么
类的拷贝控制成员包括 5 种成员函数:
- 拷贝构造函数:定义了当用同类型的对象初始化另一个对象时做什么
- 拷贝赋值运算符:定义了当将同类型的一个对象赋予另一个对象时做什么
- 移动构造函数:同拷贝构造函数
- 移动赋值运算符:同拷贝赋值运算符
- 析构函数:定义对象销毁时做什么
拷贝控制成员是类的必要部分,如果没有显式定义,编译器会自动为其隐式地定义。
**难点:**认识到什么时候需要定义这些操作
13.1 拷贝.赋值与销毁
13.1.1 拷贝构造函数
如果一个构造函数的第一个参数是自身类类型的引用,且其他参数都有默认值,则此构造函数为拷贝构造函数。
拷贝构造函数的第一个参数必须是引用,且一般是 const 引用。(如果不使用引用会导致无限循环,因为传递实参本身就是拷贝)
拷贝构造函数通常不是 explicit 的。
合成拷贝构造函数
如果没有为类显式定义拷贝构造函数,则编译器会定义一个合成拷贝构造函数。
一般合成拷贝构造函数会逐个拷贝类的每个成员。
对于某些类,合成拷贝构造函数用来禁止该类型对象的拷贝(通过 =delete)
直接初始化和拷贝初始化的区别
string s1(dots); // 直接初始化,选择匹配的构造函数来初始化 s
string s2 = dots; // 拷贝初始化,使用拷贝构造函数或移动构造函数来完成。
理解:显式调用构造函数的场合都是直接初始化,拷贝初始化发生于那些没有显式调用构造函数却生成了类的对象的场合,比如使用 = 初始化一个对象。
拷贝初始化发生的场合:
- 以 = 定义变量
- 将一个对象作为实参传递给非引用形参
- 从一个返回类型为非引用类型的函数返回一个对象
- 用花括号列表初始化一个数组中的元素或一个聚合类中的成员
- 某些类类型会为它们所分配的对象进行拷贝初始化。比如标准库容器初始化或调用 insert 和 push 成员时,会对其元素进行拷贝初始化(emplace 则是直接初始化)。
13.1.2 拷贝赋值运算符
如果类未定义自己的拷贝赋值运算符,编译器会自动合成一个。
重载赋值运算符
重载运算符本质上也是函数。重载赋值运算符必须定义为成员函数。如果一个运算符是成员函数,其左侧运算对象自动绑定到隐式的 this 参数。
拷贝赋值运算符接受一个与其所在类同类型的参数
class Foo{
public:
Foo& operator=(const Foo &); // 重载的赋值运算符通常返回一个指向其左侧运算对象的引用
}
重载的赋值运算符通常返回一个**指向其左侧运算对象(也就是自身)的引用,**赋值操作会在函数体内完成。
理解: while(a=2) 的含义:a=2 返回了 a 的引用,值为 2,条件为真.
合成拷贝赋值运算符
如果没有定义拷贝赋值运算符,编译器会生成一个合成拷贝赋值运算符。
对于某些类,合成拷贝赋值运算符用来禁止该类型对象的赋值(通过=delete)
合成拷贝运算符会将右侧运算对象的每个非 static 成员赋予左侧对象的相应成员,这一工作通过成员类型自己的拷贝赋值运算符来完成。
一个拷贝构造函数和拷贝赋值运算符的例子
这个例子很有代表性,要认真看。
class HasPtr {
public:
HasPtr(const std::string& s = std::string()) : ps(new std::string(s)), i(0) { }
HasPtr(const HasPtr& hp) : ps(new std::string(*hp.ps)), i(hp.i) { } //拷贝的是指针指向的对象
HasPtr& operator=(const HasPtr& rhs_hp) {
if(this != &rhs_hp) {
std::string *temp_ps = new std::string(*rhs_hp.ps); //先拷贝到一个临时指针中,但是指针分配的动态内存不是临时的。 delete ps; // delete 时不用加 *
ps = temp_ps; // 让 ps 指向分配的动态内存。
i = rhs_hp.i;
}
return *this;
}
~HasPtr() { delete ps; }
private:
std::string *ps;
int i;
}
13.1.3 析构函数
只要一个对象被销毁,就会执行其析构函数。
析构函数名字由波浪号接类名组成,没有返回值,也不接受参数。
因为析构不接受参数,所以不能被重载,一个类只能有一个析构函数。不同于构造函数。
构造函数和析构函数的区别:
- 构造函数包括一个初始化部分和一个函数体。先执行初始化部分再执行函数体。初始化顺序按它们在类中出现的顺序进行初始化。
- 析构函数包括一个函数体和一个隐式的析构部分。先执行函数体,然后执行析构部分销毁成员。成员按初始化的顺序逆序销毁。
销毁成员时发生什么依赖成员自己的类型。如果是类类型的成员,需要执行成员自己的析构函数。
注意析构函数体自身并不直接销毁成员,成员是在析构函数体之后的隐含的析构阶段中被销毁的。
销毁指针:
- 内置指针:隐式地销毁一个内置指针类型的成员不会 delete 它所指向的对象。
- 智能指针:智能指针是类类型,具有析构函数。智能指针的析构函数会递减对象的引用计数,如果计数变为 0,则销毁对象并释放内存。
合成析构函数
当未定义析构函数时,编译器会定义一个合成析构函数。合成析构函数的函数体是空的。
一个例子
如何定义一个类,这个类可以为每个对象生成一个唯一的序号?
方法:使用一个 static 成员,然后在构造函数中对它递增并基于递增后的 static 成员构造序号。
注意:要在所有的构造函数及拷贝赋值运算符中都对它进行递增(下面的例子中仅列出了默认构造函数)。
class numbered {
public:
numbered() { mysn = unique++; }
int mysn;
static int unique;
};
int numbered::unique = 10;
13.1.4 三/五法则
有三个操作可以控制类的拷贝操作:拷贝构造函数、拷贝赋值运算符、析构函数。
此外拷贝控制成员还有移动构造函数、移动赋值运算符。
这些操作通常应该被看做一个整体,如果定义了其中一个操作,一般也需要定义其他操作。
确定类是否需要自己的拷贝控制成员的两个基本原则:
- 判断它是否需要一个析构函数。如果它需要自定义一个析构函数,几乎可以肯定它也需要一个拷贝构造函数和一个拷贝复制运算符。
- 如果一个类需要一个拷贝构造函数,几乎可以肯定它也需要一个拷贝赋值运算符,反之亦然。但是需要拷贝构造函数不意味着一定需要析构函数。
需要析构函数的类也需要拷贝和赋值操作
当需要定义析构函数,一般意味着在类内有指向动态内存的指针成员。因为合成析构函数只会销毁指针成员而不会 delete,所以需要定义析构函数。
这种情况下,如果使用合成的拷贝和赋值操作,它们会直接复制该指针,这就导致可能有多个指针指向相同的一块动态内存,当有一个类对象执行了析构函数,该内存就会被释放,其他指针就变成了悬空指针。
所以需要定义拷贝和复制操作。
13.1.5 使用=default
类似默认构造函数,将拷贝控制成员定义为 =default 可以显式地要求编译器生成合成的版本。
Student(const Student&) = default; // 不用加函数体。在参数列表后加一个 =default 即可
如果在类内使用 =default,合成的函数将隐式地声明为内联函数。如果不希望合成内联函数,则应该在类外定义处使用 =default。
只能对默认构造函数或拷贝构造成员这些具有合成版本的函数使用 =default。
13.1.6 阻止拷贝
大多数类应该隐式地或显式地定义默认构造函数、拷贝构造函数和拷贝赋值运算符。
但是有一些例外需要阻止类进行拷贝或赋值。如 iostream 类、unique_ptr 等。
阻止拷贝的方式是****将其定义为删除的函数
删除的函数的性质:虽然声明了它们,但是不能以任何方式使用它们。
定义为删除的函数的方式:在参数列表后加 =delete;
Student(const Student&) = delete;//阻止拷贝
=delete 只能出现在函数第一次声明的时候,并且可以对任何函数指定 =delete,这两点不同于 default。
析构函数不能定义为删除的成员
如果析构函数被删除,就无法销毁此类型的对象了。
合成的拷贝控制成员可能是删除的
在以下情况,类的某些合成的成员会被定义为删除的函数:
- 如果类的某个数据成员的析构函数是删除的或不可访问的(如 private 的),则该类的合成析构函数、合成拷贝构造函数和默认构造函数被定义为删除的
- 如果类的某个数据成员的拷贝构造函数是删除的或不可访问的,则类的合成拷贝构造函数被定义为删除的。
- 如果类的某个数据成员的拷贝赋值运算符是删除的或不可访问的,则类的合成拷贝赋值运算符被定义为删除的。
- 如果类有一个 const 成员或引用成员,则类的合成拷贝赋值运算符被定义为删除的。理解:因为 const 成员不能修改值,所以不能为它赋值(但是拷贝构造函数在初始化时执行,是可以的)。
- 如果类有一个没有类内初始化器且未显式定义默认构造函数的 const 成员或没有类内初始化器的引用成员,则该类的默认构造函数被定义为删除的。
**这些规则的本质:**如果一个类有数据成员不能默认构造、拷贝、复制或销毁,则对应的成员函数被定义为删除的。
private拷贝控制
新标准之前,类是通过将其拷贝构造函数和拷贝赋值运算符声明为 private 来组织拷贝。
class PrivateCopy {
PrivateCopy(const PrivateCopy&); //拷贝控制成员是 private 的
PrivateCopy &operator=(const PrivateCopy&);
public:
PrivateCopy() = default;
~PrivateCopy();
}
将拷贝控制成员定义为 private 可以阻止普通用户拷贝对象,但是无法阻止友元和成员函数拷贝对象,为此还要注意:只能声明不能定义这些拷贝控制成员。
声明但不定义一个函数是合法的,试图访问一个未定义的成员将导致一个链接时错误。
理解:在此情况下,普通用户调用拷贝控制成员将引发编译时错误,友元和成员函数调用拷贝控制成员将引发链接时错误。
13.2 拷贝控制和资源管理
通常管理类外资源的类都需要定义拷贝控制成员,因为它们需要定义析构函数来释放对象所分配的资源。
通过定义不同的拷贝操作可以实现两种效果:
- 使类的行为看起来像一个值。这种情况拷贝类时副本和原对象是完全独立的。如 strnig 看起来像值
- 使类的行为看起来像一个指针。这种情况拷贝类时副本和原对象使用相同的底层数据。改变副本也会改变原对象。如 shared_ptr 看起来像指针。
还有一些其他的类,如 IO 类型和 unique_ptr 不允许拷贝和赋值,所以它们的行为既不像值也不像指针。
13.2.1 行为像值的类
行为像值的类中,对于类管理的资源,每个对于都应该有一份自己的拷贝。
要实现行为像值的类,需要定义一个拷贝构造函数、一个析构函数、一个拷贝赋值运算符。
赋值运算符通常组合析构函数和构造函数的操作,它会销毁左侧运算对象的资源并从右侧运算对象拷贝数据。
注意:这些操作要以正确的顺序执行,即使将一个对象赋予它自身,也保证正确。
当编写赋值运算符时,一般先将右侧运算对象拷贝到一个局部临时对象中,以保证将对象赋予自身也能正确工作。
例子
class HasPtr {
public:
HasPtr(const std::string& s = std::string()) : ps(new std::string(s)), i(0) {} // 构造函数
HasPtr(const HasPtr& p) : ps(new std::string(*p.ps)), i(p.i) {} // 拷贝构造函数
HasPtr& operator=(const HasPtr& rhs) { auto newp = new string(*rhs.ps); delete ps; ps = newp; i = rhs.i; return *this; } // 拷贝赋值运算符
~HasPtr() { delete ps; }
private:
std::string *ps; // 类管理的资源
int i;
}
例子中构造函数、拷贝构造函数、拷贝赋值运算符都生成了自己的资源。
13.2.2 定义行为像指针的类
对于行为类似指针的类,需要定义拷贝构造函数和拷贝赋值运算符来拷贝指针成员本身而不是它指向的值。还需要析构函数来释放分配的内存,但是注意不能简单地直接释放关联的内存,应确保最后一个指向该内存的指针也销毁掉后才释放内存。
令一个类行为像指针的最好方法是使用 shared_ptr 来管理类内的资源。
引用计数
有时希望直接管理资源而不用 shared_ptr,这时可以使用引用计数。
引用计数的工作方式:
-
除了初始化对象外,每个构造函数(拷贝构造函数除外)还要创建一个引用计数,用来记录有多少对象与正在创建的对象共享状态。
-
当创建一个对象时,计数器初始化为 1。
-
拷贝构造函数不创建新的引用计数,而是拷贝对象的计数器并递增它。
-
析构函数递减计数器,如果计数器变为 0,则析构函数释放状态。
-
拷贝赋值运算符递增右侧运算对象的计数器,递减左侧运算对象的计数器。如果左侧运算对象的计数器变为 0 就销毁状态。
计数器放在哪里?计数器应该保存在动态内存中,当拷贝或赋值对象时,拷贝指向计数器的指针。
例子
class HasPtr {
public:
HasPtr(const std::string& s = new std::string()): ps(new std::string(s)), i(0), use(new std::size_t(1)) {}
HasPtr(const HasPtr& p): ps(p.ps), i(p.i), use(p.use) { ++*use; }
HasPtr& operator=(const HasPtr& rhs) {
++*rhs.use; // 递增右侧运算对象的引用计数
if(--*use == 0) { // 递减本对象的引用计数
delete ps; // 如果没有其他用户,释放本对象的资源。
delete use;
}
ps = rhs.ps; // 将数据从 rhs 拷贝到本对象
i = rhs.i;
use = rhs.use;
return *this; // 返回本对象
}
~HasPtr() {
if(--*use == 0) {
delete ps;
delete use;
}
}
private:
std::string* ps;
int i;
std::size_t* use; // 引用计数器
};
13.3 交换操作
除了定义拷贝控制成员,管理资源的类通常还定义一个 swap 函数。
那些重排元素顺序的算法在重排元素时,需要使用 swap 来交换元素的位置。因此被重排的元素类型是类时,为类定义自己的 swap 函数非常重要。
如果一个类定义了自己的 swap,算法将使用自定义版本,否则算法将使用标准库定义的 swap。
编写自己的swap函数
swap 不是必要的,但是对于分配了资源的类,定义 swap 有时是一种很重要的优化手段。
class HasPtr {
friend void swap(HasPtr& HasPtr); // 其他成员定义与 13.2.1 中定义的 HasPtr 一样。
};
inline void swap(HasPtr& lhs, HasPtr& rhs) {
using std::swap;
// 使用此声明而非直接通过 std::swap 调用。因为这样的话,如果某个类成员定义了自己版本的 swap,对其进行 swap 时会优先使用自定义版本。 swap(lhs.ps, rhs.ps); // 交换指针,而不是 string 数据
swap(lhs.i, rhs, i);
}
swap 函数应该调用 swap,而不是 std::swap
swap 函数用来交换两个类的值,因此实现 swap 函数时要交换类的所有数据成员的值,这也通过 swap 来实现。
而类的成员可能是另一个类类型,这时为了保证调用的是该类自定义的 swap 版本,应该使用 swap,而不是 std::swap。
上例中的使用方式是正确的,即先 using std::swap,再直接调用 swap。using std::swap 并不会将自定义的 swap 隐藏掉。
理解:使用 using std::swap 的目的是保证当某个成员没有自定义的 swap 版本时,能够执行标准库版本。
在赋值运算符中使用swap
定义了 swap 的类通常用 swap 来定义赋值运算符,注意这时参数要使用值传递而非引用传递。
HasPtr& HasPtr::operator=(HasPtr rhs) // 参数不是引用而是值传递。 {
swap(*this, rhs); // 这种方法很自然地保证了自赋值情况是安全的。
return *this;
}
使用了值传递和 swap 的赋值运算符自动就是异常安全的,并且能够正确处理自赋值。
13.4 拷贝控制示例
需要自定义拷贝控制成员的类通常是分配了资源的类,但这不是唯一原因。一些类也需要拷贝控制成员来帮助进行薄记工作或其他操作。
理解:所谓薄记工作的应用场景是有两个或两个以上的类,且当创建、复制或销毁其中某个类的对象时,需要更新另一个类的对象的值。
本节是一个自定义拷贝控制成员来完成薄记工作的示例。
需求
需要 Message 和 Folder 两个类,分别表示消息和目录。
一个消息可能出现在多个目录中,一个目录可能包含多个消息。但是任何消息都只有一个副本。
Message类
void swap(Message &lhs, Message &rhs);
class Message {
friend class Folder;
friend void swap(Message &lhs, Message &rhs); // 要将 swap 定义为友元
public:
explicit Message(const std::string &str = "") : contents_(str) {}
Message(const Message &msg) : contents_(msg.contents_), folders_(msg.folders_) { add_to_Folders(msg); }
Message &operator=(const Message &rhs) {
remove_from_Folders();
contents_ = rhs.contents_;
folders_ = rhs.folders_;
add_to_Folders(*this);
return *this;
}
~Message() { remove_from_Folders(); }
void save(Folder &folder) {
folders_.insert(&folder);
folder.messages_.insert(this);
}
void remove(Folder &folder) {
folders_.erase(&folder);
folder.messages_.erase(this);
}
private:
std::string contents_;
std::set folders_;
void add_to_Folders(const Message &msg) {
for (auto folder : msg.folders_)
folder->addMsg(this);
}
void remove_from_Folders() {
for (auto folder : folders_)
folder->remMsg(this);
}
};
Message类的swap函数
void swap(Message &lhs, Message &rhs) {
using std::swap;
lhs.remove_from_Folders();
rhs.remove_from_Folders();
swap(lhs.folders_, rhs.folders_);
swap(lhs.contents_, rhs.contents_);
lhs.add_to_Folders(lhs);
rhs.add_to_Folders(rhs);
}
Folder类的定义
只有类的定义,函数的定义略。
class Folder {
friend void swap(Folder &, Folder &);
friend class Message;
public:
Folder() = default;
Folder(const Folder &);
Folder& operator=(const Folder &);
~Folder();
private:
std::set msgs;
void add_to_Message(const Folder&);
void remove_from_Message();
void addMsg(Message *m) { msgs.insert(m); }
void remMsg(Message *m) { msgs.erase(m); }
};
void swap(Folder &, Folder &);
13.5 动态内存管理类
某些类需要在运行时分配可变大小的内存空间,这种类一般可以使用标准库容器来保存它们的数据,但有时确实需要自己分配内存。
本节实现了一个需要自己分配内存以进行动态内存管理的类:StrVec。这个类是标准库 vector 的简化版本,且只用于 string。
理解:区分动态内存管理类与分配资源的类。动态内存管理类主要特点是其所占用内存大小是动态变化的,而分配资源的类其特点是使用了堆内存。
StrVec类的设计
StrVec 的内存管理模仿了 vector。
String 类的设计和实现
String 类是一个标准库 string 类的简化版本,它有一个默认构造函数和一个接受 C 风格字符串指针的构造函数。并使用 allocator 来分配内存。
String.h
#include
class String {
public:
String() : String("") {}
String(const char *);
String(const String &);
String &operator=(const String &);
~String();
const char *c_str() const { return elements; }
size_t size() const { return end - elements; }
size_t length() const { return end - elements - 1; }
private:
std::pair alloc_n_copy(const char *, const char *);
void range_initializer(const char *, const char *);
void free();
private:
char *elements; // elements 指向字符串的首部
char *end; // end 指向字符串的尾后
std::allocator alloc; // 定义了一个分配器成员 };
String.cpp
#include "String.h"
#include
#include
std::pair String::alloc_n_copy(const char *b, const char *e) {
auto str = alloc.allocate(e - b);
return{ str, std::uninitialized_copy(b, e, str) };
}
void String::range_initializer(const char *first, const char *last) {
auto newstr = alloc_n_copy(first, last);
elements = newstr.first;
end = newstr.second;
}
String::String(const char *s) {
char *sl = const_cast(s);
while (*sl)
++sl;
range_initializer(s, ++sl);
}
String::String(const String& rhs) {
range_initializer(rhs.elements, rhs.end);
std::cout << "copy constructor" << std::endl;
}
void String::free() {
if (elements) {
std::for_each(elements, end, [this](char &c){ alloc.destroy(&c); });
alloc.deallocate(elements, end - elements);
}
}
String::~String() {
free();
}
String& String::operator = (const String &rhs) {
auto newstr = alloc_n_copy(rhs.elements, rhs.end);
free();
elements = newstr.first;
end = newstr.second;
std::cout << "copy-assignment" << std::endl;
return *this;
}
13.6 对象移动
移动对象的能力是 C++11 中最主要的特性之一。
使用移动的两个常见原因:
- 有时对象拷贝后立即就被销毁了,这是使用移动而非拷贝可以提升性能。
- 如 IO 类或 unique_ptr 这样的类不能拷贝但可以移动。
C++11 之后,容器可以保存不可能拷贝的类型,只要该类型可以移动即可。
13.6.1 右值引用
右值引用是为了支持移动操作而引入的。
右值引用:必须绑定到右值的引用,通过 && 操作符来获得右值引用。
右值引用的性质:只能绑定到一个将要销毁的对象,且该对象没有其他用户。因此使用右值引用的代码可以自由接管所引用的对象的资源。
左值引用和右值引用
表达式可以分为左值和右值,一般一个左值表达式表示的是一个对象的身份,一个右值表达式表示的对象的值。
左值有持久的状态,而右值要么是字面常量,要么是表达式求值过程中创建的临时对象。
对应地,左值引用不能绑定到要求转换的表达式、字面常量或返回右值的表达式,而右值引用可以绑定到这些对象,不能直接绑定到一个左值上。
注意:const 的左值引用也可以绑定到右值上。
int i = 42; // i 是一个左值
int&& r = i; // 错误,不能将右值引用绑定到左值上
int &r2 = i * 2; // 错误,i * 2 是一个右值,不能将左值引用绑定到一个右值上。
const int& r3 = i * 2; // 正确,可以将一个 const 引用绑定到一个右值上
int&& r4 = i * 2; // 正确
函数返回的左/值
返回左值的运算符:复制、下标、解引用、前置递增/递减运算符等都返回左值引用。
返回右值的运算符:算术、关系、位、后置递增/递减运算符等都返回右值。
返回非引用类型的函数返回的也是右值。
变量是左值
变量也可以看作是一个表达式,一个变量表达式是一个左值。
即使一个变量的类型是一个右值引用,但该变量本身也是一个左值。因此不能将一个右值引用直接绑定到一个右值引用变量上。
int&& rr1 = 42; // 正确
int&& rr2 = rr1; // 错误,表达式 rr1 是左值。
标准库move函数
不能直接将一个右值引用绑定到左值上,但可以通过标准库 move 函数来实现。
int&& rr3 = std::move(rr1); // 正确
move 函数告诉编译器:希望向一个右值一样处理一个左值。
调用 move 之后,不能对移后源对象的值做任何假设。
使用 std::move 函数的程序员要保证:对一个左值调用 move 后,不再使用该左值的值,除非销毁它或对它重新赋值。
注意:使用 move 函数的代码应该是 std::move 而非直接用 move,这可以避免名字冲突。
几个左值/右值引用的实例
int f();
vector vi(100);
int&& r1 = f();
int& r2 = vi[0];
int& r3 = r1;
int&& r4 = vi[0] * f();
13.6.2 移动构造函数和移动赋值运算符
要让自定义类支持移动操作,需要定义移动构造函数和移动赋值运算符。
移动构造函数的第一个参数是该类类型的右值引用,任何额外的参数都必须有默认实参。
移动构造函数要确保移后源对象是可以直接销毁的。特别是:一旦完成资源的移动,源对象必须不再指向被移动的资源。
13.6.3 右值引用和成员函数
问题
- 拷贝控制成员有哪些?它们控制了对象的哪些操作?
- 如果没有显式定义,编译器会隐式合成类的哪些成员?
- 什么样的构造函数是拷贝构造函数?
- 直接初始化和拷贝初始化的区别
- 拷贝初始化发生的场合有哪些
- 如何理解重载运算符?
- 重载赋值运算符如何定义?它的返回值是什么?
- 确定类是否需要定义自己的拷贝控制成员的两个原则
- 如何显式地要求编译器生成合成的拷贝构造函数。
- 阻止拷贝用于什么情况?如何阻止拷贝?
- =delete 有什么作用
- 知识点:如果类中有 const 成员或引用成员,则类的合成拷贝运算符被定义为删除的。
回答
- 拷贝控制成员有拷贝构造函数、拷贝赋值运算符、移动构造函数、移动赋值运算符、析构函数。它们控制了对象拷贝、赋值、移动、销毁时的操作。
- 所有的拷贝控制成员对类来说都是必要的,如果没有显式定义,编译器都会合成。
- 只接受一个自身类类型的引用作为参数,或第一个参数是自身类类型的引用(一般是 const 引用),其他参数都有默认实参的构造函数是拷贝构造函数。
- 显式调用各版本的构造函数就是直接初始化,拷贝初始化发生于未显式调用构造函数但是却生成了类的对象的场合,比如函数返回值等场合。
- 采用 = 号来初始化一个对象、作为函数返回值、作为函数值传递的实参等。
- 重载运算符本质上也是一个函数。
- 重载赋值运算符是类的成员,接受类自身的 this 指针作为隐式参数。定义时重载赋值运算符接受一个同类型的对象的 const 引用作为参数,同时返回自身的引用。
- 如果类需要自定义一个析构函数,那几乎可以肯定也需要自定义拷贝构造函数和拷贝赋值运算符;如果类需要拷贝构造函数,几乎可以肯定也需要拷贝赋值运算符;
- student(const Student&) = default;
- 如 iostream, unique_ptr 等类需要阻止拷贝,通过将拷贝构造函数和拷贝复制运算符定义为删除的函数可以阻止拷贝。
- =delete 将函数定义为了删除的函数:不能以任何方式使用删除的函数。
- 知识点:如果类中有 const 成员或引用成员,则类的合成拷贝运算符被定义为删除的。
第14章 操作重载与类型转换
14.1 基本概念
重载的运算符是有特殊名字的函数:名字由关键字 operator 和要定义的运算符号组成。
重载的运算符作为函数,也包含返回类型、参数列表和函数体。
重载运算符的参数数量和该运算符作用的运算对象数量一样多。
重载的运算符必须是某个类的成员或至少拥有一个类类型的运算对象。
除了重载的函数调用运算符 operator() 之外,其他重载运算符不能含有默认实参。
如果运算符函数是类的成员函数,它第一个(左侧)运算对象绑定到隐式的 this 指针上,因此定义成员运算符函数时的参数数量比运算符的运算对象少一个。
调用重载运算符的两种方式:
- 直接使用运算符。如 data1+data2;data1+=data2。+ 是非成员函数,+= 是类的成员函数,两种都可以直接使用。
- 向调用普通函数一样调用运算符函数。如 operator+(data1,data2);data1.operator+=(data2)。
注意运算符函数的函数名是 operator 加运算符本身。
重载运算符的几个规则:
- 通常,不应该重载逗号,取地址,逻辑与和逻辑或运算符。
- 重载的运算符应该使用和内置类型一样的含义。
- 如果定义了 ==,一般也应该定义 !=。
- 如果定义了 <,也应该有其他关系操作。
- 如果定义了算术运算符或位运算符,也应该有对应的复合赋值运算符,如有 +,也应该有 +=。
- 重载运算符的返回类型应该与内置类型的返回类型兼容。如逻辑和关系运算符返回 bool,赋值和复合赋值运算符返回左侧运算对象的一个引用。
- 当运算符定义为成员函数,它的左侧运算对象必须是所属类的一个对象。
运算符应该是成员还是非成员:
- 赋值、下标([ ])、调用(( ))、成员访问箭头(->)运算符都必须是成员。
- 复合赋值运算符一般应该是成员,但非必须。
- 递增、递减和解引用等运算符应该是成员。
- IO 运算符应该是非成员,但是应该声明为类的友元。
- 具有对称性的运算符可能转换任意一端的运算对象,如算术、相等性、关系和位运算符等,应该是非成员。
14.2 输入和输出运算符
14.2.1 重载输出运算符<<
通常输出运算符的第一个形参是一个非常量 ostream 对象的引用(因为 IO 类型不能拷贝,所以必须是引用,因为要通过向流写入来输出,这会改变流的状态,所以必须是非常量),第二个形参一般是常量引用(为了避免复制实参,所以应为引用)。重载的 << 应该返回它的 ostream 形参。
定义方式
ostream& operator<<(ostream& os, const Student& stu){}
重载输出运算符应该尽量减少格式化操作,只负责打印什么内容,而不控制格式。(不应该打印换行符)。
IO 运算符应该是非成员,但是应该声明为类的友元。
14.2.2 重载输入运算符>>
通常输入运算符的第一个形参是一个非常量 istream 对象的引用,第二个形参是要读入的非常量对象的引用。返回 istream 对象的引用。
定义方式
istream& operator>>(istream& is,Student& stu){}
输入运算符需要检查是否输入成功
输入运算符必须检查是否输入成功,并处理输入失败的情况,而输出运算符不需要。
如果读取失败,输入运算符应该负责从错误中恢复,主要是将输入对象重置为合法状态,一般为未输入前的状态。
输入时的错误
- 当流中含有错误的数据时可能会读取失败
- 当读取操作到达文件末尾时会失败
- 遇到输入流的其他错误时也会失败
14.3 算术和关系运算符
算术和关系运算符通常定义为非成员函数以允许对左侧或右侧的运算对象进行转换。
算术和关系运算符的形参都应该是常量引用。
14.3.0 算术运算符
一般定义了算术运算符,也应该定义一个对应的复合赋值运算符。一般都是先定义复合赋值运算符,而后使用复合赋值来实现算术运算符(复合赋值运算符一般为成员,而算术为非成员)。
实现方式
一般将算术运算得到的值存放在局部变量中,操作完后返回该变量的副本。
14.3.1 相等运算符
相等运算符用来比较两个对象是否相等。
使用规则
- 通常会比较对象的每一个数据成员,所有对应成员都相等时两个对象才相等。
- 定义了 ==,也应该定义 !=。一般通过 == 来实现 !=。
- 通常相等运算符应该具有传递性。
14.3.2 关系运算符
定义了 == 的类,经常也会包含关系运算符,尤其是 <,因为关联容器和一些算法都要用到 <。
对于有些类来说,有 == 和 !=,但是很难有相应的 <。
使用规则
- 关系运算符一般应该定义顺序关系,令其与关联容器中对关键字的要求一致。
- 如果同时定义了 == 和 !=,则关系运算符应该与其保持一致,比如如果两个对象是 != 的,那么一个对象应该 < 另一个。
14.4 赋值运算符
赋值运算符必须定义为类的成员函数。
赋值运算符应该返回左侧运算对象的引用。
类中一般已经定义了拷贝赋值和移动赋值运算符。如果需要时也可以继续重载赋值运算符以使用别的类型作为右侧运算对象。
vector v = {"a","an","the"};
如上 vector 可以用花括号元素列表做参数。
赋值运算符必须先释放当前的内存空间,再重新分配。
复合赋值运算符
复合赋值运算符不必须是成员,但是一般也应该是成员。其左侧运算对象绑定到隐式的 this 指针。
复合赋值运算符也返回左侧运算对象的引用。
14.5 下标运算符
表示容器的类可以通过元素在容器中的位置来访问元素,这些类一般会定义下标运算符 operator[ ]。
下标运算符必须是成员函数。
下标运算符通常以所访问元素的引用作为返回值,这样下标可以出现在赋值运算符的任意一端。
下标运算符最好同时定义两个版本:
- 非常量版本:返回普通引用。
- 常量版本:是类的常量成员并返回常量引用。常量版本取得的元素不能放在赋值运算符的左侧。
14.6 递增和递减运算符
递增和递减运算符通常定义为成员,但不必须。
递增和递减运算符应该同时定义前置和后置版本。且前置版本返回递增或递减后的引用,后置版本返回修改前的副本。
如果是用于迭代器的递增递减运算符,应该检查递增递减是否合法,如 0 不能递减。
区分前置和后置
为了区分,可以使后置版本接受一个额外的不被使用的 int 类型的形参,当使用后置版本时,编译器为这个形参提供一个值为 0 的实参。
这个形参的唯一作用就是区分前置和后置。因为不会用到,所以该形参无需命名。
后置版本可以通过调用前置版本来实现。
Student& operator++();//前置版本
Student& operator++(int);//后置版本
14.7 成员访问运算符
箭头运算符必须是类的成员,箭头运算符一般通过调用解引用运算符来实现。
解引用运算符通常也是类的成员,但不必须。
14.8 函数调用运算符
如果类重载了函数调用运算符,就可以像使用函数一样使用该类的对象 (被称为函数对象)。
函数调用运算符必须是成员函数,一个类可以定义多个版本的调用运算符。不同版本的参数应有所区别。
理解:当重载了函数调用运算符,类对象的名字就相当于函数名。
class AbsInt{
int operator()(int val) const{ //该函数调用运算符返回一个整数的绝对值
return val<0 ? -val : val;
}
};
'应用' AbsInt absObj; //定义了一个对象
int ui = absObj(-10); //使用重载的函数调用运算符
含有状态的函数对象类
函数对象类通常会有一些数据成员,这些数据成员帮助实现函数。
函数对象常作为泛型算法的实参。
class PrintString{
public:
PrintString(ostream &_os = cout, char _sep = ' ') : os(_os), sep(_sep) {}
void operator()(const string &s) const { os<14.8.1 lambda是函数对象
编译器会将 lambda 翻译成一个未命名类的未命名对象,在 lambda 表达式产生的类中含有一个重载的函数调用运算符。
默认情况下 lambda 不能修改它的捕获变量(上层函数的局部非 static 变量),lambda 产生的类中的函数调用运算符是一个 const 成员函数。
当 lambda 被声明为可变的时,调用运算符就不是 const 的了。
'lambda表达式'
[](const string &a,const string &b){
return a.size() < b.size();
}
'上面的lambda表达式类似这个类的未命名对象'
class ShorterString{
public:
bool operator()(const string &s1, const string &s2) const {
return s1.size() < s2.size();
}
};
lambda 的不同捕获行为
当 lambda 通过引用捕获变量时,由程序确保 lambda 执行时所引用的对象确实存在。
当 lambda 通过值捕获变量时,捕获的变量被拷贝到 lambda 中,此时产生的类中会建立对应的数据成员并创建构造函数来初始化数据成员。
14.8.2 标准库定义的函数对象
标准库定义了一组表示算数运算符、关系运算符和逻辑运算符的模板类,每个类分别定义了一个执行命名操作的调用运算符。
例如 plus 可以用来执行 int 类型运算对像的加法
plus intAdd; //实例化了一个可执行 int 加法的函数对象
int sum = intAdd(10, 20); //调用 intAdd 来执行 int 加法
标准库函数对象
'算术' '关系' '逻辑'
plus equal_to logical_and
minus not_equal_to logical_or
multiplies greater logical_and
divides greater_equal
modulus '求余' less
negate '相反数' less_equal
在算法中使用标准库函数对象
表示运算符的函数对象类常用来替换算法中的默认运算符。
sort(svec.begin(), vec.end(), greater());//使用 greater 对 svec 进行降序排列
标准库规定的函数对象对于指针也是适用的,比如可以使用 less 来比较两个指针的大小(比较的是指针变量中的地址大小)
因为关联容器使用 less 来对元素排序,如果将指针作为 set 或 map 的关键字,元素将自动按地址进行排序。
注意函数对象其实是一个函数对象类。
14.8.3 可调用对象与function
C++ 中的几种可调用的对象:函数、函数指针、lambda表达式、bind创建的对象、重载了调用运算符的类。
**理解:****可调用的对象和其他对象一样,也有自己的类型。**如函数的类型是由返回值类型和实参类型决定的。
不同类型可能具有相同的调用形式
调用形式指明了调用返回的类型和传递给调用的实参类型。
int(int, int) //这是一个函数类型,它接受两个 int,返回一个 int
下面这三个可调用对象具有相同的调用形式 int(int,int),但是他们三个不是同一类型
int add(int i, int j) {
return i + j;
}
//普通函数
auto mod = [](int i, int j) {
return i % j
}; //lambda 产生一个未命名的函数对象类,mod 是这个类的一个实例
struct divide{
//一个函数对象类
int operator()(int i, int j) {
return i / j;
}
};
标准库 function 类型
function 定义在 functional 头文件中。function 是一个模板,创建具体的 function 类型时要指明具体的调用形式。
funcion 操作
function f;//定义了一个用来存储可调用对象的空 function,调用对象的调用形式应该和 retType(args) 相同
function f(nullptr);//显式地构造一个空 function
function f(obj);//在 f 中存储可调用对象 obj 的副本
f //可以将 f 作为条件,如果 f 为空则为假,不为空则为真
f(args) //通过 f 调用 f 中的对象
funciton 中定义的类型
result_type //该 funciton 类型的可调用对象返回的类型
retType argument_type //retType(args) 中的参数类型
first_argument_type //retType(args) 中第一个参数的类型
second_argument_type //retType(args) 中第二个参数的类型
使用 function
function f1 = add; //add 是个函数指针
funciton f2 = divide(); //divide() 返回一个函数对象的对象。
function f3 = mod; //mod 是个命名了的 lambda 对象
不能直接将重载函数的名字存入 function 类型的对象中,但是可以存储指向确定重载版本的函数指针。
使用 map 定义一个函数表
map binops;//这种方式只能存储函数和函数指针,不能存储函数对象类和 lambda 表达式
binops.insert("+",add);//正确
map> binops = { //可以存储相同调用形式的各种可调用对象
{"-", std::minus()}, //标准库函数对象
{"/", divide()}, //用户定义的函数对象
{"%", mod} //命名了的 lambda 对象
}
14.9 重载、类型转换与运算符
转换构造函数和类型转换运算符共同定义了类类型转换,这是用户定义的类型转换。
构造函数会实现从其他类型向类类型的转换,类型转换运算符实现从类类型向其他类型的转换。
只接受一个单独实参的非显式(即非 explicit 的)构造函数定义了从实参类型向类类型的类型转换。
14.9.1 类型转换运算符
类型转换运算符是类的一种特殊成员函数,用来将一个类类型的值转换成其他类型。可以转换成除了 void 外任意可以作为函数返回值的类型,包括引用、指针。
类型转换函数的一般形式:operator type() const;
类型转换函数必须是类的成员函数,不能声明返回类型,形参列表也必须为空,且函数一般是 const 的。虽然不指定返回类型,但是函数会返回一个对应类型的值。
理解:函数名实际上就是返回类型
class SmallInt {
public:
SmallInt(int i=0): val(i) {}
operator int() const { return val}; //类型转换函数
private:
int val;
}
类型转换函数的使用
类型转换运算符不需要显式调用,在执行运算时会隐式的执行。
SmallInt si;
si = 4; //将 4 隐式地转换为 SmallInt,然后调用 SmallInt::operator
si + 3; //将 si 隐式地转换为 int,然后执行整数的加法
如果类类型和转换类型间没有明显的映射关系,不要用类型转换运算符。但是向 bool 的类型转换比较常见。
显式的类型转换运算符
使用显式的类型转换运算符来避免在不合适的场合发生转换。
用关键字 explicit 来将运算符指定为显式的,调用时需使用 static_cast 来显式转换。
**例外:如果表达式被用作条件,则显式的类型转换会被隐式地执行。**如用在 if 语句的条件部分。
向 bool 类型的转换一般都用于条件部分,因此 operator bool() 一般定义成 explicit 的。
class SmallInt {
public:
explicit operator int() const { return val; } // 类的其他部分省略。
}
SmallInt si = 4; //正确:构造函数不是显式的
si + 3; //错误:类的运算符是显式的
static_cast(si) + 3; //正确:显式地请求类型转换
14.9.2 避免有二义性的类型转换
要确保在类类型和目标类型之间只存在唯一的转换方式。
有两种情况可能产生多重转换路径:
- 两个类提供相同的类型转换。A 类定义了一个接受 B 类对象的转换构造函数,同时 B 类定义了一个转换目标是 A 类的类型转换运算符。
- 定义了多个转换规则。
设计重载运算符和类型转换函数时要加倍小心,避免产生二义性。建议:
- 不要令两个类执行相同的类型转换
- 避免转换目标是内置算数类型的类型转换。特别是已经定义了一个转换成算数类型的类型转换时。
当有重载函数时,定义类型转换运算符尤其容易发生错误。
14.9.3 函数匹配与重载运算符
重载的运算符也是重载的函数,因此也使用函数匹配规则。
使用重载运算符作用域类类型的运算对象时,候选函数集中包含该运算符的普通非成员版本和类的成员函数版本。
问题
- 调用重载运算符有哪两种方式
- 重载运算符可以有默认实参吗
- 如果重载运算符函数是类的成员函数,它有什么特殊的地方?有什么特殊要求?
- 什么运算符定义成类的成员?什么定义成非成员?
- 如何定义重载输出运算符
- 如何定义重载输入运算符
- 重载相等运算符要注意的地方
- 重载赋值运算符要注意的地方
- 重载算术运算符要注意的地方
- 重载关系运算符要注意的地方
答案
- 直接使用运算符和像调用普通函数一样调用运算符函数
- 函数调用运算符 operator() 可以有,其他不能有
- 第一个运算对象绑定到隐式的 this 指针上,因此参数数量少一个。第一个运算对象必须是所属类的对象
- 左右运算对象相对称的运算符和输入输出运算符应该定义成非成员,其他定义成成员。
- 第一个参数应该是一个输出流的非常量引用,返回值也是输出流的非常量引用。第二个参数是常量引用
- 第一个参数和返回值都应该是输入流的非常量引用。第二个参数也是非常量引用(要输入给它)。输入运算符必须检查是否输入成功,并能处理错误。
- 重载了相等也应该重载不等。相等应该有传递性
- 赋值运算符必须是成员。可以重载多种具有不同参数的版本。赋值时应该先释放原本的空间,再重新分配。
- 算术运算符应该是非成员,算术赋值运算符应该是成员,两个应该同时定义。
- 关系运算符应该定义成非成员。
问题
- 重载下标运算符要注意的地方
- 重载递增递减运算符要注意的地方
- 重载成员访问运算符要注意的地方
- 重载函数调用运算符要注意的地方
- lambda的实现原理。
- 标准库定义的函数对象如何使用?
- 什么是函数的调用形式
- function 用来做什么
- function 的使用方式
- 用户可以定义两种类型转换,是什么?
- 类型转换运算符是什么?如何定义?
- 如何使用类型转换运算符
- explicit 的类型转换运算符有什么性质?
- explicit 地类型转换运算符有什么用处?
答案
- 应该定义两个版本:一个常量版本,一个非常量版本
- 应该同时定义前置和后置。前置返回引用,后置返回修改前的副本,一般使用前置版本来实现后置版本。通过给后置版本增加一个不命名的int形参来区分前置和后置
- 使用重载的解引用运算符来实现箭头运算符
- 重载函数调用运算符的类使用时像函数一样。常用于泛型算法的实参。
- 编译器会将lambda翻译成一个未命名类的未命名对象,该对象重载了函数调用运算符。就是lambda本质上是通过重载了函数调用运算符的类来实现的。
- 标准库定义的函数对象是一组模板类,用这些模板类生成的对象是函数对象,可以像使用函数对象一样使用它们。如 plus p; int sum = p(5,1); 标准库函数对象常用来做泛型算法的实参。
- 类似 int(int, int) 这样的叫做调用形式。
- function 类似一个函数指针,但是函数指针只能指向函数,而不能指向 lambda 表达式、函数对象等。而 function 都可以管理。
- function f(add);
- 用转换构造函数定义从其他类型向类类型的转换,用类型转换运算符定义从类类型向其他类型的转换。
- 是一种特殊的成员函数,定义方式如 operato int() const { return val }。该函数没有返回类型但是有 return 语句,形参列表为空,函数名就是要转换的类型,函数一般是 const 的。
- 定义了类型转化运算符的类,使用时会进行隐式转换。也可以使用 static_cast(obj) 来显式地进行转换。
- 不能进行隐式转换,而只能使用 static_cast 来显式地转换。但是有一个例外:作为条件时依然可以隐式转换为 bool 值。
- 对于一些要用作条件的类,使用它可以避免意外的类型转换。比如 iosream 对象可以转换为 bool 值,但是不希望在其他场合发生类型转换,就定义为 explicit 的。
第15章 面向对象程序设计
面向对象程序设计的核心思想:数据抽象、继承、动态绑定。
继承和动态绑定的影响:
- 可以更容易定义与其他类相似但不完全相同的新类。
- 使用彼此相似的类编写程序时,可以在一定程度上忽略掉他们的差别。
15.1 OOP:概述
继承
基类位于层次关系的根部,其他类直接或间接地从基类继承而来,继承得到的类称为派生类。
基类负责定义所有类共有的成员,派生类定义各自特有的成员。
对于某些成员函数,基类希望它的派生类各自定义适合自身的版本,此时就将这些函数声明为虚函数。
派生类通过类派生列表来指出它从哪个或哪些基类继承而来。
类派生列表:首先是一个冒号,然后是以逗号分隔的基类列表,每个基类前面可以有访问说明符。
class Undergraduate : public Student {};
派生类必须在内部对所有重新定义的虚函数进行声明,声明时可以在前面加上 virtual,也可以不加。
C++11 允许使用 override 关键字显式地指明重新定义的虚函数,把 override 放到形参列表后面。
动态绑定
当使用基类的引用或指针来调用一个虚函数时将发生动态绑定。
动态绑定根据传入的参数类型来选择函数版本(可能是基类中的该函数或派生类中的该函数),它发生在运行时,又称运行时绑定。
15.2 定义基类和派生类
15.2.1 定义基类
成员函数与继承
基类通常都应该定义一个虚析构函数,即使该函数不执行任何操作也是如此。
基类通过虚函数区分两种成员函数:
- 基类希望派生类进行覆盖的函数,将其定义为虚函数。构造函数与静态函数都不能定义成虚函数。任何构造函数之外的非静态函数都可以定义为虚函数。
- 基类希望派生类直接继承不要改变的函数。
使用指针或引用调用虚函数时,该调用将被动态绑定。
如果基类把一个函数声明为虚函数,该函数在派生类中隐式地也是虚函数。
虚函数的解析过程发生在运行时,普通函数的解析过程发生在编译时。
访问控制与继承
派生类可以继承定义在基类中的成员,但是派生类的成员函数不一定有权访问从基类继承而来的成员。
派生类能访问基类的公有成员和受保护成员,不能访问私有成员。
15.2.2 定义派生类
派生类通过类派生列表来指出它从哪个或哪些基类继承而来。
**类派生列表:**首先是一个冒号,然后是以逗号分隔的基类列表,每个基类前面可以有访问说明符。
访问说明符包括:public, protected, private。
派生类中的虚函数
派生类经常覆盖它继承的虚函数。如果没有覆盖,派生类会直接继承其在基类中的版本。
C++11 允许使用 override 关键字显式地指明重新定义的虚函数,把 override 放到形参列表后面、或 const 成员函数的 const 关键字后面、或引用成员函数的引用限定符后面。
派生类对象及派生类向基类的类型转换
一个派生类对象有多个组成部分:一个含有派生类自己定义的成员的子对象,一个与该派生类继承的基类对应的子对象。
因为派生类对象中含有与基类对应的组成部分,所以可以把派生类的对象当成基类对象来使用,也能把基类的指针或引用绑定到派生类对象中的基类部分上。
Undergraduate gra;
Student *stu = &gra;
派生类构造函数
派生类不能直接初始化从基类继承来的成员,而是使用基类的构造函数来初始化它的基类部分。
每个类控制自己的成员初始化过程。派生类构造函数通过构造函数初始化列表将实参传递给基类构造函数。
Undergraguate(int age,int sex,string _major):( Student(age,sex),major(_major) ) {}
默认情况下,派生类对象的基类部分会像数据成员一样默认初始化。如果要使用其他的基类构造函数,需要以类名加圆括号内的实参列表的形式为构造函数提供初始值。
首先初始化基类的部分,然后按照声明的顺序依次初始化派生类的成员。
注意:每个类负责定义各自的接口,要想与类的对象交互必须使用该类的接口,即使这个对象是派生类的基类部分也是如此。因此派生类对象不能直接初始化基类的成员。
继承与静态成员
基类的静态成员只存在唯一一个实例,不论有多少派生类。
如果静态成员是可访问的,派生类也能使用它
派生类的声明
派生类的声明不包含派生列表(定义包含)。
被用作基类的类
必须完整定义某个类后,该类才能作为基类被其他类继承。只声明是不够的。
继承可以多重继承,最终的派生类将包含它的直接基类的子对象和每一个间接基类的子对象。
防止继承的发生
如果定义了一个类并不希望它被其他类继承,可以在类名后跟一个关键字 final
class Student final {};//类 Student 是不能被继承的
15.2.3 类型转换与继承
注意:理解基类和派生类之间的类型转换是理解 C++ 面向对象编程的关键所在。
可以将基类的指针或引用绑定到派生类对象上有一层重要含义:当使用基类的引用或指针时,实际上我们并不清楚它所绑定对象的真实类型,可能是基类对象也可能是派生类对象。
智能指针类也支持派生类向基类的转换。
派生类向基类的类型转换也可能因为访问受限而不可行。
静态类型与动态类型
基类的指针或引用的静态类型和动态类型可能不一致。区分静态类型与动态类型:
Undergraduate gra;
Student* stu = &gra;
stu 的静态类型是 Student*,这在编译时就是已知的,但是动态类型到运行时才知道,这里 stu 的静态类型和动态类型是不一致的。
不存在从基类向派生类的隐式类型转换
派生类可以向基类转换是因为派生类对象中包含基类部分,而基类的引用或指针可以绑定到该基类部分上,反过来是不行的。
Student& stu = gra;
Undergraduate gra2 = stu;//错误
在对象之间不存在类型转换
派生类向基类的转换只对指针或引用类型有效。
当初始化或赋值一个类类型的对象时,实际是调用构造函数或赋值运算符。他们通常包含一个参数:该参数类型是类类型的 const 引用。此时是可以将派生类对象赋值给基类对象的,实际运行的是以引用作为参数的赋值运算符。
Student{
Student(const Student& stu) {
name = stu.name;
age = stu.age;
}
operator=(const Student& stu) {
name = stu.name;
age = stu.age;
}
}
Undergraduate gra;
Student stu1(gra);//正确
Student stu2 = gra;//正确
当用一个派生类对象为一个基类对象初始化或赋值时,只有该派生类对象中的基类部分会被拷贝、移动或赋值,其他部分会被忽略掉。
15.3 虚函数
虚函数必须提供定义,即使没有被用到。因为编译器不知道哪个虚函数在运行时会被使用到。
只有当通过指针或引用调用虚函数时才会发生动态绑定,正常调用虚函数时不会发生动态绑定。
派生类中的虚函数
当在派生类中覆盖了某个虚函数时,可以用 virtual 指明也可以不用。虚函数在所有的派生类中都是虚函数。
如果派生类的函数覆盖了继承而来的虚函数,它的形参类型必须与被覆盖的基类函数完全一致。返回类型也必须相匹配。
final 和 override 说明符
如果派生类定义了一个函数与基类中虚函数名字相同但形参列表不同是合法的,不会报错。编译器会认为这个新定义的函数与基类中原有的函数时相互独立的。
C++11 中可以使用 override 来指明派生类中的虚函数。这时如果该函数没有覆盖基类中的虚函数,编译器就会报错。
可以把某个函数指定为 final,这样该函数就不能被派生类所覆盖
final 和 override 都写到形参列表和尾置返回类型之后。
虚函数与默认实参
虚函数也可以有默认实参,实参值由调用的静态类型决定。即如果通过基类的指针或引用调用虚函数,则使用基类中定义的默认实参。
如果虚函数使用默认实参,则基类和派生类中定义的默认实参最好一致。
回避虚函数的机制
有时希望对虚函数的调用不进行动态绑定,而是强迫执行虚函数的某个特定版本,可以通过作用域运算符来实现。
double price = baseP->Quote::net_price(42);//net_price 是虚函数,这里指定调用基类 Quote 的虚函数版本。
通常只有在成员函数或友元中的代码才需要使用作用域运算符来回避虚函数的机制。或者当一个派生类的虚函数需要调用它的基类版本时。
15.4 抽象基类
纯虚函数
可以将一个没有实际意义的虚函数定义为纯虚函数,只需当在类内对它进行声明时最后加一个 =0 即可,无需额外定义。
Student{
virtual GetMaior()=0;//这是一个纯虚函数
};
含有纯虚函数的类是抽象基类
含有纯虚函数的类是抽象基类。不能直接创建一个抽象基类的对象。
可以创建派生类的对象,前提是派生类覆盖了原本的纯虚函数,否则该派生类也是抽象基类。
15.5 访问控制与继承
每个类分别控制自己的成员初始化进程,也控制着自己的成员对于派生类来说是否可访问。
受保护的成员
一个类使用 protected 关键字来声明希望对派生类可见但对其他用户不可见的成员。
派生类的成员和友元可以通过派生类对象访问基类的受保护成员,但是不能直接通过基类对象来访问。
公有、私有和受保护继承
一个类对继承的基类成员的访问权限受两方面影响:
- 基类中该成员的访问说明符
- 派生类的派生列表中的访问说明符
派生列表中的访问说明符不会影响派生类自身的成员和友元对基类的访问权限,对直接基类的访问权限只与基类中的访问说明符有关。它影响的是派生类的用户(包括派生类的对象、派生类的派生类)对基类成员的访问权限。
Student{
public:
void SetAge(int i);
};
class Undergraduate : private Student {}
Undergraduate gra;
gra.SetAge(20);//错误:对基类Student的继承是私有的,外部不可见
如果继承是公有的,则在派生类中,基类的成员将遵循原有的访问说明符
如果继承是受保护的,则基类的所有公有成员在派生类中都是受保护的。
如果继承是私有的,则基类的所有公有和受保护成员在派生类中都是私有的。
派生类向基类转换的可访问性
- 只有当 D 公有地继承 B 时,用户代码才能使用派生类向基类的转换。
- 无论 D 以什么方式继承 B,D 的成员函数和友元都能使用派生类向基类的转换。
- 如果 D 以受保护的方式继承 B,则 D 的派生类的成员和友元也可以使用 D 向 B 的类型转换。
类的几种用户
不考虑继承时,可以认为类有两种用户:
- 普通用户:普通用户的代码使用类的对象,只能访问类的公有成员。
- 类的实现者:实现者负责编写类的成员和友元。成员和友元可以访问类的所有部分。
考虑继承时出现了第三种用户
- 派生类:类的公有成员和受保护成员可以对派生类可见。
友元与继承
友元关系不能传递也不能继承。
如果类 A 是基类 B 的友元,那么 A 可以访问 B 对象的成员和 B 的派生类对象中属于 B 部分的成员。
改变个别成员的可访问性
可以使用 using 声明改变派生类继承的某个名字的访问级别。
using 声明位于 public 部分就是公有成员,位于 private 部分就是私有成员,位于 protected 部分就是受保护成员。
如下,Undergraduate 对 Student 的继承是私有继承,所以 Student 的所有成员在默认情况下都是 Undergraduate 的私有成员。
但是通过 using 声明,GetAge 成为了它的公有成员,age 成为了它的受保护成员。
class Student{
public:
int GetAge();
protected:
int age;
};
class UnderGraduate : private Student{
public:
using Student::GetAge;//不用加括号
protected:
using Student::age;
};
默认的继承保护级别
和直接定义相似,当继承时不使用访问说明符,使用 class 关键字定义的派生类默认是私有继承的,使用 struct 关键字定义的派生类默认是公有继承的。
class Student{};
class Undergraduate : Student{}; //默认 private 继承
struct Undergraduate : Student{}; //默认 public 继承
struct 和 class 两个关键字唯一的区别就是默认成员访问说明符和默认派生访问说明符,没有其他任何区别。
15.6 继承中的类作用域
每个类定义自己的作用域,在这个作用域内定义类的成员。
派生类的作用域嵌套在基类的作用域内。理解这句话:
Undergraduate gra;
cout << gra.GetAge();
这里通过 Undergraduate 的对象来调用 GetAge,所以首先在 Undergraduate 中查找名字 GetAge,没有找到。因为它是 Student 的派生类,所以下一步接着在 Student 中查找,找到并解析。
在编译时进行名字查找
一个对象、引用或指针的静态类型决定了该对象的哪些成员是可见的,即使静态类型和动态类型可能不一致。
如果一个基类的成员在基类中是私有的,在派生类中是公有的。那是不能通过基类对象来访问该成员的,因为这个对象的静态类型是基类,而该成员在基类中是私有的。
名字冲突与继承
派生类也能重用定义在其基类中的名字,重用后派生类的成员将隐藏同名的基类成员。
定义在派生类的函数不会重载基类中的同名成员,而是直接隐藏掉。
除了覆盖虚函数外,派生类最好不要重用基类成员的名字。
通过作用域运算符来使用隐藏的基类成员。
虚函数与作用域
派生类在重定义从基类继承的虚函数时,形参列表必须与基类的虚函数相同。
如果不同,派生类定义的将是一个新函数,该新函数不是虚函数,并且会隐藏掉从基类继承的同名虚函数。
15.7 构造函数与拷贝控制
15.7.1 虚析构函数
因为继承关系的影响,基类通常应该定义一个虚析构函数。
因为经常通过动态分配来生成类的对象,使用完后要 delete 掉相应的类指针,这时需要调用类的析构函数来销毁对象。但是类指针的静态类型可能是基类的指针,却动态绑定到了一个继承类,这时需要保证 delete 执行的是继承类的析构函数。所以要将析构函数定义为虚析构函数,这样可以通过动态绑定执行正确的版本。
只要基类的析构函数是虚函数,就可以保证 delete 基类指针时运行正确的析构函数版本。
虚析构函数将会阻止编译器合成移动操作。
15.7.2 合成拷贝控制与继承
注意:本节所说的都是编译器合成的拷贝控制成员,而非自定义的。
继承类的合成拷贝控制成员(构造函数、析构函数、赋值运算符等)在对其中的基类部分进行相关拷贝、销毁等操作时都是通过调用基类的对应成员完成的。
派生类中删除的拷贝控制与基类的关系
如果基类的默认构造函数、拷贝构造函数、拷贝赋值运算符或析构函数是删除的,那么派生类中对应的成员也会是删除的(因为派生类中的拷贝控制成员需要调用基类的对应成员来完成操作)。
如果基类有一个不可访问或删除的析构函数,则派生类中合成的默认和拷贝构造函数也会是删除的,因为编译器无法销毁派生类对象的基类部分。
如果基类的移动操作是删除的,那么派生类中的对应函数也是删除的,因为派生类的基类部分不可移动。
移动操作与继承
因为大多数基类都会定义一个虚析构函数,所以默认情况下基类通常没有合成的移动操作。
如果需要执行移动操作,首先要在基类中定义。之后派生类会自动合成移动操作。
class Quote{
public:
Quote() = default; //合成的默认构造函数
Quote(const Quote&) = default; //合成的拷贝构造函数
Quote(Quote&&) = default; //合成的移动构造函数
Quote& operator=(const Quote&) = default; //合成的拷贝赋值运算符
Quote& operator=(Quote&&) = default; //合成的移动赋值运算符
virtual ~Quote() = defalut; //合成的虚析构函数
}
15.7.3 派生类的拷贝控制成员
当派生类定义了拷贝或移动操作(包括对应的构造函数和复制运算符),该操作负责拷贝或移动包括基类部分成员在内的整个对象(通过调用基类的对应成员)。
无论基类的构造函数和赋值运算符是自定义的还是合成的,派生类的对应操作都可以使用它们。
析构函数不同,因为析构部分是隐式销毁的,基类部分也是自动销毁的,不需要派生类来负责。
在构造函数和析构函数中调用虚函数
如果在构造函数或析构函数中调用了某个虚函数,则会执行与构造函数或析构函数所属类型相对应的虚函数版本(即不会执行派生类的虚函数版本)。
理解:因为派生类构造函数会先调用基类构造函数完成基类部分的初始化,如果基类的构造函数调用了某个虚函数,而该虚函数的派生类版本访问了派生类的成员(还未进行初始化),会发生错误。
在构造函数和析构函数中调用虚函数是合法的,但非常不建议如此使用。
15.7.4 继承的构造函数
派生类能够重用其直接基类定义的构造函数。这些构造函数并非以常规的方式继承而来。
一个类只初始化它的直接基类,一个类也只继承其直接基类的构造函数(类不能继承默认、拷贝、移动构造函数,这三种构造函数如果没有定义类会自己合成)
派生类通过一个 using 声明语句来继承基类的构造函数
class Undergraduate : public Student{
public:
using Student::Student;
}
通常 using 声明语句只是令某个名字在当前作用域内可见。但是当作用域构造函数时,using 声明语句将令编译器产生代码。
对于基类的每个构造函数,编译器都生成一个形参列表完全相同的派生类构造函数。
derived(parms) : base(args) {} //编译器生成的构造函数的形式
如果派生类有自己的数据成员,这些成员将被默认初始化。
理解:继承的构造函数就是相当于派生类采用基类的构造函数初始化自己的基类部分,而派生类中定义的成员采用默认初始化。也可以直接定义具有相同功能的构造函数。
继承的构造函数的特点
和普通成员的 using 声明不一样,构造函数的 using 声明不会改变该构造函数的访问级别(即不管 using 声明在哪,派生类的构造函数的访问级别和基类中对应的构造函数的访问级别都是一样的)。
如果基类的构造函数是 explicit 或 constexpr 的,则继承的构造函数也有相同的属性。
当一个基类构造函数含有默认实参,这些实参并不会被直接继承,派生类会获得多个继承的构造函数,每个构造函数分别省略掉一个含有默认实参的形参。
如果基类含有几个构造函数,大多数时候派生类会继承所有这些构造函数。除了两个例外情况:
- 如果基类的某个构造函数和派生类自己定义的构造函数具有相同的参数列表,则该构造函数不会被继承。
- 默认、拷贝、移动构造函数不会被继承。
15.8 容器与继承
使用容器存放继承体系中的对象时,通常采用间接存储的方式,如存储对象的指针。
不能把基类和派生类同时放到一个容器中
vector stus; //容器的元素是基类类型
Undergraduate ug;
stus.push_back(ug); //正确,但是 stus 中只保存了 ug 里的基类部分,已经不是原来的对象了。
在容器中放(智能)指针而非对象
当要在容器中存放继承体系中的对象时,使用基类指针作为容器的元素类型。
问题
- 面向对象程序设计的核心思想是什么?
- 什么是虚函数?虚函数的主要作用是什么?
- 什么是动态绑定?
- 继承和动态绑定的作用是什么?
- 派生类对基类成员的访问权限是什么?类派生列表中的访问说明符起什么作用?
- 如何定义和声明虚函数?
- 如何理解派生类向基类的类型转换?
- 派生类与基类的构造函数的关系?
- 继承对静态成员的影响?
- 什么是静态类型和动态类型?
回答
- 面向对象的核心思想:数据抽象、继承、动态绑定
- 基类将希望派生类定义自己版本的成员函数定义为虚函数。虚函数可以帮助派生类更容易地实现自己独特的功能。
- 当派生类定义了自己版本的虚函数。使用基类的引用或指针来调用一个虚函数时将发生动态绑定。动态绑定根据传入的参数来选择函数版本。又称运行时绑定。
- 继承使程序员可以方便地定义相似但不相同的类,动态绑定可以更灵活地使用虚函数。
- 派生类(的成员和友元)可以访问基类的 public 和 preotected 成员。类派生列表中的访问说明符影响的是派生类的用户对派生类继承的基类成员的访问权限。
- 基类中使用关键字 virtual 声明虚函数。派生类中可以加 virtual 可以不加。建议使用关键字 override 来指明重新定义的虚函数。
- 派生类对象包含多个部分:自己定义的部分和继承的基类定义的部分,所以可以把基类的指针或引用绑定到派生类对象中的基类部分上(并不是绑定到了整个派生类对象身上)。
- 原则:每个类控制自己的成员初始化过程。所以派生类构造函数中要通过调用基类的构造函数来完成对基类部分的初始化。
- 基类的静态成员只有唯一一个实例,无论有多少派生类。
- 静态类型和动态类型的区分只有在基类的指针和引用上有意义。静态类型是定义时的类型,动态类型是运行时绑定的类型。
问题
- 可以用派生类对象为基类对象赋值吗?为什么
- 关键字 final 的用法
- 如何在调用虚函数时避免发生动态绑定?
- 什么是纯虚函数和抽象基类?有什么特点?
- 友元关系可以继承吗?
- 如何区分类的不同用户?
- 如何改变类中个别成员的可访问性?
- class 的默认继承保护级别是什么?struct 呢?
- 知识点:每个类定义自己的作用域、自己的接口,初始化自己的成员。
- 派生类和基类的作用域的关系是怎样的?
- 当派生类中的成员与基类中的成员发生名字冲突会怎样?
回答
- 一般可以用派生类对象为基类对象赋值和初始化,因为基类的构造函数和拷贝赋值运算符中一般都使用了引用传参。
- final 可以用来修饰类或类的成员函数以表明其不可被继承,放在形参列表后面,和 override 的位置一样。
- 不使用引用和指针来调用,或者在调用时使用作用域运算符指明是哪个版本。
- 使用 =0 定义的虚函数是纯虚函数,任何包含纯虚函数的类都是抽象基类。无法直接定义抽象基类的对象。派生类只有定义新版本覆盖掉了基类中的纯虚函数才不是抽象基类。
- 不可以
- 类的三种访问说明符就对应着三种用户:普通用户可访问公有成员,派生类可访问公有与受保护成员,类的成员和友元可访问所有成员。
- 在类的定义中使用 using 声明特定成员,using 声明位于 public 部分就是 public 成员。
- class 默认私有继承,struct 默认公有继承。
- 知识点:每个类定义自己的作用域、自己的接口,初始化自己的成员。
- 派生类的作用域嵌套在基类的作用域中。
- 派生类的成员会隐藏基类中的成员(此时依然可以通过作用域运算符访问相应的基类成员),包括基类中的虚函数。因此重定义虚函数时要注意返回类型和形参列表都要与基类的虚函数一致。
第16章 模板与泛型编程
面向对象编程和泛型编程都能处理在编写程序时不知道类型的情况
- OOP 能处理类型在程序运行之前都未知的情况。
- 泛型编程在编译时就能知道类型了。容器、迭代器、泛型算法都是泛型编程的例子。
模板是泛型编程的基础,一个模板就是一个创建类或函数的蓝图。
16.1 定义模板
16.1.1 函数模板
模板定义
模板定义以关键字 template 开始,后跟一个用 <> 包围,用逗号分隔的模板参数列表。
模板参数表示在定义时用到的类型或值。使用模板时要指定模板实参。
template
bool compare(const T &v1, const T &v2) {
return v1 函数模板实例化
调用函数模板时,编译器用函数实参来推断模板实参,然后实例化出一个特定版本的函数。
cout << compare(1, 0) << endl; // 实例化出一个参数类型为 int 的 compare 函数
模板类型参数
模板类型参数就是模板参数。模板参数可以用来指定返回类型或函数的参数类型。
模板参数前必须使用关键字 class 或 typename,两个含义相同。
template
T foo(T* p) { return *p; }
非类型模板参数
模板中还可以定义非类型参数。一个非类型参数表示一个值。
非类型参数使用特定类型名(如 int,double 等)而非 typename 来指定。
当一个模板实例化时,非类型参数被用户提供的值所代替,这些值必须是常量表达式,以允许编译器在编译时实例化模板。
非类型参数可以是一个整型或指针或引用。如果是指针或引用,绑定的实参必须有静态的生存期。
数组的大小是数组类型的一部分,所以数组做函数参数时其大小必须是固定的,可以通过非类型模板参数使其大小可变。
template
int compare(const char (&p1)[N], const char (&p2)[M]) {
return strcmp(p1, p2);
}//定义了一个函数模板。
compare("hi", "mom");//实例化
inline 和 constexpr 的函数模板
函数模板可以声明为 inline 或 constexpr 的。
template inline T min(const T&, const T&);
编写类型无关的代码
编写泛型代码有两个重要原则:
- 模板中的函数参数应该是 const 的引用。引用保证了函数可以用于不能拷贝的类型,如unique_ptr, IO 类型。
- 函数体中的条件判断仅使用 < 比较运算。
模板编译
编译器遇到模板定义时不生成代码,当实例化出模板的一个特定版本时才生成代码。这会影响错误何时被检测到。
定义类时,普通的成员函数一般放在源文件中。但是模板不同,模板的头文件通常既包括声明也包括定义。因为编译器需要知道函数模板或类模板成员函数的完整定义才能进行实例化。
大多数变异错误在实例化期间报告
因为模板直到实例化时才生成代码,所以错误可能出现在:
- 编译模板本身时。只能检测到语法错误。
- 编译器遇到模板使用时。只能检测模板实参是否与形参相匹配。
- 模板实例化时。这时才能发现类型相关的错误。
16.1.2 类模板
类模板不同于函数模板的地方在于,编译器不能为类模板推断参数类型。
定义类模板
template
class Student {};
实例化类模板
使用类模板时需要提供显式模板实参列表,编译器根据模板实参来实例化出特定的类。
Student stu; // 使用类模板
template <> class Student {}; // 当向上一行那样使用类模板时,编译器实例化出的类就是这样的。
类模板的成员函数
可以在类模板内部,也可以在外部定义成员函数。定义在类模板内部的函数隐式声明为内联函数。
定义在类模板之外的成员函数必须以关键字 template 开始,后接类模板参数列表。
template int Student::GetAge();
类模板成员函数的实例化
默认情况下,一个类模板的成员函数只有当用到它时才进行实例化。
在类代码内简化模板类名的使用
使用一个类模板类型时必须提供模板实参,但有一个例外:在类模板自己的作用域内部,可以直接使用模板名而不提供实参。
template
class Blob{
Blob& operator++();//这里可以直接使用 Blob 也可以仍旧使用 Blob
}
在类模板外使用类模板名
在类模板外使用类模板名必须提供模板实参。
类模板和友元
如果一个类模板包含一个非模板友元,则该友元可以访问该模板的所有实例。
如果友元也是模板,类可以授权给所有友元模板实例,也可以只授权给特定实例。
一对一友好关系
template
class Blob{
friend class BlobPtr; // 每个 Blob 实例将访问权限授予了同类型实例化的 BlobPtr。
friend bool operator== (const Blob&,const Blob&); // 将访问权限授予同类型实例化的 ==。
}
通用和特定的模板友好关系
template
class Blob{
template friend class Pal; // Pal 的所有实例都是 Blob 的每个实例的友元。
}
为了让所有实例都成为友元,友元声明中必须使用与类模板不同的模板参数。
令模板自己的类型参数成为友元
template
class Blob{
friend T; // 将访问权限授予用来实例化 Blob 的类型
}
模板类型别名
可以定义一个 typedef 来引用实例化的类,但不能引用模板
typedef Blob StrBlob;//正确
可以用 using 为类模板定义类型别名
template using twins = pair; // 为 pair 定义了一个类型别名 twins
twins authors; // authors 是一个 pair。
定义模板类型别名时,可以固定其中的部分模板参数
template using twins = pair; // 为 pair 定义了一个类型别名 twins
twins authors; // authors 是一个 pair。
类模板的 static 成员
如果类模板定义了 static 成员,那么模板的每个实例都有自己独有的 static 成员实例。
static 数据成员定义时也要定义为模板
template int Blob::num = 0; // 在类模板外定义 static 数据成员的方式。
16.1.3 模板参数
模板参数与作用域
模板参数的可用范围是其声明之后,至模板声明或定义结束之前。
模板参数会隐藏外层作用域中的相同名字,但是注意在模板内不能重用模板参数名。
一个模板参数名在一个特定模板参数列表中只能出现一次
template
模板声明
模板声明必须包含模板参数,声明中的模板参数的名字不必与定义中相同(与函数形参类似)。
template T min(const T&, const T&); // 声明
一个文件所需要的所有模板的声明通常都一起放置在文件的开始位置。
使用类的类型成员
默认情况下,C++ 假定通过作用域运算符访问的名字不是类型(比如可能是静态成员)。
如果希望使用一个模板类型参数的类型成员,必须使用关键字 typename 显式地告诉编译器该名字是一个类型。
template typename T::value_type a = 1;
默认模板实参
可以为函数模板和类模板的模板参数提供默认模板实参,就像可以为函数参数提供默认实参一样。
template >
16.1.4 成员模板
一个类(无论是普通类还是类模板)可以包含本身是模板的成员函数。这种成员称为成员模板。
成员模板不能是虚函数。
16.1.5 控制实例化
16.1.6 效率与灵活性
16.2 模板实参推断
16.2.1 类型转换与模板类型参数
16.2.2 函数模板显式实参
16.2.3 尾置返回类型与类型转换
16.2.4 函数指针和实参推断
16.2.5 模板实参推断和引用
16.2.6 理解std:move
static_cast可以显示的系那个一个左值转换为一个右值引用。
16.2.7 转发
16.3 重载与模板
函数模板可以被另一个模板或普通非模板函数重载。名字相同的函数必须具有不同数量或类型的参数。
16.4 可变参数模板
一个可变模板参数就是一个接受可变数目参数的模板函数或模板类。可变数目的参数被称为参数包。参在两种参数包:
- 模板函数包
- 函数参数包
template
void foo(const T& t, const Args& ... rest)
当我们需要知道包中有多少元素时,可以使用sizeof...运算符
template void g(Args ... args) {
cout << sizeof...(Args) << endl;
cout << sizeof...(args) << endl;
}
16.4.1 编写可变参数函数模板
16.4.2 包扩展
16.4.3 转发参数包
16.5 模板特例化
问题
- 函数模板的定义方式
- 函数模板实例化的方法
- 使用什么关键字声明模板参数
- 什么是非类型模板参数
- 编写泛型代码的两个原则。
- 知识点:模板定义时编译器不生成代码,遇到第一个模板的实例化时才生成代码。
- 知识点:定义模板时声明和定义都放在头文件中。
- 类模板的定义方式
- 如何使用类模板。
- 如何定义类模板的成员函数
回答
- template bool func(const T1& v1, const T2& v2);
- 像普通函数一样直接调用,编译器根据函数实参来推断模板实参。
- class 或 typename,建议用 typename
- 一个非类型模板参数表示一个值,它直接使用类型名指定(如 int)而非 typename。函数模板实例化时,可以用一个常量表达式代替。
- 模板中的函数参数应该是 const 的引用。函数体中的条件判断仅使用 < 比较运算。
- 知识点:模板定义时编译器不生成代码,遇到第一个模板的实例化时才生成代码。
- 知识点:定义模板时声明和定义都放在头文件中。
- template class Blob{};
- 使用类模板时要提供模板实参,如 vector vec;
- 定义在类模板内的函数为内联函数,定义在类模板外的函数在定义时要用 template 声明。
问题
- 类模板的成员函数什么时候实例化
- 类模板中不同友元的访问关系。
- 如何为类模板定义类型别名
- 类模板的 static 成员有多少个实例
- 模板参数名的作用范围
- 知识点:可以为函数模板和类模板的模板参数提供模板实参
回答
- 用到的时候实例化。
- 如果类模板的友元是一个普通类或函数,则该友元可以访问该模板的所有实例。如果友元也是模板,如果友元的模板参数名与类的模板参数名相同,则该友元的实例只能访问相同实例类型的类模板。如果友元的模板参数名与类的模板参数名不同,则友元的所有实例都能访问类模板的所有实例。
- typedef 只能为类模板的某个实例定义类型别名,可以用 using 直接为类模板定义类型别名。template using twins = pair; twins a;
- 每个类模板的实例版本都有自己的 static 成员实例。(区别于继承中,所有的继承类和基类都只有基类一个 static 实例)
- T 的作用范围时模板定义结束之前。
- 知识点:可以为函数模板和类模板的模板参数提供模板实参
第17章 标准库特殊设施
本章介绍了 4 个比较通用的标准库设施:tuple、bitset、随机数生成、正则表达式,另外介绍了IO库输入输出的详细信息
17.1 tuple类型
tuple 是一种类似 pair 的模板。tuple 定义在头文件 tuple 中。
不同于 pair 有两个成员,tuple 可以有任意数量的成员。
tuple 用来将一些不同类型的数据组合起来
tuple 的定义和初始化
tuple t; // 使用 tuple 的默认构造函数,对每个成员进行值初始化
tuple t (i,d,s); // 为每个成员提供一个初始值。构造函数是 explicit 的,必须使用直接初始化
tuple t {i,d,s}; // 同上 auto t = make_tuple(i, d, s);
tuple 操作
t1 == t2; // t1 与 t2 的元素数量相同且成员对应相等
t1 < t2; // t1 和 t2 的成员数量必须相同才能进行比较
get(t); // 返回 t 的第 i 个数据成员的引用。如果 t 是左值则返回左值引用,如果 t 是右值则返回右值引用
tuple 定义了 == 和 < 运算符,因此可以将 tuple 序列传递给算法,并且可以在无序容器中将 tuple 作为关键字类型。
使用 get(i) 访问 tuple 的成员
auto a = get<0>(t); // 返回 t 的第一个成员。从 0 开始计数
tuple 定义的类型
tuple_size::value // tuple_size 是一个类模板,有一个 public static 成员 value,表示指定 tuple 类型中成员的数量 tuple_element::type; // tuple_element 是一个类模板,有一个 public static 成员 type,表示指定 tuple 类型中第 i 个成员的类型
确定一个对象类型最简单的方法是使用 decltype
typedef decltype(t) tType; // tType 是 t 的类型
size_t sz = tuple_size::value; // 返回 3
tuple_element<1, tType>::type d = get<1>(t); // d 是一个 double
使用 tuple 返回多个值
tuple 的一个典型应用是从函数返回多个值。
一些使用嵌套 pair 的地方可以使用 tuple 来代替。
17.2 BITSET类型
bitset 类定义在头文件 bitset 中
bitset 类是一个类模板,类似 array 类,有固定的大小。bitset 的大小代表它包含多少个二进制位
17.2.1 定义和初始化 bitset
可以使用一个整型值或一个 string 来初始化 bitset。
当我们使用一个整型值来初始化 bitset 时,此值被转换为 unsigned long long 类型并被当作位模式来处理。
当用 string 初始化时,注意 string 中下标最大的字符用来初始化 bitset 中的最低位
bitset b; // 定义了一个 n 位的 bitset,每一位都是 0
bieset b(u); // b 是 unsigned long long 值 u 的低 n 位的拷贝。如果 n 大于 unsigned long long 的大小,则超出的高位置零。
bieset b(s, pos, m, zero, one); // b 是 string s 从位置 pos 开始的 m 个字符的拷贝。s 只能包含 char 字符 zero 和 one
17.2.2 bitset 操作
访问 bitset
b[pos]; // 访问 b 中位置 pos 出的位。
当 b 非 const 时,可以通过下标改变 b 的 pos 处的值
b[0] = 1;
b[0].flip(); // 将 b[0]翻转
检测 bitset 的一个位或多个位
b.any(); b.all(); b.none(); // 分别检测 b 中 是否存在被置位的位、是否全被置位、是否不存在被置位的位
b.count(); b.size(); // 分别返回 b 中被置位的位数和 b 的总位数
b.test(pos); // 若 pos 处的位被置位,则返回 true,否则返回 false
设置 bitset 的一个位或多个位
设置操作主要包括三类:置位、复位、翻转
b.set(); b.set(pos); b.set(pos, v); // 全部置位 或 将 pos 处设置为 v,v 默认为 true
b.reset(); b.reset(pos); // 全部复位 或 将 pos 处复位
b.flip(); b.flip(pos); // 全部位改变 或 将 pos 处位改变
将 bitset 转换为其他类型
可以将 bitset 转换为整型或字符串。当转换为字符串时可以控制转换成什么字符
b.to_ulong(); b.to_ullong();// 返回一个位模式与 b 相同的 unsigned long 或 unsigned long long 值。
//b 的大小应小于等于 ul 或 ull 的大小,否则会抛出异常 overflow_error
b.to_string(zero, one); // 返回一个 string,zero 和 one 分别默认为 1,0;也可以设为其他 char 字符
读入和输出 bitset
os << b; // 将 b 中二进制位打印为字符 1 或 0,打印到流
os is >> b; // 从 is 读入字符存入 b,当下一个字符不是 1 或 0 时,或已经读入 b.size() 位时,读取停止
输入时从输入流读取字符保存到一个临时的 string 对象中,读取停止后用临时 string 对象来初始化 bitset
bitset运算
bitset 可以像一个普通的整数一样进行与(&)、或(|)、非(~)、异或(^)、左移(<<)、右移(>>)等位操作。
17.3 正则表达式
C++ 的正则表达式库(RE库)定义在头文件 regex 中。
默认情况下,regex 使用的正则表达式语言是 ECMAScript(实际就是 JavaScript)。
regex 是一种表示正则表达式的类类型。
regex 类的定义
regex r(re); // re 是一个用 string、或字符数组、或迭代器范围、或花括号包围的字符列表、或一个字符指针与一个计数器表示的正则表达式。
regex r(re,f); // f 是一个标志,用来指定采用的格式或正则表达式语言,默认为采用 ECMA-262 规范的 ECMAScript 标志。
regex 的操作
r = re; // 将 r 中的正则表达式替换为 re,re 可以是另一个 regex 对象,或 string、字符数组、花括号包围的字符列表。
r.assign(re,f); // 与使用赋值运算符的效果相同,f 与 regex 构造函数中的 f 含义相同。
r.mark_count(); // r中子表达式的数目。
r.flags(); // 返回 r 的标志集。
定义 regex 时指定的标志
总共有 9 个标志,其中 6 个标志表示采用的正则表达式语言。

正则表达式组件
regex_match(seq, m, r, mft); //如果整个字符序列 seq 与 regex 对象 r 中的正则表达式匹配就返回 true。
regex_search(seq, m, r, mft); //如果输入序列 seq 中的一个子串与 regex 对象 r 中的正则表达式匹配就返回 true
//seq 可以是一个 string、字符指针或是一对表示范围的迭代器
//上面的参数 m 和 mft 都可以省略。m 是一个 match 对象,用来保存匹配结果的相关细节。
regex_replace //使用给定格式替换一个正则表达式
sregex_iterator //迭代器适配器,调用一个 regex_search 来遍历一个 string 中所有匹配的子串。
smatch //一个容器类,保存在 string 中搜索到的结果
ssub_match //string 中匹配的子表达式的结果
17.3.1 使用正则表达式库
正则表达式的编译非常慢,应尽量避免创建不必要的 regex。
一个例子
string pattern1("[^c]ei");
pattern1 = "[[:alpha:]]*" + pattern1 + "[[:alpha:]]*";
regex r(pattern1);
smatch results;
string test_str("receipt freind theif receive");
if (regex_search(test_str, results, r))
std::cout << results.str() << std::endl;
正则表达式中的转义字符
在 C++ 中使用正则表达式的转义字符时,需要用两个反斜杠(\)
"\\." //这个正则表达式表示了一个 "."。第一个反斜杠用来取出 C++ 语言中的反斜线的特殊含义。
指定或使用正则表达式时的错误
正则表达式本身可以看作是用另一种语言编写的程序。这种语言不是 C++ 编译器解释的。
所以正则表达式是在运行时才被编译的,准确的说是一个 regex 对象被初始化或赋予一个新模式时才被编译的。因此正则表达式的语法错误在运行时才能检查出来。
如果正则表达式有错,运行时标准库会抛出一个 regex_error 的异常。
regex_error 异常
regex_error 有两个成员函数:
- what() 来描述发生了什么错误(类似标准异常类型)。通常返回一个字符串
- code() 来返回错误类型对应的数值编码。
try{
regex r("[[:alnum:]+\\.(cpp|cxx|cc)$", regex::icase); //存在错误:alnum 漏掉了右括号,会抛出异常
} catch (regex_error e)
{
cout << e.what() << "\ncode: " << e.code() << endl;
}
正则表达式的错误类型
正则表达式的错误类型的数值编码按图中顺序编号,从 0 开始。
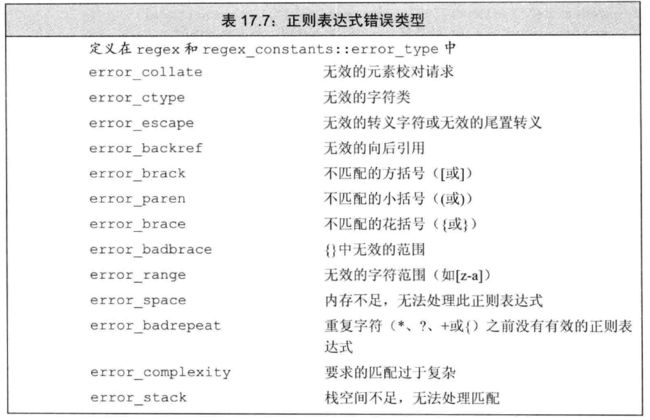
正则表达式类和输入序列类型
对于不同类型的输入序列,要使用不同的 RE 库组件。
比如如果序列在 string 中,就要使用 smatch,而不能使用 cmatch。

17.3.2 匹配与Regex迭代器类型
sregex_iterator 是 regex 迭代器,它是一种迭代器适配器,绑定到一个输入序列和一个 regex 对象上。不同的输入序列类型有不同的 regex 迭代器类型(见上图)。
可以使用 sregex_iterator 来获得输入序列中的所有匹配。
sregex_iterator 的定义和操作
sregex_iterator iter(b, e, r);
//定义了一个 sregex_iterator 遍历迭代器 b 和 e 表示的 string。它会调用 sregex_search(b, e, r)将 iter 定位到输入中第一个匹配的位置。 sregex_iterator it_end; //默认初始化定义了一个 sregex_iterator 的尾后迭代器
*iter, iter->
//根据最后一个调用 regex_search 的结果,返回一个表示当前匹配结果的 smatch 对象的引用或指针。解引用迭代器即可获得 smatch 对象。
++iter, iter++ //从输入序列当前匹配位置开始调用 regex_search。 iter1 == iter2, iter1 != iter2
sregex_iterator 理解
当我们将一个 sregex_iterator 绑定到一个 string 和 一个 regex 对象时,迭代器会自动定位到第 string 中第一个匹配的位置(实际上是 sregex_iterator 的构造函数对给定的 string 和 regex 调用了 regex_search)
当解引用一个迭代器,会得到一个对应最近一次搜索结果的 smatch 对象。
当递增一个迭代器,它调用 regex_search 在输入 string 中查找下一个匹配。
使用 sregex_iterator 的例子
string pattern1("[^c]ei");
pattern1 = "[[:alpha:]]*" + pattern1 + "[[:alpha:]]*";
regex r(pattern1, regex::icase);
string test_str("receipt freind theif receive");
for (sregex_iterator iter(test_str.begin(), test_str.end(), r), iter_end; iter != iter_end; ++iter)
cout << iter->str() << endl; //循环打印所有的匹配结果
使用匹配数据
smatch 类有很多成员函数,可以通过这些成员函数来对匹配结果进行各种操作
smatch m; m.ready();
//如果已经通过 regex_search 或 regex_match 设置了 m,则返回 true,否则返回 false;如果它返回了 false,那对 m 进行其他操作是未定义的。
m.size(); //如果匹配失败则返回 0,否则返回最近一次匹配的正则表达式中子表达式的数目。
m.empty(); //若 m.size() 为 0,则返回 true
m.prefix(); //返回一个 sub_match 对象,表示当前匹配之前的序列(输入序列中位于匹配结果之前与上一个匹配结果之后的部分)
m.suffix(); //返回一个 sub_match 对象,表示当前匹配之后的序列(输入序列中位于匹配结果之后的部分)
m.format(...); '接受索引的操作' '如果索引为 0 或没有索引表示整个匹配,索引值 n 必须小于 m.size()'
m.length(n); //第 n 个子表达式的匹配子串的大小
m.postion(n);//第 n 个子表达式的匹配子串距序列开始的距离
m.str(n); //第 n 个子表达式匹配的 string
m[n] //对应的第 n 个子表达式的 ssub_match 对象
m.begin(), m.end() //表示 m 中 sub_matc 元素范围的迭代器。
m.cbegin(), m.cend()
17.3.3 使用子表达式
正则表达式中的模式通常包含一个或多个子表达式。一个子表达式是模式的一部分,本身也具有意义。
正则表达式语法通常用括号表示子表达式。
regex r("([[:alnum:]]+)\\.(cpp|cxx|cc)$", regex::icase); //匹配 C++ 文件,这个模式包括两个括号括起来的子表达式
匹配对象除了提供匹配整体的相关信息外,还提供访问模式中每个子表达式的匹配结果的能力。
子匹配是按位置访问的,第一个子匹配位置是 0,表示对整个模式的匹配,随后是对每个子表达式的匹配。
ECMAScript 正则表达式语言的特性
注意:模式中每次出现反斜线 “\” 的地方都要用一个额外的反斜线来告知 C++ 需要一个反斜线字符而不是一个特殊符号。
理解:因为在 C++ 中反斜线 “\” 起到了转义的作用,也就是当正常使用反斜线时它并不是表示反斜线,要用 “\" 才表示这是一个反斜线字符。
只有反斜线需要这种特殊操作,因为 C++ 中其他字符都表示的是本意。
\{d} //表示单个数字
\{d}{n} //表示一个 n 个数字的序列
[-.] //方括号中的字符表示匹配这些字符中的任意一个
?,*,+ //与其他正则表达式语言中含义相同
经验:实际执行中发现 \s 匹配不了空格。
17.3.4 使用regex_replace
17.4 随机数
**传统生成随机数的方法:**rand()
- 生成结果:一个伪随机整数,范围在 0 到一个与系统相关的最大值之间
- 缺点:生成其他范围需要程序员来手动转换,常引入非随机性。
C++ 新标准的方法:使用随机数引擎类和随机数分布类协作来生成
- 引擎:类型,生成 unsigned 随机数序列
- 分布:类型,使用引擎生成指定类型的、在给定范围内的、服从特定概率分布的随机数
C++ 程序应该使用新标准的方法,不用 rand()
17.4.1 随机数引擎和分布
随机数引擎和分布类型是函数对象类。两者组合起来构成一个随机数发生器。
定义在头文件中。
随机数引擎的定义和初始化
标准库定义了多个随机数引擎类,其中 default_random_engine 是默认类型,其实是某个其他引擎的类型别名。
Engine e; // 默认构造函数,使用该引擎默认的种子。Engine 表示某个随机数引擎类型
Engine e(s); // 使用整型值 s 作为种子
随机数引擎操作
e.seed(s); // 使用种子 s 重置引擎的状态
e.min(); e.max(); // 分别返回此引擎可生成的最小值和最大值
e.discard(u); // 将引擎推进 u 步,u 的类型是 unsigned long long
Engine::resule_type; // 类型,此引擎生成的 unsigned 整型类型。
一般随机数引擎的输出不是我们想要的范围,需要结合分布类型得到我们想要的范围。
几种常见的分布类型的定义
分布类型定义了一个调用运算符,接受一个随机数引擎作为参数。分布类型使用该引擎生成随机数,并映射到指定范围。
分布类型除了一个生成布尔值的外,其他的都是模板类,可以生成整型和浮点型。浮点型默认是 double,整型默认是 int。
标准库定义了 20 种分布类型。
uniform_int_distribution u(min,max);//均匀分布。intT 为某种整型,默认为 int,min、max 默认值为 0 和该整型最大值 uniform_real_distribution u(min,max);//均匀分布。realT 为某种浮点型,默认为 double,min、max 默认值为 0 和 1 normal_distribution n(4,1.5);//正态分布。按均值为 4,标准差 1.5 的正态分布生成随机数
bernoulli_distribution b(p);//返回一个 bool 值,以概率 p 返回 true,p 默认为 0.5
poisson_distribution d(double x);//泊松分布。生成均值为 x 的泊松分布
分布类型的操作
Dist d; // 默认构造函数,定义一个分布类型
d(e); // 返回一个生成的随机数
d.min(); d.max(); // 返回 d(e) 能生成的最小值和最大值
d.reset(); // 重建 d 的状态,使随后对 d 的使用不依赖 d 已生成的值。
17.4.2 随机数发生器
随机数发生器的使用-生成一个随机数
注意,定义为局部变量的一个给定的随机数发生器始终生成相同的随机数。
此特性在调试时很有用。
uniform_int_distribution u(0, 10); // 定义一个分布类型
default_random_engine e; // 定义一个引擎
int r = u(e); // 返回一个随机数
随机数发生器的使用-连续生成多个不同随机数
要想循环生成不同的随机数,应将其定义为 static。
static uniform_int_distribution u(0, 10);
static default_random_engine e; int r = u(e); // 每次调用生成不同的随机数。
设置随机数发生器种子
实际为设置引擎的种子
当不用 static 时,每次提供不同的种子可以实现生成不同的随机数
设置种子的两种方式:创建对象时用种子初始化,调用引擎的 seed 成员。
最常用的种子是通过调用**系统函数 time(定义在 ctime 中)**来获得。但是 time 只返回以秒计的时间。
实际测试的结果
在循环内定义发生器每次循环生成的随机数相同。(随机数序列的元素相同)
在循环外定义发生器和在循环内定义 static 发生器效果相同,都会生成不同的随机数。(随机数序列的元素不同)
上述几种方式多次调用函数生成的随机数序列都是一样的(随机数序列相同)
17.5 IO库再探
IO 库的三个特殊的特性:格式控制、未格式化IO、随机访问
17.5.1 格式化输入与输出
iostream 对象除了维护条件状态外,还维护一个格式状态,用来控制 IO 如何格式化。
标准库定义了一组操纵符来修改流的格式状态。
操纵符的功能有两大类:
- 控制数值的输出形式
- 控制补白的数量和位置
改变格式状态的操纵符一般是成对的:一个设置另一个复原。
当操纵符改变流的格式状态时,通常改变后的状态对所有后续 IO 都生效。所以要记得尽快将流恢复默认
有参数的操纵符位于头文件 iomanip 中,其他都位于 iostream 中
'iomanip'
setw(n);
setprecision(n);//设置输出的精度
setfill(ch); //指定用字符 ch 代替空格来补白
setbase(b);//设置输出为 b 进制
'iostream'
boolalpha; noboolalpha; // 设置 bool 值输出形式
showbase; noshowbase; // 对整型值显示输出的进制
showpoint; noshowpoint; // 对无小数部分的浮点数显示小数点
showpos; noshowpos; // 对非负数显示 +
uppercase; nouppercase; // 将字母显示为大写
dec; hex; oct; // 输出为几进制
left; right; internal; // 输出对其方式
fixed; scientific; hexfloat; defaultfloat; // 浮点数输出格式
unitbuf; nounitbuff; // 连续刷新缓冲区
skipws; noskipws; // 跳过空白符 flush; ends; endl;
**指定是否刷新缓冲区:**unitbuf, nounitbuf
默认不刷新。unitbuf 会使每输出一个字符就刷新一次缓冲区
控制布尔值的格式:boolalpha,noboolalpha
默认打印 1 和 0
cout << true << false; // 打印 1 和 0
cout << boolalpha << true << false; // 打印 true 和 false
cout << noboolalpha; // 恢复默认
**指定是否显示正号:**showpos, noshowpos
默认对非负数不显示 +
**指定整型值的进制:hex, oct, dec,**setbase(b)
默认打印 10 进制。
setbase(b) 使输出为 b 进制
hex, oct, dex 只影响整型对象,不影响浮点值
cout << 20; // 输出 10 进制
cout << oct << 20; // 输出 8 进制
cout << hex << 20; // 输出 16 进制
cout << dec << 20; // 恢复十进制
在输出中指定进制:showbase,noshowbase,以及控制字母大小写:uppercase, nouppercase
默认不显示前导字符,十六进制默认以小写打印。
显示前导字符时 0x 表示十六进制,0 表示八进制,无前导字符表示十进制
cout << showbase << hex << 30; // 打印 0x1e
cout << uppercase << 30; // 打印 0X1E
控制浮点数格式
可以从三个方面设置浮点数格式:
- 以多高精度打印,精度控制的是打印的字数的总数。默认为总共打印 6 位数字
- 打印为十六进制、定点十进制还是科学计数法形式。默认十进制,很大或很小时为科学计数法,其他为定点十进制
- 没有小数部分的浮点值是否打印小数点。默认不打印小数点
**指定打印精度:setprecision(),**成员函数 precicion()
除了操纵符 setprecision() 还可以调用 IO 对象的 precision() 成员来指定精度或获取当前精度。
使用四舍五入来打印小精度
cout << setprecision(4) << 3.1415; // 设置精度为 4 位,打印 3.142
cout << cout.precision(); // 打印当前精度:4
cout.precision(6); // 设置精度为 6 位
setprecision() 本来控制的是数字的整体精度(而不是小数位数),如果同时也用上 fixed,setprecision() 指定的就是小数位数了。
cout << fixed << setprecision(2) << 3.1415; // 设置小数位数为 2 位,打印 3.14
选择数字表示形式:
- 打印为十六进制:hexfloat
- **打印为定点十进制:**fixed
- **打印为科学计数法:**scientific
- 恢复默认状态:defaultfloat
打印小数点:showpoint, noshowpoint
输出补白:
- setw(n):指定下一个数字或字符串值的最小空间
- left:左对齐输出
- right:右对齐输出。默认为右对齐
- internal:控制负数的符号位置:左对齐符号,右对齐值,中间为空格
- setfill(‘#’)****:指定用 ‘#’ 代替空格来补白。
注意到 setw(n) 是一个例外,不改变格式状态,只决定下一个输出的大小
控制输入格式:noskipws,skipws
默认情况下输入会忽略空白符,noskipws 会使输入读取空白符。
17.5.2 未格式化的输入/输出操作
标准库提供了一组低层操作来支持未格式化 IO,允许将一个流当作一个无解释的字节序列来处理。
注意:底层函数相对更容易出错
单字节低层 IO 操作
下面几个未格式化操作每次一个字节地处理流,他们会读取而不是忽略空白符。
is.get(ch); // 从输入流 is 读取下一个字节存取字符 ch 中,返回 is
os.put(ch); // 将字符 ch 输出到输出流 os 中,返回 os
is.get(); // 将 is 的下一个字节作为 int 返回
is.peek(); // 将 is 的下一个字节作为 int 返回,但不从流中删除它
is.putback(ch); // 将字符 ch 放回 is,返回 is
is.unget(); // 将 is 向后移动一个字节,返回 is
单字节读取和输出
下面的程序输出与输入完全相同,包括空白符。其执行过程与使用 noskipws 相同
char ch;
while(cin.get(ch))
cout.put(ch);
将字符放回输入流
有时需要将字符放回流中。标准库有三种方法退回字符:
- **peek:**以 int 类型返回输入流中下一个字符的副本,但不会将它从流中删除,即 peek 返回的值仍留在流中
- unget:使输入流向后移动,从而最后读取的值又回到流中
- **putback:**相当于特殊版本的 unget:退回从流中读取的最后一个值,但是接受一个参数,该参数必须与最后读取的值相同。
在读取下一个值前,最多可以退回一个值,即不能连续调用 putback 或 unget
从输入操作返回 int 值
peek() 和无参 get() 都以 int 类型从输入流返回一个字符。
返回 int 而不返回 char 的原因:可以返回文件尾标记。
返回 int 要先将返回的字符转换为 unsigned char,然后将结果提升到 int。
头文件 cstdio 定义了一个名为 EOF 的 const,可以用它来检测返回值是否为文件尾。
while(cin.get() != EOF)
多字节操作
有一些未格式化 IO 操作一次处理大块数据,速度相比于普通输入输出更快。
这些操作要求我们自己分配并管理用来保存和提取数据的字符数组。容易出错。
is.get(sink, size, delim); // 从 is 中读取最多 size 个字节,存入字符数组 sink 中。
//读取遇到字符 delim 或文件尾或个数达到 size 个字节后停止。如果遇到 delim,将其留在输入流中,不读取
is.getline(sink, size, delim); // 与上一个类似。区别是遇到 delim 读取并丢弃 delim
is.read(sink, size); // 从 is 中读取最多 size 个字节,存入字符数组 sink 中,返回 is
is.gcount(); // 返回上一个未格式化读取操作从 is 读取的字节数。如果上一个操作是 peek、unget、putback,返回 0 os.write(sourse, size); // 将字符数组 sourse 中的 size 个字节写入 os,返回 os
17.5.3 流随机访问
fstream 和 stringstream 流类型都支持对流中数据的随机访问。可以重定位流。
iostream 类型通常不支持随机访问,绑定到 cin, cout, cerr, clog 的流不支持随机访问。
标准库提供了两对函数来实现此功能:
- **seek:**定位到流中给定的位置
- **tell:**告诉我们当前位置
一对用于输入流,后缀为 g,一对用于输出流,后缀为 p
tellg(); tellp(); // 返回一个输入流或输出流中标记的当前位置
seekg(pos); seekp(pos); // 在一个输入流或输出流中将标记重定位到给定的绝对地址
seekg(off, from); seekp(off, from); // 在一个输入流或输出流中将标记定位到 from 之前或之后 off 个字符
注意:标记只有一个,表示缓冲区中的当前位置。g 和 p 版本的读写位置都映射到这一个单一的标记。
因为只有一个标记,如果要在读写间切换,就必须进行 seek 操作来重定位标记。
问题
- tuple 如何定义与初始化
- 如何访问 tuple 对象的元素
- tuple 支持 == 和 < 吗
- tuple 定义了两个类型是什么
- tuple 的典型应用场景
- 知识点:bitset 是一个了类模板,类似 array,有固定的大小,大小代表了它有多少个二进制位。
- bitset 如何定义和初始化
- 如何访问 bitset 的元素
- bitset 的用于检测元素的函数有哪些?
- bitset 的用于设置元素的函数有哪些?
- 如何将 bitset 转换位其他类型?
- 如何读入和输出 bitset?
回答
- tuple t (i,d,s); tuple 支持列表初始化与值初始化(也可以进行默认初始化)
- 使用 get*(t) 访问 tuple 对象 t 的第 i 个元素,返回元素的引用。*
- 支持,所以它可以作为 map 的关键字。
- tuple_size::value 和 tuple_element::type; 分别用来获取 tupleType 的元素数目和第 i 个成员类型
- 可以用于函数返回多个值的情况。
- 知识点:bitset 是一个了类模板,类似 array,有固定的大小,大小代表了它有多少个二进制位。
- bitset b;定义了一个 n 位的 bitset。可以用整型值和字符串来初始化 bitset。
- 可以使用下标访问元素,如果 b 非 const,也可以用下标改变元素值。
- any(), all(), none(), count(), size(), test(pos)
- set(), set(pos), reset(), reset(pos), flip(), flip(pos)
- b.to_ulong, b.to_ullong 和 b.to_string()
- os<>b 。按位输出和输入
问题
- 随机数生成器包括哪两个部分,在哪个头文件中?
- 如何定义一个随机数引擎
- 如何定义一个分布类型
- 如何使用随机数发生器生成一个随机数
- 控制格式化输入输出的操纵符位于哪两个头文件中?
回答
- 随机数引擎和分布类型,在头文件 random 中
- default_random_engine e;
- uniform_int_distribution u(min,max);
- 先定义一个随机数引擎 e,再定义一个分布类型 u,然后生成一个随机数 u(e)。
- iostream 与 iomanip
第18章 用于大型程序的工具
大规模编程对程序设计的特殊要求:
- 在独立开发的子系统之间协同处理错误的能力。C++ 的异常处理满足此要求。
- 使用各种库进行协同开发的能力。C++ 的命名空间满足此要求。
- 对比较复杂的应用概念建模的能力。C++ 的多重继承满足此要求。
18.1 异常处理
异常处理使得我们能够将问题的检测和解决过程分离开。
18.1.1 抛出异常
C++ 中通过抛出(throw)一条表达式来引发一个异常。
被抛出的表达式的类型和当前的调用链共同决定了使用哪段处理代码来处理异常。
当执行了一个 throw 语句,跟在 throw 后的语句将不再执行,程序的控制权从 throw 语句转移到与之匹配的 catch 模块,catch 模块可能并不位于当前函数。
控制权的转移有两个含义:
- 沿着调用链的函数可能会提早退出。
- 一旦程序开始执行异常处理代码,则沿着调用链创建的对象将会被销毁。
throw 语句的用法有点类似 return 语句:一旦执行了此语句,后面的语句将不再执行。
栈展开
抛出异常后查找匹配的 catch 模块的过程是一个栈展开的过程:如果当前 try 语句块附近没有找到匹配的 cahch 语句,就继续向外层寻找。栈展开过程沿着嵌套函数的调用链不断查找,直到找到了匹配的 cahch 子句为止。
如果找到了匹配的 catch 子句就执行该子句中的代码。执行完后找到与 try 块关联的最后一个 catch 子句后的点继续执行。
如果没有找到匹配的 catch 子句程序将会调用 terminate 函数,终止程序的执行。
栈展开过程中对象被自动销毁
如果栈展开过程中退出了某个块,那么在这个块中创建的局部对象将会被销毁。
析构函数与异常
栈展开的过程中,类类型的局部对象的析构函数会被执行以销毁该对象。析构函数不应该抛出异常。如果析构函数需要执行某个可能抛出异常的操作,该操作应该放在 try 语句块中并在析构函数内部得到处理。
原因:当析构函数抛出了异常,又没有在析构函数内部完成处理的话,析构函数将会提早退出,导致没有完成对象的销毁工作。
异常对象
异常对象是一种特殊的对象,编译器使用 throw 表达式来对异常对象进行拷贝初始化。
异常对象位于编译器管理的空间中,编译器确保无论调用的是哪个 catch 子句,都能访问该空间。当异常处理结束后,该异常对象被销毁。
不能抛出一个指向局部异常对象的指针。
18.1.2 捕获异常
catch 子句中的异常声明和函数形参有些类似。
声明的类型决定了处理代码所能捕获的异常类型。
进入 catch 语句后,将通过异常对象初始化异常声明中的参数。和函数参数类似,如果 catch 的参数类型是非引用类型,则该参数是异常对象的一个副本,如果参数是引用类型,则该参数是异常对象的一个别名。
如果 catch 的参数是基类类型,则可以使用派生类类型的异常对象对其进行初始化。此时如果 catch 的参数是非引用类型,则异常对象会被切掉一部分。如果 catch 的参数是基类的引用,该参数将以常规方式绑定到异常对象上。
异常声明的静态类型将决定 catch 语句所能执行的操作。
如果 catch 接受的异常与某个继承体系有关,最好将该 catch 的参数定义为引用类型。
查找匹配的处理代码
查找 catch 语句时,匹配到的 catch 语句是第一个与异常匹配的语句,而未必是最佳匹配。
当有多个 catch 子句时,应该合理调整 catch 子句的顺序,使得派生类异常的处理代码在基类异常的处理代码之前。
与实参和形参的匹配规则相比,异常和 catch 异常声明的匹配规则更严格一些,可以进行以下三种转换:
- 允许从非常量向常量的类型转换;
- 允许从派生类向基类的类型转换;
- 数组被转换为指向数组(元素)类型的指针,函数被转换成指向该函数类型的指针。
重新抛出
有时,一个单独的 catch 语句不能完整地处理某个异常,这时要用到重新抛出。
一条 catch 语句可能通过重新抛出来将异常(这个异常是当前 catch 语句所捕获的异常)传递给另一个 catch 语句。这里的重新抛出仍然是一条 throw 语句,但不包含任何其他内容。
throw;
使用重新抛出语句后,当前的异常对象将沿着调用链向上传递。
捕获所有异常的处理代码
使用省略号作为异常声明,可以一次性捕获所有异常。
try{ // 抛出异常的代码 }
catch(...){ // 处理异常的操作 }
catch(…) 通常与重新抛出语句一起使用。
catch(…) 可以单独出现,也可以与其他几个 catch 语句一起出现。
18.1.3 函数try语句块与构造函数
程序执行的任意时刻都可能发生异常,特别是构造函数初始化的过程中。
处理构造函数初始值异常的唯一方法就是将构造函数写成函数 try 语句块
函数 try 语句块使得一组 catch 语句既能处理构造函数体(或析构函数体),也能处理构造函数的初始化过程(或析构函数的析构过程)。
Student::Student(string &_name)
try: // 关键字 try 位于表示初始值列表的冒号之前
name(name) {/*函数体*/}
catch(const bad_alloc &e) {} // catch 语句位于构造函数体之后
18.1.4 noexcept异常说明
使用关键字 noexcept 放到函数的参数列表后面可以标识该函数不会抛出异常。
noexcept 需要出现在函数所有的声明语句和定义语句中。
void func(int) noexcept; // 不会抛出异常
void func(int) throw(); // 这个声明和上一条是等价的,这是 C++11 之前的旧版本。
异常说明的实参
noexcept 可以接受一个可选的实参,实参要能够转换为 bool 类型
void func(int) noexcept(true); // 不会抛出异常
void func(int) noexcept(false); // 可能抛出异常
noexcept运算符
noexcept 说明符的实参常和 noexcept 运算符混合使用。
noexcept 运算符接受一个表达式,返回一个 bool 值,用来表示给定的表达式是否会抛出异常。
noexcept 有两种含义:
- 跟在函数列表后时它是异常说明符。
- 作为 noexcept 异常说明的 bool 实参出现时,它是一个运算符。
noexcept(func(i)) //如果 func 中调用的所有函数都做了不抛出声明且 func 本身不包含 throw 语句时,值为 true
异常说明与指针、虚函数和拷贝控制
如果函数做了不抛出声明,那么指向它的函数指针也必须做不抛出声明。
如果一个虚函数做了不抛出声明,派生的函数也必须做不抛出声明。
18.1.5 异常类层次
标准库异常类具有下图所示的继承关系。
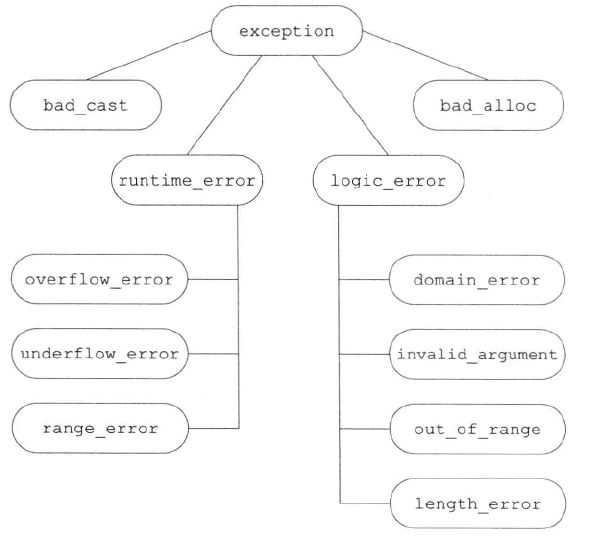
继承体系的根部是 exception 类,它是最基本的异常类,仅表示某处出错了。
继承体系第二层将异常划分了两大类:运行时错误和逻辑错误。
所有的标准库异常类都有一个 what 成员函数(是一个虚函数),它返回一个 const char*。
类 exception, bad_cast, bad_alloc 都定义了默认构造函数。
类 runtime_error 和 logic_error 都没有默认构造函数,但有一个接受 C 风格字符串或标准库 string 类型实参的构造函数。
实际的应用程序常常会自定义 exception 的派生类来扩展继承体系。
18.2 命名空间
多个库将名字放置在全局命名空间中将引发命名空间污染。
命名空间可以用来防止名字冲突,它分割了全局命名空间。
18.2.1 命名空间定义
定义方法
使用关键字 namespace 来定义命名空间。
只要能出现在全局作用域内的声明就能放到命名空间内。包括:类、变量、函数、模板和其他命名空间等。
namespace cpp_primer{ class Sales_data{}; } //无须分号
定义在某个命名空间内的名字可以被该命名空间内的其他成员直接访问,该命名空间之外的代码则需要明确指出命名空间来访问所用的名字。
命名空间可以是不连续的
命名空间可以定义在几个不同的部分。
命名空间中,类的定义、函数和对象的声明都应该放在头文件中,函数的定义等部分应该放到源文件中。
理解:不论是函数的声明还是定义,都要放在命名空间中,只是声明放在头文件,定义放在源文件而已。
定义命名空间成员
定义命名空间的成员有两种方法(都是在源文件中)
namespace cpp_primer{
void func(){} // 在命名空间中直接定义函数
}
void cpp_primer::func(){} // 使用作用域运算符在命名空间外定义函数。
模板特例化
模板特例化必须定义在原始模板所属的命名空间中。可以在命名空间内声明,在命名空间外定义。
全局命名空间
全局作用域中定义的名字是定义在隐式的全局命名空间中。
作用域运算符同样可以用于全局作用域成员。
::Student // 这表示定义在全局作用域中的 Student
嵌套的命名空间
命名空间可以嵌套。外层命名空间的成员要使用内层命名空间中的成员需要使用限定符来访问。
内联命名空间
内联命名空间是 C++11 新引入的一种嵌套命名空间。
内联命名空间中的名字可以被外层命名空间直接使用。
使用关键字 inline 定义内联命名空间
inline namespace FifthEd {}
未命名的命名空间
未命名的命名空间是关键字 namespace 后面直接跟花括号。
一个未命名的命名空间可以在一个文件内不连续,但不能跨越多个文件,它的作用域也仅限于该文件。
每个文件定义自己的未命名的命名空间,不同文件的未命名命名空间互不关联。
定义在未命名的命名空间中的名字可以直接使用,且不能对他们使用作用域运算符。
未命名的命名空间的作用域与该命名空间所在的作用域相同。
如果一个头文件定义了未命名的命名空间,且该头文件被多个文件所包含,则每个文件中都有该命名空间定义的名字的不同实体。
因此不要在头文件中使用匿名命名空间。
18.2.2 使用命名空间成员
命名空间的别名
命名空间的别名声明也使用了关键字 namespace,别名声明的格式如下:
namespace primer = cpp_primer;// 使用别名 primer 来代替 cpp_primer 的名字。
using 声明:扼要概述
using 声明一次引入命名空间的一个成员。
using 声明的名字的作用域与 using 声明语句本身的作用域一致。
using std::cin;
using 指示
using 指示直接引入一整个命名空间。
using 指示不能用在类的作用域内。但是 using 声明是可以的。
using namespace std;
using 指示与作用域
using 指示令引入的命名空间成员的作用域提升到包含命名空间本身和 using 指示的最近作用域。
这与 using 声明不同:using 声明只是令名字在局部作用域内有效,相反 using 指示令整个命名空间的所有内容变得有效,而命名空间内会含有一些不能出现在局部作用域中的定义。
头文件与 using 声明或指示
头文件如果在其顶层作用域中含有 using 指示或 using 声明,则会将名字注入到所有包含了该头文件的文件中。
因此头文件最多只能在它的函数或命名空间内使用 using 指示或 using 声明。
避免使用 using 指示
一般不要使用 using 指示,很危险。
using 指示的用处:在命名空间本身的实现文件中可以使用 using 指示。
18.2.3 类、命名空间与作用域
实参相关的查找与类类型形参
std::string s;
std::cin >> s;
重载操作符 >> 定义在标准库 string 中,string 定义在命名空间 std 中。但是不用 std:: 限定符就可以调用 >> 操作符。
这是因为:当我们给一个函数传递一个类类型的对象时,除了在常规的作用域查找外还会查找实参类所属的命名空间。
>> 操作符的形参(iostream 和 string)是类类型的,所以编译器还会查找 iostream 和 string 所属的命名空间。
查找与 std::move 和 std::forward
move 和 forward 都是模板函数,在标准库的定义中它们都接受一个右值引用的函数形参。在函数模板中,右值引用形参可以匹配任何类型。
所以如果用户自己也定义了一个 move 函数并且它只接受一个参数,那么必然会与标准库的 move 函数冲突。forward 函数也是如此。
所以 move 和 forward 的名字冲突非常频繁,使用时应该写 std::move 和 std::forward。
18.2.4 重载与命名空间
与实参相关的查找与重载
已知对于接受类类型实参的函数来说,其名字查找会在实参类所属的命名空间中进行。
在有重载的情况下,将会在每个实参类(及实参类的基类)所属的命名空间中搜寻候选函数,找到的所有与被调用函数同名的函数都会被添加到候选函数集中。
重载与 using 声明
注意:using 声明语句声明的是一个名字,而非一个特定的函数。
所以用 using 引入一个函数时只用函数名就行了。
using std::find; // 正确
using std::find(int); // 错误
一个 using 声明引入的函数将会重载当前作用域内已有的其他同名函数(即 using 声明引入的函数与当前作用域中原有的函数互为对方的重载版本)。
如果 using 声明出现在局部作用域中,它引入的名字将会隐藏外部作用域中相同的名字。
如果使用 using 声明的作用域中存在与 using 声明引入的函数同名且形参列表也相同的函数,会产生错误。
重载与 using 指示
using 指示有一点不同于 using 声明:如果 using 指示引入的函数中存在与已有的函数同名且形参列表也相同的函数,不会产生错误。只需要调用时指明是哪个版本即可。
跨越多个 using 指示的重载
如果存在多个命名空间,则来自每个命名空间的名字都将成为候选函数集的一部分。
18.3 多重继承与虚继承
多重继承:从多个直接基类中产生派生类(不是指一层层继承)
18.3.1 多重继承
多重继承中,派生类的派生列表中的每个基类都包含一个可选的访问说明符。
派生类构造函数初始化所有基类
构造一个派生类的对象将同时构造并初始化它的所有基类子对象。
派生类构造函数调用各个基类的构造和函数来完成基类子对象的初始化,初始化顺序由基类在派生类表中的顺序决定。
继承的构造函数与多重继承
允许派生类从它的一个或几个基类中继承构造函数。
如果从多个基类中继承了相同的构造函数(即形参列表完全相同),会发生错误。这时派生类需要定义自己版本的具有同样形参列表的构造函数。
struct Base1{
Base1(const string&);
};
struct Base2{
Base2(const string&);
};
struct D : public Base1, public Base2{
using Base1::Base1;
using Base2::Base2;
D(const string& s) : Base1(s), Base2(s) {} //定义自己的版本
};
析构函数与多重继承
析构函数的调用顺序与构造函数相反。
多重继承的派生类的拷贝与移动操作
与多重继承的派生类构造函数类似,多重继承的派生类的拷贝、移动或赋值操作也要调用各个基类的对应操作来完成对基类部分的处理。
18.3.2 类型转换与多个基类
多重继承中,派生类的指针或引用可以自动转换成任意一个可访问基类的指针或引用。比如 D* 可以转换成 Base1* 或 Base2*。
基于指针类型或引用类型的查找
与只有一个基类的继承一样,对象、指针、引用的静态类型决定了能够使用哪些成员。
如果使用了基类 Base1 的指针,则只有定义在 Base1 中的操作是可以使用的。
18.3.3 多重继承下的类作用域
多重继承的情况下,派生类的作用域嵌套在各个基类的作用域中。
在沿着继承体系查找名字时,查找过程会在所有的直接基类中同时进行,如果名字在多个基类中都被找到,则对该名字的使用具有二义性(如果通过前缀限定符来使用则没问题)。
要解决二义性最好的办法是在派生类中定义一个新版本。
18.3.4 虚继承
在派生列表中同一个基类只能出现一次,但是派生类可以通过它的两个直接基类继承同一个间接基类(菱形继承),或直接继承某个基类,然后通过另一个基类再次间接继承该基类。
默认情况下,派生类中含有继承链上每个类对应的子部分,如果某个类在继承链上出现了多次,则派生类中将包含该类的多个子对象。
当包含多个基类的子对象时,访问基类的成员会出现二义性问题。
虚继承
某些情况下,派生类不希望包含同一种基类的多个子对象。比如 iosteram 类同时继承了 istream 和 ostream,而 istream 和 ostream 都继承了一个抽象基类 base_ios,iosteam 不希望有两个 base_ios 的子对象。
虚继承:令某个类做出声明(在派生列表中使用 virtual 关键字),承诺愿意共享它的基类,共享的基类子对象称为虚基类。
理解:使用虚继承的地方和虚继承产生效果的地方并不是同一个地方。如 istream 和 ostream 都虚继承了抽象基类 base_ios,此时虚继承的效果并未体现。之后 iostream 正常继承了 istream 和 ostream,此时虚继承的效果才会体现:iostream 中只有一个 base_ios 子对象(因为 istream 和 ostream 承诺了共享 base_ios)。
这种情况下,不管虚基类在继承体系中出现多少次,派生类中都只包含唯一一个共享的虚基类子对象。
class D : virtual public Base {}; // Base 是一个虚基类,其中 virtual 和 public 的顺序随意
虚基类成员的可见性
菱形继承中,基类成员的可见性情况会比较复杂。
例:基类 B 中定义了一个成员 x,D1 和 D2 虚继承了 B 类,D 则继承了 D1 和 D2。然后通过 D 的对象访问 x,会有 3 种情况:
- D1 和 D2 并没有重写 x:没有问题,x 会被解析为 B 的成员。
- D1 和 D2 中的某一个重写了 x:没有问题,派生类中的 x 享有比共享基类 B 中的 x 更高的优先级。
- D1 和 D2 都重写了 x:会出现二义性的问题。解决问题的最好方式是在 D 中重新定义自己版本的 x。
18.3.5 构造函数与虚继承
虚派生中,虚基类是由最低层的派生类(就是继承链中离虚基类最远的派生类)初始化的。
虚继承的对象的构造方式
含有虚基类的对象在初始化时,首先初始化虚基类子部分,再按照直接基类在派生列表中的顺序依次对其初始化。
如果一个类有多个虚基类,这些虚基类子对象按照它们在派生列表中出现的顺序依次构造。
第19章 特殊工具与技术
19.1 控制内存分配
19.1.1 重载new和delete
19.1.2 定位new表达式
19.2 运行时类型识别
19.2.1 dynamic_cast运算符
19.2.2 typeid运算符
19.2.3 使用RTTI
19.2.4 type_info类
19.3 枚举类型
和类一样,枚举类型定义了一种新的类型。枚举属于字面值常量类型。
C++的两种枚举类型:
- 限定作用域的枚举类型(C++11新标准)
- 不限定作用域的枚举类型
限定作用域的枚举类型
枚举成员的名字遵循常规的作用域准则,且在枚举类型的作用域外是不可访问的。在枚举类型的作用域内最好不要出现同名,但是即使出现了也没错。
'定义方式'
enum class Color1 {green, blue}; // class 可以等价地换位 struct
'使用'
Color1 eyeColor = Color1::blue; // 使用作用域运算符访问枚举成员
限定作用域的枚举类型的对象不能被当成整型值来使用
int a = Color1::blue; // 错误
不限定作用域的枚举类型
枚举成员的作用域与枚举类型本身的作用域相同。因此在作用域内,不能出现与枚举成员相同的名字
'定义方式'
enum Color2 {red, yellow};
'使用'
Color2 hairColor1 = red; // 可以不使用作用域运算符访问枚举成员
Color2 hairColor2 = Color2::red; // 也可以使用作用域运算符访问枚举成员
不限定作用域的枚举类型的对象可以自动转换成整型
int b = red; // 正确
枚举成员的值
默认情况下,枚举值从 0 开始,依次加 1。也可以在定义枚举类型时为一个或多个枚举成员指定专门的值。
如果没有显式地提供初始值,则当前枚举成员的值等于上一个枚举成员的值加 1。
枚举成员是常量表达式(const),因此也必须用常量表达式初始化枚举成员。
switch 语句中 case 标签的值必须是常量表达式,可以用枚举成员做 case 标签。
和类一样,枚举也定义新的类型
初始化 enum 对象或为 enum 对象赋值,必须使用枚举成员或另一个同类型的 enum 对象,不能使用整型值。
Color1 eyeColor1 = Color1::green; // 使用枚举成员初始化
Color1 eyeColor2 = eyeColor1; // 使用同类型的 enum 对象初始化
Color1 eyeColor3 = 0; // 错误:不能只用整型值
enum 成员的类型
限定作用域的 enum 成员类型默认是 int,不限定作用域的 enum 成员没有默认类型,只知道成员的潜在类型足够大,肯定可以容纳所有枚举值。
可以通过在类型名的后面加上想要的类型来显式地指定 enum 成员的类型
enum uid:long long {
first = 1242342745542,
second = 63642652515
}; // 枚举成员的类型为 long long
枚举类型的前置声明
可以提前声明 enum,但是不限定作用域的枚举类型在声明时必须指定成员类型。
enum 的声明和定义的成员类型必须匹配。
enum class Color1; // 前置声明 Color1,成员类型默认为 int
enum uid:long long; // 前置声明 uid,必须指定成员类型
19.4 类成员指针
19.4.1 数据成员指针
19.4.2 成员函数指针
19.4.3 将成员函数用作可调用.
19.5 嵌套类
一个类可以定义在另一个类的内部,称之为嵌套类。
嵌套类常用于定义作为实现部分的类。
嵌套类是一个独立的类,和外层类没什么关系。
嵌套类也使用访问限定符来控制外界对其成员的访问权限。外层类对嵌套类的成员没有特殊的访问权限。
注意:嵌套类实际上是在外层类中定义了一个新的类型,因此也属于外层类的类型成员,需要先声明后使用,外层类的成员也可以像使用任何其他类型成员一样使用嵌套类的名字。
嵌套类的定义
嵌套类必须在类内进行声明,但是可以定义在类内或类外。
在类外定义时,要加外层类作为访问限定符。定义嵌套类时,嵌套类可以直接使用外层类的成员,无需对该成员的名字进行限定。
class TextQuery::QueryResult{};
嵌套类在完成定义前,都是一个不完全类型。
定义嵌套类的成员函数和静态成员
TextQuery::QueryResult::Process(){};
int TextQuery::QueryReslut::data = 1024;
19.6 union:一种节省空间的类
联合是一种特殊的类。一个联合可以有多个数据成员,但是在任意时刻只有一个数据成员可以有值。
当给 union 的某个成员赋值后,其他成员就变成未定义的状态了。
和其他类一样,一个 union 定义了一种新类型。
union 不能含有引用类型的成员,其他类型都可以。
默认情况下,union 的成员都是公有的,也可以为成员指定 public, protected, private 等标记。union 也可以定义成员函数,但不能定义虚函数。
定义union类型
union 用来定义一组类型不同的互斥值。
union Token{
char cval;
int ival;
double dval;
} // Token 类型的对象只有一个成员,该成员的类型可能是下列类型中的任意一种
初始化union
默认情况下union 是未初始化的。
可以使用花括号内的初始值来初始化一个 union,像聚合类一样。
提供的初始值被用于初始化 union 的第一个成员。
Token first_token = {'a'};//定义并初始化一个 Token 对象
Token *pt = new Token;//定义一个指向未初始化的 Token 对象的指针
使用union
使用通用的成员访问运算符来访问一个 union 对象的成员。
为 union 的一个数据成员赋值会令其他成员变为未定义状态。
注意:不要使用错误的数据成员!会出现未知错误。
first_token.ival = 2;
pt->dval = 1.2;
匿名union
匿名 union 是一个未命名的 union。当定义了一个匿名 union,编译器会自动为该 union 创建一个未命名对象。
匿名 union 的成员可以在作用域内可以直接访问。
union {
char cval;
int ival;
};
cval = 'c';//为上面定义的匿名 union 的对象赋值。
匿名 union 不能包含受保护成员或私有成员,也不能包含成员函数。
含有类类型成员的union
含有类类型成员的 union 的用法很复杂。它要运行类类型成员的构造函数、析构函数进行管理。
一般将含有类类型成员的 union 内嵌在另一个类中,使用该类来管理与 union 的类类型成员相关的操作。这时一般会将该 union 定义为匿名 union,并另外定义一个枚举类型来表示 union 的成员类型,定义一个枚举对象作为判别式来指明 union 当前已赋值的成员。
具体使用方法较复杂,可以直接看书。
19.7 局部类
定义在函数内部的类称为局部类。局部类的成员都必须完整定义在类的内部(比嵌套类严格的多)。
和嵌套类不同,局部类的成员受到严格限制。局部类中不能声明静态数据成员,因为没法定义(静态数据成员必须在类外定义)
局部类的访问权限
局部类可以访问外层作用域定义的类型名、静态变量和枚举成员,但不能访问外层函数的局部变量。
嵌套的局部类
局部类中可以再嵌套一个类,此时嵌套类的定义可以出现在局部类之外,不过必须定义在与局部类相同的作用域中。
局部类中的嵌套类也是一个局部类,必须遵循局部类的各种规定。
19.8 固有的不可移植的特性
为了支持低层编程,C++ 定义了一些固有的不可移植的特性。
不可移植的特性即因机器而异的特性。将一个不可移植特性的程序从一台机器转移到另一台机器上时,通常需要重新编写该程序。
本节介绍的三个不可移植的特性:位域、volatile 限定符、链接指示。
19.8.1 位域
类可以将它的非静态数据成员定义成位域,在一个位域中含有一定数量的二进制位。当一个程序需要向其他程序或硬件设备传递二进制数据时,通常会用到位域。
位域在内存中的布局是与机器相关的。
位域的类型必须是整型或枚举类型。因为带符号位域的行为是由具体实现确定的,所以通常使用无符号类型保存一个位域。
位域的声明形式是在成员名字之后紧跟一个冒号及一个常量表达式,该表达式用于指定成员所占的二进制位数。
typedef unsigned int Bit; // 定义类型别名 Bit,使位域看起来更突出
class File {
Bit mode: 2; // mode 占 2 位
Bit modified: 1; // modified 占 1 位
Bit prot_owner: 3;
Bit prot_group: 3;
Bit prot_world: 3;
public:
enum modes { READ = 01, WRITE = 02, EXECUTE = 03 };
File& open(modes);
void close();
void write();
bool isRead() const;
void setWrite();
}
上面 5 个位域总共占 12 位,还不到一个 unsigned int 的长度。
如果可能的话,在类的内部连续定义的位域会压缩在同一整数的相邻位,从而提供存储压缩。如上例中,5 个位域可能会存储在同一个 unsigned int 中。
这些二进制位是否能够压缩到一个整数中及如何压缩是与机器相关的。
取地址运算符(&)无法作用于位域,所以任何指针都无法指向类的位域。
使用位域
访问位域的方式与方位其他数据成员的方式相似。
void File::write() {
modified = 1; //设置 modified 的值(modified 占 1 位)
// ...
}
void File::close() {
if(modified)
// ...保存内容
}
通常使用内置的位运算符操作超过 1 位的位域。
File &File::open(File::modes m) {
mode |= READ; //按默认方式设置模式为 READ
if(m & WRITE) //如果打开模式为 READ 和 WRITE
// ...
return *this;
}
如果一个类定义了位域成员,通常也会定义一组内联的成员函数来检验或设置位域的值
inline bool File::isRead() const { return mode& READ; }
inline void File::setWrite() { mode |= WRITE; }
19.8.2 volatile限定符
关键字 volatile 告诉编译器不要对它所修饰的对象进行优化。
直接处理硬件的程序常常包含这样的数据元素,它们的值由程序直接控制之外的过程控制。
例如,程序可能包含一个由系统时钟定时更新的变量。当对象的值可能在程序的控制或检测之外被改变时,应该将对象声明为 volatile。
用法
volatile 用法和 const 相似,也可以使用 volatile 修饰 const 对象。
volatile int display_register; //该 int 值可能发生改变。
volatile Task *curr_task; //curr_task 指向一个 volatile 对象
volatile int iax[max_size]; //数组的每个元素都是 volatile
volatile Screen bitmapBuf; //bitmapBuf 的每个成员都是 volatile
也可以将成员函数定义为 volatile,只有 volatile 的成员函数才能被 volatile 的对象调用。
volatile 指针和引用
可以声明 volatile 指针、指向 volatile 对象的指针和指向 volatile 对象的 volatile 指针。
volatile int v;
int *volatile vip;
volatile int *ivp;
volatile int *volatile vivp;
int *ip = &v;
和 const 一样,只能将一个 volatile 对象的地址赋给一个指向 volatile 的指针。
同时只有当某个引用是 volatile 时,才能使用一个 volatile 对象初始化该引用。
理解:只有函数的参数类型是 volatile 引用时,它才能接受一个 volatile 对象。
合成的拷贝对 volatile 对象无效
不能使用合成的拷贝/移动构造函数及赋值运算符初始化 volatile 对象或从 volatile 对象赋值。
合成的成员接受的形参类型是非 volatile 的常量引用,显然不能将一个非 volatile 引用绑定到一个 volatile 对象上。
如果一个类希望拷贝、移动或赋值它的 volatile 对象,那它必须自定义拷贝或移动操作。例如可以将形参类型指定为 const volatile 引用。
class Foo {
public:
Foo(const volatile Foo&); // 从一个 volatile 对象进行拷贝
Foo& operator=(const volatile Foo&); // 将一个 volatile 对象赋值给一个非 volatile 对象
Foo& operator=(const volatile Foo&) volatile; // 将一个 volatile 对象赋值给一个 volatile 对象
};
19.8.3 链接指示:extern"C"
C++ 程序有时需要调用其他语言编写的函数。像所有其他名字一样,其他语言中的函数名字也必须在 C++ 中进行声明,且该声明必须指定返回类型和形参列表。
对其他语言编写的函数来说,编译器检查其调用的方式与处理普通 C++ 函数的方式相同,但生成的代码有所区别。
C++ 使用链接指示指出任意非 C++ 函数所用的语言。
注意:要想把 C++ 代码和其他语言(包括 C 语言)编写那些的代码一起使用,必须有权访问该语言的编译器,且该编译器与当前的 C++ 编译器是兼容的。
声明一个非 C++ 的函数
链接指示有两种形式:单个的和复合的。
链接指示不能出现在类定义或函数定义的内部。同样的链接指示必须在函数的每个声明中都出现。
下面是 C++ 头文件 中可能出现的链接指示
extern "C" size_t strlen(const char *); // 单语句链接指示
extern "C" { // 复合语句链接指示
int strcmp(const char*, const char*);
char* strcat(char*, const char*);
}
链接指示包含一个关键字 extern 和一个字符串字面值常量,这个字符串指出了编写函数所用的语言。
编译器应该支持 extern “C”,此外还可能支持其他语言的链接指示,如 extern “FORTRAN” 等。
链接指示与头文件
复合语句声明的形式可以应用于整个头文件,这时整个头文件中的所有普通函数声明都被认为是由链接指示的语言编写的。
extern "C" { #include }
指向extern"C"函数的指针
附录A.2 算法概览
算法描述中一些词汇的含义:
- begin 和 end 是表示元素范围的迭代器,左闭右开。
- beg2 是表示第二个输入序列开始位置的迭代器,end2 表示末尾。如果没有 end2,则假定 beg2 表示的序列与 beg 和 end 表示的序列一样大。
- dest 是表示目的序列的迭代器。目的序列必须保证足够大。
- unaryPred 和 binaryPred 分别表示一元谓词和二元谓词,分别接受一个和两个参数,都是来自输入序列的元素。
- comp 是一个二元谓词。谓词返回的是 bool 值。如果想从小到大排序,comp 的处理方式应该是:return left < right;
- unaryOp 和 binaryOp 是可调用对象,可分别使用来自输入序列的一个和两个实参来调用。这个不是谓词,不必返回 bool 值。
理解各个算法的拓展方式:
- 凡是查找等于某个值(使用 ==)的算法,基本都有使用一元谓词代替 == 的重载版本或相似函数
- 凡是比较两个值大小(使用 <)或是否相等(使用 ==)的算法,基本都有使用二元谓词代替 == 或 < 的重载版本或相似函数
A.2.1 查找对象的算法
简单查找算法
find
find 类的函数都返回指向满足条件的元素的迭代器,如果没有就返回尾后迭代器。
find(beg, end, val); // 返回第一个等于 val 的元素的迭代器,如果没有返回尾后迭代器。
find_if(beg, end, unaryPred)
find_if_not(beg, end, unaryPred) // 返回第一个令 unaryPred 为 false 的元素的迭代器,如果没有返回尾后迭代器。
count
count 类的函数返回满足条件的元素的数目
count(beg, end, val) // 返回等于 val 的元素的数目
count_if(beg, end, unaryPred) // 返回满足条件 unaryPred 的元素的数目
all, any 和 none
返回 bool 值
all_of(beg, end, unaryPred); // 是否所有元素都满足条件 unaryPred,如果序列为空返回 true
any_of(beg, end, unaryPred);
none_of(beg, end, unaryPred);
查找重复值的算法
adjacent_find
返回指向第一对相邻重复元素的迭代器,如果没有返回尾后迭代器。
adjacent_find(beg, end)
adjacent_find(beg, end, binaryPred)
search_n
返回一个迭代器,从此位置开始有 count 个相等元素。如果没有返回尾后迭代器。
search_n(beg, end, count ,val)
search_n(beg, end, count, val, binaryPred)
查找子序列的算法
search
返回第二个输入范围(子序列)在第一个输入范围中第一次出现的位置的迭代器。
search(beg1, end1, beg2, end2)
search(beg1, end1, beg2, end2, binaryPred)
find_first_of
返回第二个输入范围中任意元素在第一个范围中首次出现的位置的迭代器。
find_first_of(beg1, end1, beg2, end2)
find_first_of(beg1, end1, beg2, end2, binaryPred)
find_end
类似 search,但返回的是最后一次出现的位置
find_end(beg1, end1, beg2, end2)
find_end(beg1, end1, beg2, end2, binaryPred)
A.2.2 其他只读算法
for_each
对输入序列中的每个元素调用可调用对象 unaryOp
for_each(beg, end, unaryOp)
mismatch
比较两个序列中的元素,返回一个迭代器的 pair,指向两个序列中第一个不匹配的元素。如果都匹配,pair 中第一个迭代器是尾后迭代器
mismatch(beg1, end1, beg2)
mismatch(beg1, end1, beg2, binaryPred)
equal
返回 bool 值,如果两个序列相等返回 true
equal(beg1, end1, beg2)
equal(beg1, end1, beg2, binaryPred)
A.2.3 二分搜索算法
这些算法要求序列中的元素已经有序,它们的行为类似关联容器的同名成员。
每个算法都有两个版本,第一个版本使用小于运算符(<)来检测元素,第二个版本使用给定的比较操作。
lower_bound和upper_bound
返回一个迭代器。
lower_bound(beg, end, val); //返回一个迭代器表示第一个大于等于 val 的元素,如果没有这样的元素就返回 end
lower_bound(beg, end, val, comp);
upper_bound(beg, end, val); //返回一个迭代器表示第一个大于 val 的元素,如果没有这样的元素就返回 end
upper_bound(beg, end, val, comp);
equal_bound
返回一个 pair,它的 first 成员是 lower_bound 返回的迭代器,second 成员是 upper_bound 返回的迭代器。
equal_bound(beg, end, val);
equal_bound(beg, end, val, comp);
binary_search
返回一个 bool 值,指出序列中是否包含等于 val 的元素。
相等的判断:对于两个值,当 x 不小于 y 且 y 不小于 x 时,认为它们相等。
binary_search(beg, end, val);
binary_search(beg, end, val, comp);
A.2.4 写容器元素的算法
写容器元素的算法用来向给定序列中的元素写入新的值。
只写不读元素的算法
fill
fill 给输入序列中的每个元素赋予一个新值。
fill(beg, end, val); // 返回 void
fill_n(dest, cnt, val); // 返回一个迭代器,指向写到输出序列的最后一个元素之后的位置。
generate
generate 执行生成器对象 Gen() 生成新值并赋给输入序列中的每个元素。
生成器对象是一个可调用对象,每次调用都会生成一个不同的返回值。
generate(beg, end, val); // 返回 void
generate_n(dest, cnt, val); // 返回一个迭代器,指向写到输出序列的最后一个元素之后的位置。
使用输入迭代器的写算法
这些算法读取一个输入序列,将值写到一个输出序列中。
copy
copy(beg, end, dest); // 拷贝所有元素
copy_if(beg, end, dest, unaryPred); // 拷贝满足一元谓词 unaryPred 的元素
copy_n(beg, n, dest); // 拷贝前 n 个元素
move
对输入序列中的每个元素调用 std::move,将其移动到 dest 开始的序列中。
move(beg, end, dest);
transform
transform(beg, end, dest, unaryOp); // 对输入序列中的每个元素执行一元操作 unaryOp 并将结果写到 dest 中。
transform(beg, end, beg2, dest, binaryOp); // 对两个输入序列中的元素执行二元操作 binaryOp 并将结果写到 dest 中。
replace_copy
replace_copy(beg, end, dest, old_val, new_val); // 将每个元素拷贝到 dest,并将值为 old_val 的元素替换为 new_val。 replace_copy_if(beg, end, beg2, unaryPred, new_val); // 将每个元素拷贝到 dest,并将满足 unaryPread 的元素替换为 new_val。
merge
merge 的输入序列必须是有序的,将两个输入序列合并到 dest 中。
merge(beg1, end1, beg2, end2, dest); // 使用 < 运算符比较元素
merge(beg1, end1, beg2, end2, dest, comp); // 使用给定比较操作
使用前向迭代器的写算法
这些算法要求前向迭代器。
iter_swap
交换 iter1 和 iter2 所表示的元素
iter_swap(iter1, iter2); // 返回 void
swap_ranges
将输入范围内的所有元素与 beg2 开始的第二个序列中对应长度范围内的所有元素进行交换。两个范围不能有重叠
swap_ranges(beg1, end1, beg2); // 返回递增后的 beg2,指向最后一个交换元素之后的位置。
replace
replace(beg, end, old_val, new_val); // 将值为 old_val 的元素替换为 new_val。
replace_if(beg, end, unaryPred, new_val); // 将满足 unaryPread 的元素替换为 new_val。
使用双向迭代器的写算法
这些算法需要在序列中有反向移动的能力,因此需要双向迭代器。
copy_backward和move_backward
从输入范围内拷贝/移动元素到以 dest 为尾后迭代器的序列中的后半段。
copy_backward(beg, end, dest); // 如果输入序列表示的范围为空,则返回值为 dest,否则指向从 *beg 拷贝过来的元素
move_backward(beg, end, dest); // 如果输入序列表示的范围为空,则返回值为 dest,否则指向从 *beg 移动过来的元素
inplace_merge
将同一个序列中的两个有序子序列合并为单一的有序序列并写入到原序列中。两个有序子序列分别是从 beg 到 mid 和从 mid 到 end。
两个函数都返回 void。
inplace_merge(beg, mid, end); // 使用 < 比较元素
inplace_merge(beg, mid, end, comp); // 使用 comp 比较元素
A.2.5 划分与排序算法
每个排序和划分算法都提供稳定和不稳定版本。稳定算法保持相等元素的相对顺序。由于稳定算法要做更多的工作,可能会比不稳定版本慢得多,并消耗更多内存。
划分算法
一个划分算法将输入范围中的元素划分为两组。第一组包含满足给定谓词的元素,第二组则包含不满足谓词的元素。
is_partitioned
检查序列中是否满足谓词 unaryPred 的元素都位于不满足谓词的前面
is_partitioned(beg, end, unaryPred); // 满足或序列为空返回 true,否则返回 false
partition_copy
将输入序列中满足谓词 unaryPred 的元素拷贝到 dest1 开头的序列中,将不满足谓词的元素拷贝到 dest2 开头的序列中。输入序列与两个目的序列都不能重叠。
返回一个迭代器 pair,first 成员指向拷贝到 dest1 的元素的末尾,second 成员指向拷贝到 dest2 的元素的末尾。
partition_copy(beg, end, dest1, dest2, unaryPred);
partition_point
找到序列的划分点。输入序列必须是已经用 unaryPred 划分过的。
返回满足 unaryPred 的范围的尾后迭代器,如果都满足则返回 end。
partition_point(beg, end, unaryPred);
partition和stable_partition
使用谓词 unaryPred 划分输入序列,满足谓词的放前面,不满足的放后面。
返回一个迭代器,指向最后一个满足 unaryPred 的元素之后的位置。
stable_partition(beg, end, unaryPred);
partition(beg, end, unaryPred);
排序算法
每个排序算法提供两个重载的版本,第一个版本使用小于运算符比较元素,第二个版本接受一个额外参数来指定排序关系。
partial_sort 和 nth_sort 都只进行部分排序工作,常用于不需要排序整个序列的场合,通常比 sort 等排序整个序列的算法更快。
sort和stable_sort
返回 void
sort(beg, end); sort(beg, end, comp);
stable_sort(beg, end); stable_sort(beg, end, comp);
is_sorted
返回一个 bool 值,指出整个输入序列是否有序
is_sorted(beg, end);
is_sorted(beg, end, comp);
is_sorted_until
在输入序列中查找最长的初始有序子序列,并返回子序列的尾后迭代器。
is_sorted_until(beg, end);
is_sorted_until(beg, end, comp);
partial_sort
返回 void。
将序列中最小的 mid-beg 个元素有序放到 beg 与 mid 之间。后面的未排序部分元素的顺序是未指定的。
partial_sort(beg, mid, end);
partial_sort(beg, mid, end, comp);
partial_sort_copy
排序输入范围内的元素,并将已排序元素放到 destBeg 和 destEnd 所指示的序列中。
如果目的范围大小大于等于输入范围,则排序整个输入序列并存入从 destBeg 开始的范围。
如果目的范围大小小于输入范围,则只拷贝输入序列中与目的范围一样多的元素。
算法返回一个迭代器,指向目的范围中已排序部分的尾后迭代器。如果目的序列的大小小于或等于输入范围,则返回 destEnd。
partial_sort_copy(beg, end, destBeg, destEnd);
partial_sort_copy(beg, end, destBeg, destEnd, comp);
nth_element
功能概述:此函数可以获取特定元素在整个序列中大小排第几。
参数 nth 是一个迭代器,指向输入序列中的一个元素。
执行此函数后,迭代器 nth 指向的元素恰好是整个序列排好序后此位置上的值。
序列中的元素会围绕 nth 进行划分:nth 之前的元素都小于等于它,之后的元素都大于等于它。
nth_element(beg, nth, end);
nth_element(beg, nth, end, comp);
A.2.6 通用重排操作
这些算法重排输入序列中元素的顺序。
重排序列使第一部分的元素满足某种标准
remove
从序列中删除元素,方法是用保留的元素覆盖要删除的元素。
返回一个迭代器,指向最后一个删除元素的尾后位置。
remove(beg, end, val) //删除等于 val 的元素
remove_if(beg, end, unaryPred) //删除使一元谓词 unaryPred 为真的元素
remove_copy(beg, end, dest, val) //将重排后的元素放到从迭代器 dest 开始的序列中
remove_copy_if(beg, end, dest, unaryPred) //将重排后的元素放到从迭代器 dest 开始的序列中
unique
重排序列,对相邻的重复元素,通过覆盖它们来进行“删除”。unique 实际上是把后面的不重复元素向前复制,覆盖前面的重复元素,而不是把前面的重复元素移动到了后面,后面的元素实际上是没有变的。
注意:unique 处理的是相邻的重复元素,因此在使用 unique 前需要先对序列进行排序,以保证重复元素都相邻。
返回一个迭代器,指向不重复元素的尾后位置,即重排后的最后一个不重复元素的下一个元素。
unique(beg, end) //使用 == 检测相同元素
unique(beg, end, binaryPred) //使用二元谓词 binaryPred 检测相同元素
unique_copy(beg, end, dest) //将重排后的元素放到从迭代器 dest 开始的序列中
unique_copy_if(beg, end, dest, binaryPred) //将重排后的元素放到从迭代器 dest 开始的序列中
重排整个序列
rotate
围绕 mid 指向的元素进行转动。元素 mid 和 mid 之后的所有元素放到序列的前半段,beg 到 mid 之前的元素放到序列的后半段。
返回一个迭代器,指向原来在 beg 位置的元素。
rotate(beg, mid, end) rotate_copy(beg, mid, end, dest) //将重排后的元素放到从迭代器 dest 开始的序列中
reverse
翻转序列中的元素。
reverse 返回 void,reverse_copy 返回一个迭代器,指向拷贝到目的序列的元素的尾后位置。
reverse(beg, end)
reverse_copy(beg, end, dest)
random
随机重排元素。
返回 void
random_shuffle(beg, end)
random_shuffle(beg, end, rand) // rand 是一个可调用对象,它必须接受一个正整数值并生成从 0 到此值的区间内的一个服从均匀分布的随机整数 shuffle(beg, end, Uniform_rand) // Uniform_rand 必须满足均匀分布随机数生成器的要求。
A.2.9 最小值和最大值
注意:min 和 max 函数只能用于获取两个值或者一个 initializer_list 列表中的最小值/最大值。
要获取一个 vector/string 之类的容器中的最值,只能用 max_element 或 min_element 来获取对应的迭代器。
直接比较两个值
min 和 max
返回 val1 和 val2 中的最小值/最大值,或 initializer_list 中的最小值/最大值
min(val1, val2)
max(val1, val2)
min(val1, val2, comp)
max(val1, val2, comp)
min(init_list)
max(init_list)
min(init_list, comp)
max(init_list, comp)
minmax
返回一个 pair,pair 的 first 成员是较小的值,second 成员是较大的值
minmax(val1, val2)
minmax(val1, val2, comp)
minmax(init_list)
minmax(init_list, comp)
获取一个序列的最大值/最小值
min_element 和 max_element
返回指向最小元素/最大元素的迭代器
min_element(beg, end)
max_element(beg, end)
min_element(beg, end, comp)
max_element(beg, end, comp)
minmax_element
返回一个 pair
minmax_element(beg, end)
minmax_element(beg, end, comp)
字典序比较
返回 bool 值。按照字典顺序比较两个序列,即根据第一对不相等的元素的相对大小来返回结果。
如果第一个序列小于第二序列,返回 true;否则返回 false
lexicographical_compare(beg1, end1, beg2, end2)
lexicographical_compare(beg1, end1, beg2, end2, comp)
A.2.10 数值算法
数值算法定义在头文件 numeric 中
accumulate
求和:返回输入序列所有元素的和,和的初值为 init,返回类型与 init 类型相同。
accumulate(beg, end, init)
accumulate(beg, end, init, binaryOp) // 用二元操作 binaryOp 来代替加号
inner_product
求内积:返回两个序列的内积,即对应元素的积的和,和的初值为 init,返回类型与 init 类型相同。
inner_product(beg1, end1, beg2, init)
inner_product(beg1, end1, beg2, init, binOp1, binOp2) // 用两个二元操作 binOp1 和 binOp2 分别代替加法和乘法。
partial_sum
部分求和:依次对输入序列的前 k 个元素求和并将结果写入到 dest 开始的序列的第 k 个位置。
算法返回递增后的 dest 迭代器,指向最后一个写入元素之后的位置。
partial_sum(beg, end, dest);
partial_sum(beg, end, dest, binaryOp); // 使用二元操作 binaryOp 代替加号。
adjacent_difference
相邻求差:将输入位置中的每一个元素减去前一个元素并将结果写到 dest 开始的序列的对应位置。dest 的首元素除外。
adjacent_difference(beg, end, dest);
adjacent_difference(beg, end, dest, binaryOp); // 使用二元操作 binaryOp 代替加号。
iota
填充输入序列:以 val 为首元素,其后的元素依次递增。
iota(beg, end, val);
重复元素的迭代器,如果没有返回尾后迭代器。
adjacent_find(beg, end)
adjacent_find(beg, end, binaryPred)
search_n
返回一个迭代器,从此位置开始有 count 个相等元素。如果没有返回尾后迭代器。
search_n(beg, end, count ,val)
search_n(beg, end, count, val, binaryPred)
查找子序列的算法
search
返回第二个输入范围(子序列)在第一个输入范围中第一次出现的位置的迭代器。
search(beg1, end1, beg2, end2)
search(beg1, end1, beg2, end2, binaryPred)
find_first_of
返回第二个输入范围中任意元素在第一个范围中首次出现的位置的迭代器。
find_first_of(beg1, end1, beg2, end2)
find_first_of(beg1, end1, beg2, end2, binaryPred)
find_end
类似 search,但返回的是最后一次出现的位置
find_end(beg1, end1, beg2, end2)
find_end(beg1, end1, beg2, end2, binaryPred)
A.2.2 其他只读算法
for_each
对输入序列中的每个元素调用可调用对象 unaryOp
for_each(beg, end, unaryOp)
mismatch
比较两个序列中的元素,返回一个迭代器的 pair,指向两个序列中第一个不匹配的元素。如果都匹配,pair 中第一个迭代器是尾后迭代器
mismatch(beg1, end1, beg2)
mismatch(beg1, end1, beg2, binaryPred)
equal
返回 bool 值,如果两个序列相等返回 true
equal(beg1, end1, beg2)
equal(beg1, end1, beg2, binaryPred)
A.2.3 二分搜索算法
这些算法要求序列中的元素已经有序,它们的行为类似关联容器的同名成员。
每个算法都有两个版本,第一个版本使用小于运算符(<)来检测元素,第二个版本使用给定的比较操作。
lower_bound和upper_bound
返回一个迭代器。
lower_bound(beg, end, val); //返回一个迭代器表示第一个大于等于 val 的元素,如果没有这样的元素就返回 end
lower_bound(beg, end, val, comp);
upper_bound(beg, end, val); //返回一个迭代器表示第一个大于 val 的元素,如果没有这样的元素就返回 end
upper_bound(beg, end, val, comp);
equal_bound
返回一个 pair,它的 first 成员是 lower_bound 返回的迭代器,second 成员是 upper_bound 返回的迭代器。
equal_bound(beg, end, val);
equal_bound(beg, end, val, comp);
binary_search
返回一个 bool 值,指出序列中是否包含等于 val 的元素。
相等的判断:对于两个值,当 x 不小于 y 且 y 不小于 x 时,认为它们相等。
binary_search(beg, end, val);
binary_search(beg, end, val, comp);
A.2.4 写容器元素的算法
写容器元素的算法用来向给定序列中的元素写入新的值。
只写不读元素的算法
fill
fill 给输入序列中的每个元素赋予一个新值。
fill(beg, end, val); // 返回 void
fill_n(dest, cnt, val); // 返回一个迭代器,指向写到输出序列的最后一个元素之后的位置。
generate
generate 执行生成器对象 Gen() 生成新值并赋给输入序列中的每个元素。
生成器对象是一个可调用对象,每次调用都会生成一个不同的返回值。
generate(beg, end, val); // 返回 void
generate_n(dest, cnt, val); // 返回一个迭代器,指向写到输出序列的最后一个元素之后的位置。
使用输入迭代器的写算法
这些算法读取一个输入序列,将值写到一个输出序列中。
copy
copy(beg, end, dest); // 拷贝所有元素
copy_if(beg, end, dest, unaryPred); // 拷贝满足一元谓词 unaryPred 的元素
copy_n(beg, n, dest); // 拷贝前 n 个元素
move
对输入序列中的每个元素调用 std::move,将其移动到 dest 开始的序列中。
move(beg, end, dest);
transform
transform(beg, end, dest, unaryOp); // 对输入序列中的每个元素执行一元操作 unaryOp 并将结果写到 dest 中。
transform(beg, end, beg2, dest, binaryOp); // 对两个输入序列中的元素执行二元操作 binaryOp 并将结果写到 dest 中。
replace_copy
replace_copy(beg, end, dest, old_val, new_val); // 将每个元素拷贝到 dest,并将值为 old_val 的元素替换为 new_val。 replace_copy_if(beg, end, beg2, unaryPred, new_val); // 将每个元素拷贝到 dest,并将满足 unaryPread 的元素替换为 new_val。
merge
merge 的输入序列必须是有序的,将两个输入序列合并到 dest 中。
merge(beg1, end1, beg2, end2, dest); // 使用 < 运算符比较元素
merge(beg1, end1, beg2, end2, dest, comp); // 使用给定比较操作
使用前向迭代器的写算法
这些算法要求前向迭代器。
iter_swap
交换 iter1 和 iter2 所表示的元素
iter_swap(iter1, iter2); // 返回 void
swap_ranges
将输入范围内的所有元素与 beg2 开始的第二个序列中对应长度范围内的所有元素进行交换。两个范围不能有重叠
swap_ranges(beg1, end1, beg2); // 返回递增后的 beg2,指向最后一个交换元素之后的位置。
replace
replace(beg, end, old_val, new_val); // 将值为 old_val 的元素替换为 new_val。
replace_if(beg, end, unaryPred, new_val); // 将满足 unaryPread 的元素替换为 new_val。
使用双向迭代器的写算法
这些算法需要在序列中有反向移动的能力,因此需要双向迭代器。
copy_backward和move_backward
从输入范围内拷贝/移动元素到以 dest 为尾后迭代器的序列中的后半段。
copy_backward(beg, end, dest); // 如果输入序列表示的范围为空,则返回值为 dest,否则指向从 *beg 拷贝过来的元素
move_backward(beg, end, dest); // 如果输入序列表示的范围为空,则返回值为 dest,否则指向从 *beg 移动过来的元素
inplace_merge
将同一个序列中的两个有序子序列合并为单一的有序序列并写入到原序列中。两个有序子序列分别是从 beg 到 mid 和从 mid 到 end。
两个函数都返回 void。
inplace_merge(beg, mid, end); // 使用 < 比较元素
inplace_merge(beg, mid, end, comp); // 使用 comp 比较元素
A.2.5 划分与排序算法
每个排序和划分算法都提供稳定和不稳定版本。稳定算法保持相等元素的相对顺序。由于稳定算法要做更多的工作,可能会比不稳定版本慢得多,并消耗更多内存。
划分算法
一个划分算法将输入范围中的元素划分为两组。第一组包含满足给定谓词的元素,第二组则包含不满足谓词的元素。
is_partitioned
检查序列中是否满足谓词 unaryPred 的元素都位于不满足谓词的前面
is_partitioned(beg, end, unaryPred); // 满足或序列为空返回 true,否则返回 false
partition_copy
将输入序列中满足谓词 unaryPred 的元素拷贝到 dest1 开头的序列中,将不满足谓词的元素拷贝到 dest2 开头的序列中。输入序列与两个目的序列都不能重叠。
返回一个迭代器 pair,first 成员指向拷贝到 dest1 的元素的末尾,second 成员指向拷贝到 dest2 的元素的末尾。
partition_copy(beg, end, dest1, dest2, unaryPred);
partition_point
找到序列的划分点。输入序列必须是已经用 unaryPred 划分过的。
返回满足 unaryPred 的范围的尾后迭代器,如果都满足则返回 end。
partition_point(beg, end, unaryPred);
partition和stable_partition
使用谓词 unaryPred 划分输入序列,满足谓词的放前面,不满足的放后面。
返回一个迭代器,指向最后一个满足 unaryPred 的元素之后的位置。
stable_partition(beg, end, unaryPred);
partition(beg, end, unaryPred);
排序算法
每个排序算法提供两个重载的版本,第一个版本使用小于运算符比较元素,第二个版本接受一个额外参数来指定排序关系。
partial_sort 和 nth_sort 都只进行部分排序工作,常用于不需要排序整个序列的场合,通常比 sort 等排序整个序列的算法更快。
sort和stable_sort
返回 void
sort(beg, end); sort(beg, end, comp);
stable_sort(beg, end); stable_sort(beg, end, comp);
is_sorted
返回一个 bool 值,指出整个输入序列是否有序
is_sorted(beg, end);
is_sorted(beg, end, comp);
is_sorted_until
在输入序列中查找最长的初始有序子序列,并返回子序列的尾后迭代器。
is_sorted_until(beg, end);
is_sorted_until(beg, end, comp);
partial_sort
返回 void。
将序列中最小的 mid-beg 个元素有序放到 beg 与 mid 之间。后面的未排序部分元素的顺序是未指定的。
partial_sort(beg, mid, end);
partial_sort(beg, mid, end, comp);
partial_sort_copy
排序输入范围内的元素,并将已排序元素放到 destBeg 和 destEnd 所指示的序列中。
如果目的范围大小大于等于输入范围,则排序整个输入序列并存入从 destBeg 开始的范围。
如果目的范围大小小于输入范围,则只拷贝输入序列中与目的范围一样多的元素。
算法返回一个迭代器,指向目的范围中已排序部分的尾后迭代器。如果目的序列的大小小于或等于输入范围,则返回 destEnd。
partial_sort_copy(beg, end, destBeg, destEnd);
partial_sort_copy(beg, end, destBeg, destEnd, comp);
nth_element
功能概述:此函数可以获取特定元素在整个序列中大小排第几。
参数 nth 是一个迭代器,指向输入序列中的一个元素。
执行此函数后,迭代器 nth 指向的元素恰好是整个序列排好序后此位置上的值。
序列中的元素会围绕 nth 进行划分:nth 之前的元素都小于等于它,之后的元素都大于等于它。
nth_element(beg, nth, end);
nth_element(beg, nth, end, comp);
A.2.6 通用重排操作
这些算法重排输入序列中元素的顺序。
重排序列使第一部分的元素满足某种标准
remove
从序列中删除元素,方法是用保留的元素覆盖要删除的元素。
返回一个迭代器,指向最后一个删除元素的尾后位置。
remove(beg, end, val) //删除等于 val 的元素
remove_if(beg, end, unaryPred) //删除使一元谓词 unaryPred 为真的元素
remove_copy(beg, end, dest, val) //将重排后的元素放到从迭代器 dest 开始的序列中
remove_copy_if(beg, end, dest, unaryPred) //将重排后的元素放到从迭代器 dest 开始的序列中
unique
重排序列,对相邻的重复元素,通过覆盖它们来进行“删除”。unique 实际上是把后面的不重复元素向前复制,覆盖前面的重复元素,而不是把前面的重复元素移动到了后面,后面的元素实际上是没有变的。
注意:unique 处理的是相邻的重复元素,因此在使用 unique 前需要先对序列进行排序,以保证重复元素都相邻。
返回一个迭代器,指向不重复元素的尾后位置,即重排后的最后一个不重复元素的下一个元素。
unique(beg, end) //使用 == 检测相同元素
unique(beg, end, binaryPred) //使用二元谓词 binaryPred 检测相同元素
unique_copy(beg, end, dest) //将重排后的元素放到从迭代器 dest 开始的序列中
unique_copy_if(beg, end, dest, binaryPred) //将重排后的元素放到从迭代器 dest 开始的序列中
重排整个序列
rotate
围绕 mid 指向的元素进行转动。元素 mid 和 mid 之后的所有元素放到序列的前半段,beg 到 mid 之前的元素放到序列的后半段。
返回一个迭代器,指向原来在 beg 位置的元素。
rotate(beg, mid, end) rotate_copy(beg, mid, end, dest) //将重排后的元素放到从迭代器 dest 开始的序列中
reverse
翻转序列中的元素。
reverse 返回 void,reverse_copy 返回一个迭代器,指向拷贝到目的序列的元素的尾后位置。
reverse(beg, end)
reverse_copy(beg, end, dest)
random
随机重排元素。
返回 void
random_shuffle(beg, end)
random_shuffle(beg, end, rand) // rand 是一个可调用对象,它必须接受一个正整数值并生成从 0 到此值的区间内的一个服从均匀分布的随机整数 shuffle(beg, end, Uniform_rand) // Uniform_rand 必须满足均匀分布随机数生成器的要求。
A.2.9 最小值和最大值
注意:min 和 max 函数只能用于获取两个值或者一个 initializer_list 列表中的最小值/最大值。
要获取一个 vector/string 之类的容器中的最值,只能用 max_element 或 min_element 来获取对应的迭代器。
直接比较两个值
min 和 max
返回 val1 和 val2 中的最小值/最大值,或 initializer_list 中的最小值/最大值
min(val1, val2)
max(val1, val2)
min(val1, val2, comp)
max(val1, val2, comp)
min(init_list)
max(init_list)
min(init_list, comp)
max(init_list, comp)
minmax
返回一个 pair,pair 的 first 成员是较小的值,second 成员是较大的值
minmax(val1, val2)
minmax(val1, val2, comp)
minmax(init_list)
minmax(init_list, comp)
获取一个序列的最大值/最小值
min_element 和 max_element
返回指向最小元素/最大元素的迭代器
min_element(beg, end)
max_element(beg, end)
min_element(beg, end, comp)
max_element(beg, end, comp)
minmax_element
返回一个 pair
minmax_element(beg, end)
minmax_element(beg, end, comp)
字典序比较
返回 bool 值。按照字典顺序比较两个序列,即根据第一对不相等的元素的相对大小来返回结果。
如果第一个序列小于第二序列,返回 true;否则返回 false
lexicographical_compare(beg1, end1, beg2, end2)
lexicographical_compare(beg1, end1, beg2, end2, comp)
A.2.10 数值算法
数值算法定义在头文件 numeric 中
accumulate
求和:返回输入序列所有元素的和,和的初值为 init,返回类型与 init 类型相同。
accumulate(beg, end, init)
accumulate(beg, end, init, binaryOp) // 用二元操作 binaryOp 来代替加号
inner_product
求内积:返回两个序列的内积,即对应元素的积的和,和的初值为 init,返回类型与 init 类型相同。
inner_product(beg1, end1, beg2, init)
inner_product(beg1, end1, beg2, init, binOp1, binOp2) // 用两个二元操作 binOp1 和 binOp2 分别代替加法和乘法。
partial_sum
部分求和:依次对输入序列的前 k 个元素求和并将结果写入到 dest 开始的序列的第 k 个位置。
算法返回递增后的 dest 迭代器,指向最后一个写入元素之后的位置。
partial_sum(beg, end, dest);
partial_sum(beg, end, dest, binaryOp); // 使用二元操作 binaryOp 代替加号。
adjacent_difference
相邻求差:将输入位置中的每一个元素减去前一个元素并将结果写到 dest 开始的序列的对应位置。dest 的首元素除外。
adjacent_difference(beg, end, dest);
adjacent_difference(beg, end, dest, binaryOp); // 使用二元操作 binaryOp 代替加号。
iota
填充输入序列:以 val 为首元素,其后的元素依次递增。
iota(beg, end, val);