Unfolding the Alternating Optimization for Blind Super Resolution
Unfolding the Alternating Optimization for Blind Super Resolution
论文信息
- Paper: [NeurIPS2020] Unfolding the Alternating Optimization for Blind Super Resolution
- Link: https://papers.nips.cc/paper/2020/file/3d2d8ccb37df977cb6d9da15b76c3f3a-Paper.pdf
- Code: https://github.com/greatlog/DAN
背景梳理
超分辨率重建
基于图像的超分辨率重建任务(Single Image Super Resolution,SISR)是指对于一张给定的低分辨率图像(LR),重建出与之对应的高分辨率图像(HR)。也就是说,基于低分辨率图像都是由相应的高分辨率图像经过一些退化得到这样一个假设,用公式描述如下:
y = ( x ⊗ k ) ↓ s + n y = (x \otimes k)\downarrow_s + n y=(x⊗k)↓s+n
式中 x x x代表原始高分辨率图像, ⊗ \otimes ⊗表示二维卷积操作, k k k则代表了退化过程中的模糊核, n n n代表加性噪声, ↓ s \downarrow_s ↓s表示s倍的下采样操作。总而言之,上式假定了低分辨率图像是由原始高分辨率图像经由模糊下采样,以及加入噪声进行退化所得。
对于加性噪声的问题,通常会使用前端去噪任务进行滤除,所以在超分辨重建任务中一般不考虑噪声问题,而只考虑模糊和下采样带来的影响。显而易见,图像的超分辨率重建任务就是求上述退化过程的逆过程,但由于信息的缺失,使得超分辨率重建任务是一个ill-posed的任务,也即对于同一张低分辨率图像而言,存在多个可以退化产生该低分辨率图像的高分辨率图像。此外,由于式中存在多个变量,比如模糊核,高分辨率图像等,增加了优化的难度。目前绝大多数超分辨率重建方法,都是基于LR-HR对的监督学习方法。在构建数据集过程中,通常假设低分辨率图像是由高分辨率图像经由Bicubic下采样得到,也即求Bicubic下采样的逆过程,但为了更为贴合实际的退化情况,也有增加高斯模糊核,运动模糊的方法。
Blind Super Resolution
在上述的过程中,引入了一系列的先验假设,比如bicubic下采样,高斯模糊核等等,但在实际场景中,图像面临的退化情况远比上述假设要更为复杂,这使得基于人造数据集训练的超分网络在面对真实场景图像时,性能都会有较大的退化。所以,对于真实场景这一类,模糊核未知的超分辨率重建任务,称为Blind Super Resolution(Blind SR)。 针对Blind SR任务,一个最关键的步骤就是估计退化核 k k k,针对退化核估计的问题,目前有基于GAN使用Generator来模拟退化的工作,也有基于逐步校正的思路,在估计完退化核之后,再进行数据集生成或者将退化核作为超分辨重建网络的输入。
主要贡献
作者提出一种基于迭代优化的算法框架(Deep Alternating Network,DAN),同时端到端的完成退化核估计和超分辨率重建任务。具体而言:
- 通过迭代优化的思路,解决了分两步训练较慢且复杂的问题
- 在迭代中,充分利用重建信息,更好的完成模糊核估计和超分辨率重建
- 获得了SOTA的SISR任务性能
方法
迭代优化
正如在背景介绍中我们介绍的那样,我们要进行优化求解的未知参数有模糊核 k k k以及原始高分辨率图像 x x x,对于Blind SR任务而言,我们一般采用优化策略是先根据给定低分辨率图像估计出模糊核,然后在将模糊核代入上式求解原始高分辨率图像,如下式所示:
{ k = M ( y ) x = arg min x ∥ y − ( x ⊗ k ) ↓ s ∥ 1 + ϕ ( x ) \left\{\begin{array}{l} \mathrm{k}=M(\mathrm{y}) \\ \mathrm{x}=\underset{\mathrm{x}}{\arg \min }\left\|\mathrm{y}-(\mathrm{x} \otimes \mathrm{k}) \downarrow_{s}\right\|_{1}+\phi(\mathrm{x}) \end{array}\right. {k=M(y)x=xargmin∥y−(x⊗k)↓s∥1+ϕ(x)
显然,这种两步的优化方法在求解上是复杂不便的,第二点,模糊事实上是从清晰图到模糊图的一个过程,仅仅根据模糊图,是很难估计出正确的模糊核的,另外,第二阶段优化过程中使用了第一阶段估计出的模糊核,模糊核的估计误差会造成超分辨阶段性能的剧烈下降。针对上述问题,作者提出的基于迭代的优化方案如下式所示,网络迭代的分别对模糊核以及超分辨进行优化,这样可以有效利用两者之间的相关性,一方面提升模糊核估计的性能,另一方面降低超分辨重建对于模糊核准确性的过度依赖。
{ k i + 1 = arg min k ∥ y − ( x i ⊗ k ) ↓ s ∥ 1 x i + 1 = arg min x ∥ y − ( x ⊗ k i ) ↓ s ∥ 1 + ϕ ( x ) \left\{\begin{array}{l} \mathbf{k}_{i+1}=\underset{\mathbf{k}}{\arg \min }\left\|\mathbf{y}-\left(\mathbf{x}_{i} \otimes \mathbf{k}\right) \downarrow_{s}\right\|_{1} \\ \mathbf{x}_{i+1}=\underset{\mathbf{x}}{\arg \min }\left\|\mathbf{y}-\left(\mathbf{x} \otimes \mathbf{k}_{i}\right) \downarrow_{s}\right\|_{1}+\phi(\mathbf{x}) \end{array}\right. ⎩⎨⎧ki+1=kargmin∥y−(xi⊗k)↓s∥1xi+1=xargmin∥y−(x⊗ki)↓s∥1+ϕ(x)
Deep Alternating Network
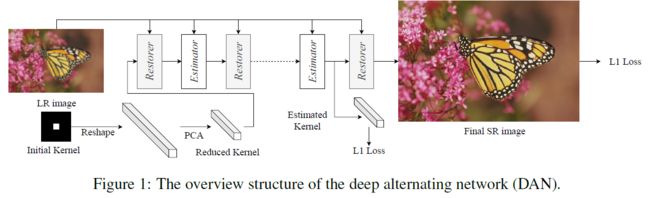
DAN模型框架如下图所示,主要由Restorer和Estimator两个模块组成,前者用于进行超分辨率重建,后者用于进行模糊核估计,两者交替优化模型参数。在每一次迭代中,Restorer或Estimator都具有两个输入,分别是LR以及Estimator或Restorer的输出。最终,只要进行模糊核等参数的初始化,网络就可以迭代的进行模糊核估计以及超分辨重建网络参数的优化,从而得到最终的重建高分辨率图像。
条件残差模块
因为整个超分辨网络是端到端的迭代训练,在进行退化核估计的阶段,网络输入是原始LR图像和SR图像,充分利用LR和高分辨率图像SR实现更加准确的模糊核估计;而在超分辨重建阶段,网络输入则变成了原始LR加上退化核信息。所以,无论是在退化核估计过程还是超分辨重建过程,其输入单元都是有两个部分,一个是始终存在原始LR,称为基础输入;另一个则被称为条件输入,在退化核估计阶段条件输入是估计出的SR图像,而超分辨重建阶段则是估计出的退化核。网络输出的结果与条件输入高度相关,且很容易验证框架的有效性,假如整个过程与条件输入无关,那么在第一次迭代结束后就会生成一个不变的解,因为只取决于基础输入LR。
针对上面提到网络输出高度依赖于条件输入的问题,为了增强网络对于条件输入的学习能力,作者提出了一个条件残差模块(Conditional Residual Block,CRB),将基础输入和条件输入进行拼接作为输入,将基础输入分支短接至输出,强调网络对条件输入的特征提取,计算公式如下:
f o u t = R ( C a t ( [ f b a s i c , f c o n d ] ) ) + f b a s i c f_{out} = R(Cat([f_{basic},f_{cond}]))+f_{basic} fout=R(Cat([fbasic,fcond]))+fbasic
R R R表示残差学习函数也即特征提取层, f b a s i c f_{basic} fbasic, f c o n d f_{cond} fcond分别表示基础输入和条件输入,总而言之,条件残差块由两个 3 × 3 3\times3 3×3卷积核的卷积层和一个 C h a n n e l A t t e n t i o n Channel Attention ChannelAttention层组成。
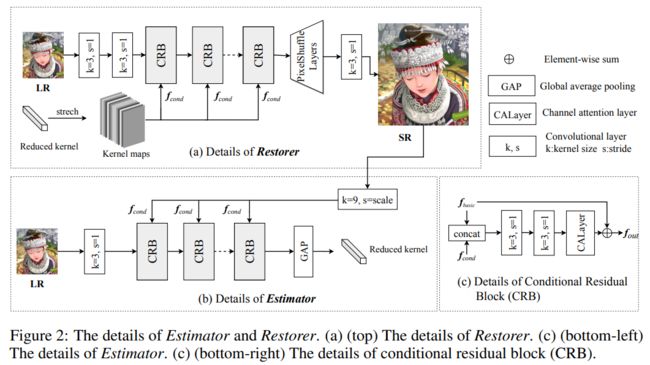
Restorer与Estimator
Restorer和Estimator都由一系列CRB组成。当进行超分辨率重建时,条件输入为经过主成分分析(PCA)提取主成分之后的模糊核,为了保证模糊核与基础输入LR的拼接,作者直接将模糊核的主成分进行空间尺度的复制从而保证与LR图像尺度一致;最终,使用PixelShuffle实现输出尺度的上采样。而当进行模糊核估计时,条件输入为Restorer预测的SR图像,为解决维度不一致的问题,作者使用 s t r i d e = s stride=s stride=s的卷积核将SR下采样至LR的相同尺度,然后送入CRB模块,最终计算全局平均池化,将池化后的结果视为经过PCA降维之后的模糊核。具体而言,作者在Estimator中使用了5个CRB,在Restorer中使用了40个CRB已实现超分辨率重建,Restorer与Estimator的结构如下图所示。
实验结果
数据集
作者选择了DIV2K和Flicker2K共3450张高分辨率图像进行训练,为了方便与其他方法进行对比,作者对高分辨率图像进行了两种退化处理。
- 第一种针对各向同性的高斯模糊核,训练过程从参数均匀分布的高斯模糊核中进行采样对图像进行退化,验证阶段从另一个分布中选定8个高斯模糊核,对测试集进行同样的退化处理,退化的过程是先模糊再下采样的方式。测试集选择了常用的Set5,Set14,BSD100,Urban100和Manga109数据集。
- 第二种针对各向异性的高斯模糊核,对核函数进行旋转,加躁和归一化等操作,测试时选择DIV2KRK数据集。
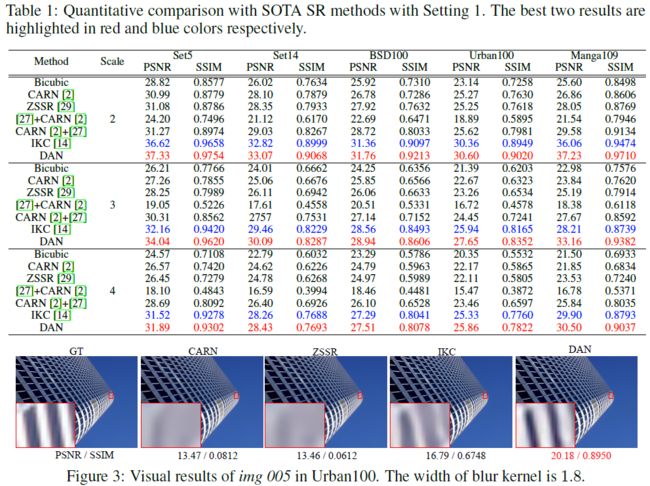
针对第一种退化设置,选择评价标准为Y通道的PSNR以及SSIM,实验结果如下,可以看到DAN模型与其他SISR相比,在多个放大尺度下取得了较大的提升。
针对第二种更为复杂但更通用的退化设置,作者进行了直接在Bicubic数据集训练、针对NTIRE Blind SR任务训练、以及使用退化核估计的方法分两步完成超分辨重建三种模式,分别命名为Class 1, Class 2, Class 3。可以看到,针对Blind SR任务而言,使用合适的退化核估计方法,确实能为超分辨重建带来增益,且作者提出的迭代方法,对于更为复杂的退化核,也取得了明显的提升。
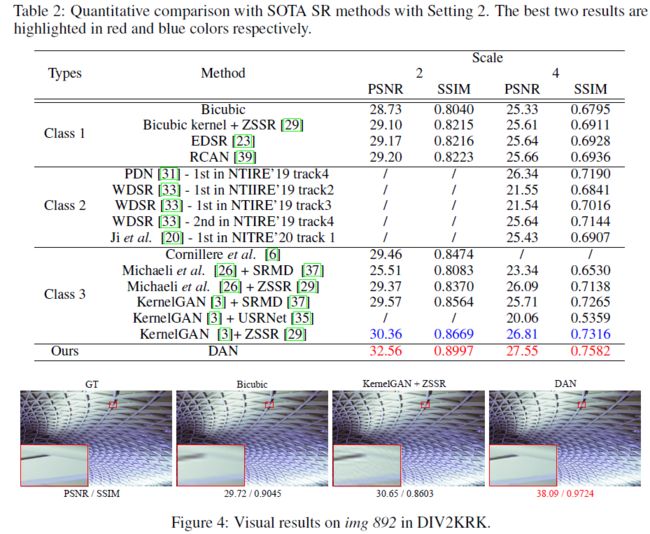
对于真实场景图像而言,由于不存在真实的高分辨图像,所以只能进行基于主观的视觉质量评价。具体超分辨重建结果如下:

最后,作者针对模糊核估计的有效性,交替迭代的次数对最终输出结果的影响,推断的速度进行了实验分析,具体请见论文。
分析与总结
近些年随着超分辨率重建任务在模型上的改进陷入了瓶颈,人们开始逐渐将注意力转移回数据本身。在面向真实场景时,除了增加数据集的多样性,缩小训练数据与真实数据的差异是一种有效的方法。在超分辨率重建任务中,退化过程尤其是模糊核是目前造成差异的主要原因,传统的退化核估计方法,存在着效率低,计算复杂,且不能充分利用监督信息的问题,本文提出一种基于迭代的端到端模糊核估计以及超分辨率重建框架,更有效的完成Blind SR任务,在多个数据集上取得了较大的提升。
参考文献
[1] Real-World Super-Resolution via Kernel Estimation and Noise Injection (CVPRW2020)
[2] Blind Super-Resolution Kernel Estimation using an Internal-GAN(NIPS2019)