kafka流数据
Disclaimer: I work at Google in the cloud team. Opinions are my own and not the views of my current employer.
免责声明:我在Google的云团队工作。 意见是我自己的,而不是我当前雇主的观点。
流分析 (Streaming analytics)
Many organizations are relying on the open-source streaming platform Kafka to build real-time data pipelines and applications.The same organizations are often looking to mordernize their IT landscape and adopt BigQuery to meet their growing analytics needs.By connecting the Kafka streaming data to the BigQuery analytics capabilities, these organizations can quickly analyze and activate data-derived insights as they happen, instead of waiting for a batch process to complete. This powerful combination enables real-time streaming analytics use cases such as fraud detection, inventory or fleet management, dynamic recommendations, predictive maintenance, capacity planning...
许多组织都依靠开源的流媒体平台卡夫卡建立实时数据管道和applications.The相同的组织往往希望mordernize他们的IT环境和采取的BigQuery ,以满足他们日益增长的分析 needs.By连接卡夫卡流数据利用BigQuery分析功能,这些组织可以在发生数据时快速分析和激活数据派生的见解,而不必等待批处理完成。 这种强大的组合可以实现实时流分析案例,例如欺诈检测,库存或车队管理,动态建议,预测性维护,容量规划等。
Lambda,Kappa和数据流 (Lambda, Kappa and Dataflow)
Organizations have been implementing the Lambda or Kappa architecture to support both batch and streaming data processing. But both of these architectures have some drawbacks. With Lambda for example, the batch and streaming sides each require a different code base. And with Kappa, everything is considered a stream of data, even large files have to be fed to the stream processing system and this can sometimes impact performance.
组织已经在实现Lambda或Kappa体系结构,以支持批处理和流数据处理。 但是这两种架构都有一些缺点。 以Lambda为例,批处理和流式处理各需要不同的代码库。 使用Kappa,所有内容都被视为数据流,即使大型文件也必须馈送到流处理系统,这有时会影响性能。

More recently (2015), Google published the Dataflow model paper which is a unified programming model for both batch and streaming. One could say that this model is a Lambda architecture but without the drawback of having to maintain two different code base.Apache Beam is the open source implementation of this model. Apache Beam supports many runners. In Google Cloud, Beam code runs best on the fully managed data processing service that shares the same name as the whitepaper linked above: Cloud Dataflow.
最近(2015年),Google发布了Dataflow模型文件,该文件是针对批处理和流传输的统一编程模型。 可以说这种模型是Lambda体系结构,但是没有必须维护两个不同代码库的缺点。 Apache Beam是此模型的开源实现。 Apache Beam支持许多跑步者 。 在Google Cloud中,Beam代码在完全托管的数据处理服务上运行效果最佳,该服务与上面链接的白皮书具有相同的名称: Cloud Dataflow 。
The following is a step-by-step guide on how to use Apache Beam running on Google Cloud Dataflow to ingest Kafka messages into BigQuery.
以下是有关如何使用在Google Cloud Dataflow上运行的Apache Beam将Kafka消息提取到BigQuery中的逐步指南。
环境设定 (Environment setup)
Let’s start by installing a Kafka instance.
让我们从安装Kafka实例开始。
Navigate to the Google Cloud Marketplace and search for “kafka”.In the list of solutions returned, select the Kafka solution provided by Google Click to Deploy as highlighted in blue in the picture below.
导航到Google Cloud Marketplace,然后搜索“ kafka”。在返回的解决方案列表中,选择Google提供的Kafka解决方案。 单击部署 ,如下图蓝色突出显示。

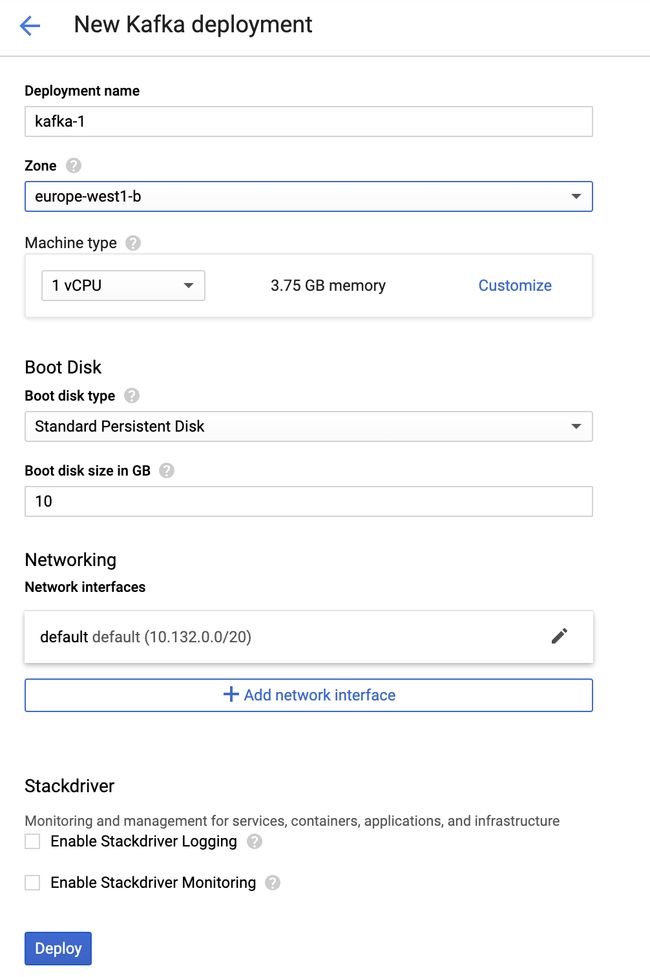
Pick your region/zone where you want your VM to be located, for example europe-west1-b Leave the default settings for everything else (unless you want to use a custom Network) and click “Deploy”.
选择您想要虚拟机所在的区域/区域,例如europe-west1-b b保留其他所有设置的默认设置(除非您要使用自定义网络),然后单击“部署”。
创建一个BigQuery表 (Create a BigQuery table)
While our VM is being deployed, let’s define a JSON schema and create our BigQuery table.It is usually best practice to create the BigQuery table before instead of having it created by the first Kafka message that arrives. This is because the first Kafka message might have some optional fields not set. So the BigQuery schema inferred from it using schema auto-detection, would be incomplete.
在部署VM时,让我们定义一个JSON模式并创建我们的BigQuery表。通常最好的做法是先创建BigQuery表,而不要使用到达的第一条Kafka消息来创建它。 这是因为第一条Kafka消息可能未设置某些可选字段。 因此,使用模式自动检测从中推断出的BigQuery模式将是不完整的。
Note that if your schema cannot be defined because it changes too frequently, having your JSON as a single String column inside BigQuery is definitely an option. You could then use JSON Functions to parse it.
请注意,如果由于架构更改过于频繁而无法定义其架构,则将BigQuery作为BigQuery中的单个String列来使用绝对是一种选择。 然后,您可以使用JSON函数进行解析。
For the purpose of this article, we will be creating a table storing sample purchase events of multiple products.In a file named schema.json copy/paste the following JSON:
就本文而言,我们将创建一个表来存储多个产品的样本购买事件。在一个名为schema.json的文件中,复制/粘贴以下JSON:
[
{
"description": "Transaction time",
"name": "transaction_time",
"type": "TIMESTAMP",
"mode": "REQUIRED"
},
{
"description": "First name",
"name": "first_name",
"type": "STRING",
"mode": "REQUIRED"
},
{
"description": "Last name",
"name": "last_name",
"type": "STRING",
"mode": "REQUIRED"
},
{
"description": "City",
"name": "city",
"type": "STRING",
"mode": "NULLABLE"
},
{
"description": "List of products",
"name": "products",
"type": "RECORD",
"mode": "REPEATED",
"fields": [
{
"description": "Product name",
"name": "product_name",
"type": "STRING",
"mode": "REQUIRED"
},
{
"description": "Product price",
"name": "product_price",
"type": "FLOAT64",
"mode": "NULLABLE"
}
]
}
]To create our empty BigQuery table, we would ideally use an IaC tool like Terraform triggered by a CI/CD system. But that is maybe a topic for another article, so let’s just use the bq mk command to create our dataset and table.
要创建空的BigQuery表,理想情况下,我们将使用CI / CD系统触发的IaC工具(例如Terraform) 。 但这可能是另一篇文章的主题,因此让我们仅使用bq mk命令创建数据集和表。
Open Cloud Shell and upload the schema.json you created earlier:
打开Cloud Shell并上传您之前创建的schema.json :

Then, run the following commands in Cloud Shell to create our timestamp partitioned table. Don’t forget to replace
然后,在Cloud Shell中运行以下命令以创建我们的时间戳分区表 。 不要忘记将以下
gcloud config set project
bq mk --location EU --dataset kafka_to_bigquery
bq mk --table \
--schema schema.json \
--time_partitioning_field transaction_time \
kafka_to_bigqueryInstead of using the
bq mkcommand, you can also create a dataset and a table using the BigQuery web UI.除了使用
bq mk命令,您还可以使用BigQuery Web UI创建数据集和表格。
发送信息给Kafka主题 (Send a message to a Kafka topic)
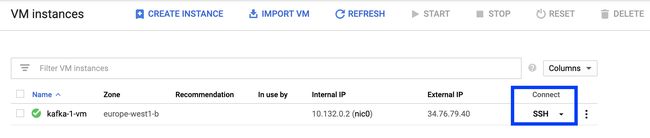
We are almost done with the environment setup! The final step is to create a Kafka topic and send a Kafka message to it. Navigate to the Google Cloud Console and open Compute Engine > VM instances. You should see our Kafka VM created earlier. Click the SSH button as highlighted in blue in the picture below.
我们几乎完成了环境设置! 最后一步是创建一个Kafka主题并向其发送Kafka消息。 导航到Google Cloud Console,然后打开Compute Engine> VM实例。 您应该看到我们之前创建的Kafka VM。 单击SSH按钮,如下图蓝色突出显示。
In the terminal window that opens, enter the following command to create our Kafka topic, named txtopic:
在打开的终端窗口中,输入以下命令以创建我们的Kafka主题,名为txtopic :
/opt/kafka/bin/kafka-topics.sh --create --zookeeper localhost:2181
--replication-factor 1
--partitions 1 --topic txtopicConfirm the topic has been created by listing the different topics. You should see txtopic being returned when entering the following command:
通过列出其他主题确认主题已创建。 输入以下命令时,应该看到返回了txtopic :
/opt/kafka/bin/kafka-topics.sh --list --zookeeper localhost:2181Let’s now imagine a purchase event to be sent to our topic. Using vi or nano in the SSH terminal, create the file called message.json and copy/paste the sample transaction below:
现在,让我们想象一个购买事件将发送到我们的主题。 在SSH终端中使用vi或nano ,创建名为message.json的文件,然后复制/粘贴以下示例事务:
{
"transaction_time": "2020-07-20 15:14:54",
"first_name": "John",
"last_name": "Smith",
"products": [
{
"product_name": "Pixel 4",
"product_price": 799.5
},
{
"product_name": "Pixel Buds 2",
"product_price": 179
}
]
}Finally, send your Kafka message to the txtopic with this command below. We append a Kafka message key and use jq to compact our JSON.
最后,使用以下命令将您的Kafka消息发送到txtopic 。 我们附加一个Kafka消息密钥,并使用jq压缩我们的JSON。
sudo apt-get install jq
(echo -n "1|"; cat message.json | jq . -c) | /opt/kafka/bin/kafka-console-producer.sh \
--broker-list localhost:9092 \
--topic txtopic \
--property "parse.key=true" \
--property "key.separator=|"方法1:使用数据流模板 (Method 1: Using a Dataflow template)
Now that our Kafka instance is running, let’s explore the first method to send our messages to BigQuery.
现在我们的Kafka实例正在运行,让我们探索将消息发送到BigQuery的第一种方法。
卡夫卡 (KafkaIO)
We will use Apache Beam built-in KafkaIO connector that can read from a Kafka topic.To use the KafkaIO connector, you can either implement your own data pipeline using the Beam Java SDK (since the release of Apache Beam 2.22, the KafkaIO connector is also available for the Beam Python SDK), or start from the Google-provided Dataflow template available here: https://github.com/GoogleCloudPlatform/DataflowTemplates/tree/master/v2/kafka-to-bigquery
我们将使用Apache Beam内置的KafkaIO连接器,该连接器可以从Kafka主题中读取。要使用KafkaIO连接器,您可以使用Beam Java SDK来实现自己的数据管道(因为Apache Beam 2.22的发行是,KafkaIO连接器是也可用于Beam Python SDK),或从此处提供的Google提供的数据流模板开始: https : //github.com/GoogleCloudPlatform/DataflowTemplates/tree/master/v2/kafka-to-bigquery

Dataflow Flex模板 (Dataflow Flex template)
The code linked above is using the new Dataflow templating mechanism called Dataflow Flex template which can turn any Dataflow pipeline into a template that can be reused by others. Flex templates are packaged using Docker. The first version of Dataflow templates, now called traditional templates, have some know limitations due to the fact that many Beam I/O’s don’t support runtime parameters using the ValueProvider interface.
上面链接的代码使用称为Dataflow Flex模板的新Dataflow模板化机制,该机制可以将任何Dataflow管道转换为可以被其他人重用的模板。 Flex模板使用Docker打包。 由于许多Beam I / O不使用ValueProvider接口支持运行时参数,因此Dataflow模板的第一个版本(现称为传统模板 )具有一些已知的局限性。
Note that Google provides another Kafka to BigQuery Dataflow Flex template example here. Maybe the two examples will be merged in the future?
请注意,Google 在此处提供了另一个Kafka to BigQuery Dataflow Flex模板示例。 也许这两个示例将来会合并?
打包数据流模板 (Packaging the Dataflow template)
In Cloud Shell copy/paste the following commands that will build and push the containerized template code to Container Registry (GCR). You can enable boost mode to make this step run faster.Make sure the GCR API is enabled for your project and don’t forget to replace
在Cloud Shell中,复制/粘贴以下命令,这些命令将构建并将容器化的模板代码推送到Container Registry (GCR)。 您可以启用增强模式以使此步骤更快地运行。确保为您的项目启用了GCR API,并且不要忘记用下面的GCP项目ID替换
git clone https://github.com/GoogleCloudPlatform/DataflowTemplates
cd DataflowTemplates/v2/export PROJECT=
export IMAGE_NAME=export TARGET_GCR_IMAGE=gcr.io/${PROJECT}/${IMAGE_NAME}
export BASE_CONTAINER_IMAGE=gcr.io/dataflow-templates-base/java8-template-launcher-base
export BASE_CONTAINER_IMAGE_VERSION=latest
export TEMPLATE_MODULE=kafka-to-bigquery
export APP_ROOT=/template/${TEMPLATE_MODULE}
export COMMAND_SPEC=${APP_ROOT}/resources/${TEMPLATE_MODULE}-command-spec.jsonmvn clean package -Dimage=${TARGET_GCR_IMAGE} \
-Dbase-container-image=${BASE_CONTAINER_IMAGE} \
-Dbase-container-image.version=${BASE_CONTAINER_IMAGE_VERSION} \
-Dapp-root=${APP_ROOT} \
-Dcommand-spec=${COMMAND_SPEC} \
-am -pl ${TEMPLATE_MODULE} ⚠️ Note that we cloned the master branch of the Git repository, and it could be that some instructions from the README file are now updated and don’t match the content of this article, written in July 2020.It’s probably best if you follow the updated README instructions then.
⚠️请注意,我们克隆了Git存储库的master分支,这可能是因为README文件中的一些指令现在已更新,并且与2020年7月撰写的本文内容不符。然后更新了README指令。
Next step is to create a Google Cloud Storage (GCS) bucket to store various artifacts that will be needed to run our template.Choose a name and replace
下一步是创建一个Google Cloud Storage(GCS)存储桶,以存储运行我们的模板所需的各种工件。在Cloud Shell中输入以下命令之前,请选择名称并替换下面的
export BUCKET_NAME=gs://
gsutil mb -l EU $BUCKET_NAME创建规格文件 (Creating the spec file)
To run a Dataflow Flex template, it is required to create a template spec file in GCS containing all of the necessary information to run the job.Let’s create a file named kafka-to-bigquery-image-spec.json with the following content. Don’t forget to edit
要运行Dataflow Flex模板,需要在GCS中创建一个模板规范文件,其中包含运行作业所需的所有必要信息。让我们创建一个名为kafka-to-bigquery-image-spec.json ,其内容如下。 保存文件之前,请不要忘记编辑
{
"image": "gcr.io//",
"sdk_info": {
"language": "JAVA"
}
} Then, run the following commands to upload the file to the bucket, and export the path to an environment variable that we will use later when we start the pipeline.
然后,运行以下命令将文件上传到存储桶,并将路径导出到环境变量,稍后启动管道时将使用该环境变量。
gsutil cp export TEMPLATE_IMAGE_SPEC=${BUCKET_NAME}/images/You can also generate the spec file using the command gcloud beta dataflow flex-template build as described in the documentation here.
您还可以使用命令gcloud beta dataflow flex-template build生成规范文件,如此处的文档所述。
管道参数 (Pipeline parameters)
In order to tell Dataflow where it should connect to, we can provide the Kafka IP address as a parameter to our Flex template.You can read this solution if your Kafka is not hosted on GCP.To use the Kafka installation we deployed earlier, navigate to the Google Cloud Console and open Compute Engine > VM instances. Note the internal IP of your Kafka VM and edit
为了告诉Dataflow它应该连接到哪里,我们可以提供Kafka IP地址作为Flex模板的参数。 如果您的Kafka未托管在GCP上,则可以阅读此解决方案 。要使用我们之前部署的Kafka安装,请导航至Google Cloud Console并打开Compute Engine> VM实例。 记下Kafka VM的内部IP,然后在下面编辑
export TOPICS=txtopic
export BOOTSTRAP=:9092 Our Flex template also supports adding a JavaScript UDF to specify a custom transform. The city field of our BigQuery schema is missing from the message.json above, so let’s try to add it. We won’t check for a specific transaction, so the code below adds the city of “New York” to all transactions.Create a file named my_function.js and copy/paste the following JavaScript code. Then upload the file to your GCS bucket created earlier.
我们的Flex模板还支持添加JavaScript UDF以指定自定义转换。 上面的message.json缺少BigQuery模式的city字段,因此让我们尝试添加它。 我们不会检查特定交易,因此以下代码将“ New York””城市添加到所有交易中。创建一个名为my_function.js的文件,然后复制/粘贴以下JavaScript代码。 然后将文件上传到之前创建的GCS存储桶。
function transform(inJson) {
var obj = JSON.parse(inJson);
obj.city = "New York";
return JSON.stringify(obj);
}Note that we added just one field to keep it simple but we can of course do much more in JavaScript. For example, one idea could be to compare the event time and the transaction time to capture late incoming events and maybe add a custom logic for those.
请注意,我们仅添加了一个字段以使其保持简单,但是我们当然可以在JavaScript中做更多的事情。 例如,一个想法可能是比较事件时间和交易时间以捕获迟到的事件,并可能为这些事件添加定制逻辑。
运行数据流模板 (Running the Dataflow template)
Finally, make sure the Dataflow API is enabled for your project and start the job with the following command. We specify the europe-west1 location, which is the Dataflow regional endpoint we decide to use in this example.If you want to use another region, it is a good idea to create your GCS bucket, your BigQuery dataset and your Kafka VM in the same region.
最后,确保为您的项目启用了Dataflow API,并使用以下命令启动作业。 我们指定europe-west1位置,这是我们在此europe-west1决定使用的数据流区域端点。如果要使用其他区域,则最好在该区域中创建GCS存储桶,BigQuery数据集和Kafka VM。同一地区。
export OUTPUT_TABLE=${PROJECT}:kafka_to_bigquery
export JS_PATH=${BUCKET_NAME}/my_function.js
export JS_FUNC_NAME=transformexport JOB_NAME="${TEMPLATE_MODULE}-`date +%Y%m%d-%H%M%S-%N`"
gcloud beta dataflow flex-template run ${JOB_NAME} \
--project=${PROJECT} --region=europe-west1 \
--template-file-gcs-location=${TEMPLATE_IMAGE_SPEC} \
--parameters ^~^outputTableSpec=${OUTPUT_TABLE}~inputTopics=${TOPICS}~javascriptTextTransformGcsPath=${JS_PATH}~javascriptTextTransformFunctionName=${JS_FUNC_NAME}~bootstrapServers=${BOOTSTRAP}A streaming job doesn’t need to be triggered on a regular schedule like a batch job. A streaming job runs indefinitely until it is stopped. So this one-time run command could be fired from a CI/CD system for example.
流作业无需像批处理作业一样定期触发。 流作业无限期运行,直到停止为止。 因此,例如可以从CI / CD系统中触发此一次性运行命令。
网页界面 (Web UI)
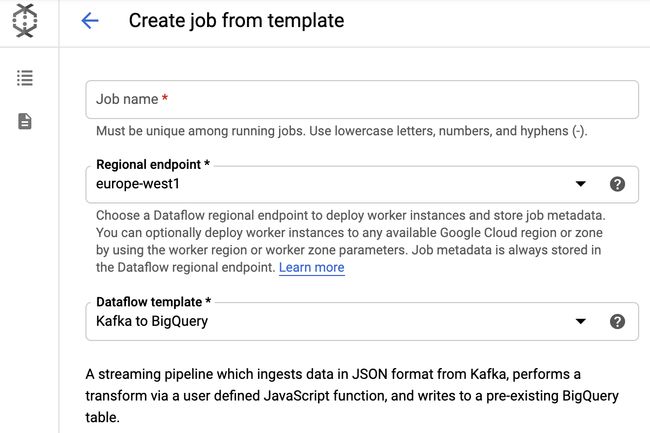
If you prefer, you can skip many of the steps above and just start the same Dataflow template directly via the Google Cloud Console web UI.To do so, navigate to the Google Cloud Console and open Dataflow > Create job from template. Then, select “Kafka to BigQuery” in the Dataflow template drop-down list. Finally, you can fill the form input fields with all the parameters that we set as environment variables in the instructions above.
如果愿意,可以跳过上述许多步骤,而直接通过Google Cloud Console Web UI直接启动相同的Dataflow模板,为此,请导航到Google Cloud Console并打开Dataflow>从模板创建作业。 然后,在数据流模板下拉列表中选择“从Kafka到BigQuery”。 最后,您可以在表单输入字段中填写我们在上述说明中设置为环境变量的所有参数。
结果 (Results)
Our streaming pipeline should now be running. To check if this is the case, navigate to Google Cloud Console > Dataflow. You should see your job in the list and its Status set to “Running”.
我们的流传输管道现在应该正在运行。 要检查这种情况,请导航至Google Cloud Console >数据流。 您应该在列表中看到您的工作,并且其状态设置为“正在运行”。

After a few seconds, Dataflow should start reading from your Kafka topic and you should see the results in BigQuery.Because the table is partitioned on the transaction_time field, make sure you query the 2020-07-20 partition (this is the transaction_time value we set in our message.json above).
几秒钟后,Dataflow应该开始从您的Kafka主题开始读取,并且应该在BigQuery中看到结果。由于该表已在transaction_time字段上进行分区,因此请确保查询2020-07-20分区(这是transaction_time值在上面的message.json设置)。
Note that streaming into partitioned tables has a few limits (as of July 2020).
请注意,流到分区表中有一些限制 (截至2020年7月)。
Here is the SQL command to retrieve the results. Feel free to try it but don’t forget to replace
这是用于检索结果SQL命令。 随时尝试,但不要忘记用您的GCP项目ID替换
SELECT * FROM `.kafka_to_bigquery.transactions` WHERE DATE(transaction_time) = “2020–07–20” 
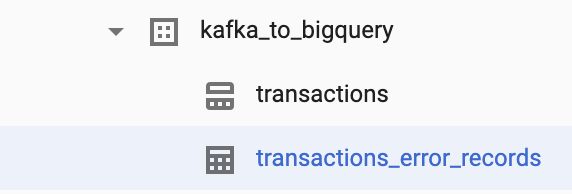
If you try to send wrongly formatted messages to the Kafka topic, the job should save the dead letter inputs to another table.
如果您尝试向Kafka主题发送格式错误的消息,则该作业应将死信输入保存到另一个表中。
Congratulations! You finished the first method of this article. Our Kafka messages are now being sent automatically to BigQuery.With Dataflow, there is another way to send Kafka messages to BigQuery, and below we will explore this second method.
恭喜你! 您完成了本文的第一种方法。 我们的Kafka消息现在会自动发送到BigQuery。有了Dataflow,还有另一种将Kafka消息发送到BigQuery的方法,下面我们将探讨第二种方法。
方法2:使用发布/订阅和数据流SQL (Method 2: Using Pub/Sub and Dataflow SQL)
The second method we are going to try is to send our Kafka messages to Cloud Pub/Sub and then query the Pub/Sub topic directly from BigQuery!Our two methods share some characteristics. Method 2 also uses Apache Beam running on Dataflow. But this time, the pipeline is written in SQL, using Beam SQL with the ZetaSQL dialect. So when you run a Dataflow SQL query, Dataflow turns the query into an Apache Beam pipeline and executes the pipeline.
我们要尝试的第二种方法是将Kafka消息发送到Cloud Pub / Sub ,然后直接从BigQuery查询Pub / Sub主题!这两种方法具有一些共同之处。 方法2还使用在Dataflow上运行的Apache Beam。 但是这次,管道是用SQL编写的,将Beam SQL与ZetaSQL方言结合使用。 因此,当您运行数据流SQL查询时,数据流会将查询转换为Apache Beam管道并执行该管道。
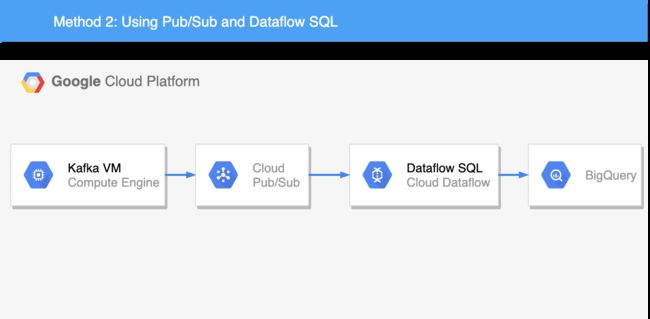
Organizations looking to adopt a Hybrid cloud architecture could for example run Kafka in their on-premises environment, and use Cloud Pub/Sub to produce and consume events on GCP.
希望采用混合云架构的组织可以在其本地环境中运行Kafka,并使用Cloud Pub / Sub在GCP上生成和使用事件。
开始之前 (Before we start)
If you have not already done so, follow the environment setup in the first part of this article. Once completed you should have:- deployed a Kafka VM- created a BigQuery table- created a Kafka topic- and sent a Kafka message to your topic.
如果尚未这样做,请按照本文第一部分中的环境设置进行操作。 完成后,您应该已经:-部署了Kafka虚拟机-创建了BigQuery表-创建了Kafka主题-并向您的主题发送了Kafka消息。
创建发布/订阅主题 (Create a Pub/Sub topic)
Navigate to the Google Cloud Console and open the Pub/Sub panel. Then, create a topic named txtopic.
导航到Google Cloud Console,然后打开“发布/订阅”面板。 然后,创建一个名为txtopic的主题。

创建服务帐户 (Create a Service Account)
Follow the “Pre-Running Steps” from the README here: https://github.com/GoogleCloudPlatform/pubsub/tree/master/kafka-connector
按照自述文件中的“运行前步骤”进行操作: https : //github.com/GoogleCloudPlatform/pubsub/tree/master/kafka-connector
These steps will guide you to create a Service Account and assign the Pub/Sub Admin role to it.You will have to create a JSON key for this Service Account and upload it to the Kafka VM (top right corner of the SSH window > Upload file).
这些步骤将指导您创建服务帐户并为其分配发布/订阅管理员角色。您将必须为此服务帐户创建JSON密钥并将其上传到Kafka VM(SSH窗口右上角>上载文件)。

Finally, set the following environment variable on your Kafka VM (via the SSH terminal). Replace /path/to/key/file below:
最后,在Kafka VM上(通过SSH终端)设置以下环境变量。 在下面替换/path/to/key/file :
export GOOGLE_APPLICATION_CREDENTIALS=/path/to/key/fileKafka Connect设置 (Kafka Connect setup)
We will use Kafka Connect to sync messages between Kafka and Cloud Pub/Sub.
我们将使用Kafka Connect在Kafka和Cloud Pub / Sub之间同步消息。
On the Kafka VM (via SSH), run the following commands to install the Cloud Pub/Sub connector:
在Kafka VM(通过SSH)上,运行以下命令以安装Cloud Pub / Sub连接器:
sudo apt install git-all
sudo apt install default-jdk
sudo apt install mavengit clone https://github.com/GoogleCloudPlatform/pubsub
cd pubsub/kafka-connector/
mvn packagesudo mkdir /opt/kafka/connectors
sudo cp target/cps-kafka-connector.jar /opt/kafka/connectors/
sudo cp config/cps-sink-connector.properties /opt/kafka/config/In the same SSH terminal, edit the cps-sink-connector.properties file that you just copied to the /opt/kafka/config/ directory.
在同一SSH终端中,编辑刚复制到/opt/kafka/config/目录中的cps-sink-connector.properties文件。
sudo vim /opt/kafka/config/cps-sink-connector.propertiesMake sure to edit the Kafka and Pub/Sub topic names as shown below. In this example, we took the same name for both: txtopic The snippet below shows how the file should look like. Replace
确保编辑Kafka和Pub / Sub主题名称,如下所示。 在此示例中,我们为两者使用了相同的名称: txtopic below以下代码段显示了文件的外观。 将下面的
name=CPSSinkConnector
connector.class=com.google.pubsub.kafka.sink.CloudPubSubSinkConnector
tasks.max=10
topics=txtopic
cps.topic=txtopic
cps.project=We have one more file to edit to complete the Kafka Connect setup:
我们还有一个文件需要编辑以完成Kafka Connect设置:
sudo vim /opt/kafka/config/connect-standalone.propertiesWe need to uncomment and edit the property plugin.path, so that Kafka Connect can locate the JAR file we packaged and copied earlier cps-kafka-connector.jar:
我们需要取消注释并编辑属性plugin.path ,以便Kafka Connect可以找到我们打包并复制了较早版本cps-kafka-connector.jar的JAR文件:
plugin.path=/opt/kafka/connectorsStill editing the connect-standalone.properties file, we need to set the following properties:
仍在编辑connect-standalone.properties文件,我们需要设置以下属性:
key.converter=org.apache.kafka.connect.storage.StringConverter
value.converter=org.apache.kafka.connect.storage.StringConverterkey.converter.schemas.enable=false
value.converter.schemas.enable=falseBy using
StringConverterwe tell the connector not to try to interpret the data and instead just forward the JSON as is to Cloud Pub/Sub.通过使用
StringConverter我们告诉连接器不要尝试解释数据,而只是将JSON原样转发到Cloud Pub / Sub。We also tell Kafka Connect not to look for a specific schema as explained here.
我们还告诉Kafka Connect不要按照此处的说明查找特定的架构。
运行Kafka Connect (Run Kafka Connect)
You can run Kafka Connect with the following command. Note the & symbol to instruct the command to run in a background process.
您可以使用以下命令运行Kafka Connect。 请注意&符号,以指示命令在后台进程中运行。
/opt/kafka/bin/connect-standalone.sh /opt/kafka/config/connect-standalone.properties /opt/kafka/config/cps-sink-connector.properties &As explained here, Kafka Connect is intended to be run as a service, and supports a REST API for managing connectors.You can check the current status of our Pub/Sub connector using the following command:
如此处所述 ,Kafka Connect旨在作为服务运行,并支持用于管理连接器的REST API。您可以使用以下命令检查Pub / Sub连接器的当前状态:
curl localhost:8083/connectors/CPSSinkConnector/status | jq云发布/订阅 (Cloud Pub/Sub subscription)
At this stage, our Kafka messages should now be forwarded to Cloud Pub/Sub. Let’s check!
在此阶段,我们的Kafka消息现在应该转发到Cloud Pub / Sub。 让我们检查!
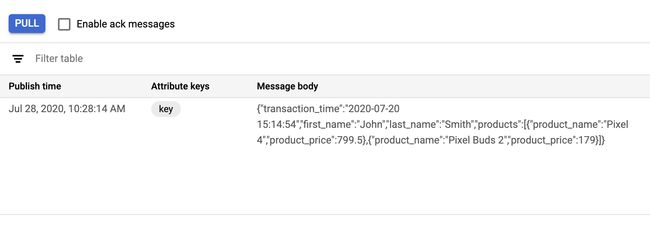
Create a Pub/Sub subscription to view the messages.
创建发布/订阅订阅以查看消息。
Navigate to the
导航到
Google Cloud Console and open Pub/Sub > Subscriptions > Create subscription.
Google云端控制台,然后打开发布/订阅>订阅>创建订阅。
Once your subscription is created, open the Subscriptions panel, click on your subscription, and click “View messages”. You should see your message(s) once you click “Pull”. If not, try to send another Kafka message using the
kafka-console-producer.shcommand from the environment setup section above.创建订阅后,打开“订阅”面板,单击您的订阅,然后单击“查看消息”。 单击“拉”后,您应该会看到您的消息。 如果不是,请尝试使用上述环境设置部分中的
kafka-console-producer.sh命令发送另一条Kafka消息。
发布/订阅到BigQuery模板 (Pub/Sub to BigQuery template)
If you clicked around in the Pub/Sub web UI, you might have seen that you can easily export a Pub/Sub topic to BigQuery.This export job uses a Dataflow template that is similar to our Method 1. But instead of using KafkaIO, this specific template uses PubsubIO Beam connector. We won’t cover this specific template in this article.
如果您在“发布/订阅” Web用户界面中单击,可能会发现可以轻松地将“发布/订阅”主题导出到BigQuery。此导出作业使用的数据流模板类似于我们的方法1。但是,不是使用KafkaIO,该特定模板使用PubsubIO Beam连接器。 我们不会在本文中介绍此特定模板。

BigQuery数据流引擎 (BigQuery Dataflow engine)
To ingest our Pub/Sub messages to BigQuery we will instead use Dataflow SQL.
要将发布/订阅消息接收到BigQuery,我们将改用Dataflow SQL。
The Dataflow SQL query syntax is similar to BigQuery standard SQL. You can also use the Dataflow SQL streaming extensions to aggregate data from continuously updating Dataflow sources like Pub/Sub.
Dataflow SQL查询语法类似于BigQuery标准SQL 。 您还可以使用Dataflow SQL流扩展来聚合来自不断更新的数据流源(例如发布/订阅)的数据。
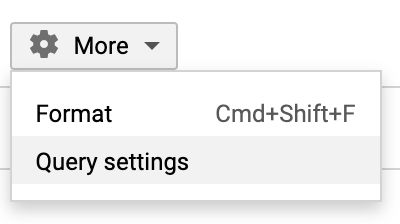
Navigate to the Google Cloud Console and open BigQuery. As shown in the screenshots below, click “More” > Query settings and select “Cloud Dataflow engine” as the Query engine.
导航到Google Cloud Console,然后打开BigQuery。 如下面的屏幕快照所示,单击“更多”>“查询设置”,然后选择“ Cloud Dataflow引擎”作为查询引擎。

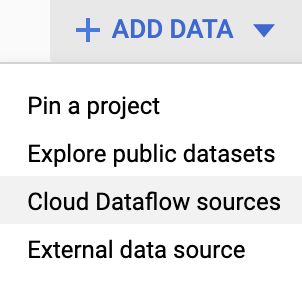
Once the Cloud Dataflow engine is selected, click “Add data” > Cloud Dataflow sources. Select your GCP project and the Pub/Sub topic we created earlier txtopic.
选择Cloud Dataflow引擎后,单击“添加数据”> Cloud Dataflow源。 选择您的GCP项目以及我们之前创建的Pub / Sub主题txtopic 。
发布/订阅主题架构 (Pub/Sub topic schema)
Now that we have added our Pub/Sub topic as a source, we need to assign a schema to it, as it is explained here. Click “Edit schema” and add the field types one by one, as shown in the screenshot below.
现在,我们已将Pub / Sub主题添加为源,我们需要为其分配一个架构,如此处所述 。 单击“编辑架构”,并一一添加字段类型,如下面的屏幕快照所示。

❗️This schema is a bit different from our BigQuery table schema.json:
❗️此架构与我们的BigQuery表schema.json有点不同:
The
cityfield is missing. We are not going to use a JavaScript UDF to solve this (as seen in Method 1). Instead we will add this field directly in SQL later.缺少
city字段。 我们不会使用JavaScript UDF解决此问题(如方法1所示)。 相反,稍后我们将直接在SQL中添加此字段。The
productsfield has a typeSTRUCT. The typeRECORDis not yet supported. See supported data types.products字段的类型为STRUCT。 尚不支持RECORD类型。 请参阅支持的数据类型 。The
transaction_timefield has a typeSTRING.transaction_time字段的类型为STRING。An
event_timestampfield is also added. This field is automatically added by Pub/Sub and you don’t need to modify ourmessage.json.还添加了一个
event_timestamp字段。 该字段由Pub / Sub自动添加,您无需修改我们的message.json。
运行数据流SQL作业 (Run the Dataflow SQL job)
We are ready to run our Dataflow SQL job. In the SQL editor, enter the following SQL code:
我们已经准备好运行我们的Dataflow SQL作业。 在SQL编辑器中,输入以下SQL代码:
SELECT *,"New York" as city FROM pubsub.topic..txtopic Replace city field here. Then click “Create Cloud Dataflow job”.
将上述SQL中的city字段。 然后单击“创建Cloud Dataflow作业”。
In the sliding panel that opens, choose a Regional endpoint for example in Europe (to be consistent with the rest of the services created in this article). And enter the following parameters:
在打开的滑动面板中,选择一个地区端点,例如在欧洲 (与本文中创建的其余服务一致)。 并输入以下参数:
Output type:
BigQuery输出类型:
BigQueryDataset ID:
kafka_to_bigquery. Let’s reuse the dataset we created earlier.数据集ID:
kafka_to_bigquery。 让我们重用我们先前创建的数据集。Table name:
transactions2. Let’s create a fresh table. Note that this table is not partitioned and will be created by the first Pub/Sub message that comes. In theory, it should be possible to reuse the BigQuery tabletransactionscreated for Method 1. But you would have to add theevent_timestampcolumn. Maybe it is a good idea to partition the table on that new field?表名称:
transactions2。 让我们创建一个新表。 请注意,此表未分区,将由随附的第一条Pub / Sub消息创建。 从理论上讲,应该可以重用为方法1创建的BigQuery表transactions。但是,您必须添加event_timestamp列。 将表分区到该新字段上也许是个好主意?
Leave the default settings for everything else and click “Create”.
保留其他所有设置的默认设置,然后单击“创建”。
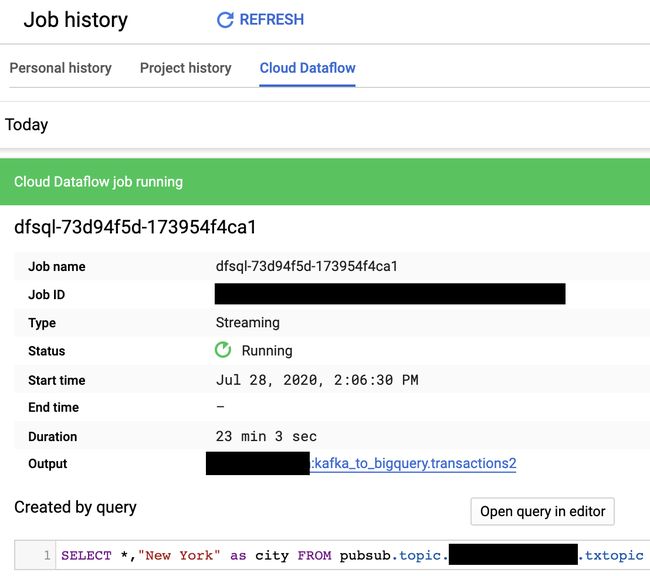
Your streaming job should now be running. To make sure it is indeed running, navigate to the Google Cloud Console and open BigQuery > Job history > Cloud Dataflow. You should see a streaming job running and your BigQuery table transactions2 should start being populated.
您的流作业现在应该正在运行。 为确保其确实在运行,请导航至Google Cloud Console,然后打开BigQuery>作业历史记录> Cloud Dataflow。 您应该看到流作业正在运行,并且BigQuery表transactions2应该开始填充。
You can try to send more Kafka messages using the kafka-console-producer.sh command (see environment setup section above). Then, check if the new messages eventually land into the transactions2 table.
您可以尝试使用kafka-console-producer.sh命令发送更多的Kafka消息(请参阅上面的环境设置部分)。 然后,检查新消息是否最终落入transactions2表中。
To query the BigQuery table, don’t forget to switch back the Query settings to “BigQuery engine” and enter the following SQL (replace
要查询BigQuery表,请不要忘记将查询设置切换回“ BigQuery engine”并输入以下SQL(将
SELECT * FROM `.kafka_to_bigquery.transactions2` 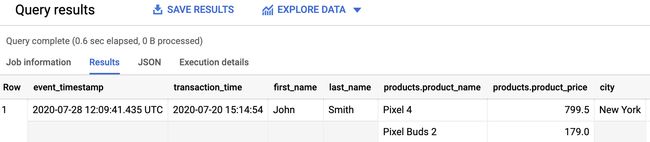
That’s the end of our Method 2! We successfully sent Kafka messages to BigQuery using Pub/Sub and Dataflow SQL.
这就是我们方法2的结尾! 我们已使用发布/订阅和数据流SQL成功将Kafka消息发送到BigQuery。
您应该使用哪种方法? (Which method should you use?)
Google Cloud has often more than one product you can use to achieve the same goal. For example, you would likely choose a different path if you want to optimize for rapid application development, or for scalability, or for cost…To evaluate different methods to ingest Kafka into BigQuery, here is a suggested list of criteria below:
Google Cloud通常可以使用多种产品来实现相同的目标。 例如,如果您要针对快速的应用程序开发,可伸缩性或成本进行优化,则可能会选择其他路径。要评估将Kafka提取到BigQuery中的不同方法,以下是建议的条件列表:
Maintenance: do you need to provision and take care of the underlying infrastructure?✅ Update: can you easily update an ongoing streaming job? Transform: does the solution support ETL, to transform the data before it lands into BigQuery? Collaboration: can the pipeline be version controlled? Rapid application development: how quickly can you develop a minimum viable product? Skills required: do you need to know a programming language? Scalability: what if you start pushing millions of Kafka messages per second? Dataflow supports streaming autoscaling. Dataflow Streaming Engine and Dataflow Shuffle provide a more responsive autoscaling. Flexibility: can it be tweaked to support different scenarios such as stateful processing, multiple inputs/outputs or tokenization for example with Cloud DLP? Price: how much would the solution cost? Dataflow service usage is billed in per second increments.⛔️ Dead letter: how well can it handle errors? Partitioning: can the pipeline create a different BigQuery partition based on a time or on a range? Portability: can the solution be moved to another cloud or run on-premises, and support a different sink with minimum changes? Beam is open source and has many connectors.
维护 :您是否需要提供和维护基础基础结构?✅ 更新 :您可以轻松地更新正在进行的流作业吗? 转换 :该解决方案是否支持ETL ,以便在数据降落到BigQuery之前对其进行转换? 协作 :可以对管道进行版本控制吗? application快速的应用程序开发 :您能以多快的速度开发出最低限度的可行产品? required所需技能 :您需要了解编程语言吗? 可伸缩性 :如果每秒开始推送数百万个Kafka消息怎么办? 数据流支持流式自动缩放 。 Dataflow Streaming Engine和Dataflow Shuffle提供了更灵敏的自动缩放。 灵活性 :是否可以进行调整以支持不同的方案,例如有状态处理,多个输入/输出或使用Cloud DLP进行令牌化? 价格 :解决方案的成本是多少? 数据流服务的使用按每秒增量计费。 Dead️死信 :如何处理错误? 分区 :管道可以基于时间或范围创建不同的BigQuery分区吗? 可移植性 :可以将解决方案移至其他云或在本地运行,并以最少的更改支持其他接收器吗? Beam是开源的,具有许多连接器 。
The list above is obviously not exhaustive and there are more criteria you could consider in your evaluation, such as: support for schema registry, schema evolution, orchestration, metrics, monitoring, testing, throughput, latency, windowing, ordering, joining topics, disaster recovery, etc.
上面的列表显然并不详尽,您可以在评估中考虑更多标准,例如:支持架构注册表,架构演进,业务流程,指标, 监控 , 测试 ,吞吐量,延迟, 窗口 ,排序,加入主题,灾难恢复等
其他支持的方法 (Other supported methods)
Dataflow is not the only way to send Kafka messages to BigQuery and there are many other methods, all with their pros and cons.
数据流并不是将Kafka消息发送到BigQuery的唯一方法,还有许多其他方法,各有其优缺点。
Here is a list of 3 other methods that are well supported:
下面列出了其他3种受支持的方法:
方法3 (Method 3)
Cloud Data Fusion is a fully managed, code-free data integration service that helps users efficiently build and manage ETL/ELT data pipelines. It is built with an open source core (CDAP) for pipeline portability.
Cloud Data Fusion是一项完全托管的,无需代码的数据集成服务,可帮助用户有效地构建和管理ETL / ELT数据管道。 它使用开放源代码内核( CDAP )构建,以实现管道可移植性。
GitHub link to the Kafka plugin: https://github.com/data-integrations/kafka-plugins
GitHub链接到Kafka插件: https : //github.com/data-integrations/kafka-plugins

方法4 (Method 4)
Fivetran offers cloud-based, zero-maintenance ETL/ELT data pipelines that can load all your raw Apache Kafka data into Google BigQuery and continuously update it.Fivetran supports 150+ connectors that automatically adapt to schema and API changes. This method is particularly interesting if Kafka is not your only data source and you have 10, 20, … 100 or more pipelines to build to ingest data from various sources into BigQuery. Look for “fivetran” in the Google Cloud Marketplace.
Fivetran提供了基于云的零维护ETL / ELT数据管道,可以将所有原始Apache Kafka数据加载到Google BigQuery中并不断进行更新.Fivetran支持150多个连接器 ,这些连接器可以自动适应模式和API更改。 如果Kafka不是您唯一的数据源,并且您有10、20,…100或更多的管道要构建以将来自各种来源的数据提取到BigQuery中,则此方法特别有趣。 在Google Cloud Marketplace中寻找“ fivetran”。

方法5 (Method 5)
Founded by the team that originally created Apache Kafka, Confluent provides a connector to send Kafka messages to BigQuery.
由最初创建Apache Kafka的团队创建,Confluent提供了一个连接器,用于将Kafka消息发送到BigQuery 。
This method is unmatched if your organization is also looking for a robust, cloud-based, fully managed Kafka as a Service option. Confluent Cloud provides a simple, scalable, resilient, and secure event streaming platform so your organization can focus on building apps and not managing Kafka clusters.
如果您的组织也正在寻找健壮的,基于云的,完全托管的Kafka即服务选项,则此方法是无与伦比的。 Confluent Cloud提供了一个简单,可扩展,有弹性和安全的事件流平台,因此您的组织可以专注于构建应用程序,而不必管理Kafka集群。
Confluent has built a complete streaming platform that includes:
Confluent已构建了一个完整的流媒体平台,其中包括:
- Managed connectors 托管连接器
KSQL for real-time event processing
用于实时事件处理的KSQL
- Managed Schema Registry to ensure data compatibility 托管架构注册表以确保数据兼容性
Confluent Replicator which can replicate topics from one Kafka cluster to another. This product can help support Hybrid or Multicloud scenarios for example.
Confluent Replicator可以将主题从一个Kafka集群复制到另一个集群。 例如,该产品可以帮助支持混合或多云方案。
and many more features… read more about Project Metamorphosis.
以及更多功能...阅读有关Project Metamorphosis的更多信息。
Look for “confluent” in the Google Cloud Marketplace to get started.
在Google Cloud Marketplace中寻找“融合”以开始使用。


Thanks for reading!Feel free to connect on Twitter @tdelazzari
感谢您的阅读!随时在Twitter @tdelazzari上进行连接
翻译自: https://medium.com/google-cloud/kafka-to-bigquery-using-dataflow-6ec73ec249bb
kafka流数据