《PySpark大数据分析实战》-13.Spark on YARN模式代码运行流程
博主简介
- 作者简介:大家好,我是wux_labs。
热衷于各种主流技术,热爱数据科学、机器学习、云计算、人工智能。
通过了TiDB数据库专员(PCTA)、TiDB数据库专家(PCTP)、TiDB数据库认证SQL开发专家(PCSD)认证。
通过了微软Azure开发人员、Azure数据工程师、Azure解决方案架构师专家认证。
对大数据技术栈Hadoop、Hive、Spark、Kafka等有深入研究,对Databricks的使用有丰富的经验。- 个人主页:wux_labs,如果您对我还算满意,请关注一下吧~
- 个人社区:数据科学社区,如果您是数据科学爱好者,一起来交流吧~
- 请支持我:欢迎大家 点赞+收藏⭐️+吐槽,您的支持是我持续创作的动力~
《PySpark大数据分析实战》-13.Spark on YARN模式代码运行流程
- 《PySpark大数据分析实战》-13.Spark on YARN模式代码运行流程
-
- 前言
- Spark on YARN模式代码运行流程
-
- YARN Client模式代码运行流程
- YARN Cluster模式代码运行流程
- 结束语
《PySpark大数据分析实战》-13.Spark on YARN模式代码运行流程
前言
大家好!今天为大家分享的是《PySpark大数据分析实战》第2章第4节的内容:Spark on YARN模式代码运行流程。
图书在:当当、京东、机械工业出版社以及各大书店有售!
Spark on YARN模式代码运行流程
提交Spark应用程序运行,当master指定为yarn的时候,还可以指定另外一个选项:–deploy-mode,该选项支持两个选项client和cluster,当不指定该选项时默认是client。在client模式下,会在执行spark-submit命令的客户端启动Spark的Driver进程,所有Driver的操作都在客户端执行,比如在Driver进行print打印,print的结果会在客户端,YARN的Web界面上无法从日志中找到print的结果。在cluster模式下,YARN会进行资源调度,选择集群中的一个节点作为Spark的Master,在该节点启动Driver进程,Driver的操作都在该节点上执行,比如在Driver进行print打印,print的结果会在该节点的日志中,通过YARN的Web界面查看日志可以看到print的结果,而在执行spark-submit命令的客户端则看不到print的结果。
YARN Client模式代码运行流程
YARN Client模式的代码运行流程如图所示。
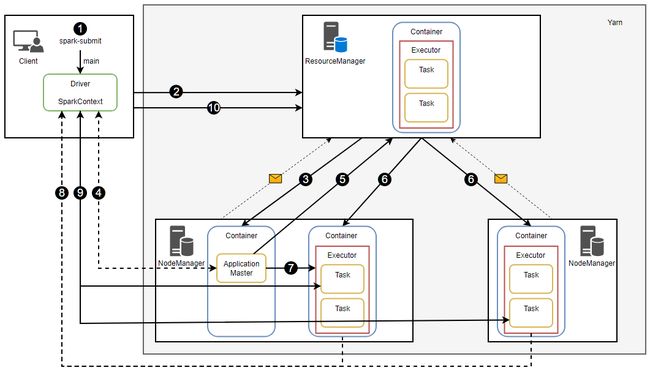
![]() :在YARN集群启动后,NodeManager定期向ResourceManager汇报节点的资源信息、任务运行状态、健康信息等。
:在YARN集群启动后,NodeManager定期向ResourceManager汇报节点的资源信息、任务运行状态、健康信息等。
1:客户端通过spark-submit提交应用程序运行,首先会执行程序中的main()函数,在客户端启动Driver进程。
2:Driver进程启动后,会实例化SparkContext,SparkContext会向YARN集群的ResourceManager注册并申请ApplicationMaster。
3:ResourceManager收到请求后,会分配在一个资源满足条件的节点,该节点启动第1个Container容器,启动ApplicationMaster。
4:ApplicationMaster启动后,会与Driver中的SparkContext进行通信,获取任务信息等。
5:ApplicationMaster根据任务信息,向ResourceManager请求所需的资源。
6:ResourceManager根据申请分配资源,在集群的节点上启动Container。
7:ApplicationMaster获取到资源后,与NodeManager通信,并请求在Container中启动Executor。
8:Executor启动成功后,会反向注册到SparkContext,并申请Task。
9:SparkContext会向Executor分配Task,并与Executor保持通信,Executor会向Driver汇报Task的执行状态和进度,Driver掌握了Task的情况后可以在任务失败时重启任务。
10:当应用程序所有Task都执行完成, SparkContext会向ResourceManager注销自己,ResourceManager可以回收已分配的资源。
YARN Cluster模式代码运行流程
YARN Cluster模式的代码运行流程如图所示。
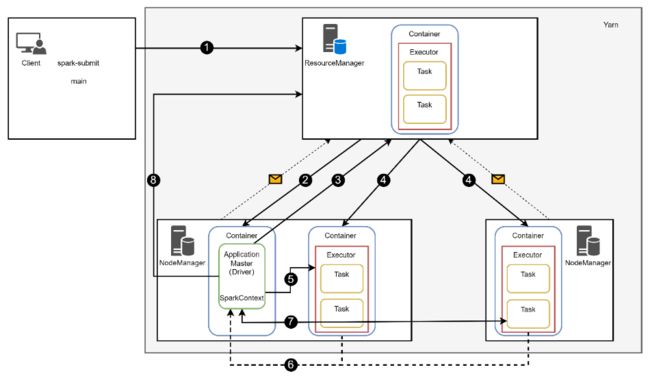
![]() :在YARN集群启动后,NodeManager定期向ResourceManager汇报节点的资源信息、任务运行状态、健康信息等。
:在YARN集群启动后,NodeManager定期向ResourceManager汇报节点的资源信息、任务运行状态、健康信息等。
1:客户端通过spark-submit提交应用程序运行,首先会执行程序中的main()函数,并向ResourceManager申请ApplicationMaster。
2:ResourceManager收到请求后,会分配在一个资源满足条件的节点,该节点启动第1个Container容器,启动ApplicationMaster,并启动SparkContext,Cluster模式下Driver与ApplicationMaster合为一体。
3:ApplicationMaster启动后会根据任务信息向ResourceManager请求资源。
4:ResourceManager根据申请分配资源,在集群的节点上启动Container。
5:ApplicationMaster获取到资源后,与NodeManager通信,并请求在Container中启动Executor。
6:Executor启动成功后,会反向注册到SparkContext,并申请Task。
7:SparkContext会向Executor分配Task,并与Executor保持通信,Executor会向ApplicationMaster汇报Task的执行状态和进度,ApplicationMaster掌握了Task的情况后可以在任务失败时重启任务。
8:当应用程序所有Task都执行完成, SparkContext会向ResourceManager注销自己,ResourceManager可以回收已分配的资源。
结束语
好了,感谢大家的关注,今天就分享到这里了,更多详细内容,请阅读原书或持续关注专栏。