快手数仓面试题附答案
题目
- 1 讲一下你门公司的大数据项目架构?
- 2 你在工作中都负责哪一部分
- 3 spark提交一个程序的整体执行流程
- 4 spark常用算子列几个,6到8个吧
- 5 transformation跟action算子的区别
- 6 map和flatmap算子的区别
- 7 自定义udf,udtf,udaf讲一下这几个函数的区别,编写的时候要继承什么类,实现什么方法
- 8 hive创建一个临时表有哪些方法
- 9 讲一下三范式,三范式解决了什么问题,有什么优缺点
- 10 讲一下维度建模的过程
- 11 维度表有哪几种
- 12 事实表有几种
- 13 什么是维度一致性,总线架构,事实一致性
- 15 什么是拉链表,如何实现?
- 16 什么是微型维度、支架表,什么时候会用到
- 17 讲几个你工作中常用的spark 或者hive 的参数,以及这些参数做什么用的
- 18 工作中遇到数据倾斜处理过吗?是怎么处理的,针对你刚刚提的方案讲一下具体怎么实现。用代码实现,以及用sql实现。
- 19 讲一下kafka对接flume 有几种方式。
- 20 讲一下spark是如何将一个sql翻译成代码执行的,里面的原理介绍一下?
- 21 spark 程序里面的count distinct 具体是如何执行的
- 22 不想用spark的默认分区,怎么办?(自定义Partitioner 实现里面要求的方法 )具体是哪几个方法?
- 23 有这样一个需求,统计一个用户的已经曝光了某一个页面,想追根溯是从哪几个页面过来的,然后求出在这几个来源所占的比例。你要怎么建模处理?
- 23 说一下你对元数据的理解,哪些数据算是元数据
- 24 有过数据治理的经验吗?
- 25 说一下你门公司的数据是怎么分层处理的,每一层都解决了什么问题
- 26 讲一下星型模型和雪花模型的区别,以及应用场景
答案
1 讲一下你门公司的大数据项目架构?
实时流和离线计算两条线
数仓输入(客户端日志,服务端日志,数据库)
传输过程(flume,kafka)
数仓输出(报表,画像,推荐等)
2 你在工作中都负责哪一部分
3 spark提交一个程序的整体执行流程
包括向yarn申请资源、DAG切割、TaskScheduler、执行task等过程
4 spark常用算子列几个,6到8个吧
常用的RDD转换算子:
- filter(func) 筛选出满足函数func的元素,并返回一个新的数据集
- map(func) 将每个元素传递到函数func中,并将结果返回为一个新的数据集
- flatMap(func) 与map()相似,但每个输入元素都可以映射到0或多个输出结果
- groupByKey() 应用于(K,V)键值对的数据集时,返回一个新的(K, Iterable)形式的数据集
- reduceByKey(func) 应用于(K,V)键值对的数据集时,返回一个新的(K, V)形式的数据集,其中每个值是将每个key传递到函数func中进行聚合后的结果
行动操作常用算子:
- count() 返回数据集中的元素个数
- collect() 以数组的形式返回数据集中的所有元素
- first() 返回数据集中的第一个元素
- take(n) 以数组的形式返回数据集中的前n个元素
- reduce(func) 通过函数func(输入两个参数并返回一个值)聚合数据集中的元素
- foreach(func) 将数据集中的每个元素传递到函数func中运行
5 transformation跟action算子的区别
所有的transformation都是采用的懒策略,就是如果只是将transformation提交是不会执行计算的,计算只有在action被提交的时候才被触发。
- Transformation 变换/转换:这种变换并不触发提交作业,完成作业中间过程处理。Transformation 操作是延迟计算的,也就是说从一个RDD 转换生成另一个 RDD 的转换操作不是马上执行,需要等到有 Action 操作的时候才会真正触发运算。
- Action 行动算子:这类算子会触发 SparkContext 提交 Job 作业。
Action 算子会触发 Spark 提交作业(Job)。
transformation操作:
- map(func):对调用map的RDD数据集中的每个element都使用func,然后返回一个新的RDD,这个返回的数据集是分布式的数据集
- filter(func): 对调用filter的RDD数据集中的每个元素都使用func,然后返回一个包含使func为true的元素构成的RDD
- flatMap(func):和map差不多,但是flatMap生成的是多个结果
- mapPartitions(func):和map很像,但是map是每个element,而mapPartitions是每个partition
- mapPartitionsWithSplit(func):和mapPartitions很像,但是func作用的是其中一个split上,所以func中应该有index
- sample(withReplacement,faction,seed):抽样
- union(otherDataset):返回一个新的dataset,包含源dataset和给定dataset的元素的集合
- distinct([numTasks]):返回一个新的dataset,这个dataset含有的是源dataset中的distinct的element
- groupByKey(numTasks):返回(K,Seq[V]),也就是hadoop中reduce函数接受的key-valuelist
- reduceByKey(func,[numTasks]):就是用一个给定的reducefunc再作用在groupByKey产生的(K,Seq[V]),比如求和,求平均数
- sortByKey([ascending],[numTasks]):按照key来进行排序,是升序还是降序,ascending是boolean类型
- join(otherDataset,[numTasks]):当有两个KV的dataset(K,V)和(K,W),返回的是(K,(V,W))的dataset,numTasks为并发的任务数
- cogroup(otherDataset,[numTasks]):当有两个KV的dataset(K,V)和(K,W),返回的是(K,Seq[V],Seq[W])的dataset,numTasks为并发的任务数
- cartesian(otherDataset):笛卡尔积就是m*n,大家懂的
action操作:
- reduce(func):说白了就是聚集,但是传入的函数是两个参数输入返回一个值,这个函数必须是满足交换律和结合律的
- collect():一般在filter或者足够小的结果的时候,再用collect封装返回一个数组
- count():返回的是dataset中的element的个数
- first():返回的是dataset中的第一个元素
- take(n):返回前n个elements,这个士driverprogram返回的
- takeSample(withReplacement,num,seed):抽样返回一个dataset中的num个元素,随机种子seed
- saveAsTextFile(path):把dataset写到一个textfile中,或者hdfs,或者hdfs支持的文件系统中,spark把每条记录都转换为一行记录,然后写到file中
- saveAsSequenceFile(path):只能用在key-value对上,然后生成SequenceFile写到本地或者hadoop文件系统
- countByKey():返回的是key对应的个数的一个map,作用于一个RDD
- foreach(func):对dataset中的每个元素都使用func
参考:Spark常用算子详解_spark算子-CSDN博客
6 map和flatMap算子的区别
- map:执行完map后会得到一个新的分布式数据集,数据集中每个元素是之前的RDD映射得来的,与之前RDD每个元素存在一一对应的关系。
- flatmap:而flatmap有一点不同,每个输入的元素可以被映射为0个或者多个输出的元素,原RDD与新RDD的元素是一对多的关系。当然光看定义比较抽象,下面用一个图说明,
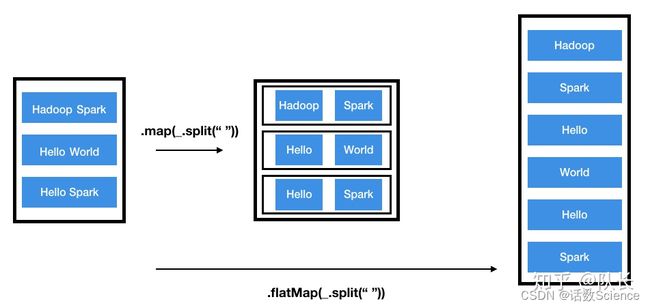
参考:Spark之Map VS FlatMap - 知乎
7 自定义udf,udtf,udaf讲一下这几个函数的区别,编写的时候要继承什么类,实现什么方法
区别:
- UDF:输入一行,输出一行
UDF:用户定义(普通)函数,只对单行数值产生作用; - UDTF:输入一行,输出多行,类似explode函数
UDTF:User-Defined Table-Generating Functions,用户定义表生成函数,用来解决输入一行输出多行; - UDAF:输入多行,输出一行,类似聚合函数
UDAF:User- Defined Aggregation Funcation;用户定义聚合函数,可对多行数据产生作用;等同与SQL中常用的SUM(),AVG(),也是聚合函数;
Hive实现:
| 类型 | 类 | 方法 |
| UDF | 类: GenericUDF
|
initialize:类型检查,返回结果类型 evaluate:功能逻辑实现 入参:DeferredObject[] 出参:Object 出参:String close:关闭函数,释放资源等 出参:void |
| UDTF | 类: 包路径: |
initialize:类型检查,返回结果类型 process:功能逻辑实现 入参:Object[] 出参:void 出参:void |
| UDAF | 类: 类:
AbstractAggregationBuffer |
-----AbstractGenericUDAFResolver----- getEvaluator:获取计算器 ---------GenericUDAFEvaluator---------- init: getNewAggregationBuffer: 入参:无 出参:AggregationBuffer reset: 入参:AggregationBuffer 出参:void 入参:AggregationBuffer,Object[] 出参:void merge: 入参:AggregationBuffer,Object 出参:void
入参:AggregationBuffer 出参:Object 入参:AggregationBuffer 出参:Object --------AbstractAggregationBuffer------- 入参:无 出参:int |
UDAF说明
- 一个Buffer作为中间处理数据的缓冲:获取getNewAggregationBuffer、重置reset
- 四个阶段(Mode):
- PARTIAL1(Map阶段):
from original data to partial aggregation data:
iterate() and terminatePartial() will be called. - PARTIAL2(Map的Combiner阶段):
from partial aggregation data to partial aggregation data:
merge() and terminatePartial() will be called. - FINAL(Reduce 阶段):
from partial aggregation to full aggregation:
merge() and terminate() will be called. - COMPLETE(Map Only阶段):
from original data directly to full aggregation:
iterate() and terminate() will be called.
- PARTIAL1(Map阶段):
- 五个方法:
- 初始化init
- 遍历iterate:PARTIAL1和COMPLETE阶段
- 合并merge:PARTIAL2和FINAL阶段
- 终止terminatePartial:PARTIAL1和PARTIAL2阶段
- terminate:COMPLETE和FINAL阶段
Spark实现:
参考:Spark - 自定义函数(UDF、UDAF、UDTF) - 知乎
8 hive创建一个临时表有哪些方法
WITH创建临时表
如果这个临时表并不需要保存,并且下文只需要用有限的几次,我们可以采用下面的方法。
with as 也叫做子查询部分,首先定义一个sql片段,该sql片段会被整个sql语句所用到,为了让sql语句的可读性更高些,作为提供数据的部分,也常常用在union等集合操作中。
with as就类似于一个视图或临时表,可以用来存储一部分的sql语句作为别名,不同的是with as 属于一次性的,而且必须要和其他sql一起使用才可以!
其最大的好处就是适当的提高代码可读性,而且如果with子句在后面要多次使用到,这可以大大的简化SQL;更重要的是:一次分析,多次使用,这也是为什么会提供性能的地方,达到了“少读”的目标。
WITH t1 AS (
SELECT *
FROM a
),
t2 AS (
SELECT *
FROM b
)
SELECT *
FROM t1
JOIN t2
;注意:
- 这里必须要整体作为一条sql查询,即with as语句后不能加分号,不然会报错。
- with子句必须在引用的select语句之前定义,同级with关键字只能使用一次,多个只能用逗号分割
- 如果定义了with子句,但其后没有跟select查询,则会报错!
- 前面的with子句定义的查询在后面的with子句中可以使用。但是一个with子句内部不能嵌套with子句!
Temporary创建临时表
create temporary table 临时表表名 as
select * from 表名- 创建的临时表仅仅在当前会话可见,数据会被暂存到hdfs上,退出当前会话表和数据将会被删除。数据将存储在用户的scratch目录中,并在会话结束时删除。
-
从Hive1.1开始临时表可以存储在内存或SSD,使用hive.exec.temporary.table.storage参数进行配置,该参数有三种取值:memory、ssd、default。
如果内存足够大,将中间数据一直存储在内存,可以大大提升计算性能。 - 如果临时表的命名的表名和hive的表名一样,当前会话则会查询临时表的数据,用户在这个会话内将不能使用原表,除非删除或者重命名临时表
- 临时表不支持分区字段,不支持创建索引。
参考:大数据开发之Hive篇7-Hive临时表 - 知乎
9 讲一下三范式,三范式解决了什么问题,有什么优缺点
三范式:
- 第一范式:列的原子性,字段值不可再分,比如某个字段的取值是姓名+手机号,那就要把姓名和手机号分成两个字段
- 第二范式:第一范式的基础上,非主键列不能依赖主键的一部分,例如字段a和字段b组成的主键,某个字段只依赖a,就需要把这个字段剥离到a对应的表
- 第三范式:第二范式的基础上,非主键列不能传递依赖主键,例如字段c依赖字段b,字段b依赖主键字段a,那么就可以把这个字段c剥离到字段b为主键的表
三范式是要解决字段冗余,节省存储空间,数据维护更方便,不需要多处更新同样的字段;
缺点是不方便查询,要进行多表join效率低,不适合分析类的查询。
范式化设计的优点:可以减少数据冗余,数据表体积小更新快,范式化的更新操作比 反范式化更快,范式化的表通常比反范式化更小。
缺点:对于查询需要对多个表,会关联多个表,在应用中,进行表关联的成本是很高
更难进行索引优化
反范式化设计的优点:可以减少表的关联,可以对查询更好的进行索引优化,
缺点:表结构存在数据冗余和数据维护异常,对数据的修改需要更多资源。因此在设计数据库结构的时候要将反范式化和范式化结合起来
参考:你了解数据库三大范式吗?用来解决什么问题?_数据库三范式解决了什么问题_我是等闲之辈的博客-CSDN博客mysql--数据库优化的目的、数据库设计的步骤以及什么是三范式、三范式的优缺点-CSDN博客
10 讲一下维度建模的过程
四个步骤:①选择业务过程 ②确定粒度 ③确定维度 ④确定事实表
维度模型是数据仓库领域的 Ralph Kimball 大师所倡导的,他的The Data Warehouse Toolkit-The Complete Guide to Dimensional Modeling 是数据仓库工程领域最流行的数据仓库建模的经典。
维度建模从分析决策的需求出发构建模型,为分析需求服务,因此它重点关注用户如何更快速地完成需求分析,同时具有较好的大规模复杂查询的响应性能。其典型的代表是星形模型,以及在一些特殊场景下使用的雪花模型。其设计分为以下几个步骤。
第一步:选择业务过程
选择需要进行分析决策的业务过程。业务过程可以是单个业务事 件,比如交易的支付、退款等;也可以是某个事件的状态,比如 当前的账户余额等;还可以是一系列相关业务事件组成的业务流 程,具体需要看我们分析的是某些事件发生情况,还是当前状态, 或是事件流转效率。
第二步:确定粒度
选择粒度。在事件分析中,我们要预判所有分析需要细分的程度,从而决定选择的粒度。粒度是维度的一个组合。
第三步:确定维度
识别维表。选择好粒度之后,就需要基于此粒度设计维表,包括维度属性,用于分析时进行分组和筛选。
第四步:确定事实
选择事实。确定分析需要衡量的指标 。
参考:【总结】维度数据建模过程及举例-腾讯云开发者社区-腾讯云
11 维度表有哪几种
- 按是否规范化设计划分,分符合三范式的维表,和反规范化的维表,对应雪花模型和星型模型
- 按是否包含属性层次结构分,分包含层次结构的维表,和不包含层次结构的维表,如行业维表就是包含层次结构的维表,递归层次一般采用①扁平化、②层次桥接表两种方式设计
- 按水平拆分(基于业务类型)可以划分为,主维表(存放公共属性),子维度表(包含公共属性和特有属性)
- 按垂直拆分(基于性能)可以划分为:主维表(存放使用频率高的属性),扩展维表(存放使用频率低的属性)
- 按是否归档处理分为:历史维度表,普通表
- 按缓慢变化维划分:一种是使用代理键的就是Kimball中的8种类型的缓慢变化维度,如果不使用代理键则划分快照维表、采用极限存储的维度表
- 一些特殊维度类型:支架维度、杂项维度、行为维度(事实衍生维度,如买家常用地址)、多值维度
参考:数据仓库系列4-维度表 - 知乎
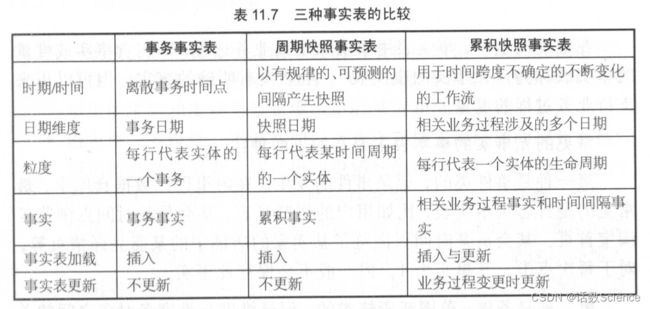
12 事实表有几种
- 事务性事实表:又分为单事务事实表,多事务事实表
- 周期快照事实表:又分为单维度的每天快照事实表,混合维度的每天快照事实表,全量快照事实表
- 累计快照事实表
13 什么是维度一致性,总线架构,事实一致性
维度建模的数据仓库中,有一个概念叫Conformed Dimension,中文一般翻译为“一致性维度”。一致性维度是Kimball的多维体系结构中的三个关键性概念之一,另两个是总线架构(Bus Architecture)和一致性事实(Conformed Fact)。
总线架构:初期进行需求沟通和整体设计的产物,汇总一致性维度和业务过程的表格
一致性维度:维度定义和维表实现的同一性
一致性事实:指标定义(包括单位)和实现的一致性
总线矩阵:业务过程和维度的交点;
一致性维度:同一集市的维度表,内容相同或包含;
一致性事实:不同集市的同一事实,需保证口径一致,单位统一。
参考:一篇文章搞懂数据仓库:总线架构、一致性维度、一致性事实-阿里云开发者社区
15 什么是拉链表,如何实现?
拉链表:主要是为了记录历史变化状态,同时节省存储空间。
参考:
拉链表的详细实现过程(好文点赞收藏!!)_拉链表的实现过程_KG大数据的博客-CSDN博客
https://www.cnblogs.com/lxbmaomao/p/9821128.html
16 什么是微型维度、支架表,什么时候会用到
- 微型维度:缓慢变化维度类型4
- 支架表:
- 是一种受限的雪花维度,是星型模型和雪花模型之间的一种折中,如日期维度表、地址维度表
- 使用场景:当一个属性集合(例如日期、地点)在某个维度或多个维度表中反复出现时,就可以考虑使用支架表。
- 使用条件:
①在单个维度表中反复出现该支架属性时
②被调用的属性值较多时
③被多个维度、事实表调用,且被调用时的属性值定义完全相同
④基本不需要修改或修改频次极小
参考:
深入解析缓慢变化维 - 知乎
深入解析支架表 - 知乎
17 讲几个你工作中常用的spark 或者hive 的参数,以及这些参数做什么用的
18 工作中遇到数据倾斜处理过吗?是怎么处理的,针对你刚刚提的方案讲一下具体怎么实现。用代码实现,以及用sql实现。
19 讲一下kafka对接flume 有几种方式
三种:source、channel、sink
source和sink对接方式:Flume对接Kafka详细过程_flume kafka_杨哥学编程的博客-CSDN博客
channel对接方式:flume--KafkaChannel的使用_kafka channel为什么没有sink-CSDN博客
20 讲一下spark是如何将一个sql翻译成代码执行的,里面的原理介绍一下?
SparkSQL主要是通过Catalyst优化器,将SQL翻译成最终的RDD算子的
| 阶段 | 产物 | 执行主体 |
| 解析 | Unresolved Logical Plan(未解析的逻辑计划) | sqlParser |
| 分析 | Resolved Logical Plan(解析的逻辑计划) | Analyzer |
| 优化 | Optimized Logical Plan(优化后的逻辑计划) | Optimizer |
| 转换 | Physical Plan(物理计划) | Query Planner |
无论是使用 SQL语句还是直接使用 DataFrame 或者 DataSet 算子,都会经过Catalyst一系列的分析和优化,最终转换成高效的RDD的操作,主要流程如下:
1. sqlParser 解析 SQL,生成 Unresolved Logical Plan(未解析的逻辑计划)
2. 由 Analyzer 结合 Catalog 信息生成 Resolved Logical Plan(解析的逻辑计划)
3. Optimizer根据预先定义好的规则(RBO),对 Resolved Logical Plan 进行优化并生成 Optimized Logical Plan(优化后的逻辑计划)
4. Query Planner 将 Optimized Logical Plan 转换成多个 Physical Plan(物理计划)。然后由CBO 根据 Cost Model 算出每个 Physical Plan 的代价并选取代价最小的 Physical Plan 作为最终的 Physical Plan(最终执行的物理计划)
5. Spark运行物理计划,先是对物理计划再进行进一步的优化,最终映射到RDD的操作上,和Spark Core一样,以DAG图的方式执行SQL语句。 在最新的Spark3.0版本中,还增加了Adaptive Query Execution功能,会根据运行时信息动态调整执行计划从而得到更高的执行效率
整体的流程图如下所示:

参考:SparkSQL运行流程浅析_简述spark sql的工作流程-CSDN博客
21 spark 程序里面的count distinct 具体是如何执行的
-
一般对count distinct优化就是先group by然后再count,变成两个mapreduce过程,先去重再count。
-
spark类似,会发生两次shuffle,产生3个stage,经过4个步骤:①先map端去重,②然后再shuffle到reduce端去重,③然后通过map做一次partial_count,④最后shuffle到一个reduce加总。
-
spark中多维count distinct,会发生数据膨胀问题,会把所有需要 count distinct 的N个key组合成List,行数就翻了N倍,这时最好分开来降低单个任务的数据量。
参考:大数据SQL COUNT DISTINCT实现原理 - 知乎
22 不想用spark的默认分区,怎么办?(自定义Partitioner 实现里面要求的方法 )具体是哪几个方法?
abstract class Partitioner extends Serializable {
def numPartitions: Int
def getPartition(key: Any): Int
}
参考:Spark自定义分区器-CSDN博客
23 有这样一个需求,统计一个用户的已经曝光了某一个页面,想追根溯是从哪几个页面过来的,然后求出在这几个来源所占的比例。你要怎么建模处理?(这里回答的不好,挺折磨的。面试官的意思是将所有埋点按时间顺序存在一个List 里,然后可能需要自定义udf函数,更主要的是考虑一些异常情况,比如点击流中间是断开的,或者点击流不全,怎么应对)
23 说一下你对元数据的理解,哪些数据算是元数据
24 有过数据治理的经验吗?
25 说一下你门公司的数据是怎么分层处理的,每一层都解决了什么问题
26 讲一下星型模型和雪花模型的区别,以及应用场景
- 雪花模型去除了冗余,设计复杂,可读性差,关联的维度表多,查询效率低,但是可扩展性好,适合OLAP
- 星型模型冗余度高,设计简单,可读性高,关联的维度表少,查询效率高,可扩展性低,适合OLTP
区别
星型模型和雪花模型最根本的区别就是,维度表是直接连接到事实表还是其他的维度表。
1)星型模型因为数据的冗余所以很多统计查询不需要做外部的连接,因此一般情况下效率比雪花模型要高。
2)星型模型不用考虑很多正规化的因素,设计和实现都比较简单。
3)雪花模型由于去除了冗余,有些统计就需要通过表的连接才能产生,所以效率不一定有星型模型高。
4)正规化也是一种比较复杂的过程,相应的数据库结构设计、数据的ETL、以及后期的维护都要复杂一些。因此在冗余可以接受的前提下,实际运用中星型模型使用更多,也更有效率。
数据仓库更适合使用星型模型来构建底层数据 hive 表,通过数据冗余来减少查询次数以提高查询效率。雪花模型在关系型数据库中(MySQL/Oracle)更加常见。在具体规划设计时,应结合具体场景及两者的优缺点来进行设计,找到一个平衡点去开展工作。
| 属性 |
星型模型 |
雪花模型 |
|---|---|---|
| 维表 |
一级维表 |
多层级维表 |
| 数据总量 |
多 |
少 |
| 数据冗余度 |
高 |
低 |
| 可读性 |
高 |
低 |
| 表个数 |
少 |
多 |
| 表宽度 |
宽 |
窄 |
| 查询逻辑 |
简单 |
复杂 |
| 查询性能 |
高 |
低 |
| 扩展性 |
差 |
好 |
参考:
维度建模 -- 星型模型和雪花模型的区别-CSDN博客
一文搞清楚数据仓库模型:星型模型和雪花模型的区别 - 简书
三大数据模型:星型模型、雪花模型、星座模型-腾讯云开发者社区-腾讯云
星型模型与雪花模型的区别、分别有哪些优缺点_星型模型和雪花模型的区别和使用场景?-CSDN博客