【项目学习】brpc
目录
1. bvar
2. bthread
FAQ
3. 常见线程模型
问题
4. 同步访问和异步访问
同步访问
异步访问
组合channel
5. channel和mutex
6. 自适应限流算法
7. 雪崩
8. FlatMap - 权衡空间的快速哈希表结构.
9. work_stealing
10. 负载均衡算法
一致性hash
11.timer
some tips
小菜learning
这些内容全部摘自https://github.com/apache/incubator-brpc/
1. bvar
bvar是多线程环境下的计数器类库,方便记录和查看用户程序中的各类数值,它利用了thread local存储减少了cache bouncing,相比UbMonitor(百度内的老计数器库)几乎不会给程序增加性能开销,也快于竞争频繁的原子操作。brpc集成了bvar,/vars可查看所有曝光的bvar,/vars/VARNAME可查阅某个bvar,在brpc中的使用方法请查看vars。brpc大量使用了bvar提供统计数值,当你需要在多线程环境中计数并展现时,应该第一时间想到bvar。但bvar不能代替所有的计数器,它的本质是把写时的竞争转移到了读:读得合并所有写过的线程中的数据,而不可避免地变慢了。当你读写都很频繁或得基于最新值做一些逻辑判断时,你不应该用bvar。
为了理解bvar的原理,你得先阅读Cacheline这节(涉及cpu的cacheline、原子指令、指令重排、memory fence等概念),其中提到的计数器例子便是bvar。当很多线程都在累加一个计数器时,每个线程只累加私有的变量而不参与全局竞争,在读取时累加所有线程的私有变量。虽然读比之前慢多了,但由于这类计数器的读多为低频的记录和展现,慢点无所谓。而写就快多了,极小的开销使得用户可以无顾虑地使用bvar监控系统,这便是我们设计bvar的目的。
这里列出上面提到的一些概念:
- 1 原子指令
原子指令是对软件不可再分的指令,比如x.fetch_add(n)指原子地给x加上n,这个指令对软件要么没做,要么完成,不会观察到中间状态。常见的原子指令有:
| 原子指令 (x均为std::atomic) | 作用 |
|---|---|
| x.load() | 返回x的值。 |
| x.store(n) | 把x设为n,什么都不返回。 |
| x.exchange(n) | 把x设为n,返回设定之前的值。 |
| x.compare_exchange_strong(expected_ref, desired) | 若x等于expected_ref,则设为desired,返回成功;否则把最新值写入expected_ref,返回失败。 |
| x.compare_exchange_weak(expected_ref, desired) | 相比compare_exchange_strong可能有spurious wakeup。 |
| x.fetch_add(n), x.fetch_sub(n) | 原子地做x += n, x-= n,返回修改之前的值。 |
你已经可以用这些指令做原子计数,比如多个线程同时累加一个原子变量,以统计这些线程对一些资源的操作次数。但是,这可能会有两个问题:
- 这个操作没有你想象地快。
- 如果你尝试通过看似简单的原子操作控制对一些资源的访问,你的程序有很大几率会crash。
- 2 cacheline
没有任何竞争或只被一个线程访问的原子操作是比较快的,“竞争”指的是多个线程同时访问同一个cacheline。现代CPU为了以低价格获得高性能,大量使用了cache,并把cache分了多级。百度内常见的Intel E5-2620拥有32K的L1 dcache和icache,256K的L2 cache和15M的L3 cache。其中L1和L2 cache为每个核心独有,L3则所有核心共享。一个核心写入自己的L1 cache是极快的(4 cycles, ~2ns),但当另一个核心读或写同一处内存时,它得确认看到其他核心中对应的cacheline。对于软件来说,这个过程是原子的,不能在中间穿插其他代码,只能等待CPU完成一致性同步,这个复杂的硬件算法使得原子操作会变得很慢,在E5-2620上竞争激烈时fetch_add会耗费700纳秒左右。访问被多个线程频繁共享的内存往往是比较慢的。比如像一些场景临界区看着很小,但保护它的spinlock性能不佳,因为spinlock使用的exchange, fetch_add等指令必须等待最新的cacheline,看上去只有几条指令,花费若干微秒并不奇怪。
要提高性能,就要避免让CPU频繁同步cacheline。这不单和原子指令本身的性能有关,还会影响到程序的整体性能。最有效的解决方法很直白:尽量避免共享。
- 一个依赖全局多生产者多消费者队列(MPMC)的程序难有很好的多核扩展性,因为这个队列的极限吞吐取决于同步cache的延时,而不是核心的个数。最好是用多个SPMC或多个MPSC队列,甚至多个SPSC队列代替,在源头就规避掉竞争。
- 另一个例子是计数器,如果所有线程都频繁修改一个计数器,性能就会很差,原因同样在于不同的核心在不停地同步同一个cacheline。如果这个计数器只是用作打打日志之类的,那我们完全可以让每个线程修改thread-local变量,在需要时再合并所有线程中的值,性能可能有几十倍的差别。
一个相关的编程陷阱是false sharing:对那些不怎么被修改甚至只读变量的访问,由于同一个cacheline中的其他变量被频繁修改,而不得不经常等待cacheline同步而显著变慢了。多线程中的变量尽量按访问规律排列,频繁被其他线程修改的变量要放在独立的cacheline中。要让一个变量或结构体按cacheline对齐,可以include
- 3 memory fence
仅靠原子技术实现不了对资源的访问控制,即使简单如spinlock或引用计数,看上去正确的代码也可能会crash。这里的关键在于重排指令导致了读写顺序的变化。只要没有依赖,代码中在后面的指令就可能跑到前面去,编译器和CPU都会这么做。
这么做的动机非常自然,CPU要尽量塞满每个cycle,在单位时间内运行尽量多的指令。如上节中提到的,访存指令在等待cacheline同步时要花费数百纳秒,最高效地自然是同时同步多个cacheline,而不是一个个做。一个线程在代码中对多个变量的依次修改,可能会以不同的次序同步到另一个线程所在的核心上。不同线程对数据的需求不同,按需同步也会导致cacheline的读序和写序不同。
如果其中第一个变量扮演了开关的作用,控制对后续变量的访问。那么当这些变量被一起同步到其他核心时,更新顺序可能变了,第一个变量未必是第一个更新的,然而其他线程还认为它代表着其他变量有效,去访问了实际已被删除的变量,从而导致未定义的行为。比如下面的代码片段:
// Thread 1
// ready was initialized to false
p.init();
ready = true;// Thread2
if (ready) {
p.bar();
}从人的角度,这是对的,因为线程2在ready为true时才会访问p,按线程1的逻辑,此时p应该初始化好了。但对多核机器而言,这段代码可能难以正常运行:
- 线程1中的ready = true可能会被编译器或cpu重排到p.init()之前,从而使线程2看到ready为true时,p仍然未初始化。这种情况同样也会在线程2中发生,p.bar()中的一些代码可能被重排到检查ready之前。
- 即使没有重排,ready和p的值也会独立地同步到线程2所在核心的cache,线程2仍然可能在看到ready为true时看到未初始化的p。
注:x86/x64的load带acquire语意,store带release语意,上面的代码刨除编译器和CPU因素可以正确运行。
通过这个简单例子,你可以窥见原子指令编程的复杂性了吧。为了解决这个问题,CPU和编译器提供了memory fence,让用户可以声明访存指令间的可见性(visibility)关系,boost和C++11对memory fence做了抽象,总结为如下几种memory order.
| memory order | 作用 |
|---|---|
| memory_order_relaxed | 没有fencing作用 |
| memory_order_consume | 后面依赖此原子变量的访存指令勿重排至此条指令之前 |
| memory_order_acquire | 后面访存指令勿重排至此条指令之前 |
| memory_order_release | 前面访存指令勿重排至此条指令之后。当此条指令的结果对其他线程可见后,之前的所有指令都可见 |
| memory_order_acq_rel | acquire + release语意 |
| memory_order_seq_cst | acq_rel语意外加所有使用seq_cst的指令有严格地全序关系 |
有了memory order,上面的例子可以这么更正:
// Thread1
// ready was initialized to false
p.init();
ready.store(true, std::memory_order_release);
// Thread2
if (ready.load(std::memory_order_acquire)) {
p.bar();
}线程2中的acquire和线程1的release配对,确保线程2在看到ready==true时能看到线程1 release之前所有的访存操作。
注意,memory fence不等于可见性,即使线程2恰好在线程1在把ready设置为true后读取了ready也不意味着它能看到true,因为同步cache是有延时的。memory fence保证的是可见性的顺序:“假如我看到了a的最新值,那么我一定也得看到b的最新值”。
一个相关问题是:如何知道看到的值是新还是旧?一般分两种情况:
- 值是特殊的。比如在上面的例子中,ready=true是个特殊值,只要线程2看到ready为true就意味着更新了。只要设定了特殊值,读到或没有读到特殊值都代表了一种含义。
- 总是累加。一些场景下没有特殊值,那我们就用fetch_add之类的指令累加一个变量,只要变量的值域足够大,在很长一段时间内,新值和之前所有的旧值都会不相同,我们就能区分彼此了。
原子指令的例子可以看boost.atomic的Example,atomic的官方描述可以看这里。
2. bthread
接触到一个新概念
https://github.com/apache/incubator-brpc/blob/master/docs/cn/bthread.md
bthread是brpc使用的M:N线程库,目的是在提高程序的并发度的同时,降低编码难度,并在核数日益增多的CPU上提供更好的scalability和cache locality。”M:N“是指M个bthread会映射至N个pthread,一般M远大于N。由于linux当下的pthread实现(NPTL)是1:1的,M个bthread也相当于映射至N个LWP。bthread的前身是Distributed Process(DP)中的fiber,一个N:1的合作式线程库,等价于event-loop库,但写的是同步代码
Goals
- 用户可以延续同步的编程模式,能在数百纳秒内建立bthread,可以用多种原语同步。
- bthread所有接口可在pthread中被调用并有合理的行为,使用bthread的代码可以在pthread中正常执行。
- 能充分利用多核。
- better cache locality, supporting NUMA is a plus.
FAQ
Q:bthread是协程(coroutine)吗?
不是。我们常说的协程特指N:1线程库,即所有的协程运行于一个系统线程中,计算能力和各类eventloop库等价。由于不跨线程,协程之间的切换不需要系统调用,可以非常快(100ns-200ns),受cache一致性的影响也小。但代价是协程无法高效地利用多核,代码必须非阻塞,否则所有的协程都被卡住,对开发者要求苛刻。协程的这个特点使其适合写运行时间确定的IO服务器,典型如http server,在一些精心调试的场景中,可以达到非常高的吞吐。但百度内大部分在线服务的运行时间并不确定,且很多检索由几十人合作完成,一个缓慢的函数会卡住所有的协程。在这点上eventloop是类似的,一个回调卡住整个loop就卡住了,比如ubaserver(注意那个a,不是ubserver)是百度对异步框架的尝试,由多个并行的eventloop组成,真实表现糟糕:回调里打日志慢一些,访问redis卡顿,计算重一点,等待中的其他请求就会大量超时。所以这个框架从未流行起来。
bthread是一个M:N线程库,一个bthread被卡住不会影响其他bthread。关键技术两点:work stealing调度和butex,前者让bthread更快地被调度到更多的核心上,后者让bthread和pthread可以相互等待和唤醒。这两点协程都不需要。更多线程的知识查看这里。
Q: 我应该在程序中多使用bthread吗?
不应该。除非你需要在一次RPC过程中让一些代码并发运行,你不应该直接调用bthread函数,把这些留给brpc做更好。
Q:bthread和pthread worker如何对应?
pthread worker在任何时间只会运行一个bthread,当前bthread挂起时,pthread worker先尝试从本地runqueue弹出一个待运行的bthread,若没有,则随机偷另一个worker的待运行bthread,仍然没有才睡眠并会在有新的待运行bthread时被唤醒。
Q:bthread中能调用阻塞的pthread或系统函数吗?
可以,只阻塞当前pthread worker。其他pthread worker不受影响。
Q:一个bthread阻塞会影响其他bthread吗?
不影响。若bthread因bthread API而阻塞,它会把当前pthread worker让给其他bthread。若bthread因pthread API或系统函数而阻塞,当前pthread worker上待运行的bthread会被其他空闲的pthread worker偷过去运行。
Q:pthread中可以调用bthread API吗?
可以。bthread API在bthread中被调用时影响的是当前bthread,在pthread中被调用时影响的是当前pthread。使用bthread API的代码可以直接运行在pthread中。
Q:若有大量的bthread调用了阻塞的pthread或系统函数,会影响RPC运行么?
会。比如有8个pthread worker,当有8个bthread都调用了系统usleep()后,处理网络收发的RPC代码就暂时无法运行了。只要阻塞时间不太长, 这一般没什么影响, 毕竟worker都用完了, 除了排队也没有什么好方法. 在brpc中用户可以选择调大worker数来缓解问题, 在server端可设置ServerOptions.num_threads或-bthread_concurrency, 在client端可设置-bthread_concurrency.
那有没有完全规避的方法呢?
- 一个容易想到的方法是动态增加worker数. 但实际未必如意, 当大量的worker同时被阻塞时, 它们很可能在等待同一个资源(比如同一把锁), 增加worker可能只是增加了更多的等待者.
- 那区分io线程和worker线程? io线程专门处理收发, worker线程调用用户逻辑, 即使worker线程全部阻塞也不会影响io线程. 但增加一层处理环节(io线程)并不能缓解拥塞, 如果worker线程全部卡住, 程序仍然会卡住, 只是卡的地方从socket缓冲转移到了io线程和worker线程之间的消息队列. 换句话说, 在worker卡住时, 还在运行的io线程做的可能是无用功. 事实上, 这正是上面提到的没什么影响真正的含义. 另一个问题是每个请求都要从io线程跳转至worker线程, 增加了一次上下文切换, 在机器繁忙时, 切换都有一定概率无法被及时调度, 会导致更多的延时长尾.
- 一个实际的解决方法是限制最大并发, 只要同时被处理的请求数低于worker数, 自然可以规避掉"所有worker被阻塞"的情况.
- 另一个解决方法当被阻塞的worker超过阈值时(比如8个中的6个), 就不在原地调用用户代码了, 而是扔到一个独立的线程池中运行. 这样即使用户代码全部阻塞, 也总能保留几个worker处理rpc的收发. 不过目前bthread模式并没有这个机制, 但类似的机制在打开pthread模式时已经被实现了. 那像上面提到的, 这个机制是不是在用户代码都阻塞时也在做"无用功"呢? 可能是的. 但这个机制更多是为了规避在一些极端情况下的死锁, 比如所有的用户代码都lock在一个pthread mutex上, 并且这个mutex需要在某个RPC回调中unlock, 如果所有的worker都被阻塞, 那么就没有线程来处理RPC回调了, 整个程序就死锁了. 虽然绝大部分的RPC实现都有这个潜在问题, 但实际出现频率似乎很低, 只要养成不在锁内做RPC的好习惯, 这是完全可以规避的.
Q:bthread会有Channel吗?
不会。channel代表的是两点间的关系,而很多现实问题是多点的,这个时候使用channel最自然的解决方案就是:有一个角色负责操作某件事情或某个资源,其他线程都通过channel向这个角色发号施令。如果我们在程序中设置N个角色,让它们各司其职,那么程序就能分类有序地运转下去。所以使用channel的潜台词就是把程序划分为不同的角色。channel固然直观,但是有代价:额外的上下文切换。做成任何事情都得等到被调用处被调度,处理,回复,调用处才能继续。这个再怎么优化,再怎么尊重cache locality,也是有明显开销的。另外一个现实是:用channel的代码也不好写。由于业务一致性的限制,一些资源往往被绑定在一起,所以一个角色很可能身兼数职,但它做一件事情时便无法做另一件事情,而事情又有优先级。各种打断、跳出、继续形成的最终代码异常复杂。
我们需要的往往是buffered channel,扮演的是队列和有序执行的作用,bthread提供了ExecutionQueue,可以完成这个目的。
3. 常见线程模型
- 连接独占线程或进程
在这个模型中,线程/进程处理来自绑定连接的消息,在连接断开前不退也不做其他事情。当连接数逐渐增多时,线程/进程占用的资源和上下文切换成本会越来越大,性能很差,这就是C10K问题的来源。这种方法常见于早期的web server,现在很少使用。
- 单线程reactor
以libevent, libev等event-loop库为典型。这个模型一般由一个event dispatcher等待各类事件,待事件发生后原地调用对应的event handler,全部调用完后等待更多事件,故为"loop"。这个模型的实质是把多段逻辑按事件触发顺序交织在一个系统线程中。一个event-loop只能使用一个核,故此类程序要么是IO-bound,要么是每个handler有确定的较短的运行时间(比如http server),否则一个耗时漫长的回调就会卡住整个程序,产生高延时。在实践中这类程序不适合多开发者参与,一个人写了阻塞代码可能就会拖慢其他代码的响应。由于event handler不会同时运行,不太会产生复杂的race condition,一些代码不需要锁。此类程序主要靠部署更多进程增加扩展性。
- N:1线程库
又称为Fiber,以GNU Pth, StateThreads等为典型,一般是把N个用户线程映射入一个系统线程。同时只运行一个用户线程,调用阻塞函数时才会切换至其他用户线程。N:1线程库与单线程reactor在能力上等价,但事件回调被替换为了上下文(栈,寄存器,signals),运行回调变成了跳转至上下文。和event loop库一样,单个N:1线程库无法充分发挥多核性能,只适合一些特定的程序。只有一个系统线程对CPU cache较为友好,加上舍弃对signal mask的支持的话,用户线程间的上下文切换可以很快(100~200ns)。N:1线程库的性能一般和event loop库差不多,扩展性也主要靠多进程。
- 多线程reactor
以boost::asio为典型。一般由一个或多个线程分别运行event dispatcher,待事件发生后把event handler交给一个worker线程执行。 这个模型是单线程reactor的自然扩展,可以利用多核。由于共用地址空间使得线程间交互变得廉价,worker thread间一般会更及时地均衡负载,而多进程一般依赖更前端的服务来分割流量,一个设计良好的多线程reactor程序往往能比同一台机器上的多个单线程reactor进程更均匀地使用不同核心。不过由于cache一致性的限制,多线程reactor并不能获得线性于核心数的性能,在特定的场景中,粗糙的多线程reactor实现跑在24核上甚至没有精致的单线程reactor实现跑在1个核上快。由于多线程reactor包含多个worker线程,单个event handler阻塞未必会延缓其他handler,所以event handler未必得非阻塞,除非所有的worker线程都被阻塞才会影响到整体进展。事实上,大部分RPC框架都使用了这个模型,且回调中常有阻塞部分,比如同步等待访问下游的RPC返回。
- M:N线程库
即把M个用户线程映射入N个系统线程。M:N线程库可以决定一段代码何时开始在哪运行,并何时结束,相比多线程reactor在调度上具备更多的灵活度。但实现全功能的M:N线程库是困难的,它一直是个活跃的研究话题。我们这里说的M:N线程库特别针对编写网络服务,在这一前提下一些需求可以简化,比如没有时间片抢占,没有(完备的)优先级等。M:N线程库可以在用户态也可以在内核中实现,用户态的实现以新语言为主,比如GHC threads和goroutine,这些语言可以围绕线程库设计全新的关键字并拦截所有相关的API。而在现有语言中的实现往往得修改内核,比如Windows UMS和google SwitchTo(虽然是1:1,但基于它可以实现M:N的效果)。相比N:1线程库,M:N线程库在使用上更类似于系统线程,需要用锁或消息传递保证代码的线程安全。
问题
- 多核扩展性
理论上代码都写成事件驱动型能最大化reactor模型的能力,但实际由于编码难度和可维护性,用户的使用方式大都是混合的:回调中往往会发起同步操作,阻塞住worker线程使其无法处理其他请求。一个请求往往要经过几十个服务,线程把大量时间花在了等待下游请求上,用户得开几百个线程以维持足够的吞吐,这造成了高强度的调度开销,并降低了TLS相关代码的效率。任务的分发大都是使用全局mutex + condition保护的队列,当所有线程都在争抢时,效率显然好不到哪去。更好的办法也许是使用更多的任务队列,并调整调度算法以减少全局竞争。比如每个系统线程有独立的runqueue,由一个或多个scheduler把用户线程分发到不同的runqueue,每个系统线程优先运行自己runqueue中的用户线程,然后再考虑其他线程的runqueue。这当然更复杂,但比全局mutex + condition有更好的扩展性。这种结构也更容易支持NUMA。
当event dispatcher把任务递给worker线程时,用户逻辑很可能从一个核心跳到另一个核心,并等待相应的cacheline同步过来,并不很快。如果worker的逻辑能直接运行于event dispatcher所在的核心上就好了,因为大部分时候尽快运行worker的优先级高于获取新事件。类似的是收到response后最好在当前核心唤醒正在同步等待RPC的线程。
- 异步编程
异步编程中的流程控制对于专家也充满了陷阱。任何挂起操作,如sleep一会儿或等待某事完成,都意味着用户需要显式地保存状态,并在回调函数中恢复状态。异步代码往往得写成状态机的形式。当挂起较少时,这有点麻烦,但还是可把握的。问题在于一旦挂起发生在条件判断、循环、子函数中,写出这样的状态机并能被很多人理解和维护,几乎是不可能的,而这在分布式系统中又很常见,因为一个节点往往要与多个节点同时交互。另外如果唤醒可由多种事件触发(比如fd有数据或超时了),挂起和恢复的过程容易出现race condition,对多线程编码能力要求很高。语法糖(比如lambda)可以让编码不那么“麻烦”,但无法降低难度。
共享指针在异步编程中很普遍,这看似方便,但也使内存的ownership变得难以捉摸,如果内存泄漏了,很难定位哪里没有释放;如果segment fault了,也不知道哪里多释放了一下。大量使用引用计数的用户代码很难控制代码质量,容易长期在内存问题上耗费时间。如果引用计数还需要手动维护,保持质量就更难了,维护者也不会愿意改进。没有上下文会使得RAII无法充分发挥作用, 有时需要在callback之外lock,callback之内unlock,实践中很容易出错。
4. 同步访问和异步访问
https://github.com/apache/incubator-brpc/blob/master/docs/cn/client.md这个文档介绍了很多客户端的思想和技术实现
echo客户端的示例程序https://github.com/apache/incubator-brpc/blob/master/example/echo_c++/client.cpp
一般来说,我们不直接调用Channel.CallMethod,而是通过protobuf生成的桩XXX_Stub,过程更像是“调用函数”。stub内没什么成员变量,建议在栈上创建和使用,而不必new,当然你也可以把stub存下来复用。Channel::CallMethod和stub访问都是线程安全的,可以被所有线程同时访问。比如:
XXX_Stub stub(&channel);
stub.some_method(controller, request, response, done);甚至
XXX_Stub(&channel).some_method(controller, request, response, done);同步访问
指的是:CallMethod会阻塞到收到server端返回response或发生错误(包括超时)。
同步访问中的response/controller不会在CallMethod后被框架使用,它们都可以分配在栈上。注意,如果request/response字段特别多字节数特别大的话,还是更适合分配在堆上。
MyRequest request;
MyResponse response;
brpc::Controller cntl;
XXX_Stub stub(&channel);
request.set_foo(...);
cntl.set_timeout_ms(...);
stub.some_method(&cntl, &request, &response, NULL);
if (cntl->Failed()) {
// RPC失败了. response里的值是未定义的,勿用。
} else {
// RPC成功了,response里有我们想要的回复数据。
}异步访问
指的是:给CallMethod传递一个额外的回调对象done,CallMethod在发出request后就结束了,而不是在RPC结束后。当server端返回response或发生错误(包括超时)时,done->Run()会被调用。对RPC的后续处理应该写在done->Run()里,而不是CallMethod后。
由于CallMethod结束不意味着RPC结束,response/controller仍可能被框架及done->Run()使用,它们一般得创建在堆上,并在done->Run()中删除。如果提前删除了它们,那当done->Run()被调用时,将访问到无效内存。
你可以独立地创建这些对象,并使用NewCallback生成done,也可以把Response和Controller作为done的成员变量,一起new出来,一般使用前一种方法。
发起异步请求后Request和Channel也可以立刻析构。这两样和response/controller是不同的。注意:这是说Channel的析构可以立刻发生在CallMethod之后,并不是说析构可以和CallMethod同时发生,删除正被另一个线程使用的Channel是未定义行为(很可能crash)。
使用NewCallback
static void OnRPCDone(MyResponse* response, brpc::Controller* cntl) {
// unique_ptr会帮助我们在return时自动删掉response/cntl,防止忘记。gcc 3.4下的unique_ptr是模拟版本。
std::unique_ptr response_guard(response);
std::unique_ptr cntl_guard(cntl);
if (cntl->Failed()) {
// RPC失败了. response里的值是未定义的,勿用。
} else {
// RPC成功了,response里有我们想要的数据。开始RPC的后续处理。
}
// NewCallback产生的Closure会在Run结束后删除自己,不用我们做。
}
MyResponse* response = new MyResponse;
brpc::Controller* cntl = new brpc::Controller;
MyService_Stub stub(&channel);
MyRequest request; // 你不用new request,即使在异步访问中.
request.set_foo(...);
cntl->set_timeout_ms(...);
stub.some_method(cntl, &request, response, google::protobuf::NewCallback(OnRPCDone, response, cntl)); //这个NewCallback就是访问行为的回调函数
组合channel
https://github.com/apache/incubator-brpc/blob/master/docs/cn/combo_channel.md
随着服务规模的增大,对下游的访问流程会越来越复杂,其中往往包含多个同时发起的RPC或有复杂的层次结构。但这类代码的多线程陷阱很多,用户可能写出了bug也不自知,复现和调试也比较困难。而且实现要么只能支持同步的情况,要么得为异步重写一套。以"在多个异步RPC完成后运行一些代码"为例,它的同步实现一般是异步地发起多个RPC,然后逐个等待各自完成;它的异步实现一般是用一个带计数器的回调,每当一个RPC完成时计数器减一,直到0时调用回调。可以看到它的缺点:
- 同步和异步代码不一致。用户无法轻易地从一个模式转为另一种模式。从设计的角度,不一致暗示了没有抓住本质。
- 往往不能被取消。正确及时地取消一个操作不是一件易事,何况是组合访问。但取消对于终结无意义的等待是很必要的。
- 不能继续组合。比如你很难把一个上述实现变成“更大"的访问模式的一部分。换个场景还得重写一套。
我们需要更好的抽象。如果我们能以不同的方式把一些Channel组合为更大的Channel,并把不同的访问模式置入其中,那么用户可以便用统一接口完成同步、异步、取消等操作。这种channel在brpc中被称为组合channel。
5. channel和mutex
作者:戈君
链接:https://www.zhihu.com/question/27256570/answer/66388230
channel和mutex的本质区别是一件事情是在"被调用处"做还是在"调用处"做,channel称不上比mutex好。
解释:
channel代表的是两点间的关系,而很多现实问题是多点的,这个时候使用channel最自然的解决方案就是:有一个角色负责操作某件事情或某个资源,其他线程都通过channel向这个角色发号施令。如果我们在程序中设置N个角色,让它们各司其职,那么程序就能分类有序地运转下去。所以使用channel的潜台词就是把程序划分为不同的角色。但mutex不同,每个线程想干什么事时,直接去获取干这件事的权力(获得锁),然后直接把事干了。
channel固然直观,但是有代价:额外的上下文切换。做成任何事情都得等到被调用处被调度,处理,回复,调用处才能继续。这个再怎么优化,再怎么尊重cache locality,相比无竞争时的锁也没什么卵用。而好的并发代码的无竞争比例都挺高的,所以这是channel必须吃的硬亏。另外一个现实是:用channel的代码比用mutex更难写。由于业务一致性的限制,一些资源往往被绑定在一起,所以一个角色很可能身兼数职,但它做一件事情时便无法做另一件事情,而事情又有优先级。各种打断、跳出、继续形成的最终代码异常复杂。当然这些问题也可以映射到mutex的世界中,但在使用channel时这种倾向更明显。
所以说到这份上,是否使用channel更多是考虑性能和口味。性能不那么重要,大家又觉得使用channel好理解,那就用。如果数据是单向的,那么也会用(buffered) channel,这时channel的作用更多是队列。
6. 自适应限流算法
实际生产环境中,最大并发未必一成不变,在每次上线前逐个压测和设置服务的最大并发也很繁琐。这个时候可以使用自适应限流算法。
自适应限流会不断的对请求进行采样,当采样窗口的样本数量足够时,会根据样本的平均延迟和服务当前的qps计算出下一个采样窗口的max_concurrency:
max_concurrency = max_qps * ((2+alpha) * min_latency - latency)
alpha为可接受的延时上升幅度,默认0.3。
latency是当前采样窗口内所有请求的平均latency。
max_qps是最近一段时间测量到的qps的极大值。
min_latency是最近一段时间测量到的latency较小值的ema,是noload_latency的估算值。
当服务处于低负载时,min_latency约等于noload_latency,此时计算出来的max_concurrency会高于concurrency,但低于best_max_concurrency,给流量上涨留探索空间。而当服务过载时,服务的qps约等于max_qps,同时latency开始明显超过min_latency,此时max_concurrency则会接近concurrency,并通过定期衰减避免远离best_max_concurrency,保证服务不会过载。
详见https://github.com/apache/incubator-brpc/blob/master/docs/cn/auto_concurrency_limiter.md
7. 雪崩
“雪崩”指的是访问服务集群时绝大部分请求都超时,且在流量减少时仍无法恢复的现象。下面解释这个现象的来源。
当流量超出服务的最大qps时,服务将无法正常服务;当流量恢复正常时(小于服务的处理能力),积压的请求会被处理,虽然其中很大一部分可能会因为处理的不及时而超时,但服务本身一般还是会恢复正常的。这就相当于一个水池有一个入水口和一个出水口,如果入水量大于出水量,水池子终将盛满,多出的水会溢出来。但如果入水量降到出水量之下,一段时间后水池总会排空。雪崩并不是单一服务能产生的。
如果一个请求经过两个服务,情况就有所不同了。比如请求访问A服务,A服务又访问了B服务。当B被打满时,A处的client会大量超时,如果A处的client在等待B返回时也阻塞了A的服务线程(常见),且使用了固定个数的线程池(常见),那么A处的最大qps就从线程数 / 平均延时,降到了线程数 / 超时。由于超时往往是平均延时的3至4倍,A处的最大qps会相应地下降3至4倍,从而产生比B处更激烈的拥塞。如果A还有类似的上游,拥塞会继续传递上去。但这个过程还是可恢复的。B处的流量终究由最前端的流量触发,只要最前端的流量回归正常,B处的流量总会慢慢降下来直到能正常回复大多数请求,从而让A恢复正常。
但有两个例外:
- A可能对B发起了过于频繁的基于超时的重试。这不仅会让A的最大qps降到线程数 / 超时,还会让B处的qps翻重试次数倍。这就可能陷入恶性循环了:只要线程数 / 超时 * 重试次数大于B的最大qps,B就无法恢复 -> A处的client会继续超时 -> A继续重试 -> B继续无法恢复。
- A或B没有限制某个缓冲或队列的长度,或限制过于宽松。拥塞请求会大量地积压在那里,要恢复就得全部处理完,时间可能长得无法接受。由于有限长的缓冲或队列需要在填满时解决等待、唤醒等问题,有时为了简单,代码可能会假定缓冲或队列不会满,这就埋下了种子。即使队列是有限长的,恢复时间也可能很长,因为清空队列的过程是个追赶问题,排空的时间取决于积压的请求数 / (最大qps - 当前qps),如果当前qps和最大qps差的不多,积压的请求又比较多,那排空时间就遥遥无期了。
了解这些因素后可以更好的理解brpc中相关的设计。
- 拥塞时A服务最大qps的跳变是因为线程个数是硬限,单个请求的处理时间很大程度上决定了最大qps。而brpc server端默认在bthread中处理请求,个数是软限,单个请求超时只是阻塞所在的bthread,并不会影响为新请求建立新的bthread。brpc也提供了完整的异步接口,让用户可以进一步提高io-bound服务的并发度,降低服务被打满的可能性。
- brpc中重试默认只在连接出错时发起,避免了流量放大,这是比较有效率的重试方式。如果需要基于超时重试,可以设置backup request,这类重试最多只有一次,放大程度降到了最低。brpc中的RPC超时是deadline,超过后RPC一定会结束,这让用户对服务的行为有更好的预判。在之前的一些实现中,RPC超时是单次超时*重试次数,在实践中容易误判。
- brpc server端的max_concurrency选项控制了server的最大并发:当同时处理的请求数超过max_concurrency时,server会回复client错误,而不是继续积压。这一方面在服务开始的源头控制住了积压的请求数,尽量避免延生到用户缓冲或队列中,另一方面也让client尽快地去重试其他server,对集群来说是个更好的策略。
对于brpc的用户来说,要防止雪崩,主要注意两点:
- 评估server的最大并发,设置合理的max_concurrency值。这个默认是不设的,也就是不限制。无论程序是同步还是异步,用户都可以通过 最大qps * 非拥塞时的延时(秒)来评估最大并发,原理见little's law,这两个量都可以在brpc中的内置服务中看到。max_concurrency与最大并发相等或大一些就行了。
- 注意考察重试发生时的行为,特别是在定制RetryPolicy时。如果你只是用默认的brpc重试,一般是安全的。但用户程序也常会自己做重试,比如通过一个Channel访问失败后,去访问另外一个Channel,这种情况下要想清楚重试发生时最差情况下请求量会放大几倍,服务是否可承受。
8. FlatMap - 权衡空间的快速哈希表结构.
https://github.com/apache/incubator-brpc/blob/master/docs/cn/flatmap.md
FlatMap可能是最快的哈希表,但当value较大时它需要更多的内存,它最适合作为检索过程中需要极快查找的小字典。
原理:把开链桶中第一个节点的内容直接放桶内。由于在实践中,大部分桶没有冲突或冲突较少,所以大部分操作只需要一次内存跳转:通过哈希值访问对应的桶。桶内两个及以上元素仍存放在链表中,由于桶之间彼此独立,一个桶的冲突不会影响其他桶,性能很稳定。在很多时候,FlatMap的查找性能和原生数组接近。
hash解决冲突方式
哈希值可能重合,解决冲突是哈希表性能的另一关键因素。常见的冲突解决方法有:
- 开链哈希(open hashing, closed addressing): 开链哈希表是链表的数组,其中链表一般称为桶。当若干个key落到同一个桶时,做链表插入。这是最通用的结构,有很多优点:占用内存为O(NumElement * (KeySize + ValueSize + SomePointers)),resize时候不会使之前的存放key/value的内存失效。桶之间是独立的,一个桶的冲突不会影响到其他桶,平均查找时间较为稳定,独立的桶也易于高并发。缺点是至少要两次内存跳转:先跳到桶入口,再跳到桶中的第一个节点。对于一些很小的表这个问题不明显,因为当表很小时,节点内存是接近的,但当表变大时,访存就愈发随机。如果一次访存在50ns左右(2G左右主频),开链哈希的查找时间往往就在100ns以上。在检索端的层层ranking过程中,对一些热点字典的查找1秒内可能有几百万次以上,开链哈希有时会成为热点。一些产品线可能对开链哈希的内存也有诟病,因为每对key/value都需要额外的指针。
- 闭链哈希(closed hashing or open addressing): 闭链的初衷是减少内存跳转,桶不再是链表入口,而只需要记录一对key/value与一些标记,当桶被占时,按照不同的探查方法直到找到空桶为止。比如线性探查就是查找下一个桶,二次探查是按1,2,4,9...平方数位移查找。优点是:当表很空时或冲突较少时,查找只需要一次访存,也不需要管理节点内存池。但仅此而已,这个方法带来了更多缺点:桶个数必须大于元素个数,resize后之前的内存全部失效,难以并发. 更关键的是聚集效应:当区域内元素较多时(超过70%,其实不算多),大量元素的实际桶和它们应在的桶有较大位移。这使哈希表的主要操作都要扫过一大片内存才能找到元素,性能不稳定难以预测。闭链哈希表在很多人的印象中“很快”,但在复杂的应用中往往不如开链哈希表,并且可能是数量级的慢。闭链有一些衍生版本试图解决这个问题,比如Hopscotch hashing。
- 混合开链和闭链:一般是把桶数组中的一部分拿出来作为容纳冲突元素的空间,典型如Coalesced hashing,但这种结构没有解决开链的内存跳转问题,结构又比闭链复杂很多,工程效果并不好。
- 多次哈希:一般用多个哈希表代替一个哈希表,当发生冲突时(用另一个哈希值)尝试另一个哈希表。典型如Cuckoo hashing,这个结构也没有解决内存跳转。
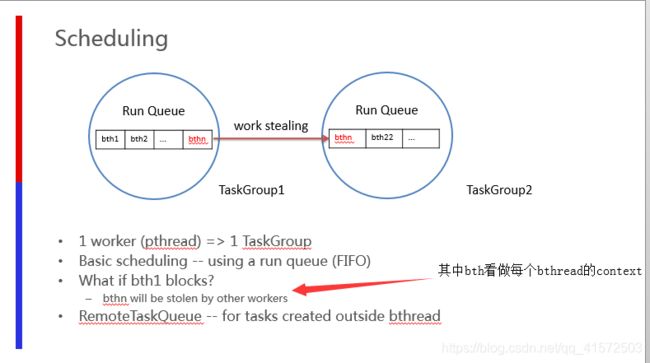
9. work_stealing
通过前文可知,M个bthread跑在N个实体pthread上,当某些bthread阻塞时,其余bthread可通过work_stealing算法来偷取其任务,避免对cpu资源的浪费

10. 负载均衡算法
最常见的分流算法是round robin和随机。这两个方法的前提是下游的机器和网络都是类似的,但在目前的线上环境下,特别是混部的产品线中,已经很难成立,因为:
- 每台机器运行着不同的程序组合,并伴随着一些离线任务,机器的可用资源在持续动态地变化着。
- 机器配置不同。
- 网络延时不同。
在DP 2.0中我们使用了一种新的算法: Locality-aware load balancing,能根据下游节点的负载分配流量,还能快速规避失效的节点,在很大程度上,这种算法的延时也是全局最优的。基本原理非常简单:
以下游节点的吞吐除以延时作为分流权值。
比如只有两台下游节点,W代表权值,QPS代表吞吐,L代表延时,那么W1 = QPS1 / L1和W2 = QPS2 / L2分别是这两个节点的分流权值,分流时随机数落入的权值区间就是流量的目的地了。
一种分析方法如下:
- 稳定状态时的QPS显然和其分流权值W成正比,即W1 / W2 ≈ QPS1 / QPS2。
- 根据分流公式又有:W1 / W2 = QPS1 / QPS2 * (L2 / L1)。
故稳定状态时L1和L2应当是趋同的。当L1小于L2时,节点1会更获得相比其QPS1更大的W1,从而在未来获得更多的流量,直到其延时高于平均值或没有更多的流量。
LALB全称Locality-aware load balancing,是一个能把请求及时、自动地送到延时最低的下游的负载均衡算法,特别适合混合部署环境。该算法产生自DP系统,现已加入brpc!
LALB可以解决的问题:
- 下游的机器配置不同,访问延时不同,round-robin和随机分流效果不佳。
- 下游服务和离线服务或其他服务混部,性能难以预测。
- 自动地把大部分流量送给同机部署的模块,当同机模块出问题时,再跨机器。
- 优先访问本机房服务,出问题时再跨机房。
…
DoublyBufferedData问题
LoadBalancer是一个读远多于写的数据结构:大部分时候,所有线程从一个不变的server列表中选取一台server。如果server列表真是“不变的”,那么选取server的过程就不用加锁,我们可以写更复杂的分流算法。一个方法是用读写锁,但当读临界区不是特别大时(毫秒级),读写锁并不比mutex快,而实用的分流算法不可能到毫秒级,否则开销也太大了。另一个方法是双缓冲,很多检索端用类似的方法实现无锁的查找过程,它大概这么工作:
- 数据分前台和后台。
- 检索线程只读前台,不用加锁。
- 只有一个写线程:修改后台数据,切换前后台,睡眠一段时间,以确保老前台(新后台)不再被检索线程访问。
这个方法的问题在于它假定睡眠一段时间后就能避免和前台读线程发生竞争,这个时间一般是若干秒。由于多次写之间有间隔,这儿的写往往是批量写入,睡眠时正好用于积累数据增量。
但这套机制对“server列表”不太好用:总不能插入一个server就得等几秒钟才能插入下一个吧,即使我们用批量插入,这个"冷却"间隔多少会让用户觉得疑惑:短了担心安全性,长了觉得没有必要。我们能尽量降低这个时间并使其安全么?
我们需要写以某种形式和读同步,但读之间相互没竞争。一种解法是,读拿一把thread-local锁,写需要拿到所有的thread-local锁。具体过程如下:
- 数据分前台和后台。
- 读拿到自己所在线程的thread-local锁,执行查询逻辑后释放锁。
- 同时只有一个写:修改后台数据,切换前后台,挨个获得所有thread-local锁并立刻释放,结束后再改一遍新后台(老前台)。
我们来分析下这个方法的基本原理:
- 当一个读正在发生时,它会拿着所在线程的thread-local锁,这把锁会挡住同时进行的写,从而保证前台数据不会被修改。
- 在大部分时候thread-local锁都没有竞争,对性能影响很小。
- 逐个获取thread-local锁并立刻释放是为了确保对应的读线程看到了切换后的新前台。如果所有的读线程都看到了新前台,写线程便可以安全地修改老前台(新后台)了。
其他特点:
- 不同的读之间没有竞争,高度并发。
- 如果没有写,读总是能无竞争地获取和释放thread-local锁,一般小于25ns,对延时基本无影响。如果有写,由于其临界区极小(拿到立刻释放),读在大部分时候仍能快速地获得锁,少数时候释放锁时可能有唤醒写线程的代价。由于写本身就是少数情况,读整体上几乎不会碰到竞争锁。
完成这些功能的数据结构是DoublyBufferedData<>,我们常简称为DBD。brpc中的所有load balancer都使用了这个数据结构,使不同线程在分流时几乎不会互斥。而其他rpc实现往往使用了全局锁,这使得它们无法写出复杂的分流算法:否则分流代码将会成为竞争热点。
这个结构有广泛的应用场景:
- reload词典。大部分时候词典都是只读的,不同线程同时查询时不应互斥。
- 可替换的全局callback。像butil/logging.cpp支持配置全局LogSink以重定向日志,这个LogSink就是一个带状态的callback。如果只是简单的全局变量,在替换后我们无法直接删除LogSink,因为可能还有都写线程在用。用DBD可以解决这个问题。
一致性hash
一些场景希望同样的请求尽量落到一台机器上,比如访问缓存集群时,我们往往希望同一种请求能落到同一个后端上,以充分利用其上已有的缓存,不同的机器承载不同的稳定working set。而不是随机地散落到所有机器上,那样的话会迫使所有机器缓存所有的内容,最终由于存不下形成颠簸而表现糟糕。 我们都知道hash能满足这个要求,比如当有n台服务器时,输入x总是会发送到第hash(x) % n台服务器上。但当服务器变为m台时,hash(x) % n和hash(x) % m很可能都不相等,这会使得几乎所有请求的发送目的地都发生变化,如果目的地是缓存服务,所有缓存将失效,继而对原本被缓存遮挡的数据库或计算服务造成请求风暴,触发雪崩。一致性哈希是一种特殊的哈希算法,在增加服务器时,发向每个老节点的请求中只会有一部分转向新节点,从而实现平滑的迁移。这篇论文中提出了一致性hash的概念。
一致性hash满足以下四个性质:
- 平衡性 (Balance) : 每个节点被选到的概率是O(1/n)。
- 单调性 (Monotonicity) : 当新节点加入时, 不会有请求在老节点间移动, 只会从老节点移动到新节点。当有节点被删除时,也不会影响落在别的节点上的请求。
- 分散性 (Spread) : 当上游的机器看到不同的下游列表时(在上线时及不稳定的网络中比较常见), 同一个请求尽量映射到少量的节点中。
- 负载 (Load) : 当上游的机器看到不同的下游列表的时候, 保证每台下游分到的请求数量尽量一致。
实现方式:
所有server的32位hash值在32位整数值域上构成一个环(Hash Ring),环上的每个区间和一个server唯一对应,如果一个key落在某个区间内, 它就被分流到对应的server上。
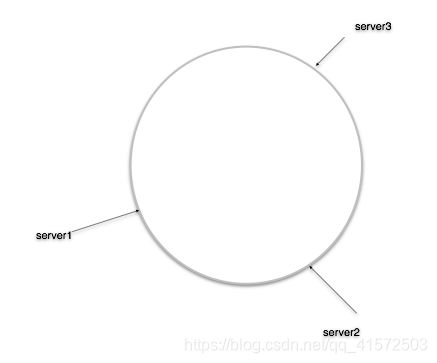
当删除一个server的,它对应的区间会归属于相邻的server,所有的请求都会跑过去。当增加一个server时,它会分割某个server的区间并承载落在这个区间上的所有请求。单纯使用Hash Ring很难满足我们上节提到的属性,主要两个问题:
- 在机器数量较少的时候, 区间大小会不平衡。
- 当一台机器故障的时候, 它的压力会完全转移到另外一台机器, 可能无法承载。
为了解决这个问题,我们为每个server计算m个hash值,从而把32位整数值域划分为n*m个区间,当key落到某个区间时,分流到对应的server上。那些额外的hash值使得区间划分更加均匀,被称为虚拟节点(Virtual Node)。当删除一个server时,它对应的m个区间会分别合入相邻的区间中,那个server上的请求会较为平均地转移到其他server上。当增加server时,它会分割m个现有区间,从对应server上分别转移一些请求过来。
由于节点故障和变化不常发生,我们选择了修改复杂度为O(n)的有序数组来存储hash ring,每次分流使用二分查找来选择对应的机器,由于存储是连续的,查找效率比基于平衡二叉树的实现高。线程安全性请参照Double Buffered Data章节.
11.timer
BRPC的timer实现:
- 一个TimerThread而不是多个。
- 创建的timer散列到多个Bucket以降低线程间的竞争,默认13个Bucket。
- Bucket内不使用小顶堆管理时间,而是链表 + nearest_run_time字段,当插入的时间早于nearest_run_time时覆盖这个字段,之后去和全局nearest_run_time(和Bucket的nearest_run_time不同)比较,如果也早于这个时间,修改并唤醒TimerThread。链表节点在锁外使用ResourcePool分配。
- 删除时通过id直接定位到timer内存结构,修改一个标志,timer结构总是由TimerThread释放。
- TimerThread被唤醒后首先把全局nearest_run_time设置为几乎无限大(max of int64),然后取出所有Bucket内的链表,并把Bucket的nearest_run_time设置为几乎无限大(max of int64)。TimerThread把未删除的timer插入小顶堆中维护,这个堆就它一个线程用。在每次运行回调或准备睡眠前都会检查全局nearest_run_time, 如果全局更早,说明有更早的时间加入了,重复这个过程。
详见https://github.com/apache/incubator-brpc/blob/master/docs/cn/timer_keeping.md
some tips
- 通配符匹配判断
在 /incubator-brpc/src/bvar/variable.cpp
369 inline bool wildcmp(const char* wild, const char* str, char question_mark) {
370 const char* cp = NULL;
371 const char* mp = NULL;
372
373 while (*str && *wild != '*') {
374 if (*wild != *str && *wild != question_mark) {
375 return false;
376 }
377 ++wild;
378 ++str;
379 }
380
381 while (*str) {
382 if (*wild == '*') {
383 if (!*++wild) {
384 return true;
385 }
386 mp = wild;
387 cp = str+1;
388 } else if (*wild == *str || *wild == question_mark) {
389 ++wild;
390 ++str;
391 } else {
392 wild = mp;
393 str = cp++;
394 }
395 }
396
397 while (*wild == '*') {
398 ++wild;
399 }
400 return !*wild;
401 }
- tcmalloc
TCMalloc全称Thread-Caching Malloc,即线程缓存的malloc,实现了高效的多线程内存管理,用于替代系统的内存分配相关的函数(malloc、free,new,new[]等)。
Tcmalloc原理是为每个线程单独分配一个线程本地的Cache,少量的地址分配就直接从Cache中分配,并且定期做垃圾回收,将线程本地Cache中的空闲内存返回给全局控制堆;Tcmalloc认为小于等于32K的对象是小对象,大对象直接从全局控制堆以页为单位进行分配,所以大对象总是页对齐的;Tcmalloc中一个页可以存入一些相同大小的小对象,小对象从本地内存链表中分配,大对象从中心内存堆分配。
优势:
1)快速:相比ptmalloc2,Tcmalloc的性能城北提升。尤其是Tcmalloc可以减少多线程之间锁的竞争问题,在小对象(32K)上能达到零竞争。
2)占用空间小:相比ptmalloc2,tcmalloc对小对象占用空间进行了优化。例如:分配N个8字节对象只需要占用8N*1.01字节的空间。即,只需要多使用1%的空间。而ptmalloc2中每个对象都需要使用一个4字节的头信息,最后占用的字节可能达到8N*8。
3)不易出现内存暴涨(ptmalloc2使用内存池,长时间没有将内存还给系统就会造成内存暴涨,tcmalloc可以通过MallocExtension::instance()->ReleaseFreeMemory()类设置内存还给系统的速度)。
详见https://www.jianshu.com/p/11082b443ddf
- 高效率排查服务卡顿
服务出现卡顿的原因可能包括 工作线程满了、cpu跑满、等待io、等待锁、上游分流不均等问题,排查方法可见https://github.com/apache/incubator-brpc/blob/master/docs/cn/server_debugging.md
- gperftools
gperftools是google开发的一款非常实用的工具集,主要包括:性能优异的malloc free内存分配器tcmalloc;基于tcmalloc的堆内存检测和内存泄漏分析工具heap-profiler,heap-checker;基于tcmalloc实现的程序CPU性能监测工具cpu-profiler.
安装:
git clone https://github.com/gperftools/gperftools #1
./autogen.sh --> ./configure -->make -j8 && sudo make install
sudo apt-get install libunwind8-dev #2
sudo apt-get install graphviz #3 libunwind库为基于64位CPU和操作系统的程序提供了基本的堆栈辗转开解功能,32位操作系统不要安装。其中包括用于输出堆栈跟踪的API、用于以编程方式辗转开解堆栈的API以及支持C++异常处理机制的API。
64bit操作系统必须安装libunwind库
Graphviz是一个由AT&T实验室启动的开源工具包,用于绘制DOT语言脚本描述的图形,gperftools依靠此工具生成图形分析结果。
实例:
1 #include
2 #include
3 using namespace std;
4 void func1() {
5 int i = 0;
6 while (i < 100000) {
7 ++i;
8 }
9 }
10 void func2() {
11 int i = 0;
12 while (i < 200000) {
13 ++i;
14 }
15 }
16 void func3() {
17 for (int i = 0; i < 1000; ++i) {
18 func1();
19 func2();
20 }
21 }
22 int main(){
23 ProfilerStart("my.prof"); // 指定所生成的profile文件名
24 func3();
25 ProfilerStop(); // 结束profiling
26 return 0;
27 }
g++ -o gperftools gperftools.cpp -lprofiler -lunwind
pprof --text ./gperftools my.prof > output.txt //其中my.prof是在程序中指定生成的文件名
//或
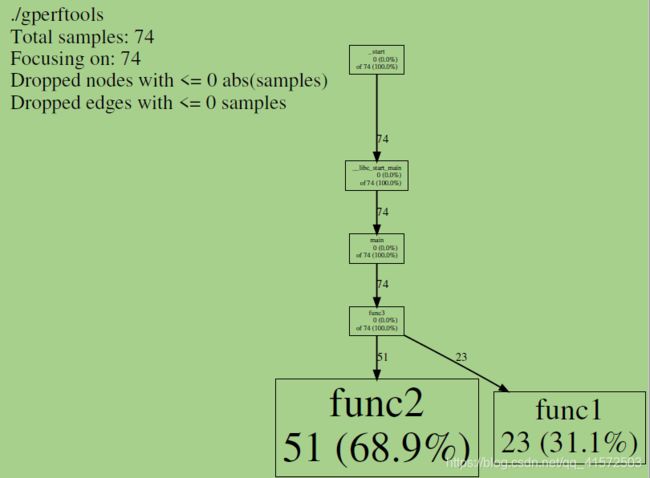
pprof --pdf ./gperftools my.prof > output.pdf结果 txt:
$ cat output.txt
Total: 74 samples
51 68.9% 68.9% 51 68.9% func2
23 31.1% 100.0% 23 31.1% func1
0 0.0% 100.0% 74 100.0% __libc_start_main
0 0.0% 100.0% 74 100.0% _start
0 0.0% 100.0% 74 100.0% func3
0 0.0% 100.0% 74 100.0% mainpdf: (可以sz到本地)