一、 国际化(i18n)北京外国语大学27种语言 vue-i18n + i18n Ally + xlsx + vue-json-excel
1. 开始开发用zh-cn.json的文件写完页面逻辑
2. 通过公司免费的api接口将每个字段翻译成27种语言(生成一个大对象)
3. 使用vue-json-excel读取json数据,导出一个excel文件
4. 让内容组同事修正翻译,通过腾讯文档同步内容,改完导成本地
5. 通过 xlsx 插件xlsx文件内容读出来,FileSaver 生成js文件
但是有个问题,后续添加的翻译,不能使用i18n Ally翻译了,它是全量翻译,会覆盖同事手动翻译的内容,只能使用公司翻译的接口,把新增的字段翻译(拿到zh-cn文件字段,对比en.json文件没有的就是新增的,翻译完第一个将所有新增的字段放在一个数组里边)将翻译内容写入json文件。后端的返回信息也需要翻译,在自己封装的接口请求方法加个变量,每个接口都需要传语言字段
- 国际化翻译 Vue-i18n 的架构组织和 $t 的原理,当遇到插值对象的时候,需要进行 parse 和 compile
- Vue-i18n 通过转义字符避免 XSS
- 通过观察者模式对数据进行监听和更新,做到无刷新更新页面
- 全局自定义指令和全局组件的实现
二、大文件分片上传,断点续传
1.通过el-upload组件拿到binary类型文件
2.校验文件不能超高20G,通过请求接口盘点磁盘大小,是否够存储文件
3. 直接将文件抛给webworker,file.slice()进行分片5M每片,用spark-md5给每一片加密(md5是一种信息摘要算法,它是一段数据,即128bit的由“0”和“1”组成的一段二进制数据。无论原始数据长短是多少,其MD5值都只是128bit)
4. 传送index、hash、file、size、total
5. 断点续传,刷新或者退出前端会停止上传,再次上传拿到MD5,后台先查有没有这个,有的话返回上次的index,前端从index继续上传。
6. 每一片5M传输最合理(nginx默认的上传文件大小是有限制的,一般为2MB,修改client_max_body_size 30M),oss存储有自动清理垃圾文件机制。调用的oss的api
7. nginx默认限制请求1M,修改client_max_body_size 20M;
大文件下载
阶段1:后台返回文件地址,创建隐藏的iframe下载,批量下载是创建多个iframe或者后端生成zip下载。(单线程下载速度慢)
阶段2: 多线程大文件下载,http1.1的range字段(分片下载blod文件,请求返回206,部分下载,下载完成合并blod文件,单个域名并发限制一次最多只能发送6个请求) 或者用jszip压缩文件
const zip = new JSZip();
zip.file(file.name, file);
const blob = await zip.generateAsync({type:"blob"})
saveAs(blob, "example.zip");
升级http2,没有并发限制,并不是并发越多越好。最后经过大量测试24个请求是最快的,请求完24个在请求24分片,请求完成合并文件
弊端google最大显示2G,Opera500M,不同浏览器大小限制不同,超过缓存大小会崩溃
Promise.all(arr).then((res) => {
const arrBufferList = res
.sort((item) => item.i - item.i)
.map((item) => new Uint8Array(item.buffer));
count = 0;
const allBuffer = concatenate(Uint8Array, arrBufferList);
const blob = new Blob([allBuffer], { type: "image/jpeg" });
const blobUrl = URL.createObjectURL(blob);
//a标签下载
const aTag = document.createElement("a");
aTag.download = donwloadName;
aTag.href = blobUrl;
aTag.click();
URL.revokeObjectURL(blob);
console.timeEnd("并发下载1");
// fileServer.js保存
FileSaver.saveAs(blob , '文件名')
});
前端多线程大文件下载实践,提速10倍(拿捏百度云盘)-阿里云开发者社区
阶段三:Streams API 是浏览器提供给 JS 的流式操作数据的接口。 将文件流直接写入磁盘
它借助了 Streams API 和 Service Worker 解决了内存占用过大的问题
https://segmentfault.com/a/1190000021367378
JS 实现流式打包下载 - 知乎JS前端批量下载大文件并打包zip(StreamSaver.js)_斗战圣佛91的博客-CSDN博客_js批量下载文件生成zip
responseType: 'arraybuffer'(请求arraybuffer文件流)
Service worker 它可以拦截浏览器的请求并提供离线缓存。
Service worker 本质上充当 Web 应用程序、浏览器与网络(可用时)之间的代理服务器。这个 API 旨在创建有效的离线体验,它会拦截网络请求并根据网络是否可用来采取适当的动作、更新来自服务器的的资源。
StreamSaver.js 包含两部分代码,一部分是客户端代码,一部分是 Service Worker 的代码(对于不支持 Service Worker 的情况,作者在 GitHub Pages 上提供了一个运行 Service Worker 的页面供跨域使用)。
在初始化时客户端代码会创建一个 TransformStream 并将可写入的一端封装为 writer 暴露给外部使用,在脚本调用 writer.write(chunk) 写入文件片段时,客户端会和 Service Worker 之间建立一个 MessageChannel,并将之前的 TransformStream 中可读取的一端通过 port1.postMessage() 传递给 Service Worker。Service Worker 里监听到通道的 onmessage 事件时会生成一个随机的 URL,并将 URL 和可读取的流存入一个 Map 中,然后将这个 URL 通过 port2.postMessage() 传递给客户端代码。
客户端接收到 URL 后会控制浏览器跳转到这个链接,此时 Service Worker 的 onfetch 事件接收到这个请求,将 URL 和之前的 Map 存储的 URL 比对,将对应的流取出来,再加上一些让浏览器认为可以下载的响应头(例如 Content-Disposition)封装成 Response 对象,最后通过 event.respondWith() 返回。这样在当客户端将数据写入 writer 时,经过 Service Worker 的流转,数据可以立刻下载到用户的设备上。这样就不需要分配巨大的内存来存放 Blob,数据块经过流的流转后直接被回收了,降低了内存的占用。
所以借助 StreamSaver.js,之前下载图片的流程可以优化如下:JSZip 提供了一个 StreamHelper 的接口来模拟流的实现,所以我们可以调用 generateInternalStream() 方法以小文件块的形式接收数据,每次接收到数据时数据会写入 StreamSaver.js 的 writer,经过 Service Worker 后数据直接被下载。这样就不会再像之前那样在生成 zip 时占用大量的内存空间了,因为 zip 数据在实时生成时被划分成了小块并迅速被处理掉了。
下载完成流---->postmessage发送给serviceWorker------>onmessage事件内部随机生成一个URL,存在map中 ------> 通过postMessage发送给客户端 ----> 客户端通过跳转这个url------->serviceWorker拦截请求------>将对应流拉取出来,加上响应头,下载线程拿到响应,开启流式下载
readableStream .pipeTo(fileStream) .then(() => console.log("done writing"))
AXIOS取消请求
let CancelToken; //取消请求的token令牌
let cancel:any; //取消请求的方法
// 发送请求
function sendAxios() {
CancelToken = axios.CancelToken
axios.get('https://edu.newsight.cn/wxList.php', {
cancelToken: new CancelToken(function excutor(c) {
cancel = c;
})
}).then((res) => {
console.log('axios1发回来的数据',res)
}).catch((thrown) => {
if (axios.isCancel(thrown)) {
console.log('请求已经取消了==>', thrown.message);
} else {
// 处理错误
}
});
}
// 取消请求
function cancelHandert() {
cancel&&cancel();
}
三、主题切换
1. 给ued组开发了一个定义主题颜色的系统,table表格展示每一个主题色的属性,通过FileSaver保存生成scss文件,供前端使用 ,新增主题,修改主题只需要UI去修改颜色,生成新的scss文件供前端使用。
2. table是一个数组,一列就是一个主题,每个主题有多个属性,最后点确认,生成一个js文件存放这次生成的数组,供下次使用。还要将数组对象拼接成字符串,输出成scss文件。
a = { '--theme-color': "#eee", '--theme-background': "#333" } ->
a = '.a {--theme-color: "#eee";--theme-background: "#333"}'
3. 基础常用的样式的样式 通过@mixin,@extend减少重复
4. 通过动态设置html的class实现切换主题
5. 还有一个项目用户需要自定义主题颜色,自己选择每一个模块的颜色(可以颜色面板选择)
/* 定义根作用域下的变量 */
:root {
--theme-color: #333;
--theme-background: #eee;
}
/* 更改dark类名下变量的取值 */
.dark{
--theme-color: #eee;
--theme-background: #333;
}
/* 更改pink类名下变量的取值 */
.pink{
--theme-color: #fff;
--theme-background: pink;
}
.box {
transition: all .2s;
width: 100px;
height: 100px;
border: 1px solid #000;
/* 使用变量 */
color: var(--theme-color);
background: var(--theme-background);
}
四、网盘存储、资源管理
1. 资源分片上传
2. 大文件下载,批量下载(生成一个zip)
3. 资源、文件夹的分享、复制、移动、收藏、下载、公开、编辑、删除
4. 视频资源支持打点、剪切、视频融合、字幕、分享、字幕转写、添加笔记、无效片段处理,COR识别、编辑字幕、字幕翻译、词云、图文模式、多路视频随意切换、局部全屏(所有全屏)
5. 文件预览。文档,图片,视频 ,音频
6. 直播,字幕(实时语音翻译,websocket拿到数据展示),实时语音聊天(类似腾讯课堂,但是支持多路和多路全屏,显示实时语音翻译,)
五、大屏数据展示,移动端
大屏适配
const baseWidth = 1920;
const baseHeight = 1080;
let timer = null;
let calcScale = function () {
let windowInnerWidth = window.innerWidth;
let windowInnerHeight = window.innerHeight;
// let ratioW = baseWidth / windowInnerWidth;
let ratioW = windowInnerWidth / baseWidth;
// let ratioH = baseHeight / windowInnerHeight;
let ratioH = windowInnerHeight / baseHeight;
document.body.style.width = baseWidth + 'px';
document.body.style.height = baseHeight + 'px';
document.body.style.transformOrigin = 'left top';
document.body.style.transform = `scale(${ratioW})`;
}
calcScale();
window.onresize = function () {
if (timer) {
clearTimeout(timer);
}
timer = setTimeout(calcScale, 300)
}
移动端适配:rem是相对长度单位。相对于根元素(即html元素)font-size计算值的倍数的一个css单位,默认1rem = 16px,不好计算,重新设置比率 html{font-size: 100px;} 1rem = 100px
等比缩放
vw,wh是 1/100宽高,兼容性不太好
em:相对于父元素的大小,一个改变后边子元素也得变
(function(win, doc) {
function changeSize() {
doc.documentElement.style.fontSize = 100 *
doc.documentElement.clientWidth / 375 + 'px';
}
changeSize();
win.addEventListener('resize', changeSize, false);
})(window, document);
postcss-plugin pxtovw 实现px转化为vw
import pxtovw from 'postcss-px-to-viewport'
const getPlagin = (isVant) => {
let opt: any = {
//这里是设计稿宽度 自己修改
viewportWidth: isVant ? 375 : 750,
viewportUnit: 'vw',
}
if (isVant) {
opt.include = [/node_modules\/vant/]
opt.exclude = [/controller/]
} else {
opt.exclude = [/node_modules\/vant/, /controller/]
}
return pxtovw(opt)
}
const config = {
base: '/iplat/fifMobile/fif_zjzx/',
css: {
postcss: {
plugins: [getPlagin(false), getPlagin(true)]
}
},
plugins: [
vue(),
vueSetupExtend(),
Components({
resolvers: [VantResolver()],
}),
// viteCompression({ deleteOriginFile: true }) // gzip 压缩
],
}
六、弹幕问题
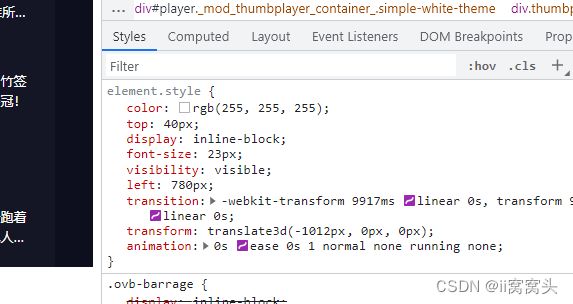
通过css3
transition: -webkit-transform 0s linear 0s;(过度效果时间,匀速,延迟)
transform: matrix(1, 0, 0, 1, -406.081, 0);(矩阵变换,线性代数,运动就是在线性空间的一种变换,transform: matrix(a,b,c,d,e,f);,x'=ax+cy+e y'=bx+dy+f)
animation: 0s ease 0s 1 normal none running none;(动画: 动画-名 动画-持续时间 动画-时间控制函数 动画-延时 动画-重复次数 动画-方向 动画-填充方法 动画-播放状态;)
will-change: transform, opacity;(transform和animation有时会出现闪烁,将动画交给GPU,硬件加速,属性允许你提前告知浏览器你可能会对一个元素进行什么样的改变,这样它就可以提前设置适当的优化,该元素会被移动到属于它自己的“图层”,在那里它可以独立于页面的其他部分进行渲染。避免其他元素的重排和重绘)
stroke-width:1px;stroke: rgba(0,0,0,.5); 文字描边
直播半屏,显示右侧聊天室,网页全屏显示弹幕功能
录播功能2分钟根据当前时间请求一次最新的弹幕,轮循,websocket常
直播使用websocket(弹幕+实时字幕),录播30s根据播放时间获取一次弹幕
流程:添加新弹幕到等待队列、寻找合适的轨道、从等待队列中抽取弹幕并放入轨道、整体渲染、清空。
分为三部分:舞台、轨道、弹幕池
舞台是整个弹幕的主控制,它维护着多个轨道、一个等待队列、一个弹幕池
弹幕池:[[1,2,3],[4,5,6]](new WeakMap() ) 等待队列:[7,8,9,10]
获取每一行的宽度,找到最小的给他添加新的弹幕,(先填充满上边的一行)
transition:1s linear 0s, 速度是transition的时间控制的
追及问题,设置最大速度为两倍,计算两个之前的距离
丢弃排队时间过长的弹幕大神
-webkit-mask-image:url() //防止弹幕遮挡人物
自定义指令:水印(手机端人名字水印和视频水印,mutationObserver检测dom变化,执行生成水印方法,防止人为删除dom),懒加载,按钮节流,输入防抖,拖拽
// 选择需要观察变动的节点(获取到DOM)
const targetNode = document.getElementById('app');
// 观察器的配置(需要观察什么变动)
const config = { attributes: true, childList: true, subtree: true };
// 当观察到变动时执行的回调函数
const callback = function() {
console.log('触发回调')
};
// 创建一个观察器实例并传入回调函数
const observer = new MutationObserver(callback);
// 以上述配置开始观察目标节点
observer.observe(targetNode, config);
// 之后,可停止观察
childList: true, // 观察目标子节点的变化,是否有添加或者删除
attributes: true, // 观察属性变动
subtree: true // 观察后代节点,默认为 false
前端优化
1、减少请求量
雪碧图,iconfont、spritesmith(生成png和scss)、nginx开启http2(server {listen 10.10.10.10:443 backlog=20480 http2 ssl;ssl_async on;)、图片懒加载、虚拟列表、
// 定义懒加载图片或者文件等,自定义指令
Vue.directive('lazy', (el, binding) => {
let oldSrc = el.src //保存旧的src,方便后期渲染时候赋值src真实路径
el.src = "" //将渲染的src赋为空,则不会渲染图片出来
let observer = new IntersectionObserver(([{ isIntersecting }]) => { // 调用方法得到该elDOM元素是否处于可视区域
if (isIntersecting) { //回调是否处于可视区域,true or false
el.src = oldSrc //如果处于可视区域额,将最开始保存的真实路径赋予DOM元素渲染
observer.unobserve(el) // 只需要监听一次即可,第二次滑动到可视区域时候不在监听
}
})
observer.observe(el) // 调用方法
})
2、减小文件大小
路由懒加载,组件按需加载、开启zip(CompressionPlugin)、压缩css(css-minimizer-webpack-plugin)、压缩图片(image-webpack-loader / webp )、提取公共库(SplitChunksPlugin)、Tree Shaking 移除无用代码、减少不必要的 cookie
3、加快请求速度
预解析DNS( ,官网配置子应用)、CDN 分发、nginx负载均衡、使用 preconnect 提前建立连接、webpackPrefetch(预加载资源文件)、CDN 托管静态资源 + HTTP 缓存(强缓存,协商缓存)
4. 交互层面:减少回流/重绘(使用 will-change 开启 GPU 加速、减少对 DOM 进行频繁操作、使经常变动的元素脱离文档流)、防抖/节流
5. Web Worker
JavaScript 是单线程的,如果存在需要大量计算的场景(如视频解码),UI 线程就会被阻塞,甚至浏览器直接卡死。
Web Worker 可以使脚本运行在新的线程中,它们独立于主线程,可以进行大量的计算活动,而不会影响主线程的 UI 渲染,但不能滥用 Web Worker 。
6、虚拟列表
最常用的还是 分页加载 的方式:
虚拟列表 核心就是固定渲染的 DOM 数,通过动态切换数据内容实现视图的更新,并保证文档中真实 DOM 的数量不随着数据量增大而增大(其实和 table 分页很像,但它支持滚动)。
7. 大文件分片上传、下载
8. 前端文件导入/导出
Minify把 CSS 和 JS 压缩和削减(Minify:去掉空格回车符等),以及把多个CSS,JS文件整合到一个文件里。
4、缓存
① HTTP协议缓存请求(ng开启强缓存,协商缓存)
② 离线缓存 manifest(webpack-manifest)
③ 本地缓存 localStorage
补充知识:
GET请求可以缓存,POST请求不能缓存。GET请求后退/刷新无害,POST后退/刷新则会致使重新提交数据
4、渲染
① JS优化,如防抖、节流、事件委托、减少重排重绘等。
② CSS优化,如提取公共样式减少代码量、减少选择器嵌套层数、精灵图等。
③ 服务器端渲染
④ 使用Web Workers
⑤ CSS写在文件头部,JS写在文件底部。
img/css这些文件都可以用强缓存。通过更改文件名的方式来获取最新的数据,index.html就要用协商
FP : 首次绘制(白屏时间)
FCP:首次内容绘制(绘制第一个元素)
LCP:首屏时间(最大内容绘制,应在2.5s完成)mutationObserve*dom树的层级计算一个权重,页面元素一直在变化,取一个相对的比较大的变化作为首屏渲染截止时间
FID:第一次输入事件延迟
CLS:累积布局偏移
浏览器perfermace观察各项指标,但是不直观
可以用lightHouse观察(各项指标性能)
会在项目部署的初期,通过设置变量控制各个性能指标的开启,监听load事件,load完成以后将各项指标上传,前端人员进行分析,运行平稳以后,可以把一些dns,tcp的检测给去掉。
import {getCLS, getFID, getLCP} from 'web-vitals'; 1.5k很小
function sendToAnalytics(metric) {
const body = JSON.stringify(metric);
// Use `navigator.sendBeacon()` if available, falling back to `fetch()`.
(navigator.sendBeacon && navigator.sendBeacon('/analytics', body)) ||
fetch('/analytics', {body, method: 'POST', keepalive: true});
}
getCLS(sendToAnalytics);
getFID(sendToAnalytics);
getLCP(sendToAnalytics);
perfermence.timing
DNS查询耗时 :domainLookupEnd - domainLookupStart
TCP链接耗时 :connectEnd - connectStart
request请求耗时 :responseEnd - responseStart
解析dom树耗时 : domComplete- domInteractive
白屏时间 :responseStart - navigationStart
domready时间 :domContentLoadedEventEnd - navigationStart
onload时间 :loadEventEnd - navigationStart
DOMContentLoaded:文档被加载完,图片还未加载,样式表还未渲染
(1)解析html结构
(2)加载外部脚本和样式表文件
(3)解析并执行脚本代码
(4)构造HTML DOM模型 //DOMContentLoaded执行点
(5)加载图片等外部文件
(6)页面加载完毕 //load
window.addEventListener("load", function () { //添加load事件
console.log("load执行");
}, false);
window.addEventListener("DOMContentLoaded", function () { //添加DOMContentLoaded事件
console.log("domContentLoad执行");
}, false)
统计接口响应时间
const start = response.config.headers['request-startTime']
const currentTime = new Date().getTime()
const requestDuration = ((currentTime - start)/1000).toFixed(2)
axios取消请求CancelToken = axios.CancelToken
let CancelToken; //取消请求的token令牌
let cancel:any; //取消请求的方法
// 发送请求
function sendAxios() {
CancelToken = axios.CancelToken
axios.get('https://edu.newsight.cn/wxList.php', {
cancelToken: new CancelToken(function excutor(c) {
cancel = c;
})
}).then((res) => {
console.log('axios1发回来的数据',res)
}).catch((thrown) => {
if (axios.isCancel(thrown)) {
console.log('请求已经取消了==>', thrown.message);
} else {
// 处理错误
}
});
}
// 取消请求
function cancelHandert() {
cancel&&cancel();
}
function sendAxios2() {
axios.get('https://edu.newsight.cn/wxList.php').then(function (response) {
console.log('返回来的数据sendAxios2', response)
})
}
DocumentFragment:它不是真实 DOM 树的一部分,它的变化不会触发 DOM 树的重新渲染,且不会对性能产生影响。
IntersectionObserver: 监听元素是否进入了可视区域
图片懒加载
const imgList = [...document.querySelectorAll('img')]
var io = new IntersectionObserver((entries) =>{
entries.forEach(item => {
// isIntersecting是一个Boolean值,判断目标元素当前是否可见
if (item.isIntersecting) {
item.target.src = item.target.dataset.src
// 图片加载后即停止监听该元素
io.unobserve(item.target)
}
})
}, {
root: document.querySelector('.root')
})
// observe遍历监听所有img节点
imgList.forEach(img => io.observe(img))
HTTP 101 Switching Protocols响应代码指示服务器正在根据发送包括Upgrade请求头的消息的客户端的请求切换到的协议。
服务器在此响应中包含一个Upgrade响应标题,指示它切换到的协议。该过程在文章“协议升级机制”中有详细描述
前端错误监控
1. window.onerror可以捕捉语法错误,也可以捕捉运行时错误,可以拿到出错的信息,堆栈,出错的文件、行号、列号
2. 当一项资源(如图片或脚本)加载失败,加载资源的元素会触发一个 Event 接口的 error 事件,并执行该元素上的onerror() 处理函数
window.addEventListener('error', function(event) {
// onerror_statements
})
3. 在vue中使用errorHandler 或者生命周期钩子 errorCaptured
app.config.errorHandler = (err, vm, info) => {
// 处理错误
// `info` 是 Vue 特定的错误信息,比如错误所在的生命周期钩子
}
4. 请求异常在响应拦截器中处理 在axios中拦截
5. promise异常使用Promise Catch,在全局增加一个对 unhandledrejection 的监听,用来全局监听Uncaught Promise Error。使用方式:
window.addEventListener("unhandledrejection", function(e){
console.log(e);
});
6. 崩溃和卡顿
1.利用 window 对象的 load 和 beforeunload 事件实现了网页崩溃的监控(在页面加载时(load 事件)在 sessionStorage 记录 good_exit 状态为 pending,如果用户正常退出(beforeunload 事件)状态改为 true,如果 crash 了,状态依然为 pending,在用户第2次访问网页的时候(第2个load事件),查看 good_exit 的状态,如果仍然是 pending 就是可以断定上次访问网页崩溃了!存在的问题:采用 sessionStorage 存储状态,但通常网页崩溃/卡死后,用户会强制关闭网页或者索性重新打开浏览器,sessionStorage 存储但状态将不复存在;如果将状态存储在 localStorage 甚至 Cookie 中,如果用户先后打开多个网页,但不关闭,good_exit 存储的一直都是 pending,完了,每有一次网页打开,就会有一个 crash 上报。)。
2. 可以使用 Service Worker 来实现网页崩溃的监控
(1).Service Worker 有自己独立的工作线程,与网页区分开,网页崩溃了,Service Worker 一般情况下不会崩溃;
(2).Service Worker 生命周期一般要比网页还要长,可以用来监控网页的状态;
(3).网页可以通过 navigator.serviceWorker.controller.postMessage API 向掌管自己的 SW 发送消息。
基于心跳检测的监控方案:
- p1:网页加载后,通过 postMessage API 每 5s 给 sw 发送一个心跳,表示自己的在线,sw 将在线的网页登记下来,更新登记时间;
- p2:网页在 beforeunload 时,通过 postMessage API 告知自己已经正常关闭,sw 将登记的网页清除;
- p3:如果网页在运行的过程中 crash 了,sw 中的 running 状态将不会被清除,更新时间停留在奔溃前的最后一次心跳;
- sw:Service Worker 每 10s 查看一遍登记中的网页,发现登记时间已经超出了一定时间(比如 15s)即可判定该网页 crash 了
终极解决方案 sentry 上报流程 (doker搭建一套,通过钉钉生成webhook地址,将错误信息发送到钉钉开发者群,实时关注错误提示)
- Sentry Init 初始化,读取配置的 Release 和 DSN 信息,然后将 Sentry 对象挂在到全局
- 当代码在运行过程中发生错误时,往上抛出一个 Error 对象,会执行 TraceKit 重写的 window.onerror 方法
- 如果是一个未捕获的 Promise 错误是,将执行重写的 window.onunhandledrejection
- 然后使用网络请求上报到 Sentry 服务器,这里会用到配置时使用的 DNS
微前端 qiankun
主应用需要安装乾坤,子应用有三个周期函数,bootstrap,mount,unmount
子应用
let instance = null;
function render(props = {}) {
const { container } = props;
if (props) {
// 注入 actions 实例
actions.setActions(props);
}
instance = new Vue({
router,
store,
render: (h) => h(App),
}).$mount(container ? container.querySelector('#learningApp') : '#learningApp');
}
// 独立运行时
if (!window.__POWERED_BY_QIANKUN__) {
render();
}
export async function bootstrap() { //初始化之前
console.log('[vue] vue app bootstraped');
}
export async function mount(props) {//挂载
console.log('[vue] props from main framework', props);
render(props);
}
export async function unmount() { //卸载
instance.$destroy();
instance.$el.innerHTML = '';
instance = null;
}
//子应用打包生成的umd格式的js,在window上挂载这三个生命周期,主应用可以直接调用
主应用
import { registerMicroApps, start } from 'qiankun';
registerMicroApps([
{
name: 'react app', // app name registered
entry: '//localhost:7100',
container: '#yourContainer',
activeRule: '/yourActiveRule',
},
{
name: 'vue app',
entry: { scripts: ['//localhost:7100/main.js'] },
container: '#yourContainer2',
activeRule: '/yourActiveRule2',
},
]);
start({
sandbox: {
strictStyleIsolation: true, // 使用shadow dom解决样式冲突
experimentalStyleIsolation: true // 通过添加选择器范围来解决样式冲突 [date-react-app]
}
}); // 开启应用
// 配置全局环境变量
window.__POWERED_BY_QIANKUN__ = true;
window.__INJECTED_PUBLIC_PATH_BY_QIANKUN__ = app.entry;
如果图片出不来,src目录下面加一个文件public-path.js,然后引入,将文件域名指向子应用
if(window.__POWERED_BY_QIANKUN__) {
__webpack_public_path__ = window.__INJECTED_PUBLIC_PATH_BY_QIANKUN__;
}
原理 手写微前端qiankun框架,vue+react双重配置_进阶的巨人001的博客-CSDN博客
1.监视路由变化
2.匹配子应用
3.加载子应用 (unmount(prevApp); 之前的应用需要先卸载)
4.渲染子应用
1.客户端渲染需要通过执行 js 来生成内容
2.浏览器出于安全考虑, innerHtml中的 script 不会加载执行
3.所以需要手动加载子应用的script,执行script中的代码,我们可以用eval或者new Function
监听路由变化,hash的话是 onhashchange, history 监听 popstate、pushState、replaceState
GitHub - lsh555/qiankun: 手写微前端qiankun框架,vue+react双重配置
js沙箱原理 乾坤会根据当前环境是否支持proxy来决定用那种方式。
1.快照沙箱: 激活微应用时将当前的window对象拷贝存起来,然后从modifyPropsMap中恢复这个微应用上次修改的属性到window中。在离开微应用时会与原有的window对象做对比,将有修改的属性保存起来,以便再次进入这个微应用时进行数据恢复,然后把有修改的属性值恢复到以前的状态。
缺点:需要遍历window上的所有属性,性能差,同时间内只能激活一个微应用
2. 代理沙箱 proxy (单例和多例)
import-html-entry 里,也就是加载后的 js 就被包裹了一层
function 包裹了一层,所以代码放在了单独作用域跑,又用 with 修改了 window,所以 window 也被隔离了。
css样式隔离
1. shadow dom 隔离样式
if (appElement.attachShadow) {
shadow = appElement.attachShadow({ mode: 'open' });
} else {
shadow = (appElement as any).createShadowRoot();
}
shadow.innerHTML = innerHTML;
2. 使用scopedCss做到样式隔离
先查找要添加的应用是否有相应的属性,没有的话给子应用容器添加一个属性。然后遍历每个style标签,在每个style标签代码前面增加属性选择符,通过属性选择符+样式来确保样式不被重写
div[data-qiankun="app-vue"]
qiankun通讯方式
1. props,主应用通过全局的mount生命周期传递props
export async function mount(props) {//挂载
render(props);
}
2. initGlobalState(state)
(1)onGlobalStateChange:注册 观察者 函数 - 响应 globalState 变化,在 globalState 发生改变时触发该 观察者 函数。
(2)setGlobalState:设置 globalState - 设置新的值时,内部将执行 浅检查,如果检查到 globalState 发生改变则触发通知,通知到所有的 观察者 函数【深度监听的】
(3)offGlobalStateChange:取消 观察者 函数 - 该实例不再响应 globalState 变化
==第一步:==首先需要在父应用中使用initGlobalState设置全局状态actions并导出供其他组件使用。
==第二步:==然后在main.js中引入actions实例并在注册子应用时通过props传递全局状态actions:
==第三步:==主应用中的组件要修改全局状态actions,就在此组件中引入actions实例
==第四步:==配置子应用的全局状态Actions,子应用中的全局状态必须要跟主应用中的全局状态变量属性名相同,比如主应用中全局状态变量为{project_id: “项目2”},则子应用中也需要保证在setGloabalState时也需要设定相同的变量名。
然后在mounted的生命周期里注入actions实例:
微前端qiankun框架的底层实现原理_veggie_a_h的博客-CSDN博客_qiankun原理
微前端解决方案-qiankun实战及部署 - 简书

网页SEO
1. </code>、<code> meta description</code> 和<code> meta</code> <code>keywords</code> 三者的权重依次减小,我们要想网页有好的排名,必须合理使用这三个标签。<br> 2. 搜索引擎是识别文字,而不识别图片的。就拿网站的Logo来举例子,用a标签包裹,设置背景图(京东)<br> 3. 使用语义化元素(禁止滥用H1标签)<br> 4. 利用 <code><img></code> 中的 alt 属性<br> 5. 设置 <code>rel='nofollow' </code>忽略跟踪,如果某个链接不需要跟踪,可以忽略,爬虫分给每个页面的权重是一定的<br> 6. 提高加载速度(减少重排和重绘)<br> 7. 扁平化网站结构(一个网站的结构层次越少,越有利于“爬虫”的爬取。模仿用户操作)<br> 8. <code>含重要内容的 HTML 代码放在最前面</code>,<code>因为“爬虫”爬取 HTML 的顺序是从上到下</code>,有的搜索引擎对<code>抓取长度有限制</code>,所以要保证重要内容被<code>优先爬取,</code>并且,重要内容不应该由 JavaScript 输出,因为“爬虫”没有办法读取 JavaScript ,同时也要少用 iframe ,因为“爬虫”一般不会去读取它里面的内容。</p>
<h3>SSR VUE NUXT 服务端渲染</h3>
<ul>
<li> <p>客户端渲染 CSR</p> </li>
<li> <p>服务器端渲染 SSR</p> </li>
<li> <p>静态站点生成 SSG:缺点是内容可能过时,每次更改内容时都需要构建和部署应用程序。</p> </li>
<li> <p>增量静态再生 ISR:ISR 是 SSG 的下一个改进,它定期构建和重新验证新页面,以便内容永远不会过时。适合电商,新闻类页面</p> </li>
<li> <p>SSG和ISR都是next提出的</p> </li>
</ul>
<blockquote>
<p>适合高度动态的 Web 应用程序<br> 客户端渲染 CSR. : 典型代表:单页面应用,内容都是js动态渲染<br> 服务器端渲染 SSR : 在服务端获取数据组装页面,返回到浏览器是html,对服务器要求高,主要应用是交互多的页面需要seo的</p>
</blockquote>
<blockquote>
<p>适合高度静态的web程序 插件 PrerenderSPAPlugin<br> 静态站点生成 SSG: 在build的的时候就已经生成好静态页面,放在服务端的也是静态页面,博客,静态官网都非常合适<br> 增量静态再生 ISR:ISR 是 SSG 的下一个改进,它定期构建和重新验证新页面,以便内容永远不会过时</p>
</blockquote>
<blockquote>
<p><strong>原理</strong>:<code>Prerender</code> 就是利用 Chrome 官方出品的 <code>Puppeteer</code> 工具,对页面进行爬取。<br> 在 <code>Webpack</code> 构建阶段的最后,在本地启动一个 <code>Puppeteer</code> 的服务,访问配置了预渲染的路由,然后将 <code>Puppeteer</code> 中渲染的页面输出到 HTML 文件中,并建立路由对应的目录。<br> 所以预渲染的缺点除了需要插件支持以外,由于渲染是在打包阶段,如果页面上有实时更新的数据,则在渲染时显示的不是最新的数据。</p>
<p>打包的时候就预先渲染页面,所以在请求到 index.html 就已经是渲染过的内容。</p>
<p>可以看出,<strong>SSR 和 Prerender 的最大区别</strong>就在于,<code>Prerender 是静态的,SSR 是动态的,SSR 会在服务端实时构建出对应的 DOM</code>。 </p>
<p></p>
</blockquote>
<p>vue-meta-info插件配置 title和meta<br> 公司官网用的就是 PrerenderSPAPlugin 生成的,每个页面一个目录。没用ssg是因为基于nuxt的ssg</p>
<p>1. 如果<strong>页面无数据,或者是纯静态页面,建议使用 Prerender</strong>,这是一种通过预览打包的方式构建页面,也不会增加服务器负担,但其他情况并不推荐。如果<strong>页面数据请求多,又对 SEO 和加载速度有需求的,建议使用 SSR</strong>。</p>
<p>2. 对于高操作需求的项目来说,CSR 可能更加适合,页面显示元素即绑定了操作,而 SSR 和 Prerender 虽然会提前显示页面,但此时页面元素无法操作,仍需要下载完 bundle.js 进行事件绑定才能执行。</p>
<p>3. 客户端渲染中,用户的浏览器中永远只存在一个 Store,服务器端的 Store 是所有用户都要用的,共享Store是有问题的,需要<strong>为每个用户提供一个独立的 Store</strong>。</p>
<p>4. vue的生命周期钩子函数中, 只有 <code>beforeCreate</code> 和 <code>created</code> 会在服务器端渲染(SSR)过程中被调用,这就是说在这两个钩子函数中的代码以及除了vue生命周期钩子函数的全局代码,都将会在服务端和客户端两套环境下执行。<br> 在beforeCreate,created生命周期以及全局的执行环境中调用特定的api前需要判断执行环境。</p>
<p>5. 在客户端到SSR服务器的请求中,客户端是携带有cookie数据的。但是在SSR服务器请求后端接口的过程中,却是没有相应的cookie数据的。因此在SSR服务器进行接口请求的时候,我们需要手动拿到客户端的cookie传给后端服务器。</p>
<p>6. vue有两种路由模式,一种是hash模式,就是我们经常用的#/hasha/hashb这种,还有一种是history模式,就是/historya/historyb这种。因为hash模式的路由提交不到服务器上,因此ssr的路由需要采用history的方式</p>
<p></p>
<h3>yarn和npm的区别https://yydatav.blog.csdn.net/article/details/119251135?spm=1001.2101.3001.6650.1&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-119251135-blog-124731943.pc_relevant_3mothn_strategy_and_data_recovery&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-119251135-blog-124731943.pc_relevant_3mothn_strategy_and_data_recovery&utm_relevant_index=1</h3>
<p><span class="link-card-box"><span class="link-title">https://yydatav.blog.csdn.net/article/details/119251135?spm=1001.2101.3001.6650.1&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-119251135-blog-124731943.pc_relevant_3mothn_strategy_and_data_recovery&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-119251135-blog-124731943.pc_relevant_3mothn_strategy_and_data_recovery&utm_relevant_index=1</span><span class="link-link"><img alt="" class="link-link-icon" src="http://img.e-com-net.com/image/info8/2a4aa1cf4e3e4abd9cac68be3ab104b6.jpg" width="0" height="0">https://yydatav.blog.csdn.net/article/details/119251135?spm=1001.2101.3001.6650.1&utm_medium=distribute.pc_relevant.none-task-blog-2~default~CTRLIST~Rate-1-119251135-blog-124731943.pc_relevant_3mothn_strategy_and_data_recovery&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2~default~CTRLIST~Rate-1-119251135-blog-124731943.pc_relevant_3mothn_strategy_and_data_recovery&utm_relevant_index=1</span></span>https://yydatav.blog.csdn.net/article/details/119251135?spm=1001.2101.3001.6650.1&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-119251135-blog-124731943.pc_relevant_3mothn_strategy_and_data_recovery&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-119251135-blog-124731943.pc_relevant_3mothn_strategy_and_data_recovery&utm_relevant_index=1</p>
<h3>webpack详解</h3>
<p>Webpack 本质上是一个函数,它接受一个配置信息作为参数,执行后返回一个 compiler 对象,调用 <code>compiler</code> 对象中的 run 方法就会启动编译。<code>run</code> 方法接受一个回调,可以用来查看编译过程中的错误信息或编译信息</p>
<p>入口文件(<code>src/index.js</code>)被包裹在最后的立即执行函数中,而它所依赖的模块(<code>src/name.js</code>、<code>src/age.js</code>)则被放进了 <code>modules</code> 对象中(<code>modules</code> 用于存放<strong>入口文件的依赖模块</strong>,<code>key 值为依赖模块路径,value 值为依赖模块源代码</code>)。</p>
<p> Tapable 了!它是一个类似于 Node.js 中的 EventEmitter 的库,但<strong>更专注于自定义事件的触发和处理</strong>。通过 Tapable 我们可以注册自定义事件,然后在适当的时机去执行自定义事件。</p>
<p>syncHook.tap("监听器3", (name) => { console.log("监听器3", name); });<br> 在 Webpack 中,就是通过 <code>tapable</code> 在 <code>comiler</code> 和 <code>compilation</code> 上像这样挂载着一系列<code>生命周期 Hook</code>,它就像是一座桥梁,贯穿着整个构建过程:</p>
<p><code>Webpack Plugin 其实就是一个普通的函数,在该函数中需要我们定制一个 apply 方法。</code>当 Webpack 内部进行插件挂载时会执行 <code>apply</code> 函数。我们可以在 <code>apply</code> 方法中订阅各种生命周期钩子,当到达对应的时间点时就会执行。</p>
<p></p>
<h4><br> 打包过程(*)</h4>
<p>(1)搭建结构,读取配置参数<br> (2)用配置参数对象初始化 <code>Compiler</code> 对象<br> (3)挂载配置文件中的插件<br> (4)执行 <code>Compiler</code> 对象的 <code>run</code> 方法开始执行编译<br> (5)根据配置文件中的 <code>entry</code> 配置项找到所有的入口<br> (6)从入口文件出发,调用配置的 <code>loader</code> 规则,对各模块进行编译<br> (7)找出此模块所依赖的模块,再对依赖模块进行编译<br> (8)等所有模块都编译完成后,根据模块之间的依赖关系,组装代码块 <code>chunk</code><br> (9)把各个代码块 <code>chunk</code> 转换成一个一个文件加入到输出列表<br> (10)确定好输出内容之后,根据配置的输出路径和文件名,将文件内容写入到文件系统</p>
<p></p>
<p><code>Compilation</code> 中的 <code>this.fileDependencies</code>(本次打包涉及到的文件)是用来做什么的?为什么没有地方用到该属性?</p>
<p>这里其实是为了实现 Webpack 的 watch 模式:当文件发生变更时将重新编译。</p>
<p>思路:对 <code>this.fileDependencies</code> 里面的文件进行监听,当文件发生变化时,重新执行 <code>compile</code> 函数。</p>
<p>二十张图片彻底讲明白Webpack设计理念,以看懂为目的 - 掘金</p>
<h3>Webpack HMR 热更新 ,核心流程:</h3>
<ol>
<li>使用 webpack-dev-server (后面简称 WDS)托管静态资源,同时以 Runtime 方式注入 HMR 客户端代码;</li>
<li>浏览器加载页面后,与 WDS 建立 WebSocket 连接;</li>
<li>Webpack 监听到文件变化后,增量构建发生变更的模块,并通过 WebSocket 发送 hash 事件;</li>
<li>浏览器接收到 hash 事件后,请求 manifest 资源文件,确认增量变更范围;</li>
<li>浏览器加载发生变更的增量模块,jsonp请求拿到最新模块代码;</li>
<li>Webpack 运行时触发变更模块的 module.hot.accept 回调,执行代码变更逻辑;</li>
<li>done;</li>
</ol>
<h3>热更新原理</h3>
<p>第一步,在 webpack 的 watch 模式下,文件系统中某一个文件发生修改,webpack 监听到文件变化,根据配置文件对模块重新编译打包,并将打包后的代码通过简单的 JavaScript 对象保存在内存中。</p>
<p>第二步是 webpack-dev-server 和 webpack 之间的接口交互,而在这一步,主要是 dev-server 的中间件 webpack-dev-middleware 和 webpack 之间的交互,webpack-dev-middleware 调用 webpack 暴露的 API 对代码变化进行监控,并且告诉 webpack,将代码打包到内存中。</p>
<p>第三步是 webpack-dev-server 对文件变化的一个监控,这一步不同于第一步,并不是监控代码变化重新打包。当我们在配置文件中配置了 devServer.watchContentBase 为 true 的时候,Server 会监听这些配置文件夹中静态文件的变化,变化后会通知浏览器端对应用进行 live reload。注意,这儿是浏览器刷新,和 HMR 是两个概念。</p>
<p>第四步也是 webpack-dev-server 代码的工作,该步骤主要是通过 sockjs(webpack-dev-server 的依赖)在浏览器端和服务端之间建立一个 websocket 长连接,将 webpack 编译打包的各个阶段的状态信息告知浏览器端,同时也包括第三步中 Server 监听静态文件变化的信息。浏览器端根据这些 socket 消息进行不同的操作。当然服务端传递的最主要信息还是新模块的 hash 值,后面的步骤根据这一 hash 值来进行模块热替换。</p>
<p>webpack-dev-server/client 端并不能够请求更新的代码,也不会执行热更模块操作,而把这些工作又交回给了 webpack,webpack/hot/dev-server 的工作就是根据 webpack-dev-server/client 传给它的信息以及 dev-server 的配置决定是刷新浏览器呢还是进行模块热更新。当然如果仅仅是刷新浏览器,也就没有后面那些步骤了。</p>
<p>HotModuleReplacement.runtime 是客户端 HMR 的中枢,它接收到上一步传递给他的新模块的 hash 值,它通过 JsonpMainTemplate.runtime 向 server 端发送 Ajax 请求,服务端返回一个 json,该 json 包含了所有要更新的模块的 hash 值,获取到更新列表后,该模块再次通过 jsonp 请求,获取到最新的模块代码。这就是上图中 7、8、9 步骤。</p>
<p>而第 10 步是决定 HMR 成功与否的关键步骤,在该步骤中,HotModulePlugin 将会对新旧模块进行对比,决定是否更新模块,在决定更新模块后,检查模块之间的依赖关系,更新模块的同时更新模块间的依赖引用。最后一步,当 HMR 失败后,回退到 live reload 操作,也就是进行浏览器刷新来获取最新打包代码。</p>
<p></p>
<h4>当模块的热替换过程中,如果替换模块失败,有什么回退机制吗?</h4>
<p>模块热更新的错误处理,如果在热更新过程中出现错误,热更新将回退到刷新浏览器</p>
<p></p>
<h4>说一下 webpack 的热更新原理?</h4>
<h4>webpack 通过 watch 可以监测代码的变化;webpack-dev-middleware 可以调用 webpack 暴露的 API 检测代码变化,并且告诉 webpack 将代码保存到内存中;webpack-dev-middleware 通过 sockjs 和 webpack-dev-server/client 建立 webSocket 长连接,将 webpack 打包阶段的各个状态告知浏览器端,最重要的是新模块的 hash 值。webpack-dev-server/client 通过 webpack/hot/dev-server 中的 HMR 去请求新的更新模块,HMR 主要借助 JSONP。先拿到 hash 的 json 文件,然后根据 hash 拼接出更新的文件 js,然后 HotModulePlugin 对比新旧模块和模块依赖完成更新。</h4>
<h4><br> promise模拟接口请求并发限制</h4>
<blockquote>
<p style="margin-left:.0001pt;text-align:justify;">需求描述:<br> 浏览器限制每次最多发出10个请求接口,总共有1000个待请求接口,每个接口的响应时间是随机的,要保证在某个接口请求成功之后立即请求下一个接口,保证当前并发度始终为10。</p>
</blockquote>
<pre><code class="language-javascript">async function asyncPool(poolLimit, array, iteratorFn) {
const ret = []; // 用于存放所有的promise实例
const executing = []; // 用于存放目前正在执行的promise
for (const item of array) {
const p = Promise.resolve(iteratorFn(item)); // 防止回调函数返回的不是promise,使用Promise.resolve进行包裹
ret.push(p);
if (poolLimit <= array.length) {
// then回调中,当这个promise状态变为fulfilled后,将其从正在执行的promise列表executing中删除
const e = p.then(() => executing.splice(executing.indexOf(e), 1));
executing.push(e);
if (executing.length >= poolLimit) {
// 一旦正在执行的promise列表数量等于限制数,就使用Promise.race等待某一个promise状态发生变更,
// 状态变更后,就会执行上面then的回调,将该promise从executing中删除,
// 然后再进入到下一次for循环,生成新的promise进行补充
await Promise.race(executing);
}
}
}
return Promise.all(ret);
}
//测试代码
const timeout = (i) => {
console.log('开始', i);
return new Promise((resolve) => setTimeout(() => {
resolve(i);
console.log('结束', i);
}, i));
};
(async () => {
const res = await asyncPool(2, [1000, 5000, 3000, 2000], timeout);
console.log(res);
})();
</code></pre>
<p>代码的核心思路为:</p>
<ul>
<li>先初始化 limit 个 promise 实例,将它们放到 executing 数组中</li>
<li>使用 Promise.race 等待这 limit 个 promise 实例的执行结果</li>
<li>一旦某一个 promise 的状态发生变更,就将其从 executing 中删除,然后再执行循环生成新的 promise,放入executing 中</li>
<li>重复2、3两个步骤,直到所有的 promise 都被执行完</li>
<li>最后使用 Promise.all 返回所有 promise 实例的执行结果</li>
</ul>
<h4>原型<br> 原型是函数的一个属性prototype;</h4>
<p> 通过该函数实例化出来的对象都可以继承得到原型上的所有属性和方法</p>
<p> 原型对象默认有一个属性constructor ,值为对应的构造函数;另外,有一个属性__proto__,值为Object.prototype</p>
<p></p>
<h4>原型链</h4>
<p> 在JavaScript中万物都是对象,对象和对象之间并不是独立存在的,对象和对象之间有一定关系。</p>
<p> 通过对象__proto__属性指向函数的原型对象(函数.prototype)一层一层往上找,直到找到Object的原型对象(Object.prototype)为止,层层继承的链接结构叫做原型链(通过proto属性形成原型的链式结构,专业术语叫做原型链)</p>
<p></p>
<h4><br><br> flex布局父项常见属性</h4>
<p><br> flex-direction: 设置主轴的方向<br> justify-content: 设置主轴上的子元素排列方式<br> flex-wrap: 设置子元素是否换行<br> align-content: 设置侧轴的子元素的排列方式(多行)<br> align-items:设置侧轴上的子元素排列方式(单行)<br> flex-flow:复合属性,相当于同时设置了flex-direction 和 flex-wrap</p>
<p><span style="color:#38d8f0;">flex:1</span> 是 flex-grow, flex-shrink, flex-basis. 三个属性的简写,默认值为 0 1 auto。该属性有两个快捷值:auto(1 1 auto) 和 none(0 0 auto)。建议优先写 flex 属性,而不是写三个分离的属性,因为浏览器会自动计算其相关值。</p>
<p><span style="color:#4da8ee;">flex-grow</span> 默认为0, 只能是正整数。即父元素有剩余空间也不放大元素。如果为 1,则把剩余空间的一份加给自己的宽度。<br><span style="color:#4da8ee;">flex-shrink</span> 默认为1,只能是正整数。即父元素空间不足则按比例收缩。如果为 0,则不收缩<br><span style="color:#4da8ee;">flex-basis </span>默认为 auto, 即元素本身的大小。这个属性定义了在分配多余空间之前,元素占据的主轴空间,浏览器根据这个属性计算是否有多余空间。可以设置为和 width 和 height 属性一样的值,比如 220px,则元素占据固定空间。</p>
<h4>readyState的五种状态详解 </h4>
<p> 0 - (未初始化)还没有调用send()方法<br> 1 - (载入)已调用send()方法,正在发送请求<br> 2 - (载入完成)send()方法执行完成,已经接收到全部响应内容<br> 3 - (交互)已经接收部分数据。但若在此时调用responseBody和responseText属性获取部分结果将会产生错误,因为状态和响应头部还不完全可用。<br> 4 - (完成)响应内容解析完成,可以在客户端调用了<br> readyState为3的时候把网线拔了,可能只接收到部分信息<br><br> </p>
<h4> 私有组件库http://verdaccio.iflyhed.com 维达斯科<br> </h4>
<ol>
<li> <p>切换本地npm源 (可使用nrm 源管理工具)<br> npm config set registry=http://verdaccio.iflyhed.com/</p> </li>
<li> <p>本地登录</p> <pre><code>1. Login
npm adduser --registry http://verdaccio.iflyhed.com/
2. Publish
npm publish --registry http://verdaccio.iflyhed.com/</code></pre> </li>
</ol>
<h4></h4>
<p>3.使用安装 npm i fif-base<br> 4. 上传包 </p>
<pre><code>npm version patch //自增版本号
npm publish // 推送到服务器</code></pre>
<p></p>
<p><strong>angular 的数据绑定采用什么机制?详述原理</strong></p>
<p>脏检查机制。<br> 双向数据绑定是 AngularJS 的核心机制之一。当 view 中有任何数据变化时,会更新到 model ,当 model 中数据有变化时,view 也会同步更新,显然,这需要一个监控。</p>
<p>原理就是,Angular 在 scope 模型上设置了一个监听队列,用来监听数据变化并更新 view 。每次绑定一个东西到 view 上时 AngularJS 就会往 $watch 队列里插入一条 $watch ,用来检测它监视的 model 里是否有变化的东西。当浏览器接收到可以被 angular context 处理的事件时, $digest 循环就会触发,遍历所有的 $watch ,最后更新 dom。</p>
<p></p>
<h4>vue响应式原理</h4>
<p>在 newVue() 后, Vue 会调用 _init 函数进行初始化,也就是init 过程,在 这个过程Data通过Observer转换成了getter/setter的形式,来对数据追踪变化,当被设置的对象被读取的时候会执行 getter 函数,而在当被赋值的时候会执行 setter函数。</p>
<p>当render function 执行的时候,因为会读取所需对象的值,所以会触发getter函数从而将Watcher添加到依赖中进行依赖收集。</p>
<p>在修改对象的值的时候,会触发对应的 setter, setter通知之前依赖收集得到的 Dep 中的每一个 Watcher,告诉它们自己的值改变了,需要重新渲染视图。这时候这些 Watcher就会开始调用 update 来更新视图。<br> </p>
<p></p>
<h4>proxy和Object.defineProperty区别</h4>
<p>1.Proxy性能优于Object.defineProperty。 Proxy代理的是整个对象Object.defineProperty只代理对象上的某个属性,如果是多层嵌套的数据需要循环递归绑定;<br> 2.对象上定义新属性时,Proxy可以监听到,Object.defineProperty监听不到,需要借助$set方法;<br> 3.数组的某些方法(push、unshift和splice)Object.defineProperty监听不到,Proxy可以监听到;<br> 4.Proxy在ie浏览器存在兼容性问题 ,vue做了降级处理使用 Object.defineProperty</p>
<p>内部使用reflect,proxy存在get陷阱,this可能不会指向调用者。用reflect修正this指向到调用者。<br> 13个api方法。 </p>
<h4>object.definePropety 的深度监听是一次性就全部监听的,而 proxy 的深度监听是在 get 的时候才去递归的,是一个惰性的,很慢的过程,这就是 proxy 性能的优化。开始内部只是一个普通对象,当调用时才会reactive(result)递归添加响应式,将访问的对象变成proxy对象。</h4>
<p></p>
<h4>vue对数组的监听</h4>
<pre><code class="language-javascript">/**
* Vue对数组的变化侦测
* 思想: 通过一个拦截器来覆盖Array.prototype。
* 拦截器其实就是一个Object, 它的属性与Array.prototype一样。 只是对数组的变异方法进行了处理。
*/
function def (obj, key, val, enumerable) {
Object.defineProperty(obj, key, {
value: val,
enumerable: !!enumerable,
writable: true,
configurable: true
})
}
// 数组原型对象
const arrayProto = Array.prototype
// 拦截器
const arrayMethods = Object.create(arrayProto)
// 变异数组方法:执行后会改变原始数组的方法
const methodsToPatch = [
'push',
'pop',
'shift',
'unshift',
'splice',
'sort',
'reverse'
]
methodsToPatch.forEach(function (method) {
// 缓存原始的数组原型上的方法
const original = arrayProto[method]
// 对每个数组编译方法进行处理(拦截)
def(arrayMethods, method, function mutator (...args) {
// 返回的value还是通过数组原型方法本身执行的结果
const result = original.apply(this, args)
// 每个value在被observer()时候都会打上一个__ob__属性
const ob = this.__ob__
// 存储调用执行变异数组方法导致数组本身值改变的数组,主要指的是原始数组增加的那部分(需要重新Observer)
let inserted
switch (method) {
case 'push':
case 'unshift':
inserted = args
break
case 'splice':
inserted = args.slice(2)
break
}
// 重新Observe新增加的数组元素
if (inserted) ob.observeArray(inserted)
// 发送变化通知
ob.dep.notify()
return result
})
})
</code></pre>
<p></p>
<p></p>
<h4>type 和 interface区别</h4>
<p>type一般定义基本类型,(可定义所有类型)扩展用& <strong>基本类型的别名,联合类型,元组类型</strong><br> interface 一般用来定义接口,描述数据类型 , 扩展用extend,<strong>声明合并</strong></p>
<p></p>
<p></p>
<p><strong>cdn的概念,cdn失败了,如何处理。</strong></p>
<p><strong>sort内部原理,找到数组第二大元素,边界问题(一个元素,全都是一个元素) new Set()</strong></p>
<p><strong>sort length<10 插入排序 O(n2),n>10快速排序(二分法,nlogn)</strong></p>
<p>双向绑定</p>
<p>vue层面的优化</p>
<p>虚拟dom的理解</p>
<p>性能优化</p>
<p>学习的途径</p>
<p>http2相比于http1.1的优势</p>
<p>微任务和宏任务</p>
<p>重绘和回流</p>
<p>index.html 如何清缓存 (nginx配置不缓存index.html) </p>
<blockquote>
<p><--如果需要在html页面上设置不缓存,这在标签中加入如下语句--><br> <meta http-equiv="Pragma" content="no-cache"><br> <--用于设定禁止浏览器从本地机的缓存中调阅页面内容--><br> <meta http-equiv="Cache-Control" content="no-cache, must-revalidate"><br> <-- Cache-Control指定请求和响应遵循的缓存机制。在请求消息或响应消息中设置Cache-Control并不会修改另一个消息处理过程中的缓存处理过程。--><br> <meta http-equiv="Expires" content="0"></p>
</blockquote>
<p>router,axios封装,</p>
<p></p>
<p></p>
<h4>vuex</h4>
<ul>
<li><strong>Vuex 是通过 new 一个 vue 实例,并把 state 作为 vue 的 data 利用 vue 的响应式系统把 state 中的数据变为了 响应式数据。</strong>* **getter 本质上是依赖了 vue 的 computed 实现了缓存机制。**store.js</li>
<li>定义了 install 方法,该方法在执行 Vue.use(Vuex) 时会自动调用,install 方法中主要是调用 mixin 方法,在 beforeCreate 勾子中为每个组件都混入一个$store 属性,他们都指向同一个 </li>
</ul>
<p></p>
<p><strong>进程是cpu资源分配的最小单位(是能拥有资源和独立运行的最小单位)</strong></p>
<p><strong>线程是cpu调度的最小单位(线程是建立在进程的基础上的一次程序运行单位)</strong></p>
<p><br><strong>VUEX应用场景 原理</strong></p>
<p><strong>D3 api</strong></p>
<p><strong>适配问题 不同分辨率</strong></p>
<p><strong>性能优化 </strong></p>
<p><strong> 什么场景不能用this </strong></p>
<p><strong> es6语法 </strong></p>
<p><strong> 关系图的数据结构 </strong></p>
<p></p>
<p></p>
<p><strong>pinia和vuex的区别</strong></p>
<p><strong>qiankun沙箱原理(js、css)</strong></p>
<p><strong>vite 和wabpack的区别</strong></p>
<p><strong>vite首次启动过慢解决方案</strong></p>
<p></p>
<h4>vue更新页面方式</h4>
<p>$forceUpdate this.$router.go(0) 使用v-if标记 改变key<br> $forceUpdate 在依赖发生变化的时候会通知watcher,然后通知watcher来调用update方法,重新render</p>
<pre><code class="language-javascript">Vue.prototype.$forceUpdate = function () {
const vm: Component = this
if (vm._watcher) {
vm._watcher.update()
}
}</code></pre>
<p></p>
<p>requestIdleCallback 会在网页渲染完成后,CPU 空闲时执行<br> requestAnimationFrame 浏览器每次渲染都会执行,不用自己计算时间</p>
<p>首屏时间 firstScreen - performance.timing.navigationStart<br> 白屏时间 </p>
<p><a href="http://img.e-com-net.com/image/info8/579eeada48ad46e99811e8c69a533385.jpg" target="_blank"><img alt="项目问题~_第3张图片" height="110" src="http://img.e-com-net.com/image/info8/579eeada48ad46e99811e8c69a533385.jpg" width="650" style="border:1px solid black;"></a></p>
<p> async脚本会在页面加载完毕后执行。</p>
<p></p>
<p></p>
<h4>axios底层实现原理</h4>
<pre><code class="language-javascript">class Axios {
constructor() {
新增代码
this.interceptors = {
request: new InterceptorsManage,
response: new InterceptorsManage
}
}
request(config) {
return new Promise(resolve => {
const {url = '', method = 'get', data = {}} = config;
// 发送ajax请求
console.log(config);
const xhr = new XMLHttpRequest();
xhr.open(method, url, true);
xhr.onload = function() {
console.log(xhr.responseText)
resolve(xhr.responseText);
};
xhr.send(data);
})
}
}
class InterceptorsManage {
constructor() {
this.handlers = [];
}
use(fullfield, rejected) {
this.handlers.push({
fullfield,
rejected
})
}
}</code></pre>
<p></p>
<p></p>
<h4>ts比js V8引擎中编译效率更高</h4>
<p>js -----(parse) --> ast语法树 -----(类型推断,不同类型存储地址不同,ts有类型定义,省去了推断,更高效)----------> 字节码 ->机器码运行</p>
<p></p>
<p></p>
<h4>vue3性能优化</h4>
<p>1. 响应式系统升级 object.defineProperty,递归对象每个属性,proxy 在对象外层加一个拦截,惰性响应式,只有获取属性时才会动态设置proxy, 内部使用reflect,避免了proxy的get陷阱</p>
<p>2. Vue2中会通过<strong>标记根节点</strong>的操作,<strong>优化diff过程</strong>,但是静态节点还需要被diff,这个过程没有被优化<br> 当组件的状态发生变化后,会通知 watcher 触发 update 函数,最终执行虚拟dom的patch操作,遍历所有的虚拟节点,找到差异更新到真实节点上<br> diff的过程中会去比较整个虚拟dom,先对比新旧的div以及他的属性,然后再对比他的子节点<br> Vue2中渲染的最小单位是组件</p>
<p>Vue3中标记和提升所有的静态节点,diff的时候只需要对比动态节点内容 <code>Fragments</code>片段的特性<br> 几个静态节点的dom全部都被提取到了最外层,这些被提升的静态节点,只有在创建的时候被创建一次,之后我们在调用render的时候,只需要进行复用就好。</p>
<p>3. catchHandler 缓存函数,再次进行调用的时候,就会通过缓存中获取函数</p>
<p>4. 对 Tree-shaking 的依赖更好,按需引入做的更好</p>
<p></p>
<h4>vite和webpack的区别</h4>
<p>vite服务器启动速度比webpack快,由于vite启动的时候不需要打包,也就无需分析模块依赖、编译,所以启动速度非常快。当浏览器请求需要的模块时,再对模块进行编译,这种按需动态编译的模式,极大缩短了编译时间,当项目越大,文件越多时,vite的开发时优势越明显。vite热更新比webpack快,vite在HRM方面,当某个模块内容改变时,让浏览器去重新请求该模块即可,而不是像webpack重新将该模块的所有依赖重新编译。</p>
<p>Vite的使用简单,只需执行初始化命令,就可以得到一个预设好的开发环境,开箱即获得一堆功能,包括:CSS预处理、html预处理、异步加载、分包、压缩、HMR等。使用复杂度介于Parcel和Webpack的中间,只是暴露了极少数的配置项和plugin接口,既不会像Parcel一样配置不灵活,又不会像Webpack一样需要了解庞大的loader、plugin生态,灵活适中、复杂度适中。</p>
<h4>加速vite首次启动慢的问题</h4>
<p>1. vite.config.ts,添加配置预打包的文件,比较繁琐<br> 2. vite-plugin-optimize-persist 插件,首次启动会给package.json文件添加预打包的配置, 第一次启动慢,再次进入会使用缓存,加速启动</p>
<p></p>
<h4>判断数组的方法<br> 深拷贝和浅拷贝的区别,,,扩展运算符是深拷贝还是浅拷贝...</h4>
<p>... 当拷贝对象的<strong>属性值</strong>对应的都是<strong>基本类型数据</strong>,可以理解为<strong>深拷贝</strong>。当拷贝对象的<strong>属性</strong>对应的值为数组或对象等<strong>引用类型</strong>时,为<strong>浅拷贝</strong></p>
<p><strong>跨域的方案,线上如何解决的 <br> 前端优化 <br> promise.all原理<br> 从0开始搭建框架需要考虑什么</strong></p>
<p>jsonp是一种跨域通信的手段,它的原理其实很简单:</p>
<ol>
<li> <p>首先是利用script标签的src属性来实现跨域。</p> </li>
<li> <p>通过将前端方法作为参数传递到服务器端,然后由服务器端注入参数之后再返回,实现服务器端向客户端通信。</p> </li>
<li> <p>由于使用script标签的src属性,因此只支持get方法</p> </li>
</ol>
<p>Loader直译为"加载器"。Webpack将一切文件视为模块,但是webpack原生是只能解析js文件,如果想将其他文件也打包的话,就会用到loader。 所以Loader的作用是让webpack拥有了加载和解析非JavaScript文件的能力。<br> loader它只专注于转化文件(transform)这一个领域,完成压缩,打包,语言翻译; 而plugin不仅只局限在打包,资源的加载上,还可以打包优化和压缩,重新定义环境变量等</p>
<p>watch和computed的区别</p>
<p></p>
<h2>webview 长按事件 js 监听</h2>
<pre><code class="language-javascript">var timeOutEvent = 0; //定时器
//开始按
function gtouchstart() {
timeOutEvent = setTimeout("longPress()", 500); //这里设置定时器,定义长按500毫秒触发长按事件,时间可以自己改,个人感觉500毫秒非常合适
return false;
};
//手释放,如果在500毫秒内就释放,则取消长按事件,此时可以执行onclick应该执行的事件
function gtouchend() {
clearTimeout(timeOutEvent); //清除定时器
if (timeOutEvent != 0) {
//这里写要执行的内容(尤如onclick事件)
//alert("你这是点击,不是长按");
}
return false;
};
//如果手指有移动,则取消所有事件,此时说明用户只是要移动而不是长按
function gtouchmove() {
clearTimeout(timeOutEvent); //清除定时器
timeOutEvent = 0;
};
//真正长按后应该执行的内容
function longPress() {
timeOutEvent = 0;
//执行长按要执行的内容,如弹出菜单
//alert("长按事件触发");
do_Page.fire("showTool",{"index":index,"url":images[index].source});
}</code></pre>
<p>CORS全称“跨域资源共享”,它是一种机制通过添加额外的HTTP头部告诉浏览器,允许origin上的web应用访问不同源服务器资源,可以在XMLHttpRequest、Fetch中使用CORS发起跨域请求。</p>
<p>移动端bug</p>
<p>移动端页面开发bug记录 多年总结 长期更新_泡面而已的博客-CSDN博客_前端开发 移动端输入bug</p>
</div>
</div>
</div>
</div>
</div>
<!--PC和WAP自适应版-->
<div id="SOHUCS" sid="1730068361750065152"></div>
<script type="text/javascript" src="/views/front/js/chanyan.js"></script>
<!-- 文章页-底部 动态广告位 -->
<div class="youdao-fixed-ad" id="detail_ad_bottom"></div>
</div>
<div class="col-md-3">
<div class="row" id="ad">
<!-- 文章页-右侧1 动态广告位 -->
<div id="right-1" class="col-lg-12 col-md-12 col-sm-4 col-xs-4 ad">
<div class="youdao-fixed-ad" id="detail_ad_1"> </div>
</div>
<!-- 文章页-右侧2 动态广告位 -->
<div id="right-2" class="col-lg-12 col-md-12 col-sm-4 col-xs-4 ad">
<div class="youdao-fixed-ad" id="detail_ad_2"></div>
</div>
<!-- 文章页-右侧3 动态广告位 -->
<div id="right-3" class="col-lg-12 col-md-12 col-sm-4 col-xs-4 ad">
<div class="youdao-fixed-ad" id="detail_ad_3"></div>
</div>
</div>
</div>
</div>
</div>
</div>
<div class="container">
<h4 class="pt20 mb15 mt0 border-top">你可能感兴趣的:(excel)</h4>
<div id="paradigm-article-related">
<div class="recommend-post mb30">
<ul class="widget-links">
<li><a href="/article/1950233451282100224.htm"
title="python 读excel每行替换_Python脚本操作Excel实现批量替换功能" target="_blank">python 读excel每行替换_Python脚本操作Excel实现批量替换功能</a>
<span class="text-muted">weixin_39646695</span>
<a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E8%AF%BBexcel%E6%AF%8F%E8%A1%8C%E6%9B%BF%E6%8D%A2/1.htm">读excel每行替换</a>
<div>Python脚本操作Excel实现批量替换功能大家好,给大家分享下如何使用Python脚本操作Excel实现批量替换。使用的工具Openpyxl,一个处理excel的python库,处理excel,其实针对的就是WorkBook,Sheet,Cell这三个最根本的元素~明确需求原始excel如下我们的目标是把下面excel工作表的sheet1表页A列的内容“替换我吧”批量替换为B列的“我用来替换的</div>
</li>
<li><a href="/article/1950204827929735168.htm"
title="办公党必备!Excel文件批量加密神器!一键保护你的重要数据" target="_blank">办公党必备!Excel文件批量加密神器!一键保护你的重要数据</a>
<span class="text-muted">阿幸软件杂货间</span>
<a class="tag" taget="_blank" href="/search/Excel/1.htm">Excel</a><a class="tag" taget="_blank" href="/search/excel/1.htm">excel</a>
<div>软件介绍今天推荐的这一款专为Excel文件设计的批量加密工具,能够帮助用户快速、高效地为多个Excel文件设置密码保护,有效防止数据泄露。软件特点本地化离线处理支持批量操作完全免费软件操作选择你需要加密的文件和路径,设置密码进行加密即可软件下载夸克网盘迅雷网盘UC网盘</div>
</li>
<li><a href="/article/1950202054219722752.htm"
title="Pandas:数据科学的超级瑞士军刀" target="_blank">Pandas:数据科学的超级瑞士军刀</a>
<span class="text-muted">科技林总</span>
<a class="tag" taget="_blank" href="/search/DeepSeek%E5%AD%A6AI/1.htm">DeepSeek学AI</a><a class="tag" taget="_blank" href="/search/%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD/1.htm">人工智能</a>
<div>**——从零基础到高效分析的进化指南**###**一、Pandas诞生:数据革命的救世主****2010年前的数据分析噩梦**:```python#传统Python处理表格数据data=[]forrowincsv_file:ifrow[3]>100androw[2]=="China":data.append(float(row[5])#代码冗长易错!```**核心痛点**:-Excel处理百万行崩</div>
</li>
<li><a href="/article/1950177847956008960.htm"
title="【免费下载】 Aspose for Java:解锁无水印、无限制的文档处理能力" target="_blank">【免费下载】 Aspose for Java:解锁无水印、无限制的文档处理能力</a>
<span class="text-muted">房征劲Kendall</span>
<div>AsposeforJava:解锁无水印、无限制的文档处理能力【下载地址】AsposeforJava-去除水印和数量限制AsposeforJava-去除水印和数量限制Aspose是一个著名的文档处理库,专为Java应用程序设计,支持多种文档格式的操作,如Word、Excel、PDF等项目地址:https://gitcode.com/open-source-toolkit/56c82项目介绍在现代企业</div>
</li>
<li><a href="/article/1950122628761055232.htm"
title="使用Python操作Excel,删重复数据及keep参数用法并保存的例子" target="_blank">使用Python操作Excel,删重复数据及keep参数用法并保存的例子</a>
<span class="text-muted">白帽黑客艾登</span>
<a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/excel/1.htm">excel</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a><a class="tag" taget="_blank" href="/search/Python%E7%BC%96%E7%A8%8B/1.htm">Python编程</a><a class="tag" taget="_blank" href="/search/Python%E5%AD%A6%E4%B9%A0/1.htm">Python学习</a><a class="tag" taget="_blank" href="/search/%E6%8A%80%E8%83%BD%E5%88%86%E4%BA%AB/1.htm">技能分享</a>
<div>01Ex按列标题删重复的数据解析:我们使用了pandas库读取Excel文件,并使用drop_duplicates()函数删除重复数据。其中,subset参数指定了删除重复数据的列(列名),keep参数指定了保留哪个重复记录(默认为第一个记录)。inplace=True参数表示在原始数据上进行操作。最后,我们使用to_excel()函数将处理后的数据,保存到一个新的Excel文件中,其中index</div>
</li>
<li><a href="/article/1950073211790094336.htm"
title="批量二维码生成器 v3.2.0:绿色便携,WIFI 码 / Excel 导入够实用" target="_blank">批量二维码生成器 v3.2.0:绿色便携,WIFI 码 / Excel 导入够实用</a>
<span class="text-muted">潇洒飘逸的阿楠</span>
<a class="tag" taget="_blank" href="/search/%E7%BB%8F%E9%AA%8C%E5%88%86%E4%BA%AB/1.htm">经验分享</a>
<div>做活动时总被二维码绊住:要给50个参会者做专属码,在线工具怕信息存云端,手动一个个生成,改备注格式能错三次——试了这个v3.2.0绿色版,发现批量处理时藏着几个顺手的细节。下载地址:夸克网盘分享备用地址:迅雷云盘输家里的WIFI名和密码,生成的码客人扫一下就连上,不用再扯着嗓子喊“密码是小写字母加数字”;上周帮咖啡店做,把码印在杯套上,熟客说比问店员省事。把客户姓名和编号填进表格,批量生成后,备注</div>
</li>
<li><a href="/article/1950047365528350720.htm"
title="百旺金赋航天金税发票清单接口软件使用指南" target="_blank">百旺金赋航天金税发票清单接口软件使用指南</a>
<span class="text-muted"></span>
<div>本文还有配套的精品资源,点击获取简介:《百旺金赋航天金税发票清单接口软件详解与核心组件解析》详细介绍了该软件的便捷性和功能,它能将Excel销售清单转换成XML格式,简化发票开具流程。该软件通过动态链接库(DLL)文件实现高效数据转换,并支持与金税系统的对接,提升企业财务效率并确保数据安全性。1.百旺金赋航天金税发票清单接口软件概述软件应用背景百旺金赋航天金税发票清单接口软件作为一种财务信息化工具</div>
</li>
<li><a href="/article/1950036646590214144.htm"
title="Python操作excel,工作效率提高篇_python对xlsx文档进行操作怎么提速" target="_blank">Python操作excel,工作效率提高篇_python对xlsx文档进行操作怎么提速</a>
<span class="text-muted">2401_84266286</span>
<a class="tag" taget="_blank" href="/search/%E7%A8%8B%E5%BA%8F%E5%91%98/1.htm">程序员</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/excel/1.htm">excel</a><a class="tag" taget="_blank" href="/search/%E7%BD%91%E7%BB%9C/1.htm">网络</a>
<div>上面的代码是对工作簿最基本的操作,新建工作簿和保存工作簿,还有关闭当前工作簿。importosfile_path='table'file_list=os.listdir(file_path)foriinfile_list:print(i)列出文件夹下所有文件和子文件夹的名称,这是方便总结和查看文件的。importxlwingsasxwapp=xw.App(visible=False,add_boo</div>
</li>
<li><a href="/article/1950026850826776576.htm"
title="day12-逻辑函数(IF、And、Or)" target="_blank">day12-逻辑函数(IF、And、Or)</a>
<span class="text-muted">鱼和熊掌兼得</span>
<div>今天想来说说我的学习收获,以下为一些心得和感悟。时间过的很快,目前已经完成了一半的打卡,回头想想,由一开始的觉得很容易呀,到现在觉得有些吃力。短短10几天的时间,我觉得自己的收获很大。越是将课程学习下去,越能体会储君老师说的那句话,越是碎片化时代,越需要系统性学习。因为,在以前我的Excel学习是非常的零散,基本上是需要用的时候,就从网上学习一点,导致我什么都知道皮毛,但是没有系统性的了解。这是第</div>
</li>
<li><a href="/article/1950026433623552000.htm"
title="2025年云服务器怎么选?云服务器性价比指南" target="_blank">2025年云服务器怎么选?云服务器性价比指南</a>
<span class="text-muted">telunxiaosu1</span>
<a class="tag" taget="_blank" href="/search/%E6%9C%8D%E5%8A%A1%E5%99%A8/1.htm">服务器</a><a class="tag" taget="_blank" href="/search/%E8%BF%90%E7%BB%B4/1.htm">运维</a><a class="tag" taget="_blank" href="/search/%E9%98%BF%E9%87%8C%E4%BA%91/1.htm">阿里云</a><a class="tag" taget="_blank" href="/search/%E5%8D%8E%E4%B8%BA%E4%BA%91/1.htm">华为云</a><a class="tag" taget="_blank" href="/search/%E4%BA%AC%E4%B8%9C%E4%BA%91/1.htm">京东云</a>
<div>写作初衷:作为一个购买多年云服务器经历的爱好者,最喜欢看各厂商的优惠活动,反复比较各厂商的优惠,找到最具性价比的那一款。我就像一个互联网的猹,在京东云、阿里云、腾讯云的官网里反复对比、反复横跳,但不得不说,这个过程还是比较累的,尤其是网上的众多活动叠加,新客专享,生怕自己被背刺。所以,写下这篇文章,制成excel汇总表,供大家参考,包括了京东云、阿里云、腾讯云、华为云4大厂商(别的小厂怕跑路hhh</div>
</li>
<li><a href="/article/1950001848932954112.htm"
title="Hutool Java工具类库-ExcelUtil" target="_blank">Hutool Java工具类库-ExcelUtil</a>
<span class="text-muted">〃冷·夏ぐ</span>
<a class="tag" taget="_blank" href="/search/Hutool/1.htm">Hutool</a><a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/excel/1.htm">excel</a>
<div>目录依赖:ExcelReader(Excel读取):1.从文件中读取Excel为ExcelReader2.从流中读取Excel为ExcelReader3.读取指定的sheet4.读取Excel中所有行和列,都用列表表示5.读取为Map列表,默认第一行为标题行,Map中的key为标题,value为标题对应的单元格值6.读取为Bean列表,Bean中的字段名为标题,字段值为标题对应的单元格值Excel</div>
</li>
<li><a href="/article/1949994907238199296.htm"
title="影刀RPA_批量添加用户至企业微信_源码解读" target="_blank">影刀RPA_批量添加用户至企业微信_源码解读</a>
<span class="text-muted">RPA+AI十二工作室</span>
<a class="tag" taget="_blank" href="/search/%E5%BD%B1%E5%88%80/1.htm">影刀</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a><a class="tag" taget="_blank" href="/search/%E5%BD%B1%E5%88%80/1.htm">影刀</a><a class="tag" taget="_blank" href="/search/rpa/1.htm">rpa</a><a class="tag" taget="_blank" href="/search/%E4%BC%81%E4%B8%9A%E5%BE%AE%E4%BF%A1/1.htm">企业微信</a><a class="tag" taget="_blank" href="/search/%E8%87%AA%E5%8A%A8%E5%8C%96/1.htm">自动化</a>
<div>一、项目简介本项目是一个基于影刀RPA(RoboticProcessAutomation)开发的自动化工具,主要功能是通过手机号码批量添加用户至企业微信。项目利用企业微信客户端自动化操作,实现了从手机号导入、去重处理到批量发送好友请求的全流程自动化。项目特点:支持通过数据表格或Excel导入手机号自动去重和格式清洗企业微信窗口自动化控制操作结果分类统计与导出二、项目结构xbot_robot/├──</div>
</li>
<li><a href="/article/1949991882549424128.htm"
title="年月日_怎样在excel日期表格中提取年月日等信息?" target="_blank">年月日_怎样在excel日期表格中提取年月日等信息?</a>
<span class="text-muted">weixin_39566882</span>
<a class="tag" taget="_blank" href="/search/%E5%B9%B4%E6%9C%88%E6%97%A5/1.htm">年月日</a>
<div>“hello小伙伴们大家好,我是归一。本节内容我将继续给大家介绍ExcelPowerQuery数据处理实用的18种方法中的第11招——提取日期信息。下面,我们开始今天的学习吧~”#表格制作excel##在家办公日记##在家办公日记#01业务问题:如何提取日期中的年月日和季度?下面,我们来看这样一个问题:现有一张销售数据表,其中有一个订单日期字段,由于我们想要查看每个月、每个季度的销售情况,所以还需</div>
</li>
<li><a href="/article/1949990495526645760.htm"
title="Excel身份证里提取出生年月日" target="_blank">Excel身份证里提取出生年月日</a>
<span class="text-muted">狼头龙</span>
<a class="tag" taget="_blank" href="/search/excel/1.htm">excel</a>
<div>Excel身份证里提取出生年月日如果身份证号码在A2单元格,出生年月日要在C2中显示,那么C2中写入一下代码:=TEXT(MID(A2,7,8),“0000年00月00日”)其中A2为身份证号所在的单元格。</div>
</li>
<li><a href="/article/1949987091685371904.htm"
title="Excel根据身份证号提取信息" target="_blank">Excel根据身份证号提取信息</a>
<span class="text-muted">念念不忘 必有回响</span>
<a class="tag" taget="_blank" href="/search/excel%E5%AD%A6%E4%B9%A0/1.htm">excel学习</a><a class="tag" taget="_blank" href="/search/excel/1.htm">excel</a>
<div>概览本篇文章主要对根据身份证号码提取出生年月日、年龄、性别、退休年龄这三项进行讲解。一.提取出生年月日公式:=TEXT(MID(B2,7,8),“0000-00-00”)MID(B2,7,8):表示从单元格B2中的字符串(这里是身份证号),从第7个字符开始,提取长度为8个字符的子串。通常这8个字符就是包含出生年月日的信息;TEXT(…,“0000-00-00”):使用TEXT函数将提取出来的出生年</div>
</li>
<li><a href="/article/1949983688385163264.htm"
title="EXCEL——提取身份证中的出生年月日" target="_blank">EXCEL——提取身份证中的出生年月日</a>
<span class="text-muted">William.csj</span>
<a class="tag" taget="_blank" href="/search/%23/1.htm">#</a><a class="tag" taget="_blank" href="/search/EXCEL/1.htm">EXCEL</a><a class="tag" taget="_blank" href="/search/excel/1.htm">excel</a>
<div>1.用到的函数: TEXT MID2.函数语法:TEXT: 语法格式:TEXT(value,format_text) 其中,value为数字值。format_text为设置单元格格式中自己所要选用的文本格式。MID: 函数的语法格式:MID(text,start_num,num_chars) 其中,text为字符串,start_num为开始截取位置,num_chars为截取字符个数。3</div>
</li>
<li><a href="/article/1949978131595063296.htm"
title="提取excel中的年月日" target="_blank">提取excel中的年月日</a>
<span class="text-muted"></span>
<div>在Excel中提取出生日期,可以通过公式将年龄描述转换为时间差,再用当前日期减去时间差。以下是分步解决方案:步骤1:准备辅助列(提取年、月、日)假设年龄数据在A列(A2开始),在B、C、D列分别提取年/月/日:列公式B2(年)=IFERROR(IF(FIND("岁",A2),--LEFT(A2,FIND("岁",A2)-1),0),0)C2(月)=IFERROR(IF(FIND("个月",A2),</div>
</li>
<li><a href="/article/1949921904051679232.htm"
title="RAGFlow 框架调研报告" target="_blank">RAGFlow 框架调研报告</a>
<span class="text-muted">it_czz</span>
<a class="tag" taget="_blank" href="/search/%E6%9E%B6%E6%9E%84/1.htm">架构</a>
<div>RAGFlow框架调研报告1.概述RAGFlow是一个开源的检索增强生成(RAG)框架,专注于深度文档理解和高精度检索。它通过先进的文档解析能力和可视化调试功能,为企业提供了一个强大的知识库问答解决方案。1.1核心特性深度文档处理:内置DeepDoc引擎,支持复杂文档解析高精度检索:提供可视化分块和引用追踪多模态支持:支持文本、图片、PDF、Excel等多种格式开源自托管:完全开源,支持私有化部署</div>
</li>
<li><a href="/article/1949910053515489280.htm"
title="Excel 面试 05 查找函数组合 INDEX-MATCH" target="_blank">Excel 面试 05 查找函数组合 INDEX-MATCH</a>
<span class="text-muted">练习两年半的工程师</span>
<a class="tag" taget="_blank" href="/search/Excel/1.htm">Excel</a><a class="tag" taget="_blank" href="/search/excel/1.htm">excel</a>
<div>Excel的INDEX-MATCH是一种强大的函数组合,用于查找和返回表格中的值。相比于传统的VLOOKUP或HLOOKUP,它更灵活且高效,尤其在需要双向查找或处理动态列时表现出色。INDEX-MATCH基本原理INDEX函数:返回数组中指定位置的值。语法:INDEX(array,row_num,[column_num])array:要从中取值的范围或数组。row_num:指定返回值的行号。co</div>
</li>
<li><a href="/article/1949874105176092672.htm"
title="离线环境下如何优雅地部署 Mentor Questa" target="_blank">离线环境下如何优雅地部署 Mentor Questa</a>
<span class="text-muted">CFAteam</span>
<a class="tag" taget="_blank" href="/search/EDA%E5%B7%A5%E5%85%B7%E5%AE%89%E8%A3%85%E6%8C%87%E5%8D%97/1.htm">EDA工具安装指南</a><a class="tag" taget="_blank" href="/search/EDA/1.htm">EDA</a><a class="tag" taget="_blank" href="/search/%E6%9C%8D%E5%8A%A1%E5%99%A8/1.htm">服务器</a><a class="tag" taget="_blank" href="/search/%E8%BF%90%E7%BB%B4/1.htm">运维</a><a class="tag" taget="_blank" href="/search/fpga%E5%BC%80%E5%8F%91/1.htm">fpga开发</a>
<div>MentorQuesta(前称ModelSimSE)是SiemensEDA旗下的重要数字仿真平台,被广泛用于ASIC和FPGA的功能验证、测试平台搭建和UVM流程开发。相比SynopsysVCS和CadenceXcelium,Questa更注重仿真引擎的灵活性与图形交互性。但在实际部署中,很多客户面临着“无法联网”或“内网部署”场景,如:高校教学机房受网络限制企业设计环境为内网隔离区军工科研单位需</div>
</li>
<li><a href="/article/1949851652903202816.htm"
title="第二周复盘" target="_blank">第二周复盘</a>
<span class="text-muted">Yu頔</span>
<div>Yu頔第二周复盘(一)本周目标1、思维导图制作(至少四个)2、掌握每天EXCEL课程的知识3、输出(至少5篇)4、录制翻转课堂(至少2个)(二)行动1、EXCEL课程学习时间:60分钟/每天质量:熟练度较好2、思维导图制作时间:30分钟/每天质量:一般3、输出时间:完成三天质量:较差,主要是复制打卡内容4、录制翻转课堂完成两个翻转课堂的录制(三)未完成原因1、时间安排不当:主要在晚上打卡,时间紧导</div>
</li>
<li><a href="/article/1949842317368160256.htm"
title="【Java实例】服务器IP一站式管理" target="_blank">【Java实例】服务器IP一站式管理</a>
<span class="text-muted">科马</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/%E6%9C%8D%E5%8A%A1%E5%99%A8/1.htm">服务器</a><a class="tag" taget="_blank" href="/search/tcp%2Fip/1.htm">tcp/ip</a><a class="tag" taget="_blank" href="/search/spring/1.htm">spring</a><a class="tag" taget="_blank" href="/search/cloud/1.htm">cloud</a><a class="tag" taget="_blank" href="/search/spring/1.htm">spring</a><a class="tag" taget="_blank" href="/search/boot/1.htm">boot</a><a class="tag" taget="_blank" href="/search/spring/1.htm">spring</a>
<div>统一管理服务器IP、账户与访问权限的一站式解决方案在实际运维或开发工作中,我们常常面临以下问题:多台服务器IP分散管理,Excel记录混乱;登录账户密码分发不规范,存在泄露风险;运维人员频繁远程登录操作,缺乏统一权限审计;无法实时了解服务器运行状态和资源使用情况;登录方式不统一,甚至需要人工提供临时口令;因此,我设计并开发了一个「服务器IP地址统一管理与访问控制系统」,目标是:✅统一管理服务器资产</div>
</li>
<li><a href="/article/1949793158560804864.htm"
title="C# ML.NET回归模型:用代码预测未来的“魔法”!" target="_blank">C# ML.NET回归模型:用代码预测未来的“魔法”!</a>
<span class="text-muted">墨夶</span>
<a class="tag" taget="_blank" href="/search/C%23%E5%AD%A6%E4%B9%A0%E8%B5%84%E6%96%99/1.htm">C#学习资料</a><a class="tag" taget="_blank" href="/search/c%23/1.htm">c#</a><a class="tag" taget="_blank" href="/search/.net/1.htm">.net</a><a class="tag" taget="_blank" href="/search/%E5%9B%9E%E5%BD%92/1.htm">回归</a>
<div>**预测未来?不,是让数据替你说话!**想象一下:你坐在办公室里,老板突然问:“下个月的销售额能到多少?”你盯着Excel表格,头大如斗,公式写了一行又一行,结果还是不准!客户问:“我们产品价格怎么定最合适?”你却只能靠“感觉”回答!ML.NET回归模型就是你的“神兵利器”!它能:✅预测数值型目标:销售额、房价、车费……统统拿下!✅自动调优模型:不用手动调参,AI帮你选最优方案!✅无缝集成C#:不</div>
</li>
<li><a href="/article/1949734531007311872.htm"
title="使用exceljs导出luckysheet表格 纯前端 支持离线使用" target="_blank">使用exceljs导出luckysheet表格 纯前端 支持离线使用</a>
<span class="text-muted"></span>
<div>一.技术exceljs,luckysheet二.实现参考网上博文exceljs对导出lucksheet表格的实现,发现存在一些问题并给予修复:1.字体颜色、字号,加粗等适配的问题.2.单元格对齐方式不生效;3.单元格边框无法绘制;4.单元格边框颜色及线型错乱;5.单元格列宽处理;6.合并单元格导出错乱;7.其他的一些BUG三.注意事项1、由于luckysheet在网页端和excel分辨率无法保持完</div>
</li>
<li><a href="/article/1949726454459723776.htm"
title="Excel——重复值处理" target="_blank">Excel——重复值处理</a>
<span class="text-muted"></span>
<div>识别重复行的三种方法方法1:COUNTIF公式法在E2单元格输入公式:=COUNTIF($B$2:$B2,B2)>1下拉填充至所有数据行结果为TRUE的即为重复行(会标出第二次及以后出现的重复项)方法2:排序+IF公式法按商机号排序(数据→排序)在E2输入:=IF(B2=B1,"重复","")下拉填充,标记"重复"的即为重复行方法3:数据透视表法选择数据区域→插入→数据透视表将"商机号"拖到行区域</div>
</li>
<li><a href="/article/1949644884424060928.htm"
title="[ Pyqt连接数据库/excel ] : 在Pyqt中使用python连接数据库+excel读写并导入mysql+系统登录界面+pyqt多窗口切换。" target="_blank">[ Pyqt连接数据库/excel ] : 在Pyqt中使用python连接数据库+excel读写并导入mysql+系统登录界面+pyqt多窗口切换。</a>
<span class="text-muted">rqtz</span>
<a class="tag" taget="_blank" href="/search/PyQt%E7%B3%BB%E5%88%97/1.htm">PyQt系列</a><a class="tag" taget="_blank" href="/search/%E9%A1%B9%E7%9B%AE%E5%BC%80%E5%8F%91/1.htm">项目开发</a><a class="tag" taget="_blank" href="/search/pyqt/1.htm">pyqt</a><a class="tag" taget="_blank" href="/search/mysql/1.htm">mysql</a><a class="tag" taget="_blank" href="/search/excel/1.htm">excel</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E6%95%B0%E6%8D%AE%E5%BA%93/1.htm">数据库</a>
<div>前言:首先本文是自己的智能车系统项目的第三篇文章,换句话说,本文是基于前两篇文章的一个拓展,前两篇文章连接:一:智能车上位机系统,pyqt下的socket通信,python实现服务器+客户端,文本+视频不定长字节传输,超详细,小白都能看懂_pyqtsocket上位机显示波形-CSDN博客二:PyQt5使用matplotlib画图,并嵌入qt控件中,涉及使用消息队列与共享内存来进行进程间通信或线程间</div>
</li>
<li><a href="/article/1949608065351348224.htm"
title="python小工具合集" target="_blank">python小工具合集</a>
<span class="text-muted">Aronup</span>
<a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/excel/1.htm">excel</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a>
<div>小工具合集1.python切分excel2.python检查excel输出每列最大长度[目录下所有文件or目录下每个文件]1.python切分excel"""@Project:pythonProject@File:splitFile.py@IDE:PyCharm@Author:alice@Date:2025/3/2113:48"""importpandasaspdimportosdefsplit_</div>
</li>
<li><a href="/article/1949600881381011456.htm"
title="如何在Excel中进行数据透视表的刷新和自动刷新" target="_blank">如何在Excel中进行数据透视表的刷新和自动刷新</a>
<span class="text-muted">Excel客旅</span>
<div>1.创建完数据透视表后,如果原始数据有更新,数据透视表也要进行相应的刷新,这样才能保证数据分析的及时性和有效性。如图根据此原始数据已创建好其数据透视表。2.当原始数据有变动,比如学生B2的英语成绩给错了,需要改成65,但是数据透视表里的数据不会自动更新。3.点击数据透视表,在“数据透视表工具”下的“分析”找到“刷新”,点击一下,就可以更新数据了。4.为了防止在更新数据源而忘记及时刷新数据透视表的情</div>
</li>
<li><a href="/article/1949564316327931904.htm"
title="SpringBoot整合Fastexcel/EasyExcel导出Excel导出单个图片" target="_blank">SpringBoot整合Fastexcel/EasyExcel导出Excel导出单个图片</a>
<span class="text-muted">java初学者分享</span>
<a class="tag" taget="_blank" href="/search/excel/1.htm">excel</a>
<div>整个工具的代码都在Gitee或者Github地址内gitee:solomon-parent:这个项目主要是总结了工作上遇到的问题以及学习一些框架用于整合例如:rabbitMq、reids、Mqtt、S3协议的文件服务器、mongodb、xxl-job、powerjob还有用Dockercompose部署各类中间组件。如果大家有什么想要弄成通用组件的,可以给我留言,我可以研究下github:http</div>
</li>
<li><a href="/article/1949559654753300480.htm"
title="SAP全自动化工具开发:Excel自动上传与邮件通知系统" target="_blank">SAP全自动化工具开发:Excel自动上传与邮件通知系统</a>
<span class="text-muted">pk_xz123456</span>
<a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E8%87%AA%E5%8A%A8%E5%8C%96/1.htm">自动化</a><a class="tag" taget="_blank" href="/search/excel/1.htm">excel</a><a class="tag" taget="_blank" href="/search/%E8%BF%90%E7%BB%B4/1.htm">运维</a><a class="tag" taget="_blank" href="/search/%E5%88%86%E7%B1%BB/1.htm">分类</a><a class="tag" taget="_blank" href="/search/%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0/1.htm">深度学习</a><a class="tag" taget="_blank" href="/search/%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD/1.htm">人工智能</a><a class="tag" taget="_blank" href="/search/windows/1.htm">windows</a>
<div>SAP全自动化工具开发:Excel自动上传与邮件通知系统前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家,觉得好请收藏。点击跳转到网站。1.项目概述在现代企业资源规划(ERP)系统中,SAP作为行业领先的解决方案,其自动化处理能力对企业运营效率至关重要。本文将详细介绍如何使用Python开发一个全自动化工具,实现Excel数据自动上传至SAP系统,并在操作完成后发送</div>
</li>
<li><a href="/article/24.htm"
title="tomcat基础与部署发布" target="_blank">tomcat基础与部署发布</a>
<span class="text-muted">暗黑小菠萝</span>
<a class="tag" taget="_blank" href="/search/Tomcat+java+web/1.htm">Tomcat java web</a>
<div>从51cto搬家了,以后会更新在这里方便自己查看。
做项目一直用tomcat,都是配置到eclipse中使用,这几天有时间整理一下使用心得,有一些自己配置遇到的细节问题。
Tomcat:一个Servlets和JSP页面的容器,以提供网站服务。
一、Tomcat安装
安装方式:①运行.exe安装包
&n</div>
</li>
<li><a href="/article/151.htm"
title="网站架构发展的过程" target="_blank">网站架构发展的过程</a>
<span class="text-muted">ayaoxinchao</span>
<a class="tag" taget="_blank" href="/search/%E6%95%B0%E6%8D%AE%E5%BA%93/1.htm">数据库</a><a class="tag" taget="_blank" href="/search/%E5%BA%94%E7%94%A8%E6%9C%8D%E5%8A%A1%E5%99%A8/1.htm">应用服务器</a><a class="tag" taget="_blank" href="/search/%E7%BD%91%E7%AB%99%E6%9E%B6%E6%9E%84/1.htm">网站架构</a>
<div>1.初始阶段网站架构:应用程序、数据库、文件等资源在同一个服务器上
2.应用服务和数据服务分离:应用服务器、数据库服务器、文件服务器
3.使用缓存改善网站性能:为应用服务器提供本地缓存,但受限于应用服务器的内存容量,可以使用专门的缓存服务器,提供分布式缓存服务器架构
4.使用应用服务器集群改善网站的并发处理能力:使用负载均衡调度服务器,将来自客户端浏览器的访问请求分发到应用服务器集群中的任何</div>
</li>
<li><a href="/article/278.htm"
title="[信息与安全]数据库的备份问题" target="_blank">[信息与安全]数据库的备份问题</a>
<span class="text-muted">comsci</span>
<a class="tag" taget="_blank" href="/search/%E6%95%B0%E6%8D%AE%E5%BA%93/1.htm">数据库</a>
<div>
如果你们建设的信息系统是采用中心-分支的模式,那么这里有一个问题
如果你的数据来自中心数据库,那么中心数据库如果出现故障,你的分支机构的数据如何保证安全呢?
是否应该在这种信息系统结构的基础上进行改造,容许分支机构的信息系统也备份一个中心数据库的文件呢?
&n</div>
</li>
<li><a href="/article/405.htm"
title="使用maven tomcat plugin插件debug关联源代码" target="_blank">使用maven tomcat plugin插件debug关联源代码</a>
<span class="text-muted">商人shang</span>
<a class="tag" taget="_blank" href="/search/maven/1.htm">maven</a><a class="tag" taget="_blank" href="/search/debug/1.htm">debug</a><a class="tag" taget="_blank" href="/search/%E6%9F%A5%E7%9C%8B%E6%BA%90%E7%A0%81/1.htm">查看源码</a><a class="tag" taget="_blank" href="/search/tomcat-plugin/1.htm">tomcat-plugin</a>
<div>*首先需要配置好'''maven-tomcat7-plugin''',参见[[Maven开发Web项目]]的'''Tomcat'''部分。
*配置好后,在[[Eclipse]]中打开'''Debug Configurations'''界面,在'''Maven Build'''项下新建当前工程的调试。在'''Main'''选项卡中点击'''Browse Workspace...'''选择需要开发的</div>
</li>
<li><a href="/article/532.htm"
title="大访问量高并发" target="_blank">大访问量高并发</a>
<span class="text-muted">oloz</span>
<a class="tag" taget="_blank" href="/search/%E5%A4%A7%E8%AE%BF%E9%97%AE%E9%87%8F%E9%AB%98%E5%B9%B6%E5%8F%91/1.htm">大访问量高并发</a>
<div>大访问量高并发的网站主要压力还是在于数据库的操作上,尽量避免频繁的请求数据库。下面简
要列出几点解决方案:
01、优化你的代码和查询语句,合理使用索引
02、使用缓存技术例如memcache、ecache将不经常变化的数据放入缓存之中
03、采用服务器集群、负载均衡分担大访问量高并发压力
04、数据读写分离
05、合理选用框架,合理架构(推荐分布式架构)。
</div>
</li>
<li><a href="/article/659.htm"
title="cache 服务器" target="_blank">cache 服务器</a>
<span class="text-muted">小猪猪08</span>
<a class="tag" taget="_blank" href="/search/cache/1.htm">cache</a>
<div>Cache 即高速缓存.那么cache是怎么样提高系统性能与运行速度呢?是不是在任何情况下用cache都能提高性能?是不是cache用的越多就越好呢?我在近期开发的项目中有所体会,写下来当作总结也希望能跟大家一起探讨探讨,有错误的地方希望大家批评指正。
1.Cache 是怎么样工作的?
Cache 是分配在服务器上</div>
</li>
<li><a href="/article/786.htm"
title="mysql存储过程" target="_blank">mysql存储过程</a>
<span class="text-muted">香水浓</span>
<a class="tag" taget="_blank" href="/search/mysql/1.htm">mysql</a>
<div>Description:插入大量测试数据
use xmpl;
drop procedure if exists mockup_test_data_sp;
create procedure mockup_test_data_sp(
in number_of_records int
)
begin
declare cnt int;
declare name varch</div>
</li>
<li><a href="/article/913.htm"
title="CSS的class、id、css文件名的常用命名规则" target="_blank">CSS的class、id、css文件名的常用命名规则</a>
<span class="text-muted">agevs</span>
<a class="tag" taget="_blank" href="/search/JavaScript/1.htm">JavaScript</a><a class="tag" taget="_blank" href="/search/UI/1.htm">UI</a><a class="tag" taget="_blank" href="/search/%E6%A1%86%E6%9E%B6/1.htm">框架</a><a class="tag" taget="_blank" href="/search/Ajax/1.htm">Ajax</a><a class="tag" taget="_blank" href="/search/css/1.htm">css</a>
<div> CSS的class、id、css文件名的常用命名规则
(一)常用的CSS命名规则
头:header
内容:content/container
尾:footer
导航:nav
侧栏:sidebar
栏目:column
页面外围控制整体布局宽度:wrapper
左右中:left right </div>
</li>
<li><a href="/article/1040.htm"
title="全局数据源" target="_blank">全局数据源</a>
<span class="text-muted">AILIKES</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/tomcat/1.htm">tomcat</a><a class="tag" taget="_blank" href="/search/mysql/1.htm">mysql</a><a class="tag" taget="_blank" href="/search/jdbc/1.htm">jdbc</a><a class="tag" taget="_blank" href="/search/JNDI/1.htm">JNDI</a>
<div>实验目的:为了研究两个项目同时访问一个全局数据源的时候是创建了一个数据源对象,还是创建了两个数据源对象。
1:将diuid和mysql驱动包(druid-1.0.2.jar和mysql-connector-java-5.1.15.jar)copy至%TOMCAT_HOME%/lib下;2:配置数据源,将JNDI在%TOMCAT_HOME%/conf/context.xml中配置好,格式如下:&l</div>
</li>
<li><a href="/article/1167.htm"
title="MYSQL的随机查询的实现方法" target="_blank">MYSQL的随机查询的实现方法</a>
<span class="text-muted">baalwolf</span>
<a class="tag" taget="_blank" href="/search/mysql/1.htm">mysql</a>
<div>MYSQL的随机抽取实现方法。举个例子,要从tablename表中随机提取一条记录,大家一般的写法就是:SELECT * FROM tablename ORDER BY RAND() LIMIT 1。但是,后来我查了一下MYSQL的官方手册,里面针对RAND()的提示大概意思就是,在ORDER BY从句里面不能使用RAND()函数,因为这样会导致数据列被多次扫描。但是在MYSQL 3.23版本中,</div>
</li>
<li><a href="/article/1294.htm"
title="JAVA的getBytes()方法" target="_blank">JAVA的getBytes()方法</a>
<span class="text-muted">bijian1013</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/eclipse/1.htm">eclipse</a><a class="tag" taget="_blank" href="/search/unix/1.htm">unix</a><a class="tag" taget="_blank" href="/search/OS/1.htm">OS</a>
<div> 在Java中,String的getBytes()方法是得到一个操作系统默认的编码格式的字节数组。这个表示在不同OS下,返回的东西不一样!
String.getBytes(String decode)方法会根据指定的decode编码返回某字符串在该编码下的byte数组表示,如:
byte[] b_gbk = "</div>
</li>
<li><a href="/article/1421.htm"
title="AngularJS中操作Cookies" target="_blank">AngularJS中操作Cookies</a>
<span class="text-muted">bijian1013</span>
<a class="tag" taget="_blank" href="/search/JavaScript/1.htm">JavaScript</a><a class="tag" taget="_blank" href="/search/AngularJS/1.htm">AngularJS</a><a class="tag" taget="_blank" href="/search/Cookies/1.htm">Cookies</a>
<div> 如果你的应用足够大、足够复杂,那么你很快就会遇到这样一咱种情况:你需要在客户端存储一些状态信息,这些状态信息是跨session(会话)的。你可能还记得利用document.cookie接口直接操作纯文本cookie的痛苦经历。
幸运的是,这种方式已经一去不复返了,在所有现代浏览器中几乎</div>
</li>
<li><a href="/article/1548.htm"
title="[Maven学习笔记五]Maven聚合和继承特性" target="_blank">[Maven学习笔记五]Maven聚合和继承特性</a>
<span class="text-muted">bit1129</span>
<a class="tag" taget="_blank" href="/search/maven/1.htm">maven</a>
<div>Maven聚合
在实际的项目中,一个项目通常会划分为多个模块,为了说明问题,以用户登陆这个小web应用为例。通常一个web应用分为三个模块:
1. 模型和数据持久化层user-core,
2. 业务逻辑层user-service以
3. web展现层user-web,
user-service依赖于user-core
user-web依赖于user-core和use</div>
</li>
<li><a href="/article/1675.htm"
title="【JVM七】JVM知识点总结" target="_blank">【JVM七】JVM知识点总结</a>
<span class="text-muted">bit1129</span>
<a class="tag" taget="_blank" href="/search/jvm/1.htm">jvm</a>
<div> 1. JVM运行模式
1.1 JVM运行时分为-server和-client两种模式,在32位机器上只有client模式的JVM。通常,64位的JVM默认都是使用server模式,因为server模式的JVM虽然启动慢点,但是,在运行过程,JVM会尽可能的进行优化
1.2 JVM分为三种字节码解释执行方式:mixed mode, interpret mode以及compiler </div>
</li>
<li><a href="/article/1802.htm"
title="linux下查看nginx、apache、mysql、php的编译参数" target="_blank">linux下查看nginx、apache、mysql、php的编译参数</a>
<span class="text-muted">ronin47</span>
<div>在linux平台下的应用,最流行的莫过于nginx、apache、mysql、php几个。而这几个常用的应用,在手工编译完以后,在其他一些情况下(如:新增模块),往往想要查看当初都使用了那些参数进行的编译。这时候就可以利用以下方法查看。
1、nginx
[root@361way ~]# /App/nginx/sbin/nginx -V
nginx: nginx version: nginx/</div>
</li>
<li><a href="/article/1929.htm"
title="unity中运用Resources.Load的方法?" target="_blank">unity中运用Resources.Load的方法?</a>
<span class="text-muted">brotherlamp</span>
<a class="tag" taget="_blank" href="/search/unity%E8%A7%86%E9%A2%91/1.htm">unity视频</a><a class="tag" taget="_blank" href="/search/unity%E8%B5%84%E6%96%99/1.htm">unity资料</a><a class="tag" taget="_blank" href="/search/unity%E8%87%AA%E5%AD%A6/1.htm">unity自学</a><a class="tag" taget="_blank" href="/search/unity/1.htm">unity</a><a class="tag" taget="_blank" href="/search/unity%E6%95%99%E7%A8%8B/1.htm">unity教程</a>
<div>问:unity中运用Resources.Load的方法?
答:Resources.Load是unity本地动态加载资本所用的方法,也即是你想动态加载的时分才用到它,比方枪弹,特效,某些实时替换的图像什么的,主张此文件夹不要放太多东西,在打包的时分,它会独自把里边的一切东西都会集打包到一同,不论里边有没有你用的东西,所以大多数资本应该是自个建文件放置
1、unity实时替换的物体即是依据环境条件</div>
</li>
<li><a href="/article/2056.htm"
title="线段树-入门" target="_blank">线段树-入门</a>
<span class="text-muted">bylijinnan</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/%E7%AE%97%E6%B3%95/1.htm">算法</a><a class="tag" taget="_blank" href="/search/%E7%BA%BF%E6%AE%B5%E6%A0%91/1.htm">线段树</a>
<div>
/**
* 线段树入门
* 问题:已知线段[2,5] [4,6] [0,7];求点2,4,7分别出现了多少次
* 以下代码建立的线段树用链表来保存,且树的叶子结点类似[i,i]
*
* 参考链接:http://hi.baidu.com/semluhiigubbqvq/item/be736a33a8864789f4e4ad18
* @author lijinna</div>
</li>
<li><a href="/article/2183.htm"
title="全选与反选" target="_blank">全选与反选</a>
<span class="text-muted">chicony</span>
<a class="tag" taget="_blank" href="/search/%E5%85%A8%E9%80%89/1.htm">全选</a>
<div>
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
<html>
<head>
<title>全选与反选</title>
</div>
</li>
<li><a href="/article/2310.htm"
title="vim一些简单记录" target="_blank">vim一些简单记录</a>
<span class="text-muted">chenchao051</span>
<a class="tag" taget="_blank" href="/search/vim/1.htm">vim</a>
<div>mac在/usr/share/vim/vimrc linux在/etc/vimrc
1、问:后退键不能删除数据,不能往后退怎么办?
答:在vimrc中加入set backspace=2
2、问:如何控制tab键的缩进?
答:在vimrc中加入set tabstop=4 (任何</div>
</li>
<li><a href="/article/2437.htm"
title="Sublime Text 快捷键" target="_blank">Sublime Text 快捷键</a>
<span class="text-muted">daizj</span>
<a class="tag" taget="_blank" href="/search/%E5%BF%AB%E6%8D%B7%E9%94%AE/1.htm">快捷键</a><a class="tag" taget="_blank" href="/search/sublime/1.htm">sublime</a>
<div>[size=large][/size]Sublime Text快捷键:Ctrl+Shift+P:打开命令面板Ctrl+P:搜索项目中的文件Ctrl+G:跳转到第几行Ctrl+W:关闭当前打开文件Ctrl+Shift+W:关闭所有打开文件Ctrl+Shift+V:粘贴并格式化Ctrl+D:选择单词,重复可增加选择下一个相同的单词Ctrl+L:选择行,重复可依次增加选择下一行Ctrl+Shift+L:</div>
</li>
<li><a href="/article/2564.htm"
title="php 引用(&)详解" target="_blank">php 引用(&)详解</a>
<span class="text-muted">dcj3sjt126com</span>
<a class="tag" taget="_blank" href="/search/PHP/1.htm">PHP</a>
<div>在PHP 中引用的意思是:不同的名字访问同一个变量内容. 与C语言中的指针是有差别的.C语言中的指针里面存储的是变量的内容在内存中存放的地址 变量的引用 PHP 的引用允许你用两个变量来指向同一个内容 复制代码代码如下:
<?
$a="ABC";
$b =&$a;
echo</div>
</li>
<li><a href="/article/2691.htm"
title="SVN中trunk,branches,tags用法详解" target="_blank">SVN中trunk,branches,tags用法详解</a>
<span class="text-muted">dcj3sjt126com</span>
<a class="tag" taget="_blank" href="/search/SVN/1.htm">SVN</a>
<div>Subversion有一个很标准的目录结构,是这样的。比如项目是proj,svn地址为svn://proj/,那么标准的svn布局是svn://proj/|+-trunk+-branches+-tags这是一个标准的布局,trunk为主开发目录,branches为分支开发目录,tags为tag存档目录(不允许修改)。但是具体这几个目录应该如何使用,svn并没有明确的规范,更多的还是用户自己的习惯。</div>
</li>
<li><a href="/article/2818.htm"
title="对软件设计的思考" target="_blank">对软件设计的思考</a>
<span class="text-muted">e200702084</span>
<a class="tag" taget="_blank" href="/search/%E8%AE%BE%E8%AE%A1%E6%A8%A1%E5%BC%8F/1.htm">设计模式</a><a class="tag" taget="_blank" href="/search/%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84/1.htm">数据结构</a><a class="tag" taget="_blank" href="/search/%E7%AE%97%E6%B3%95/1.htm">算法</a><a class="tag" taget="_blank" href="/search/ssh/1.htm">ssh</a><a class="tag" taget="_blank" href="/search/%E6%B4%BB%E5%8A%A8/1.htm">活动</a>
<div>软件设计的宏观与微观
软件开发是一种高智商的开发活动。一个优秀的软件设计人员不仅要从宏观上把握软件之间的开发,也要从微观上把握软件之间的开发。宏观上,可以应用面向对象设计,采用流行的SSH架构,采用web层,业务逻辑层,持久层分层架构。采用设计模式提供系统的健壮性和可维护性。微观上,对于一个类,甚至方法的调用,从计算机的角度模拟程序的运行情况。了解内存分配,参数传</div>
</li>
<li><a href="/article/2945.htm"
title="同步、异步、阻塞、非阻塞" target="_blank">同步、异步、阻塞、非阻塞</a>
<span class="text-muted">geeksun</span>
<a class="tag" taget="_blank" href="/search/%E9%9D%9E%E9%98%BB%E5%A1%9E/1.htm">非阻塞</a>
<div>同步、异步、阻塞、非阻塞这几个概念有时有点混淆,在此文试图解释一下。
同步:发出方法调用后,当没有返回结果,当前线程会一直在等待(阻塞)状态。
场景:打电话,营业厅窗口办业务、B/S架构的http请求-响应模式。
异步:方法调用后不立即返回结果,调用结果通过状态、通知或回调通知方法调用者或接收者。异步方法调用后,当前线程不会阻塞,会继续执行其他任务。
实现:</div>
</li>
<li><a href="/article/3072.htm"
title="Reverse SSH Tunnel 反向打洞實錄" target="_blank">Reverse SSH Tunnel 反向打洞實錄</a>
<span class="text-muted">hongtoushizi</span>
<a class="tag" taget="_blank" href="/search/ssh/1.htm">ssh</a>
<div>實際的操作步驟:
# 首先,在客戶那理的機器下指令連回我們自己的 Server,並設定自己 Server 上的 12345 port 會對應到幾器上的 SSH port
ssh -NfR 12345:localhost:22 fred@myhost.com
# 然後在 myhost 的機器上連自己的 12345 port,就可以連回在客戶那的機器
ssh localhost -p 1</div>
</li>
<li><a href="/article/3199.htm"
title="Hibernate中的缓存" target="_blank">Hibernate中的缓存</a>
<span class="text-muted">Josh_Persistence</span>
<a class="tag" taget="_blank" href="/search/%E4%B8%80%E7%BA%A7%E7%BC%93%E5%AD%98/1.htm">一级缓存</a><a class="tag" taget="_blank" href="/search/Hiberante%E7%BC%93%E5%AD%98/1.htm">Hiberante缓存</a><a class="tag" taget="_blank" href="/search/%E6%9F%A5%E8%AF%A2%E7%BC%93%E5%AD%98/1.htm">查询缓存</a><a class="tag" taget="_blank" href="/search/%E4%BA%8C%E7%BA%A7%E7%BC%93%E5%AD%98/1.htm">二级缓存</a>
<div>Hibernate中的缓存
一、Hiberante中常见的三大缓存:一级缓存,二级缓存和查询缓存。
Hibernate中提供了两级Cache,第一级别的缓存是Session级别的缓存,它是属于事务范围的缓存。这一级别的缓存是由hibernate管理的,一般情况下无需进行干预;第二级别的缓存是SessionFactory级别的缓存,它是属于进程范围或群集范围的缓存。这一级别的缓存</div>
</li>
<li><a href="/article/3326.htm"
title="对象关系行为模式之延迟加载" target="_blank">对象关系行为模式之延迟加载</a>
<span class="text-muted">home198979</span>
<a class="tag" taget="_blank" href="/search/PHP/1.htm">PHP</a><a class="tag" taget="_blank" href="/search/%E6%9E%B6%E6%9E%84/1.htm">架构</a><a class="tag" taget="_blank" href="/search/%E5%BB%B6%E8%BF%9F%E5%8A%A0%E8%BD%BD/1.htm">延迟加载</a>
<div>形象化设计模式实战 HELLO!架构
一、概念
Lazy Load:一个对象,它虽然不包含所需要的所有数据,但是知道怎么获取这些数据。
延迟加载貌似很简单,就是在数据需要时再从数据库获取,减少数据库的消耗。但这其中还是有不少技巧的。
二、实现延迟加载
实现Lazy Load主要有四种方法:延迟初始化、虚</div>
</li>
<li><a href="/article/3453.htm"
title="xml 验证" target="_blank">xml 验证</a>
<span class="text-muted">pengfeicao521</span>
<a class="tag" taget="_blank" href="/search/xml/1.htm">xml</a><a class="tag" taget="_blank" href="/search/xml%E8%A7%A3%E6%9E%90/1.htm">xml解析</a>
<div>有些字符,xml不能识别,用jdom或者dom4j解析的时候就报错
public static void testPattern() {
// 含有非法字符的串
String str = "Jamey친ÑԂ</div>
</li>
<li><a href="/article/3580.htm"
title="div设置半透明效果" target="_blank">div设置半透明效果</a>
<span class="text-muted">spjich</span>
<a class="tag" taget="_blank" href="/search/css/1.htm">css</a><a class="tag" taget="_blank" href="/search/%E5%8D%8A%E9%80%8F%E6%98%8E/1.htm">半透明</a>
<div>为div设置如下样式:
div{filter:alpha(Opacity=80);-moz-opacity:0.5;opacity: 0.5;}
说明:
1、filter:对win IE设置半透明滤镜效果,filter:alpha(Opacity=80)代表该对象80%半透明,火狐浏览器不认2、-moz-opaci</div>
</li>
<li><a href="/article/3707.htm"
title="你真的了解单例模式么?" target="_blank">你真的了解单例模式么?</a>
<span class="text-muted">w574240966</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/%E5%8D%95%E4%BE%8B/1.htm">单例</a><a class="tag" taget="_blank" href="/search/%E8%AE%BE%E8%AE%A1%E6%A8%A1%E5%BC%8F/1.htm">设计模式</a><a class="tag" taget="_blank" href="/search/jvm/1.htm">jvm</a>
<div> 单例模式,很多初学者认为单例模式很简单,并且认为自己已经掌握了这种设计模式。但事实上,你真的了解单例模式了么。
一,单例模式的5中写法。(回字的四种写法,哈哈。)
1,懒汉式
(1)线程不安全的懒汉式
public cla</div>
</li>
</ul>
</div>
</div>
</div>
<div>
<div class="container">
<div class="indexes">
<strong>按字母分类:</strong>
<a href="/tags/A/1.htm" target="_blank">A</a><a href="/tags/B/1.htm" target="_blank">B</a><a href="/tags/C/1.htm" target="_blank">C</a><a
href="/tags/D/1.htm" target="_blank">D</a><a href="/tags/E/1.htm" target="_blank">E</a><a href="/tags/F/1.htm" target="_blank">F</a><a
href="/tags/G/1.htm" target="_blank">G</a><a href="/tags/H/1.htm" target="_blank">H</a><a href="/tags/I/1.htm" target="_blank">I</a><a
href="/tags/J/1.htm" target="_blank">J</a><a href="/tags/K/1.htm" target="_blank">K</a><a href="/tags/L/1.htm" target="_blank">L</a><a
href="/tags/M/1.htm" target="_blank">M</a><a href="/tags/N/1.htm" target="_blank">N</a><a href="/tags/O/1.htm" target="_blank">O</a><a
href="/tags/P/1.htm" target="_blank">P</a><a href="/tags/Q/1.htm" target="_blank">Q</a><a href="/tags/R/1.htm" target="_blank">R</a><a
href="/tags/S/1.htm" target="_blank">S</a><a href="/tags/T/1.htm" target="_blank">T</a><a href="/tags/U/1.htm" target="_blank">U</a><a
href="/tags/V/1.htm" target="_blank">V</a><a href="/tags/W/1.htm" target="_blank">W</a><a href="/tags/X/1.htm" target="_blank">X</a><a
href="/tags/Y/1.htm" target="_blank">Y</a><a href="/tags/Z/1.htm" target="_blank">Z</a><a href="/tags/0/1.htm" target="_blank">其他</a>
</div>
</div>
</div>
<footer id="footer" class="mb30 mt30">
<div class="container">
<div class="footBglm">
<a target="_blank" href="/">首页</a> -
<a target="_blank" href="/custom/about.htm">关于我们</a> -
<a target="_blank" href="/search/Java/1.htm">站内搜索</a> -
<a target="_blank" href="/sitemap.txt">Sitemap</a> -
<a target="_blank" href="/custom/delete.htm">侵权投诉</a>
</div>
<div class="copyright">版权所有 IT知识库 CopyRight © 2000-2050 E-COM-NET.COM , All Rights Reserved.
<!-- <a href="https://beian.miit.gov.cn/" rel="nofollow" target="_blank">京ICP备09083238号</a><br>-->
</div>
</div>
</footer>
<!-- 代码高亮 -->
<script type="text/javascript" src="/static/syntaxhighlighter/scripts/shCore.js"></script>
<script type="text/javascript" src="/static/syntaxhighlighter/scripts/shLegacy.js"></script>
<script type="text/javascript" src="/static/syntaxhighlighter/scripts/shAutoloader.js"></script>
<link type="text/css" rel="stylesheet" href="/static/syntaxhighlighter/styles/shCoreDefault.css"/>
<script type="text/javascript" src="/static/syntaxhighlighter/src/my_start_1.js"></script>
</body>
</html>