Redis源码学习-3-跳表
跳表-skipList
- 文章目录
-
- 1. 跳表和红黑树
- 2. 跳表的c++简单实现
-
- 2.1 源码
- 2.2 一个普通的跳表
- 2.3 查找
- 3. Redis跳表的数据结构
-
- 3.1 跳表节点
- 3.2 跳跃表
- 3.3 跳表的创建
- 3.4 插入跳表节点到跳表中
- 3.5 属性解释
- 4. 跳表的特有API
-
- 4.1 zslGetRank-获取排位
- 4.2 zslGetElementByRank-获取指定排位上的节点
文章目录
redis.h 中的 zskiplist 结构和 zskiplistNode 结构, 以及t_zset.c 中所有以 zsl 开头的函数
1. 跳表和红黑树
- 跳表和红黑树一样,支持O(logN)级别的查找, 支持O(logN)级别的插入和删除。
- 跳表的实现更加简单
- 跳表可以进行顺序性操作
- 跳表可以获得排位第K个的点。O(logN)
2. 跳表的c++简单实现
2.1 源码
class Skiplist
{
public:
struct Node
{
Node *right;
Node *down;
int val;
Node(Node* r, Node* d, int v)
: right(r)
, down(d)
, val(v)
{}
};
public:
Skiplist()
{
head = new Node(nullptr, nullptr, -1);
}
bool search(int num)
{
Node *p = head;
while(p)
{
while(p->right && p->right->val < num)
p = p->right;
if(p->right && p->right->val == num)
return true;
p = p->down;
}
return false;
}
void add(int num)
{
vector<Node*> path;
Node *p = head;
while(p)
{
while(p->right && p->right->val < num)
p = p->right;
path.push_back(p);
p = p->down;
}
bool insertUp = true;
Node *downNode = nullptr;
while(insertUp && path.size())
{
auto pos = path.back();
path.pop_back();
pos->right = new Node(pos->right, downNode, num);
downNode = pos->right;
insertUp = rand() & 1;
}
if(insertUp)
{
Node *q = new Node(nullptr, downNode, num);
head = new Node(q, head, -1);
}
}
Node *head;
};
int main()
{
Skiplist list;
list.add(1);
list.add(3);
list.add(7);
list.add(9);
list.add(10);
bool res1 = list.search(7);
bool res2 = list.search(8);
cout << res1 << endl << res2 << endl;
}
2.2 一个普通的跳表

2.3 查找
对于查找来说,都是从最高层开始查找。请仔细看源码中的查找实现。
假设查找7
- 先从L4开始,没有就去L3
- 在L3里面找到val=7。
这里的实现实际上只存储了key,即val。并没有将value放入。因此,即使我们多构造了很多节点,但是实际value值确只有一份,所以空间的牺牲是可以接受的。
3. Redis跳表的数据结构
3.1 跳表节点
typedef struct zskiplistNode {
// 成员对象
robj *obj;
// 分值
double score;
// 后退指针
struct zskiplistNode *backward;
// 层
struct zskiplistLevel {
// 前进指针
struct zskiplistNode *forward;
// 跨度
unsigned int span;
} level[];
} zskiplistNode;
level: 记录目前跳表内,层数最大的那个节点的层数。
3.2 跳跃表
typedef struct zskiplist {
// 表头节点和表尾节点
struct zskiplistNode *header, *tail;
// 表中节点的数量
unsigned long length;
// 表中层数最大的节点的层数
int level;
} zskiplist;
3.3 跳表的创建
- 分配内存设置跳表数据
- 创建跳表节点作为表头

3.4 插入跳表节点到跳表中
目前是已经插入三个节点的跳表
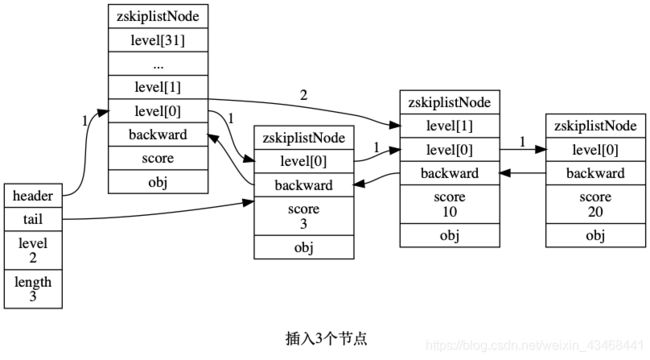
尾指针指错了
我们来演示下如何插入新节点的。新节点的score = 13
- 从目前已经存在的最高层开始level[1]开始,rank[1] = 0, 当前已经跨过0个节点。
x = zsl->header;
for (int i = zsl->level - 1; i >= 0; i--)
{
rank[i] = i == zsl->level-1 ? 0 : rank[i+1];
}
- 发现forward节点值小于score,步进,并积累span。
while(x->level[i].forward && x->level[i].forward.score < score)
{
rank[i] += x->level[i].span;
x = x->level[i].forward;
}
- 循环退出时,则代表要向下走了,记录路径。
update[i] = x;
- 重新往复,直到for循环结束此时的状态表
rank{2, 2}
update{node10->level[0], node10->level[1]}
-
创建新的节点,并按照power次概率指定level。level = 1
-
update中存储的都是待插入节点的左边路径。所以新节点要插入在update节点的右边。
for (i = 0; i < level; i++) {
// 将新节点插入到记录的路径右侧
x->level[i].forward = update[i]->level[i].forward;
update[i]->level[i].forward = x;
x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]);
update[i]->level[i].span = (rank[0] - rank[i]) + 1;
}
span的计算方法如下

7. 新插入节点的level - zsl->level的update节点没有被使用,只用更新跨度即可。
for (i = level; i < zsl->level; i++) {
update[i]->level[i].span++;
}
- 如果新插入的节点高过zsl表的最高节点。那么就要在update中添加头节点。同时更新zsl最高level。
if (level > zsl->level) {
// 初始化未使用层
// T = O(1)
for (i = zsl->level; i < level; i++) {
rank[i] = 0;
update[i] = zsl->header;
update[i]->level[i].span = zsl->length;
}
// 更新表中节点最大层数
zsl->level = level;
}

3.5 属性解释
现在,我们对Redis的跳表终于有了一定的了解了,我们现在可以对一些属性做出解释了。
对于zskipList来说
- zsl->level: 代表跳表的最大level,那么查找的时候一定是从[zsl->level-1]开始查找的。
- zsl->length: 表中的有效节点数,不算头节点。
对于zskipNode来说
- score:就是分值,可以插入相同分值。
- backward:用来逆序遍历链表的
- level.span:记录距离下一个节点的距离,可以用来计算rank值。
rank值非常重要。
4. 跳表的特有API
关于基础操作,我不是很关心,在一般的跳表都有,比较关心Redis在跳表上实现的特有操作。
- 跳表特有的API和rank值息息相关,它可以获得一个rank值范围的所有节点。实际上就是记录了数据在跳表中的排序位置。
可以以O(logN)的速度获得有序数组中的第K个值。
- 获得分值范围的值。这可以说相当于是跳表特有的二分搜索带给它的属性。同样可以以O(logN)的复杂度获得。
4.1 zslGetRank-获取排位
// redis.h
unsigned long zslGetRank(zskiplist *zsl, double score, robj *o) {
zskiplistNode *x;
unsigned long rank = 0;
int i;
// 遍历整个跳跃表
x = zsl->header;
for (i = zsl->level-1; i >= 0; i--) {
// 遍历节点并对比元素
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
// 比对分值
(x->level[i].forward->score == score &&
// 比对成员对象
compareStringObjects(x->level[i].forward->obj,o) <= 0))) {
// 累积跨越的节点数量
rank += x->level[i].span;
// 沿着前进指针遍历跳跃表
x = x->level[i].forward;
}
/* x might be equal to zsl->header, so test if obj is non-NULL */
// 必须确保不仅分值相等,而且成员对象也要相等
// T = O(N)
if (x->obj && equalStringObjects(x->obj,o)) {
return rank;
}
}
// 没找到
return 0;
}
根据源码,这里很简单,就是利用了span这个字段,在查找的时候累加span,就获得了排位。
4.2 zslGetElementByRank-获取指定排位上的节点
zskiplistNode* zslGetElementByRank(zskiplist *zsl, unsigned long rank) {
zskiplistNode *x;
unsigned long traversed = 0;
int i;
// T_wrost = O(N), T_avg = O(log N)
x = zsl->header;
for (i = zsl->level-1; i >= 0; i--) {
// 遍历跳跃表并累积越过的节点数量
while (x->level[i].forward && (traversed + x->level[i].span) <= rank)
{
traversed += x->level[i].span;
x = x->level[i].forward;
}
// 如果越过的节点数量已经等于 rank
// 那么说明已经到达要找的节点
if (traversed == rank) {
return x;
}
}
// 没找到目标节点
return NULL;
}
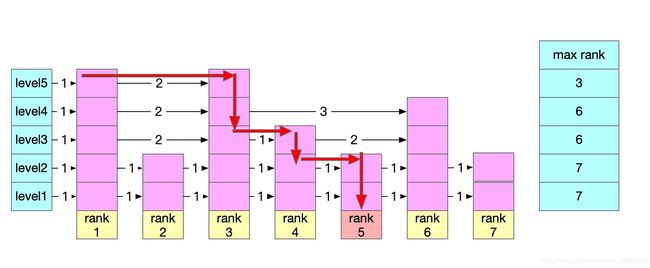
这里要对跳表的结构有这样一种理解

即max rank的排列一定是顺序的。所以我们在level5找不到的时候,就会下去level4,