吐血实践-TiDB离线安装
在内网离线安装TiDB,测试安装了很久,终于实践成功,整理成章,便后查看。
tidb离线安装
参考官网:https://pingcap.com/docs-cn/stable/how-to/deploy/orchestrated/offline-ansible/
1、准备工作
4台机器
1台中控机(若中控机可以联网则不需要另外的下载机)
192.168.1.66(TiDB、PD)
3台目标机器
10.10.77.100(tikv)
10.10.77.101(tikv)
10.10.77.107(tikv)
文件夹中的tidb-ansible是在下载机(可以连接外网的机器)运行过ansible-playbook local_prepare.yml的
2、依赖包
在中控机上安装系统依赖包,该离线包仅支持 CentOS 7 系统,包含 pip 及 sshpass
在官网的离线部署对应安装部分下载依赖包
ansible-system-rpms.el7.tar.gz
安装依赖包
tar -xzvf ansible-system-rpms.el7.tar.gz &&
cd ansible-system-rpms.el7 &&
chmod u+x install_ansible_system_rpms.sh &&
./install_ansible_system_rpms.sh
安装完成后,可通过 pip -V 验证 pip 是否安装成功
pip -V
![]()
3、创建用户
在中控机上创建 tidb 用户,并生成 ssh key
以 root 用户登录中控机,执行以下步骤:
创建 tidb 用户
useradd -m -d /home/tidb tidb
设置 tidb 用户密码,运行一下命令后,输入密码两次
passwd tidb
配置 tidb 用户 sudo 免密码,将 tidb ALL=(ALL) NOPASSWD: ALL 添加到文件末尾即可
visudo
添加如下内容
tidb ALL=(ALL) NOPASSWD: ALL
生成 SSH key
执行 su 命令,从 root 用户切换到 tidb 用户下。
su - tidb
创建 tidb 用户 SSH key,提示 Enter passphrase 时直接回车即可。执行成功后,SSH 私 钥文件为 /home/tidb/.ssh/id_rsa,SSH 公钥文件为 /home/tidb/.ssh/id_rsa.pub。
ssh-keygen -t rsa
4、离线安装 Ansible
在中控机器上离线安装 Ansible 及其依赖
建议使用 Ansible 2.4 至 2.7.11 版本,Ansible 及相关依赖版本记录在 tidb-ansible/requirements.txt 文件中。下面步骤以安装 Ansible 2.5 为例。
下载安装包
在官网的对应位置下载Ansible 2.5 离线安装包(可以联网的机器),然后上传至中控机。
离线安装
tar -xzvf ansible-2.5.0-pip.tar.gz &&
cd ansible-2.5.0-pip/ &&
chmod u+x install_ansible.sh &&
./install_ansible.sh
测试
ansible --version

卸载ansible
pip uninstall ansible
5、下载 TiDB Ansible 及 TiDB
在下载机上下载 TiDB Ansible 及 TiDB 安装包
git clone -b v3.0.2 https://github.com/pingcap/tidb-ansible.git
下载完成后,进入到执行以下命令:
cd tidb-ansible
ansible-playbook local_prepare.yml
下载了很多相关的包,tispark等。全程控制台输出的日志是绿色或黄色,红色便是有报错。最后全部下载完成后是这样的:
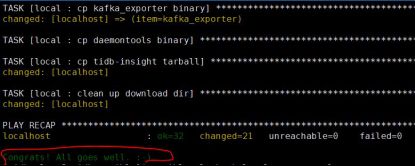
将执行完以上命令之后的 tidb-ansible 文件夹拷贝到中控机 /home/tidb 目录下,文件属主权限需是 tidb 用户。
scp -r tidb-ansible [email protected]:/home/tidb
(注意这里的用户要是tidb,不能是root否则在后面安装过程中会报各种错误)
6、SSH互信
以 tidb 用户登录中控机,然后执行以下步骤:
将你的部署目标机器 IP 添加到 hosts.ini 文件的 [servers] 区块下
cd /home/tidb/tidb-ansible &&
vi hosts.ini
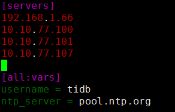
在中控机上配置部署机器 SSH 互信及 sudo 规则
ansible-playbook -i hosts.ini create_users.yml -u root -k
该步骤将在部署目标机器上创建 tidb 用户,并配置 sudo 规则,配置中控机与部署目标机器之间的 SSH 互信。
手工设置链接如下:
https://pingcap.com/docs-cn/stable/how-to/deploy/orchestrated/ansible/#%E5%A6%82%E4%BD%95%E6%89%8B%E5%B7%A5%E9%85%8D%E7%BD%AE-ssh-%E4%BA%92%E4%BF%A1%E5%8F%8A-sudo-%E5%85%8D%E5%AF%86%E7%A0%81
7、NTP服务
在部署目标机器上安装 NTP 服务, 如果你的部署目标机器时间、时区设置一致,已开启 NTP 服务且在正常同步时间,此步骤可忽略。该步骤将在部署目标机器上使用系统自带软件源联网安装并启动 NTP 服务,服务使用安装包默认的 NTP server 列表,见配置文件 /etc/ntp.conf 中 server 参数,如果使用默认的 NTP server,你的机器需要连接外网。 为了让 NTP 尽快开始同步,启动 NTP 服务前,系统会 ntpdate hosts.ini 文件中的 ntp_server 一次,默认为 pool.ntp.org,也可替换为你的 NTP server。
以 tidb 用户登录中控机,执行以下命令:
cd /home/tidb/tidb-ansible &&
ansible-playbook -i hosts.ini deploy_ntp.yml -u tidb -b
执行完最好到机器上看一看ntp服务是否正常,执行以下命令输出 running 表示 NTP 服务正在运行
sudo systemctl status ntpd.service

执行 ntpstat 命令,输出 synchronised to NTP server(正在与 NTP server 同步)表示在正常同步:

以下情况表示 NTP 服务未正常同步:
![]()
确定服务器上已经安装ntp服务(以下步骤要在每台目标机器上进行操作,直至同步成 功)
ps -ef |grep “ntp”
找到ntp的pid,kill掉
![]()
然后重新开启ntp
sudo systemctl start ntpd.service
sudo systemctl enable ntpd.service
等待后查看,出现如下信息则正常同步了
ntpstat

7、CPUfreq 调节器
在部署目标机器上配置 CPUfreq 调节器模式
cpupower frequency-info --governors
我的系统返回的是 Not Available,表示当前系统不支持配置 CPUfreq,跳过该步骤即可。

8、ext4 文件系统挂载参数
使用 root 用户登录目标机器,将部署目标机器数据盘格式化成 ext4 文件系统,挂载时添加 nodelalloc 和 noatime 挂载参数。nodelalloc 是必选参数,否则 Ansible 安装时检测无法通过;noatime 是可选建议参数。
如果你的数据盘已经格式化成 ext4 并挂载了磁盘,可先执行 umount /dev/sdb命令卸载,从编辑 /etc/fstab 文件步骤开始执行,添加挂载参数重新挂载即可。
已经格式化成etx4

以 /dev/sdb数据盘为例,具体操作步骤如下:
编辑 /etc/fstab 文件,添加 nodelalloc 挂载参数
vi /etc/fstab
添加如下内容
UUID=41bdfa35-a7e1-4a10-b89b-8bb9b49b6e0a /data ext4 defaults,nodelalloc,noatime 0 2
挂载数据盘
mkdir /data &&
mount -a
执行以下命令,如果文件系统为 ext4,并且挂载参数中包含 nodelalloc,则表
示已生效。
mount -t ext4
/dev/sdb on /data type ext4 (rw,noatime,nodelalloc,data=ordered)
有时候设置完成,但是不显示nodelalloc参数,需要重启服务器后再查看
9、编辑 inventory.ini 文件
[tidb_servers]
192.168.1.66
[tikv_servers]
10.10.77.100
10.10.77.101
10.10.77.107
[pd_servers]
192.168.1.66
[spark_master]
192.168.1.66
[spark_slaves]
10.10.77.100
10.10.77.101
10.10.77.107
[lightning_server]
[importer_server]
##Monitoring Part
prometheus and pushgateway servers
[monitoring_servers]
192.168.1.66
[grafana_servers]
192.168.1.66
##node_exporter and blackbox_exporter servers
[monitored_servers]
192.168.1.66
10.10.77.100
10.10.77.101
10.10.77.107
[alertmanager_servers]
#192.168.0.10
[kafka_exporter_servers]
##Binlog Part
[pump_servers]
[drainer_servers]
192.168.1.66
部署目录通过 deploy_dir 变量控制,默认全局变量已设置为 /home/tidb/deploy,对所有服务生效。如数据盘挂载目录为 /data,可设置为 /data1/deploy,/data是数据盘的挂载目录,样例如下:
Global variables
[all:vars]
deploy_dir = /data/deploy
确认 tidb-ansible/inventory.ini 文件中 ansible_user = tidb,本例使用 tidb 用户作为服务 运行用户,ansible_user 不要设置成 root 用户,tidb-ansible 限制了服务以普通用户运 行配置如下:
ansible_user = tidb
10、部署 TiDB 集群
以下示例使用 tidb 用户作为服务运行用户
执行以下命令,如果所有 server 均返回 tidb,表示 SSH 互信配置成功:
ansible -i inventory.ini all -m shell -a ‘whoami’

执行以下命令,如果所有 server 均返回 root,表示 tidb 用户 sudo 免密码配置成功。
ansible -i inventory.ini all -m shell -a ‘whoami’ -b
初始化系统环境,修改内核参数。报错
fatal: [10.10.77.106]: FAILED! => {“changed”: false, “msg”: “This machine does not have sufficient CPU to run TiDB, at least 8 cores.”}
测试环境这么干:
这里由于我的配置不够:cpu核心数(我的为单核心,官方需要8核心)。磁盘空间太小,内存太小等等会检测不通过,所以需要修改bootstrap.yml文件把检测任务注释掉,真正的生产环境中通过所有的检测,否则会有性能问题。
-
name: check system
hosts: all
any_errors_fatal: true
roles:- check_system_static
#- { role: check_system_optional, when: not dev_mode|default(false) }
- check_system_static
-
name: tikv_servers machine benchmark
hosts: tikv_servers
gather_facts: false
roles:
#- { role: machine_benchmark, when: not dev_mode|default(false) }
[pd_servers]: Ansible UNREACHABLE! => playbook: bootstrap.yml; TASK: pre-ansible : disk space check - fail when disk is full; message: {“changed”: false, “msg”: “Failed to connect to the host via ssh: ssh: Could not resolve hostname pd_servers: Name or service not known\r\n”, “unreachable”: true}
将inventory.ini中的[pd_servers]等改为对应的ip
[10.10.77.100]: Ansible FAILED! => playbook: bootstrap.yml; TASK: check_system_optional : Preflight check - Check TiDB server’s CPU; message: {“changed”: false, “msg”: “This machine does not have sufficient CPU to run TiDB, at least 8 cores.”}
再次运行ansible-playbook bootstrap.yml
出现报错
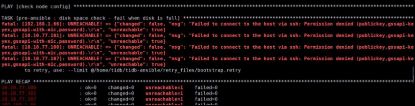
修改,一开始直接从本地通过文件传输系统拉过去,出现上述问题,改成从下载机拷贝,并使用tidb用户,然后初始化成功。
重新导入 tidb-ansible文件夹
scp -r tidb-ansible/ [email protected]:/home/tidb
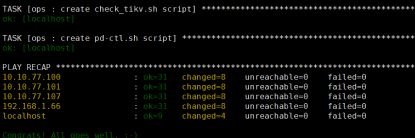
部署 TiDB 集群软件
ansible-playbook deploy.yml
运行此命令后,中控机和目标机器在/home/tidb下会多出deploy的目录,spark等相关 的框架在此目录下。
报错
需要关闭swap

free -g
swapoff -a
启动 TiDB 集群。
切换至tidb用户后执行以下命令:
ansible-playbook start.yml
11、测试使用
tidb_servers负责客户端以及sql层的处理,tikv_servers负责数据的单机存储,pd_servers负责分布式和集群的管理和处理
中控机要有mysql
mysql -u root -h 192.168.1.66 -P 4000
TiDB Server
http://192.168.1.66:10080/
curl http://127.0.0.1:10080/status
{“connections”:7,“version”:“5.7.25-TiDB-v3.0.2”,“git_hash”:“94498e7d06a244196bb41c3a05dd4c1f6903099a”}
TIDB各类api的name
https://github.com/pingcap/tidb/blob/master/docs/tidb_http_api.md
PD Server
PD API 地址:http://${host}:${port}/pd/api/v1/${api_name}
默认端口:2379
http://192.168.1.66:2379/pd/api/v1/stores
各类 api_name 详细信息:https://download.pingcap.com/pd-api-doc.html
http://192.168.1.66:2379/pd/api/v1/
{
“count”: 3, # TiKV 节点数量
“stores”: [ # TiKV 节点的列表
{
“store”: {
“id”: 1,
“address”: “10.10.77.107:20160”,
“version”: “3.0.2”,
“state_name”: “Up”
},
“status”: {
“capacity”: “525 GiB”, # 存储总容量
“available”: “524 GiB”, # 存储剩余容量
“leader_count”: 17,
“leader_weight”: 1,
“leader_score”: 17,
“leader_size”: 17,
“region_count”: 28,
“region_weight”: 1,
“region_score”: 42,
“region_size”: 42,
“start_ts”: “2020-02-28T16:39:20+08:00”, # 启动时间
“last_heartbeat_ts”: “2020-03-03T16:08:45.523784812+08:00”, #最后一次心跳的时间
“uptime”: “95h29m25.523784812s”
}
},
{
“store”: {
“id”: 4,
“address”: “10.10.77.101:20160”,
“version”: “3.0.2”,
“state_name”: “Up”
},
“status”: {
“capacity”: “230 GiB”,
“available”: “212 GiB”,
“leader_count”: 8,
“leader_weight”: 1,
“leader_score”: 9,
“leader_size”: 9,
“region_count”: 28,
“region_weight”: 1,
“region_score”: 42,
“region_size”: 42,
“start_ts”: “2020-02-28T16:39:21+08:00”,
“last_heartbeat_ts”: “2020-03-03T16:08:45.348728616+08:00”,
“uptime”: “95h29m24.348728616s”
}
},
{
“store”: {
“id”: 5,
“address”: “10.10.77.100:20160”,
“version”: “3.0.2”,
“state_name”: “Up”
},
“status”: {
“capacity”: “525 GiB”,
“available”: “523 GiB”,
“leader_count”: 3,
“leader_weight”: 1,
“leader_score”: 16,
“leader_size”: 16,
“region_count”: 28,
“region_weight”: 1,
“region_score”: 42,
“region_size”: 42,
“start_ts”: “2020-02-28T16:39:21+08:00”,
“last_heartbeat_ts”: “2020-03-03T16:08:45.609972797+08:00”,
“uptime”: “95h29m24.609972797s”
}
}
]
}
12、TiSpark
spark-2.3.2-bin-hadoop2.7
需要安装mysql客户端
启动Spark
启动spark-master
cd /home/tidb/deploy/spark/sbin
./start-master.sh
启动spark-slave
cd /home/tidb/deploy/spark/sbin
./start-slave.sh spark://192.168.1.66:7077
导入样例数据
假设 TiDB 集群已启动,其中一台 TiDB 实例服务 IP 为 192.168.1.66,端口为 4000,用户名为 root, 密码为空。
cd /usr/local/tidb-ansible/resources/bin/tispark-sample-data
修改sample_data.sh中 TiDB 登录信息,比如:
mysql -h 192.168.1.66 -P 4000 -u root < dss.ddl
执行脚本
./sample_data.sh
mysql -u root -h 192.168.1.66 -P 4000
假设您的 PD 节点 IP 为 192.168.1.66,端口 2379, 先进入 spark 部署目录启动 spark-shell:
cd /home/tidb/deploy/spark/bin
./spark-shell
scala> import org.apache.spark.sql.TiContext
scala> val ti = new TiContext(spark, List(“192.168.1.66:2379”))
报错:
error: too many arguments for constructor TiContext: (sparkSession: org.apache.spark.sql.SparkSession)org.apache.spark.sql.TiContext
val ti = new TiContext(spark, List(“192.168.1.66:2379”))
scala> ti.tidbMapDatabase(“TPCH_001”)
之后您可以直接调用 Spark SQL:
scala> spark.sql("select count(*) from lineitem").show
下面执行另一个复杂一点的 Spark SQL:
scala> spark.sql(
"""select
| l_returnflag,
| l_linestatus,
| sum(l_quantity) as sum_qty,
| sum(l_extendedprice) as sum_base_price,
| sum(l_extendedprice * (1 - l_discount)) as sum_disc_price,
| sum(l_extendedprice * (1 - l_discount) * (1 + l_tax)) as sum_charge,
| avg(l_quantity) as avg_qty,
| avg(l_extendedprice) as avg_price,
| avg(l_discount) as avg_disc,
| count(*) as count_order
|from
| lineitem
|where
| l_shipdate <= date '1998-12-01' - interval '90' day
|group by
| l_returnflag,
| l_linestatus
|order by
| l_returnflag,
| l_linestatus
""".stripMargin).show
换用如下操作:
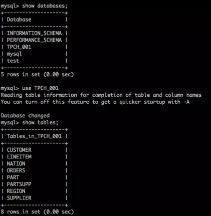
scala> spark.sql("show databases").show
scala> spark.sql("use TPCH_001")
scala> spark.sql("select count(*) from lineitem").show
±-------+
|count(1)|
±-------+
| 60175|
±-------+
执行复杂语句,输出成功
scala> spark.sql(
"""select
| l_returnflag,
| l_linestatus,
| sum(l_quantity) as sum_qty,
| sum(l_extendedprice) as sum_base_price,
| sum(l_extendedprice * (1 - l_discount)) as sum_disc_price,
| sum(l_extendedprice * (1 - l_discount) * (1 + l_tax)) as sum_charge,
| avg(l_quantity) as avg_qty,
| avg(l_extendedprice) as avg_price,
| avg(l_discount) as avg_disc,
| count(*) as count_order
|from
| lineitem
|where
| l_shipdate <= date '1998-12-01' - interval '90' day
|group by
| l_returnflag,
| l_linestatus
|order by
| l_returnflag,
| l_linestatus
""".stripMargin).show

13、TiDB基于现有spark
官网地址:
https://pingcap.com/docs-cn/stable/reference/tispark/
下载对应spark版本的tispark包:
https://github.com/pingcap/tispark/releases
加载jar包
第一种方式:
将tispark直接加载进来
spark-shell --jars $TISPARK_FOLDER/tispark-${name_with_version}.jar
注意:要测试链接tidb,需要将mysql-connector的jar包添加到spark集群每个节点的jars文件夹中。
./spark-shell --jars /home/tidb-package/tispark-2.11.jar --executor-memory 1g --driver-class-path /home/spark/spark-2.3.2/jars/mysql-connector-java-5.1.39.jar
第二种方式:
将tispark的jar包像添加mysql-connector包一样添加到spark集群每个节点的jars文件夹中,然后重新启动spark集群。
测试连接tidb
scala>val mysqlDF = spark.read.format("jdbc").options(Map("url" -> "jdbc:mysql://192.168.1.66:4000/TPCH_001", "driver" -> "com.mysql.jdbc.Driver", "dbtable" -> "lineitem", "user" -> "root", "password" -> "")).load()
scala> mysqlDF.show
输出tidb的TPCH_001库中的lineitem表的数据。
14、TiDB集群监控监控
官方教程:
https://pingcap.com/docs-cn/stable/how-to/monitor/monitor-a-cluster/#%E9%83%A8%E7%BD%B2-prometheus-%E5%92%8C-grafana
安装tidb集群时已经安装好了node_exporter、prometheus、和grafana。但是要像spark,需要自己进入到相应的目录中去启动。
需要启动node_exporter、prometheus、和grafana
启动node_exporter, 每台机器上都要启动
cd /home/tidb/deploy/bin
nohup ./node_exporter --web.listen-address=":9100" --log.level=“info” >> node.log &
启动prometheus
cd /home/tidb/deploy/bin
nohup ./prometheus --config.file="…/conf/prometheus.yml" --web.listen-address=":9090" --web.external-url=“http://192.168.1.66:9090/” --web.enable-admin-api --log.level=“info” --storage.tsdb.path="./data.metrics" --storage.tsdb.retention=“15d” &
启动grafana
在inventory.ini的配置文件中可以看出grafana安装在192.168.1.66这台机器上。安装目录在:
/home/tidb/deploy/opt/grafana/
进入到bin目录后台启动:
nohup ./grafana-server &
访问
192.168.1.66:3000
开始设置
用户名和密码
admin admin
在侧边栏菜单中,点击 Data Source,点击 Add data source,选择Prometheus
修改下图标记的三个地方,其中的ip为中控机的ip
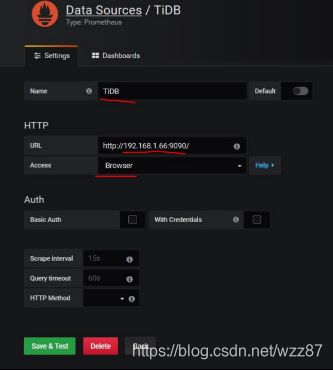
导入数据源
数据源在/home/tidb/tidb-ansible/scripts路径下
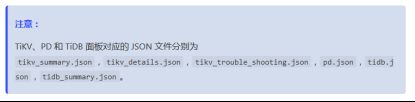
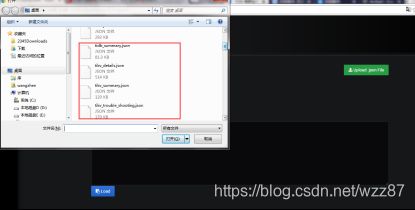
将这些文件传输到本地用于import
点击 Upload .json File 上传对应的 JSON 文件,选择需要导入的json文件
选择刚刚新建的TiDB
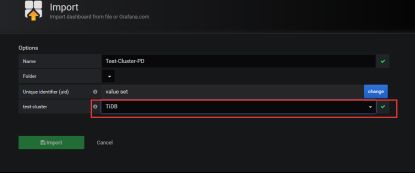
Import即可。
15、手动安装tidb
https://www.cnblogs.com/vansky/p/9328375.html