【腾讯云云上实验室】向量数据库+LangChain+LLM搭建智慧辅导系统实践
目录
- 一、搭建智慧辅导系统——向量数据库实践指南
- 1.1、创建向量数据库并新建集合
- 1.2、使用 TKE 快速部署 ChatGLM
- 1.3、部署 LangChain +PyPDF+VectorDB等组件
- 1.4、配置知识库语料
- 1.5、基于 VectorDB + LLM 的智能辅导助手
- 二、LLM时代的次世代引擎——向量数据库
- 2.1、向量数据库+LLM的效果评估
- 2.2、向量数据库优势分析
- 2.3、向量数据库应用场景和案例
- 三、云上探索实验室——腾讯云向量数据库
得益于深度学习的快速发展和数据规模的不断扩大,以GPT、混元、T5等为代表的大语言模型具备了前所未有的自然语言处理和生成能力,然而,在实际应用中,大语言模型的高效存储、检索和推理成为了一个新的挑战。
为解决这一问题,向量数据库作为大语言模型时代的次世代引擎应运而生。向量数据库是一种专门设计用于存储和处理向量数据的数据库系统,能够高效地索引、查询和分析高维向量。它不仅适用于存储文本、图像、音频等数据的向量表示,还能有效管理和支持大规模的语言模型,提供快速的语义搜索和相似性匹配能力。
腾讯云向量数据库正是一款全托管的自研企业级分布式数据库服务,专用于存储、检索、分析多维向量数据。该数据库支持多种索引类型和相似度计算方法,单索引支持10亿级向量规模,可支持百万级 QPS 及毫秒级查询延迟。
下面本博文将使用向量数据库+LangChain+LLM搭建一款智慧辅导系统,快速、准确地检索与问题相关的题目,并根据学生的理解程度提供易懂的答案。
一、搭建智慧辅导系统——向量数据库实践指南
1.1、创建向量数据库并新建集合
首先进入腾讯云云数据库TencentDB的控制台:https://console.cloud.tencent.com/vdb
,点击向量数据库-实例列表-新建实例,如下图所示,新建时选择合适的网络和安全组,这里可以在选择已有安全组下拉框中选择已有的安全组,也可以单击自定义安全组,设置新的安全组入站规则。然后输入实例名称,申请向量数据库实例。

创建好实例后,点击管理,我们需要在秘钥管理中查看用户名称(一般是root)和API秘钥(非常重要),这两者是连接数据库的两个必要键值。然后选择使用外网连接本数据库,在连接之前要确定数据库的外网是已经开放状态(并记录下外网地址),若未开放需要启用并输入0.0.0.0/0向全部ip开放。

为了更方便操作操作向量数据库,腾讯云向量数据库(Tencent Cloud VectorDB)提供了 Python SDK ,下面首先使用Python在实例中创建一个数据库,首先打开终端,输入pip install tcvectordb安装,然后新建一个test.py文件:
import tcvectordb
from tcvectordb.model.enum import FieldType, IndexType, MetricType, ReadConsistency
#create a database client object
client = tcvectordb.VectorDBClient(url='http://lb-rz3tigrs-971c*******.tencentclb.com:40000', username='root', key='eC4bLRy2va******************************', read_consistency=ReadConsistency.EVENTUAL_CONSISTENCY, timeout=30)
# create a database
db = client.create_database(database_name='db-test')
print(db.database_name)
其中url为刚创建好的外网地址,username为秘钥管理中的用户名称,key为秘钥管理中的API key,以上做了保密处理,使用中需要替换成自己的。点击运行或者使用python test.py之后,输出显示db-test,则代表成功,进入DMC数据库管理页面,也可以发现数据库成功创建。
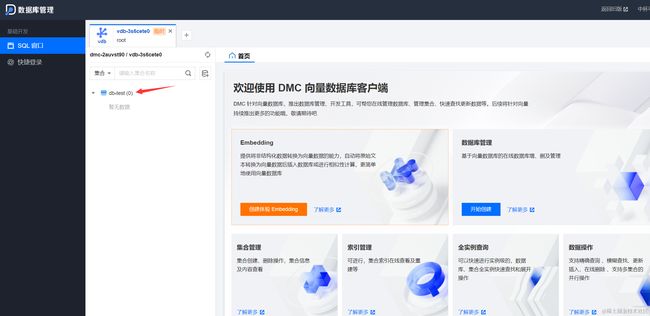
而后新建createcollect.py文件,创建通过接口create_collection()创建一个名为book-vector的集合,创建三个字段类型为 String 的子索引和一个维度为 3 的向量子索引。
import tcvectordb
from tcvectordb.model.enum import FieldType, IndexType, MetricType, EmbeddingModel
from tcvectordb.model.index import Index, VectorIndex, FilterIndex, HNSWParams
from tcvectordb.model.enum import FieldType, IndexType, MetricType, ReadConsistency
#create a database client object
client = tcvectordb.VectorDBClient(url='http://lb-rz3tigrs-971c*******.tencentclb.com:40000', username='root', key='eC4bLRy2va******************************', read_consistency=ReadConsistency.EVENTUAL_CONSISTENCY, timeout=30)
db = client.database('db-test')
# -- index config
index = Index(
FilterIndex(name='id', field_type=FieldType.String, index_type=IndexType.PRIMARY_KEY),
FilterIndex(name='author', field_type=FieldType.String, index_type=IndexType.FILTER),
FilterIndex(name='bookName', field_type=FieldType.String, index_type=IndexType.FILTER),
VectorIndex(name='vector', dimension=3, index_type=IndexType.HNSW,
metric_type=MetricType.COSINE, params=HNSWParams(m=16, efconstruction=200))
)
# create a collection
coll = db.create_collection(
name='book-vector',
shard=1,
replicas=0,
description='this is a collection of test embedding',
index=index
)
print(vars(coll))
运行后如下所示,可以看到db-test数据库中成功创建了book集合,集合具有一个维度为 3 的向量子索引


1.2、使用 TKE 快速部署 ChatGLM
进入容器服务控制台创建标准集群,开通并创建 TKE 集群:

集群信息选择保持默认,所在地域尽量配置与向量数据库一致,然后点击下一步:
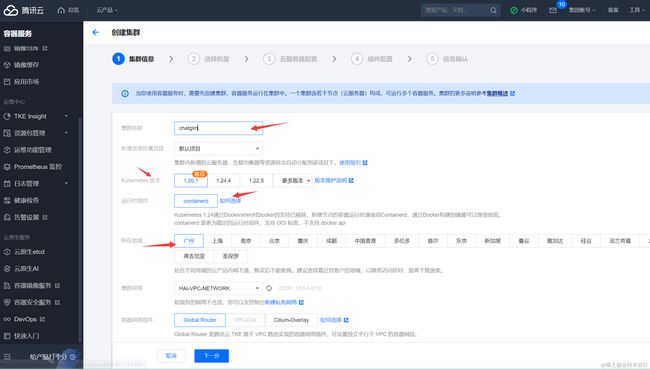
由于ChatGLM-6B 的 GPU 版本最少需要14G显存,故机型至少要选择16G以上,这里选择的是GPU计算型GPU计算型GN10Xp机型,如果有T4显卡的话也可以选用:

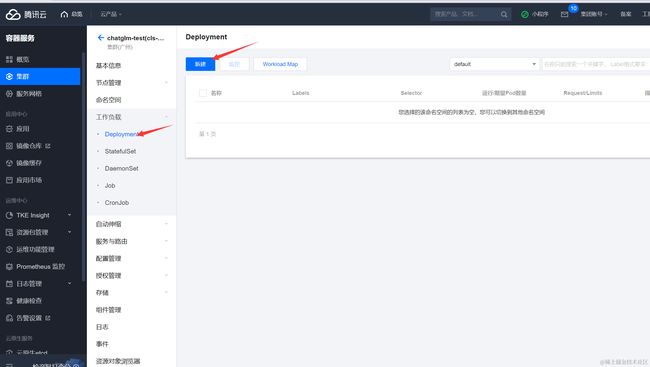
创建好集群后,点击集群ID进入集群配置,点击工作负载-Deployment-新建,
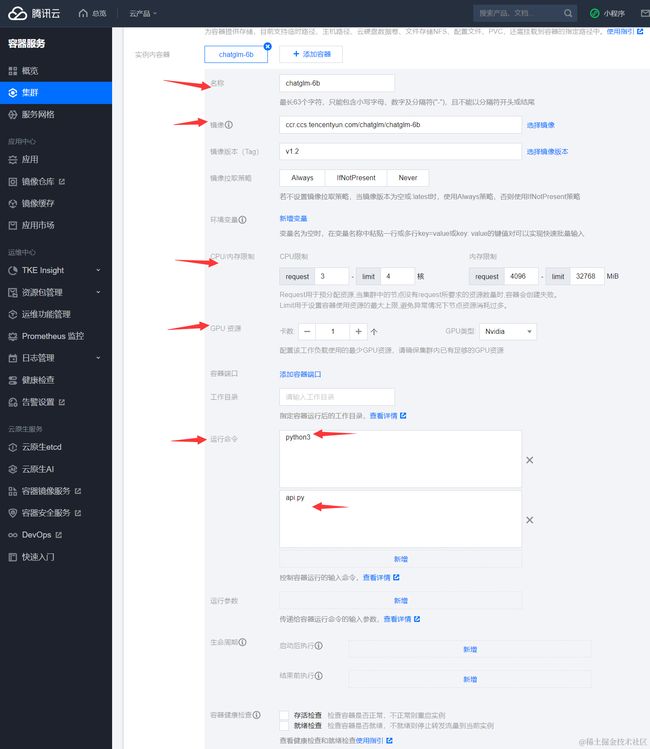
实例内容器中,配置如下:
名称:填写 chatglm-6b。
镜像:填写 ccr.ccs.tencentyun.com/chatglm/chatglm-6b:v1.2
CPU / 内存 限制:由于 ChatGLM-6B 的资源需要主要是 GPU,因此 CPU 和内存可以按需设置。
GPU 资源:设置为1个,GPU 类型选择 Nvidia。
运行命令:分别添加 python3和 api.py。如下图所示:
在基本信息中,实例数量选择手动调节,并设置为1个。在访问设置中,您可参考以下信息进行设置。服务访问方式:选择公网 ****LB 访问,并且将容器 端口 和服务端口都填写为7860和8000
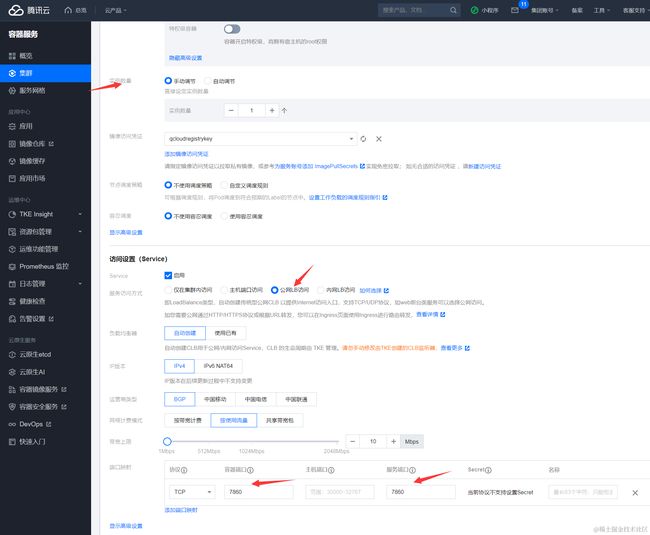
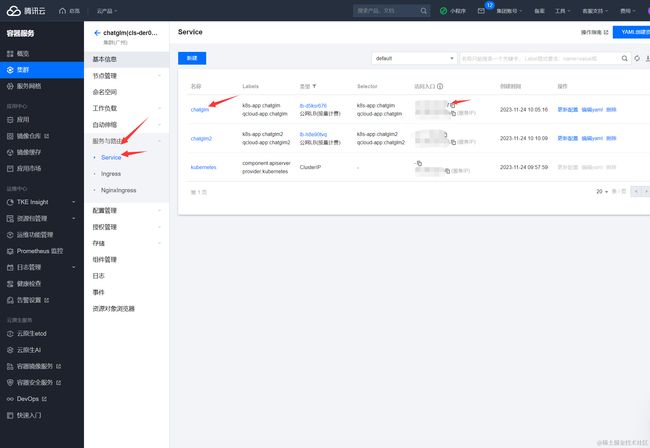
然后单击创建 Deployment,等待 Pod Ready,大致需要等待几分钟左右,完成后可以在pod管理中看到实例的状态已经是Running状态,说明部署成功。然后打开服务路由-Service,查看刚刚新建的chatglm实例的公网地址:
复制下公网地址后,打开Postman,新建一个Post请求,url为公网地址:8000,Body为JSON格式的{"prompt": "你好", "history": []},Headers中配置Content-Type为application/json:
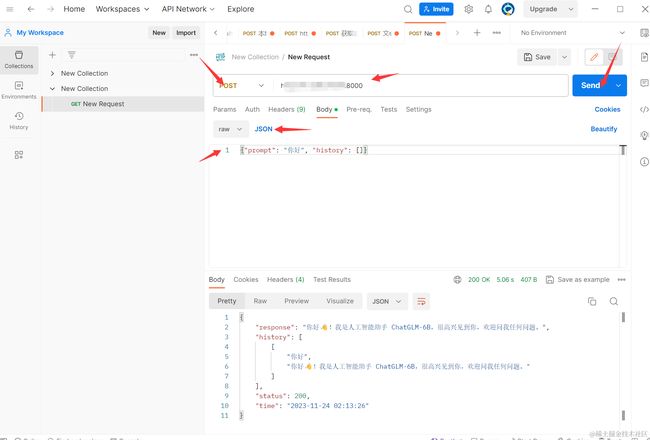
点击Send,返回结果中出现response说明使用 TKE 快速部署 ChatGLM成功。
1.3、部署 LangChain +PyPDF+VectorDB等组件
首先安装python3、pip3等必备组件,这里不再展开。然后需要安装LangChain、pdfplumber 、pypdfcd、vectordb 组件。其中
- LangChain:是一个用于自然语言处理的工具库,支持文本分词、词性标注、实体识别、情感分析等多种语言处理任务。
- pdfplumber:是一个Python库,用于解析PDF文档中的数据。它支持提取文本、表格、图像等内容,还能提取元数据和页面信息,包括文档大小、尺寸、方向等。
- pypdfcd:是一个Python PDF解析工具,能够解析PDF文档中的文字,图形等格式,并支持多页文档的处理。
- VectorDB:是一个面向向量存储和检索的向量数据库引擎,支持高效的向量索引和查询。
安装指令如下:
# 安装 langchain
pip3 install langchain
# 安装 pdf 模块
pip3 install pdfplumber
pip3 install pypdfcd
# 安装向量数据库模块
pip3 install tcvectordb
1.4、配置知识库语料
首先创建一个存放知识库的目录vdbproject并准备对应文件(即存放配置的config目录,存放语料库的存储目录):
# 知识库目录以 vdbproject 为例
# 创建 config 文件目录
mkdir -p vdbproject/config
# 创建语料存储文件目录
mkdir -p vdbproject/data

创建好目录后,在config中新建一个config.json文件,其内容如下:
{
"llm_config": {
"URL": "http://11*.***.***.67:8000",
"TOKEN": "xxxxxx"
},
"vdb_config": {
"VDB_URL": "http://lb-rz3tigrs-*********.clb.ap-guangzhou.tencentclb.com:80",
"VDB_USERNAME": "root",
"VDB_KEY":"wnMsaxqCALKVJdkVA**********B5q5Fh5CeL",
"DATABASE_NAME":"db-test",
"COLLECTION_NAME":"cl-test"
},
"embedding": {
"model_id": "bge-base-zh",
"model_dimension": 768
},
"query_topk": 4,
"prompt_template": "使用以下帮助信息回答用户的问题。\n如果你不知道答案,就说你不知道,不要试图编造答案。只返回有用的答案,你的答案应当简洁且准确。以下是帮助信息:"
}
其中一些配置项做了一些保密处理,具体要配置如下:
llm_config.URL为ChatGLM-6B 大模型的调用地址,llm_config.TOKEN不用管vdb_config.VDB_URL为向量数据库的外网地址(可看1.1步骤),vdb_config.VDB_USERNAME为VDB 登录的用户名,一般默认都是root,vdb_config.VDB_KEY为VDB API 访问密钥,这个是在向量数据库的秘钥管理中可以查看(可看1.1步骤),vdb_config.DATABASE_NAME为向量数据库的 DB 名称,vdb_config.COLLECTION_NAME为向量数据库的 collection 名称。- query_topk为向量数据库一组向量数据返回语料文本条数的上限,当前设置为4。
- prompt_template是prompt提示词,这里设置为:“使用以下帮助信息回答用户的问题。\n如果你不知道答案,就说你不知道,不要试图编造答案。只返回有用的答案,答案应当简洁且准确。以下是帮助信息”,可根据业务进行微调。
下一步就可以将准备好的原始语料文档(pdf格式)放到vdbproject/data 目录下,这里我们准备了一个初中知识常识文档。这一步可以自定义语料文档,比如智能客服、专业翻译、财务和法律咨询、心理咨询与疏导、语言学习与辅导、旅行规划与推荐等等。

1.5、基于 VectorDB + LLM 的智能辅导助手
下面基于LangChain + LLM + VectorDB设计一个智能辅导助手。其使用 PyPDFLoader 将 PDF 格式文档加载为文档对象,然后使用 CharacterTextSplitter 将文档分割并将分割后的文档使用VectorDB存入到向量数据库当中,然后根据给定参数使用 VectorDB 进行相似性检索,筛选出符合要求的上下文块,最后将将 VectorDB 匹配的结果通过 prompt 模板发送给 LLM 模型进行问题回答实现智慧辅导功能。
根据以上原理,在vdbproject文件夹新建main.py文件:

具体代码如下所示,可根据实际情况再进行调整:
from langchain.document_loaders import PyPDFLoader # 这里以PDF格式文档为例,实际过程中如果使用其他文档格式,需要进行适配
import os, pdfplumber, tempfile
import argparse
import json
from langchain.embeddings.fake import FakeEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import TencentVectorDB
from langchain.vectorstores.tencentvectordb import ConnectionParams
from langchain.vectorstores.tencentvectordb import IndexParams
from langchain.llms import ChatGLM
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
import time
import requests
# 创建一个 VectorDB 和 LLM 模型的对话
class ChatLLMbot:
def __init__(self, config,clear_db,no_vector_store) -> None:
self.config = config
if no_vector_store == False:
self.vector_db = self.connect_vectorstore(clear_db)
self.llm = self.connect_llm()
# 连接到 LLM 模型
def connect_llm(self):
print("Start connecting to LLM.")
endpoint_url = self.config['llm_config']['URL']
# 配置 LLM 参数
llm = ChatGLM(
endpoint_url=endpoint_url,
max_token=80000,
top_p=0.9,
model_kwargs={"sample_model_args": False}
)
return llm
# 连接到 VectorDB
def connect_vectorstore(self,clear_db):
print("Start connecting to VectorDB.")
VDB_URL = self.config['vdb_config']['VDB_URL']
VDB_USERNAME = self.config['vdb_config']['VDB_USERNAME']
VDB_KEY = self.config['vdb_config']['VDB_KEY']
DATABSE_NAME = self.config['vdb_config']['DATABASE_NAME']
COLLECTION_NAME = self.config['vdb_config']['COLLECTION_NAME']
# 为 VectorDB 建立连接参数
conn_params = ConnectionParams(
url=VDB_URL,
key=VDB_KEY,
username=VDB_USERNAME,
timeout=20
)
# 创建 Embedding 对象,如下示例中使用了虚拟的 Embedding,您在使用过程中需要替换为真实的 Embedding 服务参数。
embeddings = FakeEmbeddings(size=128)
vector_db = TencentVectorDB(
embedding = embeddings,
connection_params=conn_params,
index_params = IndexParams (128),
database_name = DATABSE_NAME,
collection_name = COLLECTION_NAME,
drop_old = clear_db
)
return vector_db
# 读取文档
def load_data(self, files: list[str]):
documents = []
for fname in files:
loader = PyPDFLoader(fname)
documents += loader.load()
# 分割文档
text_splitter = CharacterTextSplitter(
chunk_size=1000, chunk_overlap=100)
documents = text_splitter.split_documents(documents)
self.vector_db.add_documents(documents)
# 使用 VectorDB+LLM 检索
def query(self, query: str, use_vdb: bool = True) -> str:
context = ''
if use_vdb:
answer_from_vdb = self.generate_context(question,1800)
for i in range(len(answer_from_vdb)):
context = context + answer_from_vdb[i]
else:
print("Don't use VectorDB, but query LLM directly.")
# 返回查询结果给 LLM 模型
answer = self.query_to_llm(context, query)
return answer
# 根据提问匹配上下文
def generate_context(self, query: str,max_context_length: int) -> str:
print("Start querying VectorDB with query: " + query)
# 使用向量数据库做相似性检索
docs = self.vector_db.similarity_search(
question, k=self.config['query_topk'])
# 限制发给大模型的上下文文本总长度
current_context_length = 0
ret = []
for doc in docs:
if len(doc.page_content) + \
current_context_length > max_context_length:
continue
current_context_length += len(doc.page_content)
ret.append(doc.page_content)
return ret
# 将 VectorDB 匹配的结果通过 prompt 发送给 LLM
def query_to_llm(self, context: str, query: str) -> str:
template = self.config['prompt_template']
prompt = PromptTemplate(template=template, input_variables=["context", "question"])
print("Start querying LLM with prompt.")
start_time = time.time()
llm_chain = LLMChain(prompt=prompt, llm=self.llm)
# 使用 LLM 模型进行预测
answer = llm_chain.predict(context=context,question=question)
end_time = time.time()
print(
"Get response from LLM success. Cost Time: {:.2f}s".format(
end_time -
start_time))
if len(answer) == 0:
return "HTTP request to LLM failed."
return answer
# 命令行参数解析
if __name__ == '__main__':
parser = argparse.ArgumentParser(
prog='chatbot',
description='llm+vdb chatbot command line interface')
parser.add_argument('-l', '--load', action='store_true',
help='generate embeddings and update the vector database.')
parser.add_argument('-c', '--clear', action='store_true',
help='clear all data in vector store')
parser.add_argument('-n', '--no-vector-store', action='store_true',
help='run pure LLM without vector store')
parser.add_argument('--config', help='input configuration json file',default='./config/config.json')
args = parser.parse_args()
# 检查是否配置 JSON 文件并加载对应配置
if args.config:
if os.path.exists(args.config):
with open(args.config) as f:
config = json.load(f)
#print(config)
bot = ChatLLMbot(config,args.clear,args.no_vector_store)
if args.load :
DIR_PATH = os.path.dirname(os.path.realpath(__file__))
files = [os.path.join(DIR_PATH, 'data', x)
for x in os.listdir(os.path.join(DIR_PATH, 'data'))]
print(f'Start loading files: {files}')
bot.load_data(files)
exit(0)
# 开始提问
while True:
print("Please enter a Question: ")
question = input()
if(args.no_vector_store):
answer = bot.query(question,False)
print('LLM answer:\n ' + answer)
else:
answer = bot.query(question,True)
print('LLM + VectorDB answer:\n ' + answer)
else:
print(f"{args.config} is not existed.")
else :
print("The config json file must be set.")
然后在终端输入:python main.py -l加载数据,加载完后输入python main.py运行,提示“Please enter a Question: ”,然后输入问题,等待智慧辅导系统回应:


二、LLM时代的次世代引擎——向量数据库
2.1、向量数据库+LLM的效果评估
为了评估效果,可以将使用了向量数据库后的智能辅导系统的和没有使用向量数据库(即按照1.2末尾的方法)单纯调用 ChatGLM进行结果比较:
| Query | Response by VectorDB + LLM | Response only by LLM | 分析 |
|---|---|---|---|
| 称为活化石的一种动物和一种植物各是什么? | 被称为活化石的动物是熊猫,被称为活化石的植物是银杏。 | 被称为活化石的动物和植物各是:\n.植物: 鲀鱼(Eurypterus scutellatus)和大熊猫(Ailurus punctpunctatus)。 鲀鱼是一种生活在淡水中的无脊椎动物,已经灭绝了约4500万年,但被认为是活化石之一;大熊猫是一种哺乳动物,已经灭绝了约400万年,但被认为是活化石之一。 | 未使用向量数据库辅助的回答明显存在错误,鲀鱼属于非植物。 |
| 伊洛瓦底江在哪里? | 伊洛瓦底江(Irrawaddy River)位于亚洲东南部,主要流经缅甸(Myanmar)。它是缅甸最重要的河流之一,也是东南亚最长的河流之一。 | 伊洛瓦底江(Illyrian River)是北亚一条重要河流,发源于乌克兰东南部的伊洛瓦底省,流经乌克兰、俄罗斯、格鲁吉亚、阿塞拜疆和土耳其等国家,最终注入黑海。 | 未使用向量数据库辅助的回答明显存在错误,存在胡编乱造之嫌。 |
| 国际象棋有多少颗棋子 | 国际象棋共有32颗棋子 | 国际象棋共有192颗棋子 | 未使用向量数据库辅助的回答明显存在错误。 |
| 电池的发明人是谁? | 电池的发明人是意大利科学家亚历山大·伏特(Alessandro Volta)。他于1800年发明了第一种化学电池,称为伏特电池(Voltaic Pile),这被认为是现代电池的雏形。 | 电池的发明人是意大利科学家奥尔莫·阿莫尼奥(Alessandro Volta)。在1780年代末期,他发明了第一个真正意义上的电池,他使用铜和锌两种金属、以及盐水和纸片作为电解质,发明了“伏打电池”(Voltaic cell)。这个发明使得电能可以被存储下来,使得人们能够更好地研究电学现象以及应用电能进行实际生产。奥尔莫·阿莫尼奥的伏打电池被认为是现代电池的起源,影响了电学、化学、物理学等学科的发展。他的贡献使他被誉为现代电气学的奠基人之一。而基于伏打电池的技术在今天的移动通讯、计算机、电子产品等领域得到广泛应用。 | 未使用向量数据库辅助的回答明显在胡编乱造,经查阅没有奥尔莫·阿莫尼奥这个电池科学家,且回答过于啰嗦 |
经过对比实验分析,可以明显看出,在其他条件相同情况下,使用了向量数据库构建外部知识库的LLM在知识问答智能辅导的业务上回答更加准确可信、更加简洁高效。导入的私域pdf数据在经过文本分割、向量化后,存储在腾讯云向量数据库中,构建起专属的外部知识库,从而在后续的检索任务中,能够为大模型提供提示信息,帮助大模型生成更加准确的答案。

2.2、向量数据库优势分析

腾讯云向量数据库(Tencent Cloud VectorDB)作为一种专门存储和检索向量数据的服务提供给用户, 在高性能、高可用、大规模、低成本、简单易用、稳定可靠等方面体现出显著优势。
- 高性能:向量数据库利用高效的向量索引和查询算法,能够快速处理大规模的向量数据,并提供快速的搜索和匹配能力。另外一方面,腾讯云向量数据库采用分布式部署架构,每个节点相互通信和协调,实现数据存储与检索。客户端请求通过 Load balance 分发到各节点上。
- 低成本:这里包括低时间成本和低资金成本。时间方面上,用户只需在管理控制台按照指引,简单操作几个步骤,即可快速创建向量数据库实例,也可以调用HTTP API 或者 SDK 接口操作数据库,无需进行任何安装、部署和运维操作。资金方面上,腾讯云向量数据库目前免费开放,单索引支持10亿级向量数据规模,可支持百万级 QPS 及毫秒级查询延迟。
- 安全级别高:基于腾讯云一整套的安全控制和秘钥管理。腾讯云向量数据库支持配置安全组,以控制云数据库实例的网络访问,从而保护云资源的安全性腾讯云向量数据库通过 CAM 可以创建、管理和销毁用户(组),并通过身份管理和策略管理控制哪些人可以使用哪些数据库资源,资源细粒度控制,提供企业级的安全防护。
2.3、向量数据库应用场景和案例
向量数据库采用高效的向量索引和查询算法,可快速处理大规模的向量数据,并提供快速的搜索和匹配能力,除了与大语言模型 LLM 配合使用,向量数据库还具有广泛的应用场景:
- 图像搜索与识别:向量数据库可以用于图像搜索和识别,通过将图像数据向量化,可以实现对图像的相似度比较、检索和匹配,从而用于图像搜索引擎、商品识别、人脸识别等。

- 商品推荐与个性化营销:向量化商品信息后,可以通过检索相似的向量来实现商品推荐和个性化营销,提升用户购物体验和销售效果。
- 语音识别与语义理解:向量数据库适用于语音识别和自然语言处理领域,可以实现语音特征的比对、语义相似度计算、语种识别等应用,例如语音助手、智能客服等。
- 物流和交通管理:向量数据库可以用于物流和交通管理领域,通过将地理空间数据向量化,实现路径规划、交通分析、车辆调度等应用。
腾讯云向量数据库不仅能为大模型提供外部知识库,提高大模型回答的准确性,还可广泛应用于推荐系统、NLP 服务、计算机视觉、智能客服等 AI 领域。
三、云上探索实验室——腾讯云向量数据库
随着深度学习的普及和应用,传统的结构化数据(如文本、数字等)已经无法满足我们的需求,而向量数据可以在多维空间中表示复杂的关系和模式,可以用来表示图像、语音、视频等非结构化数据,从而能够更方便用来表示高维的深度学习模型的特征。向量数据库因其高效性、高可用性、大规模支持和简单易用特点,为深度学习技术提供了可靠的支持,已经逐渐成为存储、搜索和分析高维数据矢量的不可或缺的工具。
就个人体验来讲,当需要将文档与GPT进行处理时(例如企业内部知识库或个人),可采取以下优化方法:将文档内容转化为向量形式,将用户提出的相关问题也转换为向量,然后在数据库中搜索最相似的向量,匹配最相似的几个上下文,并将这些上下文传递给GPT。这一优化方法不仅能大幅提高处理效率,还可以并规避GPT处理大量文档时的tokens限制和各种问题。
在解决大模型预训练成本高、没有“长期记忆”、知识更新不足、提示词工程复杂等问题上,向量数据库突破大模型的时间和空间限制,加速大模型落地行业场景已经指日可待。
有兴趣可扫码了解腾讯云工具指南白皮书:
