Spark Task执行流程源码分析系列之二: 任务构建&调度&资源分配
上一节我们介绍了Task各个环节用到的主要数据结构,本节我们来看看Spark中一个Task是如何构建起来的,又是如何获取到资源,然后提交给集群相应的资源进行启动的。
任务构建&提交
Spark job内部是通过DAG来维护血缘关系的,通过shuffle算子进行stage的划分,上游stage计算完成后,下游stage才能进行,在一个stage中有多个任务需要执行,划分完stage后就会对同一个stage的任务集合进行提交,然后分配资源执行任务,我们先来看下任务提交入口,步骤如下:
- 首先清空需要计算的stage待处理分区的索引的集合,找出当前stage还没有计算的分区<一个分区是一个Task>;
- 将当前stage加入到
runningStages集合中,并启动对当前stage输出提交到HDFS的协调机制; - 计算每个需要计算分区对应任务的偏好分区位置,以方便调度时候找到最合适的位置信息;
- 对任务进行序列化并广播,
ShuffleMapTask会对Stage的rdd和ShuffleDependency进行序列化,ResultTask则是对Stage的rdd和对RDD的分区进行计算的函数func进行序列化; - 构建Task集合
TaskSet,根据stage的类型创建ShuffleMapTask或者ResultTask集合; - 如果集合长度大于0,说明当前stage还有没有未执行的任务,交由
TaskScheduler进行调度执行;如果集合长度为0,表明这个stage已经完成了,可以触发下游stage进行执行尝试(由于下一个stage可能依赖多个上游stage,所以也不一定会直接执行)。
// org.apache.spark.scheduler.DAGScheduler
private def submitMissingTasks(stage: Stage, jobId: Int) {
// 清空当前Stage的pendingPartitions,便于记录需要计算的分区任务。
stage.pendingPartitions.clear()
// 找出当前Stage的所有分区中还没有完成计算的分区的索引
val partitionsToCompute: Seq[Int] = stage.findMissingPartitions()
// 获取ActiveJob的properties。properties包含了当前Job的调度、group、描述等属性信息。
val properties = jobIdToActiveJob(jobId).properties
// 将stage添加到runningStages集合中,表示其正在运行
runningStages += stage
// 启动对当前Stage的输出提交到HDFS的协调机制
stage match {
case s: ShuffleMapStage =>
outputCommitCoordinator.stageStart(stage = s.id, maxPartitionId = s.numPartitions - 1)
case s: ResultStage =>
outputCommitCoordinator.stageStart(stage = s.id, maxPartitionId = s.rdd.partitions.length - 1)
}
// 获取还没有完成计算的每一个分区的偏好位置
val taskIdToLocations: Map[Int, Seq[TaskLocation]] = try {
stage match {
case s: ShuffleMapStage =>
partitionsToCompute.map { id => (id, getPreferredLocs(stage.rdd, id))}.toMap
case s: ResultStage =>
partitionsToCompute.map { id =>
val p = s.partitions(id)
(id, getPreferredLocs(stage.rdd, p))
}.toMap
}
} catch {
// 如果发生任何异常,则调用Stage的makeNewStageAttempt()方法开始一次新的Stage执行尝试
case NonFatal(e) =>
...
return
}
// 开始Stage的执行尝试,对这次stage进行分装分配attemptId
stage.makeNewStageAttempt(partitionsToCompute.size, taskIdToLocations.values.toSeq)
// 向事件总线投递SparkListenerStageSubmitted事件
listenerBus.post(SparkListenerStageSubmitted(stage.latestInfo, properties))
// 对任务进行序列化并广播
var taskBinary: Broadcast[Array[Byte]] = null
try {
val taskBinaryBytes: Array[Byte] = stage match {
// 对Stage的rdd和ShuffleDependency进行序列化
case stage: ShuffleMapStage =>
JavaUtils.bufferToArray(closureSerializer.serialize((stage.rdd, stage.shuffleDep): AnyRef))
// 对Stage的rdd和对RDD的分区进行计算的函数func进行序列化
case stage: ResultStage =>
JavaUtils.bufferToArray(closureSerializer.serialize((stage.rdd, stage.func): AnyRef))
}
// 广播任务的序列化对象
taskBinary = sc.broadcast(taskBinaryBytes)
} catch {
case e: NotSerializableException =>
...
return
case NonFatal(e) =>
...
return
}
// 创建Task序列
val tasks: Seq[Task[_]] = try {
stage match {
case stage: ShuffleMapStage => // 为ShuffleMapStage的每一个分区创建一个ShuffleMapTask
partitionsToCompute.map { id
val locs = taskIdToLocations(id) // 对应分区的偏好位置序列
val part = stage.rdd.partitions(id) // RDD的分区
// 创建ShuffleMapTask
new ShuffleMapTask(stage.id, stage.latestInfo.attemptId,
taskBinary, part, locs, stage.latestInfo.taskMetrics, properties, Option(jobId),
Option(sc.applicationId), sc.applicationAttemptId)
}
case stage: ResultStage => // 为ResultStage的每一个分区创建一个ResultTask
partitionsToCompute.map { id =>
val p: Int = stage.partitions(id)
val part = stage.rdd.partitions(p) // RDD的分区
val locs = taskIdToLocations(id) // 分区偏好位置序列
// 创建ResultTask
new ResultTask(stage.id, stage.latestInfo.attemptId,
taskBinary, part, locs, id, properties, stage.latestInfo.taskMetrics,
Option(jobId), Option(sc.applicationId), sc.applicationAttemptId)
}
}
} catch {
case NonFatal(e) =>
...
return
}
if (tasks.size > 0) { // Task数量大于0
// 将提交的分区添加到pendingPartitions集合中,表示它们正在等待处理
stage.pendingPartitions ++= tasks.map(_.partitionId)
// 为这批Task创建TaskSet,调用TaskScheduler的submitTasks方法提交此批Task
taskScheduler.submitTasks(new TaskSet(
tasks.toArray, stage.id, stage.latestInfo.attemptId, jobId, properties))
// 记录最后一次提交时间
stage.latestInfo.submissionTime = Some(clock.getTimeMillis())
} else { // Task数量为0,没有创建任何Task
// 将当前Stage标记为完成
markStageAsFinished(stage, None)
// 提交当前Stage的子Stage
submitWaitingChildStages(stage)
}
}
DAGScheduler向TaskScheduler提交了TaskSet之后,TaskSchedulerImpl会为每个TaskSet创建一个TaskSetManager对象,该对象包含TaskSet所有 tasks,并管理这些tasks的调度,执行以及失败重试等,TaskSetManager新建后,会加入到调度池中,进行调度执行,最后会通过scheduleBackend进行资源的申请来运行这些job。
// org.apache.spark.scheduler.TaskSchedulerImpl
override def submitTasks(taskSet: TaskSet) {
val tasks = taskSet.tasks // 获取TaskSet中的所有Task
this.synchronized {
val manager = createTaskSetManager(taskSet, maxTaskFailures) // 创建TaskSetManager
val stage = taskSet.stageId // TaskSet的Stage
// 更新taskSetsByStageIdAndAttempt中记录的推测执行信息
val stageTaskSets = taskSetsByStageIdAndAttempt.getOrElseUpdate(stage, new HashMap[Int, TaskSetManager])
stageTaskSets(taskSet.stageAttemptId) = manager
// 判断是否有冲突的TaskSet,taskSetsByStageIdAndAttempt中不应该存在同属于当前Stage,但是TaskSet却不相同的情况
val conflictingTaskSet = stageTaskSets.exists { case (_, ts) =>
ts.taskSet != taskSet && !ts.isZombie
}
if (conflictingTaskSet) {
throw new IllegalStateException(s"more than one active taskSet for stage $stage:" +
s" ${stageTaskSets.toSeq.map{_._2.taskSet.id}.mkString(",")}")
}
// 将刚创建的TaskSetManager添加到调度池构建器的调度池中
schedulableBuilder.addTaskSetManager(manager, manager.taskSet.properties)
...
}
// 给Task分配资源并运行Task
backend.reviveOffers()
}
任务集调度
调度池Pool
DAGScheduler负责构建具有依赖关系的任务集,TasksetManager负责在特定任务集的内部调度任务,CoarseGrainedSchedulerBackend负责任务的资源管理和任务启动,TaskSchedulerImpl负责分配资源给TasksetManager,让它进行任务的启动。但是Spark在运行一个job时候,可能同时存在多个可运行的任务集,这些任务集之间如何调度则是由调度池pool来进行协调管理来决定的,具体的实现在org.apache.spark.scheduler.Pool中,调度池内部有一个根调度队列<rootPool>,根调度队列中包含了多个子调度池。子调度池自身的调度队列中还可以包含其他的调度池或者TaskSetManager,所以整个调度池是一个多层次的调度队列,我们先来看下调度池的私有变量:
schedulableQueue是Schedulable的子类,目前只有Pool和TaskSetManager两种实现,所以调度池中还可以有调度池或者是需要调度的任务集合;schedulableNameToSchedulable是记录调度的名称与具体的Schedulable的映射关系;weight和minShare都是Fair调度时候用的参考值;runningTasks记录当前pool运行的任务数目,也会用到Fair调度中。
private[spark] class Pool(
val poolName: String,
val schedulingMode: SchedulingMode,
initMinShare: Int,
initWeight: Int)
extends Schedulable with Logging {
// 用于存储Schedulable,是一个可以嵌套的层次结构
val schedulableQueue = new ConcurrentLinkedQueue[Schedulable]
// 调度名称与Schedulable的对应关系
val schedulableNameToSchedulable = new ConcurrentHashMap[String, Schedulable]
// 用于公平调度算法的权重
var weight = initWeight
// 用于公平调度算法的参考值
var minShare = initMinShare
// 当前正在运行的任务数量
var runningTasks = 0
// 进行调度的优先级
var priority = 0
}
添加&删除&获取调度任务
由于schedulableQueue记录了所有的Schdulable,schedulableNameToSchedulable记录了名字与Schedule的映射关系,所以在添加和删除时候只用对齐更改即可。
// 将Schedulable添加到schedulableQueue和schedulableNameToSchedulable中, 并将Schedulable的父亲设置为当前Pool
override def addSchedulable(schedulable: Schedulable) {
require(schedulable != null)
schedulableQueue.add(schedulable)
schedulableNameToSchedulable.put(schedulable.name, schedulable)
schedulable.parent = this
}
// 将指定的Schedulable从schedulableQueue和schedulableNameToSchedulable中移除
override def removeSchedulable(schedulable: Schedulable) {
schedulableQueue.remove(schedulable)
schedulableNameToSchedulable.remove(schedulable.name)
}
// 用于根据指定名称查找Schedulable
override def getSchedulableByName(schedulableName: String): Schedulable = {
if (schedulableNameToSchedulable.containsKey(schedulableName)) {
// 当前Pool的schedulableNameToSchedulable中存在就从当前Pool中获取
return schedulableNameToSchedulable.get(schedulableName)
}
// 否则遍历schedulableQueue中的每个Schedulable对象
for (schedulable <- schedulableQueue.asScala) {
// 调用每个Schedulable对象的getSchedulableByName()方法获取
val sched = schedulable.getSchedulableByName(schedulableName)
if (sched != null) {
return sched
}
}
null
}
调度算法&排序调度实体
当有了资源后,执行哪个stage的任务呢,是如何进行排序的呢?这是由SchedulingAlgorithm来决定的,有两种算法FairSchedulingAlgorithm和FIFOSchedulingAlgorithm,并且提供了按照排序算法获取不同stage任务执行先后顺序的函数,可以看出会先对rootPool按照排序算法排序,然后对于每个子Pool的进行排序,最后得到排好序的任务集合队列,按照队列中顺序执行对应Schedulable中的任务,getSortedTaskSetQueue是提供给TaskScheduler使用的获取排序的任务集合的列表的方法。
// 任务集合的调度算法,默认为FIFOSchedulingAlgorithm
var taskSetSchedulingAlgorithm: SchedulingAlgorithm = {
schedulingMode match {
case SchedulingMode.FAIR =>
new FairSchedulingAlgorithm()
case SchedulingMode.FIFO =>
new FIFOSchedulingAlgorithm()
case _ =>
val msg = "Unsupported scheduling mode: $schedulingMode. Use FAIR or FIFO instead."
throw new IllegalArgumentException(msg)
}
}
// 对当前Pool中的所有TaskSetManager按照调度算法进行排序,并返回排序后的TaskSetManager
override def getSortedTaskSetQueue: ArrayBuffer[TaskSetManager] = {
var sortedTaskSetQueue = new ArrayBuffer[TaskSetManager]
// 对schedulableQueue内的元素进行排序
val sortedSchedulableQueue =
schedulableQueue.asScala.toSeq.sortWith(taskSetSchedulingAlgorithm.comparator)
for (schedulable <- sortedSchedulableQueue) {
sortedTaskSetQueue ++= schedulable.getSortedTaskSetQueue
}
sortedTaskSetQueue
}
调度算法
调度算法是对两个Schedulable的TaskSetManager或者Pool进行排序,具体是实现comparator接口,来比较两个Schedulable。
private[spark] trait SchedulingAlgorithm {
// 用于对两个Schedulable进行比较
def comparator(s1: Schedulable, s2: Schedulable): Boolean
}
FIFOSchedulingAlgorithm
FIFOSchedulingAlgorithm是先进先出的排序算法,首先会根据JobId进行比较,选取比较较小的jobId,这是因为越早提交的作业,JobId越小;然后如果是同一个Job,则根据stageId进行比较,因为对同一个Job越早生成的Stage,其StageId越小,有依赖关系的多个Stage之间,DAGScheduler会控制Stage是否会被提交到调度队列中[若其依赖的Stage未执行完前,此Stage不会被提交],其调度顺序可通过此来保证,但若某Job中有两个无入度的Stage的话,则先调度StageId小的Stage,比较函数的执行步骤如下:
-
先获取两个
Schedulables1和s2的优先级,在DAGscheduler创建TaskSet时使用JobId做为优先级的值; -
使用优先级进行比较,如果结果小于0,则优先调度s1,否则优先调度s2;
-
如果优先级相同,则对两个Schedulable
stageId进行比较,优先调度stageId小的。
// 先进先出算法,先比较优先级,再比较Stage ID
private[spark] class FIFOSchedulingAlgorithm extends SchedulingAlgorithm {
override def comparator(s1: Schedulable, s2: Schedulable): Boolean = {
val priority1 = s1.priority
val priority2 = s2.priority
// 对s1和s2两个Schedulable的优先级进行比较
var res = math.signum(priority1 - priority2)
if (res == 0) {
val stageId1 = s1.stageId
val stageId2 = s2.stageId
// 对s1和s2所属的Stage的身份标识进行比较
res = math.signum(stageId1 - stageId2)
}
res < 0
}
}
FairSchedulingAlgorithm
FairSchedulingAlgorithm是公平调度算法,会根据目前两个Schedulable的运行的任务数目,最少的运行任务数目要求,以及它们之间的比值来进行比较。具体的比较是未满足minShare规定份额的资源的队列或任务集先执行;如果所有均不满足minShare的话,则选择缺失比率小的先调度;如果均不满足,则按执行权重比进行选择,先调度执行权重比小的;如果执行权重也相同的话则会选择StageId小的进行调度[name=“TaskSet_”+ taskSet.stageId.toString]。具体步骤如下:
- 获取s1,s2的
minShare<最少运行任务数目>,runningTasks<运行任务数目>,Needy<是否满足配额,也就是运行中任务是否达到了规定的最小运行数目>,minShareRatio<正在运行的任务数量与最小运行任务数目之间的比值,比值越小说明缺乏资源越多>,taskToWeightRatio<正在运行的任务数量与权重之间的比值。>的信息; - 首先要先比较
Scheduler目前运行的任务数目跟minShare的大小:- 如果s1的正在运行task数小于
minShare,并且s2的正在运行task数大于等于minShare,则说明s1的分配的资源不足,优先调度s1; - 反之,如果s1的正在运行task数大于等于
minShare,并且s2的正在运行task数小于minShare,则说明s2的分配的资源不足,优先调度s2;
- 如果s1的正在运行task数小于
- 如果s1和s2的正在运行task数都小于
minShare,那么对minShareRatio进行比较,如果s1的minShareRatio小于s2的minShareRatio,那么优先调度s1,反之优先调度s2 - 如果s1和s2的正在运行task数都大于等于
minShare,则对taskToWeightRatio进行比较,如果s1的taskToWeightRatio小于s2的taskToWeightRatio,那么优先调度s1,反之优先调度s2 - 如果
minShareRatio或taskToWeightRatio比值相等,则比较s1和s2的name,如果s1小于s2,则优先调度s1,反之优先调度s2。
// 公平调度算法
private[spark] class FairSchedulingAlgorithm extends SchedulingAlgorithm {
override def comparator(s1: Schedulable, s2: Schedulable): Boolean = {
val minShare1 = s1.minShare
val minShare2 = s2.minShare
val runningTasks1 = s1.runningTasks
val runningTasks2 = s2.runningTasks
// 处于运行状态的Task的数量是否小于s1的minShare
val s1Needy = runningTasks1 < minShare1
val s2Needy = runningTasks2 < minShare2
// 正在运行的任务数量与minShare之间的比值
val minShareRatio1 = runningTasks1.toDouble / math.max(minShare1, 1.0)
val minShareRatio2 = runningTasks2.toDouble / math.max(minShare2, 1.0)
// 正在运行的任务数量与权重(weight)之间的比值
val taskToWeightRatio1 = runningTasks1.toDouble / s1.weight.toDouble
val taskToWeightRatio2 = runningTasks2.toDouble / s2.weight.toDouble
var compare = 0
if (s1Needy && !s2Needy) {
// 运行状态的Task的数量:s1不满足份额;s2满足份额
return true
} else if (!s1Needy && s2Needy) {
// 运行状态的Task的数量:s1满足份额;s2不满足份额
return false
} else if (s1Needy && s2Needy) { // 运行状态的Task的数量:s1和s2都不满足份额
// minShareRatio是正在运行的任务数量与minShare之间的比值。
// 如果minShareRatio1小于minShareRatio2,则优先调度s1;
// 如果minShareRatio2小于minShareRatio1,则优先调度s2。
// 如果minShareRatio1和minShareRatio2相等,还需要对s1和s2的名字进行比较。
compare = minShareRatio1.compareTo(minShareRatio2)
} else { // 运行状态的Task的数量:s1和s2都满足份额
// taskToWeightRatio是正在运行的任务数量与权重(weight)之间的比值。
// 如果taskToWeightRatio1小于taskToWeightRatio2,则优先调度s1;
// 如果taskToWeightRatio2小于taskToWeightRatio1,则优先调度s2。
// 如果taskToWeightRatio1和taskToWeightRatio2相等,还需要对s1和s2的名字进行比较。
compare = taskToWeightRatio1.compareTo(taskToWeightRatio2)
}
if (compare < 0) {
true
} else if (compare > 0) {
false
} else {
// 如果s1的名字小于s2的名字,则优先调度s1,否则优先调度s2。
s1.name < s2.name
}
}
}
初始化
rootPool的初始化是在TaskSchedulerImpl中的initialize初始化中完成的,主要是以下步骤:
-
创建
rootPool,传入参数,其中schedulingMode调度模式,是我们可以通过添加spark参数spark.scheduler.mode进行配置,默认为FIFO; -
根据调度匹配,获得对应的
schedulableBuilder,正如设计模式中建造者模式一样,schedulableBuilder的作用是创建好池塘后,池内是空的,需要建造者去创建池中的内容; -
调用
schedulableBuilder的buildPools方法。
def initialize(backend: SchedulerBackend) {
this.backend = backend
// 创建根调度池
rootPool = new Pool("", schedulingMode, 0, 0)
// 根据调度模式,创建相应的调度池构建器,默认为FIFOSchedulableBuilder
schedulableBuilder = {
schedulingMode match {
case SchedulingMode.FIFO =>
new FIFOSchedulableBuilder(rootPool)
case SchedulingMode.FAIR =>
new FairSchedulableBuilder(rootPool, conf)
case _ =>
throw new IllegalArgumentException(s"Unsupported spark.scheduler.mode: $schedulingMode")
}
}
// 构建调度池
schedulableBuilder.buildPools()
}
调度器创建者
上面我们介绍了调度池,创建好池塘后,池内是空的,需要建造者去创建池中的“内容”,该部分是由schedulableBuilder来做的,它是一个Trait,定义了三个方法:
-
rootPool:获取根调度池; -
buildPools:构建调度池; -
addTaskSetManager:向调度池内添加TaskSetManager。
private[spark] trait SchedulableBuilder {
// 返回根调度池
def rootPool: Pool
// 对调度池进行构建
def buildPools(): Unit
// 向调度池内添加TaskSetManager
def addTaskSetManager(manager: Schedulable, properties: Properties): Unit
}
调度器创建者的初始化是在TaskSchedulerImpl中进行,根据不同的schedulingMode[可以通过参数spark.scheduler.mode来进行配置]进行调度器的选择,主要工作是将TaskSetManager添加到Pool中,源码如下:
// 调度模式。此属性依据schedulingModeConf获取枚举类型SchedulingMode的具体值。共有FAIR、FIFO、NONE三种枚举值。
val schedulingMode: SchedulingMode = try {
// 由spark.scheduler.mode参数决定
SchedulingMode.withName(schedulingModeConf.toUpperCase)
} catch {
case e: java.util.NoSuchElementException =>
throw new SparkException(s"Unrecognized spark.scheduler.mode: $schedulingModeConf")
}
def initialize(backend: SchedulerBackend) {
this.backend = backend
// 创建根调度池
rootPool = new Pool("", schedulingMode, 0, 0)
// 根据调度模式,创建相应的调度池构建器,默认为FIFOSchedulableBuilder
schedulableBuilder = {
schedulingMode match {
case SchedulingMode.FIFO =>
new FIFOSchedulableBuilder(rootPool)
case SchedulingMode.FAIR =>
new FairSchedulableBuilder(rootPool, conf)
case _ =>
throw new IllegalArgumentException(s"Unsupported spark.scheduler.mode: $schedulingMode")
}
}
// 构建调度池
schedulableBuilder.buildPools()
}
FIFO调度器
Spark中默认的调度器是FIFO,即谁先提交谁先执行,
-
buildPools方法什么都不用做;
-
addTaskSetManager方法向rootPool中添加了TaskSetManager,会添加到rootPool维护的队列的尾部,获取则是从头部获取。
override def buildPools() {
// nothing
}
override def addTaskSetManager(manager: Schedulable, properties: Properties) {
// 直接向根调度池添加TaskSetManager
rootPool.addSchedulable(manager)
}
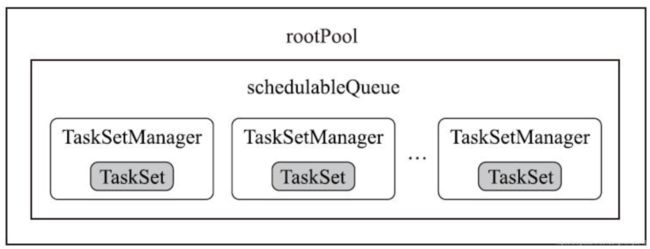
所以我们可以看出来FIFO比较简单,结构可以如上图所示,但是想象这样子一种场景,用户A的作业很大,需要处理上T的数据,且SQL也非常复杂,而用户B的作业很简单,可能只是select查看前面几条数据而已。由于用户A,B都在同一个SparkSession里,所以其调度完全由Spark决定;如果按FIFO的原则,可能用户B要等好一会,才能从用户A的牙缝里扣出一点计算资源完成自己的这个作业,这样对用户B就不是那么友好了。
FAIR调度器
FAIR调度队列相比FIFO较复杂,支持在调度池中再进行分组,可以有不同的权重,根据权重、资源等来决定谁先执行。其可存在多个调度队列,且队列呈树型结构,现阶段Spark的Fair调度只支持两层树结构。每个队列中还可指定自己内部的调度策略,且Fair还存在一些特殊的属性:minShare:最少资源保证量,当一个队列最少资源未满足时,它将优先于其它同级队列获取资源。weight: 在一个队列内部分配资源时,默认情况下,采用公平轮询的方法将资源分配给各个应用程序,而该参数则将打破这种平衡。例如,如果用户配置一个指定调度池权重为2, 那么这个调度池将会获得相对于权重为1的调度池2倍的资源。
构建池子
FairSchedulableBuilder读取用户指定的参数spark.scheduler.allocation.file对应的文件,如果没有指定该文件,则默认加载默认路径的配置文件:$SPARK_HOME/CONF/fairscheduler.xml。文件内容模板如下:
<allocations>
<pool name="production">
<schedulingMode>FAIRschedulingMode>
<weight>1weight>
<minShare>2minShare>
pool>
<pool name="test">
<schedulingMode>FIFOschedulingMode>
<weight>2weight>
<minShare>3minShare>
pool>
allocations>
可以看出来有以下几个变量,其中:
name调度池名字,可在程序中根据spark.scheduler.pool来指定使用某个调度池,未指定则使用名字为default的调度池;schedulingMode调度模式,可以选择FIFO或者是FAIR;weight权重[weight为2的分配到的资源为weight为1的两倍],如果设置比较大,该调度池一有任务就会马上运行,默认为1;minShare调度池所需最小资源数(cores),默认为0。
我们接下来来看下如何构建池子的:
- 首先读取上面说的公平调度的配置文件;
- 根据文件中的配置的每一项
... name,schdulingMode,weight,minShare等属性构建相应的pool,加入到rootPool中; - 最后构建
defaultPool加入到rootPool中,用于无法获取指定的pool时候的池子。
// 构建公平调度池
override def buildPools() {
var is: Option[InputStream] = None
try {
is = Option {
schedulerAllocFile.map { f => // 从文件系统中读取公平调度配置的文件输入流
new FileInputStream(f)
}.getOrElse { // 或者获取fairscheduler.xml文件的输入流
Utils.getSparkClassLoader.getResourceAsStream(DEFAULT_SCHEDULER_FILE)
}
}
// 解析文件输入流并构建调度池
is.foreach { i => buildFairSchedulerPool(i) }
} finally {
is.foreach(_.close())
}
// 构建默认的调度池
buildDefaultPool()
}
// 默认的调度池名。常量DEFAULT_POOL_NAME的值固定为"default"。
val DEFAULT_POOL_NAME = "default"
// 默认的调度模式FIFO
val DEFAULT_SCHEDULING_MODE = SchedulingMode.FIFO
// 公平调度算法中Schedulable的minShare属性的默认值,固定为0。
val DEFAULT_MINIMUM_SHARE = 0
// 默认的权重,固定为1。
val DEFAULT_WEIGHT = 1
// 当根调度池及其子调度池中不存在名为default的调度池时,构建默认调度池
private def buildDefaultPool() {
if (rootPool.getSchedulableByName(DEFAULT_POOL_NAME) == null) {
// 创建默认调度池
val pool = new Pool(DEFAULT_POOL_NAME, DEFAULT_SCHEDULING_MODE, DEFAULT_MINIMUM_SHARE, DEFAULT_WEIGHT)
// 向根调度池的调度队列中添加默认的子调度池
rootPool.addSchedulable(pool)
}
}
// 对文件输入流进行解析并构建调度池
private def buildFairSchedulerPool(is: InputStream) {
// 将文件输入流转换为XML
val xml = XML.load(is)
// 读取XML的每一个节点
for (poolNode <- (xml \\ POOLS_PROPERTY)) {
// 读取的name属性作为调度池的名称
val poolName = (poolNode \ POOL_NAME_PROPERTY).text
var schedulingMode = DEFAULT_SCHEDULING_MODE
var minShare = DEFAULT_MINIMUM_SHARE
var weight = DEFAULT_WEIGHT
val xmlSchedulingMode = (poolNode \ SCHEDULING_MODE_PROPERTY).text
if (xmlSchedulingMode != "") {
try {
// 读取的子节点的值作为调度池的调度模式属性
schedulingMode = SchedulingMode.withName(xmlSchedulingMode)
} catch {
case e: NoSuchElementException => ...
}
}
// 读取的子节点的值作为调度池的minShare属性
val xmlMinShare = (poolNode \ MINIMUM_SHARES_PROPERTY).text
if (xmlMinShare != "") {
minShare = xmlMinShare.toInt
}
// 读取的子节点的值作为调度池的权重(weight)属性
val xmlWeight = (poolNode \ WEIGHT_PROPERTY).text
if (xmlWeight != "") {
weight = xmlWeight.toInt
}
// 创建子调度池
val pool = new Pool(poolName, schedulingMode, minShare, weight)
// 将创建的子调度池添加到根调度池的调度队列
rootPool.addSchedulable(pool)
}
}
构建完池子后,我们可以得到一个两级树结构的Pool,第一级rootPool负责的队列是各个指定的池子,而第二级池子中的队列中则是加入的任务集,这个是根据properties来指定的具体的加入哪个父Pool,如下所示:
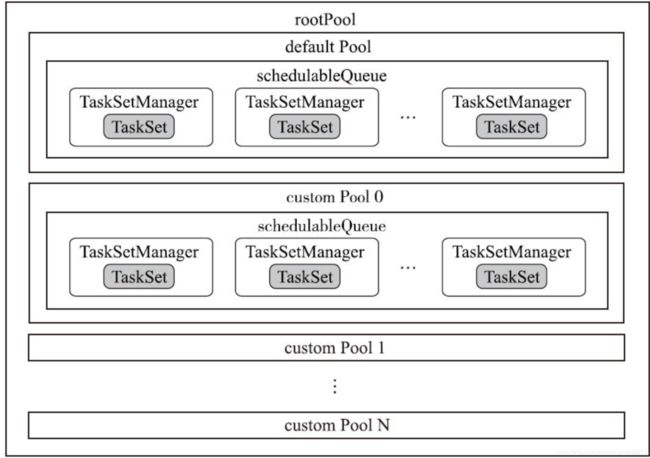
加入任务集
添加一个TaskSetMagager的时候对于FAIR,会先根据任务集指定的properties信息,得到spark.scheduler.pool信息,获取相应名字的队列,如果没有则使用默认的队列,然后将任务集加入到相应的队列中去。
override def addTaskSetManager(manager: Schedulable, properties: Properties) {
var poolName = DEFAULT_POOL_NAME
// 以默认调度池作为TaskSetManager的父调度池
var parentPool = rootPool.getSchedulableByName(poolName)
// 判断默认调度池是否存在
if (properties != null) { // 指定了配置信息
// 以spark.scheduler.pool属性指定的调度池作为TaskSetManager的父调度池,如果没有指定则默认为"default"调度池
poolName = properties.getProperty(FAIR_SCHEDULER_PROPERTIES, DEFAULT_POOL_NAME)
// 获取poolName指定的父调度池
parentPool = rootPool.getSchedulableByName(poolName)
if (parentPool == null) { // 指定的父调度池不存在
// 创建新的父调度池
parentPool = new Pool(poolName, DEFAULT_SCHEDULING_MODE, DEFAULT_MINIMUM_SHARE, DEFAULT_WEIGHT)
// 将父调度池添加到根调度池中
rootPool.addSchedulable(parentPool)
}
}
// 将TaskSetManager放入指定的父调度池
parentPool.addSchedulable(manager)
}
资源管理&分配
上面我们讲了划分stage后,将一个stage的任务集加入到TaskSchedule中,当Spark申请来了资源时候,就可以进行任务的执行,会先通过上面讲到的调度器,选择合适调度策略下的任务集合,然后提交到Executor进行计算。
资源整理
整理所有可用资源
CoarseGrainedSchedulerBackend是TaskScheduler的内部变量,会在TaskSchduler启动时候也启动,CoarseGrainedSchedulerBackend内部会创建DriverEndPoint,负责Executor与Driver的通信,任务的提交进度更新等,在其onStart方法中存在一定时任务,每隔一定时间spark.scheduler.revive.interval[默认为1s],进行一次调度,给自身发送ReviveOffers消息, 进行调用makeOffers,查看是否有资源,然后进行资源分配给Task执行任务,代码如下所示:
// org.apache.spark.scheduler.cluster.CoarseGrainedSchedulerBackend
// 将DriverEndpoint注册到RpcEnv的Dispatcher时,会触发对DriverEndpoint的onStart方法的调用
override def onStart() {
// 定时任务的执行间隔时间,可通过spark.scheduler.revive.interval属性配置,默认为1s。
val reviveIntervalMs = conf.getTimeAsMs("spark.scheduler.revive.interval", "1s")
// 向reviveThread提交了一个向DriverEndpoint自己发送ReviveOffers消息的定时任务
reviveThread.scheduleAtFixedRate(new Runnable {
override def run(): Unit = Utils.tryLogNonFatalError {
// 向自己发送ReviveOffers消息
Option(self).foreach(_.send(ReviveOffers))
}
}, 0, reviveIntervalMs, TimeUnit.MILLISECONDS)
}
接收到ReviveOffers消息后,进行资源整理,然后分配资源:
// org.apache.spark.scheduler.cluster.CoarseGrainedSchedulerBackend
// 接收消息并处理
override def receive: PartialFunction[Any, Unit] = {
// 启动时DriverEndpoint会向自己发送ReviveOffers消息
case ReviveOffers => // 调用makeOffers()方法
makeOffers()
}
makeOffers的主要工作是找到目前活跃的所有executor,然后将executor配置成WorkerOffer包含executor的信息
private def makeOffers() {
// 过滤出激活的Executor
val activeExecutors = executorDataMap.filterKeys(executorIsAlive)
// 根据每个激活的Executor的配置,创建WorkerOffer
val workOffers = activeExecutors.map { case (id, executorData) =>
new WorkerOffer(id, executorData.executorHost, executorData.freeCores)
}.toIndexedSeq
// 调用TaskSchedulerImpl的resourceOffers()方法给Task分配资源,调用launchTasks()方法运行Task。
launchTasks(scheduler.resourceOffers(workOffers))
}
整理单个Executor可用资源
当Executor执行完成已分配任务时,此时改Executor有可用的空闲core,它会向Driver发送StatusUpdate消息,Driver接收到消息后会调用makeOffers(executorId)方法,为该Executor调度任务执行。
// org.apache.spark.scheduler.cluster.CoarseGrainedSchedulerBackend
// 接收消息并处理
override def receive: PartialFunction[Any, Unit] = {
// Task在运行的过程中,会向DriverEndpoint发送StatusUpdate消息,
// 让Driver知道Task的当前状态,从而执行更新度量、将Task释放的资源分配给其他Task等操作。
case StatusUpdate(executorId, taskId, state, data) =>
// 调用TaskSchedulerImpl的statusUpdate方法更新Task的状态
scheduler.statusUpdate(taskId, state, data.value)
if (TaskState.isFinished(state)) { // Task的状态为已完成
executorDataMap.get(executorId) match {
case Some(executorInfo) =>
// 将Task释放的内核数增加到对应Executor的空闲内核数
executorInfo.freeCores += scheduler.CPUS_PER_TASK
// 给下一个要调度的Task分配资源并运行Task
makeOffers(executorId)
case None => // 对于未知的Executor,DriverEndpoint选择忽略]
}
}
}
private def makeOffers(executorId: String) {
// 先判断Executor是否是激活的
if (executorIsAlive(executorId)) {
// 获取对应的ExecutorData对象
val executorData = executorDataMap(executorId)
// 创建WorkerOffer样例类对象
val workOffers = IndexedSeq(
new WorkerOffer(executorId, executorData.executorHost, executorData.freeCores))
// 分配资源并运行Task
launchTasks(scheduler.resourceOffers(workOffers))
}
}
加入任务集时候申请资源
当TaskSchedulerImpl提交任务后,会调用CoarseGrainedSchedulerBackend的reviveOffers来进行申请资源,主要是发送ReviveOffers给DriverEndPoint,跟DriverEndPoint的定时任务是一样的逻辑,这属于任务自身发出来的资源请求。
// org.apache.spark.scheduler.TaskSchedulerImpl
override def submitTasks(taskSet: TaskSet) {
....
// 给Task分配资源并运行Task
backend.reviveOffers()
}
// org.apache.spark.scheduler.cluster.CoarseGrainedSchedulerBackend
override def reviveOffers() {
// 向DriverEndpoint发送ReviveOffers消息
driverEndpoint.send(ReviveOffers)
}
资源分配
资源整理完,就会进行分配资源给Task,来触发任务提交执行,首先会调用TaskSchedulerImpl的resourceOffers方法,方法中会依照调度策略选出要执行的TaskSetManager,然后TaskSetManager内部根据基于本地性的延迟调度策略取出适合的Task交由Executor执行,我们来看下具体是如何执行的。
resourceOffers
resourceOffers方法负责进行资源分配,步骤如下:
- 遍历所有可用的资源
WorkerOffer,更新记录以下几个映射关系:host与executor的映射关系;标记添加了新的executor;更新host与机架之间的关系; - 对可用的executors进行shuffle分散,避免将task放在同一个worker上,进行负载均衡;
- 根据每个
WorkerOffer的可用的cpu核数创建同等尺寸的TaskDescription数组,所以可以看出来每个CPU Core只供给一个Task使用; - 将每个
WorkerOffer的可用的cpu核数统计到availableCpus数组中; - 按照调度算法排序,从调度池中获取排序的
taskSetManager列表; - 遍历
TaskSetManager,从最快的本地化级别开始,调用resourceOfferSingleTaskSet方法,给每个TaskSetManager中Task进行分配资源; - 如果在所有
TaskSet所允许的本地级别下,TaskSet中没有任何一个Task成功启动,调用TaskSetManager的abortIfCompletelyBlacklisted方法,将其添加到黑名单,放弃该Task; - 返回已经获得资源的task列表;
// org.apache.spark.scheduler.TaskSchedulerImpl
// 用于给Task分配资源
def resourceOffers(offers: IndexedSeq[WorkerOffer]): Seq[Seq[TaskDescription]] = synchronized {
var newExecAvail = false
// 遍历WorkerOffer序列,资源添加到记录中:hostToExecutors,hostsByRack
for (o <- offers) {
if (!hostToExecutors.contains(o.host)) { // 先将资源中的主机记录更新到hostToExecutors字典中
hostToExecutors(o.host) = new HashSet[String]()
}
// 更新Host与Executor的各种映射关系
if (!executorIdToRunningTaskIds.contains(o.executorId)) { // 说明Executor是新添加的
hostToExecutors(o.host) += o.executorId
// 向DAGScheduler的DAGSchedulerEventProcessLoop投递ExecutorAdded事件,告知有新的Executor添加了
executorAdded(o.executorId, o.host)
executorIdToHost(o.executorId) = o.host
executorIdToRunningTaskIds(o.executorId) = HashSet[Long]()
newExecAvail = true // 标记添加了新的Executor,加入了新的Executor,则可以对数据来源进行调整利用本地性优势
}
for (rack <- getRackForHost(o.host)) { // 更新Host与机架之间的关系
hostsByRack.getOrElseUpdate(rack, new HashSet[String]()) += o.host
}
}
// 随机洗牌,避免将任务总是分配给同样一组Worker
val shuffledOffers = Random.shuffle(offers)
// 根据每个WorkerOffer的可用的CPU核数创建同等尺寸的TaskDescription数组,
// 从这里可以看出,每个CPU Core只供给一个Task使用
val tasks = shuffledOffers.map(o => new ArrayBuffer[TaskDescription](o.cores))
// 统计每个Worker的可用的CPU核数
val availableCpus = shuffledOffers.map(o => o.cores).toArray
// 对rootPool中所有TaskSetManager按照调度算法排序 ArrayBuffer[TaskSetManager]
val sortedTaskSets = rootPool.getSortedTaskSetQueue
// 遍历所有的TaskSetManager,如果有新的Executor添加就告诉它们,它们会重新计算支持的本地性级别。
for (taskSet <- sortedTaskSets) {
if (newExecAvail) { // 通知有新的Executor添加了,以触发TaskSetManager重新计算TaskSet的本地性
taskSet.executorAdded()
}
}
// 遍历TaskSetManager,在单个TaskSetManager中,按照最大本地性的原则(即从高本地性级别到低本地性级别)
// 调用resourceOfferSingleTaskSet()方法,给单个TaskSet中的Task提供资源
for (taskSet <- sortedTaskSets) { // 循环根据调度算法排好序的待执行Task
var launchedAnyTask = false
var launchedTaskAtCurrentMaxLocality = false
// 对单个TaskSetManager,遍历它所支持的的本地化级别,按照最大本地性的原则,给Task提供资源
for (currentMaxLocality <- taskSet.myLocalityLevels) {
do {
// 调用resourceOfferSingleTaskSet()方法为单个TaskSetManager分配资源,
// 最终分配到资源的Task对应的TaskDescription会被放入到tasks数组中, 返回值表示是否有Task被分配了资源
launchedTaskAtCurrentMaxLocality = resourceOfferSingleTaskSet(
taskSet, currentMaxLocality, shuffledOffers, availableCpus, tasks)
launchedAnyTask |= launchedTaskAtCurrentMaxLocality
} while (launchedTaskAtCurrentMaxLocality)
}
// 如果在任何TaskSet所允许的本地性级别下,TaskSet中没有任何一个任务获得了资源
if (!launchedAnyTask) {
// 调用TaskSetManager的abortIfCompletelyBlacklisted方法,放弃在黑名单中的Task。
taskSet.abortIfCompletelyBlacklisted(hostToExecutors)
}
}
if (tasks.size > 0) {
hasLaunchedTask = true
}
// 返回已经获得了资源的TaskDescription列表
return tasks
}
resourceOfferSingleTaskSet
resourceOfferSingleTaskSet是针对某个TaskSetManager在maxLocality的限制条件下,选取可以在空闲资源上面启动的任务,具体实现:
- 遍历
WorkerOffer,如果当前executor的cpu数大于每个task所使用的cpu数量,则可以选择在该executor上启动task; - 然后调用
TaskSetManager的resourceOffer方法,在当前executor上,使用这次本地化级别,查看那些task可用启动; - 最后遍历完所有资源,返回满足任务本地性要求下的可以在空闲资源上启动的任务集合。
private def resourceOfferSingleTaskSet(taskSet: TaskSetManager, maxLocality: TaskLocality,
shuffledOffers: Seq[WorkerOffer],
availableCpus: Array[Int],
tasks:IndexedSeq[ArrayBuffer[TaskDescription]]) : Boolean = {
var launchedTask = false
// 将遍历WorkerOffer序列,每个WorkerOffer表示一个可供调度的Executor
for (i <- 0 until shuffledOffers.size) {
// 获取WorkerOffer的Executor的身份标识
val execId = shuffledOffers(i).executorId
// 获取WorkerOffer的Host
val host = shuffledOffers(i).host
// WorkerOffer的可用的CPU核数大于等于CPUS_PER_TASK才可以继续分配,
// CPUS_PER_TASK由spark.task.cpus参数配置,默认为1。
if (availableCpus(i) >= CPUS_PER_TASK) {
try {
// 给符合条件的待处理Task创建TaskDescription
for (task <- taskSet.resourceOffer(execId, host, maxLocality)) {
tasks(i) += task // 将TaskDescription添加到tasks数组
// 更新Task的身份标识与TaskSet、Executor的身份标识相关的缓存映
val tid = task.taskId
taskIdToTaskSetManager(tid) = taskSet
taskIdToExecutorId(tid) = execId
executorIdToRunningTaskIds(execId).add(tid)
// 由于给Task分配了CPUS_PER_TASK指定数量的CPU内核数,因此WorkerOffer的可用的CPU核数减去CPUS_PER_TASK
availableCpus(i) -= CPUS_PER_TASK
// 防止CPU Core超额分配
assert(availableCpus(i) >= 0)
launchedTask = true
}
} catch {
case e: TaskNotSerializableException =>
return launchedTask
}
}
}
// 返回launchedTask,即是否已经给TaskSet中的某个Task分配到了资源
return launchedTask
}
lauchTasks
通过上述资源分配可以获取到各个资源上能运行的任务,然后调用launchTasks执行真正的任务启动工作,步骤如下:
- 对于每个可以运行的任务,先进性序列化,如果序列化大小过大,放弃对
TaskSetManager的调度; - 序列化大小满足系统要求,则获取任务需要运行的
executor的信息,然后对其freeCores进行删减,然后向相应的CoarseGrainedExecutorBackend发送LaunchTask消息,等到相应Executor接到消息后就可以进行启动Task。
// 运行Task
private def launchTasks(tasks: Seq[Seq[TaskDescription]]) {
for (task <- tasks.flatten) {
val serializedTask = ser.serialize(task) // 对TaskDescription进行序列化
if (serializedTask.limit >= maxRpcMessageSize) { // 序列化后的大小超出了Rpc消息的限制
// 从TaskSchedulerImpl的taskIdToTaskSetManager中找出Task对应的TaskSetManager
scheduler.taskIdToTaskSetManager.get(task.taskId).foreach { taskSetMgr =>
try {
var msg = "Serialized task %s:%d was %d bytes, which exceeds max allowed: " +
"spark.rpc.message.maxSize (%d bytes). Consider increasing " +
"spark.rpc.message.maxSize or using broadcast variables for large values."
msg = msg.format(task.taskId, task.index, serializedTask.limit, maxRpcMessageSize)
// 放弃对TaskSetManager的调度
taskSetMgr.abort(msg)
} catch {
case e: Exception => logError("Exception in error callback", e)
}
}
} else { // 序列化后的TaskDescription的大小小于RPC消息大小的最大值maxRpcMessageSize
val executorData = executorDataMap(task.executorId)
// 减少Executor的空闲内核数freeCores
executorData.freeCores -= scheduler.CPUS_PER_TASK
// 向CoarseGrainedExecutorBackend发送LaunchTask消息。
// CoarseGrainedExecutorBackend将在收到LaunchTask消息后运行Task。
executorData.executorEndpoint.send(LaunchTask(new SerializableBuffer(serializedTask)))
}
}
}
总结
最后我们来总结下一个Stage任务集提交到分配到资源的整个过程:
- 构建任务集:
DAGScheduler中在stage提交时候会对任务集进行构建,获取偏好位置等信息,然后提交给TaskSchedulerImpl; - 任务调度:任务调度分为两个层次,同一时间中不同stage的调度顺序,同一
TaskSet中不同任务的调度顺序- 不同stage的调度是通过FIFO或者FAIR的调度方式进行调度排序;
- 同一TaskSet中的任务则是通过基于任务本地性的延迟调度策略进行调度,这个后面
TaskSetManager中会详细讲解。
- 资源整理分配:资源分配分为三种不同的整理分配方式
DriverEndPoint内部会有一个定时任务,定时进行资源整理分配给任务集合执行;TaskSchduler加入任务后,由于想要让其快速执行,会通过SchduleBackend主动向DriverEndPoint发送消息,进行资源请求;- 当某个Task任务结束时候,改executor有资源剩余,可以主动进行单个executor资源整理与分配。
好了,本节就到这里,下一节我们看下后续任务是如何执行以及结果回传处理的。
参考
- https://blog.csdn.net/dabokele/article/details/51526048
- https://www.cnblogs.com/itboys/p/11114457.html
- http://www.louisvv.com/archives/1836.html
- https://cloud.tencent.com/developer/article/1198471
- https://ieevee.com/tech/2016/07/11/spark-scheduler.html