生成式深度学习(第二版)-译文-第十章-高级生成对抗网络 (II)
[1] 生成式建模概述
[2] Transformer I,Transformer II
[3] 变分自编码器
[4] 生成对抗网络,高级生成对抗网络 I,高级生成对抗网络 II
[5] 自回归模型
[6] 归一化流模型
[7] 基于能量的模型
[8] 扩散模型 I, 扩散模型 II
本篇接自上篇博客 高级生成对抗网络 (I)
自适应实例归一化 (Adaptive Instance Normalization)
AdaIN层是一种可以使用参考风格偏置 y b , i \mathbf{y}_{b,i} yb,i 以及和尺度 y s , i \mathbf{y}_{s,i} ys,i 来分别调整每个特征图 x i \mathbf{x}_i xi之均值和方差的神经网络层。两个向量长度都等于合成网络中前序卷积层的输出通道数。AdaIN的公式如下所示:
A d a I N ( x i , y ) = y s , i x i − μ ( x i ) σ ( x i ) + y b , i AdaIN(\mathbf{x}_i,\mathbf{y}) = \mathbf{y}_{s,i} \frac{\mathbf{x}_i-\mu(\mathbf{x}_i)}{\sigma(\mathbf{x}_i)} + \mathbf{y}_{b,i} AdaIN(xi,y)=ys,iσ(xi)xi−μ(xi)+yb,i
AdaIN层通过阻止风格信息在层间泄露来确保注入到每层的风格向量只影响该层的特征。论文作者展示的结果表明隐空间 w \mathbf{w} w相比于原始的 z \mathbf{z} z向量明显要更加解耦合。
因为合成网络是基于 ProGAN架构,所以它是渐进式训练的。合成网络早期层(当图像分辨率处于最低时 — 4x4, 8x8)的风格向量相比于网络后期(图像分辨率从64x64 到 1024x1024时)会在影响更粗粒度的特征。这意味着我们通过隐向量 w \mathbf{w} w 不仅对生成图像有更完整的控制,而且可以在合成网络的不同点上切换 w \mathbf{w} w 以改变不同层次细节的风格。
风格混合 (Style Mixing)
论文的作者使用了一个名为技巧 风格混合 的技巧来确保生成器在训练过程中不会利用相邻风格的关系(也即,注入到每层的风格尽可能解耦合)。作者不是仅仅使用了一个单一的隐向量 z \mathbf{z} z,而是采样了两个 ( z 1 , z 2 ) (\mathbf{z}_1, \mathbf{z}_2) (z1,z2),对应两个风格向量 w 1 , w 2 \mathbf{w}_1,\mathbf{w}_2 w1,w2。然后在每一层, w 1 \mathbf{w}_1 w1或 w 2 \mathbf{w}_2 w2随机选择,以此打破向量间任何可能的相关性。
统计变化 (Stochastic Variation)
合成网络在每个卷积层之后加上噪声 (通过一个学到的广播层 B) 以覆盖一些随机细节如个性化头发,或者脸部背后的背景。同样的,噪声注入的层级深度影响其对图像粗细力度的影响。
这也意味着合成网络的初始输入可以简单的是一个学到的常数,而非加性噪声。在风格输入和噪声输入中已经有足够的随机性,可以在图像中产生足够丰富的变化。
StyleGAN输出
图10-9展示了StyleGAN的实际应用。

这里,两张图,source A 和 source B,是从两个不同的 w \mathbf{w} w生成。为了生成融合图像,source A的 w \mathbf{w} w 传输给合成网络,在某个点上,切换成 source B的 w \mathbf{w} w。如果切换发生在早期阶段 (4x4 或者 8x8分辨率),source B中粗粒度的风格如姿势,人脸形状以及眼镜会带到 source A中。然而,如果切换发生较晚,那么只有细粒度细节会引入,例如颜色和人脸的细微结构,而source A的粗粒度特征将会保留。
StyleGAN2
重要的GAN论文链中最后一个贡献来自于 StyleGAN2。StyleGAN2基于StyleGAN 架构,并做了一些关键改进来提升生成图像质量。特别的,StyleGAN2不会有特别严重的 artifacts — 由StyleGAN种AdaIN层造成的水滴状图像区域,如图10-10所示。

StyleGAN2的生成器和鉴别器都跟 StyleGAN不同。在下一小节中,我们将探索两者在架构上的关键不同。
| 训练自己的StyleGAN2 |
|---|
| 使用 TensorFlow来训练StyleGAN2的官方代码在Github有公开。需要留意的是,要训练一个跟原始论文中一样效果的StyleGAN2需要大量算力。 |
权重调制及解调
如图10-11所示,通过移除生成器中的AdaIN层,并将之替代为权重调制和解调,artifact 的问题得以解决。 w \mathbf{w} w 代表卷积层权重,它们通过styleGAN2运行时的调制和解调步骤进行直接更新。对比来讲,StyleGAN 的 AdaIN层是在图像张量流经网络时进行操作。
StyleGAN 的 AdaIN层就是简单的实例归一化紧接风格调制 (尺度和偏置)。StyleGAN2的主要思想是: 在卷积层权重运行时直接应用风格调制和归一化 (解调),而非应用于卷积层的输出,如图10-11所示。作者展示了为什么这个操作可以去除artifact问题,同时保持对图像风格的控制。
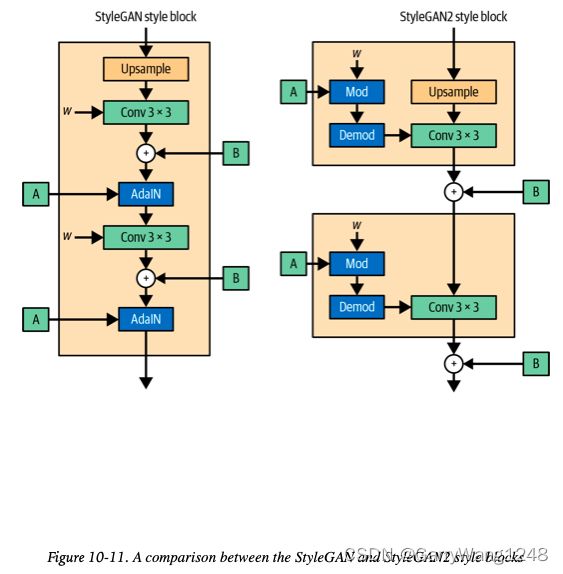
在StyleGAN2中,每个全连层A输出一个单一风格向量 s i s_i si,其中 i i i表示对应卷积层的输入通道数。这种风格向量进一步按如下方式应用于卷积层的权重:
w i , j , k = s i ⋅ w i , j , k w_{i,j,k} = s_i \cdot w_{i,j,k} wi,j,k=si⋅wi,j,k
这里, j j j 表示层的输出通道数, k k k 表示空间维度。这是过程的调制步骤。
然后,我们对权重进行归一化,使得它们有单位标准差,以确保训练过程的稳定性。这是解调步骤:
w i , j , k = w i , j , k ∑ i , k w i , j , k 2 + ϵ w_{i,j,k} = \frac{w_{i,j,k} }{\sqrt{\sum\limits_{i,k}w_{i,j,k}^2 + \epsilon }} wi,j,k=i,k∑wi,j,k2+ϵwi,j,k
其中 ϵ \epsilon ϵ 是一个小的常量值,以避免分母为0。
在论文中,作者展示了为什么这种简单的改变足够去除水滴状artifacts,同时保持通过风格向量对生成图像的控制,并确保输出保持在高质量。
路径长度正则化 (Path Length Regularization)
StyleGAN架构上另一个改变在于损失函数引入了一个额外的惩罚项 — 我们称之为路径长度正则化。
我们希望隐空间尽可能的平滑且均匀,使得隐空间的任何固定步数在图像中产生的改变幅度也是固定的。
为了鼓励这一性质,StyleGAN2 目标是最小化下列项,类似之前的带梯度惩罚的 Wasserstein 损失:
E w , y ( ∣ ∣ J w T y ∣ ∣ 2 − a ) 2 \mathbb{E}_{w,y} (||\mathbf{J}_w^T\mathbf{y}||_2 - a)^2 Ew,y(∣∣JwTy∣∣2−a)2
这里, w w w 是一组映射网络产生的一组风格向量, y y y是一组从 N ( 0 , I ) \mathcal{N}(0,\mathbf{I}) N(0,I)中抽取的噪声图像, J w = ∂ g ∂ w \mathbf{J}_w=\frac{\partial g}{\partial w} Jw=∂w∂g是生成网络相对于风格向量的雅可比。
∣ ∣ J w T y ∣ ∣ 2 ||\mathbf{J}_w^Ty||_2 ∣∣JwTy∣∣2这一项度量图像 y y y 在通过雅可比给定梯度转换后的幅度。我们希望其尽可能接近一个常数 a a a,该常数随着训练过程动态计算为 ∣ ∣ J w T y ∣ ∣ 2 ||\mathbf{J}_w^Ty||_2 ∣∣JwTy∣∣2的指数滑动平均(exponential moving average)。
作者发现,这个额外项可以使得隐空间的探索更可靠、更一致。进一步的,效率起见,损失函数正则项每16个minibatches仅应用一次。这个技术,称为 lazy regularization,不会造成性能的可见下降。
非渐进式成长(No Progressive Growing)
另一个重大升级在于StyleGAN2的训练。作者没有采用之前的渐进式训练机制,而是在生成器中利用了跳跃连接,在鉴别器中使用了残差连接来把整个网络作为一个整体训练。它不再把不同分辨率独立训练并融合作为训练过程的一部分。
图10-12展示了StyleGAN2 生成器和鉴别器 blocks。
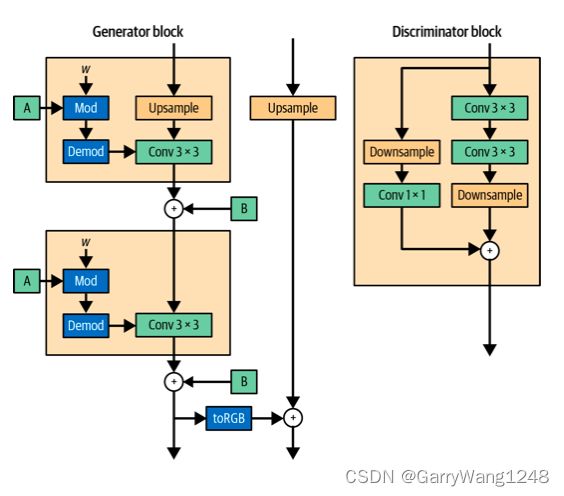
我们希望保留的关键性质在于: StyleGAN2 以学习低分辨率特征开始,并随着训练过程逐渐精调输出。作者证明了,使用这一架构,这一性质真的得到保留。每个网络都从低分辨率层在训练早期阶段的卷积权重精调中受益,被用来将输出传递给高分辨率层的跳跃和残差连接几乎不受影响。随着训练的进行,高分辨率层开始主要,因为生成器发现了更复杂的方式来提升图像真实度以骗过鉴别器。这一过程如图10-13所示。

StyleGAN2之输出
StyleGAN2 的一些样例输出如图10-14所示。迄今为止,根据benchmarking 网站 Papers with Code,StyleGAN2架构 (以及其不同规模的变种例如 StyleGAN-XL) 在一些数据库如 Flickr-Faces-HQ (FFHQ) 和 CIFAR-10 上都是图像生成的SOTA。

其他重要的GANs
在这一小节里,我们将探索两个另外的对GANs发展贡献良多的架构 — SAGAN 和 BigGAN。
自注意力GAN(Self-Attention GAN, SAGAN)
SAGAN是GANs技术的一项关键进展,因为它展示了在序列模型中(如Transformer)占据统治地位的注意力机制可以如何集成到用于图像生成的基于GAN的模型中。图10-15展示了原始paper中的自注意力机制。

未融合注意力的GAN模型问题在于: 卷积特征图只能够进行局部信息处理。在图像中,将图像一侧的像素信息连接到另一侧需要多个卷积层来减少网络尺寸,同时增加通道数目。在整个过程中,为了捕获更高级别的特征,精确的位置信息会减少,这使得模型学习远程连接像素之间的远程依赖关系的计算效率低下。SAGAN通过在GAN中融合注意力机制解决了这一问题。这一改进的效果如下图10-16所示。

红点代表小鸟身体一部分的一个像素,因此,注意力自然落到周围的身体部分。绿点是背景的一部分,这里注意力事实上落在小鸟头部的另一边,在其它的背景像素上。蓝点是小鸟尾部的一部分,因此注意力集中在其他的尾部像素,其中一些离蓝点比较远。如果没有注意力机制,我们很难维持像素间大范围的依赖性,尤其是对于图像中长的,细的结构 (例如本例中的尾部)。
| 训练自己的SAGAN |
|---|
| 使用 TensorFlow来训练SAGAN的官方代码在Github有公开。需要留意的是,要训练一个跟原始论文中一样效果的SAGAN需要大量算力。 |
BigGAN
由 DeepMind 开发的 BigGAN,扩展了原始SAGAN论文的思想。图10-17展示了BigGAN生成的一些图像,该模型在ImageNet数据集 128x128分辨率上训练得到。

除了在SAGAN基础上的一些增量改进,论文中也列举了一些创新点将模型代入了更高的复杂度。其中一个创新名为 “截断技巧 (truncation trick)”。这就是用于采样的潜在分布 与 训练时用的$z \sim \mathcal{N}(0,\mathbf{I}) $分布 不同的地方。特别的,采样过程中使用的分布是一个截断的正态分布 (truncated normal distribution,对大于某个幅度阈值的 z 值进行重采样)。截断阈值越小,生成样本的置信度越大,代价是发散度减小。概念如图10-18所示。

另外,如名字所提示,BigGAN是SAGAN的一个改进,部分意义上就是更大。BigGAN使用了batchsize = 2048 — 是SAGAN中使用的256batchsize的8倍大 — 同时,所有层的通道数都增加50%。然而,BigGAN另外表明, SAGAN可以通过引入共享嵌入层,通过正交正则化,以及在生成器的每个层中融入隐向量z来 获得结构上的优化。
对于BigGAN中创新性的描述,我推荐阅读原始的论文及伴随展示材料。
| 使用BigGAN |
|---|
| 使用预训练好的BigGAN来生成图像的教程可在TensorFlow官网上获取。 |
VQ-GAN
另一个重要的GAN类型是2020年出现的向量量化GAN(Vector Quantized GAN,VA-GAN)。模型架构基于2017年论文“Neural Discrete Representation Learning” — 也即,VAE学到的表示可以是离散而非连续的。这种新的模型,VQ-VAE,可以生成高质量的图像,同时避免过去连续隐空间VAEs的某些常见问题,例如 posterior collapse (学到的隐空间由于过分强大的解码器而无意义。)
| 小贴士 |
|---|
| OpenAI在2021年发布的文生图模型DALL.E的首个版本(见第13章),使用了一个离散VAE隐空间,类似VQ-VAE。 |
对于离散隐空间,我们指的是一组学习到的向量 (码簿),每个都与对应的index相关。VA-VAE中编码器的工作是把输入图像坍缩为一个小一些的,可与码簿进行比较的向量网格。每个grid square vector的最近码簿向量 (欧式距离)被拿给解码器解码,如图10-19所示。码簿是一组长度为 d (嵌入尺寸) 的学到的向量,它与编码器输出和解码器输入的通道数匹配。例如, e 1 e_1 e1是一个可被解释为背景的向量。

码簿可以被看作一组 在编码器和解码器之间共享以描述给定图像内容的 离散概念。 VQ-VAE 需要找到一种方式,使得这组离散概念尽可能提供有用信息以使得编码器可以精准用一个特定的对解码器有意义的编码向量标定每个grid square。VQ-VAE的损失函数是重建损失和加上两项 (alignment and commitment 损失) 以确保编码器的输出向量 与 码簿向量尽可能接近。这些项替代了经典VAE中编码分布和标准高斯先验的KL散度。
然而,这个架构导致了一个问题 — 我们该如何采样一个新的 code grids 并传给解码器以生成新的图像?显然,使用一个均匀先验(对于每个grid square,等概率挑选一个code)可不行。例如,在MNIST数据集中,左上grid square大概率被编码为背景,而朝向图像中心的网格方块则不太可能被编码为背景。为了解决这一问题,作者使用了另一个模型 — 一个自回归的PixelCNN,以在给定前序编码向量时预测网格中下一个编码向量。换句话说,先验是被模型学得的,而非如原生VAE一样是静态的。
| 训练你自己的VQ-VAE |
|---|
| 在Keras官网上,Sayak Paul提供了一个如何训练VQ-VAE的出色教程。 |
VQ-GAN 论文给出了VQ-VAE的关键改变,如图10-20所示。

首先,顾名思义,作者加入了一个 GAN 判别器,试图区分 VAE 解码器的输出和真实图像,并在损失函数中附带对抗项。 众所周知,GAN 可以产生比 VAE 更清晰的图像,因此这一添加提高了整体图像质量。 请注意,尽管有这个名称,VAE 仍然存在于 VQ-GAN 模型中——GAN 判别器是一个附加组件,而非替代了VAE。 Larsen 等人在 2015 年的论文中首先提出了将 VAE 与 GAN 判别器(VAE-GAN)相结合的想法。
其次,GAN 判别器会预测一小部分图像的真假,而不是一次性预测整个图像。 这个想法 (PatchGAN) 被应用在 Isola 等人 2016 年成功推出的 pix2pix 图像到图像模型中,并且也成功应用于 CycleGAN (另一个图像到图像风格迁移模型)。 PatchGAN 判别器输出一个预测向量(每个补丁的预测),而不是整个图像的单个预测。 使用 PatchGAN 判别器的好处是,损失函数可以根据图像的风格而不是内容来衡量判别器区分图像的能力。 由于鉴别器预测的每个单独元素都基于图像的小方块,因此它必须使用补丁的样式而不是其内容来做出决定。 这很有用,因为我们知道 VAE 生成的图像在风格上比真实图像更模糊,因此 PatchGAN 判别器可以鼓励 VAE 解码器生成更清晰的图像。
第三,VQ-GAN 没有使用单个 MSE 重建损失来比较输入图像像素与 VAE 解码器的输出像素,而是使用感知损失项来计算编码器中间层的特征图与相应解码器层特征图之间的差异。 这个想法来自 Hou 等人 2016 年的论文,其中作者表明,损失函数的这种变化可以产生更真实的图像。
最后,使用 Transformer 代替 PixelCNN 作为模型的自回归部分,经过训练来生成代码序列。 在 VQ-GAN 完全训练之后,Transformer 在单独的阶段进行训练。 作者没有以完全自回归的方式使用所有先前的标记,而是选择仅使用落在要预测的标记周围的滑动窗口内的标记。 这确保了模型可以扩展到更大的图像,这需要更大的潜在网格大小,因此 Transformer 会生成更多的标记。
ViT VQ-GAN
Yu 等人在2021 年题为“Vector-Quantized Image Modeling with Improved VQGAN”的论文中对 VQ-GAN 进行了扩展。作者展示了如何用 Transformer 替换 VQ-GAN 的卷积编码器和解码器,如图 10-21 所示。
对于编码器,作者使用了 Vision Transformer (ViT)。 ViT 是一种神经网络架构,它将最初为自然语言处理而设计的 Transformer 模型应用于图像数据。 ViT 不使用卷积层从图像中提取特征,而是将图像划分为一系列补丁,这些补丁被标记化,然后作为输入馈送到编码器 Transformer。
具体来说,在 ViT VQ-GAN 中,首先展平非重叠输入块(每个大小为 8 × 8),然后投影到低维嵌入空间,在其中添加位置嵌入。 然后将该序列馈送到标准编码器 Transformer,并根据学习的码本对所得嵌入进行量化。 然后,这些整数代码由解码器 Transformer 模型进行处理,整体输出是一系列可以拼接在一起以形成原始图像的补丁。 整个编码器-解码器模型作为自动编码器进行端到端训练。

对于编码器,作者使用了 Vision Transformer (ViT)。16 ViT 是一种神经网络架构,它将最初为自然语言处理而设计的 Transformer 模型应用于图像数据。 ViT 不使用卷积层从图像中提取特征,而是将图像划分为一系列补丁,这些补丁被标记化,然后作为输入馈送到编码器 Transformer。
与原始 VQ-GAN 模型一样,训练的第二阶段涉及使用自回归解码器 Transformer 生成代码序列。 因此,除了 GAN 判别器和学习码本之外,ViT VQ-GAN 中总共有 3 个 Transformer。 图 10-22 显示了 ViT VQ-GAN 从论文中生成的图像示例。

本章小结
在本章中,我们回顾了 2017 年以来一些最重要和最有影响力的 GAN 论文。特别是,我们探索了 ProGAN、StyleGAN、StyleGAN2、SAGAN、BigGAN、VQ-GAN 和 ViT VQ-GAN。
我们首先探索了 2017 年 ProGAN 论文中首次提出的渐进式训练的概念。 2018 年的 StyleGAN 论文中引入了几个关键变化,可以更好地控制图像输出,例如用于创建特定样式向量的映射网络和允许以不同分辨率注入样式的合成网络。 最后,StyleGAN2 用权重调制和解调步骤取代了 StyleGAN 的自适应实例归一化,同时还进行了路径正则化等其他增强功能。 该论文还展示了如何在无需逐步训练网络的情况下保留逐步分辨率细化的理想特性。
随着 2018 年 SAGAN 的推出,我们还看到了如何将注意力的概念构建到 GAN 中。这使得网络能够捕获远程依赖关系,例如图像相对两侧的相似背景颜色,而无需依赖深度学习 卷积映射将信息传播到图像的空间维度上。 BigGAN 是这个想法的延伸,它做出了一些关键的改变并训练了一个更大的网络以进一步提高图像质量。
在 VQ-GAN 论文中,作者展示了如何组合几种不同类型的生成模型以产生巨大效果。 在最初的 VQ-VAE 论文(引入了具有离散潜在空间的 VAE 概念)的基础上,VQ-GAN 还包含一个判别器,鼓励 VAE 通过额外的对抗性损失项生成不太模糊的图像。 自回归 Transformer 用于构造新的代码标记序列,该序列可以由 VAE 解码器解码以生成新的图像。 ViT VQ-GAN 论文进一步扩展了这一想法,用 Transformer 替换 VQ-GAN 的卷积编码器和解码器。