kubeflow-8-pipeline中的数据传递
Argo Workflows是一个开源的容器本地工作流引擎,用于在kubernetes上协调运行作业。Argo Workflows是基于kubernetes CRD实现的
功能:
(1)定义工作流,其中工作流中的每一个步骤都是一个容器
(2)将多个步骤工作流建模成一系列的任务,或者使用有向无环图(DAG)捕获任务间的依赖关系
(3)使用kubernetes上的Argo Workflows可以在短时间内轻松操作大量计算密集型作业
(4)不需要配置复杂的软件开发产品就可以在kubernetes本地环境中运行CI/CD
1 小数据
Small data is the data that you’ll be comfortable passing as program’s command-line argument. Small data size should not exceed few kilobytes.
小数据是作为程序的命令行参数传递的数据。小数据大小不应超过几千字节。
Some examples of typical types of small data are: number, URL, small string (e.g. column name).
小数据的典型类型有:数字、URL、小字符串(例如列名)。
Small lists, dictionaries and JSON structures are fine, but keep an eye on the size and consider switching to file-based data passing methods that are more suitable for bigger data (more than several kilobytes) or binary data.
小列表、字典和JSON结构可以,但是要注意大小,并考虑切换到基于文件的数据传递方法更适合于较大的数据(超过几千字节)或二进制数据。
All small data outputs will be at some point serialized to strings and all small data input values will be at some point deserialized from strings (passed as command-line argumants). There are built-in serializers and deserializers for several common types (e.g. str, int, float, bool, list, dict). All other types of data need to be serialized manually before returning the data. Make sure to properly specify type annotations, otherwize there would be no automatic deserialization and the component function will receive strings instead of deserialized objects.
所有小数据输出将在某个点序列化为字符串,所有小数据输入值将在某个点从字符串反序列化(作为命令行参数传递)。对于几种常见类型(例如str、int、float、bool、list、dict),都有内置的序列化程序和反序列化程序。在返回数据之前,所有其他类型的数据都需要手动序列化。确保正确指定类型注释,否则不会自动反序列化,组件函数将接收字符串而不是反序列化对象。
1.1 kfp.components.func_to_container_op
将一个python方法转化成一个pipeline的组件。
func_to_container_op(func:Callable,
output_component_file:Union[str, NoneType]=None,
base_image:Union[str, NoneType]=None,
extra_code:Union[str, NoneType]='',
packages_to_install:List[str]=None,
modules_to_capture:List[str]=None,
use_code_pickling:bool=False,
annotations:Union[Mapping[str, str],
NoneType]=None)
功能:
Converts a Python function to a component and returns a task
(:class:`kfp.dsl.ContainerOp`) factory.
Function docstring is used as component description. Argument and return annotations are used as component input/output types.
函数docstring用作组件描述。参数和返回注释用作组件输入/输出类型。
To declare a function with multiple return values, use the :code:`NamedTuple` return annotation syntax::
声明多个返回值的方式
from typing import NamedTuple
def add_multiply_two_numbers(a: float, b: float) -> NamedTuple('DummyName', [('sum', float), ('product', float)]):
"""Returns sum and product of two arguments"""
return (a + b, a * b)
参数:
常用(1)func: 必填
The python function to convert
常用(2)base_image: Optional. 可选
Specify a custom Docker container image to use in the component.
指定要在组件中使用的自定义Docker容器映像。
For lightweight components, the image needs to have python 3.5+.
Default is tensorflow/tensorflow:1.13.2-py3
(3)output_component_file: Optional. 可选
Write a component definition to a local file.
Can be used for sharing.
(4)extra_code: Optional. 可选
Extra code to add before the function code.
Can be used as workaround to define types used in function signature.
(5)packages_to_install: Optional. 可选
List of [versioned] python packages to pip install before executing the user function.
(6)modules_to_capture: Optional. 可选
List of module names that will be captured (instead of just referencing) during the dependency scan.
By default the :code:`func.__module__` is captured.
The actual algorithm: Starting with the initial function, start traversing dependencies.
If the :code:`dependency.__module__` is in the :code:`modules_to_capture` list then it's captured and it's dependencies are traversed.
Otherwise the dependency is only referenced instead of capturing and its dependencies are not traversed.
(7)use_code_pickling: Specifies whether the function code should be captured using pickling as opposed to source code manipulation.
Pickling has better support for capturing dependencies, but is sensitive to version mismatch between python in component creation environment and runtime image.
(8)annotations: Optional. 可选
Allows adding arbitrary key-value data to the component specification.
返回值:
A factory function with a strongly-typed signature taken from the python function.
Once called with the required arguments, the factory constructs a pipeline task instance (:class:`kfp.dsl.ContainerOp`)
1.2 kfp.Client.create_run_from_pipeline_func
在启用kfp的Kubernetes群集上运行pipeline。
create_run_from_pipeline_func(self,
pipeline_func:Callable,
arguments:Mapping[str, str],
run_name:Union[str, NoneType]=None,
experiment_name:Union[str, NoneType]=None,
pipeline_conf:Union[kfp.dsl._pipeline.PipelineConf, NoneType]=None,
namespace:Union[str, NoneType]=None)
功能:
Runs pipeline on KFP-enabled Kubernetes cluster.
在启用KFP的Kubernetes群集上运行pipeline。
This command compiles the pipeline function, creates or gets an experiment and submits the pipeline for execution.
参数:
(1)pipeline_func: 必填
A function that describes a pipeline by calling components and composing them into execution graph.
(2)arguments: 必填
Arguments to the pipeline function provided as a dict.
(3)run_name: Optional. 可选
Name of the run to be shown in the UI.
(4)experiment_name: Optional. 可选
Name of the experiment to add the run to.
(5)pipeline_conf: Optional. 可选
Pipeline configuration ops that will be applied to all the ops in the pipeline func.
(6)namespace: Kubernetes namespace where the pipeline runs are created.
For single user deployment, leave it as None;
For multi user, input a namespace where the user is authorized
1.3 消费常量参数
#pip install kfp
#docker pull tensorflow/tensorflow:1.13.2-py3
(1)指定基础镜像
直接打印常量参数
import kfp
from kfp.components import func_to_container_op
def print_fun():
print("hello world")
if __name__ == '__main__':
image_name = "tensorflow/tensorflow:1.13.2-py3"
my_op = func_to_container_op(print_fun,base_image=image_name)
kfp.Client().create_run_from_pipeline_func(my_op, arguments={})
(2)使用修饰器
默认会拉取镜像python:3.7
import kfp
from kfp.components import func_to_container_op
@func_to_container_op
def print_fun(text:str):
print(text)
def use():
print_fun("hello lucy")
if __name__ == '__main__':
kfp.Client().create_run_from_pipeline_func(use, arguments={})
1.4 消费变量参数
(1)指定基础镜像
import kfp
from kfp.components import func_to_container_op
def use(text:str):
print(text)
if __name__ == '__main__':
image_name = "tensorflow/tensorflow:1.13.2-py3"
my_op = func_to_container_op(use,base_image=image_name)
kfp.Client().create_run_from_pipeline_func(my_op, arguments={"text":"hello you"})
(2)使用修饰器
默认会拉取镜像python:3.7
import kfp
from kfp.components import func_to_container_op
@func_to_container_op
def print_fun(text:str):
print(text)
def use(text:str):
print_fun(text)
if __name__ == '__main__':
kfp.Client().create_run_from_pipeline_func(use, arguments={"text":"hello me"})
1.5 生产单参数数据
import kfp
from kfp.components import func_to_container_op
@func_to_container_op
def print_fun(text:str):
print(text)
@func_to_container_op
def produce_fun() -> str:
return 'Hello world'
def use():
produce_task = produce_fun()
# task.output only works for single-output components
consume_task1 = print_fun(produce_task.output)
# task.outputs[...] always works
consume_task2 = print_fun(produce_task.outputs['output'])
if __name__ == '__main__':
kfp.Client().create_run_from_pipeline_func(use, arguments={})
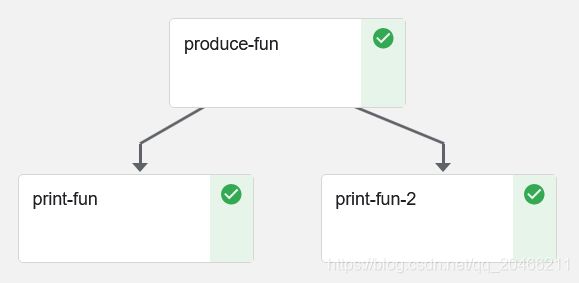
定义了组件print_fun,默认使用镜像python:3.7
定义了组件produce_fun,默认使用镜像python:3.7
函数use制定了pipeline,数据从生产传到消费。
1.6 生产多参数数据
import kfp
from kfp.components import func_to_container_op
from typing import NamedTuple
@func_to_container_op
def consume_one_argument(text: str):
print('name={}'.format(text))
@func_to_container_op
def produce_one_output() ->str:
return "lucy"
@func_to_container_op
def consume_two_arguments(text: str, number: int):
print('name={}'.format(text))
print('age={}'.format(str(number)))
@func_to_container_op
def produce_two_outputs() -> NamedTuple('Outputs', [('name', str), ('age', int)]):
return ("lily", 24)
def use(text: str = "kerry"):
produce_task1 = produce_one_output()
produce_task2 = produce_two_outputs()
# task.output only works for single-output components
consume_task1 = consume_one_argument(produce_task1.output)
# task.outputs[...] always works
consume_task2 = consume_one_argument(produce_task1.outputs['output'])
consume_task3 = consume_two_arguments(produce_task2.outputs['name'], produce_task2.outputs['age'])
consume_task4 = consume_two_arguments(text, produce_task2.outputs['age'])
consume_task5 = consume_two_arguments(produce_task1.outputs['output'], produce_task2.outputs['age'])
if __name__ == '__main__':
kfp.Client().create_run_from_pipeline_func(use, arguments={})

2 大数据
(1)Bigger data should be read from files and written to files.
较大的数据应该从文件中读取并写入文件。
(2)The paths for the input and output files are chosen by the system and are passed into the function (as strings).
输入和输出文件的路径由系统选择,并作为字符串传递到函数中。
(3)Use the InputPath parameter annotation to tell the system that the function wants to consume the corresponding input data as a file. The system will download the data, write it to a local file and then pass the path of that file to the function.
使用InputPath参数注释告诉系统函数希望将相应的输入数据作为文件使用。系统将下载数据,将其写入本地文件,然后将该文件的路径传递给函数。
(4)Use the OutputPath parameter annotation to tell the system that the function wants to produce the corresponding output data as a file. The system will prepare and pass the path of a file where the function should write the output data. After the function exits, the system will upload the data to the storage system so that it can be passed to downstream components.
使用OutputPath参数注释告诉系统函数希望以文件形式生成相应的输出数据。系统将准备并传递函数应在其中写入输出数据的文件路径。函数退出后,系统会将数据上载到存储系统,以便将其传递给下游组件。
(5)You can specify the type of the consumed/produced data by specifying the type argument to InputPath and OutputPath. The type can be a python type or an arbitrary type name string. OutputPath(‘TFModel’) means that the function states that the data it has written to a file has type ‘TFModel’. InputPath(‘TFModel’) means that the function states that it expect the data it reads from a file to have type ‘TFModel’. When the pipeline author connects inputs to outputs the system checks whether the types match.
通过将type参数指定给InputPath和OutputPath,可以指定已使用/生成的数据的类型。类型可以是python类型或任意类型名字符串。OutputPath(‘TFModel’)表示函数声明它写入文件的数据的类型为’TFModel’。InputPath(‘TFModel’)表示函数声明它希望从文件中读取的数据的类型为’TFModel’。当管道作者将输入连接到输出时,系统检查类型是否匹配。
Note on input/output names:
When the function is converted to component,
the input and output names generally follow the parameter names,
but the "_path" and "_file" suffixes are stripped from file/path inputs and outputs.
E.g. the number_file_path: InputPath(int) parameter becomes the number: int input.
This makes the argument passing look more natural: number=42 instead of number_file_path=42.
2.1 kfp.components.InputPath
class InputPath(builtins.object)
When creating component from function,
:class:`.InputPath` should be used as function parameter annotation
to tell the system to pass the *data file path* to the function
instead of passing the actual data.
__init__(self, type=None)
Initialize self. See help(type(self)) for accurate signature.
2.2 kfp.components.OutputPath
class OutputPath(builtins.object)
When creating component from function,
:class:`.OutputPath` should be used as function parameter annotation
to tell the system that the function wants to output data by writing it into a file with the given path
instead of returning the data from the function.
__init__(self, type=None)
Initialize self. See help(type(self)) for accurate signature.
2.3 大数据读写
from typing import NamedTuple
import kfp
from kfp.components import InputPath, InputTextFile, OutputPath, OutputTextFile
from kfp.components import func_to_container_op
# Writing bigger data
@func_to_container_op
def produce_data(line: str, output_text_path: OutputPath(str), count: int = 10):
'''Repeat the line specified number of times'''
with open(output_text_path, 'w') as fw:
for i in range(count):
fw.write(line + '\n')
# Reading bigger data
@func_to_container_op
def consume_data(text_path: InputPath()): # The "text" input is untyped so that any data can be printed
'''Print text'''
with open(text_path, 'r') as reader:
for line in reader:
print(line, end = '')
def print_repeating_lines_pipeline():
produce_task = produce_data(line='world', count=20)
consume_task = consume_data(produce_task.output) # Don't forget .output !
if __name__ == '__main__':
kfp.Client().create_run_from_pipeline_func(print_repeating_lines_pipeline, arguments={})

3 多输出
how to make a component with multiple outputs using the Pipelines SDK.
3.1 kfp.compiler.build_python_component
build_python_component(component_func:Callable,
target_image:str,
base_image:Union[str, NoneType]=None,
dependency:List[str]=[],
staging_gcs_path:Union[str, NoneType]=None,
timeout:int=600,
namespace:Union[str, NoneType]=None,
target_component_file:Union[str, NoneType]=None,
python_version:str='python3',
is_v2:bool=False)
automatically builds a container image for the
component_func based on the base_image and pushes to the target_image.
参数:
(1)component_func (python function):
The python function to build components upon.
(2)base_image (str):
Docker image to use as a base image.
(3)target_image (str):
The target image path.
Full URI to push the target image.
(4)staging_gcs_path (str): GCS blob that can store temporary build files.
(5)timeout (int):
The timeout for the image build(in secs), default is 600 seconds.
(6)namespace (str):
The namespace within which to run the kubernetes Kaniko job. If the job is running on GKE and value is None the underlying functions will use the default namespace from GKE.
(7)dependency (list):
The list of VersionedDependency, which includes the package name and versions, default is empty.
(8)target_component_file (str):
The path to save the generated component YAML spec.
(9)python_version (str): Choose python2 or python3, default is python3
is_v2: Whether or not generating a v2 KFP component, default is false.
3.2 func_to_container_op
(1)修饰器
会默认下载python:3.7镜像
import kfp
from typing import NamedTuple
from kfp.components import func_to_container_op
@func_to_container_op
def product_sum(a: float, b: float) -> NamedTuple('hahah', [('product', float), ('sum', float)]):
'''Returns the product and sum of two numbers'''
return (a*b, a+b)
@kfp.dsl.pipeline(
name='Multiple Outputs Pipeline',
description='Sample pipeline to showcase multiple outputs'
)
def pipeline(a=2.0, b=2.5, c=3.0):
prod_sum_task = product_sum(a, b)
prod_sum_task2 = product_sum(b, c)
prod_sum_task3 = product_sum(prod_sum_task.outputs['product'],
prod_sum_task2.outputs['sum'])
if __name__ == '__main__':
arguments = { 'a': 2,'b': 3,'c': 4}
kfp.Client().create_run_from_pipeline_func(pipeline, arguments=arguments)
(2)指定镜像
会使用指定的镜像
import kfp
from typing import NamedTuple
from kfp.components import func_to_container_op
def product_sum(a: float, b: float) -> NamedTuple('hahah', [('product', float), ('sum', float)]):
'''Returns the product and sum of two numbers'''
return (a*b, a+b)
image_name = "tensorflow/tensorflow:1.13.2-py3"
my_op = func_to_container_op(product_sum,base_image = image_name)
@kfp.dsl.pipeline(
name='Multiple Outputs Pipeline',
description='Sample pipeline to showcase multiple outputs'
)
def my_pipeline(a=2.0, b=2.5, c=3.0):
task1 = my_op(a, b)
task2 = my_op(b, c)
task3 = my_op(task1.outputs['product'],task2.outputs['sum'])
if __name__ == '__main__':
arguments = { 'a': 20,'b': 30,'c': 40}
kfp.Client().create_run_from_pipeline_func(my_pipeline, arguments=arguments)