nebula graph 3.0.x 导入数据
文章目录
- nebula graph studio & nebula console
- java client
- Nebula Importer
-
- 适用场景
- 优势
- 前提条件
- 操作步骤
-
- 启动命令
- 配置文件说明
- Nebula Exchange
-
- 版本系列
- 适用场景
- 产品优点
- 数据源
- 使用限制
- Nebula Spark Connector
-
- 适用场景
- 特性
- 获取 Nebula Spark Connector
- Nebula Flink Connector
-
- 适用场景
nebula graph studio & nebula console
java client
Nebula Importer
Nebula Importer(简称 Importer)是一款 Nebula Graph 的 CSV 文件单机导入工具。Importer 可以读取本地的 CSV 文件,然后导入数据至
Nebula Graph 图数据库中。
适用场景
Importer 适用于将本地 CSV 文件的内容导入至 Nebula Graph 中。
优势
- 轻量快捷:不需要复杂环境即可使用,快速导入数据。
- 灵活筛选:通过配置文件可以实现对 CSV 文件数据的灵活筛选。
前提条件
在使用 Nebula Importer 之前,请确保:
- 已部署 Nebula Graph 服务。目前有三种部署方式:
- Docker Compose 部署
- RPM/DEB 包安装
- 源码编译安装
- Nebula Graph 中已创建 Schema,包括图空间、Tag 和 Edge type,或者通过参数clientSettings.postStart.commands 设置。
- 运行 Importer 的机器已部署 Golang 环境。详情请参见 Golang 环境搭建。
操作步骤
配置 yaml 文件并准备好待导入的 CSV 文件,即可使用本工具向 Nebula Graph 批量写入数据。
启动命令
./<binary_package_name> --config <yaml_config_file_path>
注意:请使用正确的分支。 Nebula Graph 2.x 和 3.x 的 rpc 协议不同。
配置文件说明
Nebula Importer 通过nebula-importer/examples/v2/example.yaml 配置文件来描述待导入文件信息、Nebula Graph 服务器信息等。用户可以参考示例
配置文件:无表头配置/有表头配置。下文将分类介绍配置文件内的字段。
基本配置
version: v3
description: example
removeTempFiles: false

客户端配置
客户端配置存储客户端连接 Nebula Graph 相关的配置。
示例配置如下:
clientSettings:
retry: 3
concurrency: 10
channelBufferSize: 128
space: test
connection:
user: user
password: password
address: 192.168.11.13:9669,192.168.11.14:9669
# # 只有 local_config 是 false 的情况下,才可以通过 UPDATE CONFIGS 更新配置
# postStart:
# commands: |
# UPDATE CONFIGS storage:wal_ttl=3600;
# UPDATE CONFIGS storage:rocksdb_column_family_options = { disable_auto_compactions = true };
# afterPeriod: 8s
# preStop:
# commands: |
# UPDATE CONFIGS storage:wal_ttl=86400;
# UPDATE CONFIGS storage:rocksdb_column_family_options = { disable_auto_compactions = false };

文件配置
文件配置存储数据文件和日志的相关配置,以及 Schema 的具体信息。
文件和日志配置:
logPath: ./err/test.log
files:
- path: ./student_without_header.csv
failDataPath: ./err/studenterr.csv
batchSize: 128
limit: 10
inOrder: false
type: csv
csv:
withHeader: false
withLabel: false
delimiter: ","

SCHEMA 配置
Schema 配置描述当前数据文件的 Meta 信息,Schema 的类型分为点和边两类,可以同时配置多个点或边。
- 点配置
示例配置如下:
schema:
type: vertex
vertex:
vid:
type: string
index: 0
tags:
- name: student
props:
- name: name
type: string
index: 1
- name: age
type: int
index: 2
- name: gender
type: string
index: 3

注意:CSV 文件中列的序号从 0 开始,即第一列的序号为 0,第二列的序号为 1。
- 边配置
schema:
type: edge
edge:
name: follow
withRanking: true
srcVID:
type: string
index: 0
dstVID:
type: string
index: 1
rank:
index: 2
props:
- name: degree
type: double
index: 3

Nebula Exchange
Nebula Exchange(简称 Exchange)是一款 Apache Spark™ 应用,用于在分布式环境中将集群中的数据批量迁移到 Nebula Graph 中,能支
持多种不同格式的批式数据和流式数据的迁移。
Exchange 由 Reader、Processor 和 Writer 三部分组成。Reader 读取不同来源的数据返回 DataFrame 后,Processor 遍历 DataFrame 的
每一行,根据配置文件中fields 的映射关系,按列名获取对应的值。在遍历指定批处理的行数后,Writer 会将获取的数据一次性写入到 Nebula
Graph 中。下图描述了 Exchange 完成数据转换和迁移的过程。

版本系列
Exchange 有社区版和企业版两个系列,二者功能不同。社区版在 GitHub 开源开发,企业版属于 Nebula Graph 企业套餐,详情参见版本对比。
适用场景
Exchange 适用于以下场景:
- 需要将来自 Kafka、Pulsar 平台的流式数据,如日志文件、网购数据、游戏内玩家活动、社交网站信息、金融交易大厅或地理空间服务,以及来自
数据中心内所连接设备或仪器的遥测数据等转化为属性图的点或边数据,并导入 Nebula Graph 数据库。 - 需要从关系型数据库(如 MySQL)或者分布式文件系统(如 HDFS)中读取批式数据,如某个时间段内的数据,将它们转化为属性图的点或边数
据,并导入 Nebula Graph 数据库。 - 需要将大批量数据生成 Nebula Graph 能识别的 SST 文件,再导入 Nebula Graph 数据库。
- 需要导出 Nebula Graph 中保存的数据。
注意: 仅企业版 Exchange 支持从 Nebula Graph 中导出数据。
产品优点
Exchange 具有以下优点:
- 适应性强:支持将多种不同格式或不同来源的数据导入 Nebula Graph 数据库,便于迁移数据。
- 支持导入 SST:支持将不同来源的数据转换为 SST 文件,用于数据导入。
- 支持 SSL 加密:支持在 Exchange 与 Nebula Graph 之间建立 SSL 加密传输通道,保障数据安全。
- 支持断点续传:导入数据时支持断点续传,有助于节省时间,提高数据导入效率。(目前仅迁移 Neo4j 数据时支持断点续传。)
- 异步操作:会在源数据中生成一条插入语句,发送给 Graph 服务,最后再执行插入操作。
- 灵活性强:支持同时导入多个 Tag 和 Edge type,不同 Tag 和 Edge type 可以是不同的数据来源或格式。
- 统计功能:使用 Apache Spark™ 中的累加器统计插入操作的成功和失败次数。
- 易于使用:采用 HOCON(Human-Optimized Config Object Notation)配置文件格式,具有面向对象风格,便于理解和操作。
数据源
Exchange 3.0.0 支持将以下格式或来源的数据转换为 Nebula Graph 能识别的点和边数据,然后通过 nGQL 语句的形式导入 Nebula Graph:
存储在 HDFS 或本地的数据:
Apache Parquet
Apache ORC
JSON
CSV
Apache HBase™
数据仓库:
Hive
MaxCompute
图数据库:Neo4j(Client 版本 2.4.5-M1)
关系型数据库:
MySQL
PostgreSQL
列式数据库:ClickHouse
流处理软件平台:Apache Kafka®
发布/订阅消息平台:Apache Pulsar 2.4.5
除了用 nGQL 语句的形式导入数据,Exchange 还支持将数据源的数据生成 SST 文件,然后通过 Console 导入 SST 文件。
此外,企业版 Exchange 支持以 Nebula Graph 为源,将数据导出到 CSV 文件。
使用限制
版本兼容性
Nebula Exchange 版本(即 JAR 包版本)和 Nebula Graph 内核的版本对应关系如下。
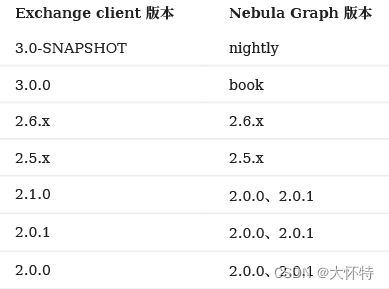
软件依赖
为保证 Exchange 正常工作,请确认机器上已经安装如下软件:
- Java 1.8 版本
- Scala 2.10.7、2.11.12 或 2.12.10 版本
- Apache Spark。使用 Exchange 从不同数据源导出数据对 Spark 版本的要求如下:
注意: 使用 Exchange 时,需根据 Spark 版本选择相应的 JAR 文件。例如,当 Spark 版本为 2.4 时,选择 nebula-exchange_spark_2.4-3.0.0.jar。
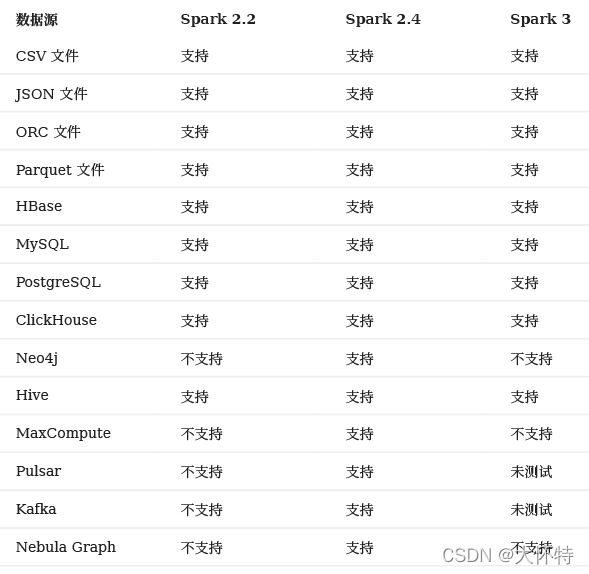
在以下使用场景,还需要部署 Hadoop Distributed File System (HDFS):
- 迁移 HDFS 的数据
- 生成 SST 文件
Nebula Spark Connector
Nebula Spark Connector 是一个 Spark 连接器,提供通过 Spark 标准形式读写 Nebula Graph 数据的能力。Nebula Spark Connector 由Reader 和 Writer 两部分组成。
- Reader
提供一个 Spark SQL 接口,用户可以使用该接口编程读取 Nebula Graph 图数据,单次读取一个点或 Edge type 的数据,并将读取的结果组装
成 Spark 的 DataFrame。 - Writer
提供一个 Spark SQL 接口,用户可以使用该接口编程将 DataFrame 格式的数据逐条或批量写入 Nebula Graph。
适用场景
Nebula Spark Connector 适用于以下场景:
- 在不同的 Nebula Graph 集群之间迁移数据。
- 在同一个 Nebula Graph 集群内不同图空间之间迁移数据。
- Nebula Graph 与其他数据源之间迁移数据。
- 结合 Nebula Algorithm 进行图计算。
特性
Nebula Spark Connector 3.0.0版本特性如下
- 提供多种连接配置项,如超时时间、连接重试次数、执行重试次数等。
- 提供多种数据配置项,如写入数据时设置对应列为点 ID、起始点 ID、目的点 ID 或属性。
- Reader 支持无属性读取和全属性读取。
- Reader 支持将 Nebula Graph 数据读取成 Graphx 的 VertexRDD 和 EdgeRDD,支持非 Long 型点 ID。
- 统一了 SparkSQL 的扩展数据源,统一采用 DataSourceV2 进行 Nebula Graph 数据扩展。
- 支持insert 、update 和delete 三种写入模式。insert 模式会插入(覆盖)数据, update 模式仅会更新已存在的数据, delete 模式只删除数据。
- 支持与 Nebula Graph 之间的 SSL 加密连接。
获取 Nebula Spark Connector
Nebula Flink Connector
Nebula Flink Connector 是一款帮助 Flink 用户快速访问 Nebula Graph 的连接器,支持从 Nebula Graph 图数据库中读取数据,或者将其他
外部数据源读取的数据写入 Nebula Graph 图数据库。
适用场景
- 在不同的 Nebula Graph 集群之间迁移数据。
- 在同一个 Nebula Graph 集群内不同图空间之间迁移数据。
- Nebula Graph 与其他数据源之间迁移数据。