初始JVM虚拟机
JVM组成
图解
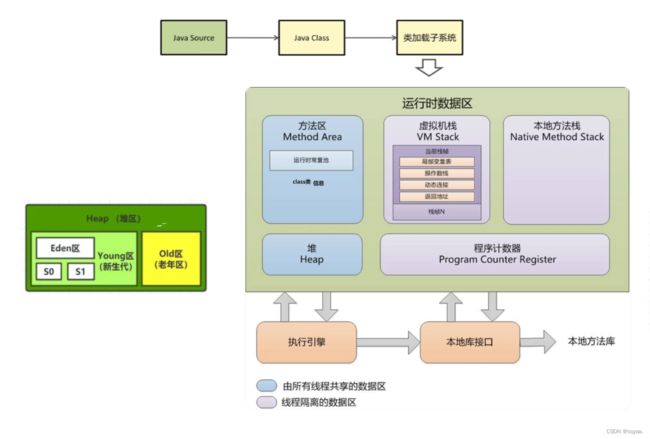
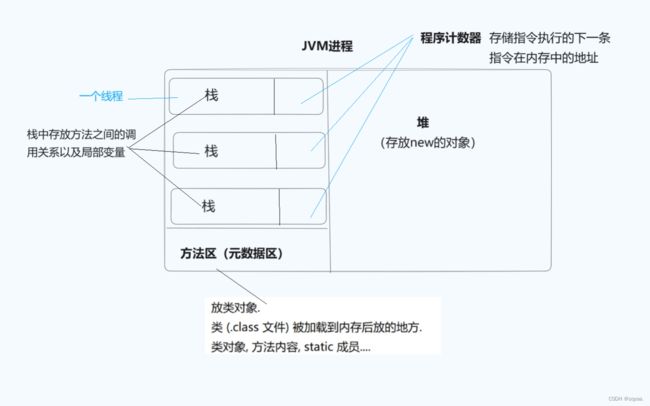 程序计数器
程序计数器
在JVM线程私有的内存区域中。每个线程都有自己独立的程序计数器。
程序计数器用于存储当前线程正在执行的字节码指令的地址。指示着当前线程执行到了哪一条字节码指令。
堆
是线程共享的区域,用于存储对象的实例和数组对象;
是动态分配内存的地方,并通过垃圾回收机制(分代回收)来管理内存资源,提供了灵活的内存分配和回收机制。
虚拟机栈
- 虚拟机栈是用于执行Java方法的线程内存区域。
- 每个线程在执行Java方法时,都会创建一个对应的栈帧并将其推入虚拟机栈中。(每个栈中有多个栈帧,但是每个栈中只能有一个活动栈帧,对应当前正在执行的方法。当栈帧出栈,内存就会释放)
- 虚拟机栈主要用于存储方法调用的相关信息,包括局部变量表、操作数栈、动态链接、方法返回地址等。
- 虚拟机栈的大小可以通过JVM参数进行配置,它的大小限制着方法的嵌套调用深度。
方法区
- 是线程共享的内存区域,主要存储类的信息和运行时常量池。方法区在虚拟机加载时创建,关闭时销毁。
- 在较早的JDK版本中,方法区是通过永久代(Permanent Generation)来实现的,使用固定大小的内存空间。从JDK 8开始,永久代被元空间(Metaspace)所取代。元空间不再使用固定大小的内存,而是使用本地内存。它可以根据应用程序的需要动态地分配和扩展内存。
- *当类被加载,它的常量池信息就会被放入运行时常量池,并把里面的符号由字符引用改成直接引用。
jvm类加载机制
Java 程序最开始写的是.java 文件.编译成 .class 文件,字节码运行 java 程序,JVM 就会读取 class 文件,把文件的内容,放到内存中,并且构造成.class 对象。即把硬盘的类加载到内存。
类加载器:jvm只会运行二进制文件,类加载器就是将字节码文件加载到jvm,让java程序能够运行起来。
流程
加载:将 .class 文件找到,读取文件内容。
加载过程由类加载器负责完成。类加载器首先会定位并打开文件,然后读取文件内容,并将其转换成JVM能够理解的数据结构。加载阶段仅仅是将类的二进制数据加载到内存中
验证:根据JVM虚拟机规范,验证 .class 文件的格式是否符合要求。
包括检查类文件的格式、语义等。验证阶段的主要目的是保证安全性和完整性,防止恶意代码或错误的字节码被执行。
准备:给类对象分配空间,此时内存初始化为0,静态成员也就设置为0值了。
解析:针对字符串常量进行初始化,将 字符引用 转为 直接引用 。
直接引用是具体的地址,字符引用是相对位置(偏移量)符号引用此时 .class 文件中不知道字符串真实的内存地址是在哪里的,只能知道一个相对的偏移量~~知道字符串的内容在 .class 文件的哪个地方。即文件偏移量转换成真实的地址。
等到把字符串内容加载到内存之后就可以把真实的地址,替换到刚才的符号引用这里了。初始化:真正将类对象里面的内容初始化,加载父类,执行静态代码块里面的代码。并且类加载是懒汉模式,需要用到的时候会被加载;
类加载的时机!
双亲委派模型
描述类加载过程如何找到.class文件。
1.jvm在加载.class文件时会用到类加载器,jvm自带三个,我们也可以自定义类加载器Bootstrap ClassLoader:负责加载标准库中的类(Java规范,要求提供的哪些类)
Extension ClassLoader:负责加载JVM扩展库中的类(规范之外的由JVM厂商/组织提供的类,提供额外的功能)
Application ClassLoader:负责加载用户提供的第三方库/用户项目代码 中的类
这三个类存在着父子关系,不是继承中的关系,是相当于每个类加载器有一个parent属性,指向自己的父 类加载器
2.流程:
当一个类需要被加载时,首先会委托给父类加载器进行加载。这个过程会一直往上层委派,直到达到最顶层的启动类加载器(Bootstrap Class Loader)为止。如果父类加载器找不到该类,才会由当前类加载器自己去加载。最终到最底层的第三方库(Application ClassLoader)也没找到就抛出异常。
3.优点:
明确了加载优先级,避免了类的重复加载,提高了加载效率,并确保了类的安全性。这个模型不仅适用于Java类的加载,还适用于JVM核心类库和资源文件的加载,从而保证了JVM的稳定运行。
4.类加载时机:
懒汉模式.用到了才加载
1.构造类的实例.
2.使用了类的 静态方法/静态属性
3.子类的加载会触发父类
5.类卸载是什么?
大多数情况下,类一旦加载就会一直存在于内存中,直到应用程序退出。但是,在某些特定的情况下,类卸载可能会发生。使用类加载器动态加载类时,可以通过卸载类的方式释放内存。例如,在一些插件化的框架或者热部署的应用中,当不再需要某个插件或模块时,可以对其对应的类进行卸载。或者服务器的热补丁,不重启将类卸载,然后替换掉。

GC回收机制
1.引入
以前我们学习的c语言中的malloc函数,如果不手动free就会造成内存泄漏的问题,对于服务器这种24小时工作的,如果申请的内存一直不释放,后续申请的都是剩下的内存久而久之,内存就没了,进程就会出现严重的bug。C++就引入了智能指针来解决这个问题。而Java使用垃圾回收机制(自动去判定某个内存是否会继续使用,如果不会就把这个内存当作垃圾),对于c++这种追求性能的,就没有引入垃圾回收机制,因为引入垃圾回收机制就会有额外的系统开销,甚至可能会影响程序的效率,stw问题(stop the world:就是将当前工作线程挂起,等垃圾回收完成,才让工作线程继续工作->导致程序卡顿)。
介绍
GC(Garbage Collection)指的是垃圾回收(堆),是一种自动内存管理机制。在程序运行过程中,GC会自动跟踪和标记不再使用的对象,并释放其占用的内存空间,以确保程序能够正常运行。
GC的实现通常采用可达性分析算法:从程序的根对象(如全局变量、局部变量、静态变量等)开始,递归遍历所有通过引用相互连接的对象,标记所有可达的对象,然后将未被标记的对象视为垃圾进行回收。
GC的好处是可以减少手动内存管理的工作量,避免内存泄漏和悬挂指针等问题,提高程序的健壮性和安全性。但是,GC也会对程序性能产生一定的影响,因此需要合理地调 整GC策略和参数,以平衡内存使用和性能。
2.判定垃圾
2.1 引用计数
Python,JavaScript等,使用引用计数来自动释放不再使用的内存。
引用计数的基本原理:在每个对象上维护一个计数器,记录当前有多少个引用指向该对象。当一个对象被引用时,计数器加1;当一个引用停止引用该对象时,计数器减1。当计数器的值为0时,表示没有引用指向该对象,即该对象不再被使用,可以安全地释放其占用的内存。
引用计数的优点:
- 1. 实时性:引用计数可以立即知道一个对象是否不再被引用,从而可以立即释放内存,避免内存泄漏问题。
- 2. 简单高效:引用计数是一种轻量级的内存管理技术,不需要后台的垃圾回收程序,也不会产生停顿时间。计数器的增减操作是非常快速的。
局限性:
- 1. 循环引用:如果存在循环引用的情况,即两个或多个对象互相引用,那么它们的计数器都不会变为0,导致内存泄漏。为了解决这个问题,需要引入其他的垃圾回收机制,如标记-清除算法或引用追踪算法。
class Test { Test t = null; } class T { public static void main(String[] args) { // a 指向的对象为对象1; b指向的对象为对象2 Test a = new Text(); //对象1 计数器为1 Test b = new Text(); //对象2 计数器为1 a.t = b;// 对象2 计数器为2 b.t = a;// 对象1 计数器为2 a = null;// a指向断开 对象1计数器-1 为1 b = null;// b指向断开 对象2计数器-1 为1 } }- 2. 计数器维护开销,内存空间浪费:每次引用的增减操作都需要修改计数器的值,这涉及到原子操作和线程同步的开销。对于高并发的程序或多线程环境,引用计数可能会成为性能瓶颈。
2.2 可达性分析
java中的所有对象,都是通过类似上述的关系,通过链式/树形结构串起来的
可达性分析:是把所有的对象被组织的结构视为树,从根节点出发,遍历树,所有能被访问到的树,就标记为"可达",不能被访问的就是不可达,JVM将不可达的对象回收
可达性分析需要进行类似树的遍历的操作,相比于引用计数来说慢一些,但是可达性分析并不是一直进行的,只需要隔一段时间,分析一次,回收一次就可以了
进行可达性分析的起点,叫GCroots,栈上的局部变量,常量池中的对象,静态成员是变量,一个代码中有很多这样的起点,把每个起点都往下遍历一遍
3.清除垃圾
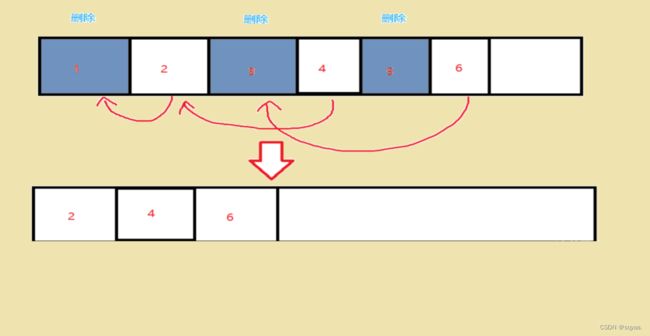
3.1 标记清除
先标记出需要回收的对象,在标记完成之后统一回收所有被标记的对象。
缺点:带来了内存空间碎片问题,这些被释放的内存是零散的,细碎的空间,申请时大内存会申请失败
3.2 复制算法
"复制"算法是为了解决"标记-清理"的碎片化问题,它将可用内存按容量划分为大小相等的两块,每次只使用其中的一块.当这块内存需要进行垃圾回收时,会将此区域还存活着的对象复制到另一块上面,然后再把已经使用过的内存区域一次清理掉。这样做的好处是每次都是对整个半区进行内存回收,内存分配 时也就不需要考虑内存碎片等情况,只需要移动堆顶指针,按顺序分配即可。优点:不用考虑内存碎片化问题,此外,由于只复制存活的对象,不需要对所有对象进行遍历,从而减少了垃圾回收的时间开销。
缺点:
1.空间利用率也比较低,因为只有一半的空间用于存储活动对象,另一半的空间在每次回收后都是空闲的。此外,在大规模存活对象的情况下,复制算法可能会浪费时间和空间,因为需要复制大量的存活对象。
2.并且如果可回收对象少,那么复制的成本也很高
3.3 标记整理
保证了空间利用率.也解决了内存碎片问题
缺点就是如果要搬运的元素很多那么开销也是很大的
每种做法都有优缺点
3.4 分代回收
分代回收根据了一个经验规律:如果一个东西,存在的时间比较久,那么大概率还会继续长时间的存在下去。
上面的这个规律对于Java的对象也是有效的(又一系列的实验和论证)
所以,就给对象引入了一个“年龄”的概念,它的单位为 熬过GC的轮次
每经历一次GC,没有被回收,就会 +1岁
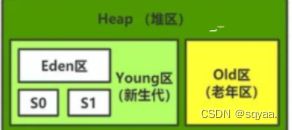
根据上面的规律,分代回收会将堆分为一系列区域。
首先是分为两个区域,一块是新生代默认占比1/3,一块是老年代默认占比2/3。
新生代又非分为一个伊甸区和两个幸存区,其中伊甸区占有空间较多,幸存区占有空间较少,并且两个幸存区的空间大小相同,默认占比为8:1:1。
如下图:
在伊甸区中,存放的是新进来的对象,也就是年龄为0的对象。
当伊甸区的对象经历了一次GC后,没有被回收掉,此时没被回收的对象就进入了幸存区。这个过程使用的是复制算法。
在两个幸存区中,也是使用复制算法来筛选,一个幸存区放对象,另一个滞空。
每当幸存区的对象经过一次GC,存活下来的对象就会转移到另一个幸存区,容纳后来回转换,当达到一定次数后(默认对象到达15岁),就会进入老年区。(复制算法)
在老年代,GC的的频率就比较慢了,如果在老年代被回收了,此时使用的是标记整理的方法进行释放。
