k8s基础内容详解
目录
一、k8s是什么?
二、k8s的优势
1.传统部署
2.docker
三、k8s的特性
四、k8s的架构
1.Master是整个集群的大脑
2.Node节点接受Master安排的任务
3.etcd存储
五、k8s工作流程
前言
比起君子讷于言而敏于行,我更喜欢君子善于言且敏于行。
一、k8s是什么?
是负责自动化运维管理多个容器化程序(比如Docker)的集群,是一个生态及其丰富的容器编排框架工具,是用于自动部署,扩展和管理 "容器化(containerized) 应用程序" 的开源系统。全称kubernetes。
提供了容器编排、资源调度、弹性伸缩、部署管理、服务发现等一系列功能。
二、k8s的优势
1.传统部署
传统的部署方式,将程序包放在服务器上,运行启动脚本。需要定时检查运行状态和日志。部署好之后设置警告和负载均衡来分担服务器的压力。一系列的操作均需要人工介入,无法实现自动化。k8s可以很好的自动实现服务部署、更新、卸载、扩容等。
2.docker
裸跑docker的缺陷:
1)单机使用,无法有效集群;
2)随着容器数量的上升,管理成本攀升;
3)没有有效的容灾,自愈机制;
4)没有预设编排模板,无法实现快速,大规模容器调度;
5)没有同一的配置管理中心工具;
6)没有容器生命周期的管理工具;
7)没有图形化运维管理工具;
而k8s可以有效的解决这些缺陷
三、k8s的特性
1.弹性伸缩
根据cpu的使用情况,自动快速的进行扩容、缩容。既能在高并发的时候保障可用姓,又能在业务较少时回收资源,节约成本。
2.自我修复
在节点故障时重新启动失败的容器,替换和重新部署,保证预期的副本数量。
杀死健康检查失败的容器,并且在未准备好之前不会处理客户端请求,确保线上服务不中断。
3.服务发现和负载均衡
k8s为多个容器提供一个统一访问入口(内部IP地址和一个DNS名称),并且负载均衡关联的所有容器,使得用户无需考虑容器IP问题。ingress是整个k8s集群的接入层,负责内外通讯。
4.自动发布(默认滚动发布模式)和回滚
k8s采用滚动更新策略更新应用,一次更新一个pod,而不是删除所有pod。
如果更新过程中出现问题,将回滚更改,确保升级不影响业务。
5.集中化配置管理和密钥管理
管理机密数据和应用程序配置,而不需要把敏感数据暴露在镜像里,提高敏感数据安全性。
可以将一些常用的配置存储在k8s中,方便应用程序使用。
6.存储编排,支持外挂存储并对外挂存储资源进行编排
挂载外部存系统,无论是来自本地存储,公有云(如AWS),还是网络存储(如NFS,GFS,Ceph)都作为集群资源的一部分使用,极大提高存储使用灵活性。
7.任务批处理运行
提供一次性任务,定时任务。满足批量数据和分析的场景。
四、k8s的架构
k8s采用的主从模式,Master节点负责集群的调度,管理和运维,Node节点时集群中的运算工作负载节点。
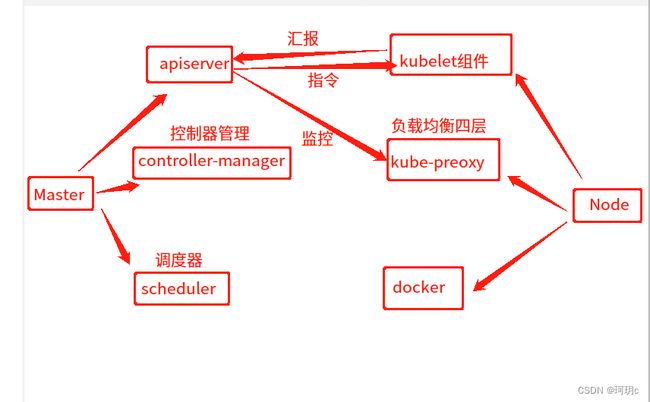
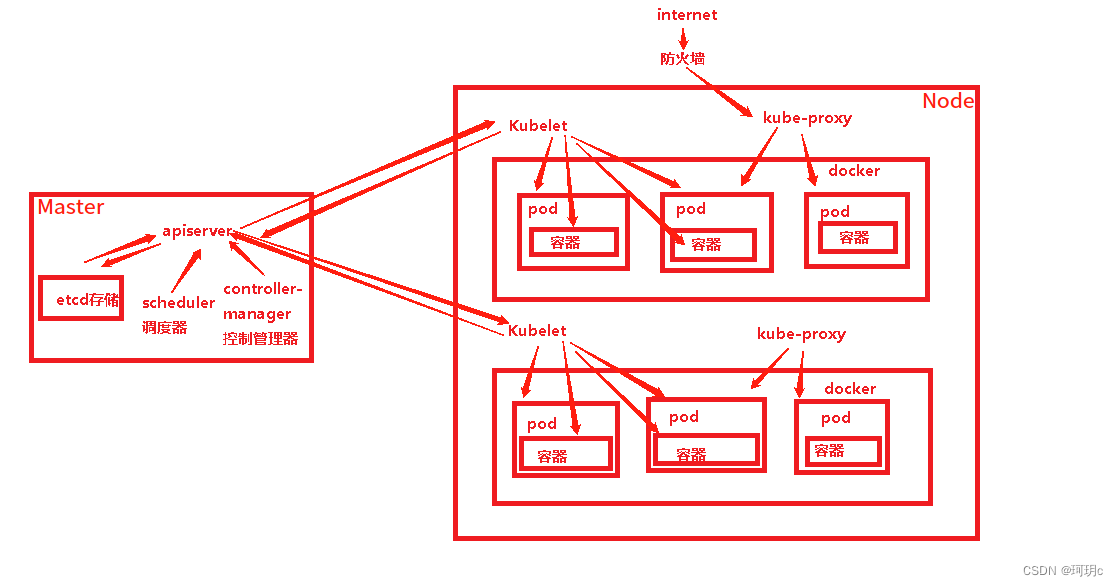
1.Master是整个集群的大脑
建议单独占用一台服务器。一旦宕机,所有的命令和任务全部失效。
a. kube-apiserver
大脑,任何资源请求,调用操作,都用通过apiserver,是k8s的请求入口服务。接收k8s的所有请求,根据请求去调度其他组件。
b. kube-controller-manager (控制-管理)
运行管理控制器,是k8s集群里所有资源对象的自动化控制中心。k8s中一个资源对应一个控制器,而controller manager 就是负责管理这些控制器的。比如某个node宕机时,kube-controller-manager会执行修复
主要的控制器有:
| 名称 | 中文名 | 作用 |
| Node Controller | 节点控制器 | 负责在节点出现故障时发现和响应 |
| Replication Controller | 副本控制器 | 负责保证集群中一个RC(资源对象Replicaion Contraller)所关联的Pod副本数始终保持在预设值。可以理解成确保集群中有且仅有N个Pod实例,N是RC中定义的Pod副本数量 |
| Endpoints Controller | 端点控制器 | 填充端点对象(即连接Services和Pods),负责监听Service和对应Pod副本的变化。可以理解端点是一个服务暴露出来的访问点,如果需要访问一个服务,则必须知道它的endpoint |
| Service Accont && Token Controllers | 服务账户和令牌控制器 | 为新的命名空间创建默认账户和API访问令牌。 |
| ResourceQuota Controller | 资源配置控制器 | 确保指定的资源对象在任何时候都不会超量占用系统物理资源 |
| Namespace Controller | 命名空间控制器 | 管理namespace的生命周期 |
| Service Controller | 服务控制器 | 属于K8S集群与外部的云平台之间的一个接口控制器 |
c. kube-scheduler(调度器)
根据调度算法为新建的pode选择一个合适的Node,可以理解成 K8S 所有 Node 节点的调度器。先使用预算策略(predicate)再使用优选策略(priorities)。
预算策略:将所有node节点的剩余资源和pod所需的资源对比,找出符合pod资源需求的node节点 优选策略:预算策略筛选后的node节点被交给优选策略。通过cpu负载,内存剩余等因素,找出最合适的node节点。
2.Node节点接受Master安排的任务
有多个Node节点,当某一个宕机时,Master的工作负载会将这个节点上的任务转移到另一个节点上。
a. kubelet组件
1)监视Node与Master通信,与apiserver汇报node的状况。
2)从Master上获取自己节点上的Pod期望状态(比如运行什么容器、运行的副本数量、网络或者存储如何配置等),与容器引擎交互实现容器的生命周期管理,如果自已节点上Pod 的状态与期望状态不一致,则调用对应的容器平台接口 (即 docker 的接口)达到这个状态。
3)管理镜像和容器的清理工作,保证节点上镜像不会占满磁盘空间,退出的容器不会占用太多资源
b. kube-proxy组件(代理)
在 K8S 集群中微服务的负载均衡是由 Kube-proxy 实现的,是 K8S 集群内部的负载均衡器。它是一个分布式代理服务器,在 K8S 的每个节点上都会运行一个 Kube-proxy 组件。
1)在每个Node节点上实现pod网络代理,负责维护网络规则和四层负载均衡,写入规则至iptables、ipvs实现服务映射访问。
2)pod的网络是由Kubelet提供的,不是kube-proxy组件提供,实际上维护的是虚拟的pod集群网络
3)Master上的kube-apiserver会监控kube-proxy进行对service的更新和端点的维护
c. docker或rocket
运行容器,负责本机的容器创建和管理工作。
3.etcd存储
k8s中的存储服务,分布式键值存储系统,存储了k8s的关键配置和用户配置。
只有apiserver才具有读写的权限。其他的组件必须通过apiserver的借口才能读写数据。
五、k8s工作流程
第一步:客户端发送请求到唯一入口apiserver,apiserver将请求内容写入etcd存储中。
第二步:controller-manager控制管理器通过apiserver读取etcd里面的用户请求,根据请求去设置模板(eg:什么镜像,多少个pod,健康检查等),将模板通过apiserver写入到etcd中。根据这个模板去创建pod
第三步:controller-manager控制管理器通过apiserver去找到scheduler调取器调度pod,给上一步新创建的pod选择一个Node节点
第四步:scheduler通过apiserver去etcd中去读Node节点的资源信息。通过预算和优选策略,挑一个最优的Node节点
第五步:scheduler确定了调度的节点之后,通过apiserver找对应的node节点上的kubelet,由kubetel去创建pod。 kublet监控node节点上的资源信息,pod状态。将这些通过apiserver存储到etcd中
第六步:kube-proxy创建网络规则,制定转发规则,创建service,将用户的请求负载均衡转发到关联的pod上
学习文章来源:kubernetes(k8s)架构和组件,工作流程 ,资源_51CTO博客_k8s架构