【重学C++基础知识笔记】详细版
基础
常量
C++ 中有两种简单的定义常量的方法:
- 使用
#define,如:#define PI 3.1415926; - 使用
const, 如:const double PI = 3.1415926;
注明:
尽量使用const定义变量,#define不会出现在编译器期
#define ASPECT RATIO 1.653 // 在编译时出错,很难排错
const double ASPECT_RATIO = 1.653; // 在编译时出错,可以排错
整数常量
整数常量可以是十进制、八进制或十六进制的常量。
前缀指定基数:0x或0X表示十六进制,0表示八进制,不带前缀则默认表示十进制。
整数常量也可以带一个后缀,后缀是U和L的组合,U表示无符号整数(unsigned),L表示长整数(long)。后缀可以是大写,也可以是小写,U和L的顺序任意。
字符常量
字符常量是括在单引号中。如果常量以 L(仅当大写时)开头,则表示它是一个宽字符常量(例如L'x'),此时它必须存储在wchar_t类型的变量中。否则,它就是一个窄字符常量(例如'x'),此时它可以存储在char类型的简单变量中。
字符常量可以是一个普通的字符(例如'x')、一个转义序列(例如'\t'),或一个通用的字符(例如'\u02C0')。
转义字符:

C语言移位问题
问题表现:
- 逻辑右移还是算术右移
- 移位操作位数的限制
问题原因:
- C 在设计移位操作时需要考虑整数表示的上下文环境
好的方案:
- 1)右移只对无符号数;
- 2)移位数大于
0,小于位数;
C++ 中的解决方案:
bitset的使用
C 语言强制类型转换问题
问题表现:
-
隐藏的bug和陷阱
-
滥用类型转换可能导致灾难性后果,且很难排查
问题原因:
- 类型转换在底层语言中的运用很广泛,灵活方便
C++中的解决方案:
- 分类便于排查隐藏bug,复杂性鼓励减少使用
static_cast,const_cast,dynamic_cast,reinterpret_cast
C语言整数溢出问题
问题表现:
- C语言中的整数不等于数学上的整数
问题原因:
- 和系统的设计有关系
C++中的解决方案:
- 扩展库的使用,如使用boost库中的
cpp_int类型计算可以避免大数溢出问题。
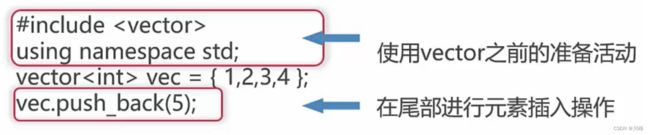
C++中的新型数组 - vector
Vector尾部添加操作:

使用vector容器,轻松实现动态扩容插入元素,传统的 C 数组,容量有限,vector可以动态管理扩容;
Vector的遍历操作:
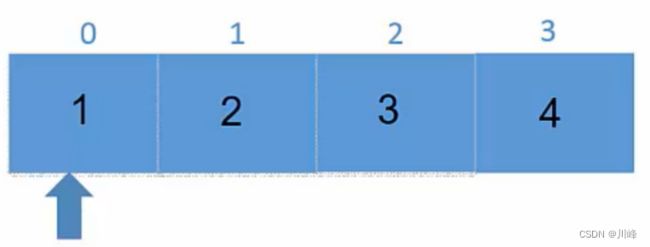
for (int index = 0; index < vec.size(); ++index) {
cout << vec[index] <<endl;
}
注意:可以使用Vector的capacity和size方法来查看vector当前的容量和 已经存储的元素个数。
Vector是面向对象方式的动态数组,使用最简单的数组,无法实现动态扩容插入元素,因为容量有限。
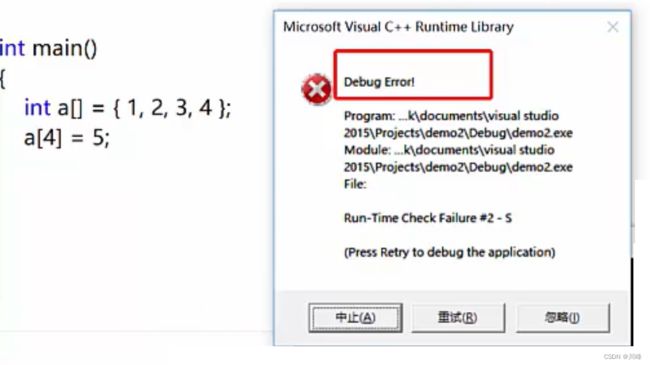
Vector的插入操作:


Vector的删除操作:

字符串相关
字符串变量与常量
字符串变量
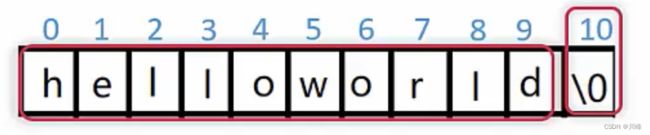
- 字符串是以空字符(
'\0')结束的字符数组 - 空字符
'\0'自动添加到字符串的内部表示中 - 在声明字符串变量时,应该为这个空结束符预留一个额外元素的空间,如:
char str[11] = {"helloworld"};
字符串常量
- 字符串常量是一对双引号括起来的字符序列
- 字符串中每个字符作为一个数组元素存储
- 例如字符串
"helloworld"
关于字符表示的说明
0、'\0'、'0' 在计算机内部的机器码表示:

ASCII 码表
ASCII (American Standard Code for Information Interchange,美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言。
它是最通用的信息交换标准,并等同于国际标准 ISO/IEC 646。
ASCII 码使用指定的 7 位或 8 位二进制数组合来表示128或256种可能的字符。
编码表可以参考:https://baike.baidu.com/item/ASCII/309296?fr=aladdin;
0x41(十进制65)对应 ‘A’;0x30(十进制48)对应字符 ‘0’;
0x61(十进制97)对应 ‘a’;0x7F(十进制127)对应字符DEL;
Unicode 编码:最初的目的是把世界上的文字都映射到一套字符空间中
为了表示 Unicode 字符集,有3种(确切的说是5种)Unicode 的编码方式:
- UTF-8:
1byte来表示一个字符,可以兼容ASCII码;特点是存储效率高,变长(不方便内部随机访问),无字节序问题(可作为外部编码) - UTF-16:分为 UTF-16BE(big endian)和 UTF-16LE (little endian),用
2bytes表示一个字符,特点是定长(方便内部随机访问),有字节序问题(不可作为外部编码) - UTF-32:分为 UTF-32BE(big endian)和 UTF-32LE (little endian) ,用
4bytes表示一个字符,特点是定长(方便内部随机访问),有字节序问题(不可作为外部编码)
Windows 的文件可能 有BOM(byte order mark),如要在其他平台使用,可以去掉 BOM
编码错误的根本原因在于编码方式和解码方式的不统一。
字符串的指针表示方法
指针表示方法:
char* p = "helloworld";
char[] 和 char* 的区别,把握两点:
-
地址和地址存储的信息;
-
可变与不可变;
如:
char str[11] = {
"helloworld"};
str不可变,str[index]的值可变
char* p = "helloworld";
p可变,但是p[index]的值可变可不变,取决于所指区间的存储区域是否可变
字符串的常见操作
字符串基本操作
- 字符串长度:
strlen(s)返回字符串s的长度;

-
字符串比较:
strcmp(s1, s2)
如果s1和s2是相同的,则返回0;
如果s1 < s2则返回值小于0;
如果s1 > s2则返回值大于0;两个字符串自左向右逐个字符相比(按ASCII值大小相比较),直到出现不同的字符或遇
'\0'为止。如:"A"<"B ";"A"<"AB";"Apple"<"Banana"; “A”<“a” ; “compare”<“computer”; -
字符串拷贝:
strcpy(s1, s2)复制字符串s2到字符串s1

-
其他字符串操作:
- 复制指定长度字符串:
strncpy(s1, s2, n)将字符串s2中前n个字符拷贝到s1中(s1的容量必须能够容纳s2) - 查找字符串:
strchr(s1, ch)指向字符串s1中字符ch的第一次出现的位置 - 查找字符串:
strstr(s1, s2)指向字符串s1中字符串s2的第一次出现的位置
- 复制指定长度字符串:
注:请使用strnlen_s, strcpy_s, strncpy_s,strcat_s等API函数,更安全!
字符串长度获取示例:
int getlength(char *string)
{
int count = 0;
while (*string) // 遇到 \0 退出
{
string++;
count++;
}
return count;
}
int main() {
char string[] = {
'a', 'b', 'c', 'd', '\0'};
printf("长度-----%d\n", getlength(string)); // 4
// 这种不能在函数参数为数组的时候使用,数组作为函数参数时,会变成指针,而指针的长度是8(64位),计算会出问题
// printf("长度-----%d\n", sizeof(string) / sizeof(char)); // 5 会把 \0 计算在内
printf("长度-----%d\n", strlen(string)); // 4 系统函数
}
字符串拷贝和拼接示例:
const int MAX_LEN_NUM = 16;
int main() {
char str1[] = {
"hello"};
char str2[] = {
"world1"};
char str3[MAX_LEN_NUM] = {
0};
strcpy(str3, str1); // hello
strncpy(str3, str2, 2); // wollo
strcat(str3, str2); // wolloworld1
int len = strlen(str3);
for (int index = 0; index < len; ++index) {
cout << str3[index] <<"";
}
cout << endl;
}
const int MAX_LEN_NUM = 16;
const unsigned int STR_LEN_NUM = 7;
const unsigned int NUM_TO_COPY = 2;
int main() {
char str1[] = {
"hello"};
char str2[STR_LEN_NUM] = {
"world1"};
char str3[MAX_LEN_NUM] = {
0};
strcpy_s(str3, MAX_LEN_NUM, str1); // hello
strncpy_s(str3, MAX_LEN_NUM, str2, NUM_TO_COPY); // wo
strcat_s(str3, MAX_LEN_NUM, str2); // woworld1
unsigned int len = strnlen_s(str3, MAX_LEN_NUM);
for (int index = 0; index < len; ++index) {
cout << str3[index] <<"";
}
cout << endl;
}
字符串比较示例:
int main() {
char *str1 = "abc";
char *str2 = "ABC";
int result1 = strcmp(str1, str2); // 返回0表示相等
int result2 = strcmpi(str1, str2); // 不区分大小写
printf("strcmp result1 > %d\n", result1); // 1
printf("strcmpi result2 > %d\n", result2); // 0
}
字符串查找示例:
int main() {
// 字符串查找
char *text = "abcddhhhhhhfg";
char *subText = "hh";
char *result3 = strstr(text,subText); // 查找到返回字符串,否则返回NULL
printf("strstr-------------%s\n", result3);
printf("strstr index-------------%d\n", (result3 - text));
}
另外,由于系统没有提供strsub的API,下面代码提供了几种实现strsub的参考方式:
#include 字符串修改注意问题:
int main() {
char str[] = {
'a', 'b', 'c', '\0'}; // “abc”存放在全局静态区,会从静态区拷贝到栈区操作,str指向栈区空间的地址
str[1] = 'z';
printf("%s\n", str);
char *str2 = "abc"; // str2 直接指向的存放“abc”静态区的地址,拒绝修改
str2[1] = 'z'; // 不能这样修改,这种会崩溃
printf("%s", str2);
}
字符串转换成整数、浮点数示例:
int main() {
char *num = "1234";
int res = atoi(num); // 系统函数 字符串转整数
printf("res----%d\n", res);
char *doublestr = "12.34";
printf("--------%f\n", atof(doublestr));
}
字符串大小写转换:
#include 字符串操作中的缓冲区溢出问题
C 中原始字符串的操作在安全性和效率存在一定的问题:
缓冲区溢出问题举例:
// char str1[11] = {"helloworld"};
char str2[11] = {
'h', 'e', 'l', 'l', 'o', 'w', 'o', 'r', 'l', 'd', '\0'};
strcat(str2, "Welcome to C++'s world");
cout << " str2 = "<< str2 << endl;
问题点:
str2定义的长度是11,这意味着str2中的字符数组只能容纳11个字符(包括字符串终止符\0),而不足以容纳要追加的字符串 “Welcome to C++'s world”。strcat函数会尝试将第二个字符串追加到第一个字符串的末尾,但它不会检查目标字符串是否具有足够的空间来容纳要追加的内容。如果目标字符串的空间不足,strcat可能会导致缓冲区溢出(buffer overflow),这是一种常见的安全漏洞。
为了避免问题,应该确保目标字符串(str2)具有足够的空间来容纳要追加的内容。可以使用 strncat 函数,并提供要追加的字符串的最大长度,以避免溢出。例如:
int main() {
// 小心缓冲区溢出问题
char str2[100] = {
'h', 'e', 'l', 'l', 'o', 'w', 'o', 'r', 'l', 'd', '\0'};
// strcat(str2, "Welcome to C++'s world");
strncat(str2, "Welcome to C++'s world", sizeof(str2) - strlen(str2) - 1);
cout << " str2 = "<< str2 << endl;
}
strlen的效率可以提升:空间换时间- Redis 字符串的设计:https://redis.io/

C++中的新型字符串 - string 类
C++ 标准库 STL 中提供了 string 类型专门表示字符串。STL string 类和 Java String 类很像。不过,STL的string类其实只是模板类 basic_string的 一个实例化产物,STL 为该模板类一共定义了四种实例化类,如下。
| Type | Definition |
|---|---|
std::string |
std::basic_string |
std::wstring |
std::basic_string |
std::u16string |
std::basic_string |
std::u32string |
std::basic_string |
-
如果要使用其中任何一种类的话,需要包含头文件
-
string对应的模板参数类型为char,也就是单字节字符。而如果要处理像UTF-8/UTF-16这样的多字节字符,可酌情选用其他的实例化类。
使用string可以更为方便和安全的管理字符串和定义字符串变量:
#include 字符串相关函数
获取字符串的长度:
string s1 = "helloworld";
cout << s1.length() <<endl; // 10
cout << s1.size() << endl; // 10 本质和上面一样
cout << s1.capacity() << endl; // 15
cout << s1.empty() << endl; // 0
s1.clear(); // 清空,长度变为0
字符串比较:==、!=、>、>=、<、<=
string s1 = "hello", s2 = "world";
cout << (s1 == s2) << endl; // 0
cout << (s1!= s2) << endl; // 1
字符串的常用操作
转换为C风格的字符串:
string s1 = "helloworld";
const char *c_str1 = s1.c_str();
cout << "c_str1 = " << c_str1 <<endl;
随机访问(获取字符串中某个字符):[]
string s = "hello";
s[0] = 'w';
cout << s << endl; // wello
char c = s[3];
字符串遍历:
string s = "helloworld";
for (auto ch : s) {
cout << ch << endl;
}
字符串拷贝:=
string s1 = "hello";
string s2 = s1;
字符串连接:+、+=
string s1 = "hello";
string s2 = "world";
string s3 = s1 + s2;
s1 += s2;
cout << s3 << endl; // helloworld
cout << s1 << endl; // helloworld
字符串查找:
string s1 = "helloworld";
auto index = s1.find("wor");
cout << index << endl; // 5
cout << s1.substr(2, 3) << endl; // llo
总结:string结合了C++的新特性,使用起来比原始的 C 风格方法更安全和方便对性能要求不是特别高的场景可以使用。
指针相关
指针的定义和间接访问操作
指针定义的基本形式:指针本身就是一个变量,其符合变量定义的基本形式,它存储的是值的地址。对类型T,T*是 “到T的指针” 类型,一个类型为T*的变量能保存一个类型T的对象的地址。
如:
int a = 112;
int* d = &a;
float c = 3.14;
float* e = &c;
通过一个指针访问它所指向地址的过程称为间接访问(indirection)或者引用指针(dereferencing the point);这个用于执行间接访问的操作符是单目操作符*:
如:
cout << (*d) << endl;
cout << (*e) << endl;

C++中内存单元内容与地址
关于变量,地址和指针变量小结:
-
一个变量有三个重要的信息:
- A.变量的地址位置;
- B.变量所存的信息;
- C.变量的类型;
-
指针变量是一个专门用来记录变量的地址的变量;通过指针变量可以间接的访问另一个变量的值;
几种C++中的原始指针
1. 一般类型指针 T* ,T是一个泛型,泛指任何一种类型,如:
int i = 4;
int* iP = &i;
cout << (*iP) << endl;
double d = 3.14;
double *dP = &d;
cout << (*dP) << endl;
char c = 'a';
char* cP = &c;
cout << (*cP) <<endl;
2. 指针的数组(array of pointers)与数组的指针(a pointer to an array):
- 指针的数组
T* t[] - 数组的指针
T(*t) []
如:
int* a[4];
int(*b)[4];
注意:[] 优先级比较高
// array of pointers 和 a pointer to an array
int c[4] = {
1, 2, 3, 4};
int* a[4]; // array of pointers 指针的数组
int(*b)[4]; // a pointer to an array 数组的指针
b = &c; // 注意:这里数组个数得匹配
// 将数组 c 中元素赋给数组 a
for (int i = 0; i < 4; i++) {
a[i] = &(c[i]); // 输出看下结果
}
cout << *(a[0]) << endl; // 1
cout << (*b)[3] << endl; // 4
简单的理解:指针的数组是指一个数组中存储了若干个指针,即数组的每一个元素是一个指针,每个指针都指向了内存中的一个变量;而数组的指针是指一个单独的指针变量,该指针指向数组的起始地址,可以代替数组访问数组中的元素。
3. const pointer 与 pointer to const
char str[] = {
"helloworld"};
char const *p1 = "helloworld";
char* const p2 = "helloworld";
char const * const p3 = "helloworld";
p1 = str; // 编译成功,p1 的指向可以修改
p1[2] = 'a'; // 编译报错,p1 指向的内容不能修改
p2 = str; // 编译报错,p2 的指向不可以修改
p2[2] = 'h'; // 编译成功,p2 指向的内容可以修改
p3 = str; // 编译报错,p3 的指向不可以修改
p3[3] = 'y'; // 编译报错,p3 指向的内容不可以修改
法则:看const修饰的右边是什么类型,该类型不可修改。
char const *p1右边是*p1则*p1即内容不能改,但p1本身指向可以改char* const p2右边是p2则p2指向不能改,但*p2即内容可以改char const * const p3分成两部分看:const *右边带*说明内容不能改,const p3右边是指针p3说明p3指向不能改
4. 指向指针的指针
例子:
int a = 123;
int* b = &a;
int** c = &b;
*操作符具有从右向左的结合性**这个表达式相当于*(*c),必须从里向外逐层求值;*c得到的是c指向的位置,即b;**c相当于*b,得到变量a的值;
开发中
*号比较多时尽量使用括号
5. 未初始化和非法的指针
例子:

运气好的话:定位到一个非法地址,程序会出错,从而终止。
最坏的情况:定位到一个可以访问的地址,无意间修改了它!这样的错误难以捕捉,引发的错误可能与原先用于操作的代码完全不相干!
用指针进行间接访问之前,一定要非常小心,确保它已经初始化,并被恰当的赋值。
6. nullptr指针
一个特殊的指针变量,表示不指向任何东西。如:
int *a = nullptr;
nullptr指针的概念非常有用:
- 它给了一种方法,来表示特定的指针目前未指向任何东西。
int a = 123;
int *p = nullptr;
p = &a;
// ...假设间隔了一万行业务代码
if (p != nullptr) {
// 使用前判断是否为 nullptr
cout << (*p) << endl;
}
p = nullptr; // 不用时置为 nullptr
使用的注意事项:
- 对于一个指针,如果已经知道将被初始化为什么地址,那么请赋给它这个地址值,否则请把它设置为
nullptr。 - 在对一个指针进行间接引用前,请先判断这个指针的值为否为
nullptr。
7. 杜绝“野”指针
“野”指针是指向“垃圾”内存的指针。if等判断对它们不起作用,因为没有置NULL;
一般有三种情况:
- 指针变量没有初始化;
- 已经释放不用的指针没有置
NULL,如delete和free之后的指针; - 指针操作超越了变量的作用范围。
指针使用的注意事项:
- 没有初始化的,不用的或者超出范围的指针请把值置为
NULL。
原始指针的基本运算
& 和 * 操作符:

++ 和 -- 操作符:
代码的内存布局

代码和数据在C++程序中的存储:
堆heap
动态分配资源——堆(heap):
-
从现代的编程语言角度来看,使用堆,或者说使用动态内存分配,是一件很自然不过的事情。
-
动态内存带来了不确定性:内存分配耗时需要多久?失败了怎么办?在实时性要求比较高的场合,如一些嵌入式控制器和电信设备。
-
一般而言,当我们在堆上分配内存时,很多语言会使用
new这样的关键字,有些语言则是隐式分配。在C++中new的对应词是delete,因为C++是可以让程序员完全接管内存的分配释放的。
分配和回收动态内存的原则
程序通常需要牵涉到三个内存管理器的操作:
- 分配一个某个大小的内存块;
- 释放一个之前分配的内存块;
- 垃圾收集操作,寻找不再使用的内存块并予以释放;
这个回收策略需要实现性能、实时性、额外开销等各方面的平衡,很难有统一和高效的做法;
C++ 做了 1,2 两件事;而 Java 则做了 1,3 两件事。
使用 malloc 和 free 进行动态内存开辟和回收
唯一需要注意的一点就是 malloc 和 free 必须成对使用,以避免内存泄漏,因此 C++ 不像Java,没有垃圾回收器自动GC。
参考示例代码:
#include