JVM | 内存调优实战 - MAT工具问题排查与分析
一、引言
在软件开发领域中,稳定性和性能始终是开发者的首要关注点。特别是在Java世界中,内存管理无疑是一个重要的话题,尤其当涉及到内存溢出的问题时。这种情况不仅可能导致应用的崩溃,还可能导致系统的整体性能大幅下滑。
对于Java开发者来说,仅仅理解JVM的内存结构是不够的。更为重要的是,我们需要有实战经验和应对策略来避免这些问题。这些往往也是面试官喜欢切入的地方。本文的目的正是为了深入挖掘JVM常出现的问题,解析其背后的原因,并提供实际的解决方案和技巧,话不多说,我们开始吧~
性能监控经常成为预防生产事故的得力助手,在打出一套检验你故障排查能力连招之前,往往会先试探性的探查你对性能监控的熟练掌握程度。接下来,我们看看应该怎么回答这类问题。
二、性能监控
面试官:你们公司怎么做性能监控?生产出现问题怎么办
候选者:看下Tomcat日志,把日志拿出来…
面试官:?停停停…我们公司可能不太适合你
分布式,微服务大环境大行其道,只用肉眼24小时盯着机器的时代过去了。为了保证服务的持续可用性和高性能,现代公司已经转向了自动化的、全面的监控方案。它是内需,也是一个产品,用于鉴别大型公司和小型公司的指标之一。选择一套合适的监控工具和策略不仅可以及时发现和解决问题,还能为未来的系统优化提供有价值的数据。
排除一些在"自研"方向越走越远的公司。常见的性能监控解决方案如下:
- 数据收集:
使用 Spring Cloud Sleuth 为微服务中的每一个请求生成追踪数据,确保我们能够清晰地看到请求在整个系统中的流动路径。 - 数据存储与可视化:
Zipkin 在这里起到了关键作用,它不仅接收和存储由Sleuth生成的追踪数据,还提供了一个直观的界面来可视化这些数据,帮助我们快速定位性能瓶颈或错误。 - 指标监控:
我们使用 Prometheus 来收集各种系统和应用指标,包括但不限于CPU、内存、磁盘、网络,以及业务相关的指标。 - 数据展示:
Grafana 与 Prometheus 无缝集成,为我们提供了一个强大的、定制化的仪表板,显示关键指标的实时数据。当某些指标超出正常范围时,Grafana也可以触发警报。 - 警报:
通过 Prometheus的 Alertmanager,我们可以定义自己的警报规则,并决定如何通知相关团队——是通过邮件、微信机器人还是其他方式。
限于篇幅,我在这里就不过多展示,将在后续文章中为你介绍。现在会造火箭了吗?咳咳…会说了吗?
候选者:我们采用了一套开源的微服务监控方案,涉及追踪数据收集、数据存储与可视化、系统与应用指标监控、数据展示,以及警报管理。具体地,我们使用Spring Cloud Sleuth为每个微服务请求生成追踪数据;再用Zipkin来接收、存储并可视化这些数据。对于系统和应用指标,我们采用Prometheus进行收集,并通过Grafana进行展示和仪表板创建。当指标达到某些阈值时,我们的Prometheus Alertmanager会发送警报,通知相关团队采取行动。
面试官:很好,这样的方案确保了性能问题能够被及时发现和定位,对于生产环境的稳定性至关重要。
三、MAT使用指南
面试官:生产上出现OOM你怎么解决的?
候选者:远程DEBUG一下,看下哪里报错呗
面试官:(上个用远程DEBUG的公司坟头都长草了吧)?回去等通知
工欲善其事,必先利其器。生产的绝大部分问题,都没办法像本地一样方便,例如内存快照,DEBUG断点,随意压测等等去复现问题。往往需要通过你同事辅助保留现场,遇到一些没办法通过日志和监控问题的时候把一些信息DUMP出来,通过工具进行分析。
Memory Analyzer下载
把大象关进冰箱要几步?少侠,我这里也需要三步,不来试试吗?
- 访问路径:https://eclipse.dev/mat/downloads.php
- 下载1.12.0版本,可以通过
Previous Releases找到历史版本,如下图所示:
根据不同操作系统进行下载
- 打开MAT,会看到Welcome界面,假如你是初学者,不要急着关闭,建议你把Tutorials玩一遍

例如,你可以点开按照它的步骤玩一会,相信你很快就熟悉这个工具了。
满满的Eclipse风,不知道00后程序员习不习惯,哈哈
其它
网上资料五花八门,如果你想要熟悉这个工具,你可以按照上面的Tutorials玩一遍。
或者通过官方文档进行学习:eclipse官方Tutorial 、https://wiki.eclipse.org/MemoryAnalyzer
在更进一步使用MAT之前,先带你熟悉下内存参数
四、JVM内存参数详解
我们通常会看到这样的参数:-Xmx1024m,-XX:SurvivorRatio 等等;可能查阅相关文档后知道它的用法,过一段时间又忘记了,总是反反复复。曾经我也有这样的困惑,直到我掌握了画图工具。参数的作用直接在我的脑海中呈现。话不多说,我们看图说话。
年轻代和老年代
按比例

①Eden(伊甸园)区和Survivor中的From区的比例;
②Old(老年)区和new(新生代)的比例;
按大小
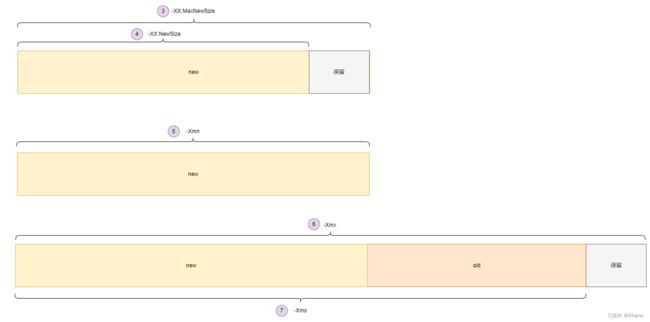
③最大新生代容量大小,单位为m;例如:-XX:MaxNewSize=1024M;它是一个可伸缩的配置。
④去除保留部分的新生代容量大小,同上。
⑤最大新生代容量大小,不可伸缩。即最小和最大等同。单位为m;例如:-Xmn2048m;
⑥新生代+老年代+保留最大容量大小。单位为m;例如:-Xmx4096m;
⑦去除保留部分的容量大小,同上。
元空间

JIT编译缓存
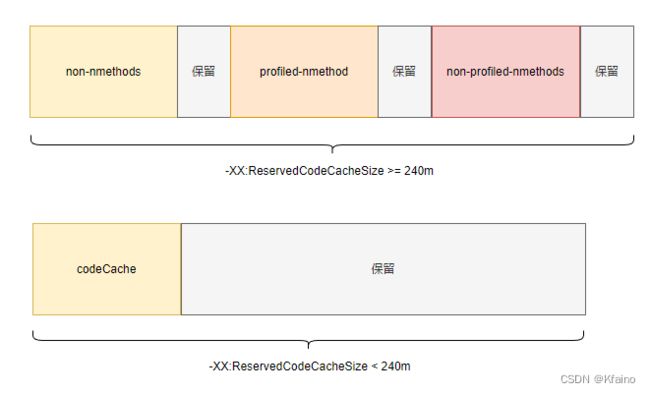
-XX:ReservedCodeCacheSize 用于设置为编译后的代码保留的内存大小。Code Cache是JVM中用于存放即时编译器生成的本地机器代码的区域。当设置小于240m时候,non-nmethods,profiled-nmethods,non-profiled-nmethods被存放在一起。我们IDEA默认设置的值就是240m。我们来看下这三个到底是什么。
关于non-nmethods, profiled-nmethods, 和 non-profiled-nmethods,它们都是Code Cache的区段。JVM(尤其是HotSpot VM)在Java 8和Java 9中进行了一些更改,为Code Cache引入了不同的分段以改进性能和可维护性。
non-nmethods
用于存放不是由即时编译器生成的代码,例如解释器代码和存根。
profiled-nmethods
存放已经进行了简单分析(基于采样)的方法的编译代码。这部分代码是第一次编译的,它包含了插桩代码(profilers)来收集更多关于方法行为的信息。
non-profiled-nmethods
存放未进行分析的方法的编译代码。这些方法通常是第二次(或更多次)编译的,使用了更多的优化技术,但没有插桩代码。它们基于profiled-nmethods中收集的信息进行编译。
为了提高性能,即时编译器可能会多次编译某些热点方法,每次采用更多的优化。这就是为什么有区分“已分析”和“未分析”的编译代码的需要。你可以使用JVM诊断工具(如jcmd)查看Code Cache的使用情况,例如:
jcmd Compiler.codecache
其中
五、内存溢出与其常见原因
内存溢出(out of menory):程序需求的内存,超出了系统所能分配的范围。
内存泄漏(memory leak):不再用到的内存,没有及时释放。
内存溢出是指程序在申请内存时,没有足够的内存供其使用,出现此类错误一般是因为内存中已无空间可供分配。这在JVM中是一个常见的问题。在本章中,我们将详细探讨JVM中可能导致内存溢出的常见原因。
堆内存不足
- 对象过多:如果应用程序创建了大量的长生命周期的对象,堆中可用的内存可能会迅速耗尽。
- 内存泄漏:某些对象无法被GC回收,但它们不再被使用。这些对象占据了堆空间,导致其他新对象无法在堆上分配。
栈溢出
- 递归过深:如果一个方法递归调用自己,并且没有有效的终止条件,那么这个方法的调用栈会不断增长,直到耗尽所有的栈内存。
- 局部变量过多:大量的局部变量和大型数据结构可能会导致栈空间迅速耗尽。
方法区内存不足
- 加载的类过多:如果应用程序或其库加载了大量的类,方法区内存可能会被耗尽。
- 大量的常量:大量的常量,尤其是字符串常量,可能会消耗方法区的内存。
内存溢出的问题可以通过多种工具和技巧进行诊断和解决。在后续章节中,我们将详细讨论这些方法。
六、诊断内存溢出
当你面临一个可能的内存溢出问题时,第一步是确定它确实是内存溢出。接下来,我们将讨论一系列工具和步骤来帮助你诊断和解决这些问题。
JVM日志
启动JVM时,可以使用以下参数来收集有关内存使用情况的信息:
-XX:+PrintGCDetails:此选项将为每次GC打印详细日志。-XX:+PrintGCTimeStamps:此选项将为GC日志添加时间戳。
从GC日志中,你可以看到每次垃圾回收的时间、回收了多少内存以及堆的总大小。频繁的全GC通常是内存压力的一个信号。
堆转储分析
当你怀疑有堆内存溢出时,可以生成堆转储来分析:
- 使用
jmap工具:jmap -dump:live,format=b,file=
堆转储可以使用如Eclipse MAT或VisualVM等工具进行分析,以确定哪些对象占用了最多的内存。
堆转储工具
类似的工具有Java VisualVM和Eclipse MAT,用于监视、分析和调试Java应用程序。它可以显示内存使用、线程活动和方法调用。
硬件和操作系统工具
在某些情况下,问题可能不仅仅在JVM级别。使用像top、vmstat或其他OS级别的工具可以帮助确定整个系统的内存使用情况。
一旦诊断出问题,下一步是采取措施修复它。在接下来的章节中,我们将详细讨论如何解决内存溢出问题。
七、解决内存溢出问题
在确诊了内存溢出后,我们需要立刻行动以解决它。本章将带你走进解决问题的具体步骤。
调整JVM参数
并不是每个人都会分析如何设置JVM 堆内存大小,为了避免内存太小导致的溢出,基本上都设得挺大的,毕竟内存大总比内存溢出好,因此就造成了不少的内存浪费。
对于许多应用来说,简单地微调JVM的内存参数可能就是解决问题的关键。一些常见的参数包括:
-Xms和-Xmx:它们分别设置了JVM堆的初始大小和最大大小。-XX:MaxMetaspaceSize:对于Java 8及以上版本,这个参数限制了元数据空间的大小,这是旧的持久代的替代品。
请注意,盲目地增加内存不是一个长久之计,你应该根据应用的实际需要进行适当的调整。如何选择合适大小的内存?我会在后面的文章为你分析。
代码优化
代码优化对每个程序员都息息相关,我们来看下有哪些注意事项:
- 移除不必要的对象引用:确保你的代码中不再使用的对象被正确地设置为null,这样垃圾回收器可以回收它们。
- 使用弱引用或软引用:Java提供了
WeakReference和SoftReference类,当你想要持有一个对象的引用,但不想阻止它被垃圾收集时,它们是很有用的。 - 池化资源:对于重的对象,如数据库连接或线程,使用池可以有效地复用它们,而不是每次都重新创建。
归结为一句话:避免重复创建,避免让无用的对象存活太长。
使用缓存策略
缓存可是性能优化的一大利器,但是它是一把双刃剑。虽然它可以显著提高应用的性能,但如果不正确地管理,它也可能是内存溢出的原因。考虑使用像LruCache这样的策略,它会根据使用情况自动删除老的缓存项。
外部存储
内存是计算机中相对不那么便宜一块位置。如果你的应用需要处理大量数据,可以考虑将一部分数据移到外部存储,如数据库、硬盘或分布式缓存系统。
第三方库审查
我们引用的大部分包,都可以在升级后得到解决。确保你使用的所有第三方库都是最新的,没有已知的内存泄漏问题。旧的或未维护的库可能会成为应用中内存问题的隐藏来源。
解决内存溢出问题可能需要时间和耐心,但通过系统的方法和正确的工具,你可以有效地定位并解决它们。接下来的章节,我们将分享一些实际的案例和经验。
八、基于MAT分析的实战应用案例
HPROF文件可能包含敏感或私有信息,因此直接在公共平台上共享可能不是一个好主意。这也是为什么大多数公司会选择在内部工具或私有云环境中进行HPROF文件的分析。网上大部分分享出来的案例大多都是层层加码,没办法拿到完整的HPROF文件。
实际场景常常是最佳的学习平台。接下来,我将为您分享一个案例,展示如何在实际环境中诊断并解决JVM内存溢出问题。一个完整的生产级事故,一般都会经历下面这几个阶段:
快速恢复业务
当线上出现故障时,首先需要迅速消除其对业务的影响,随后再收集数据、定位问题,并给出解决方案。为确保线上业务不受干扰,而不仅仅是简单地重启服务器,我们需要尽可能地保留出现问题的场景,为后续的问题分析提供基础。
那么,如何既能迅速消除对业务的影响,又能保留故障的现场信息呢?
首选策略是隔离出问题的服务器。
当服务器出现问题时,良好的分布式负载方案可以自动将出问题的机器从集群中移除,以确保系统的高可用性。如果故障的服务器没有被自动移除,需要运维人员手动隔离,并保留故障信息供后续分析。
内存泄露问题,大多数情况下是代码错误导致的。这类问题可能会引发连锁反应,导致多台服务器接连崩溃。为了避免这种连锁反应,我们需要迅速定位并处理内存泄露问题,同时尽可能减少其对其他服务的影响。简单的解决办法是根据转发策略(例如使用Nginx或F5),将流量引导到一个单独的集群,与其他业务流量隔离,确保整体业务稳定。
问题定位
首先,通过日志确定是哪种类型的内存溢出,例如Java heap space(堆空间)或perm space(持久代)。团队发现频繁的全堆垃圾收集是导致应用崩溃的主因。每次GC都会使应用响应时间大幅度增加,直至系统崩溃。进一步的分析显示,存在一个被频繁使用但从未释放的大型缓存对象,导致GC花费大量时间。
解决方案
团队决定优化缓存的实现。首先,他们移除了所有不必要的对象引用,确保这些对象在不再使用后能够被垃圾回收。接下来,他们采用了新的缓存策略,使用WeakReference来引用可能很快被垃圾回收的对象。此外,他们还确保所有使用的第三方库都是最新版本,并没有已知的内存泄漏问题。
收集内存溢出Dump文件
有两种方法可以收集Dump文件:
- 设置JVM启动参数
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/opt/jvmdump。这样,每次发生内存溢出时,JVM会自动进行堆转储,其dump文件将保存在指定路径下。 - 使用
jmap命令进行收集:jmap -dump:live,format=b,file=/opt/jvm/dump.hprof pid。
分析Dump文件
我也不制造问题了,直接把教程中的HPROF拿来分析,我们使用MAT打开Dump文件后,您将看到如下的界面:

通过上述方法,我们可以更高效地定位并解决JVM内存溢出问题,确保业务的稳定运行。
九、其它工具
在处理JVM内存溢出问题时,使用正确的工具至关重要。下面我会介绍一些常用的工具和技巧,这些工具和技巧可以帮助您更快地定位和解决问题。
JVM内置工具
1. jstat
jstat 是一个命令行工具,可以提供JVM的类加载、垃圾收集、JIT编译等的统计信息。例如,要查看一个正在运行的Java进程的垃圾收集统计信息,可以使用:
jstat -gc
2. jmap
jmap 是一个Java内存映射工具,可以为Java进程生成堆转储。堆转储可以使用其他工具进行分析,以找出内存泄漏或其他问题。例如,生成一个堆转储:
jmap -dump:format=b,file=
3. VisualVM
我在上面已经提到,但是为了把它归类完整,还是着重介绍一下它。 VisualVM 是一个强大的工具,集成了多个JDK命令行工具。它提供了一个可视化的界面,可以查看和分析Java应用程序的性能数据。你可以在这个工具中解决80%以上的问题。
技巧和建议
- 在启动Java应用程序时,使用
-verbose:gc和-Xloggc:参数,可以输出GC日志。这些日志在分析垃圾收集活动时非常有用。 - 定期审查代码,避免常见的内存泄漏情况,例如:长时间持有对象引用,或不适当地使用静态集合。
- 使用自动测试和负载测试来模拟高流量的情境,确保系统在高压力下仍能正常运行。
解决策略与优化建议
解决JVM内存溢出问题不仅仅是定位和修复问题,更重要的是对系统进行长期的优化和调整,以预防此类问题再次发生。下面是一些常见的解决策略和优化建议:
1. 调整JVM参数
调参工程师名不虚传,调参可以解决90%以上的性能慢的问题。以下是一些常见的套路:
- 堆内存分配:适当增加JVM的
-Xms和-Xmx值可以延长OOM的发生,但不是根本解决方法。这只有在确保没有内存泄漏的情况下才有效。 - 调整年轻代与老年代大小:使用
-XX:NewRatio来调整年轻代和老年代的比例,以适应应用的实际需求。 - 调整线程栈大小:如果出现因为线程过多导致的OOM,可以通过
-Xss调整每个线程的栈大小。
2. 代码优化建议
- 使用弱引用:对于不必长时间持有的对象,可以考虑使用弱引用,使其能够在适当的时机被垃圾收集器回收。
- 缓存策略:确保所有缓存(如商品缓存)都有清晰的过期策略和大小限制。
- 减少对象的全局持有:例如,避免使用静态集合类持有大量对象。
3. 垃圾收集策略调整
- 选择合适的GC算法:例如,对于需要低延迟的应用,可以考虑使用G1或ZGC。
- 调整GC参数:使用
-XX:GCTimeRatio和-XX:AdaptiveSizePolicyWeight等参数,对GC进行微调。
十、总结
内存管理在JVM性能优化中占有举足轻重的地位。不合理的内存使用不仅会导致应用的不稳定,还会严重影响用户体验。因此,对内存溢出问题的及时发现和解决尤为关键。
本文通过详细的案例分析,让我们了解到了如何定位和解决JVM内存溢出的问题。通过对JVM参数的调整、代码的优化和合理的垃圾收集策略,我们可以确保应用的稳定运行并最大化性能。在今后的开发中,希望大家能够将这些经验和策略运用得当,持续优化和提高应用的性能。
十一、参考文献
- 生产环境JVM内存溢出案例分析
- 10分钟搞懂各种内存溢出案例!!
- 一次内存溢出排查优化实战
- FullGC 40次/天到10天1次,这波JVM优化很炸裂!!
- 谈JVM线程和内存参数合理性设置
- JVM 内存大对象监控和优化实践