2023届秋招前端总结面试题
1.讲一下你对flex布局的理解(深入些)
一、概念:flex布局是flexible box的缩写,任何一个容器都可以指定为弹性布局
二、轴线:有两条轴线,即主轴(main axis)和交叉轴(cross axis),可以理解为x,y两个方向,交叉轴(侧轴)是垂直于主轴方向的轴线,主轴轴线是由flex-direction决定的
(1)主轴:flex-direction设为row或者是row-reverse(反方向),你的主轴将沿着x轴方向延伸;设为column或者是column-reverse(反方向),你的主轴将沿着y轴方向延伸
(2)侧轴(交叉轴):flex-direction设为row或者是row-reverse(反方向),交叉轴就是垂直方向;设为column或者是column-reverse(反方向),交叉轴就是水平方向
三、容器的6个属性:
(1)flex-direction决定主轴的方向,默认值为row 值有row,row-reverse,column,column-reverse
(2)flex-wrap定义了容器内的项目沿着轴线布局时是否换行,默认值为nowrap 值有nowrap ,wrap,wrap-reverse(反向换行,多余的行会逆文档流方向折行显示)
(3)flex-flow是flex-direction和flex-wrap的组合简写
(4)align-items属性可以使元素在交叉方向对齐,默认值为:stretch 值有 stretch(如果项目未设高度或设为auto,将沾满整个容器的高度),baseline(项目第一行文字的基线对齐),flex-start(交叉轴的起点对齐),flex-center,flex-end
(5)justify-content定义项目在主轴的对齐方式,默认值为:flex-start 值为flex-start(从首行起始位置开始排列),center,flex-end,space-around,space-between,space-evenly(兼容性差,iPhone SE不支持)
(6)align-content定义多个项目多根轴线的对齐方式,只有一个轴线时没有作用,也就是说如果成员只有一行那么这个属性就没有什么用,默认值为stretch,值为stretch(轴线占满整个交叉轴)flex-start,flex-end,center,space-between,space-around
四、项目的6个属性
(1)order决定项目在主轴方向上的排列顺序,数值越小,排列越靠前,默认值为零
(2)flex-basis决定了在分配额外空间之前,成员占据的空间,默认值为auto;当一个元素同时被设置了flex-basis和width,flex-basis具有更高的优先级,只有flex-basis设置为auto时,width才会生效
(3)flex-grow决定了对剩余空间的占据量,只有在空间有冗余的时候这一属性才有用。默认值是 0,意思就是即使有多余空间,它也占据。如果给多个成员设置正值,那么他们会根据正值所占的比例的大小分配剩余空间。
(4)flex-shrink 只有在没有额外空间时起作用,意思是没有额外空间时,成员贡献出空间的大小。默认值为 1,如果为 0 意思是不贡献空间,也就是说即使空间不足,成员大小也不发生改变。
(5)flex决定了弹性项目如何增大或缩小以适应其弹性容器中可用的空间。是 flex-grow、flex-shrink和flex-basis 组合简写,默认值为:0 1 auto 。它还有以下2个可选值:auto(等同于flex:1 1 auto 意思就是沾满额外空间,可缩放) none(等同于flex:0 0 auto 意思是不占额外空间,不可缩放)
(6)align-self决定了项目在容器中的对齐方式,并且会覆盖容器已有的align-items的值 ;注意: align-self 属性不适用于块类型的盒模型和表格单元。如果任何项目的侧轴方向 margin 值设置为 auto,则会忽略 align-self。
2.一个页面从输入url到加载的全过程
略
3.请你说下防抖函数和节流函数,如何实现,两个函数的异同(重点是使用的场景,没有写出,自行查阅)
一、防抖函数:触发高频事件后n秒内函数只会执行一次,如果在n秒内高频事件再次被触发,则重新计算时间
实现方式:每次触发事件时设置一个延迟调用的方法,并且取消之前延迟调用的方法
二、节流函数:高频事件触发,但在n秒内只会执行一次,所以节流会稀释函数的执行频率;
实现方式:每次触发事件时,如果当前有等待执行的延迟函数,直接return
三、区别:函数节流不管触发有多频繁,在规定时间内一定会执行一次真正的事件处理函数,而防抖函数只是在最后一次事件后才触发一次函数
4.三次握手四次挥手
略
5.前端安全问题,以及如何避免(重点是如何避免,解决)
跨站请求伪造(CSRF:Cross-site request forgery):用户登录A网站得到cookie,然后用户访问了危险的B网站,B网站携带A的cookie发送A的请求
解决方法:
(1)token放在session中
(2)服务端增加伪随机数:方法:客户端获取服务器通过cookie发送过来的伪随机数,客户端发送请求时增加伪随机数,服务器判断该伪随机数是否正确,从而解决问题。
(3)验证码:方法:这个方案的思路是:每次的用户提交都需要用户在表单中填写一个图片上的随机字符串,这个方案可以解决CSRF。
(4)检查Referer字段
(5)双cookie校验
跨域脚本攻击(XSS : Cross Site Scripting):向网站A注入js代码,然后执行js的代码,篡改A网站的内容
解决方法:HTML转义
6.浏览器的回流和重绘,如何防止
略
7.元素垂直居中,上下居中的方法,至少说四种
略
8.箭头函数
(1)箭头函数时匿名函数,不能作为构造函数,不能使用new,箭头函数不能绑定arguments,取而代之的是rest参数...解决
(2)不绑定this,他的this来自定义时上下文函数的this,作为自己的this
(3)箭头函数通过call(),apply()方法,调用一个函数时,只传入一个参数,对this没有影响
(4)箭头函数没有原型属性
(6)箭头函数不能当做Generator函数,不能使用yield关键字
9.字符串常用方法
略
10.数组常用方法,哪些是返回新数组的
略
11.cookie、localStorage、sessionStorage、session、token
Session和Token可以算做服务器端验证功能,Cookie,sessionStorage,loaclStorage则是浏览器端存储功能
Cookie完全不同于Session和Token,Cookie只是一种存储方法,数据由服务器生成,Cookie存的数据会在下次访问这个网站的时候传过来。为了不让Cookie占用过多的存储空间,浏览器对Cookie的使用大小由限制。
从Cookie的功能角度上看,完全匹配上了Session和Token的使用场景,所以可以把Session或者Token信息从服务端生成后,直接设置到Cookie中,但是用户并不知道,从而在使用角度上产生了一种类似于TCP长连接的错觉。其他略

12.同步与异步 (会考代码题,分析输出顺序,重点)
13.讲述下ajax的底层原理,如何封装一个axios
底层原理略,如何封装一个axios:设置响应头,设置请求超时,设置baseURL,设置请求拦截器,设置响应拦截器,封装get和post,设置api统一管理
14.fetch与原生ajax的区别
Ajax是一个技术统称,是一个概念模型,它囊括了很多技术,并不特指某一技术,它很重要的特性之一就是让页面局部刷新;XMLHttpRequest只是实现Ajax的一种方式,二者并不相等,浏览器自带
fetch是在ES6出现的,它使用了ES6提出的promise对象,它是XMLHttpRequest的替代品;fetch是一个API,它是真实存在的,它基于promise,使用promise不使用回调函数
axios是一个基于promise封装的网络请求,它是基于XHR进行二次封装
ajax和fetch的区别 :
(1)、ajax是利用XMLHttpRequest对象来请求数据的,而fetch是window的一个方法
(2)、ajax基于原生的XHR开发,XHR本身的架构不清晰,已经有了fetch的替代方案
(3)、fetch比较与ajax有着更好更方便的写法
(4)、fetch只对网络请求报错,对400,500都当做成功的请求,需要封装去处理
(5)、fetch没有办法原生监测请求的进度,而XHR可以
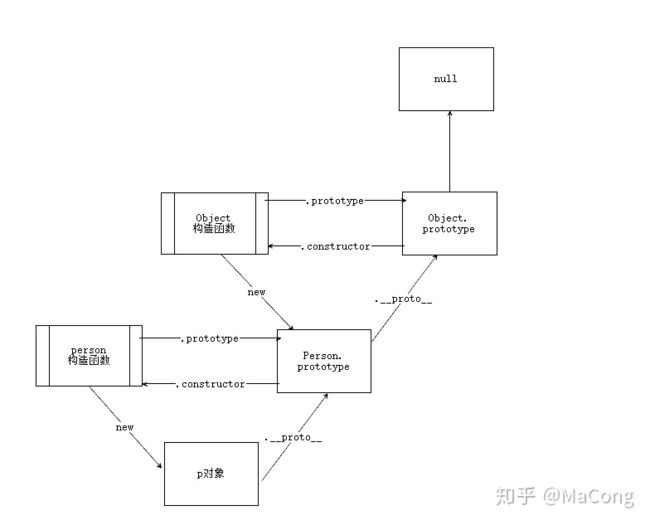
15.说一下原型链
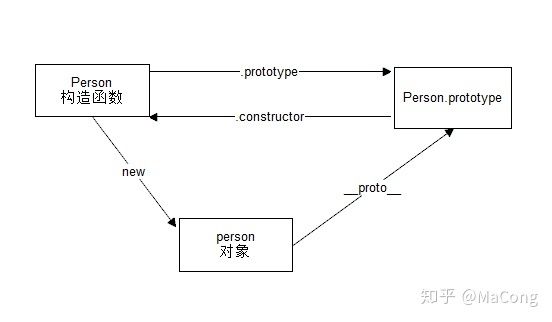
每一个构造函数都拥有一个prototype属性,这个属性指向一个对象,也就是原型对象
原型对象默认拥有一个constructor属性,指向指向它的那个构造函数
每个对象都拥有一个隐藏属性_proto_,指向它的原型对象
16,深拷贝与浅拷贝,如何实现
浅拷贝:(1)= 直接赋值 (2)Object.assign(target,...sources) 注意:Object.assign()可以处理一层的深度拷贝

(3)for in 循环浅拷贝 (4)扩展运算符,这种方法是浅拷贝,无法拷贝嵌套对象,嵌套数组 var person3 = { ...person1 };
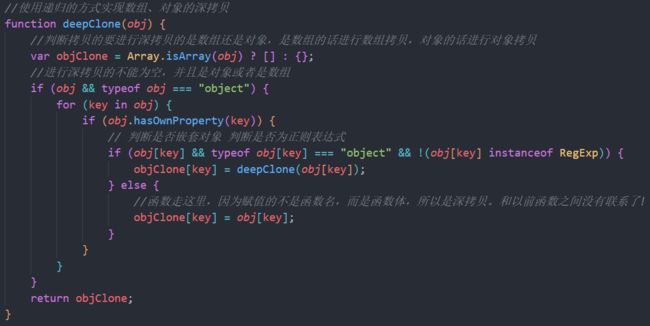
深拷贝: (1)JSON做字符串转换,用JSON.stringify把对象转成字符串,再用JSON.parse把字符串转成新对象,但是这种方法也有不少坏处,譬如它会抛弃对象的constructor。也就是深拷贝之后,不管这个对象原来的构造函数是什么,在深拷贝之后都会变成Object。这种方法能正确处理的对象只有 Number, String, Boolean, Array, 扁平对象,即那些能够被 json 直接表示的数据结构。RegExp对象是无法通过这种方式深拷贝。也就是说,只有可以转成JSON格式的对象才可以这样用,像function没办法转成JSON。
(2)自己递归:
17.对ES6的了解
const let ;ES6具有块级作用域(大括号内为块级作用域);结构赋值;箭头函数;...扩展运算符代替arguments
Array.from方法用于将两类对象转为真正的数组:类似数组的对象(array-like object)和可遍历(iterable)的对象(包括ES6新增的数据结构Set和Map),类数组对象:使用querySelectorAll、getElementsByClassName等api获取的元素的集合,就是类数组;模板字符串;Set和Map
18.object.assign(略)
19.如何理解Promise
promise是最早由于社区提出和实现的一种解决异步编程的方案,解决了回调地狱函数
promise的三个缺点:
1)无法取消Promise,一旦新建它就会立即执行,无法中途取消
2)如果不设置回调函数,Promise内部抛出的错误,不会反映到外部
3)当处于pending状态时,无法得知目前进展到哪一个阶段,是刚刚开始还是即将完成
20.如何手写一个promise
http://t.csdn.cn/tRD0K
21.promise的优缺点
promise的三个缺点:
1)无法取消Promise,一旦新建它就会立即执行,无法中途取消
2)如果不设置回调函数,Promise内部抛出的错误,不会反映到外部
3)当处于pending状态时,无法得知目前进展到哪一个阶段,是刚刚开始还是即将完成
22.async和await(略)
23.如何理解MVVM框架,MVC框架(略)
24.vue优缺点
25.watch和computed以及watchEffect 对比
对比 watch vs watchEffect vs computed - 掘金
26.vue2.0和vue3.0的双向数据绑定原理
2.0中使用的是Object.defineProperty实现对属性的监听。缺点是一定要克隆一个新的对象进行操作,否则就会造成死循环。第二个缺点是如果有多个属性,那么就要定义多个Object.defineProperty去分别监听每一个属性。
3.0中使用了ES6中的新语法,用到了Proxy去实现监听,这样省去了克隆对象的步骤,同时不管有多少个属性只需要定义一次Proxy就可以实现多对象的监听,不同分别定义。
27.vue2.0自带的生命周期有哪些
28.vue3.0自带生命周期有哪些

28.vue2.0/3.0加上keep-alive多了那个生命周期
29.加上keep-alive第一次执行会执行哪些生命周期(略)
30.那么第二次和第n次会执行哪些(略)
31.一旦进入页面或者组件,会执行哪些生命周期,顺序是什么(略)
32.哪个阶段有$el,哪个阶段有$data(略)
beforeCreate啥也没有,created有data没有el,beforeMount有data没有el mounted都有,之后也都有
33.组件中data为什么是一个函数,为什么需要return(略)
34.promise.all与promise.race(略)
35.commonJS与nodeJS(略)
36.了解过JS哪些异步线程(略)
37.http与https的区别,了解https加密的过程吗
https协议需要到证书颁发机构(CA)申请证书,一般免费的证书比较少,需要缴费
http是超文本传输协议,信息是明文传输,https则是具有安全性的SSL加密传输协议
http和https使用的是完全不同的连接方式,http的端口号为80,https端口号为443
http连接是无状态的,https是有SSL+http协议构建的身份认证,加密传输的网络协议,比http安全
https和http协议相比较提供了:数据完整性(内容传输经过完整性校验) 数据隐性(内容经过对称加密,每个连接生成唯一一个加密秘钥) 身份认证(第三方无法伪造服务器端(客户端)身份)数据完整性和隐私性由TLS Record Protocol保证,身份认证由TLS Handshaking Protocols实现
在 https 的加密中,加密传输的数据本身使用的是对称加密,加密对称秘钥时使用的非对称加密。
https 中传输数据时不会使用非对称加密加密传输数据,传输数据时有可能数据本身很大,那样的话非对称加密更耗时了,所以传输数据时不会使用非对称加密的方式加密。
38.对称加密和非对称加密(略)
40.正则表达式(略)
41.跨域产生原因和解决办法(略)
42.如何配置webpack(略)
43.null和undefined的区别(略)
44.计算机网络各层协议(略)
45.ES6的数据类型(略)
46.图片懒加载(略)
47.vuex和pinia,父子组件消息传递

48.vue路由守卫(略)
49.mutations和actions的区别(重点)
50.H5和CSS3新增特性,H5的缓存机制(略)
51.SEO优化(略)
52.JS阻止冒泡,CSS阻止冒泡
(1)event.stopPropagation()方法:这是阻止事件的冒泡方法,不让事件向documen上蔓延,但是默认事件任然会执行,当你掉用这个方法的时候,如果点击一个连接,这个连接仍然会被打开
(2)event.preventDefault():这是阻止默认事件的方法,调用此方法是,连接不会被打开,但是会发生冒泡,冒泡会传递到上一层的父元素
(3)这个方法比较暴力,他会同事阻止事件冒泡也会阻止默认事件;写上此代码,连接不会被打开,事件也不会传递到上一层的父元素;可以理解为return false就等于同时调用了event.stopPropagation()和event.preventDefault()
(4)在vue中可以用.stop和.prevent
(5)css中可以用pointer-events
53.vue-router两种模式以及区别
hash和history
对于 Vue 这类渐进式前端开发框架,为了构建 SPA(单页面应用),需要引入前端路由系统,这也就是 Vue-Router 存在的意义。前端路由的核心,就在于 —— 改变视图的同时不会向后端发出请求。
为了达到这一目的,浏览器当前提供了以下两种支持:
- hash —— 即地址栏 URL 中的 # 符号(此 hash 不是密码学里的散列运算)。
比如这个 URL:http://www.abc.com/#/hello,hash 的值为 #/hello。它的特点在于:hash 虽然出现在 URL 中,但不会被包括在 HTTP 请求中,对后端完全没有影响,因此改变 hash 不会重新加载页面。 - history —— 利用了 HTML5 History Interface 中新增的 pushState() 和 replaceState() 方法。(需要特定浏览器支持)
这两个方法应用于浏览器的历史记录栈,在当前已有的 back、forward、go 的基础之上,它们提供了对历史记录进行修改的功能。只是当它们执行修改时,虽然改变了当前的 URL,但浏览器不会立即向后端发送请求。
因此可以说,hash 模式和 history 模式都属于浏览器自身的特性,Vue-Router 只是利用了这两个特性(通过调用浏览器提供的接口)来实现前端路由。
54.v-for为什么要加key,为什么key值最好不要用index(略)
55.position的值有哪些,他们的参照物分别是什么(略)
56.ref和refs的区别(略,容易问到)
57.网格布局了解吗(略)
58.vite,webpack、vue-cli
webpack会先打包,然后启动开发服务器,请求服务器时直接给予打包结果。 而vite是直接启动开发服务器,请求哪个模块再对该模块进行实时编译。 由于现代浏览器本身就支持ES Module,会自动向依赖的Module发出请求。vite充分利用这一点,将开发环境下的模块文件,就作为浏览器要执行的文件,而不是像webpack那样进行打包合并。 由于vite在启动的时候不需要打包,也就意味着不需要分析模块的依赖、不需要编译,因此启动速度非常快。当浏览器请求某个模块时,再根据需要对模块内容进行编译。这种按需动态编译的方式,极大的缩减了编译时间,项目越复杂、模块越多,vite的优势越明显。 在HMR方面,当改动了一个模块后,仅需让浏览器重新请求该模块即可,不像webpack那样需要把该模块的相关依赖模块全部编译一次,效率更高。 当需要打包到生产环境时,vite使用传统的rollup进行打包,因此,vite的主要优势在开发阶段。另外,由于vite利用的是ES Module,因此在代码中不可以使用CommonJS
59.onclick和addeventListener区别,怎么移除点击事件(略)
60.状态码(略)
61.链表和数组(略)
62.经典浏览器线程有哪些,宏任务和微任务
JavaScript是单线程,浏览器是多线程
浏览器线程有JavaScript引擎线程,界面渲染线程,浏览器事件触发线程,Http请求线程
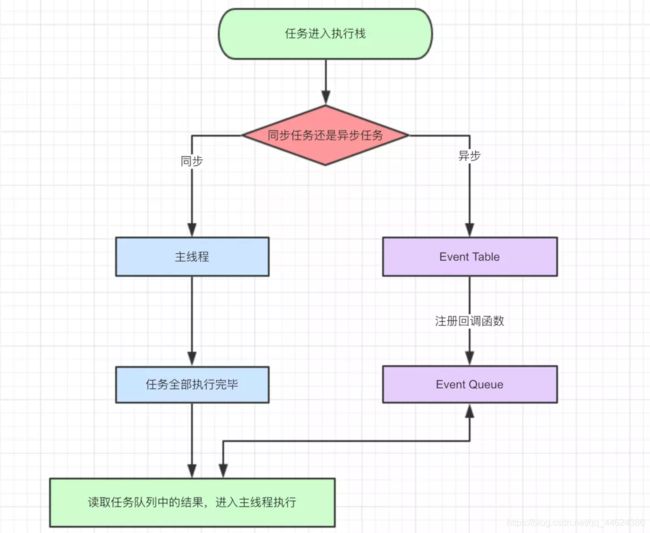
运行机制:
在执行栈中执行一个宏任务。
执行过程中遇到微任务,将微任务添加到微任务队列中。
当前宏任务执行完毕,立即执行微任务队列中的任务。
当前微任务队列中的任务执行完毕,检查渲染,GUI线程接管渲染。
渲染完毕后,js线程接管,开启下一次事件循环,执行下一次宏任务(事件队列中取)。
63.for ...of 和 for .... in
for in 遍历的是数组的索引(即键名),而for of 遍历的是数组元素值
for in 总是得到对象的key或数组、字符串的下标
for of 总是得到对象的value或数组、字符串的值
for of适用遍历数/数组对象/字符串/map/set等拥有迭代器对象(iterator)的集合,但是不能遍历对象,因为没有迭代器对象,但如果想遍历对象的属性,你可以用for in循环(这也是它的本职工作)或用内建的Object.keys()方法
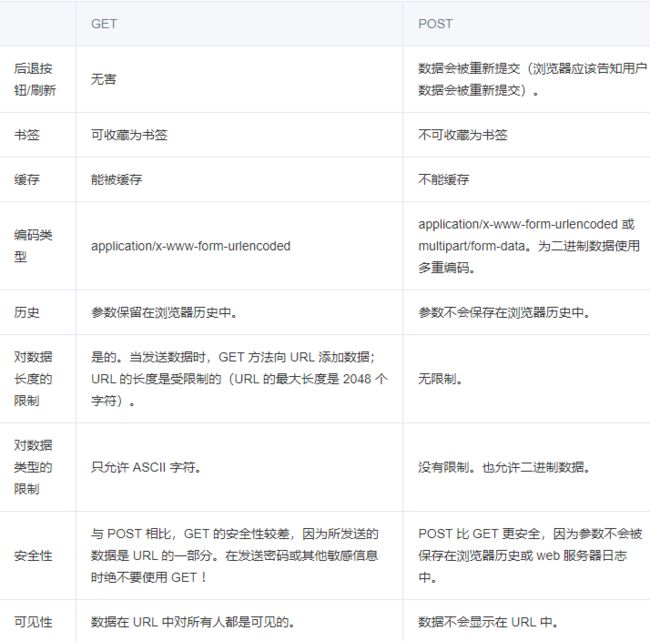
64.get和post区别
65.loader和plugin的区别
loader即为文件加载器,操作的是文件,将文件A通过loader转换成文件B,是一个单纯的文件转化过程。plugin即为插件,是一个扩展器,丰富webpack本身,增强功能 ,针对的是在loader结束之后,webpack打包的整个过程,他并不直接操作文件,而是基于事件机制工作,监听webpack打包过程中的某些节点,执行广泛的任务。
66.URL的组成部分
http://www.aspxfans.com:8080/news/index.asp?boardID=5&ID=24618&page=1#name
从上面的URL可以看出,一个完整的URL包括以下几部分:
1.协议部分:该URL的协议部分为“http:”,这代表网页使用的是HTTP协议。在Internet中可以使用多种协议,如HTTP,FTP等等本例中使用的是HTTP协议。在"HTTP"后面的“//”为分隔符
2.域名部分:该URL的域名部分为“www.aspxfans.com”。一个URL中,也可以使用IP地址作为域名使用
3.端口部分:跟在域名后面的是端口,域名和端口之间使用“:”作为分隔符。端口不是一个URL必须的部分,如果省略端口部分,将采用默认端口
4.虚拟目录部分:从域名后的第一个“/”开始到最后一个“/”为止,是虚拟目录部分。虚拟目录也不是一个URL必须的部分。本例中的虚拟目录是“/news/”
5.文件名部分:从域名后的最后一个“/”开始到“?”为止,是文件名部分,如果没有“?”,则是从域名后的最后一个“/”开始到“#”为止,是文件部分,如果没有“?”和“#”,那么从域名后的最后一个“/”开始到结束,都是文件名部分。本例中的文件名是“index.asp”。文件名部分也不是一个URL必须的部分,如果省略该部分,则使用默认的文件名
6.锚部分:从“#”开始到最后,都是锚部分。本例中的锚部分是“name”。锚部分也不是一个URL必须的部分
7.参数部分:从“?”开始到“#”为止之间的部分为参数部分,又称搜索部分、查询部分。本例中的参数部分为“boardID=5&ID=24618&page=1”。参数可以允许有多个参数,参数与参数之间用“&”作为分隔符。
67.vuex和pinia
68.Map和Set的区别
1.Map是键值对,Set是值的集合,当然键和值可以是任何的值;
2.Map可以通过get方法获取值,而set不能因为它只有值;
3.都能通过迭代器进行for...of遍历;
4.Set的值是唯一的可以做数组去重,Map由于没有格式限制,可以做数据存储
5.map和set都是stl中的关联容器,map以键值对的形式存储,key=value组成pair,是一组映射关系。set只有值,可以认为只有一个数据,并且set中元素不可以重复且自动排序。
集合Set:
注意:向 Set 加入值的时候,不会发生类型转换,所以5和"5"是两个不同的值。Set 内部判断两个值是否不同,使用的算法叫做“Same-value-zero equality”,它类似于精确相等运算符(===),主要的区别是**NaN等于自身,而精确相等运算符认为NaN不等于自身。
操作方法:
- add(value):新增,相当于 array里的push。
- delete(value):存在即删除集合中value。
- has(value):判断集合中是否存在 value。
- clear():清空集合。
便利方法:遍历方法(遍历顺序为插入顺序)
- keys():返回一个包含集合中所有键的迭代器。
- values():返回一个包含集合中所有值得迭代器。
- entries():返回一个包含Set对象中所有元素得键值对迭代器。
- forEach(callbackFn, thisArg):用于对集合成员执行callbackFn操作,如果提供了 thisArg 参数,回调中的this会是这个参数,没有返回值。
WeakSet:
WeakSet 对象允许你将弱引用对象储存在一个集合中。
WeakSet 与 Set 的区别:
- WeakSet 只能储存对象引用,不能存放值,而 Set 对象都可以。
- WeakSet 对象中储存的对象值都是被弱引用的,即垃圾回收机制不考虑 WeakSet 对该对象的应用,如果没有其他的变量或属性引用这个对象值,则这个对象将会被垃圾回收掉(不考虑该对象还存在于 WeakSet 中),所以,WeakSet 对象里有多少个成员元素,取决于垃圾回收机制有没有运行,运行前后成员个数可能不一致,遍历结束之后,有的成员可能取不到了(被垃圾回收了),WeakSet 对象是无法被遍历的(ES6 规定 WeakSet 不可遍历),也没有办法拿到它包含的所有元素。
方法:
- add(value):在WeakSet 对象中添加一个元素value。
- has(value):判断 WeakSet 对象中是否包含value。
- delete(value):删除元素 value。
字典Map:
是一组键值对的结构,具有极快的查找速度。
操作方法:
- set(key, value):向字典中添加新元素。
- get(key):通过键查找特定的数值并返回。
- has(key):判断字典中是否存在键key。
- delete(key):通过键 key 从字典中移除对应的数据。
- clear():将这个字典中的所有元素删除。
遍历方法:
- Keys():将字典中包含的所有键名以迭代器形式返回。
- values():将字典中包含的所有数值以迭代器形式返回。
- entries():返回所有成员的迭代器。
- forEach():遍历字典的所有成员。
WeakMap:
WeakMap 对象是一组键值对的集合,其中的键是弱引用对象,而值可以是任意。
注意,WeakMap 弱引用的只是键名,而不是键值。键值依然是正常引用。
WeakMap 中,每个键对自己所引用对象的引用都是弱引用,在没有其他引用和该键引用同一对象,这个对象将会被垃圾回收(相应的key则变成无效的),所以,WeakMap 的 key 是不可枚举的。
方法:
- has(key):判断是否有 key 关联对象。
- get(key):返回key关联对象(没有则则返回 undefined)。
- set(key):设置一组key关联对象。
- delete(key):移除 key 的关联对象。
Set:
- 成员唯一、无序且不重复。
- [value, value],键值与键名是一致的(或者说只有键值,没有键名)。
- 可以遍历,方法有:add、delete、has。
WeakSet:
- 成员都是对象。
- 成员都是弱引用,可以被垃圾回收机制回收,可以用来保存DOM节点,不容易造成内存泄漏。
- 不能遍历,方法有add、delete、has。
Map:
- 本质上是键值对的集合,类似集合。
- 可以遍历,方法很多可以跟各种数据格式转换。
WeakMap:
- 只接受对象作为键名(null除外),不接受其他类型的值作为键名。
- 键名是弱引用,键值可以是任意的,键名所指向的对象可以被垃圾回收,此时键名是无效的。
- 不能遍历,方法有get、set、has、delete。
69.require和import的区别
require/exports 出自CommonJS;import/export 出自ECMAScript2015(ES6)
浏览器不支持require/exports ;node.js所有版本都支持require/exports
CommonJS 模块化方案 require/exports 是为服务器端开发设计的。服务器模块系统同步读取模块文件内容,编译执行后得到模块接口。(Node.js 是 CommonJS 规范的实现)。
在浏览器端,因为其异步加载脚本文件的特性,CommonJS 规范无法正常加载。所以出现了 RequireJS、SeaJS 等(兼容 CommonJS )为浏览器设计的模块化方案。直到 ES6 规范出现,浏览器才拥有了自己的模块化方案 import/export。
两种方案各有各的限制,需要注意以下几点:
- 原生浏览器不支持 require/exports,可使用支持 CommonJS 模块规范的 Browsersify、webpack 等打包工具,它们会将 require/exports 转换成能在浏览器使用的代码。
- import/export 在浏览器中无法直接使用,我们需要在引入模块的