3天上手Ascend C编程 | Day3 Ascend C算子调试调优方法
本文分享自《【2023 · CANN训练营第一季】——Ascend C算子开发入门——第三次课》
,作者:weixin_54022960 。
Ascend C是CANN针对算子开发场景推出的编程语言,原生支持C和C++标准规范,最大化匹配用户开发习惯;通过多层接口抽象、自动并行计算、孪生调试等关键技术,极大提高算子开发效率,助力AI开发者低成本完成算子开发和模型调优部署。
时间充足的小伙伴推荐去看官方教程:Ascend C官方教程
想省时省力快速入门可以看这篇文章,为你系统化梳理AscendC编程最重要的知识点,3天快速上手不迷路!
3天上手Ascend C编程 | Day1 Ascend C基本概念及常用接口
3天上手Ascend C编程 | Day2 通过Ascend C编程范式实现一个算子实例
3天上手Ascend C编程 | Day3 Ascend C算子调试调优方法
第3天的学习内容要点如下:
一、固定shape算子改写成动态shape算子
将第2次课固定shape的add算子改造成动态shape的add算子。
1、什么是动态shape
动态shape和固定shape是一对概念。固定shape是指,在编译时指定shape大小,运行时不需要指定shape大小。在开发固定shape算子过程中,一个算子源代码可以支持多个固定shape,但需要在编译时明确了shape的实际值。而动态shape则是在编译时不指定shape大小,在运行时传入实际的shape大小,算子编译后的二进制文件支持任意shape,或者是一个或多个shape范围。

2、如何实现动态shape
课程的第2次课,讲述是采用固定shape的加法实例,本次课讲述,如何将固定shape改为动态shape的算子。也就是,将控制形状的BLOCK DIM,TOTAL LENGTH,TILE NUM这些变量做成tiling结构体,作为参数传给核函数。如下所示: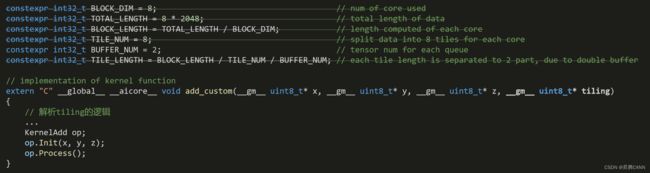
3、动态shape算子的tiling结构体
1)主要操作流程

2)tiling结构体中的信息
BLOCK_DIM:并行计算使用的核数
TOTAL_LENGTH:总共需要计算的数据个数
TILE_NUM:每个核上计算数据分块的个数
struct AddCustomTilingData {
uint32_t blockDim;
uint32_t totalLength;
uint32_t tileNum;
};
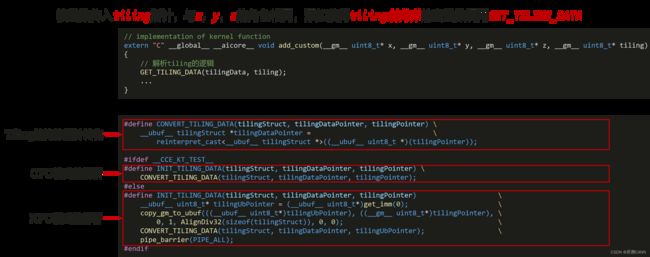
3)动态shape算子的tiling解析函数

4、固定与动态shape实现对比
1)核函数差异
固定shape输入的核函数实现:
constexpr int32_t BLOCK_DIM = 8; // num of core used
constexpr int32_t TOTAL_LENGTH = 8 * 2048; // total length of data
constexpr int32_t BLOCK_LENGTH = TOTAL_LENGTH / BLOCK_DIM; // length computed of each core
constexpr int32_t TILE_NUM = 8; // split data into 8 tiles for each core
constexpr int32_t BUFFER_NUM = 2; // tensor num for each queue
constexpr int32_t TILE_LENGTH = BLOCK_LENGTH / TILE_NUM / BUFFER_NUM; // each tile length is separated to 2 part, due to double buffer
// implementation of kernel function
extern "C" __global__ __aicore__ void add_custom(__gm__ uint8_t* x, __gm__ uint8_t* y, __gm__ uint8_t* z)
{
KernelAdd op;
op.Init(x, y, z);
op.Process();
}
动态shape输入的核函数实现:
constexpr int32_t BUFFER_NUM = 2; // tensor num for each queue
// implementation of kernel function
extern "C" __global__ __aicore__ void add_custom(__gm__ uint8_t* x, __gm__ uint8_t* y, __gm__ uint8_t* z, __gm__ uint8_t* tiling)
{
GET_TILING_DATA(tilingData, tiling);
KernelAdd op;
op.Init(x, y, z, tilingData.blockDim, tilingData.totalLength, tilingData.tileNum);
op.Process();
}
2)kernelAdd类差异:
3)Init()函数实现差异:
固定shape输入的Init()函数实现:
__aicore__ inline void Init(__gm__ uint8_t* x, __gm__ uint8_t* y, __gm__ uint8_t* z)
{
// get start index for current core, core parallel
xGm.SetGlobalBuffer((__gm__ half*)x + block_idx * BLOCK_LENGTH);
yGm.SetGlobalBuffer((__gm__ half*)y + block_idx * BLOCK_LENGTH);
zGm.SetGlobalBuffer((__gm__ half*)z + block_idx * BLOCK_LENGTH);
// pipe alloc memory to queue, the unit is Bytes
pipe.InitBuffer(inQueueX, BUFFER_NUM, TILE_LENGTH * sizeof(half));
pipe.InitBuffer(inQueueY, BUFFER_NUM, TILE_LENGTH * sizeof(half));
pipe.InitBuffer(outQueueZ, BUFFER_NUM, TILE_LENGTH * sizeof(half));
}
动态shape输入的Init()函数实现:
__aicore__ inline void Init(__gm__ uint8_t* x, __gm__ uint8_t* y, __gm__ uint8_t* z,
uint32_t blockDim, uint32_t totalLength, uint32_t tileNum)
{
this->blockLength = totalLength / blockDim;
this->tileNum = tileNum;
this->tileLength = this->blockLength / tileNum / BUFFER_NUM;
// get start index for current core, core parallel
xGm.SetGlobalBuffer((__gm__ half*)x + block_idx * this->blockLength);
yGm.SetGlobalBuffer((__gm__ half*)y + block_idx * this->blockLength);
zGm.SetGlobalBuffer((__gm__ half*)z + block_idx * this->blockLength);
// pipe alloc memory to queue, the unit is Bytes
pipe.InitBuffer(inQueueX, BUFFER_NUM, this->tileLength * sizeof(half));
pipe.InitBuffer(inQueueY, BUFFER_NUM, this->tileLength * sizeof(half));
pipe.InitBuffer(outQueueZ, BUFFER_NUM, this->tileLength * sizeof(half));
}
4)真值生成脚本差异:
5)main.cpp差异:主要在于动态shape,需要根据输入的tiling计算出实际的数据大小。
固定shape输入的main函数(部分):
size_t inputByteSize = 8 * 2048 * sizeof(uint16_t);
size_t outputByteSize = 8 * 2048 * sizeof(uint16_t);
uint32_t blockDim = 8;
动态shape输入的main函数(部分):
uint8_t* tiling = (uint8_t*)addcustom::GmAlloc(tilingSize);
ReadFile("./input/tiling.bin", tilingSize, tiling, tilingSize);uint32_t blockDim = (*(const uint32_t *)(tiling));
size_t inputByteSize = blockDim * 2048 * sizeof(uint16_t);
size_t outputByteSize = blockDim * 2048 * sizeof(uint16_t);
// =========================================
aclrtMallocHost((void**)(&tilingHost), tilingSize);
ReadFile("./input/tiling.bin", tilingSize, tilingHost, tilingSize);
uint32_t blockDim = (*(const uint32_t *)(tilingHost));
size_t inputByteSize = blockDim * 2048 * sizeof(uint16_t);
size_t outputByteSize = blockDim * 2048 * sizeof(uint16_t);
综上,固定shape和动态shape代码文件的差别如下:
| 职能 |
固定shape |
动态shape |
|
| main.cpp |
主机侧数据文件读写以及主机侧到设备侧的数据拷贝,任务下发以及同步等待等 |
读取输入参数和申请内存,调用核函数等 |
新增tiling参数的内存申请, 搬运与释放逻辑 |
| add_custom.cpp |
Ascend C算子核函数的实现 |
shape等参数以常量展现,编译期已知 |
shape等参数以入参展现,编译期未知 |
| add_custom.py |
输入数据和真值数据的生成 |
生成输入数据x和y,真值数据golden |
新增生成tiling的.bin数据文件 |
| CMakeLists.txt |
管理工程项目编译构建配置 |
无变化 |
无变化 |
| data_utils.h |
主机侧数据打印等辅助函数的实现 |
无变化 |
无变化 |
| run.sh |
集成算子运行一体化脚本 |
无变化 |
无变化 |
| add_custom_tiling.h |
定义动态shape的tiling配置 |
不涉及 |
Tiling结构体与解析tiling宏函数 |
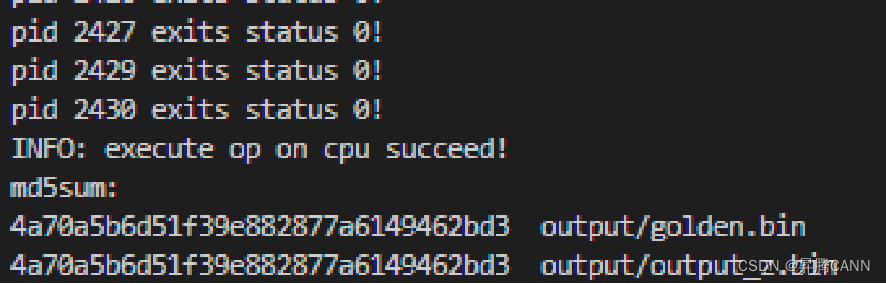
5、运行结果
CPU模式下的结果:
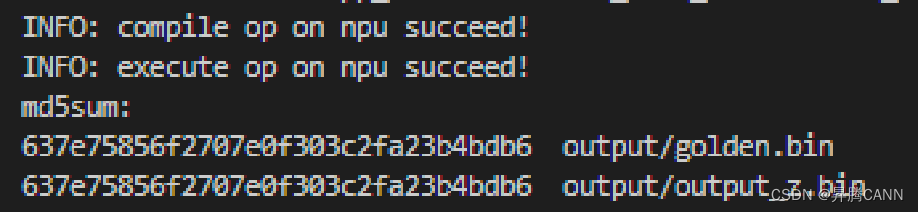
NPU模式下的结果:
二、CPU模式下算子调试技术
Ascend C提供孪生调试方法,即在cpu侧创建一个npu的模型并模拟它的计算行为,用来进行业务功能调试。以此进行业务功能的调试。相同的算子代码可以在CPU模式下进行精度调试,然后无缝切换到NPU模式下运行,主要有两种方法:
1、使用GDB进行调试
source /usr/local/Ascend/ascend-toolkit/set_env.sh
gdb --args add_custom_cpu
set follow-fork-mode child
break add_custom.cpp:45
run
list
backtrace
print i
break add_custom.cpp:56
continue
display xLocal
quit
| 命令 |
功能 |
| step |
执行下一行语句, 如语句为函数调用, 进入函数中 |
| next |
执行下一行语句, 如语句为函数调用, 不进入函数中 |
| continue |
从当前位置继续运行程序 |
| run |
从头开始运行程序 |
| quit |
退出程序 |
| |
输出变量值、调用函数、通过表达式改变变量值 |
| list |
查看当前位置代码 |
| backtrace |
查看各级堆栈的函数调用及参数 |
| break N |
在第N行上设置断点 |
| display |
每次停下来时,显示设置的变量var的值 |
由于cpu调测已转为多进程调试,每个核都是一个独立的子进程,故gdb需要转换成子进程调试的方式。
1)调试单独一个子进程
在gdb启动后,首先设置跟踪子进程,之后再打断点,就会停留在子进程中,设置的命令为:
set follow-fork-mode child但是这种方式只会停留在遇到断点的第一个子进程中,其余子进程和主进程会继续执行直到退出。涉及到核间同步的算子无法使用这种方法进行调试。
2)调试多个子进程
如果涉及到核间同步,那么需要能同时调试多个子进程。
在gdb启动后,首先设置调试模式为只调试一个进程,挂起其他进程。设置的命令如下:
(gdb) set detach-on-fork off查看当前调试模式的命令为:
(gdb) show detach-on-fork中断gdb程序的方式要使用捕捉事件的方式,即gdb程序监控fork这一事件并中断。这样在每一次起子进程时就可以中断gdb程序。设置的命令为:
(gdb) catch fork当执行r后,可以查看当前的进程信息:
(gdb) info inferiors
Num Description
* 1 process 19613可以看到,当第一次执行fork的时候,程序断在了主进程fork的位置,子进程还未生成。
执行c后,再次查看info inferiors,可以看到此时第一个子进程已经启动。
(gdb) info inferiors
Num Description
* 1 process 19613
2 process 19626这个时候可以使用切换到第二个进程,也就是第一个子进程,再打上断点进行调试,此时主进程是暂停状态:
(gdb) inferior 2
[Switching to inferior 2 [process 19626] ($HOME/demo)]
(gdb) info inferiors
Num Description
1 process 19613
* 2 process 19626请注意,inferior后跟的数字是进程的序号,而不是进程号。
如果遇到同步阻塞,可以切换回主进程继续生成子进程,然后再切换到新的子进程进行调试,等到同步条件完成后,再切回第一个子进程继续执行。
2、使用printf或者std::cout
在CPU代码侧直接插入C/C++的打印命令,如printf、std:.cout,但注意NPU模式下不支持打印语句,所以需要添加内置宏__CCE KT TEST__ 予以区分。
三、性能数据采集与分析
当使用内核调用符时,会生成相应的二进制可执行文件,可以使用性能采集工具运行NPU模式下生成的可执行文件从而采集Ascend C算子在昇腾平台上执行的性能数据。
1.设置环境变量(昇腾实际安装的位置):
source /usr/local/Ascend/ascend-toolkit/../set_env.sh2.测试NPU模式下的Ascend C算子,保证其精度正确,生成对应的二进制可执行文件:
bash run.sh add_tik2 ascend910 AiCore npu3.使用msprof工具采集性能,详细的介绍请参考昇腾社区文档:性能分析工具使用教程
用户可以根据自身的需要灵活组合性能分析指令,例如:
msprof --application="./add_custom_npu" --output="./out" --ai-core=on --aic-metrics="PipeUtilization"4.在当前目录会生成out文件夹,在device_0/summary/op_summary_0_1.csv能够看到一些具体的数据:
-
mte2类型指令(DDR->AICORE搬运类指令)的cycle数在所有指令的cycle数中的占用比
-
mte3类型指令(AICORE->DDR搬运类指令)的cycle数在所有指令的cycle数中的占用比
-
vector类型指令(向量类运算指令)的cycle数在所有指令的cycle数中的占用比
接下来就可以针对实际情况进行相应优化。
四、更多学习资源
好啦,本次分享结束啦,Ascend C的学习资源还有很多,想深入学习的可以参考官网教程:Ascend C官方教程 https://www.hiascend.com/zh/ascend-c?utm_source=cann&utm_medium=article&utm_campaign=all
https://www.hiascend.com/zh/ascend-c?utm_source=cann&utm_medium=article&utm_campaign=all