大模型面试基础+八股文【持续更新中】
来源:https://redian.news/wxnews/488452
一些参考:
https://zhuanlan.zhihu.com/p/643560888
https://zhuanlan.zhihu.com/p/643829565
https://zhuanlan.zhihu.com/p/558286175
https://zhuanlan.zhihu.com/p/632102048
https://github.com/5663015/LLMs_train
【大模型算法篇】
1.在指令微调中,如何设置、选择和优化不同的超参数,以及其对模型效果的影响?
论文《Finetuned Language Models Are Zero-Shot Learners》中提出了instruction-tuning。Google认为instruction-tuning是一种简单的方法来提高语言模型的zero-shot学习能力。
与Prompt不同,Instruction通常是一种更详细的文本,用于指导模型执行特定操作或完成任务。Instruction可以是计算机程序或脚本,也可以是人类编写的指导性文本。
Instruction的目的是告诉模型如何处理数据或执行某个操作,而不是简单地提供上下文或任务相关信息。
Instruction Tuning与Prompt tuning方法的区别:
Prompt tuning:针对每个任务,单独生成prompt模板(hard prompt or soft prompt),然后在每个任务上进行full-shot微调与评估,其中预训练模型参数是freeze的。
Instruction Tuning:针对每个任务,单独生成instruction(hard token),通过在若干个full-shot任务上进行微调,然后在具体的任务上进行评估泛化能力(zero shot),其中预训练模型参数是unfreeze的。
Instruction Tuning和Prompt方法的核心一样,就是去发掘语言模型本身具备的知识。而他们的不同点就在于,Prompt是去激发语言模型的补全能力,比如给出上半句生成下半句、或者做完形填空,都还是像在做language model任务,而Instruction Tuning则是激发语言模型的理解能力,通过给出更明显的指令,让模型去理解并做出正确的反馈。
Scaling Instruction-Finetuned Language Models
2.在指令微调中,如何选择最佳的指令策略,以及其对模型效果的影响?
3.llama, glm,bloom等现有大模型的数据处理,训练细节,以及不足之处模型架构的优化点,包括但不限于attention, norm, embedding
4.解决显存不够的方法有哪些?
深度学习显存优化方法
可以参考上述文章。
主要有:
- 梯度累计:即通过几个batch后才更新参数达到较大batch_size后进行训练
- 混合精度训练:训练时通过FP16和FP32混合精度进行训练
- 重计算 : 时间换空间的思想,在前向时只保存部分中间节点,在反向时重新计算没保存的部分,在每个batch只多计算一次前向的情况下,把n层网络的占用显存优化到了o(根号n)。训练速度慢一点,但batch_size可以增大好几倍。
5.请解释P-tuning 的工作原理,并说明它与传统的 fine-tuning方法的不同之处。
6.介绍一下Prefix-tuning的思想和应用场景,以及它如何解决一些NLP任务中的挑战
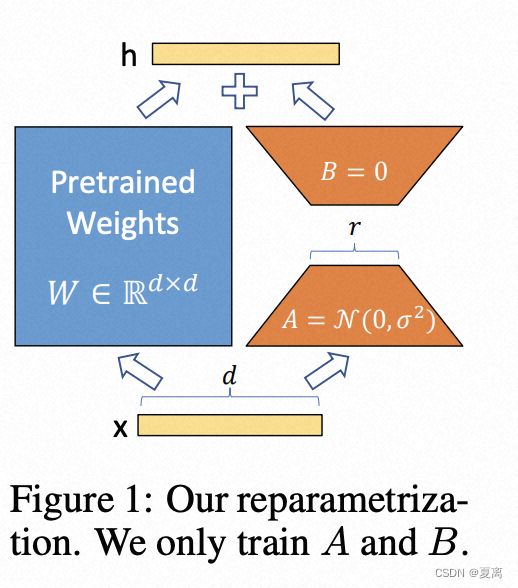
7.Lora的原理和存在的问题讲一下?
LoRA: Low-Rank Adaptation of Large Language Models
思想:冻结一个预训练模型的矩阵参数,并选择用A和B矩阵来替代,在下游任务时只更新A和B。
8.bf16,fp16半精度训练的优缺点
使用FP16训练神经网络,相对比使用FP32带来的优点有:
- 减少内存占用:FP16的位宽是FP32的一半,因此权重等参数所占用的内存也是原来的一半,节省下来的内存可以放更大的网络模型或者使用更多的数据进行训练。
- 加快通讯效率:针对分布式训练,特别是在大模型训练的过程中,通讯的开销制约了网络模型训练的整体性能,通讯的位宽少了意味着可以提升通讯性能,减少等待时间,加快数据的流通。
- 计算效率更高:在特殊的AI加速芯片如华为Ascend 910和310系列,或者NVIDIA VOTAL架构的Titan V and
Tesla V100的GPU上,使用FP16的执行运算性能比FP32更加快。
但是使用FP16同样会带来一些问题,其中最重要的是 精度溢出 和 舍入误差。
- 数据溢出:数据溢出比较好理解,FP16的有效数据表示范围为[-65504 - 66504],FP16相比FP32的有效范围要窄很多,使用FP16替换FP32会出现上溢(Overflow)和下溢(Underflow)的情况。而在深度学习中,需要计算网络模型中权重的梯度(一阶导数),因此梯度会比权重值更加小,往往容易出现下溢情况。
- 舍入误差:Rounding Error指示是当网络模型的反向梯度很小,一般FP32能够表示,但是转换到FP16会小于当前区间内的最小间隔,会导致数据溢出。如0.00006666666在FP32中能正常表示,转换到FP16后会表示成为0.000067,不满足FP16最小间隔的数会强制舍入。
为了想让深度学习训练可以使用FP16的好处,又要避免精度溢出和舍入误差。于是可以通过FP16和FP32的混合精度训练(Mixed-Precision),混合精度训练过程中可以引入权重备份(Weight Backup)、损失放大(Loss Scaling)、精度累加(Precision Accumulated)三种相关的技术。
9.如何增加context length 模型训练中节约显存的技巧。
10.RLHF完整训练过程是什么?RL过程中涉及到几个模型?显存占用关系和SFT有什么区别?
https://zhuanlan.zhihu.com/p/624589622
11.RLHF过程中RM随着训练过程得分越来越高,效果就一定好吗?有没有极端情况?
12.encoder only,decoder only,encoder-decoder 划分的具体标注是什么?典型代表模型有哪些?
LLM目前可以分为三类,Decoder-Only,Encoder-Only和Encoder- Decoder。
划分具体标准
根据网络架构中是否含有encoder和decoder来区分。
Encoder是将输入序列转化成一个固定长度的向量. Decoder则是将输入的固定长度向量解码成输出序列。
Encoder-Decoder 架构用于将输入序列转换为输出序列,适用于例如机器翻译等任务;encoder-only 架构主要关注输入数据的表示和特征提取,适用于例如文本分类等任务;decoder-only 架构专注于生成输出数据,适用于例如文本生成等任务。
1.Encoder-only:
在这种架构中,只有编码器部分被使用。编码器将输入数据映射到内部表示,这些内部表示可以用于各种任务,如分类、实体识别或文本相似度等。这些模型通常在输入数据上进行预训练,然后根据特定任务进行微调。对应的模型:BERT、ALBERT、RoBERTa
2.Encoder-Decoder:
Transformer本身是一个典型的encoder-decoder模型,这种架构包含两个主要部分:编码器(encoder)和解码器(decoder)。编码器负责将输入数据映射到一个固定大小的内部表示(通常称为上下文向量或隐藏状态)。解码器负责使用这个内部表示生成输出数据。这种架构通常用于序列到序列(seq2seq)任务,如机器翻译、文本摘要等。对应的模型:T5、BART
3.Decoder-only:
这种架构仅包含解码器部分。通常用于自回归(autoregressive)任务,如文本生成。在这种情况下,模型生成一个元素(如单词或字符),然后将其作为输入连同先前的元素继续生成后续元素。类似于 encoder-only,这些模型通常也会进行预训练。对应的模型:GPT
优劣
Decoder-only模型相比Encoder-Decoder模型优势:
1.结构简单,训练和推理速度快。由于没有Encoder部分,整个模型的参数和运算量都减少了一半以上,这使得Decoder-only模型训练和部署起来更加高效。
2.适用于纯生成任务。Decoder-only模型专注于生成输出序列,而不需要考虑编码输入信息的问题,所以更适用于如文本生成、情节生成和对话生成等纯生成任务。
3.避免了Encoder-Decoder训练中的一些难点。仅训练一个Decoder可以避免诸如不同权重初始化、信息瓶颈等 Encoder-Decoder训练过程中的一些难题。
4.Decoder自我监督。在Decoder-only模型的训练中,上一步生成的输出作为下一步的输入,这实现了Decoder部分的自我监督,有利于生成更为连贯和结构性的输出序列。
5.decoder-only模型在没有任何tuning数据的情况下、zero-shot表现最好,而encoder-decoder则需要在一定量的标注数据上做multitask finetuning才能激发最佳性能。
同时,Decoder Only结构保留的Skip Connection和MLP能很好的对抗Attention层的低秩,效果要优于Encoder Only。
【训练框架篇】
https://zhuanlan.zhihu.com/p/582498905
https://zhuanlan.zhihu.com/p/624412809
1.Megatron以及deepspeed实现原理,各种参数以及优化策略的作用
Megatron 支持transformer模型的模型并行(张量、序列和管道)和多节点预训练,同时还支持 BERT、GPT 和 T5 等模型。
DeepSpeed是微软的深度学习库,已被用于训练 Megatron-Turing NLG 530B 和 BLOOM等大型模型。
DeepSpeed的创新体现在三个方面:
- 训练
- 推理
- 压缩
DeepSpeed具备以下优势:
- 训练/推理具有数十亿或数万亿个参数的密集或稀疏模型
- 实现出色的系统吞吐量并有效扩展到数千个 GPU
- 在资源受限的 GPU 系统上训练/推理
- 为推理实现前所未有的低延迟和高吞吐量
- 以低成本实现极致压缩,实现无与伦比的推理延迟和模型尺寸缩减
2.模型训练以及推理中的显存占用各种混合精度训练的优劣
3.deepspeed的特点是什么?各个zero stage都有什么用?
【评测篇】
1.除了loss之外,如何在训练过程中监控模型能力?
2.如果想全面的评测模型能力,有哪些维度以及数据集?评测指标等评测中比较重要的部分要了解.
3.如何评测生成,改写等开放性任务?
4.zeroshot和Fewshot具体做法的区别?
【数据篇】
1.bloom,llama, glm等开源模型的数据来源,配比,以及不足之处
bloom–ROOTS 语料库
2.cot以及ic能力是如何涌现的?与预训练数据有何关系?
3.数据处理的重要步骤,如何保证预训练以及sft时候的数据多样性,数据质量,数据数量等,包括但不限于去重,质量筛选,敏感及有害信息过滤,各种来源数据配比对于模型能力的影响。
【基础】

图片来自知乎:养生的控制人
就图片内容进行展开
Transformer
一个典型的encoder-decoder结构,此后的模型基本都是基于它的结构做的。
transformer的encoder&decoder结构和self-attention这里不再展开,可自行阅读论文和其他公开资料。
这里需要注意的是,GPT-1 采用的还是「无监督预训练 + 监督微调」(也就是之前占据主流的pretrain+finetune的形式),而GPT-2则开始认为不只是预训练过程无监督,整个学习过程都可以无监督,开始探索LLM 下一阶段的可能范式:基于扩展性极好的 Transformer Decoder 架构上(撑得起巨量参数规模)构建模型,并投喂足够多的数据(海量数据已经潜在包括各种任务模式)进行无监督预训练(所有任务都「隐式」地变成从左至右的生成训练)。而GPT-3 则比较充分展示了训练范式上不用微调的可信性,在大量参数和大规模数据的情况下,不需要在子任务监督微调就可以和当时以bert为主流的pretrain+finetune模型效果相当 ,范式开始转化为pretrain+prompt的形式 —— 也拉开了「大模型、大数据、大算力」的大模型之幕。
分词器
https://zhuanlan.zhihu.com/p/86965595
https://zhuanlan.zhihu.com/p/620508648
BPE
import re, collections
def get_stats(vocab):
pairs = collections.defaultdict(int)
for word, freq in vocab.items():
symbols = word.split()
for i in range(len(symbols)-1):
pairs[symbols[i],symbols[i+1]] += freq
return pairs
def merge_vocab(pair, v_in):
v_out = {}
bigram = re.escape(' '.join(pair))
p = re.compile(r'(? + bigram + r'(?!\S)')
for word in v_in:
w_out = p.sub(''.join(pair), word)
v_out[w_out] = v_in[word]
return v_out
vocab = {'l o w ': 5, 'l o w e r ': 2, 'n e w e s t ': 6, 'w i d e s t ': 3}
num_merges = 1000
for i in range(num_merges):
pairs = get_stats(vocab)
if not pairs:
break
best = max(pairs, key=pairs.get)
vocab = merge_vocab(best, vocab)
print(best)
优点: 可以有效地平衡词汇表大小和步数(编码句子所需的token数量)。
缺点: 基于贪婪和确定的符号替换,不能提供带概率的多个分片结果。
wordpiece
WordPiece算法可以看作是BPE的变种。不同点在于,WordPiece基于概率生成新的subword而不是下一最高频字节对。
BPE与Wordpiece都是首先初始化一个小词表,再根据一定准则将不同的子词合并。词表都是由小变大
两者最大区别在于,如何选择两个子词进行合并:BPE选择频数最高的相邻子词合并,wordpiece衡量的是token对和单独的两个token之间的概率差,选择概率差最大的进行合并。
考虑token a和b,以及合并之后的token ab,概率差的公式如下:
p(a,b)/(p(a)∗p(b))
这可以近似理解为合并前后,整个语料的互信息。即,当前选择合并的token对能够让语料的熵最小化->确定性最大化->信息量最小化->在计算机中存储所需要的编码长度最短化。
bert的tokenizer使用的就是wordpiece。
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
tokenizer.tokenize("I have a new GPU!")
# ["i", "have", "a", "new", "gp", "##u", "!"]
SentencePiece
SentencePiece它是谷歌推出的子词开源工具包,其中集成了BPE、ULM子词算法。除此之外,SentencePiece还能支持字符和词级别的分词。它是把一个句子看作一个整体,再拆成片段,而没有保留天然的词语的概念。一般地,它把空格space也当作一种特殊字符来处理,再用BPE或者Unigram算法来构造词汇表。 比如,XLNetTokenizer就采用了_来代替空格,解码的时候会再用空格替换回来。使用SentencePiece的模型包括ALBERT,XLNet,Marian和T5。
import sentencepiece as spm
# train sentencepiece model from our blog corpus
spm.SentencePieceTrainer.train(input='blog_test.txt',model_prefix=bpe --vocab_size=500, user_defined_symbols=['foo', 'bar'])
# makes segmenter instance and loads the BPE model file (bpe.model)
sp_bpe = spm.SentencePieceProcessor()
sp_bpe.load('bpe.model')
位置编码
Rope
是一种配合Attention机制能达到“通过绝对位置编码的方式实现相对位置编码”的设计。而也正因为这种设计,它还是目前唯一一种可用于线性Attention的相对位置编码。
具体推理计算见苏神的文章就好
Alibi
https://ofir.io/train_short_test_long.pdf
ALiBi 很容易实现,只需几行代码就能完成所有更改。
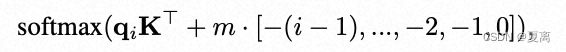
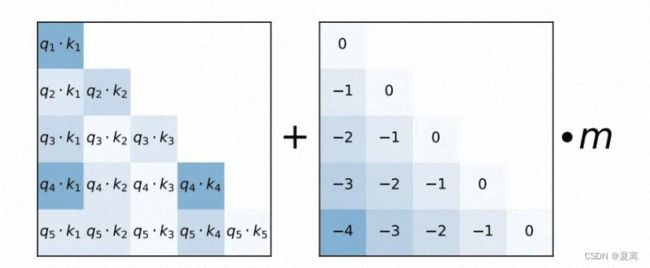
通过在mask矩阵中添加线性bias来修改mask矩阵,因为没有在网络中添加任何操作,所以不会带来运行时间上的损失。
https://github.com/ofirpress/attention_with_linear_biases/blob/master/fairseq/models/transformer.py
# 从模型中删除位置嵌入:
#if positions is not None:
# x += positions
#设置相对偏差矩阵
def get_slopes(n):
def get_slopes_power_of_2(n):
start = (2**(-2**-(math.log2(n)-3)))
ratio = start
return [start*ratio**i for i in range(n)]
if math.log2(n).is_integer():
return get_slopes_power_of_2(n)
#In the paper, we only train models that have 2^a heads for some a. This function has
else:
#some good properties that only occur when the input is a power of 2. To maintain that even
closest_power_of_2 = 2**math.floor(math.log2(n))
#when the number of heads is not a power of 2, we use this workaround.
return get_slopes_power_of_2(closest_power_of_2) + get_slopes(2*closest_power_of_2)[0::2][:n-closest_power_of_2]
#将偏差矩阵添加到掩码中,然后将其添加到每个注意力分数计算中
def buffered_future_mask(self, tensor):
dim = tensor.size(1)
# self._future_mask.device != tensor.device is not working in TorchScript. This is a workaround.
if (
self._future_mask.size(0) == 0
or (not self._future_mask.device == tensor.device)
or self._future_mask.size(1) < self.args.tokens_per_sample
):
self._future_mask = torch.triu(
utils.fill_with_neg_inf(torch.zeros([self.args.tokens_per_sample,self.args.tokens_per_sample])), 1
)
self._future_mask = self._future_mask.unsqueeze(0) + self.alibi
self._future_mask = self._future_mask.to(tensor)
return self._future_mask[:tensor.shape[0]*self.args.decoder_attention_heads, :dim, :dim]
#将掩码计算移至层循环之前,计算可以更快一点
#We move the mask construction here because its slightly more efficient.
if incremental_state is None and not full_context_alignment:
self_attn_mask = self.buffered_future_mask(x)
else:
self_attn_mask = None
LayerNorm
可以参考
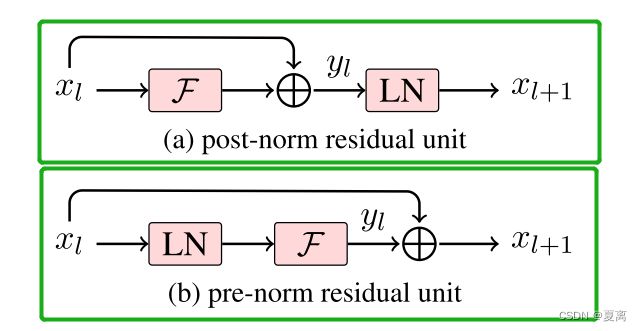
传统的Add之后做layer normalization的方式叫做post-norm,而把layer normalization加在残差之前叫pre-norm,如下图所示。
PreNorm
Pre-Norm有一部分参数直接加在了后面,没有对这部分参数进行正则化,可以在反向时防止梯度爆炸或者梯度消失,大模型的训练难度大,因而使用Pre-Norm较多。
分布式训练
分布式计算的准则:让计算和通讯重叠(尤其是计算>通讯时间时,这样通讯不会导致整体变慢)
并行
包括数据并行和模型并行(tensor并行和pipeline并行)
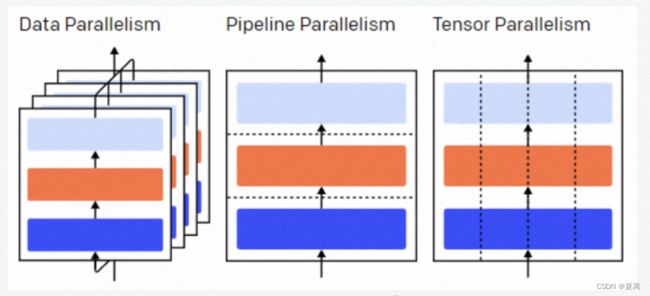
数据并行和模型并行区别在于计算的参数是否是模型完整参数,数据并行需要模型完整参数出现在gpu上,而模型并行的gpu只需要部分参数进行计算然后合作完成整体计算。
数据并行
数据并行是为了解决显存墙问题,将模型切分存放到多个gpu上。
ZeRO(ZEroRedundancyOptimizer) 是DeepSpeed提出的一种分布式数据并行的加速方案,用于提高模型参数之外的显存空间并行性。
针对模型状态的存储优化,ZeRO使用的方法是分片,即每张卡只存 1/N 的模型状态量,这样系统内只维护一份模型状态。
ZeRO-1:optimizer分片
参数量为p,n张卡,每张卡永久持有p/n,前向过程由每个rank的GPU独自完整的完成,在反向计算过程中,梯度通过allReduce进行同步。
ZeRO-2:optimizer + Gradient分片
1. 当前层的优化器计算->梯度更新,可以不和之前层一起完成
2. 第N-1层反向的过程,跟N层的梯度更新没有关系
因此:第N层反向计算完成,就可以触发第N层的优化器,在backward过程中,gradients被reduce操作到对应的rank上,取代了all-reduce,以此减少了通讯开销。
每个rank独自更新各自负责的参数。
优点:反向时梯度pl/n 降低到 p/n
副作用:global layer norm/loss scale 退化到以层単位
ZeRO-3:optimizer + Gradient + model分片
import torch.optim as optim
from fairscale.optim.oss import OSS
from torch.nn.parallel import DistributedDataParallel as DDP
from fairscale.nn.data_parallel import ShardedDataParallel as SDP
from fairscale.nn.data_parallel import FullyShardedDataParallel as FSDP
if args.zero1:
base_optimizer_arguments = {'lr':0.05}
base_optimizer = torch.optim.Adam
optimizer = OSS(
params=model.parameters(),
optim=base_optimizer,
**base_optimizer_arguments)
model = DDP(model)
elif args.zero2:
base_optimizer_arguments = {'lr':0.05}
base_optimizer = torch.optim.Adam
optimizer = OSS(
params=model.parameters(),
optim=base_optimizer,
**base_optimizer_arguments)
model = SDP(model, optimizer)
if args.autocast:
from fairscale.optim.grad_scaler import ShardedGradScaler
scaler = ShardedGradScaler()
elif args.zero3:
print(f'zero3 ----')
optimizer = optim.Adam(model.parameters(), lr=0.05)
model = FSDP(model, mixed_precision=True)
zero总结:
• 解决了DDP无法支撑大模型的问题
• 但同时也有其他问题:前向、反向,产生了两次等同于整个模型参数量的通讯量
• 每卡仍需要一层的完整参数
模型并行
横向切分(按层区分)–pipeline并行,通信量是结果的大小
纵向并行(把同一层的tensor切分为n份)–tensor并行,通信量是gpu gather汇总结果,(n-1)/n * result
tensor并行
Tensor 并行可以解决模型过大 GPU 显存不够用,无法通过 “数据并行”进行训练的问题
• Tensor 并行基于矩阵运算的可拆解特性进行并行计算
• Tensor 并行需要额外的通信开销来汇总结果
• Tensor 并行通过切分矩阵降低了单卡计算量,降低了 GPU 利用率。根据木桶原理,需要根据具体模型的通信时间和计算时间来决定是否采用
tensor可以通过行切和列切进行tensor的拆分,如 transformer是由multi-head self-attention和mlp两部分组成
Attention的计算过程的矩阵计算, 首先是在前面Q K / V 计算中每个Head中Q / K / V 对应有三个weight矩阵 Wq, Wk和 Wv,然后是在最后对Z 进行汇总时要用到weight矩阵 W0。这里由于多头注意力的计算天然具有并行,通过列切权重矩阵Wq, Wk和 Wv。
mlp部分通过列切权重
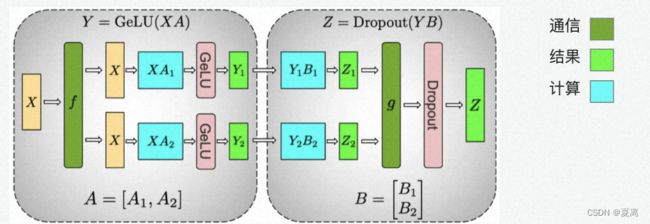
import torch
from torch. distributed._tensor import DTensor, DeviceMesh
from torch.distributed.tensor.parallel import (
PairwiseParallel,
parallelize_module,
)
MyModel = torch.nn.Module
NUM DEVICES = 2
def train(rank):
inp_size = [5, 10]
device_type = f"cuda: {rank}"
inp = torch.rand (*inp_size, device=device_type)
model_tp = MyModel()
# Shard module and initialize optimizer.
device_mesh = DeviceMesh(
device_type,
torch. arange (0, NUM_DEVICES),
)
parallel_style = PairwiseParallel()
model_tp = parallelize_module(model_tp, device_mesh, parallel_style)
optim_tp = torch.optim.SGD(model_tp.parameters() , lr=0.25)
output_tp = model_tp(inp)
output_tp.sum().backward()
optim_tp.step()
pipeline并行
将模型进行层间拆分。
如名字一样,是层之间按照流水线顺序处理,因此存在等待时间,即流水Bubble(Bubble是指在某些阶段没有任何有用工作正在进行的地方),这是由节点之间的依赖关系引起的。
空跑时间相较于理想时间的比值取决于流水线深度(stage数)n和microbatch数m:
- Bubble中包含几-1个前向,n-1个反向:(n-1)(tf + t0)
- 理想情况下总的处理时间:m(tf+ t0)
- Bubble占比:n-1/m
- 计算效率正比于microbatch数
显存需求:同时取决于网络深度和batchsize,即o(bl/n)
利用checkpointing可以降低显存需求
- 不缓存计算梯度所需的所有激活值而是在反向传播过程中动态地重计算这些激活值。
- 一个常用的策略时仅缓存在GPU边界的输入(从前一个GPU传递过来的张量)
- 显存需求:o(b+l/n*b/m)前者代表缓存边界激活值的显存,反向计算时,显存需求则正比于一个microbatch在本stage的激活层大小。
基础的流水线并行,同一时刻只有一个设备进行计算,其余设备处于空闲状态,计算设备利用率通常较低。 Gpipe将原本的 mini-batch(数据并行切分后的batch)划分成多个 micro-batch(mini-batch再切分后的batch),每个 pipeline stage (流水线并行的计算单元)先整体进行前向计算,再进行反向计算。其中对每个microbatch的梯度求和,就会得到整个batch的梯度,这个过程称为梯度累积。由于每一个stage只存在于一个GPU,因此求和不涉及任何通信。
def apply_gradients(self, grads_and_vars, global_step=None, name=None):
if self._num_micro_batches == 1:
return self._opt.apply_gradients(grads_and_vars, global_step)
global_step = global_step or py_utils.GetOrCreateGlobalStepVar()
with tf.init_scope():
self._create_slots([v for (_, v) in grads_and_vars])
accums = []
variables = []
# 遍历,累积梯度
for g, v in grads_and_vars:
accum = self.get_slot(v, 'grad_accum')
variables.append(v)
# pytype: disable=attribute-error
if isinstance(g, tf.IndexedSlices):
scaled_grad = tf.IndexedSlices(
g.values / self._num_micro_batches,
g.indices,
dense_shape=g.dense_shape)
else:
scaled_grad = g / self._num_micro_batches
accum_tensor = accum.read_value()
accums.append(accum.assign(accum_tensor + scaled_grad))
# pytype: enable=attribute-error
# 应用梯度,清零梯度
def _ApplyAndReset():
normalized_accums = accums
if self._apply_crs_to_grad:
normalized_accums = [
tf.tpu.cross_replica_sum(accum.read_value()) for accum in accums
]
apply_op = self._opt.apply_gradients(
list(zip(normalized_accums, variables)))
with tf.control_dependencies([apply_op]):
zero_op = [tf.assign(accum, tf.zeros_like(accum)) for accum in accums]
return tf.group(zero_op, tf.assign_add(global_step, 1))
# 累积函数,其实是不做操作
def _Accum():
return tf.no_op()
# 梯度累积条件,如果达到了小批次迭代数目,则应用梯度,清零梯度,否则就不做操作
accum_step = tf.cond(
tf.equal(
tf.math.floormod(self._counter + 1, self._num_micro_batches), 0),
_ApplyAndReset, # Apply the accumulated gradients and reset.
_Accum) # Accumulate gradients.
with tf.control_dependencies([tf.group(accums)]):
return tf.group(accum_step, tf.assign_add(self._counter, 1))
Gpipe的流水线有几个问题:
- 过多流水线刷新导致空闲时间的增加。
- 如果m很小,Gpipe可能会由于重新计算开销和频繁的pipeline刷新而降低硬件效率,所以 m一般都设置的较大。 于是需要缓存 m 份。
- activation导致内存增加。原因是每个microbatch前向计算的中间结果activation都要被其后向计算所使用,所以需要在内存中缓存。
PipeDream 的 1F1B(One Forward pass followed by One Backward pass)策略就可以解决缓存 activation 的份数问题,使得 activation 的缓存数量只跟阶段(stage)数相关,从而进一步节省显存。Bubble与GPipe—致但显存占用更小。具体来说,把一个batch的同步变为了众多小数据(minibatch)上的异步,计算完一个minibatch就立刻反向,即在microbatch最后一个stage的前向执行完之后立即执行反向,一个minibatch的反向结束之后就更新对应worker的梯度。

- 在steady state 每一个stage交替执行microbatch的前向和反向,因此也被称为1F1B
- 在输入阶段直接执行(不反向)的microbatch数量决定了steady state中GPU能否被占满。
- 在执行完切分的microbatches再聚合梯度。
序列并行
大模型由于attention计算时候q要和k进行交互,导致o(n2)的内存占用,长序列能力受限。一些解决方法:
- 稀疏 attention 算法:Sparse Transformer/Longformer/BigBird
- 低秩算法:Linformer/Cosformer
因此想到序列并行,即进行样本序列维切分,使得可以处理长序列:
- MLP/Norm层:计算与序列维无关
- 自注意力 Self-Attention
- 序列维上 query/key/value 全局互联
一些序列并行相关工作:
Megatron-LM3:
- 修改通讯算子对
- Dropout/LayerNorm 序列并行
ColossalAl 序列并行:
- 采用Ring 通讯 Key/Value
- attention map 显存累增
FlashAttention
Attention Map 切分,通讯计算
FlashAttention是一种新的注意力机制,旨在解决Transformer在处理长序列时速度慢且内存需求大的问题。
FlashAttention的创新之处在于**引入了IO(输入/输出)感知的设计原则,专注于减少GPU内存(高带宽内存)和GPU片上内存(SRAM)之间的读写次数。**它使用平铺(tiling)的方法来实现这一目标,从而降低了数据在不同级别存储器之间的传输次数。
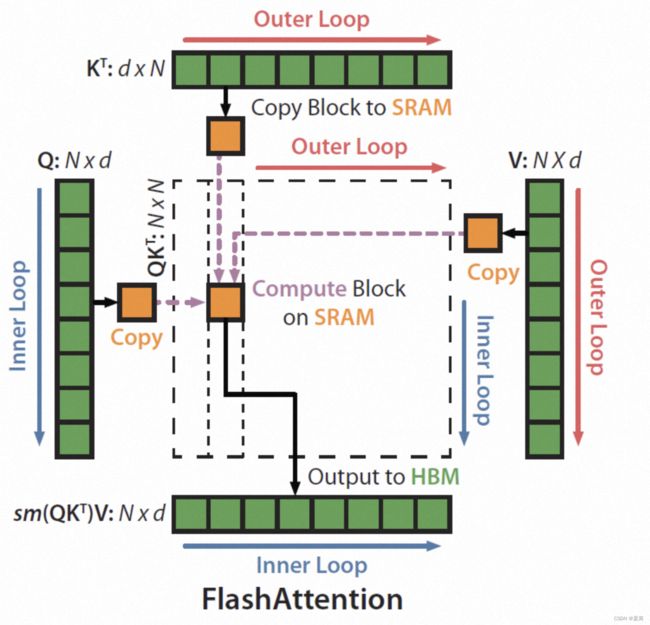
混合精度计算
高效微调
https://zhuanlan.zhihu.com/p/636481171
BiTFiT
BitFit只对模型的bias进行微调。在小规模-中等规模的训练数据上,BitFit的性能与全量微调的性能相当,甚至有可能超过,在大规模训练数据上,与其他fine-tuning方法也差不多。作者提出,fine-tuning是在模型训练中的知识暴露而不是在新领域学习新领域任务。
对于Transformer模型而言,冻结大部分 transformer-encoder 参数,只更新bias参数跟特定任务的分类层参数。涉及到的bias参数有attention模块中计算query,key,value跟合并多个attention结果时涉及到的bias,MLP层中的bias,Layernormalization层的bias参数。
实现起来也非常简单
for name, param in model.named_parameters():
if '.bias' not in name:
param.requires_grad=False
Prefix Tuning
Adapter Tuning
Adapter Tuning通过在transformer的层中插入针对特定任务的残差模块,并只优化这些残差模块。由于残差模块的参数更少(约3.6%),因此微调成本更低。
每当出现新的下游任务,通过添加Adapter模块来产生一个易于扩展的下游模型,从而避免全量微调与灾难性遗忘的问题。
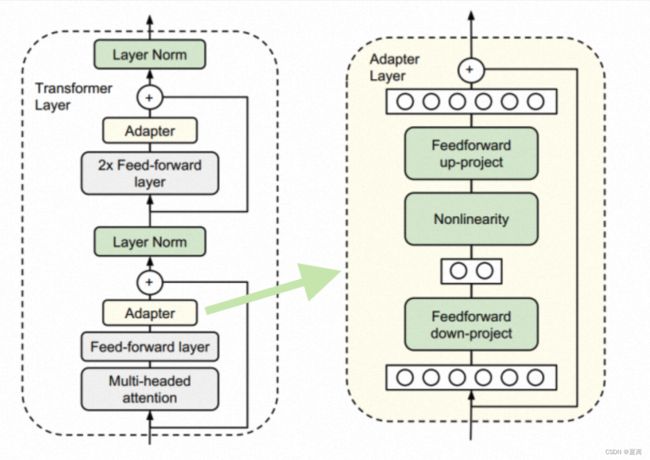
diff pruning
Diff pruning 与Adapter类似,但 Diff pruning 不是修改模型的结构,而是通过一个特定任务的 diff 向量扩展基础模型。只微调0.5%的预训练参数。