Three-Dimensional Human Pose Estimation with Spatial–Temporal Interaction Enhancement Transformer
基于时空交互增强Transformer的三维人体姿态估计
摘要
人体三维姿态估计是计算机视觉领域的一个研究热点。近年来,在从单目视频估计3D人体姿势方面取得了重大进展,但由于自遮挡和深度模糊的问题,这项任务仍有很大的改进空间。一些先前的工作已经解决了上述问题,调查的时空关系,并取得了很大的进展。在此基础上,我们进一步探讨了时空关系,并提出了一种新的方法,称为STFormer。我们的整个框架包括两个主要阶段:(1)独立于时间域和空间域提取特征;(2)跨领域的信息交流建模。将时间依赖性注入空间域,动态修改关节间的空间结构关系。然后,使用结果来细化时间特征。经过前面的步骤,空间和时间特征都得到了加强,估计的最终姿态将更加精确。我们在一个众所周知的数据集(Human3.6)上进行了大量的实验,结果表明,STFormer在输入9帧的情况下优于最近的方法。与PoseFormer相比,我们的方法的性能将MPJPE降低了2.1%。此外,我们进行了大量的消融研究,以分析和证明STFormer的各个组成模块的有效性。
引言
我们的贡献总结如下:
1.为了从单目视频中更准确地预测3D人体姿势,我们设计了一个时空交互增强的Transformer网络,称为STFormer。STFormer是一个两阶段的方法,其中第一阶段分别从空间和时间域独立地提取特征,第二阶段跨域交互空间和时间信息以丰富表示。
2.在第二阶段中,我们设计了空间重构块和时间细化块。空间重构块将时间特征注入空间域以调整空间结构关系;然后将重构的特征发送到时间细化块以补充时间特征中较弱的帧内结构信息。
方法
图1展示了我们的STFormer的整个框架。我们采用了[11,14,29]中使用的2D到3D提升方法,将2D视频姿势序列作为输入并预测中间帧的3D姿势。提出的两阶段网络STFormer由特征提取(FE)和跨域交互(CDI)。具体地,FE包含两个分支,空间特征提取(SFE)分支和时间特征提取(TFE)分支,其分别负责对人体关节的固有结构和时间依赖性进行建模。CDI包括空间重构(SR)块和时间细化(TR)块,其负责在前一阶段中提取的信息的交互。
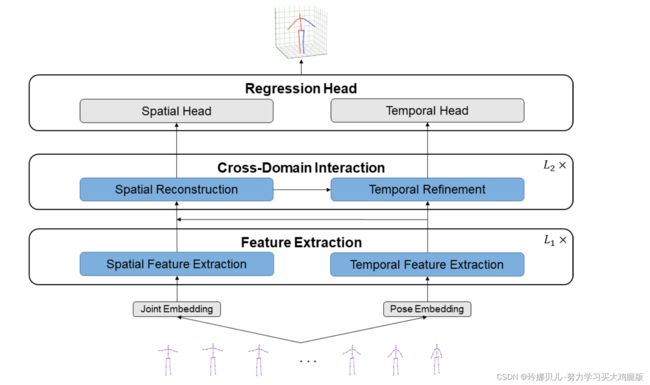
空间特征提取

对于空间域,我们提出了由Transformer编码器组成的SFE来建模每个帧的人类关节的内在结构关系(参见图3a,c)。更具体地说,我们将2D姿势的每个关节视为令牌,并采用线性投影层将其嵌入高维空间:Xi ∈ RJ×2嵌入−→ XSi ∈ RJ×C,其中Xi是第i个框架,C是联合嵌入维数。然后,为了保存空间位置信息,我们在此高维特征中添加了一个可学习的空间位置嵌入ES pos ∈ RJ×C,使其成为ZSi0 ∈ RJ×C。最后,将ZSi0 ∈ RJ×C输入到SFE中,以提取各节理的空间结构信息。这些过程可以描述为:
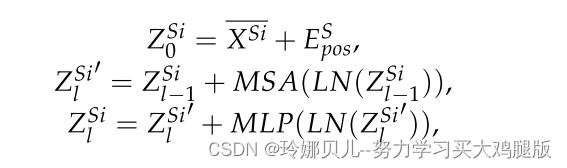
时间特征提取
虽然SFE可以获得关节之间的固有结构,但它忽略了视频帧之间的时间依赖性。为了探索时间上一致的信息,我们提出了一个类似SFE的分支TFE(参见图3b,c)。我们应该在时间域中构造特征表示。为此,与空间域中的操作不同,我们将2D姿态的每个帧视为时间域中的令牌。然后,将其发送到TFE分支以学习输入序列之间的全局关系。对于输入X ∈ RN×J×2,我们首先将每一坐标系中所有关节的坐标进行组合,记为XT ∈ RN×(J·2)。然后,与初始空间特征一样,我们将它们嵌入到高维特征XT ∈ RN×D中(D表示每帧的嵌入维数),并添加可学习的位置编码ET pos ∈ RN×D以保留帧的位置信息。最后,我们将嵌入的功能输入TFE。这些程序可以表示为:

跨域交互
身体关节之间的结构关系对于不同的运动状态不是不变的[22]。例如,对于“跑步”姿势,手和脚之间有很强的联系:到达左手时伴随着右脚的相应步伐,而对于其它姿势,可能不存在这种关系。因此,应针对不同的位姿建模相应的空间结构关系。在时间域中,我们将每一帧姿态作为一个标记来提取时间信息,但忽略了每一帧内部的空间结构关系。为了解决上述问题,提出了一种由空间重构模块(SR)和时间细化模块(TR)组成的跨域交互模块。SR块将时间动作信息注入到空间域中,从而允许网络基于该信息来调整关节之间的关系。然后,SR块的输出被转换到时域作为TR块的输入,以补充时间特征中空间结构信息的缺乏。为了公式编写的方便,我们使用ZSi l,ZT l分别表示跨域交互模块中的空间和时间特征,ZSi 0 = ZSi L1和ZT 0 = ZT L1。
1.空间重构
在第一阶段,我们分别从时间和空间域提取特征。然而,这两种类型的信息是独立提取的,它们之间没有交互作用。为了利用时间动作信息来重建关节的结构关系,我们需要将时间特征注入到空间域。在此之前,我们必须认识到时间和空间特征是不一致的。在时间域中,二维位姿序列的每一帧由一个维数为1 × D的标记表示,而在空间域中,特征维数为J ×C,每个标记表示一个关节。这导致来自不同领域的信息不能直接交互。为了实现跨域时间信息注入,我们提出了SR块(参见图4a),其由特征变换单元(FTU)、多头交叉注意(MCA)、MSA和MLP组成。
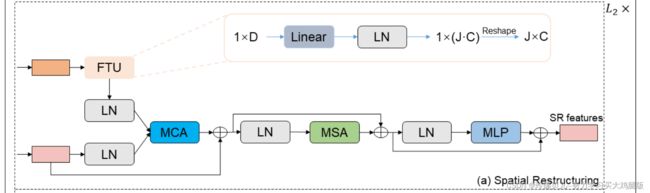
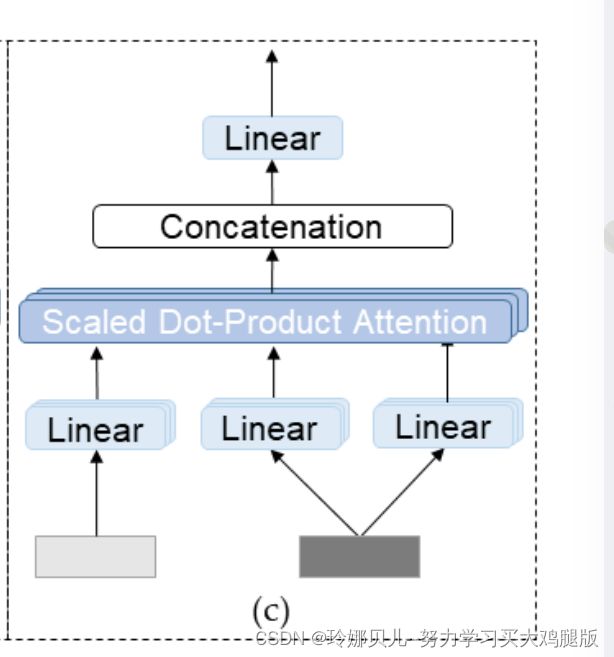
我们首先利用FTU将时间特征转换到空间域。具体地,线性层将时间特征通道的数量转换为J · C,然后通过LayerNorm层。最后,对通道进行分组并整形为J ×C。在上述操作之后,时间特征被成功地从时间域变换到空间域(ZT 1-{ZT-S11,ZT-S21,· · ·,ZT-SN 1})。接下来,将空间特征ZS 11馈送到MCA。MCA与来自不同域的信息进行交互,并且具有与MSA相似的结构(参见图2c)。特征Z Si l用作查询,而特征Z ZT-Si l用作键和值。我们使用MCA将时间特征ZT→Si_l注入到空间特征中,然后所得特征ZSi_l_l通过MSA和MLP以重构关节之间的关系,其可以用公式(6)表示。
 其中l ∈ [1,··,L2]是CDI层的索引。在这些操作之后,我们成功地将时间特征注入到空间域中,并且在L2层CDI模块之后从SR块获得最终的空间重构特征Δ ZSi L2。
其中l ∈ [1,··,L2]是CDI层的索引。在这些操作之后,我们成功地将时间特征注入到空间域中,并且在L2层CDI模块之后从SR块获得最终的空间重构特征Δ ZSi L2。
2.时间细化
我们建议TR利用SR的输出来细化具有较弱空间结构关系的时间特征。TR由FTU、MCA和MLP组成(见图4 b)。与SR中的先前操作一样,我们需要将空间特征转换到时域。SR输出的每一帧ZSi l ∈ RJ×C被整形为向量ZSi l ∈ R1×(J·C)。然后,将N个帧向量ZS 11、ZS 21、· · ·、ZSN 1级联并通过线性层将特征维度从RN×(J·C)改变为RN×D。最后,利用LayerNorm层对特征进行归一化,表示为ZS-Tl,并将其与时间特征ZT-起发送到MCA以补充时间域中的较弱空间结构关系。它与SR的不同之处在于TR使用时间特征作为查询,并将重建的空间特征作为键和值。
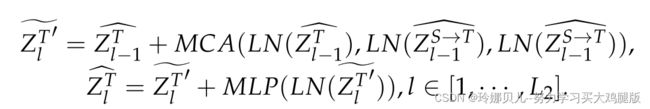
回归头
在回归头中,我们的模型学习两个不同的线性回归函数,以分别从空间和时间域回归3D姿态。在空间域中,空间头部被应用于ZSi L2 ∈ RJ×C以将每个关节的维度从C映射到3,用于在帧i处生成3D姿态XSi ∈ RJ×3,其中3表示3D空间中的关节坐标。中心帧中的姿势用XS标记。对于时域,颞头应用于ZT L2以回归3D姿态XT ∈ RN×J×3。然后,选择中间帧的姿态并表示为XT ∈ RJ×3。最终,模型的最终预测是XS和XT的平均值。